Model-Update-View pattern and dependent types
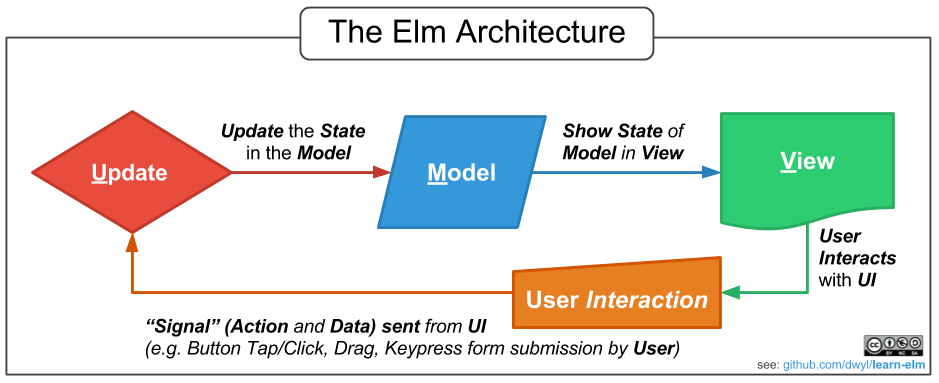
Model-Updater-View is a functional pattern that has been successfully used in the Elm language mainly for developing user interfaces. To use it, you need to create the Model type, which represents the full state of the program, the Message type, which describes the environmental events to which the program should respond, changing its state, the updater function, which from the old state and message creates a new state of the program and the view function, which calculates, according to the state of the program, the required environmental impacts that emit events of type Message. The pattern is very convenient, but it has a small drawback - it does not allow to describe what events make sense for specific program states.
A similar problem arises (and is solved) and when using the State OO pattern.
The Elm language is simple, but very strict - it checks that the updater function at least somehow processes all possible combinations of model-state and message-events. Therefore, you have to write an extra, albeit trivial, code that usually leaves the model unchanged. I want to demonstrate how this can be avoided in more complex languages - Idris, Scala, C ++ and Haskell.
All of the code here is available on GitHub for experimentation. Consider the most interesting places.
Idris
Idris is a language that supports dependent types. That is, in it, the compiler can monitor the typing, although the type of one variable may depend on the value of another. Types in Idris are similar to generalized algebraic types in Haskell. It is described by a list of type parameters and a set of constructors - functions that create objects of this type. Unlike Haskell, type parameters can be not only other types and type classes, but also values, including functions.
Let us describe on it the type of simple application using the Model-Updater-View pattern.
data Application : (model:Type) ->
(msg: model -> Type) ->
(vtype : Type -> Type) ->
Type
where
MUV : model ->
(updater : (m:model) -> (msg m) -> model) ->
(view : (m:model) -> vtype (msg m)) ->
Application model msg vtype
The parameterized Application data type is described here. Its parameters are the model type , the msg function, which converts the value of the model type to the type of event that can occur in the given state of the program, and the view type, which will be parameterized by the type of event - it can be interpreted as a function from the parameter type to a simple type.
Lyrical digression about High Kind Types
This is the only place where a type parameter is used, which itself has type parameters. This feature is not provided in all languages - it is not available, including in Elm. But in this example, the view is made into the application type parameters more “for beauty” - to show that it is a component of the pattern. You can do it as in Elm - use a fixed parameterized type as View (in Elm it is Html msg).
I want to note that HKTs are not necessary for using dependent types - these are different edges of a lambda cube
I want to note that HKTs are not necessary for using dependent types - these are different edges of a lambda cube
The msg function is unusual - it returns not a value, but a type. At run time, nothing is known about the types of values - the compiler erases all unnecessary information. That is, such a function can only be called at the compilation stage.
MUV is a constructor. It takes parameters: model - the initial state of the program, updater - the function of updating the state at an external event, and view - the function of creating an external view. Note that the type of updater and view functions depends on the model value (using the msg function from the type parameters).
