V8 under the hood
The lead developer of Yandex.Money Andrei Melikhov (also the editor / translator of the devSchacht community), using the V8 engine as an example, talks about how and through what stages the program goes through before it turns into machine code, and why you really need a new compiler.

The material was prepared based on the author's report at the HolyJS 2017 conference, which was held in St. Petersburg on June 2-3. Presentation in pdf can be found at this link .
The movie "The Last Dragon Slayer" was released a few months ago. There, if the protagonist kills the dragon, then magic disappears in the world. I want to be an antagonist today, I want to kill a dragon, because in the world of JavaScript there is no place for magic. Everything that works works explicitly. We need to figure out how it works in order to understand how it works.
I want to share my passion with you. At some point in time, I realized that I didn’t know how it worked under the hood of the V8. I started reading literature, watching reports, which are mainly in English, accumulated knowledge, systematized it and I want to bring it to you.
I hope everyone knows the difference, but I repeat. Compiled languages: in them, the source code is converted by the compiler into machine code and written to a file. They use compilation before execution. What is the advantage? It does not need to be recompiled, it is as automated as possible for the system under which it is compiled. What is the disadvantage? If your operating system is changing, and if you do not have the source, you lose the program.
Interpreted languages - when the source code is executed by the interpreter program. The benefits are that cross-platform is easy to achieve. We deliver our source code as is, and if there is an interpreter in this system, then the code will work. JavaScript is, of course, interpreted.
Immerse yourself in history. Chrome launches in 2008. Google introduced the new V8 engine that year. In 2009, Node.js was introduced on the same engine, which consisted of V8 and the libUV library, which provides io, i.e. access to files, network some things, etc. In general, two very important things for us are built on the V8 engine. Let's see what it consists of.
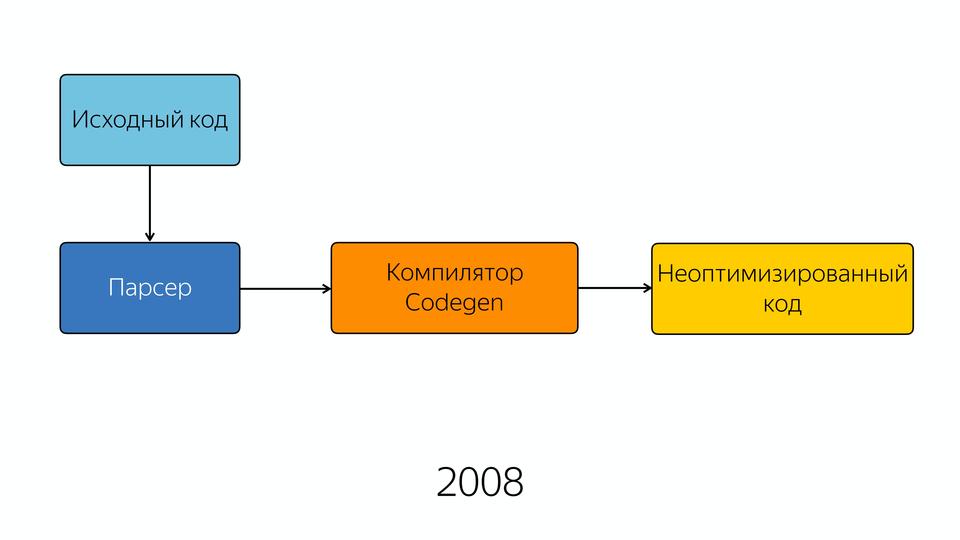
In 2008, the engine was pretty simple inside. Well, relatively simple - its layout was simple. The source code fell into the parser, from the parser into the compiler, and at the output we got semi-optimized code. Semi-optimized, because there wasn’t any good optimization then. Perhaps in those years you had to write better JavaScript, because you could not hope that the optimizer would optimize it inside.
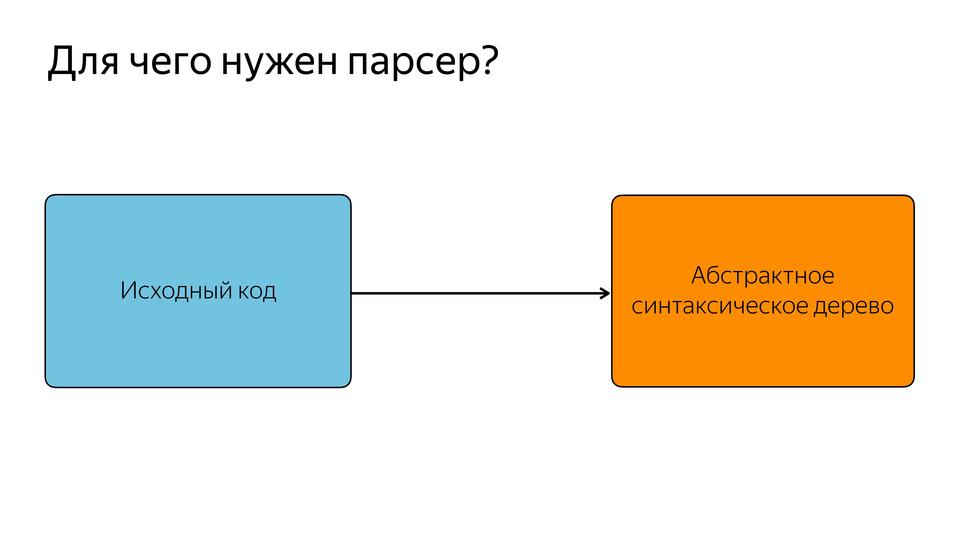
The parser is needed in order to turn the source code into an abstract syntax tree or AST. AST is a tree in which all vertices are operators, and all leaves are operands.
Let's look at an example of a mathematical expression. We have such a tree, all vertices are operators, branches are operands. What is good about it is that it is very easy to generate machine code from it later. Those who worked with Assembler know that most often the instruction consists of what to do and what to do.
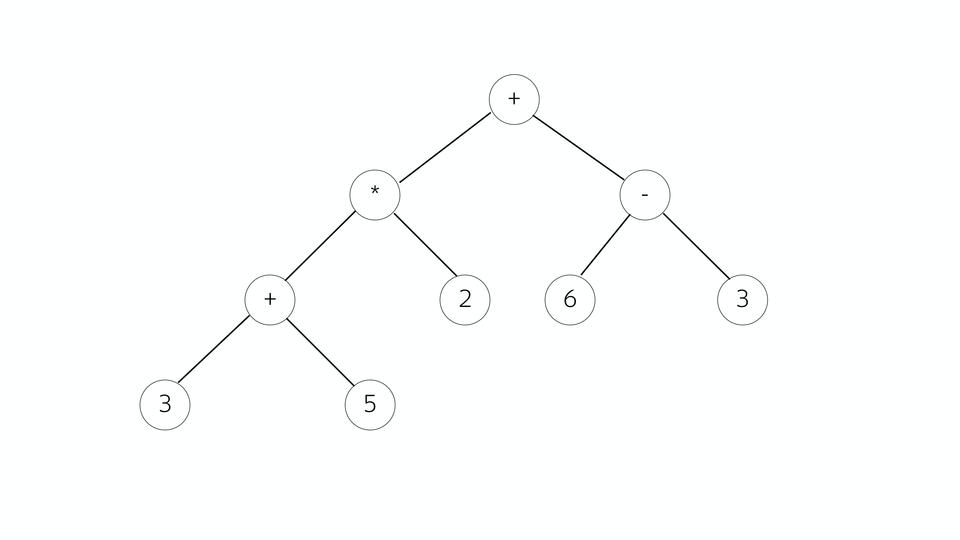
And here we can see whether we are at the current point an operator or operand. If it is an operator, we look at its operands and assemble the command.
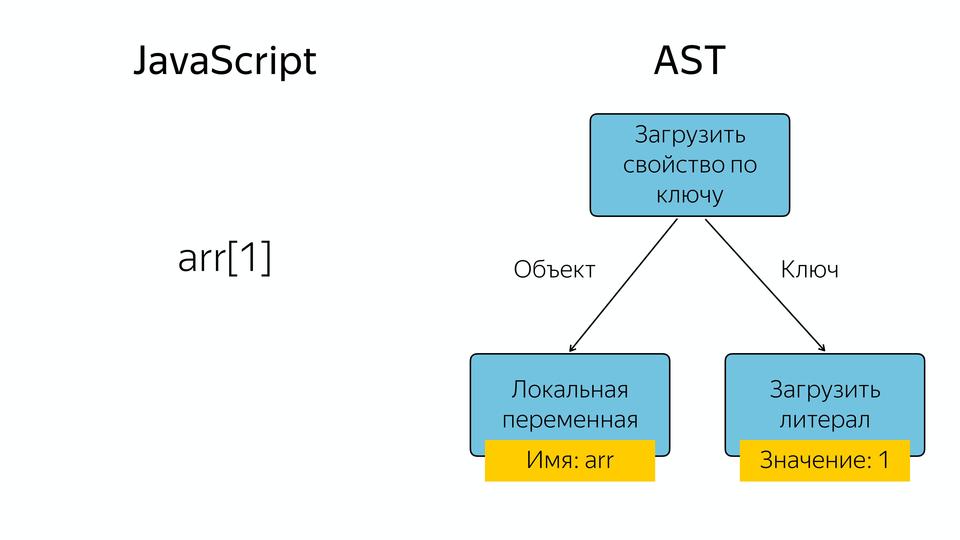
What happens in JavaScript if we have, for example, an array, and we request an element from it at index 1? An abstract syntax tree appears in which the operator "load a property by key", and the operands are the object and key by which we load this property.
As I said, our language is interpreted, but in its scheme we see a compiler. Why is he? There are actually two types of compilers. There are compilers (ahead-of-time) that compile before execution, and JIT compilers that compile at runtime. And due to JIT compilation, good acceleration is obtained. What is it for? Let's compare.

