10 lessons of the Quora recommendation system
- Tutorial
Hello, Habr! As the director of analytics for Retail Rocket, I periodically attend various profile events, and in September 2016 I was lucky enough to attend the RecSys conference on recommender systems in Boston. There were a lot of interesting reports, but we decided to translate one of them Lessons Learned from Building Real-Life Recommender Systems . It is very interesting from the perspective of how Machine Learning to apply in production systems. A lot of articles have been written about ML itself: algorithms, application practice, Kaggle contests. But the derivation of algorithms in production is a separate and big job. Let me tell you a secret, the development of the algorithm takes only 10% -20% of the time, and putting it into battle is all 80-90%. There are many restrictions: what data where to process (online or offline), model training time, model application time on servers online, etc. A crucial aspect is the choice of offline / online metrics and their correlation. At the same conference, we made a similar report by Hypothesis Testing: How to Eliminate Ideas as Soon as Possible , but chose the above-mentioned study report from Quora, because it is less specific and can be used outside of recommendation systems.
Quora Help:
Quora is a social Q & A knowledge sharing service founded in June 2009 by Adam d'Angelo and Charlie Chiver (one of the creators of the Facebook social network). Today, more than 450 million people visit the service every month.
Quora generates a personalized Q&A feed in accordance with the interests of the user. Questions and answers can be put likes and dislikes, users can “follow” other users, thus creating a kind of social network around various knowledge.
Xavier Amatriain from Quora shares 10 important lessons about recommender systems that she has developed over many years of work in the recommender system industry.
Introduction
Quora's main mission is to share and develop knowledge worldwide. Therefore, it is important for us to understand what knowledge really is. We use the mechanism of questions and answers to increase the volume of knowledge, and this distinguishes us from the Wikipedia encyclopedic approach, therefore, in our service there are millions of answers and thousands of topics.
If you go down a notch, there are three main things that we care about: relevance, demand, and quality.
- Relevance. This is the main task of any recommendation system, it is very important that each recommendation corresponds to the interests of a particular user.
- Demand. How many people want to know the answer to this question? If only a few people are interested in a question, then perhaps you should not spend effort on it.
- Quality. But if we are talking about a large number of users who are interested in a particular question, then you should definitely take care of the quality of answers in this question.
Most of the information on Quora is textual, but not working with texts, but what actions users can perform on the site is of great interest.
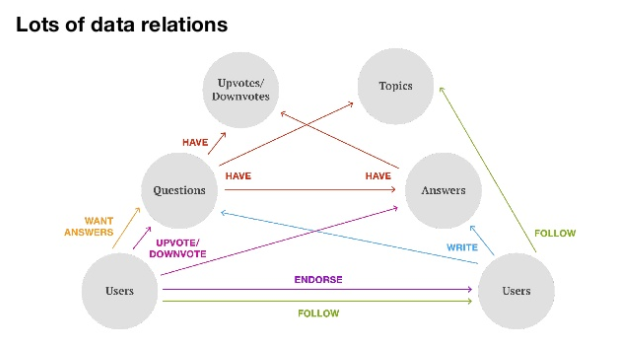
This diagram shows the different types of relationships that exist between different types of content, users, their reactions to content, etc.
Since Quora is a kind of social network, users can not only answer questions, but also “follow” each other, as well as like (upvote) and dislike (downvote) questions and answers. Related topics are used to classify questions and answers.
All these interactions generate a huge amount of data that affect personal recommendations.
Among the recommendations that we use on the site, we can distinguish the main types:
- Ranking ribbon items on the home page
- Daily Email Newsletter
- Response Ranking
- Recommendations to topics of potential interest to the user
- Recommendations from users whose answers may be of interest
- Trends
- Automatically detect question topics
- Questions Viewed by Question
Different types of recommendations are formed by completely different algorithms based on different types of data.
