How we created a device for fast processing of an event stream on FPGA
The device is called CEPappliance. CEP - from Complex Event Processing , and appliance - (and so it should be clear, but just in case) “device” from English.
We started it back in 2010 as a hobby, working on it after the main work on long evenings, smoothly turning into short nights, and on weekends. For 5 years of this work, we have created 3 prototypes in search of a solution with minimal delays and a simple programming model for data processing logic.
In 2015, we realized that we had a decent creation, which allows us to process data streams with a guaranteed delay of 2-3 microseconds. And we began to look for opportunities to turn what we started into a commercial product and, probably, stop working for the “uncle”, focus only on our product, devoting all our time to it. At the end of 2015, we found the first client, left “uncle” and set off for “free swimming”.
Today we can say for sure that the device we have succeeded. We have not yet implemented all our plans and we still have to work hard to add new functionality, sometimes correct errors. But our device has been in commercial operation for a year now.
Working for “uncles”, we studied the technical aspects and needs of trading financial instruments on exchanges well and focused primarily on them. This is automated trading (HFT, Algo Trading), risk control (Pre-trade), organization of “direct” access to trading (Direct Market Access), etc.
But we were able to make CEPappliance a fairly versatile device, applicable in areas where you need to pump a lot of data and do it not only quickly, but also with guaranteed low latencies. Thanks to the built-in support of standard network protocols and the introduction of minimal delays, the device is applicable in telecommunications for detecting security breaches in networks and controlling network load. The device can be used in telematics, when you need to make a decision in a few microseconds and respond to the receipt of signals from sensors. In this case, the logic of data processing by the device can be complex. To describe it (programming), we use some techniques of the Complex Event Processing ( CEP ) technology .
CEPappliance was conceived and created to solve problems that in a simplified form can be formulated as follows: with a total delay of less than 3 microseconds
CEPappliance different software solutions running on the CPU architectures that core device architecture is the field programmable gate array ( FPGA , FPGA ), which are implemented without exception steps solutions described problems.
CPU architectures are evolving. Hybrid variants appear (see Fig. 1 , Fig. 2 and Fig. 3), in which the time of data delivery from network interfaces to the processor (and vice versa) is reduced by transferring the processing of network and application layer protocols from the central processor to network cards. Nevertheless, the data delivery time is 1-3 microseconds (one way) and makes a significant contribution to the delay, which moves the reaction time away from the moment of signal 1 .
On FPGA we placed components for parsing, extracting, analyzing input data and generating output data on one chip, figuratively speaking “without intermediaries” (see Fig. 4 ), which are necessarily present in solutions with a central processor.

Fig. 1. Logic of a traditional solution with a central processor
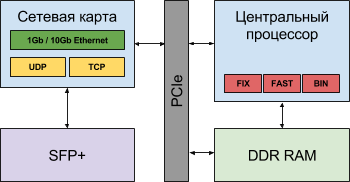
Fig. 2. Logic diagram of a hybrid solution with a central processor and TCP Offload Engine on a network card

Fig. 3.Logic scheme of a hybrid solution with a central processor, TCP Offload Engine and implementation of application layer protocols in a network card

Fig. 4. CEPappliance logic diagram
In CEPappliance, components for parsing, extracting, analyzing input data and generating output data are located on the FPGA chip and interact directly with each other.
To do this, I had to “reinvent the wheel” again. Let me remind you that we started work (back in 2010) on CEPappliance in hobby mode. They did everything themselves "as it should and correctly." As a result, among other things, we implemented Ethernet, TCP / IP, UDP, FIX, FAST and TWIME from scratch.
We were able to create these components so that the input data is parsed at the speed of their arrival (at wire speed) Components implement the relevant standards, which are “carved in stone” and do not often change. For standard protocols, we have provided a configuration mechanism. For example, FIX, FAST, TWIME, etc. protocol modules are configured using user-defined parameters and templates or schemes that describe the structure of messages.
At the same time, we proceeded from the fact that (user) data processing algorithms can change. For example, trading strategies or checks performed by a broker to minimize risks (pre-trade risk checks) follow changes in the market situation, modernization of the exchange’s microarchitecture, or regulatory requirements.
