Apache® Ignite ™ + Persistent Data Store - In-Memory penetrates disks. Part I - Durable Memory
In the Apache Ignite , since version 2.1 there was a custom implementation of Persistence .
In order to build this mechanism in its modern design, it took dozens of man-hours, which were mainly spent on building a distributed fail-safe transactional storage with SQL support.
It all started with the fundamental problems of the previous mechanism, which made it possible to integrate In-Memory Data Grid with external persistent storage, for example, Cassandra or Postgres.
This approach imposed certain restrictions - for example, it was impossible to execute SQL or distributed computing on top of data that was not in memory, but in such external storage, it was impossible to start cold and lowRTO (Recovery Time Objective) without significant additional complications.
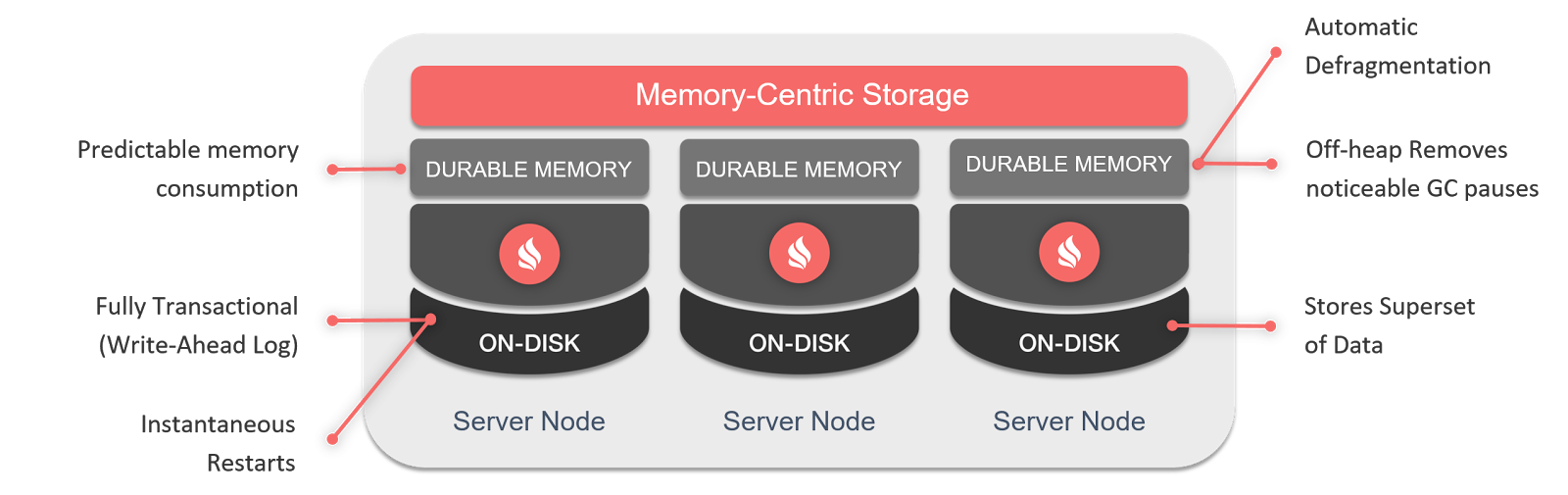
If you use Apache Ignite Persistence, then you leave yourself all the usual features of Apache Ignite - ACID , distributed transactions, distributed SQL99 , access via the Java / .NET API or JDBC / ODBC interfaces , distributed computing, and so on. But now what you use can work both on top of memory and on top of a disk that extends memory on installations from one node to several thousand nodes.
Let's see how Apache Ignite Persistence is built inside. Today I will consider its basis - Durable Memory, and in the next publication - the disk component itself.
Terminology
I will make a remark about terminology. In the context of the cache on the Apache Ignite cluster, I will use the concepts “cache” and “table” as interchangeably. I will use "cache" more often with reference to internal mechanics, and "table" - to SQL. In general, outside of Apache Ignite, these concepts may have a slightly different meaning, and outside of this article may not always be equivalent. So, given the availability of a permanent cache cache, Apache Ignite no longer always fits into the generally accepted semantics of this word. As for the “table”, based on the Apache Ignite cache, several “tables” can be defined with the ability to access using SQL, or no tables can be defined at all (then access will be possible only through the Java / .NET / C ++ API and its derivatives )
Durable memory
To build an effective mixed storage in memory and on disk, without duplicating a huge amount of code, which would significantly increase the cost of product support, it was necessary to significantly redesign the architecture for storing data in memory.