There is one and the same code. One in Pascal, the other in JavaScript. Pascal is a wonderful language. I believe that you need to learn to program with it, but not with JavaScript. If you have someone who wants to learn how to program, then show him Pascal or C.
What is the difference? Pascal can be compiled and interpreted, and JavaScript requires interpretation. The most important difference is static typing.

Because when we write in Pascal, we specify the variables that are needed, and then we write their types. Then it’s easy for the compiler to build good optimized code. How do we access variables in memory? We have an address, and we have a shift. For example, Integer 32, then we make a shift of 32 at this address into memory and get the data.
In JavaScript, no, our types always change at runtime, and the compiler, when this code executes, the first time it executes it as it is, but collects information about the types. And the second time that he performs the same function, he is already based on the data that he received the last time, assuming what types were there, can do some kind of optimization. If everything is clear with variables, they are determined by value, then what about objects?
After all, we have JavaScript, it has a prototype model, and we do not have classes for objects. Actually there is, but they are not visible. These are the so-called Hidden Classes. They are visible only to the compiler.
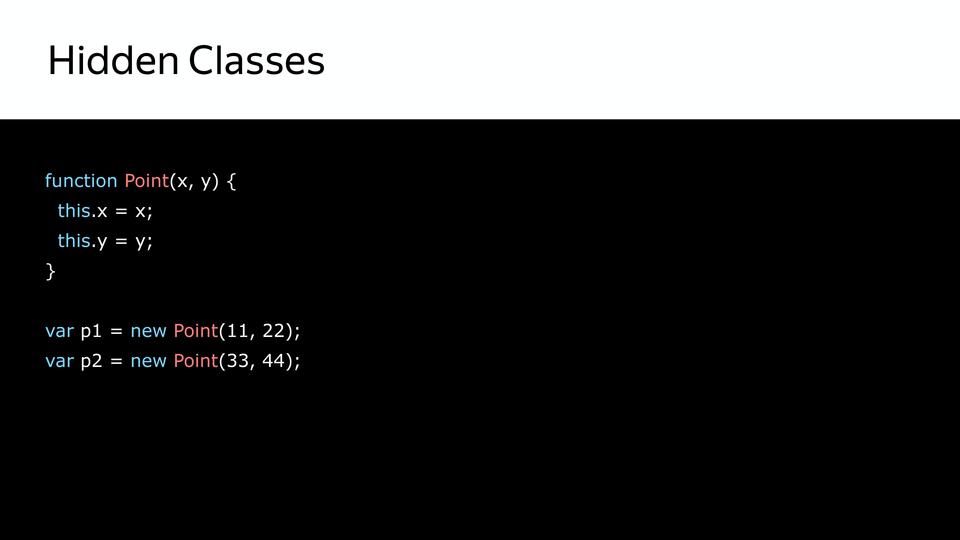
We have a point - this is a constructor, and objects are created. First, a hidden class is created that contains only the point itself.

Next, we set the property of this object x and from the fact that we had a hidden class, the next hidden class is created that contains x.
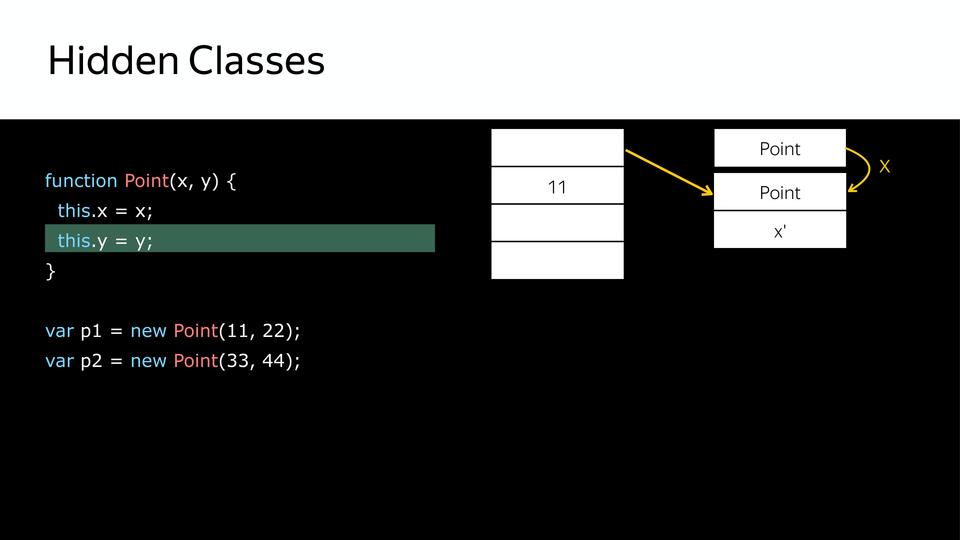
Next, we set y and, accordingly, we get another hidden class that contains x and y.
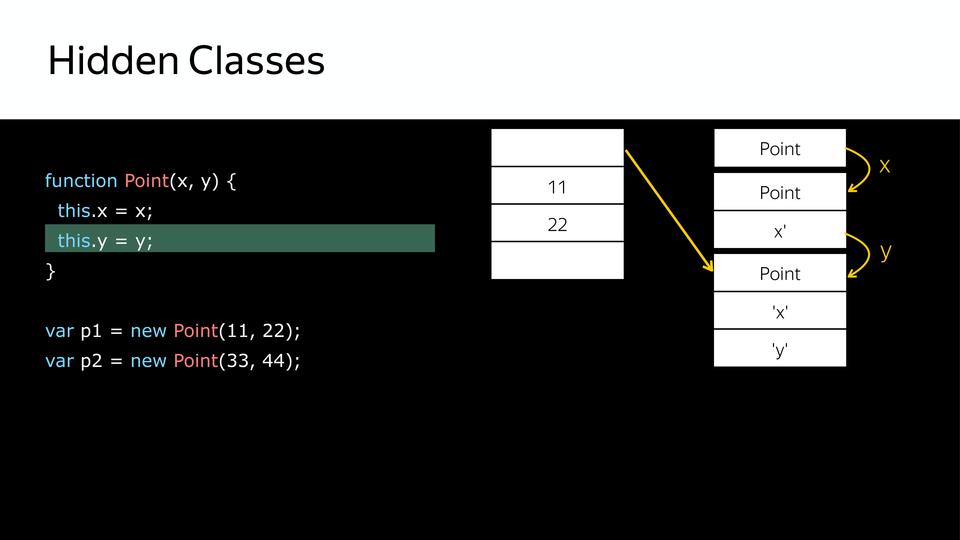
So we got three hidden classes. After that, when we create the second object using the same constructor, the same thing happens. There are already hidden classes, they no longer need to be created, you only need to map them. So that later we know that these two objects are identical in structure. And you can seem to work with them.
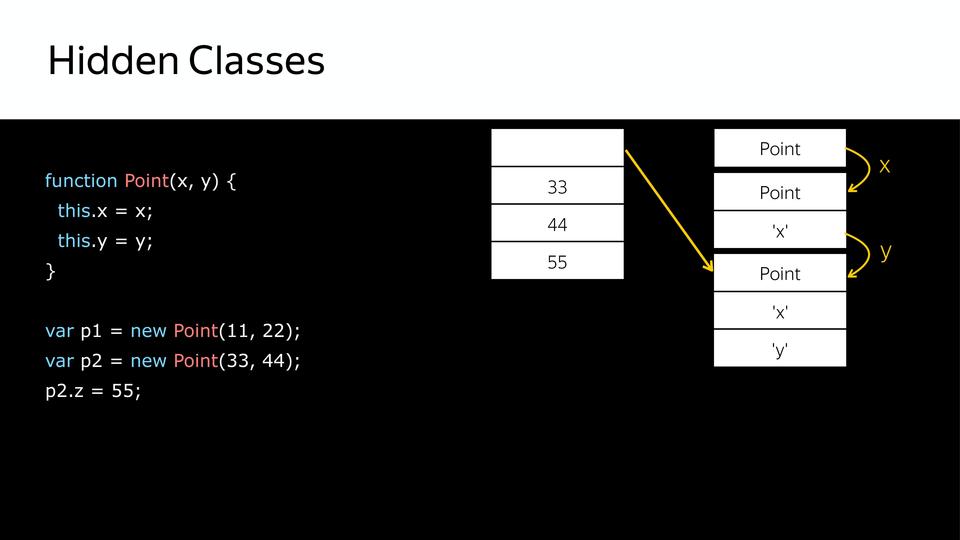
But what happens when we add a property to the p2 object later? A new hidden class is created, i.e. p1 and p2 are no longer similar. Why is it important? Because when the compiler will iterate over the point loop, and now it will have everything the same as p1, it will twist, twist, twist, bump into p2, and it has another hidden class, and the compiler goes into deoptimization, because he received not what he expected.