The development of algorithms for FPGA directly in hardware languages (VHDL, Verilog, etc.) requires significantly more time for coding, debugging and testing than development in high-level languages [2] . This also requires special skills that programmers who write programs in high-level languages, as a rule, do not possess. And if you plan to use FPGA to speed up the execution of your algorithms, then you will have to pass a detailed description of the algorithm to the FPGA developer who will implement it. Sometimes this is extremely undesirable, since the transfer of the description of the algorithm creates a risk for its owner to lose a competitive advantage.
Our device provides the user with the opportunity to describe the data processing algorithm. For this we have developed
Our own programming language, processor and compiler allow us to implement on FPGA (hardware) the functions available to the user. These functions can be parts of the algorithm or the entire algorithm - it depends on the appropriateness of such an implementation, the wishes and capabilities of the user. This approach can significantly speed up the execution of programs in the CEPappliance in some cases.
Having given the user the opportunity to program CEPappliance on their own, we obviously had to provide tools for debugging these programs. Without such tools, it would be difficult to take full advantage of the CEPappliance. Therefore, we developed a device emulator that is 100% compatible with the device itself. Having debugged the program on the emulator, you can change the configuration (in most cases, it is a change of IP address) and immediately run the program on the device.
In addition to debugging tools, the device emulator allows you to evaluate the program execution delay by the device itself. Using the delay measurements thus obtained, the program can be optimized.
And for automatic testing of user programs written for CEPappliance, we have a special tool - Test Bench, which reads test scripts in a tabular form and executes them. The same set of tests can be performed both with the device and with its emulator.
Well, summing up some of the results ... Our boards are in the data center of the Moscow Exchange and successfully trade. We can’t tell about the results of the bidding - this is not our topic, but the client is very satisfied (and this text is agreed with him).
Ahead is a lot of work on the development of the device, the search for customers in areas outside the stock trading and many new ideas!
1 About how this delay is formed in the case of data exchange via TCP / IP, see [1] . And here it is told how this delay can be reduced by implementing a hybrid architecture using FPGA.
1. S. Larsen and P. Sarangam, “Architectural Breakdown of End-to-End Latency in a TCP / IP Network,” International Journal of Parallel Programming, Springer, 2009.
2. David F. Bacon, Rodric Rabbah, and Sunil Shukla. FPGA Programming for the Masses . ACM Queue, Vol 11 (2), February 2013.
We started it back in 2010 as a hobby, working on it after the main work on long evenings, smoothly turning into short nights, and on weekends. For 5 years of this work, we have created 3 prototypes in search of a solution with minimal delays and a simple programming model for data processing logic.
In 2015, we realized that we had a decent creation, which allows us to process data streams with a guaranteed delay of 2-3 microseconds. And we began to look for opportunities to turn what we started into a commercial product and, probably, stop working for the “uncle”, focus only on our product, devoting all our time to it. At the end of 2015, we found the first client, left “uncle” and set off for “free swimming”.
Today we can say for sure that the device we have succeeded. We have not yet implemented all our plans and we still have to work hard to add new functionality, sometimes correct errors. But our device has been in commercial operation for a year now.
Working for “uncles”, we studied the technical aspects and needs of trading financial instruments on exchanges well and focused primarily on them. This is automated trading (HFT, Algo Trading), risk control (Pre-trade), organization of “direct” access to trading (Direct Market Access), etc.
But we were able to make CEPappliance a fairly versatile device, applicable in areas where you need to pump a lot of data and do it not only quickly, but also with guaranteed low latencies. Thanks to the built-in support of standard network protocols and the introduction of minimal delays, the device is applicable in telecommunications for detecting security breaches in networks and controlling network load. The device can be used in telematics, when you need to make a decision in a few microseconds and respond to the receipt of signals from sensors. In this case, the logic of data processing by the device can be complex. To describe it (programming), we use some techniques of the Complex Event Processing ( CEP ) technology .
CEPappliance was conceived and created to solve problems that in a simplified form can be formulated as follows: with a total delay of less than 3 microseconds
- receive input data (signal) via a network interface in the format of Ethernet, TCP / IP, UDP, FIX , FAST , TWIME (FIX SBE) protocols , etc .;
- parse and extract user data;
- analyze user data;
- generate output data (reaction) and send them via the network interface.
CEPappliance different software solutions running on the CPU architectures that core device architecture is the field programmable gate array ( FPGA , FPGA ), which are implemented without exception steps solutions described problems.