The new architecture - Durable Memory - like Persistence, has been running on large GridGain clients since the end of last year, and made its public debut since Apache Ignite 2.0. It provides off-heap data storage in page format.
Pages / Memory
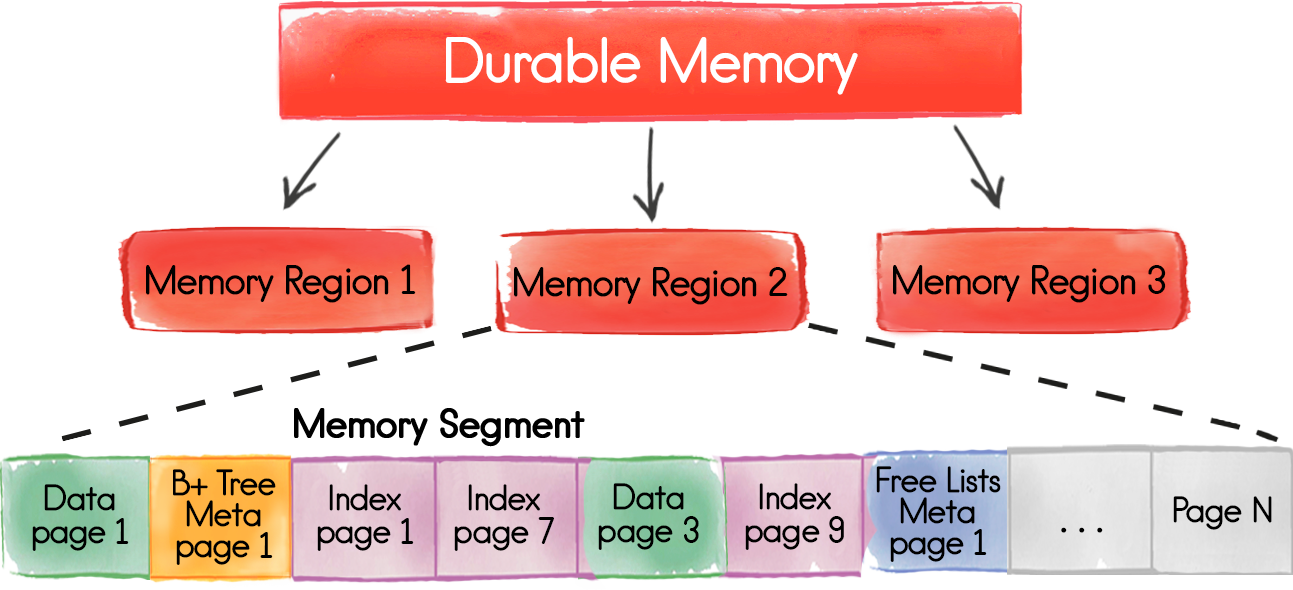
The base storage unit is a “page” that contains actual data or metadata.
When, when the allocated memory is exhausted, data is pushed to disk, this happens page by page. Therefore, the page size should not be too large, otherwise the extrusion efficiency will suffer, since in large pages, cold data is more likely to be mixed with hot data that will constantly pull the page up into memory.
But when the pages become small, there are problems of saving massive records that do not fit on one page, as well as problems of fragmentation and allocation of memory (it is too expensive to request memory from the operating system for each small page that will contain 1-2 records).
The first problem - with large recordings - is solved through the ability to "smear" such a recording into several pages, each of which stores only some segment. The flip side of this approach is lower performance when working with such records due to the need to crawl several pages to get complete information. Therefore, if this is a frequent case for you, then it makes sense to consider increasing the default page size (initially 2 KiB with the ability to vary between 1-16 KiB) through
MemoryConfiguration.setPageSize(…). In most situations, it makes sense to redefine the page size also if it differs from the page size on your SSD (most often it is 4 KiB). Otherwise, some performance degradation can be observed.
