Tutu.ru experience: how is the train schedule
Commuter trains - trains - remain one of the most popular types of passenger transport in Russia. Over the year, millions of passengers use them, traveling a total of hundreds of billions of kilometers on thousands of trains. In January 2017 alone, according to the Moscow Department of Transport, published in the Moscow Government's Unified Data Warehouse (ЕДД), the passenger traffic of suburban rail transport amounted to 42.6 million people. This is 4.1% higher than last year.
The availability, accessibility and accuracy of the timetable for electric trains excites every passenger, and for those who shape it and convey it to people, it is an important and very difficult task.
My name is Alexander Podlevskikh, I’m the lead development engineer for Tutu.ru, a team leader in the electric train, and in the article I’ll talk about the technical details and the difficulties of building an online schedule, how it all works, how we use the data provided by Russian Railways, and how our users help us keep the schedule up to date without realizing it.

The train schedule is a display of the process of train movement in a Cartesian coordinate system. In this form, the train schedule on the railway is presented.
In Russia there are about 30 suburban passenger companies (PPC), each of which is responsible for passenger service in a certain territory. On the basis of the transport order of the regions, the wishes of passengers and studies, each PPC forms proposals for changing the schedule, which are sent to JSC Russian Railways once a year (around the beginning of summer).
Having received applications for the schedule of electric trains, passenger and freight trains, Russian Railways, within a few months, develops a new train schedule (new schedule) and puts it into effect at the end of the year. Such a schedule, valid from the second Sunday of December of each year to the second Saturday of December of the following year, is called normative or basic. It is it, as a rule, that is hung out on large stands at stations and platforms; it is it that is printed in books that can be bought at the box office at a number of stations.
At the same time, most passengers of large railway junctions (for example, Moscow) know that in areas with heavy traffic there is little sense in the base schedule. The fact is that the railway regularly needs to carry out repairs, which in most cases cannot be carried out without partially closing the movement of trains. And then JSC Russian Railways develops a variant train schedule, providing, for example, alternate train movements along one track in both directions on one of the stages. In other words, temporary changes are made to the base schedule. And such changes are made to the schedule constantly, and not only due to repair work.
Before the advent of online resources with a schedule, it was possible to learn about temporary changes mainly only from announcements at stations. Moreover, the announcement is not a schedule for a specific day, but, as a rule, an A4 leaflet with changes to the base schedule. And there could be several such leaflets for one day. For example, according to one of them, the electric train went at 15:50 instead of 15:30, on the other, the same train went with a number of stops, and on the third - with changes to late evening, where few people watched (for example, the electric train started, which went at 15:40 instead of 22:00). By the way, many stations still have such announcements. An example from life can serve as an illustration: once my colleague from Tutu.ru decided to go from Moscow to the Rzhevsky district with a change, he took an electric train from Moscow to Volokolamsk and found out
With the advent of online resources, it’s become much easier to find out the schedule - just go to the website or mobile application , enter the departure and destination stations, date, and the system will show which trains will be on that day, taking into account all planned temporary changes known to date . No need to study a bunch of pieces of paper with changes. And Tutu.ru became the first online resource in Russia, on which back in 2003, not only the basic schedule, but also temporary changes began to be published.
Creating such a resource and keeping the schedule up to date was not easy. The changes had to be monitored manually: the creators of the service themselves traveled to stations, took pictures and rewritten the schedule and announcements. It is clear that it was physically impossible to go around all-all stations, so changes to the schedule were made with inaccuracies. And here our users helped a lot - they wrote and called Tutu.ru, provided us with first-hand information.
But still there were errors in the schedule, so we began to look for additional sources of information. So, shortly after the advent of suburban passenger companies (PPC), which were also interested in correctly informing passengers about the schedule, we agreed with them to receive data on the schedule and changes to it for all trains at all stations. The appearance of this source of information has significantly improved the quality of the schedule. If back in 2005, almost every user encountered at least one error on the site, then after 10 years the vast majority of users always saw an accurate and reliable schedule.