This is the so-called duck typing. What is duck typing? The expression came from American slang, if something walks like a duck, quacks like a duck, then it's a duck. Those. if p1 and p2 are identical in structure, then they belong to the same class. But we should add p2 to the structure, and these ducks quack in different ways, respectively, these are different classes.
And so we got data on what classes the objects belong to, and got data on what kind of variables, where to use this data and how to store them. For this, the Inline Caches system is used.

Let's see how Inline Caches is created for this part. At first, when our code is analyzed, it is supplemented with such calls. This is just initialization. We do not yet know what type of our Inline Caches we will have.
We can say that in this place initialize it, here download this.primes:

here download by key:

And then the BinaryOperation operation does not mean that it is binary, it means that it is binary, not unary. An operation that has left and right parts.

When the code arrives, it is all replaced with pieces of code that we already have inside the compiler, and the compiler knows how to work well with this particular case if we have type information. That is, here it is substituted for calling a code that knows how to get primes from an object:

Here it is substituted for code that knows how to get an element from an SMI array:

Here is a code that knows how to calculate the remainder of dividing two SMIs:

It already will be optimized. And so the compiler worked approximately, saturating with such pieces.

This, of course, gives some overhead, but also gives performance.
We have developed the Internet, the number of JavaScript has increased, more productivity was required, and Google responded by creating a new Crankshaft compiler.
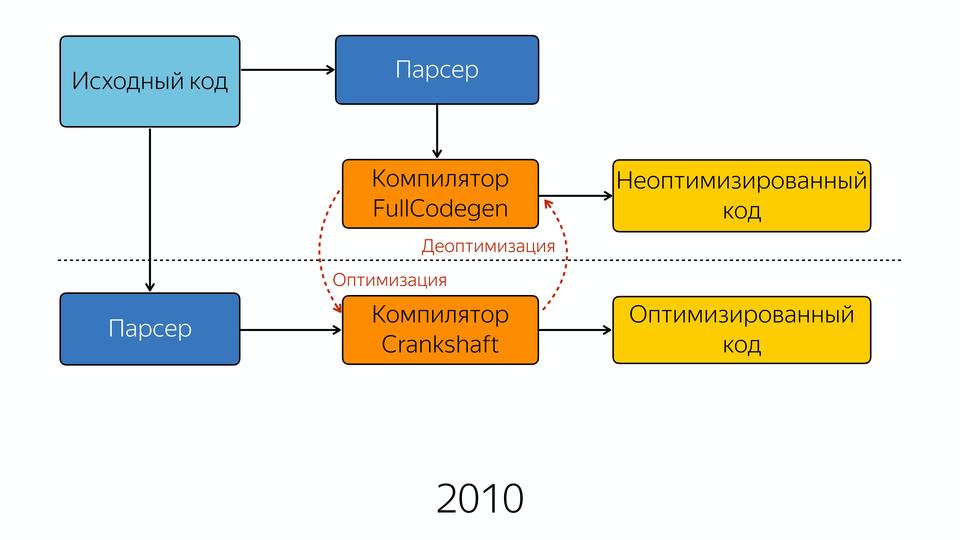
The old compiler began to be called FullCodegen because it works with a complete code base, it knows all JavaScript, how to compile it. And it produces non-optimized code. If he comes across a function that is called several times, he believes that it has become hot, and he knows that the Crankshaft compiler can optimize it. And he gives away knowledge about types and that this function can be optimized in the new Crankshaft compiler. Next, the new compiler retrieves the abstract syntax tree. It is important that he receives not from the old AST compiler, but goes back and requests the AST. And knowing about types, does optimization, and at the end we get optimized code.
If he cannot do the optimization, he falls into deoptimization. When does this happen? Here is how I said before, for example, in our Hidden Class cycle it spins, then something unexpected and we fell into deoptimization. Or, for example, many people like to do checks when we have something on the left side, and we take, for example, the length, i.e. we check if we have a string, and take its length. Why is this bad? Because when we don’t have a line, then on the left side we get Boolean and the output is Boolean, and before that there was Number. And in this case, we fall into deoptimization. Or he met a code, cannot optimize it.
Using the same code as an example. Here we had a code full of inline caches, it all inlines in the new compiler.

He inserts it all inline. Moreover, this compiler is a speculative optimizing compiler. What is he speculating on? He speculates on the knowledge of types. He suggests that if we called 10 times with this type, then this type will continue. Everywhere there are such checks that the type that he expected came, and when the type comes that he did not expect, he falls into deoptimization. These improvements gave a good performance boost, but gradually the team involved in the V8 engine realized that everything had to start from scratch. Why? There is such a way of software development when we write the first version, and we write the second version from scratch, because we understood how to write. And they created a new compiler - Turbofan in 2014.
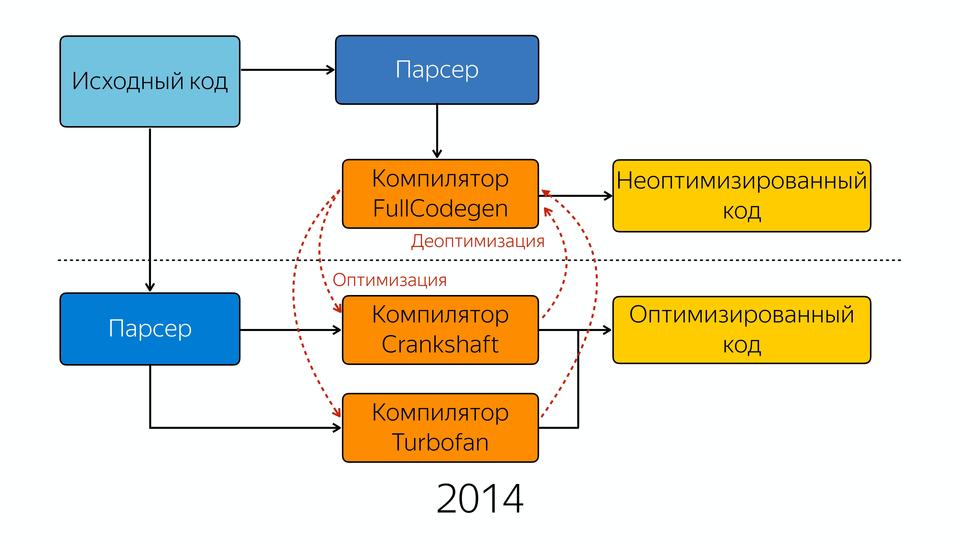
We have the source code, which gets into the parser, then into the FullCodegen compiler. So it was before, no differences. At the output, we get non-optimized code. If we can do any kind of optimization, then we go into two compilers, Crankshaft and Turbofan. FullCodegen decides whether the Turbofan compiler can optimize specific things, and if it can, it sends it to it, and if it cannot, it sends it to the old compiler. There gradually began to add new designs from ES6. We started by optimizing asm.js into it.
The old compiler was written in those years when we had powerful desktops. And it was tested on tests such as octane, synthetic, which tested peak performance. Recently, there was a Google I / O conference, and there the manager managing the development of V8 said that they basically abandoned octane, because it does not correspond to what the compiler actually works with. And this led to the fact that we had very good peak performance, but the base one, i.e. things in the code were not optimized, and when the code, which worked well, came across such things, a significant drop in performance occurred. And there are a lot of such operations, here are a few of them: forEach, map, reduce. They are written in plain JS, stuffed with checks, much slower than for. Often advised to use for.
The slow operation of bind - it is implemented internally, turns out to be completely horrible. Many frameworks wrote their own bind implementations. Often people said that I sat down, wrote bind on my knee and it works faster, amazingly. Functions containing try {} catch (e) {} (and finally) are very slow.