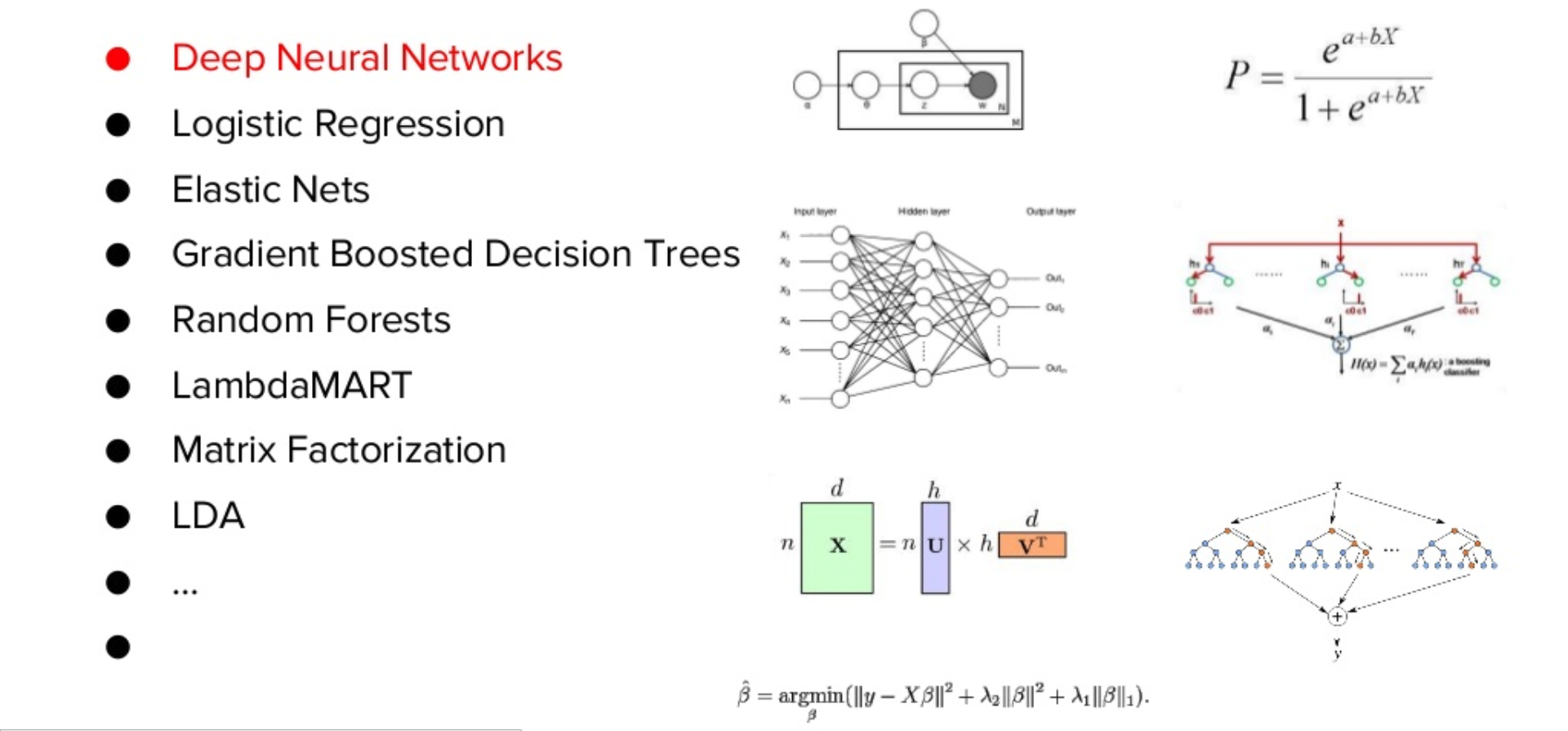
Since we solve problems that are very different from each other, we have to use many different machine learning algorithms:
- Deep Neural Networks. Since we have a lot of text data, with the help of deep neural networks we can get various features from this text
- Logistic regression
- Elastic nets
- Gradient Boosted Decision Trees
- Random forests
- Lambdamart
- Matrix Factorization
- Lda
- other
We are always looking for the best methods to solve each specific problem, and we do this not just to follow the fashion, but to get maximum efficiency.
