Kaggle: Amazon Terrain Analysis From Satellite Images

Recently on kaggle.com there was a competition Planet understanding the amazon from space
Before that, I did not deal with image recognition, so I thought it was a great chance to learn how to work with pictures. Moreover, according to the assurances of people in the chat room, the entry threshold was very low, someone even called the dataset "MNIST on steroids."
Task
Actually, what each competition begins with is the statement of the problem and the quality metric. The task was as follows: pictures were taken from satellites of the Amazon area, and for each picture it was necessary to put down labels: road, river, field, forest, clouds, clear sky, and so on (a total of 17 pieces). Moreover, in the same picture could be several classes. As you can see, in addition to the type of terrain, there were also classes related to weather conditions, and, it seems logical, the weather in the picture can be only one. Well, it cannot be both clear and cloudy. When deciding the competition, I did not look at the data with my eyes, hoping that the machine itself would figure out who whose brother was, so I had to rummage around to give examples of images:

Baseline
How to solve such a problem? Take some convolutional neural network, trained on a large dataset, and retrain the weights on your set of pictures. In theory, of course, I heard this, and everything seems to be clear here, but to take and implement it until my hands reached. Well, first of all, you need to choose a framework for work. I followed a simple path and used keras , as it has very good documentation and clear human code.
Now a little more about the procedure for further training the scales (in the industry this is called Fine-tune) A convolutional neural network, such as VGG16, trained on the ImageNet dataset, consisting of several million pictures, is taken to predict one of the 1000 classes. Well, she predicts a cat, a dog, a car, so what? Our classes are completely different ... But the point is that the lower layers of the neural network are already able to recognize such basic components of the picture as lines and gradients. All that remains for us is to remove the top layer of 1000 neurons and put our own of 17 neurons instead of it (just as many classes can be in satellite images).
Thus, the neural network will predict the probability of each of the 17 classes. How is it likely to say if there is a particular class in the picture? The simplest idea is to cut off on a single threshold: if the probability is greater than, for example, 0.2, then we include the class, if less, then we do not. You can select this threshold for each class separately, and I did not come up with anything smarter than independent (which, of course, is not true, improving one threshold can affect the selection of another) to sort through thresholds , as they were called in the chat .
No sooner said than done. Result - Top 90%leaderboard. Yes, it’s bad, but you have to start somewhere. And here I want to say about the huge advantage of competition - a forum where a lot of people, professionals and not so much, are working on one problem, and even ready-made baseline's are published. From the discussions, I immediately realized that the file wasn’t right. The fact is that you need to train your weight in two stages:
- “Freeze” the weight of all layers except the last (of that of 17 neurons) and train only him
- After the loss drops to a certain value and further fluctuates around it, “unfreeze” all the weights and train the entire grid
After these simple manipulations, I got at least some acceptable quality, in my opinion. What to do next?
Augmentation
I heard that to enrich the dataset, augmentation can be done - some transformations of the image supplied to the input of the neural network. Well, really, if we rotate the picture, then the river or the road from it will not go anywhere, but now for training we will have not one picture, but two. I decided not to be too smart and turned the pictures only at angles that were multiples of 90 degrees, and also mirrored them. Thus, the size of the training dataset increased by 8 times, which immediately affected the quality for the better.