Often there was such a sign that it is better not to use it so that performance does not slip. Actually, the code is slow because the compiler is not working properly. And with the advent of Turbofan, you can forget about it, because everything is already optimized. Also very important: the performance of asynchronous functions has been improved.
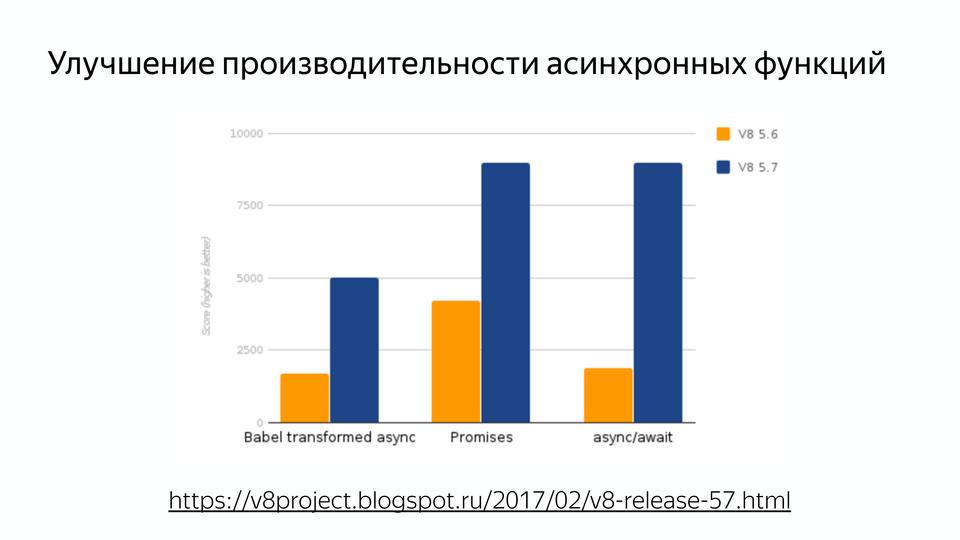
Therefore, everyone is waiting for the release of the new node, which has recently been released; performance with async / await is important there. Our language is asynchronous initially, but we could use it well only with callbacks. And those who write with promise know that their third-party implementations are faster than the native implementation.
The next challenge was to make performance predictable. There was a situation like this: code that showed itself perfectly on jsPerf, when pasted into the working code, showed a completely different performance. But there are other such cases when we could not guarantee that our code would work as productively as we originally intended.
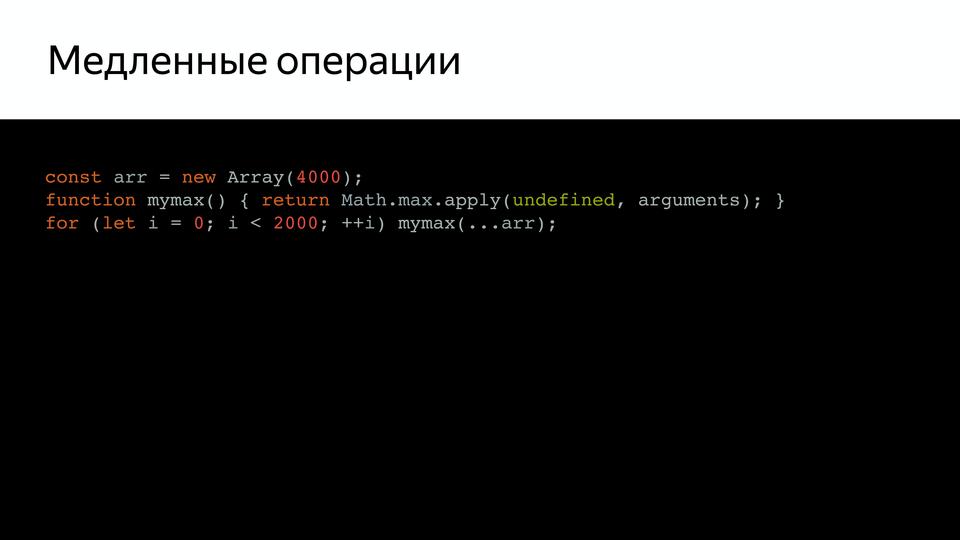
For example, we have such a fairly simple code that calls mymax, and if we check it (using the keys trace-opt and trace-deopt, they show which functions were optimized and which were not).
We can run this with node, or we can run it with D8, a special environment where V8 works separately from the browser. It shows us that optimizations have been disabled. Because too many times it was run for verification. What is the problem? It turns out that the arguments pseudo-array is too large, and inside, it turns out, there was a check for the size of this array. Moreover, this test, as Benedikt Meurer (Turbofan’s lead developer) said, didn’t make any sense, it just went over with copypaste over the years.
And why is the length limited? After all, the size of the stack is not checked, nothing, it was just so limited. This is an unexpected behavior that needed to be eliminated.

Another example, here we have a dispatcher that calls two callbacks. Also, if we call him, we will see that he was deoptimized. What is the problem here? That one function is strict, and the second is not strict. And they get different hidden classes in the old compiler. Those. he considers them different. And in this case, he also goes to deoptimization. Both this and the previous code, it is written correctly in principle, but it is deoptimized. This was unexpected.

There was also such an example on Twitter when it turned out that in some cases the for loop in chrome worked even slower than reduce. Although we know that reduce is slower. It turned out that the problem was that let was used inside the for - unexpectedly. I even installed the latest version at that time and the result is already good - fixed.
The next point was to reduce complexity. Here we had version V8 3.24.9 and it supported four architectures.
Now V8 supports nine architectures!
And the code has been accumulating for years. It was partially written in C, Assembler, JS, and this is how the developer who came to the team felt about.

The code must be easy to change so that you can respond to changes in the world. And with the introduction of Turbofan, the amount of architecture-specific code has decreased.
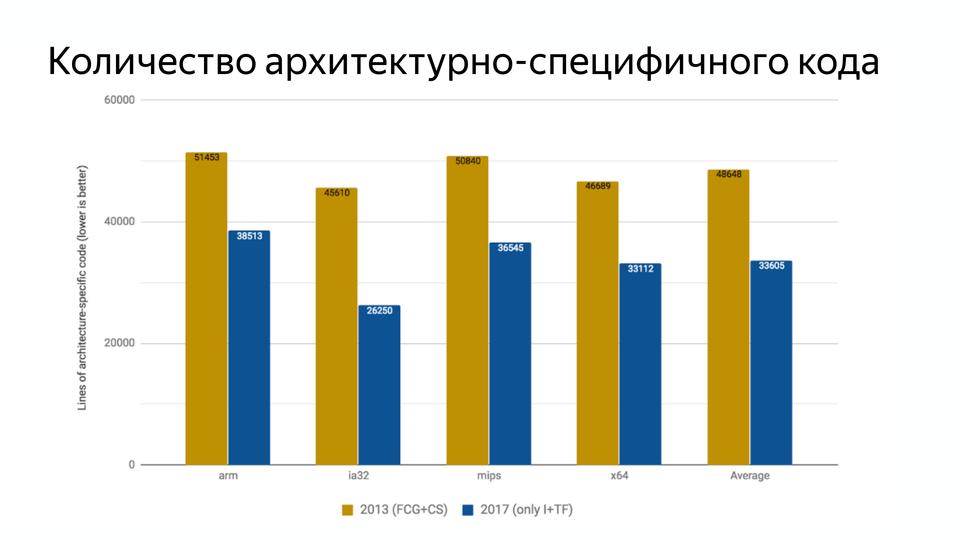
From 2013 to 2017, it became 29% less than the architecture-specific code. This was due to the emergence of a new code generation architecture in Turbofan.
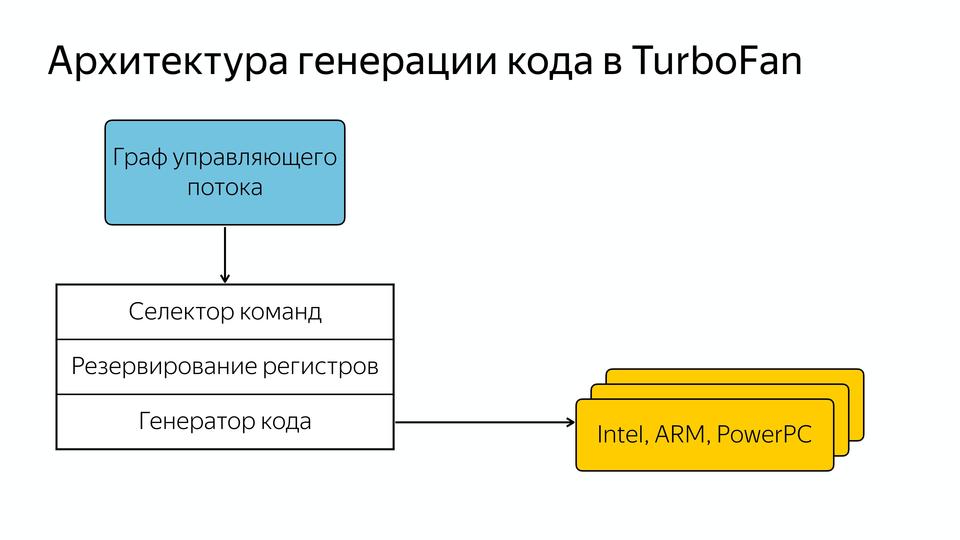
They made it data-driven, i.e. we have a control flow graph that contains data and knowledge about what should happen to them. And it falls into the general command selector, then there is a reservation of registers and then code generation for different architectures. Those. the developer no longer needs to know how everything is written for specific architectures, but more general code can be made. That's how it all happened, the code improved well, but gradually a few years after writing the compiler for the interpreted language, it turned out that an interpreter was needed.
And what's the reason? The reason is in the hands of Steve Jobs.