CPU architectures are evolving. Hybrid variants appear (see Fig. 1 , Fig. 2 and Fig. 3), in which the time of data delivery from network interfaces to the processor (and vice versa) is reduced by transferring the processing of network and application layer protocols from the central processor to network cards. Nevertheless, the data delivery time is 1-3 microseconds (one way) and makes a significant contribution to the delay, which moves the reaction time away from the moment of signal 1 .
On FPGA we placed components for parsing, extracting, analyzing input data and generating output data on one chip, figuratively speaking “without intermediaries” (see Fig. 4 ), which are necessarily present in solutions with a central processor.
Fig. 1. Logic of a traditional solution with a central processor
Fig. 2. Logic diagram of a hybrid solution with a central processor and TCP Offload Engine on a network card
Fig. 3.Logic scheme of a hybrid solution with a central processor, TCP Offload Engine and implementation of application layer protocols in a network card
Fig. 4. CEPappliance logic diagram
In CEPappliance, components for parsing, extracting, analyzing input data and generating output data are located on the FPGA chip and interact directly with each other.
To do this, I had to “reinvent the wheel” again. Let me remind you that we started work (back in 2010) on CEPappliance in hobby mode. They did everything themselves "as it should and correctly." As a result, among other things, we implemented Ethernet, TCP / IP, UDP, FIX, FAST and TWIME from scratch.
We were able to create these components so that the input data is parsed at the speed of their arrival (at wire speed) Components implement the relevant standards, which are “carved in stone” and do not often change. For standard protocols, we have provided a configuration mechanism. For example, FIX, FAST, TWIME, etc. protocol modules are configured using user-defined parameters and templates or schemes that describe the structure of messages.
At the same time, we proceeded from the fact that (user) data processing algorithms can change. For example, trading strategies or checks performed by a broker to minimize risks (pre-trade risk checks) follow changes in the market situation, modernization of the exchange’s microarchitecture, or regulatory requirements.
The development of algorithms for FPGA directly in hardware languages (VHDL, Verilog, etc.) requires significantly more time for coding, debugging and testing than development in high-level languages [2] . This also requires special skills that programmers who write programs in high-level languages, as a rule, do not possess. And if you plan to use FPGA to speed up the execution of your algorithms, then you will have to pass a detailed description of the algorithm to the FPGA developer who will implement it. Sometimes this is extremely undesirable, since the transfer of the description of the algorithm creates a risk for its owner to lose a competitive advantage.
Our device provides the user with the opportunity to describe the data processing algorithm. For this we have developed
- high level algorithmic language,
- processor of the original architecture and
- an optimizing compiler that translates programs from a high-level language into processor codes, and which can automatically parallelize program execution to several processors working simultaneously.
Our own programming language, processor and compiler allow us to implement on FPGA (hardware) the functions available to the user. These functions can be parts of the algorithm or the entire algorithm - it depends on the appropriateness of such an implementation, the wishes and capabilities of the user. This approach can significantly speed up the execution of programs in the CEPappliance in some cases.
Having given the user the opportunity to program CEPappliance on their own, we obviously had to provide tools for debugging these programs. Without such tools, it would be difficult to take full advantage of the CEPappliance. Therefore, we developed a device emulator that is 100% compatible with the device itself. Having debugged the program on the emulator, you can change the configuration (in most cases, it is a change of IP address) and immediately run the program on the device.
In addition to debugging tools, the device emulator allows you to evaluate the program execution delay by the device itself. Using the delay measurements thus obtained, the program can be optimized.
And for automatic testing of user programs written for CEPappliance, we have a special tool - Test Bench, which reads test scripts in a tabular form and executes them. The same set of tests can be performed both with the device and with its emulator.
Well, summing up some of the results ... Our boards are in the data center of the Moscow Exchange and successfully trade. We can’t tell about the results of the bidding - this is not our topic, but the client is very satisfied (and this text is agreed with him).
Ahead is a lot of work on the development of the device, the search for customers in areas outside the stock trading and many new ideas!
1 About how this delay is formed in the case of data exchange via TCP / IP, see [1] . And here it is told how this delay can be reduced by implementing a hybrid architecture using FPGA.
References
1. S. Larsen and P. Sarangam, “Architectural Breakdown of End-to-End Latency in a TCP / IP Network,” International Journal of Parallel Programming, Springer, 2009.
2. David F. Bacon, Rodric Rabbah, and Sunil Shukla. FPGA Programming for the Masses . ACM Queue, Vol 11 (2), February 2013.