Lesson 1. Implicit user feedback is almost always better than explicit
Even while working at Netflix, my favorite post was that five-point ratings are useless, which is confirmed by Youtube. But why is this happening?
The main reason is that implicit data is much more “dense” and allows you to learn much more about the users themselves. The problem of explicit feedback is that we get it only from those who agreed to give it to us. Thus, the explicit response speaks more about demonstrative public behavior than about the real reaction of the user. Therefore, an implicit feedback is more suitable for the objective function. It also correlates better with AB test results.
But not in all cases the implicit response is better. This can be well illustrated with an example where a funny picture or a loud headline attracts attention, and the user inadvertently moves the cursor or even clicks on a similar block. Activity indicators in this case will be quite high, you can get a lot of actions, but such tactics are unlikely to correlate with long-term goals, so it is important to be able to combine implicit and explicit responses.
In Quora, we use both implicit responses, such as page visits, clicks on questions, answers and user profiles, as well as various explicit signals: likes, dislikes, sharing, etc. In order to prepare quality data for training a model, you need to learn how to combine explicit and implicit responses.
Lesson 2. Be mindful of the data your system learns from.
The second lesson relates to how you prepare your data, how it enters your recommendation system and how the algorithm of the recommendation system will learn from it.
Even for the trivial task of binary classification, it is not always obvious which response is considered positive and which is negative.
In the case of Quora, you can find a lot of examples where it is very difficult to understand what is positive and what is negative. For example, what to do with funny but meaningless answers that have many likes? Or what about the short but informative answer of a famous expert? Should it be considered positive? Or how to evaluate a very long informative answer that users don’t read and don’t like? There can be many such examples.
Speaking of Netflix, how do you rate a movie that a user watched for five minutes and stopped? At first glance, this suggests that the film is not very interesting, but what if the user simply paused it to watch tomorrow?
Thus, there are many hidden behavioral factors that you need to learn to understand, evaluate and take into account in teaching the recommendation system.
Imagine that you have a more difficult task - ranking, where you have to put different labels. In this case, a lot of time is spent on preparing data for training, but even more time can be spent on separating positive and negative examples. This can be a rather complicated and time-consuming process, but it is critical for solving the problem.
Lesson 3. Your system can only learn what you teach it.
The third lesson is about model training. In addition to the data for training the model, two more things are important: your target function (for example, the probability of the user reading the answer) and the metric (for example, precision or recall). They form what your model will learn from.
For example, we need to optimize the likelihood of watching a movie in a movie theater and its high rating by the user, using the history of previous views and ratings, then it is worth trying the NDCG metric as the final one, considering films with a rating of 4 or higher as a positive result. This is a fairly long way, but it brings really good results.
Once you have identified these three points, you can begin work, but keep in mind that there are many details and pitfalls. If you forget to define at least one of these aspects, there is a risk that you will set the task incorrectly and will optimize something that is not related to your real goal.
What we do at Quora:
- Data for model training - implicit and explicit responses that are collected on the site
- The objective function is the value of showing the question / answer to the user and the weighted sum of all user actions that they (questions / answers) will receive. It should correlate with the long-term goals of the company. Accordingly, you need to solve the regression problem, i.e. correlate user actions with the objective function
- Metrics. Since we are talking about working with the Q & A recommendations ribbon, and it is just a list of elements, you need to select the appropriate ranking metric, for example NDCG, which will make sense for solving this particular problem.