This, of course, is not the iPhone itself, but those smartphones that spawned the iPhone, which gave convenient access to the Internet. And this led to the fact that the number of users on mobile devices exceeded the number on desktops.
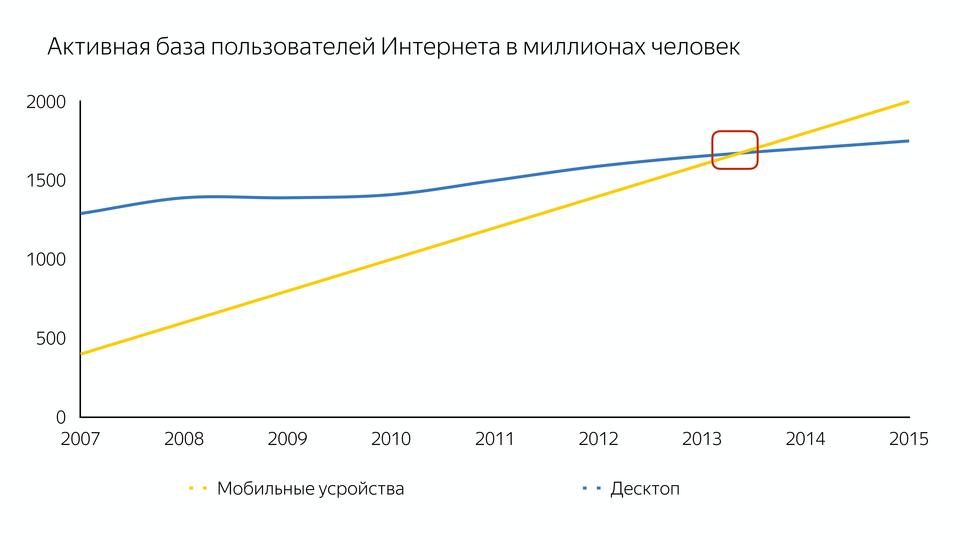
And initially, compilers were designed for powerful desktops, and not for mobile devices.
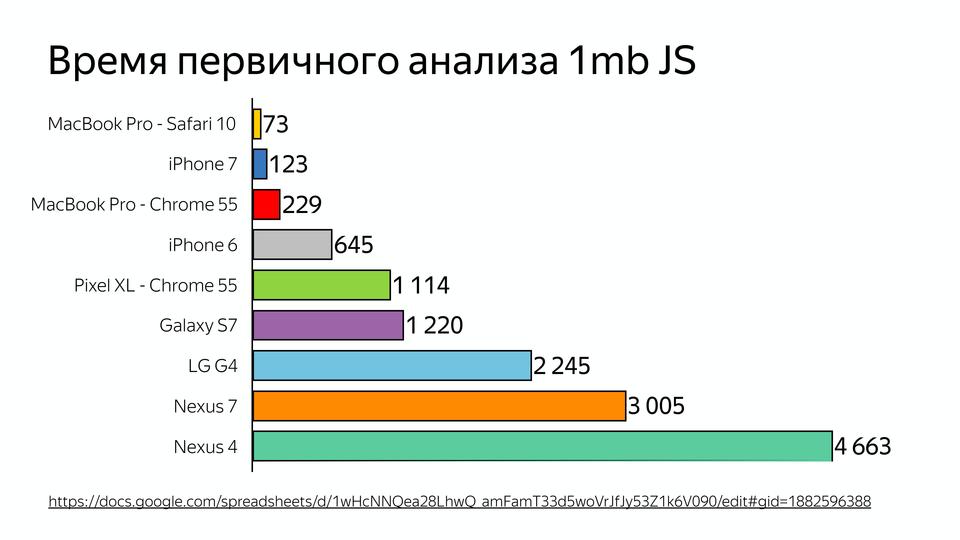
Here is a 1MB JavaScript initial analysis timeline. And recently there was a question why VKontakte does server rendering, but not client rendering. Because the time spent on JS analysis can be 2-5 times longer on mobile devices. And we are talking about top-end devices, and people often go with completely different ones.
And one more problem: many Chinese devices have 512 MB of memory, and if you look at how V8 memory is allocated, there is another problem.
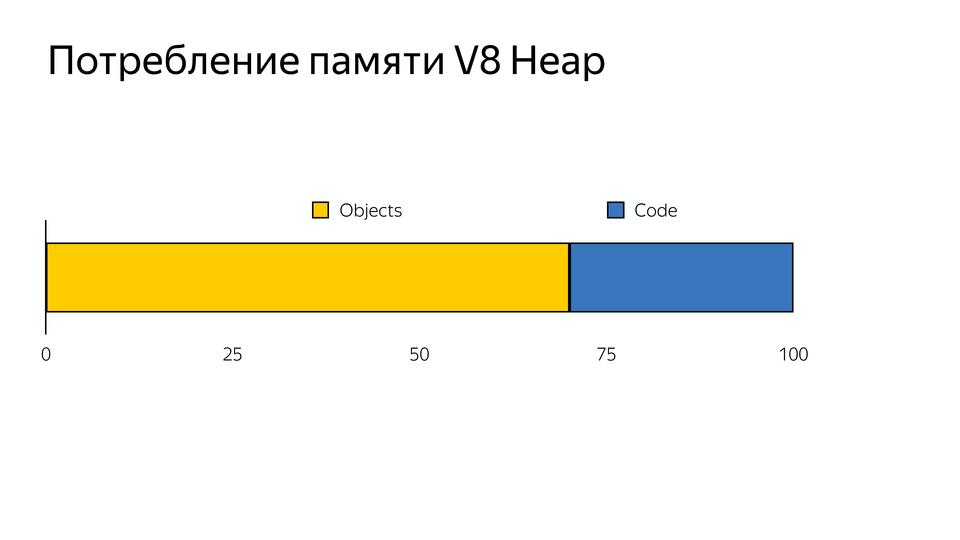
The memory is divided into objects (what our code uses) and code objects (this is what the compiler uses - for example, stores inline caches there). It turns out that 30% of the memory is occupied by a virtual machine to support internal use. We cannot manage this memory; the compiler consumes it.
It was necessary to do something with this, and in 2016 the Android development team from London responded by creating a new Ignition interpreter.

You may notice that the code optimized by the Turbofan compiler does not call the parser for the syntax tree, but receives something from the interpreter. It receives a bytecode.
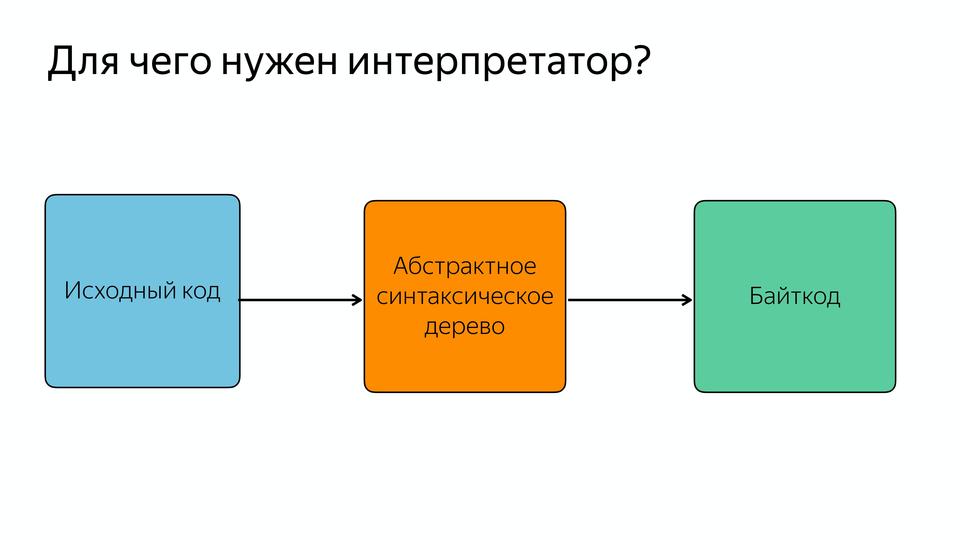
Now the abstract syntax tree is parsed into bytecode, and this JavaScript parsing happens once, then the bytecode is used.
If someone does not know, bytecode is a compact platform-independent representation of the program. This is somewhat similar to assembler, only platform independent. This is what it is called because all instructions occupy one byte.
Let's see how bytecode is generated for such a piece of the program.

We have a program, we have a generated bytecode, and we have a set of registers.
So we set the values for these input registers, which will get into our program. At the first stage, we load the accumulator into a special register (it is needed so as not to waste the registers once, but is involved only in calculations) smi integer equal to 100.

The next command tells us that we need to subtract from the register a2 (in the tablet we see 150 there) the previous battery value (100). In accumulator we got 50.

Next, the team tells us what needs to be saved in r0. It is associated with the variable d.

Further it becomes more clear. Again, load the value from b, multiply by the value of accumulator, add a0 and get the output, respectively, 105.
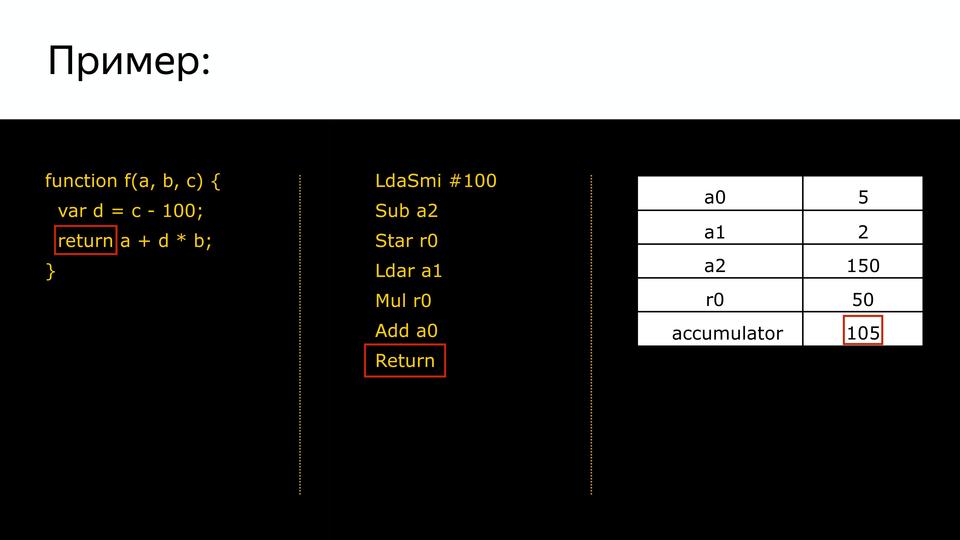
And our whole program turns into a long chain of bytecode. Thus, the memory consumption that was spent on storing our code was reduced.
There was a second problem, the memory that inline caches consumed. To do this, we switched to new caches - Data-driven IC, which reduce the cost of the slow path. The slow way is how the non-optimized code works, the fast code when it is optimized.
On the left we see the old scheme. When we need to find a field in an object, we store knowledge about where it lies in the object, somewhere we store this object and are able to handle it. In the new scheme, there is a control vector in which there is data and commands, and knowledge of what to do with these commands. And it goes through loading inline caches, on the fast track, if deoptimization, then on the slow path. And, accordingly, this scheme no longer requires the storage of calls to objects, and it turns out to be more compact. As a result, after the implementation of the scheme, memory consumption on the same code decreased.
And finally, this year the scheme has been greatly simplified.
Here we always work in the Turbofan compiler. You may notice that the FullCodegen compiler used to know all JS, and the Crankshaft compiler was only part of JS, and now the Turbofan compiler knows all JS and works with all JS. If he can’t optimize, he gives out non-optimized code, if he can, then, accordingly, optimized. And he turns to the interpreter for the code.