The second problem - with fragmentation - is partially solvedonline defragmentation built into the platform, which leaves only some small “fireproof residue” in the data page that is too small to fit anything else into it.
The third problem - the high cost of allocating memory for pages with a large number of them - is solved through the next level of abstraction, “segments”.
Memory segments
Segments are continuous blocks of memory that are an atomic unit of allocated memory. When the allocated memory ends, and if the restriction on use has not yet been reached, the OS requests an additional segment, which is further divided into pages inside.
In the current implementation, it is planned to allocate up to 16 memory segments to one region with a segment volume of at least 256 MiB. The actual volume of a segment is defined as the difference between the maximum allowed memory and the originally allocated, divided by 15 (the 16th segment is the initially allocated memory). For example, if the upper limit is 512 GiB per node, and 16 GiB is initially allocated, then the size of the allocated segments will be (512 - 16) / 15 ≈ 33 GiB.
When we talk about segments, we cannot but mention the restrictions on memory consumption. Let us consider their implementation in more detail.
It is not optimal to make global settings for all relevant parameters: maximum and initial volumes, crowding out, and so on, as different data may have different storage requirements. One example is the online and archive data storage. We may wish to store orders for the last year in the online storage, which for the most part is in memory, because there may be hot data, but at the same time we may want to store the old order history and past internal transactions without taking up, even temporarily precious memory.
It would be possible to make restrictions on the level of each cache, but then we would find ourselves in a situation where with a large number of tables - several hundreds or thousands - we would have to allocate a few memory crumbs each, or do overbooking, quickly getting a low memory error.
A mixed approach was chosen that allows us to define limits for groups of tables, which brings us to the next level of abstraction.
Regions of memory / Regions
The top level of the Durable Memory storage architecture is the logical entity “memory region”, which groups tables that share a single storage area with their settings, restrictions, and so on.
For example, if your application has a cache of goods with critical data for reliability and a number of derivative aggregate caches that are actively filled, but not very critical for loss, then you can define two memory regions: the first, with a consumption limit of 384 GiB and strict guarantees of consistency, bind the cache of goods, and to the second, with a limit of 64 GiB and with weakened guarantees, bind all the temporary caches that will share these 64 GiB of memory.
Regions of memory impose restrictions, determine storage settings and group caches in terms of group space allocated for storage.
Page Types and Data Retrieval
Memory pages are divided into several types, the key of which are data and index pages .
Data pages store data directly; they are already broadly discussed above. If the record does not fit on one page, then it will be spread out in several, but this is not a free operation. And if there are a lot of large entries in the application scenario, then it makes sense to increase the page size through
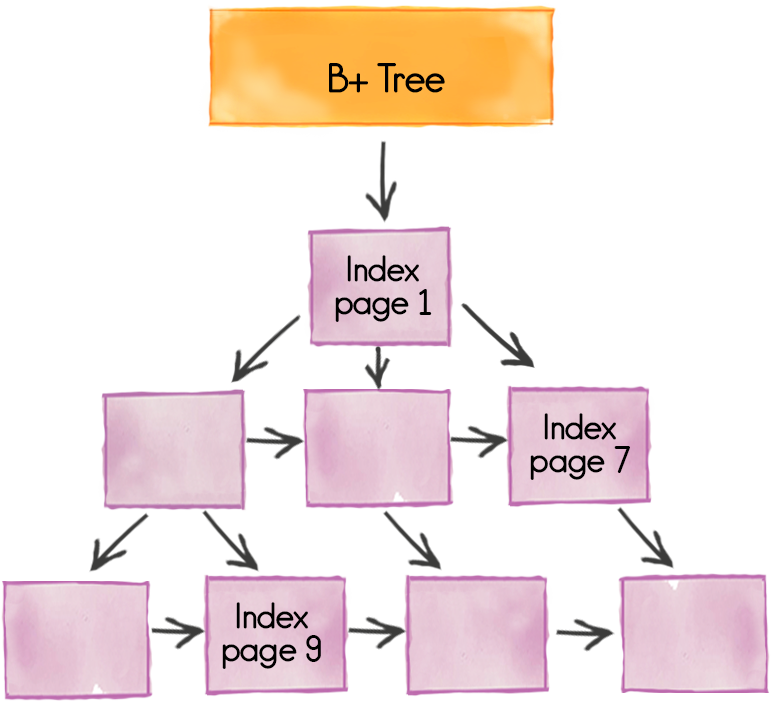
MemoryConfiguration.setPageSize(…). Data is pushed to disk by page: the page is either completely in RAM or completely on disk. Index pages are stored as B + trees, each of which can be distributed across several pages. Index pages are always in memory for maximum online access when searching for data.