Since errors in the data from the control panel, although rare, occur, and our operators also sometimes make mistakes, we did not stop and connected another source - the Central database of the suburban schedule of the Main Computing Center of Russian Railways , to which the employees of Russian Railways make the schedule of suburban trains and changes to it throughout Russia.
Now on Tutu.ru you can find information about timetables, routes and schedules of electric trains for 17 “regions” (conditional breakdown of the territory, approximately according to the limits of responsibility of the relevant control centers). Tutu.ru receives the data of the main schedule before putting it into effect, as well as information about temporary changes in the schedule (options for the movement of trains on specific days).
This information gets into our database by operators who, in semi-manual mode, enter it through the interface. In those areas with which we do not have partnerships, specialists manually browse schedule sites and enter data manually. This approach requires a lot of labor and can lead to errors, as a result of which our schedule does not completely coincide with the real one.
When we decided to connect the MCC database, we did not know exactly how to use it. It was originally supposed to be an additional data source for obtaining more data, possibly more accurate. It was known that some of the details in the timetable model here and in the GVC system are different: for example, the train moves along one route, reaches the end station, stands at this station for some time, then it changes its number and it continues to move on, but on a different schedule and route. As a rule, in the MCC system these two trains appear as different, and on the Russian Railways website there will be no such train in the schedule from the station from the first section to the station from the second. We have such situations handled individually, and if you have confidence, Since this structure simply stands at the station and then continues to move on, changing the number, it starts up as one object. It will have a composite number — the numbers of the original trains indicated through the “/” separator — and this train will be present as a result of the search for trains between stations from different sections.
Changes that are sent from some control stations (for example, CPPC or SZ PPK) to partners / subscribers do not contain data about all stops of the electric train, but only about individual points (railway station, checkpoint, road crossing, waypoint, etc.), and the time it takes for the train to go through intermediate points (such as a stopping point, platform, and others), at which it nonetheless stops, each partner calculates in his own way.
Consider an example: the electric train No. 6600 in the Riga direction, according to the usual schedule, follows daily and has stops in Nakhabino at 5:04, Opaliha 5:10, Krasnogorsk 5:14, Pavshino 5:18 onwards. On July 9, the train’s schedule changes and information comes from the carrier’s company that the train will leave Nakhabino at 4:57, and Pavshino will continue to operate according to the standard schedule.
The data in the MCC are as follows: at Nakhabino and Pavshino stations, 4:57 and 5:18, respectively, are entered, and the transit time of the intermediate stations is calculated in proportion to the initial walking schedule, i.e., in the ratio of 6: 4: 4 (as if the train was in this section goes slower) and it turns out that the stop in Opaliha is postponed to 5:06, and the train will go to the Krasnogorsk station at 5:12. For a long time, the calculation algorithm on the Tutu.ru website was similar, and in 99% of cases the train will have just such a movement. But there were cases when the cause of the change disappeared (for example, repair) and the train moved in the area at the usual speed. In our example, this would mean that she would have reached Opaliha in 6 minutes (5:03), then to Krasnogorsk in 4 minutes (5:07), and to Pavshino in 4 minutes (5:11). Then, to follow the schedule,
What would this mean for users? A user who arrived at the Krasnogorskaya station at 5:10 would end up waiting for the next train. Because of such cases, the time for stopping points at which the exact time is not known on the Tutu.ru website is now entered using an algorithm different from the MCC. The time is calculated on the basis of the initial schedule of movement or, in general, the minimum transit time of the train between given stations. We give the user, with a high degree of probability, the time is less by a few minutes than the train will go. It’s better to come to the platform a couple of minutes earlier than a couple of minutes later.