Then I thought, why not do the same, but in the prediction phase: take the network outputs for the converted pictures and average? It seems that so predictions will be more stable. I tried to implement it, I already learned how to rotate the pictures. Unexpectedly, but it really worked: with the same network architecture, I climbed 100 lines on the leaderboard. Only later did I learn from the chat that everything had already been invented before me and this technique is called Test Time Augmentation .
Ensemble 1
Recently, there is an opinion that to win the competition you just need to “stack xgboosts”. Yes, without building ensembles, it is unlikely to be able to get to the top, but without good physical engineering, without competent validation, it simply will not give any result. Therefore, before proceeding with the ensemble, a considerable amount of work needs to be done.
What models can be combined in the image recognition problem? The obvious idea is the various architectures of convolutional neural networks. You can read about their topologies in this article .
I used the following:
- VGG16
- VGG19
- Resnet101
- Resnet152
- Inception_v3
How to ensemble? For starters, you can take and average the predictions of all networks. If they do not correlate very much and give approximately the same quality, then, in my experience, averaging works almost always. It worked now.
Team
At the very least, I got to the border of the bronze medal. Meanwhile, a week remained until the end of the competition. It is at this time that the so-called merge deadline comes - the moment after which teaming is prohibited. And so, 20 minutes before the deadline, I think, why don't I, in fact, team up with someone? I look at the leaderboard, hoping to find someone from the chat near me. But nobody is online. Only asanakoy , which at that time was as much as 40 lines taller than me. What, what if? Well, I wrote. It remains 2 minutes to deadline'a - I get the answer that asanakoy does not mind uniting if I am ready to do something further. Artyom SanakoevIt turned out to be a PhD student in Computer Vision with existing victories in competitions, which, of course, could not but rejoice me. Teamwork is a huge plusparticipating in kaggle competitions because it allows newcomers like me to learn something new from their more experienced colleagues directly during a joint solution to the problem. Try to participate, and if you have at least small successes and a great desire to do something, then you will certainly be taken to a team where they will teach everything and everyone will show. Well, the first thing you want after the merger is to get an instant boost by combining your decisions. Which we did, climbing 30 lines at the same time, which was quite good, considering that a minimum of effort was made for this. Thanks to Artyom, I realized that I greatly under-trained my networks, and one of his models in the trash paid in quality all my combined. But there was still time to correct everything with the help of the advice of his teammate.
Ensemble 2
And so there were a few days left until the end of the competition, Artyom left for the CVPR conference , and I remained sitting with a bundle of predictions of various grids. Averaging is certainly good, but there are more advanced techniques such as stacking. The following idea is to break a training set, for example, into 5 parts, train the model in 4 of them, predict in the 5th,
and do it for all 5 folds. Explanatory picture:
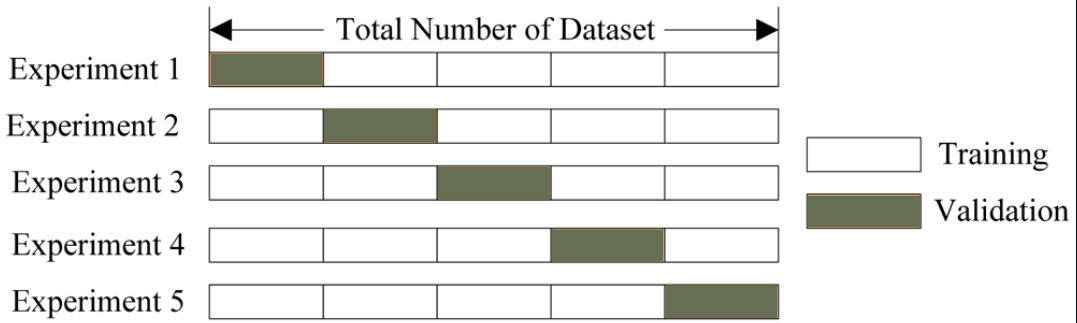
More about stacking, again, on the example of a competition, you can read here .
How to apply this to our task: we have predictions of the probabilities of each network for each of the 17 classes, total 6 networks * 17 classes = 102 recognition. This will be our new training set. On the resulting table, I trained a binary classifier for each of the classes (a total of 17 classifiers). As a result, there were label probabilities for each shot. Further to them you can apply the previously used greedy algorithm. But, to my surprise, stacking performed worse than simple averaging. For myself, I explained this by the fact that we had different breakdowns of the training set into folds - Artyom used 5 folds, and I only 4 folds (the more folds, the better, but you need to spend more time training models). Then it was decided to do stacking only on the predictions of their neural networks, and then take the weighted sum of the result with Artyom’s predictions. The second level models used were: lightgbm, xgboost and a three-layer perceptron, after which their outputs were averaged.
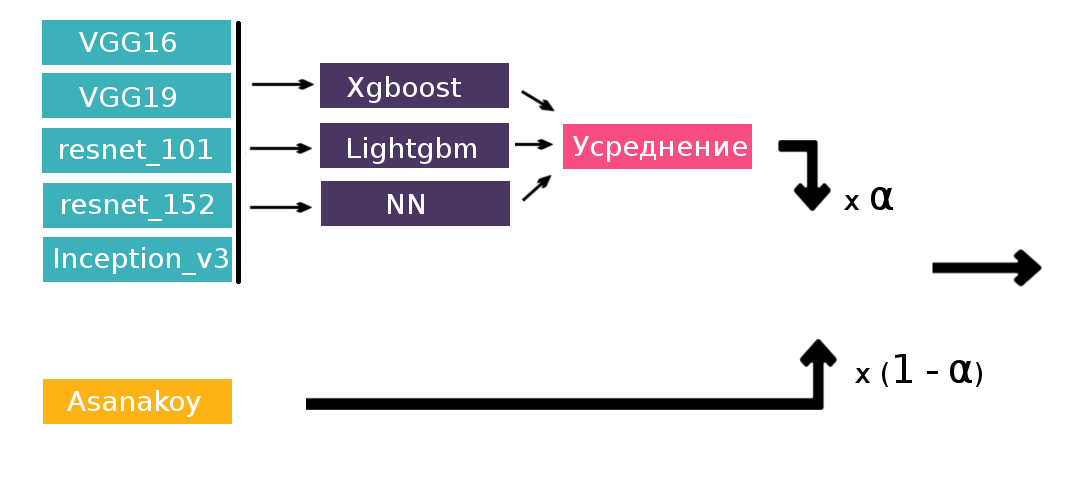
And here the stacking really worked, on the leaderboard we went up to confident silver medals. There were almost no ideas and time left, and I decided to add another neural network to the stacking with the last layer of four neurons and softmax activation, which predicted exclusively weather conditions. If a narrower problem is known, then why not use it? This gave an improvement, but not to say that it is very strong.
Summary
Nevertheless, as a result, we were in 17th place out of almost a thousand, which for the first competition in deep learning seems very good. Gold medals started from 11th place, and I realized that we were really close, and the solution differs from the top one, perhaps only with implementation details.
What else could be done
- At the forum, many wrote that the Densenet architecture shows very good results, but because of
my curvature of thelack of experience, I could not connect it - Make single folds, but more (in the chat they wrote that they do 10 folds)
- To predict the weather, it was possible to use not one model, but several
In conclusion, I would like to thank the responsive chat community ods.ai , where you can always ask for advice, and almost always help. In addition, two chat teams managed to take 3 and 7 places respectively.