Lesson 4. Explanations may be as important as the recommendations themselves
The fourth lesson is on the importance of explaining certain recommendations and their impact on perception. The explanations provide an opportunity to understand why what you recommend will be interesting to you. For example, Netflix recommends movies based on previous views. In the case of Quora, users are recommended topics, similar questions, people who can be “followed”, and explanations help to understand why this will be interesting.
Lesson 5. If you need to choose only one algorithm, bet on matrix factorization
If you can use only one algorithm, then I would put on matrix factorization. I often get questions about what to do if a startup has only one engineer and needs to build a recommendation system. My answer is matrix factorization. The main reason is that despite the fact that it can be combined with other algorithms, it gives a good result on its own.

Factorization is, in a sense, teaching without a teacher, because it simply reduces dimensionality, as does the PCA method. But it can also be used for teaching tasks with a teacher. For example, you can reduce the dimension and then solve the regression problem with respect to your tagged data.
Matrix factorization is suitable for different types of data, and for different types of data you can use their various implementations. For implicit signals, you can use ALS or BPR, you can go to tensor factorization or even factorization machines.
We at Quora wrote our own library, called QMF . This is a small library that implements the basic methods of matrix factorization. It is written in C ++ and can be easily used in production.
Lesson 6. Everything is an ensemble
The most interesting lies in the ensemble of algorithms. Suppose you started by factorizing matrices and hired a second engineer. He becomes bored, and this is a great moment to try a different teaching method, and then combine them into an ensemble.
At the Netflix Prize open competition, the winning team used the ensemble as the last step of the model. The Bellcor team used GBDT (Gradient boosted decision trees) to create an ensemble, and when they teamed up with the BigChaos team, they used neural networks as the last layer of the ensemble, and thus came to some kind of deep learning.
If you have different models that make different transformations on different layers, you get unlimited possibilities of working with a neural network. It almost looks like a makeshift deep neural network. However, we are not talking about deep learning in the classical sense.
Thanks to ensembles, various algorithms can be combined using different models, such as logical regression, or non-linear Random Forest methods, or even neural networks.
Another interesting thing is that you turn any model in the ensemble into a feature. Thus, we blur the line between features and models. It is interesting that you can divide their production into different engineers, and then combine them - this leads to good scalability, as well as the possibility of use in other models.
Lesson 7. To build recommender systems, it is also important to be able to properly build features
To get optimal results, you need to understand the data (domain knowledge), namely, what is behind them. If you don’t understand your mission, but simply take some matrix of features that you are interested in, some data, twist them, optimize the objective function for the matrix, then this can optimize not what you really need.
At Quora, we need to rank answers and show users the best ones. But how to choose the "best" to create the right ranking system? Assessing various aspects, we deduced that a good answer should be truthful, informative (i.e. give an explanation), useful for a long time, well formatted, etc.
It's pretty hard to get a neural network to understand what a good answer is. To do this, you must learn to interpret the data and build features that will be associated with those aspects that are important in order to optimize the model specifically for your tasks.
In our case, you need to have features that are associated with the quality of the text, its formatting, user response, etc. Some of them are easy to make, others are quite difficult, for some you may need a separate ML model.
I would give expressed the properties of a good feature as useful, "reusable", transformable, interpretable and reliable.

Lesson 8. Why is it important to be able to answer questions
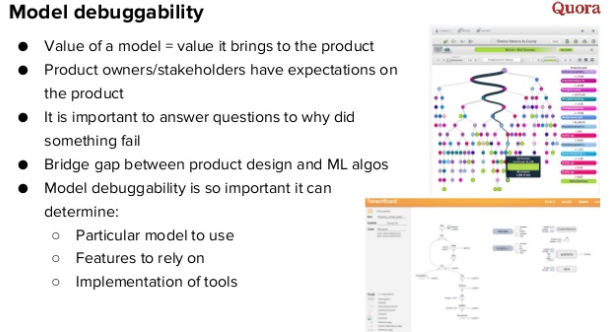
The value of the model lies not in its accuracy and correctness, but in what it brings to the product and how much it satisfies the expectations of product managers. If your algorithm is at variance with their understanding, you will need to answer questions why the recommendations here are just that. It is very important to be able to debug the recommendation model, and even better, a visual debugging system.