Now let's see how to run this application
muvRun : (Application modelType msgType IO) -> IO a
muvRun (MUV model updater view) =
do
msg <- view model
muvRun (MUV (updater model msg) updater view)
As an external view, we chose the I / O operation (in Idris, as in Haskell, the I / O operations are first class values, so that they are executed, additional steps must be taken, usually returning such an operation from the main function).
Briefly about IO
When executing an operation of type (IO a), there is some impact on the outside world, possibly empty, and a value of type a is returned to the program, but the functions of the standard library are designed so that it can only be processed by generating a new value of type IO b. Thus, pure functions are separated from functions with side effects. This is unusual for many programmers, but it helps to write more reliable code.
Since the muvRun function generates input / output, it should return IO, but since it will never be completed, the type of operation can be any - IO a.
Now we describe the types of entities with which we are going to work
data Model = Logouted | Logined String
data MsgOuted = Login String
data MsgIned = Logout | Greet
total
msgType : Model -> Type
msgType Logouted = MsgOuted
msgType (Logined _) = MsgIned
The model type is described here, reflecting the presence of two interface states - the user is not logged in, and the user with the name of type String is logged in.
Next, we describe two different types of messages that are relevant for different versions of the model - if we are logged in, we can only log in under a certain name, and if we are logged in, we can either log out or say hello. Idris is a strongly typed language that prevents the possibility of confusing different types.
And finally, a function that sets the model value to match the message type.
The function is declared total - that is, it should not fall or freeze, the compiler will try to trace this. msgType is called at the compilation stage, which means its totality means that the compilation does not hang due to our error, although it cannot guarantee that the execution of this function will lead to the exhaustion of system resources.
It is also guaranteed that she will not execute “rm -rf /”, because there is no IO in her signature.
We describe updater:
total
updater : (m:Model) -> (msgType m) -> Model
updater Logouted (Login name) = Logined name
updater (Logined name) Logout = Logouted
updater (Logined name) Greet = Logined name
I think the logic of this function is clear. I want to once again note the totality - it means that the Idris compiler will verify that we have considered all the alternatives allowed by the type system. Elm also performs such a check, but he cannot know that we can’t log out if not logged in yet, and will require explicit processing of the condition
updater Logouted Logout = ???Idris will find type mismatch in an extra check.
Now let's start the view - as usual in the UI, this will be the most difficult part of the code.
total
loginPage : IO MsgOuted
loginPage = do
putStr "Login: "
map Login getLine
total
genMsg : String -> MsgIned
genMsg "" = Logout
genMsg _ = Greet
total
workPage : String -> IO MsgIned
workPage name = do
putStr ("Hello, " ++ name ++ "\n")
putStr "Input empty string for logout or nonempty for greeting\n"
map genMsg getLine
total
view : (m: Model) -> IO (msgType m)
view Logouted = loginPage
view (Logined name) = workPage name
view should create an I / O operation that returns messages whose type again depends on the model value. We have two options: loginPage, which displays the “Login:” message, reads the line from the keyboard and wraps it in the Login message and workPage with the username parameter, which displays a greeting and returns different messages (but of the same type - MsgIned) depending on the user will enter an empty or non-empty string. view returns one of these operations depending on the model value, and the compiler checks their type, despite the fact that it is different.
Now we can create and run our application
app : Application Model Main.msgType IO
app = MUV Logouted updater view
main : IO ()
main = muvRun appA subtle point should be noted here - the muvRun function returns IO a , where a was not specified, and the main value is of type IO () , where () is the name of a type, usually called Unit , which has a single value, also written as an empty tuple () . But the compiler can do this easily. substituting a () instead.
Scala and path-dependent types
Scala does not have full support for dependent types, but there are types dependent on the instance of the object through which it is referenced (path dependent types). In the theory of dependent types, they can be described as a variant of the sigma type. Path-dependent types allow you to prohibit folding vectors from different vector spaces, or to describe who you can kiss with whom . But we will apply them for simpler tasks.
sealed abstract class MsgLogouted
case class Login(name: String) extends MsgLogouted
sealed abstract class MsgLogined
case class Logout() extends MsgLogined
case class Greet() extends MsgLogined
abstract class View[Msg] {
def run() : Msg
}
sealed abstract class Model {
type Message
def view() : View[Message]
}
case class Logouted() extends Model {
type Message = MsgLogouted
override def view() : View[Message]
....
