What should be the size of the Thread Pool?
In our article Stream API & ForkJoinPool, we already talked about the possibilities to change the size of the thread pool, which we can use in parallel handlers that use the Stream API or Fork Join. I hope this information came in handy when as a Senior Java Developer, you were able to increase the performance of your developed system by changing the default pool size. Since our coursesAs a whole, they are sharpened to go a step higher from the junior and middle middle higher, then part of the program is built on the basis of the basic questions asked at the interviews. One of which sounds like this: “You have an application. And there is a task using the Stream API or Fork Join, which can be parallelized. Under what conditions can you find it reasonable to change the default thread pool size? What size do you propose in this case? ”
You can try to answer this question yourself before reading further to check your own readiness for such an interview at the moment.
To back up theoretical considerations with real numbers, we suggest running a small benchmark for the standard Arrays.parallelSort () method, which implements a variant of the merge sort algorithm and runs on ForkJoinPool.commonPool (). Run this algorithm on the same large array with different sizes commonPool and analyze the results.

The machine on which the benchmark was run has 4 cores and the Windows operating system, which is not the most suitable for server applications, overloaded with background services, so a fairly significant scatter is visible in the results, but nevertheless it will not hurt to see the essence of things.
The benchmark is written using JMH and looks like this:
Having executed this code, we got the following final results (in fact, several runs were made, the numbers were slightly different, but the overall picture remained unchanged):
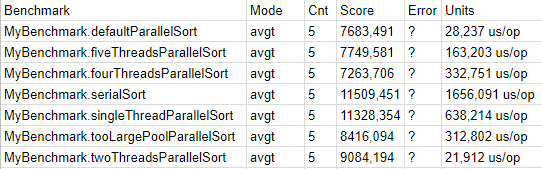
So the winner of the rating was fourThreadsParallelSort. In this test, we set the pool size to the number of cores on my machine, and therefore one more than the default pool. Nevertheless, the fact that this micro-benchmark wins does not mean that you should determine the size of commonPool in your application equal to the number of cores, and not use one less worker, as the JDK developers suggest. We would suggest accepting their point of view and never change the size of commonPool for most applications, however if we want to squeeze the maximum out of the machine and are ready to prove by the more general macro benchmarks that the game is worth the candle, we can get a small gain in more complete CPU utilization setting commonPool equal to the number of cores. At the same time, do not forget that system threads, for example Garbage Collector,
defaultParallelSort - was in second place. Pool size - 3 threads. During the process, CPU utilization was observed at about 70%, in contrast to 90% in the previous case. Therefore, it turned out to be incorrect to argue that the main program stream from which we call parallel sorting will become a full-fledged worker raking fork join tasks.
fiveThreadsParallelSort - showed us how we begin to lose efficiency by setting the pool size to just one more than the number of cores. This test lost a little to the default, while CPU utilization was about 95%.
tooLargePoolParallelSort - showed that if we further increase the pool size (in this case, up to 128 threads), then we will continue to lose efficiency and utilize the processor even more densely (about 100%).
twoThreadsParallelSort - was in last place in the ranking, and demonstrated that if we simply leave one of the cores without work for no particular reason, the result will be very mediocre.
You may ask, what about serialSort and singleThreadParallelSort? But nothing. They simply cannot be compared with other options, because inside there is no merge sort at all, but a completely different algorithm - DualPivotQuickSort, and on different input data it can show results that are both inferior to the tested algorithm and superior to them. You can say more, on most random arrays that were considered, DualPivotQuickSort significantly outperformed Arrays.parallelSort, and it was just lucky to generate this time an array in which parallelSort showed the best results. Therefore, we decided to include this particular array in the benchmarks so that you would not think that parallelSort never makes any sense to use. Sometimes it has, but do not forget to check it and prove it with good tests.
And finally, let's try to answer the question: "In what cases can it be reasonable to resize commonPool?". We have already considered one case - if we want to utilize the CPU more densely, then sometimes it may make sense to set the size of commonPool equal to the number of cores, and not one less than the default value. Another case may be the situation when others are launched at the same time as our application, and we want to manually divide the processor cores between applications (although docker seems to be more appropriate for these purposes). And finally, it may turn out that the tasks that we really want to put in the Fork Join Pool are not clean enough. If these tasks allow themselves not only to calculate and read / write in RAM, but also to sleep, wait, or read / write to a blocking input / output source. In this case, it is not recommended to place such tasks in commonPool, because they will take up a precious thread from the pool, the thread will go into standby mode, and the kernel, which was supposed to be utilized by this thread, will be idle. Therefore, for such a little sleepy tasks it is better to create a separate, custom ForkJoinPool.
THE END
Questions and suggestions as always welcome here and at the open door . We are waiting, sir.
You can try to answer this question yourself before reading further to check your own readiness for such an interview at the moment.
To back up theoretical considerations with real numbers, we suggest running a small benchmark for the standard Arrays.parallelSort () method, which implements a variant of the merge sort algorithm and runs on ForkJoinPool.commonPool (). Run this algorithm on the same large array with different sizes commonPool and analyze the results.
The machine on which the benchmark was run has 4 cores and the Windows operating system, which is not the most suitable for server applications, overloaded with background services, so a fairly significant scatter is visible in the results, but nevertheless it will not hurt to see the essence of things.