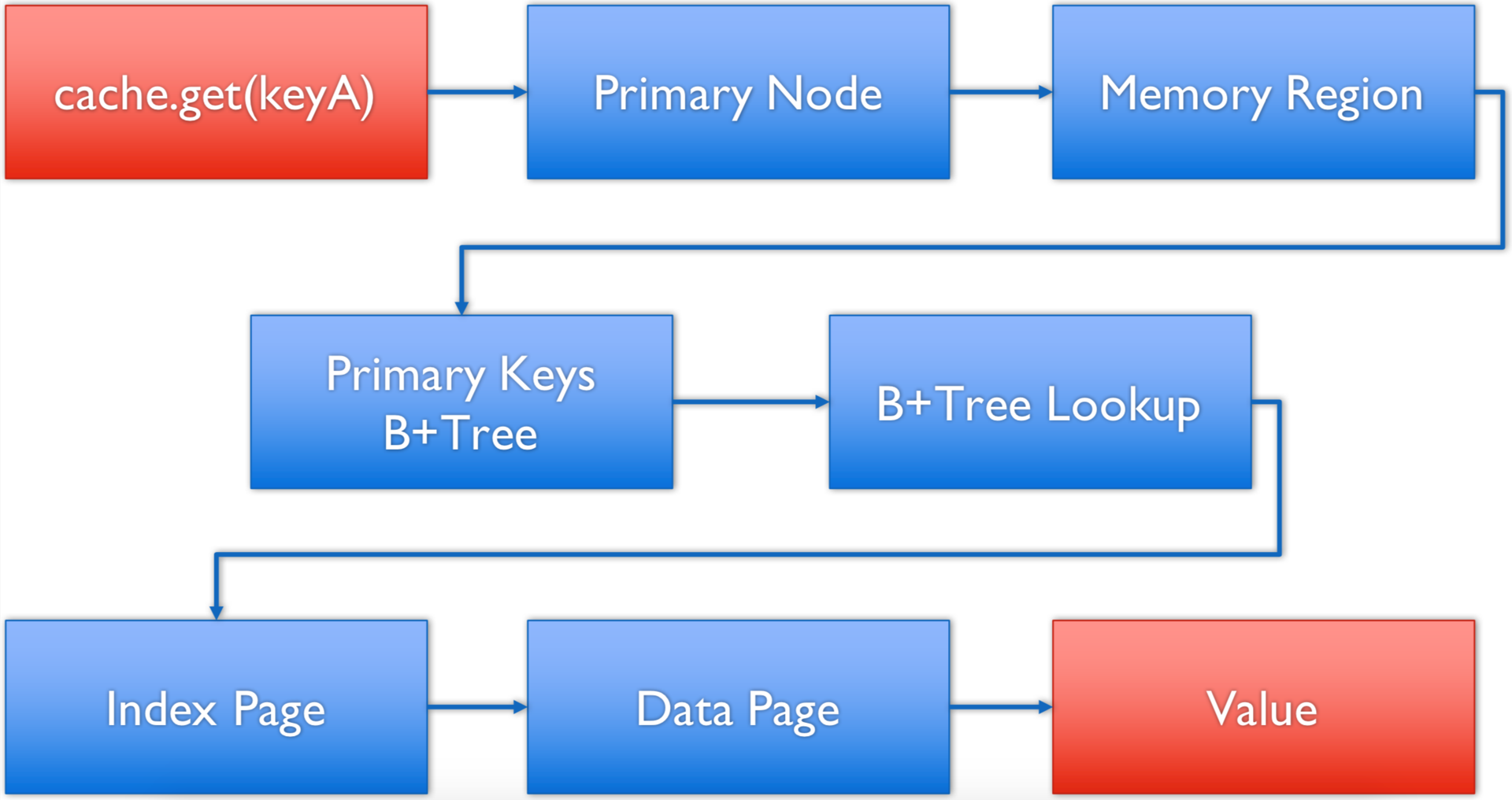
In such a scheme, to obtain data by key, we go through the following process:
- method is called on the client
cache.get(keyA); - the client determines the server node that is responsible for this key using the built-in affinity function and delegates the request over the network to this server node;
- the server node determines the region of memory that is responsible for the cache by the key in which the request is made;
- in the corresponding region, a meta-information page is being accessed, which contains entry points to the B + trees using the primary key of this cache;
- a search is made for the desired index page for a given key;
- the index page actually searches for the key and determines the data page that contains it, as well as the offset in this page;
- a data page is being accessed, and a value is read from it by key.