}
case class Logined(name: String) extends Model {
type Message = MsgLogined
override def view() : View[Message]
....
}
Algebraic types in Scala are modeled through inheritance. The type corresponds to a certain sealed abstract class , and each constructor inherits a case class from it . We will try to use them precisely as algebraic types, describing all variables as belonging to the parent sealed abstract class .
The classes MsgLogined and MsgLogouted within our program do not have a common ancestor. The view function had to be spread over different classes of the model in order to have access to a specific type of message. This has its advantages that proponents of OO will appreciate - the code turns out to be grouped in accordance with business logic, everything connected with one use case turns out to be close by. But I would rather like to separate view into a separate function, the development of which could be transferred to another person.
Now we implement updater
object Updater {
def update(model: Model)(msg: model.Message) : Model = {
model match {
case Logouted() => msg match {
case Login(name) => Logined(name)
}
case Logined(name) => msg match {
case Logout() => Logouted()
case Greet() => model
}
}
}
}Here, using path-dependent types, we describe the type of the second argument from the value of the first. In order for Scala to perceive such dependencies, the functions have to be described in a curried form, that is, as a function of the first argument, which returns a function of the second argument. Unfortunately, Scala does not perform many type checks at this point, for which the compiler has enough information.
Now we give a complete implementation of the model and view
case class Logouted() extends Model {
type Message = MsgLogouted
override def view() : View[Message] = new View[Message] {
override def run() = {
println("Enter name ")
val name = scala.io.StdIn.readLine()
Login(name)
}
}
}
case class Logined(name: String) extends Model {
type Message = MsgLogined
override def view() : View[Message] = new View[Message] {
override def run() = {
println(s"Hello, $name")
println("Empty string for logout, nonempy for greeting.")
scala.io.StdIn.readLine() match {
case "" => Logout()
case _ => Greet()
}
}
}
}
abstract class View[Msg] {
def run() : Msg
}
object Viewer {
def view(model: Model): View[model.Message] = {
model.view()
}
}
The type returned by the view function depends on the instance of its argument. But for implementation, she turns to the model.
The application created like this starts like this
object Main {
import scala.annotation.tailrec
@tailrec def process(m: Model) {
val msg = Viewer.view(m).run()
process(Updater.update(m)(msg))
}
def main(args: Array[String]) = {
process(Logouted())
}
}Thus, the code of the runtime system does not know anything about the internal structure of models and types of messages, but the compiler can verify that the message matches the current model.
Here, we did not need all the capabilities provided by path-dependent types. Interesting properties will appear if we work simultaneously with several instances of Model-Updater-View systems, for example, when simulating a multi-agent world (view would then be the agent’s effect on the world and receiving feedback). In this case, the compiler verified that the message is being processed by the agent for which it is intended, despite the fact that all agents are of the same type.
C ++
C ++ is still sensitive to the order of definitions, even if they are all made in one file. This creates some inconvenience. I will present the code in a convenient sequence for demonstrating ideas. An ordered version for compilation can be viewed on GitHub .
Algebraic types can be implemented in the same way as in Scala - an abstract class corresponds to a type, and concrete descendants correspond to constructors (let's call them “constructor classes", so as not to be confused with ordinary C ++ constructors) of an algebraic type.
C ++ has support for path-dependent types, but the compiler cannot use this type abstractly, without knowing the actual type with which it is associated. Therefore, it is not possible to implement Model-Updater-View with their help.