We have classes that are not visible (many know that there are new classes in ES6, but it's just sugar). They need to be monitored, because code for good performance should be monomorphic, not polymorphic. Those. if the classes included in the function change for us, their hidden class changes for objects that fall into our function, then the code becomes polymorphic and it is poorly optimized. If our objects come of the same type of hidden class, then, accordingly, the code is monomorphic.
In V8, code goes through an interpreter and a JIT compiler. The task of the JIT compiler is to make the code faster. The JIT compiler runs our code in a loop and each time, based on the data that it received last time, it tries to make the code better. It fills it with knowledge about the types that it receives during the first run, and due to this makes some optimizations. Inside it are pieces that are oriented to work with maximum performance. If we have a + b in our code, this is slow. We know that it is number + number or string + string, we can do it quickly. This is what the JIT compiler does.
The better the optimization, the higher the overhead (time, memory). The task of the interpreter is to reduce the memory overhead. Even with the advent of Turbofan, they abandoned some optimizations that were earlier, because they decided to increase the base performance and slightly reduce the peak.
The compiler has two modes of operation - cold and hot. Cold is when our function is launched for the first time. If the function was run several times, then the compiler realizes that it is already hot and is trying to optimize it. There is an ambush with tests. When developers run tests many times and receive any data, this is already optimized hot code. But in reality, this code can be called once or twice and show a completely different performance. This must be taken into account.
With monomorphic code the same example. That is, when we write the code, we can help our compiler. We can write code as if we had a typed language (do not redefine variables, do not write different types in them, always return the same type).
That's all the basic secrets.
Read links
github.com/v8/v8/wiki/TurboFan
http://benediktmeurer.de/
http://mrale.ph/
http://darksi.de/
https://medium.com/@amel_true
If you love JS as much as we do, and enjoy digging around in his entire interior, you might be interested in these reports at the upcoming Moscow HolyJS conference :
The material was prepared based on the author's report at the HolyJS 2017 conference, which was held in St. Petersburg on June 2-3. Presentation in pdf can be found at this link .
The movie "The Last Dragon Slayer" was released a few months ago. There, if the protagonist kills the dragon, then magic disappears in the world. I want to be an antagonist today, I want to kill a dragon, because in the world of JavaScript there is no place for magic. Everything that works works explicitly. We need to figure out how it works in order to understand how it works.
I want to share my passion with you. At some point in time, I realized that I didn’t know how it worked under the hood of the V8. I started reading literature, watching reports, which are mainly in English, accumulated knowledge, systematized it and I want to bring it to you.
Is our language interpreted or compiled?
I hope everyone knows the difference, but I repeat. Compiled languages: in them, the source code is converted by the compiler into machine code and written to a file. They use compilation before execution. What is the advantage? It does not need to be recompiled, it is as automated as possible for the system under which it is compiled. What is the disadvantage? If your operating system is changing, and if you do not have the source, you lose the program.
Interpreted languages - when the source code is executed by the interpreter program. The benefits are that cross-platform is easy to achieve. We deliver our source code as is, and if there is an interpreter in this system, then the code will work. JavaScript is, of course, interpreted.
Immerse yourself in history. Chrome launches in 2008. Google introduced the new V8 engine that year. In 2009, Node.js was introduced on the same engine, which consisted of V8 and the libUV library, which provides io, i.e. access to files, network some things, etc. In general, two very important things for us are built on the V8 engine. Let's see what it consists of.
In 2008, the engine was pretty simple inside. Well, relatively simple - its layout was simple. The source code fell into the parser, from the parser into the compiler, and at the output we got semi-optimized code. Semi-optimized, because there wasn’t any good optimization then. Perhaps in those years you had to write better JavaScript, because you could not hope that the optimizer would optimize it inside.
What is the parser for in this scheme?
The parser is needed in order to turn the source code into an abstract syntax tree or AST. AST is a tree in which all vertices are operators, and all leaves are operands.
Let's look at an example of a mathematical expression. We have such a tree, all vertices are operators, branches are operands. What is good about it is that it is very easy to generate machine code from it later. Those who worked with Assembler know that most often the instruction consists of what to do and what to do.
And here we can see whether we are at the current point an operator or operand. If it is an operator, we look at its operands and assemble the command.
What happens in JavaScript if we have, for example, an array, and we request an element from it at index 1? An abstract syntax tree appears in which the operator "load a property by key", and the operands are the object and key by which we load this property.
Why in javascript compiler?
As I said, our language is interpreted, but in its scheme we see a compiler. Why is he? There are actually two types of compilers. There are compilers (ahead-of-time) that compile before execution, and JIT compilers that compile at runtime. And due to JIT compilation, good acceleration is obtained. What is it for? Let's compare.
There is one and the same code. One in Pascal, the other in JavaScript. Pascal is a wonderful language. I believe that you need to learn to program with it, but not with JavaScript. If you have someone who wants to learn how to program, then show him Pascal or C.
What is the difference? Pascal can be compiled and interpreted, and JavaScript requires interpretation. The most important difference is static typing.
Because when we write in Pascal, we specify the variables that are needed, and then we write their types. Then it’s easy for the compiler to build good optimized code. How do we access variables in memory? We have an address, and we have a shift. For example, Integer 32, then we make a shift of 32 at this address into memory and get the data.
In JavaScript, no, our types always change at runtime, and the compiler, when this code executes, the first time it executes it as it is, but collects information about the types. And the second time that he performs the same function, he is already based on the data that he received the last time, assuming what types were there, can do some kind of optimization. If everything is clear with variables, they are determined by value, then what about objects?
After all, we have JavaScript, it has a prototype model, and we do not have classes for objects. Actually there is, but they are not visible. These are the so-called Hidden Classes. They are visible only to the compiler.
How are Hidden Classes created?
We have a point - this is a constructor, and objects are created. First, a hidden class is created that contains only the point itself.
Next, we set the property of this object x and from the fact that we had a hidden class, the next hidden class is created that contains x.
Next, we set y and, accordingly, we get another hidden class that contains x and y.
So we got three hidden classes. After that, when we create the second object using the same constructor, the same thing happens. There are already hidden classes, they no longer need to be created, you only need to map them. So that later we know that these two objects are identical in structure. And you can seem to work with them.