SQL
SQL queries using H2 generate a two-step execution plan (in the general case), which essentially boils down to a MapReduce-like approach. The first stage of the plan is "poured" into all the nodes that are responsible for the table, where the determination of the region of memory responsible for the table is likewise performed. Further, if the selection is by index, the desired index page is searched, the locations of the selected values are determined, and iteration is performed on them. In the case of a full scan, a complete iteration occurs on the primary index and, accordingly, access to all pages.
crowding out
Starting with version 2.0, extrusion works page by page, with deleting the page from memory. If Persistence is configured, the copy of the page and the entry in the indexes will remain intact, which will enable later to raise the necessary information from the local disk. If Persistence is explicitly turned off or not configured, then crowding out will completely remove the corresponding data from the cluster.
Pagination makes it impossible to easily work with key-value pairs, but it lays on Persistence much better, and with good enough page size gives good results.
Version 2.1 supports 3 extrusion modes :
- disabled - crowding out does not occur; an error is thrown when there is not enough memory;
- random lru - during extrusion in a loop, random 5 pages of data are selected, after which one is deleted — the one with the least access time stamp (accessed the longest). An approach with selection of 5 random pages was chosen due to the complexity of the high-performance implementation of the complete ordering of access time stamps;
- random 2 lru - similar to the previous version, but each page has two access timestamps - the last and the penultimate - and the smallest of them is used for selection. This approach allows you to more effectively handle situations, for example, with rare full scans or rare queries over a large part of the data array, which with random lru can create the appearance that some cold pages are hot.
DataPageEvictionMode
/** * Defines memory page eviction algorithm. A mode is set for a specific * {@link MemoryPolicyConfiguration}. Only data pages, that store key-value entries, are eligible for eviction. The * other types of pages, like index or meta pages, are not evictable. */ public enum DataPageEvictionMode { /** Eviction is disabled. */ DISABLED, /** * Random-LRU algorithm. **
*/ RANDOM_LRU, /** * Random-2-LRU algorithm: scan-resistant version of Random-LRU. *- Once a memory region defined by a memory policy is configured, an off-heap array is allocated to track * last usage timestamp for every individual data page. The size of the array is calculated this way - size = * ({@link MemoryPolicyConfiguration#getMaxSize()} / {@link MemoryConfiguration#pageSize})
*- When a data page is accessed, its timestamp gets updated in the tracking array. The page index in the * tracking array is calculated this way - index = (pageAddress / {@link MemoryPolicyConfiguration#getMaxSize()}
*- When it's required to evict some pages, the algorithm randomly chooses 5 indexes from the tracking array and * evicts a page with the latest timestamp. If some of the indexes point to non-data pages (index or system pages) * then the algorithm picks other pages.
*
* This algorithm differs from Random-LRU only in a way that two latest access timestamps are stored for every * data page. At the eviction time, a minimum between two latest timestamps is taken for further comparison with * minimums of other pages that might be evicted. LRU-2 outperforms LRU by resolving "one-hit wonder" problem - * if a data page is accessed rarely, but accidentally accessed once, it's protected from eviction for a long time. */ RANDOM_2_LRU; // ... }
* * *
In the next publication, I will examine in more detail how Durable Memory rests on the implementation of disk storage ( WAL + Checkpointing), and also dwell on the possibilities of creating snapshots that provide proprietary GridGain extensions.