But C ++ has a powerful template system. The dependence of the type on the model value can be hidden in the template parameter of the specialized version of the executive system.
struct Processor {
virtual const Processor *next() const = 0;
};
template struct ProcessorImpl : public Processor {
const CurModel * model;
ProcessorImpl(const CurModel* m) : model(m) { };
const Processor *next() const {
const View * view = model->view();
const typename CurModel::Message * msg = view->run();
delete view;
const Model * newModel = msg->process(model);
delete msg;
return newModel->processor();
}
};
We describe an abstract execution system, with the only method - to accomplish all that is required and return a new execution system suitable for the next iteration. The concreted version has a template parameter and will be specialized for each model constructor class. It is important here that all properties of the CurModel type will be checked during template specialization with a specific type parameter, and at the time of compilation of the template itself, it is not necessary to describe them (although it is possible using concepts or other ways to implement type classes) Scala also has a fairly powerful system of parameterized types, but it performs parameter-type property checks at the time of compilation of the parameterized type. The implementation of such a pattern there is difficult, but possible, thanks to the support of type classes.
We describe the model.
struct Model {
virtual ~Model() {};
virtual const Processor *processor() const = 0;
};
struct Logined : public Model {
struct Message {
const virtual Model * process(const Logined * m) const = 0;
virtual ~Message() {};
};
struct Logout : public Message {
const Model * process(const Logined * m) const;
};
struct Greet : public Message {
const Model * process(const Logined * m) const;
};
const std::string name;
Logined(std::string lname) : name(lname) { };
struct LoginedView : public View {
...
};
const View * view() const {
return new LoginedView(name);
};
const Processor *processor() const {
return new ProcessorImpl(this);
};
};
struct Logouted : public Model {
struct Message {
const virtual Model * process(const Logouted * m) const = 0;
virtual ~Message() {};
};
struct Login : public Message {
const std::string name;
Login(std::string lname) : name(lname) { };
const Model * process(const Logouted * m) const;
};
struct LogoutedView : public View {
...
};
const View * view() const {
return new LogoutedView();
};
const Processor *processor() const {
return new ProcessorImpl(this);
};
};
The "designer classes" of the "all carry their own" model - that is, they contain the message and view classes specialized for them, and they also know how to create an executive system for themselves. Native types of View have a common ancestor for all models, which may be useful when developing more complex execution systems. It is important that message types are completely isolated and do not have a common ancestor.
The updater implementation is separate from the model because it requires that the type of model be fully described.
const Model * Logouted::Login::process(const Logouted * m) const {
delete m;
return new Logined(name);
};
const Model * Logined::Logout::process(const Logined * m) const {
delete m;
return new Logouted();
};
const Model * Logined::Greet::process(const Logined * m) const {
return m;
};
Now let's put together everything related to view, including the internal entities of models
template struct View {
virtual const Message * run() const = 0;
virtual ~View() {};
};
struct Logined : public Model {
struct LoginedView : public View {
const std::string name;
LoginedView(std::string lname) : name(lname) {};
virtual const Message * run() const {
char buf[16];
printf("Hello %s", name.c_str());
fgets(buf, 15, stdin);
return (*buf == 0 || *buf == '\n' || *buf == '\r')
? static_cast(new Logout())
: static_cast(new Greet);
};
};
const View * view() const {
return new LoginedView(name);
};
};
struct Logouted : public Model {
struct LogoutedView : public View {
virtual const Message * run() const {
char buf[16];
printf("Login: ");
fgets(buf, 15, stdin);
return new Login(buf);
};
};
const View * view() const {
return new LogoutedView();
};
};
And finally, write main
int main(int argc, char ** argv) {
const Processor * p = new ProcessorImpl(new Logouted());
while(true) {
const Processor * pnew = p->next();
delete p;
p = pnew;
}
return 0;
}
And again Scala, already with type classes
In structure, this implementation almost completely repeats the C ++ version.