This allows you to check the model much faster than if it were a completely black box - in this case, it is almost impossible to find the cause of bad recommendations.
For example, from any question / answer from the Quora feed, we can get all the features, analyze them and understand why the model recommended this or that question or answer to each user.
Lesson 9. Data and model is good, but even better is the right approach to evaluating effectiveness
When we received the data and the model, the next question arises - the correct methodology for evaluating effectiveness.
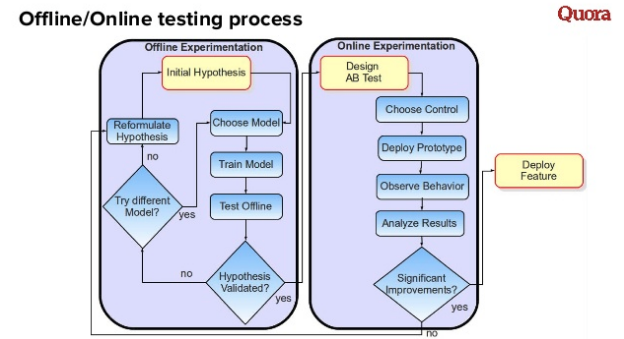
This is a diagram that explains some ideal innovation process when implementing algorithms in recommendation systems. The basic idea is that there are two processes.
The first is offline experiments, that is, the process of testing and training the model. If the model works better according to the chosen metric, we consider it good and can start the second process - online AB testing. Is the result of the AB test negative? The first process starts on a new one.
Thus, an iterative process arises that will make your work faster and better.
When evaluating test results, decisions should be based on data. This is often easier said than done, it should be part of your company’s culture.
You must select a common master metric, such as user retention or other long-term metrics.
The main problem is that long-term metrics are difficult to measure, so sometimes you need to use shorter-term metrics. The main thing is that they correlate with your main metric!
In offline testing, standard metrics are typically used to measure how well your model works. But it’s crucial to find a way for these metrics to correlate with online results.
Lesson 10. No need to use a distributed system for a recommendation system
The last tip will be quite controversial - you do not need to use a distributed system to build a recommendation system. Many follow a simple path, but based on my experience working with data in various companies, most tasks can be freely solved on one machine.

Everything can be counted on one machine instead of a cluster, if certain requirements are met:
- data sampling
- offline computing
- efficient parallel code
If you do not care about costs, delays, speed, debugging capabilities, etc., then you can continue to do this on a distributed cluster. You can simply ask 200 servers, deploy your spark cluster on them and build a recommendation system. Quora, as a startup, always thinks about reducing costs, because we have to pay for everything ourselves. We also constantly think about how complex things we create, and how easy it will be to debug.
If we talk about the matrix factorization algorithm, the first thing that is important to understand is that absolutely all factors are not necessary - very often you can get good accuracy with the right sampling, the result will be as if we were working with the full amount of data. Secondly, many things can be done offline. For example, you can calculate user factors online and product factors offline.
The full presentation can be viewed here .
Retail rocket
If you want to apply these lessons, then you are welcome to us. We are looking for an engineer in our analytic team Retail Rocket . We are developing recommendation algorithms on the Spark / Hadoop computing cluster (30+ servers, 2 Petabytes of data). The results of our team can be seen on hundreds of e-commerce sites in Russia and abroad. Our technological stack: Hadoop, Spark, Mongodb, Redis, Kafka. The main programming language is Scala. We already have hypothesis testing processes (new algorithms) both offline and online (AB tests), and we are constantly looking for ways to improve our recommendations. To this end, we study the scientific articles of leading researchers and test them in practice. Link to vacancy (ANALYTICS ENGINEER)