But what happens when we add a property to the p2 object later? A new hidden class is created, i.e. p1 and p2 are no longer similar. Why is it important? Because when the compiler will iterate over the point loop, and now it will have everything the same as p1, it will twist, twist, twist, bump into p2, and it has another hidden class, and the compiler goes into deoptimization, because he received not what he expected.
This is the so-called duck typing. What is duck typing? The expression came from American slang, if something walks like a duck, quacks like a duck, then it's a duck. Those. if p1 and p2 are identical in structure, then they belong to the same class. But we should add p2 to the structure, and these ducks quack in different ways, respectively, these are different classes.
And so we got data on what classes the objects belong to, and got data on what kind of variables, where to use this data and how to store them. For this, the Inline Caches system is used.
Let's see how Inline Caches is created for this part. At first, when our code is analyzed, it is supplemented with such calls. This is just initialization. We do not yet know what type of our Inline Caches we will have.
We can say that in this place initialize it, here download this.primes:
here download by key:
And then the BinaryOperation operation does not mean that it is binary, it means that it is binary, not unary. An operation that has left and right parts.
What happens at runtime?
When the code arrives, it is all replaced with pieces of code that we already have inside the compiler, and the compiler knows how to work well with this particular case if we have type information. That is, here it is substituted for calling a code that knows how to get primes from an object:
Here it is substituted for code that knows how to get an element from an SMI array:
Here is a code that knows how to calculate the remainder of dividing two SMIs:
It already will be optimized. And so the compiler worked approximately, saturating with such pieces.
This, of course, gives some overhead, but also gives performance.
We have developed the Internet, the number of JavaScript has increased, more productivity was required, and Google responded by creating a new Crankshaft compiler.
The old compiler began to be called FullCodegen because it works with a complete code base, it knows all JavaScript, how to compile it. And it produces non-optimized code. If he comes across a function that is called several times, he believes that it has become hot, and he knows that the Crankshaft compiler can optimize it. And he gives away knowledge about types and that this function can be optimized in the new Crankshaft compiler. Next, the new compiler retrieves the abstract syntax tree. It is important that he receives not from the old AST compiler, but goes back and requests the AST. And knowing about types, does optimization, and at the end we get optimized code.
If he cannot do the optimization, he falls into deoptimization. When does this happen? Here is how I said before, for example, in our Hidden Class cycle it spins, then something unexpected and we fell into deoptimization. Or, for example, many people like to do checks when we have something on the left side, and we take, for example, the length, i.e. we check if we have a string, and take its length. Why is this bad? Because when we don’t have a line, then on the left side we get Boolean and the output is Boolean, and before that there was Number. And in this case, we fall into deoptimization. Or he met a code, cannot optimize it.
Using the same code as an example. Here we had a code full of inline caches, it all inlines in the new compiler.
He inserts it all inline. Moreover, this compiler is a speculative optimizing compiler. What is he speculating on? He speculates on the knowledge of types. He suggests that if we called 10 times with this type, then this type will continue. Everywhere there are such checks that the type that he expected came, and when the type comes that he did not expect, he falls into deoptimization. These improvements gave a good performance boost, but gradually the team involved in the V8 engine realized that everything had to start from scratch. Why? There is such a way of software development when we write the first version, and we write the second version from scratch, because we understood how to write. And they created a new compiler - Turbofan in 2014.
We have the source code, which gets into the parser, then into the FullCodegen compiler. So it was before, no differences. At the output, we get non-optimized code. If we can do any kind of optimization, then we go into two compilers, Crankshaft and Turbofan. FullCodegen decides whether the Turbofan compiler can optimize specific things, and if it can, it sends it to it, and if it cannot, it sends it to the old compiler. There gradually began to add new designs from ES6. We started by optimizing asm.js into it.
Why do we need a new compiler?
- Improve basic performance
- Make performance predictable.
- Reduce source code complexity
What does it mean to “improve basic performance”?
The old compiler was written in those years when we had powerful desktops. And it was tested on tests such as octane, synthetic, which tested peak performance. Recently, there was a Google I / O conference, and there the manager managing the development of V8 said that they basically abandoned octane, because it does not correspond to what the compiler actually works with. And this led to the fact that we had very good peak performance, but the base one, i.e. things in the code were not optimized, and when the code, which worked well, came across such things, a significant drop in performance occurred. And there are a lot of such operations, here are a few of them: forEach, map, reduce. They are written in plain JS, stuffed with checks, much slower than for. Often advised to use for.
The slow operation of bind - it is implemented internally, turns out to be completely horrible. Many frameworks wrote their own bind implementations. Often people said that I sat down, wrote bind on my knee and it works faster, amazingly. Functions containing try {} catch (e) {} (and finally) are very slow.
Often there was such a sign that it is better not to use it so that performance does not slip. Actually, the code is slow because the compiler is not working properly. And with the advent of Turbofan, you can forget about it, because everything is already optimized. Also very important: the performance of asynchronous functions has been improved.
Therefore, everyone is waiting for the release of the new node, which has recently been released; performance with async / await is important there. Our language is asynchronous initially, but we could use it well only with callbacks. And those who write with promise know that their third-party implementations are faster than the native implementation.
The next challenge was to make performance predictable. There was a situation like this: code that showed itself perfectly on jsPerf, when pasted into the working code, showed a completely different performance. But there are other such cases when we could not guarantee that our code would work as productively as we originally intended.
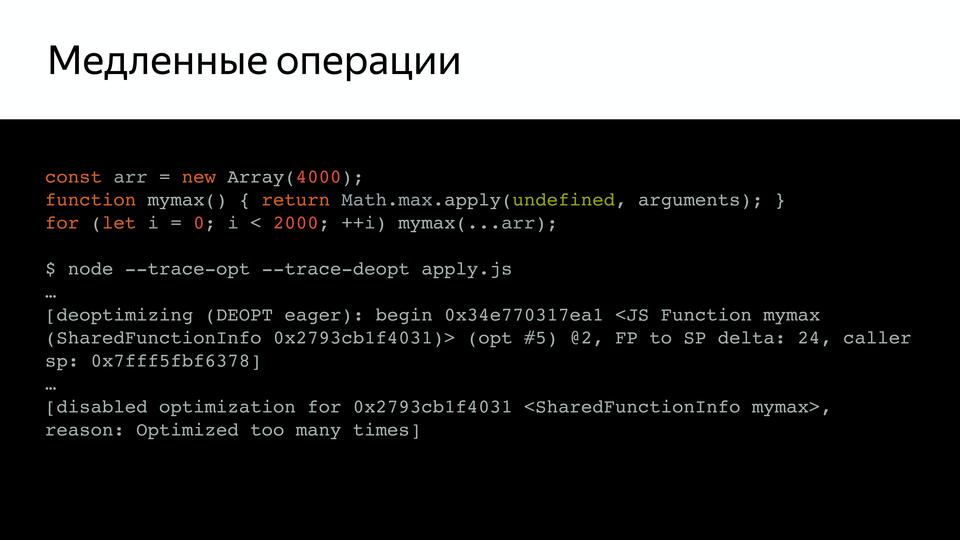
For example, we have such a fairly simple code that calls mymax, and if we check it (using the keys trace-opt and trace-deopt, they show which functions were optimized and which were not).
We can run this with node, or we can run it with D8, a special environment where V8 works separately from the browser. It shows us that optimizations have been disabled. Because too many times it was run for verification. What is the problem? It turns out that the arguments pseudo-array is too large, and inside, it turns out, there was a check for the size of this array. Moreover, this test, as Benedikt Meurer (Turbofan’s lead developer) said, didn’t make any sense, it just went over with copypaste over the years.
And why is the length limited? After all, the size of the stack is not checked, nothing, it was just so limited. This is an unexpected behavior that needed to be eliminated.
Another example, here we have a dispatcher that calls two callbacks. Also, if we call him, we will see that he was deoptimized. What is the problem here? That one function is strict, and the second is not strict. And they get different hidden classes in the old compiler. Those. he considers them different. And in this case, he also goes to deoptimization. Both this and the previous code, it is written correctly in principle, but it is deoptimized. This was unexpected.