Similar piece of code
abstract class View[Message] {
def run(): Message
}
abstract class Processor {
def next(): Processor;
}
sealed abstract class Model {
def processor(): Processor
}
sealed abstract class LoginedMessage
case class Logout() extends LoginedMessage
case class Greet() extends LoginedMessage
case class Logined(val name: String) extends Model {
override def processor(): Processor = new ProcessorImpl[Logined, LoginedMessage](this)
}
sealed abstract class LogoutedMessage
case class Login(name: String) extends LogoutedMessage
case class Logouted() extends Model {
override def processor(): Processor = new ProcessorImpl[Logouted, LogoutedMessage](this)
}
object Main {
import scala.annotation.tailrec
@tailrec def process(p: Processor) {
process(p.next())
}
def main(args: Array[String]) = {
process(new ProcessorImpl[Logouted, LogoutedMessage](Logouted()))
}
}
But in the implementation of the runtime, subtleties arise.
class ProcessorImpl[M <: Model, Message](model: M)(
implicit updater: (M, Message) => Model,
view: M => View[Message]
) extends Processor {
def next(): Processor = {
val v = view(model)
val msg = v.run()
val newModel = updater(model,msg)
newModel.processor()
}
}Here we see new mysterious parameters (implicit updater: (M, Message) => Model, view: M => View [Message]) . The implicit keyword means that when the function is called (more precisely, the class constructor), the compiler will look in the context for objects of suitable types marked as implicit and pass them as appropriate parameters. This is a rather complicated concept, one of its applications is the implementation of type classes. Here they promise the compiler that for specific implementations of the model and message we will provide all the necessary functions. Now keep this promise.
object updaters {
implicit def logoutedUpdater(model: Logouted, msg: LogoutedMessage): Model = {
(model, msg) match {
case (Logouted(), Login(name)) => Logined(name)
}
}
implicit def viewLogouted(model: Logouted) = new View[LogoutedMessage] {
override def run() : LogoutedMessage = {
println("Enter name ")
val name = scala.io.StdIn.readLine()
Login(name)
}
}
implicit def loginedUpdater(model: Logined, msg: LoginedMessage): Model = {
(model, msg) match {
case (Logined(name), Logout()) => Logouted()
case (Logined(name), Greet()) => model
}
}
implicit def viewLogined(model: Logined) = new View[LoginedMessage] {
val name = model.name
override def run() : LoginedMessage = {
println(s"Hello, $name")
println("Empty string for logout, nonempy for greeting.")
scala.io.StdIn.readLine() match {
case "" => Logout()
case _ => Greet()
}
}
}
}
import updaters._Haskell
There are no dependent types in mainstream Haskell. It also lacks inheritance, which we essentially used when implementing the pattern in Scala and C ++. But single-level inheritance (with elements of dependent types) can be modeled using more or less standard language extensions -TypeFamilies and ExistentialQuantification. For the general interface of child OOP classes, a type class is created in which there is a dependent "family" type, the child classes themselves are represented as a separate type, and then they are wrapped in an "existential" type with a single constructor.
data Model = forall m. (Updatable m, Viewable m) => Model m
class Updatable m where
data Message m :: *
update :: m -> (Message m) -> Model
class (Updatable m) => Viewable m where
view :: m -> (View (Message m))
data Logouted = Logouted
data Logined = Logined String
I tried to spread updater and view as far as possible, so I created two different classes of types, but so far it has turned out badly.
Implementing updater is simple
instance Updatable Logouted where
data Message Logouted = Login String
update Logouted (Login name) = Model (Logined name)
instance Updatable Logined where
data Message Logined = Logout | Greeting
update m Logout = Model Logouted
update m Greeting = Model m
I had to fix IO as a View. Attempts to make it more abstract greatly complicated and increased the coherence of the code - the Model type must know which View we are going to use.
import System.IO
type View a = IO a
instance Viewable Logouted where
view Logouted = do
putStr "Login: "
hFlush stdout
fmap Login getLine
instance Viewable Logined where
view (Logined name) = do
putStr $ "Hello " ++ name ++ "!\n"
hFlush stdout
l <- getLine
pure $ if l == ""
then
Logout
else
Greeting
Well, the runtime differs little from the same in Idris
runMUV :: Model -> IO a
runMUV (Model m) = do
msg <- view m
runMUV $ update m msg
main :: IO ()
main = runMUV (Model Logouted)