The benchmark is written using JMH and looks like this:
```
package ru.klimakov;
import org.openjdk.jmh.annotations.*;
import java.util.Arrays;
import java.util.Random;
import java.util.concurrent.TimeUnit;
@Fork(1)
@Warmup(iterations = 10)
@Measurement(iterations = 5)
@BenchmarkMode(Mode.AverageTime )
@OutputTimeUnit(TimeUnit.MICROSECONDS)
public class MyBenchmark {
@State(Scope.Benchmark)
public static class BenchmarkState {
public static final int SEED = 42;
public static final int ARRAY_LENGTH = 1_000_000;
public static final int BOUND = 100_000;
volatile long[] array;
@Setup
public void initState() {
Random random = new Random(SEED);
this.array = new long[ARRAY_LENGTH];
for (int i = 0; i < this.array.length; i++) {
this.array[i] = random.nextInt(BOUND);
}
}
}
@Benchmark
public long[] defaultParallelSort(BenchmarkState state) {
Arrays.parallelSort(state.array);
return state.array;
}
@Benchmark
public long[] twoThreadsParallelSort(BenchmarkState state) {
System.setProperty(
"java.util.concurrent.ForkJoinPool.common.parallelism", "2");
Arrays.parallelSort(state.array);
return state.array;
}
@Benchmark
public long[] threeThreadsParallelSort(BenchmarkState state) {
System.setProperty(
"java.util.concurrent.ForkJoinPool.common.parallelism", "3");
Arrays.parallelSort(state.array);
return state.array;
}
@Benchmark
public long[] fourThreadsParallelSort(BenchmarkState state) {
System.setProperty(
"java.util.concurrent.ForkJoinPool.common.parallelism", "4");
Arrays.parallelSort(state.array);
return state.array;
}
@Benchmark
public long[] fiveThreadsParallelSort(BenchmarkState state) {
System.setProperty(
"java.util.concurrent.ForkJoinPool.common.parallelism", "5");
Arrays.parallelSort(state.array);
return state.array;
}
@Benchmark
public long[] tooLargePoolParallelSort(BenchmarkState state) {
System.setProperty(
"java.util.concurrent.ForkJoinPool.common.parallelism", "128");
Arrays.parallelSort(state.array);
return state.array;
}
@Benchmark
public long[] singleThreadParallelSort(BenchmarkState state) {
System.setProperty(
"java.util.concurrent.ForkJoinPool.common.parallelism", "1");
Arrays.parallelSort(state.array);
return state.array;
}
@Benchmark
public long[] serialSort(BenchmarkState state) {
Arrays.sort(state.array);
return state.array;
}
}
```Having executed this code, we got the following final results (in fact, several runs were made, the numbers were slightly different, but the overall picture remained unchanged):
So the winner of the rating was fourThreadsParallelSort. In this test, we set the pool size to the number of cores on my machine, and therefore one more than the default pool. Nevertheless, the fact that this micro-benchmark wins does not mean that you should determine the size of commonPool in your application equal to the number of cores, and not use one less worker, as the JDK developers suggest. We would suggest accepting their point of view and never change the size of commonPool for most applications, however if we want to squeeze the maximum out of the machine and are ready to prove by the more general macro benchmarks that the game is worth the candle, we can get a small gain in more complete CPU utilization setting commonPool equal to the number of cores. At the same time, do not forget that system threads, for example Garbage Collector,
defaultParallelSort - was in second place. Pool size - 3 threads. During the process, CPU utilization was observed at about 70%, in contrast to 90% in the previous case. Therefore, it turned out to be incorrect to argue that the main program stream from which we call parallel sorting will become a full-fledged worker raking fork join tasks.
fiveThreadsParallelSort - showed us how we begin to lose efficiency by setting the pool size to just one more than the number of cores. This test lost a little to the default, while CPU utilization was about 95%.
tooLargePoolParallelSort - showed that if we further increase the pool size (in this case, up to 128 threads), then we will continue to lose efficiency and utilize the processor even more densely (about 100%).
twoThreadsParallelSort - was in last place in the ranking, and demonstrated that if we simply leave one of the cores without work for no particular reason, the result will be very mediocre.
You may ask, what about serialSort and singleThreadParallelSort? But nothing. They simply cannot be compared with other options, because inside there is no merge sort at all, but a completely different algorithm - DualPivotQuickSort, and on different input data it can show results that are both inferior to the tested algorithm and superior to them. You can say more, on most random arrays that were considered, DualPivotQuickSort significantly outperformed Arrays.parallelSort, and it was just lucky to generate this time an array in which parallelSort showed the best results. Therefore, we decided to include this particular array in the benchmarks so that you would not think that parallelSort never makes any sense to use. Sometimes it has, but do not forget to check it and prove it with good tests.
And finally, let's try to answer the question: "In what cases can it be reasonable to resize commonPool?". We have already considered one case - if we want to utilize the CPU more densely, then sometimes it may make sense to set the size of commonPool equal to the number of cores, and not one less than the default value. Another case may be the situation when others are launched at the same time as our application, and we want to manually divide the processor cores between applications (although docker seems to be more appropriate for these purposes). And finally, it may turn out that the tasks that we really want to put in the Fork Join Pool are not clean enough. If these tasks allow themselves not only to calculate and read / write in RAM, but also to sleep, wait, or read / write to a blocking input / output source. In this case, it is not recommended to place such tasks in commonPool, because they will take up a precious thread from the pool, the thread will go into standby mode, and the kernel, which was supposed to be utilized by this thread, will be idle. Therefore, for such a little sleepy tasks it is better to create a separate, custom ForkJoinPool.
THE END
Questions and suggestions as always welcome here and at the open door . We are waiting, sir.