There was also such an example on Twitter when it turned out that in some cases the for loop in chrome worked even slower than reduce. Although we know that reduce is slower. It turned out that the problem was that let was used inside the for - unexpectedly. I even installed the latest version at that time and the result is already good - fixed.
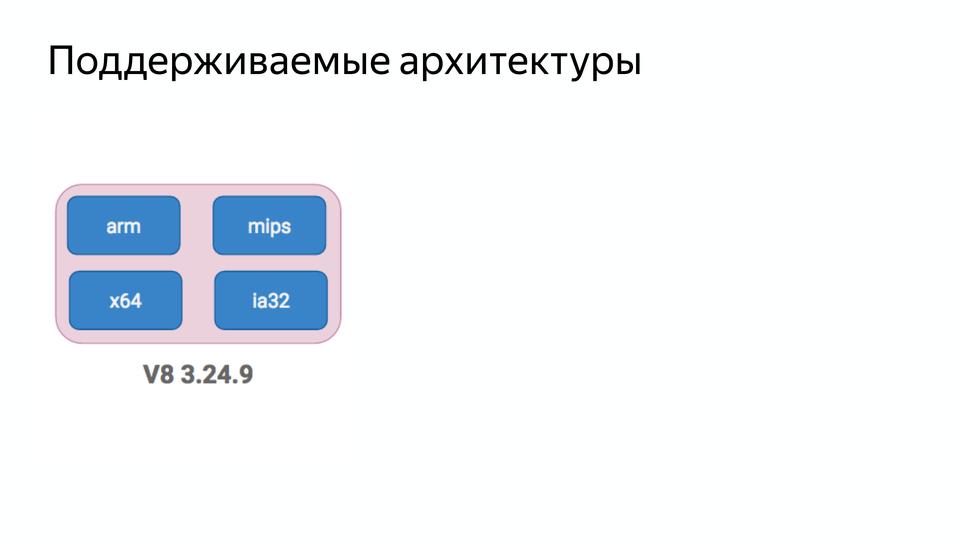
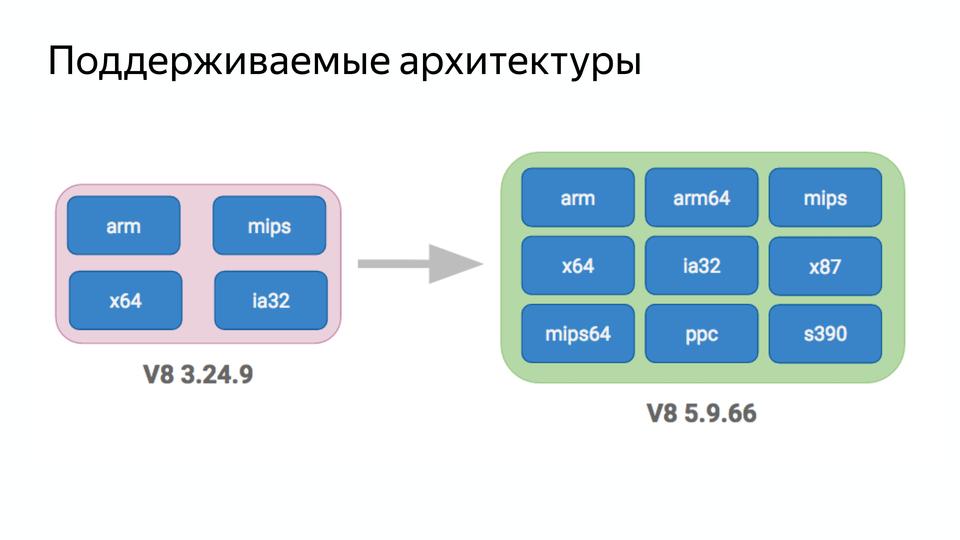
The next point was to reduce complexity. Here we had version V8 3.24.9 and it supported four architectures.
Now V8 supports nine architectures!
And the code has been accumulating for years. It was partially written in C, Assembler, JS, and this is how the developer who came to the team felt about.
The code must be easy to change so that you can respond to changes in the world. And with the introduction of Turbofan, the amount of architecture-specific code has decreased.
From 2013 to 2017, it became 29% less than the architecture-specific code. This was due to the emergence of a new code generation architecture in Turbofan.
They made it data-driven, i.e. we have a control flow graph that contains data and knowledge about what should happen to them. And it falls into the general command selector, then there is a reservation of registers and then code generation for different architectures. Those. the developer no longer needs to know how everything is written for specific architectures, but more general code can be made. That's how it all happened, the code improved well, but gradually a few years after writing the compiler for the interpreted language, it turned out that an interpreter was needed.
And what's the reason? The reason is in the hands of Steve Jobs.
This, of course, is not the iPhone itself, but those smartphones that spawned the iPhone, which gave convenient access to the Internet. And this led to the fact that the number of users on mobile devices exceeded the number on desktops.
And initially, compilers were designed for powerful desktops, and not for mobile devices.
Here is a 1MB JavaScript initial analysis timeline. And recently there was a question why VKontakte does server rendering, but not client rendering. Because the time spent on JS analysis can be 2-5 times longer on mobile devices. And we are talking about top-end devices, and people often go with completely different ones.
And one more problem: many Chinese devices have 512 MB of memory, and if you look at how V8 memory is allocated, there is another problem.
The memory is divided into objects (what our code uses) and code objects (this is what the compiler uses - for example, stores inline caches there). It turns out that 30% of the memory is occupied by a virtual machine to support internal use. We cannot manage this memory; the compiler consumes it.
It was necessary to do something with this, and in 2016 the Android development team from London responded by creating a new Ignition interpreter.
You may notice that the code optimized by the Turbofan compiler does not call the parser for the syntax tree, but receives something from the interpreter. It receives a bytecode.
Now the abstract syntax tree is parsed into bytecode, and this JavaScript parsing happens once, then the bytecode is used.
If someone does not know, bytecode is a compact platform-independent representation of the program. This is somewhat similar to assembler, only platform independent. This is what it is called because all instructions occupy one byte.
Let's see how bytecode is generated for such a piece of the program.
We have a program, we have a generated bytecode, and we have a set of registers.
So we set the values for these input registers, which will get into our program. At the first stage, we load the accumulator into a special register (it is needed so as not to waste the registers once, but is involved only in calculations) smi integer equal to 100.
The next command tells us that we need to subtract from the register a2 (in the tablet we see 150 there) the previous battery value (100). In accumulator we got 50.
Next, the team tells us what needs to be saved in r0. It is associated with the variable d.
Further it becomes more clear. Again, load the value from b, multiply by the value of accumulator, add a0 and get the output, respectively, 105.
And our whole program turns into a long chain of bytecode. Thus, the memory consumption that was spent on storing our code was reduced.
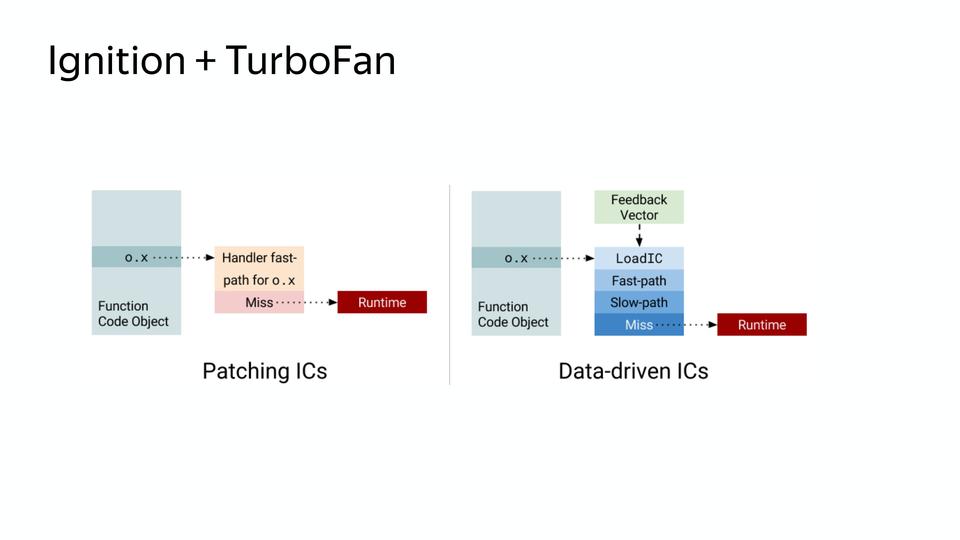
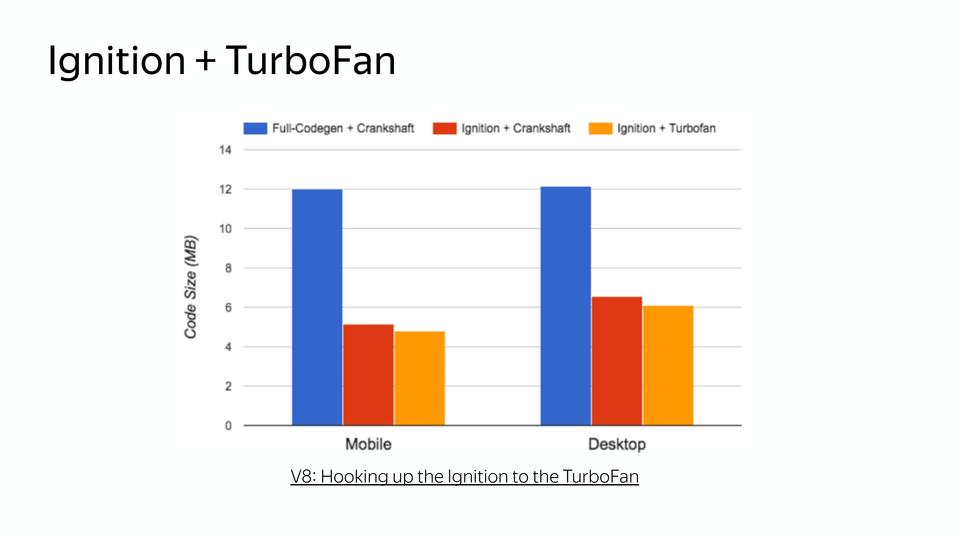
There was a second problem, the memory that inline caches consumed. To do this, we switched to new caches - Data-driven IC, which reduce the cost of the slow path. The slow way is how the non-optimized code works, the fast code when it is optimized.
On the left we see the old scheme. When we need to find a field in an object, we store knowledge about where it lies in the object, somewhere we store this object and are able to handle it. In the new scheme, there is a control vector in which there is data and commands, and knowledge of what to do with these commands. And it goes through loading inline caches, on the fast track, if deoptimization, then on the slow path. And, accordingly, this scheme no longer requires the storage of calls to objects, and it turns out to be more compact. As a result, after the implementation of the scheme, memory consumption on the same code decreased.
And finally, this year the scheme has been greatly simplified.
Here we always work in the Turbofan compiler. You may notice that the FullCodegen compiler used to know all JS, and the Crankshaft compiler was only part of JS, and now the Turbofan compiler knows all JS and works with all JS. If he can’t optimize, he gives out non-optimized code, if he can, then, accordingly, optimized. And he turns to the interpreter for the code.
We have classes that are not visible (many know that there are new classes in ES6, but it's just sugar). They need to be monitored, because code for good performance should be monomorphic, not polymorphic. Those. if the classes included in the function change for us, their hidden class changes for objects that fall into our function, then the code becomes polymorphic and it is poorly optimized. If our objects come of the same type of hidden class, then, accordingly, the code is monomorphic.
In V8, code goes through an interpreter and a JIT compiler. The task of the JIT compiler is to make the code faster. The JIT compiler runs our code in a loop and each time, based on the data that it received last time, it tries to make the code better. It fills it with knowledge about the types that it receives during the first run, and due to this makes some optimizations. Inside it are pieces that are oriented to work with maximum performance. If we have a + b in our code, this is slow. We know that it is number + number or string + string, we can do it quickly. This is what the JIT compiler does.
The better the optimization, the higher the overhead (time, memory). The task of the interpreter is to reduce the memory overhead. Even with the advent of Turbofan, they abandoned some optimizations that were earlier, because they decided to increase the base performance and slightly reduce the peak.
The compiler has two modes of operation - cold and hot. Cold is when our function is launched for the first time. If the function was run several times, then the compiler realizes that it is already hot and is trying to optimize it. There is an ambush with tests. When developers run tests many times and receive any data, this is already optimized hot code. But in reality, this code can be called once or twice and show a completely different performance. This must be taken into account.
With monomorphic code the same example. That is, when we write the code, we can help our compiler. We can write code as if we had a typed language (do not redefine variables, do not write different types in them, always return the same type).
That's all the basic secrets.
Read links
github.com/v8/v8/wiki/TurboFan
http://benediktmeurer.de/
http://mrale.ph/
http://darksi.de/
https://medium.com/@amel_true
If you love JS as much as we do, and enjoy digging around in his entire interior, you might be interested in these reports at the upcoming Moscow HolyJS conference :
- Better, faster, stronger - getting more from the web platform (Martin Splitt)
- The Post JavaScript Apocalypse (Douglas Crockford)
- Testing serverless applications (Slobodan Stojanovic)