In addition, errors related to the human factor that were made when making the schedule in the MCC system were noticed. For these and other reasons, it was decided that directly importing data from the MCC is undesirable. Instead, it is more important to find out how the data stored in the MCC and ours differs. Based on these data, as well as on the basis of other sources (including actual inspections of trains at stations in difficult cases), specialists will decide which data is “more accurate” (or will be more useful to users).
But before you compare something, you need to establish at least some kind of connection between the objects. Initially, we had neither train correspondences nor station correspondences and there were no fields by which this correspondence could be strictly established. About 25 thousand objects of stations and 15 thousand objects of trains were found in the MCC base, which made it difficult to search for relevant trains “head-on”, that is, by searching and comparing each station with each station and each train with each train.
Given the possible discrepancies described above in the algorithm for populating the models, the comparison would have to be fuzzy. This means that we would not look for the exact equality of objects, but objects with slight differences in one of the data fields, for example, the difference in departure time by 2-3 minutes on one of the dates. Fuzzy comparison is a rather expensive action, and given the fact that pairs of objects for comparison would be hundreds of millions, such a method would not produce results in a reasonable amount of time. And in the end, there would be few established correspondences, because initially all the features were not known.
This was done in several stages and several passes. The first step was to establish correspondence between the objects of the stations. According to the identifiers that we had and in the MCC database, it was not possible to unambiguously establish compliance. For example, in Russia there are 9 stopping points “105 KM” and 17 stopping points “106 KM”. So, comparing the names was not very effective: there were about 10% of stations with unique names for which it was possible to find unique stations in the MCC base.
In this regard, our schedule database specialist Aleksey Derkachev helped a lot, who somewhere dug up the correspondence between the seven-digit codes of Express-3 stations (which we widely use as one of the station identifiers) and the station code from the MCC database. Using this table, we managed to find a pair for about half of the stations that we participate in train schedules. After it was possible to compare at least such a number of stations, it was possible to proceed to the next stage: try to find the same trains.
To do this, an automatic script went through all the pairs of stations found and made a selection of train schedules for a particular station. Next, each set of received trains was compared, and when finding the exact match (i.e. the number of stations on the route is the same, the arrival / departure times of the train at each station are the same, the train number is similar, the weekly schedule is the same), duplicates were deleted and in our schedule there was only one train.
Thus, for some of the trains it was possible to find pairs. After the correspondence between the trains was established, it was possible to return to the stations again - to go through the pairs of trains found and, since they are the same, then the stations in the route are most likely the same. This gave some more matching stations. After which it was possible again to try to look for matching trains. Along the way, it was possible to experiment with different search parameters, different assumptions, take into account more and more new features of the formation and storage of the schedule. After a dozen iterations, the correspondence database could already be used.
Schedule data of trains change quite often: hundreds of changes are made per day, and before the start and end of the summer season, changes can reach several thousand per day. In addition, changes do not always simultaneously fall both in our database and in the MCC database, all the more so according to the rules of interaction, we can upload data updates only at a certain time twice a day. And experts can enter data into their database around the clock.
Each time, reconciling all trains is quite time-consuming operation, comparison criteria may change (for example, part of the discrepancies in one minute may be considered insignificant and you may not pay attention to these discrepancies) and the data itself may change during this time, new trains may be added for which no matches have yet been found. Our customers help us find the discrepancies. Every second, an average of 10 schedule searches occur on the site.
For each search in the background, data from a local copy of the MCC data is requested and a comparison is made. If the trains are similar (by number, weekly schedule and transit time of the station), but there is no match for them, then it is installed. If there is a match, but the data diverge, then the found discrepancy is saved. And in the future, schedule specialists will be able to look at the general list of discrepancies, discrepancies for a specific pair of trains and find out why the data diverge, and then decide whether to change them on our website or not.
At the moment, the whole system is still being finalized, both in terms of comparing models, and in terms of display convenience and working with it, because there are a lot of discrepancies, most of them are insignificant and do not need to be shown in the first place. Differences between models and used scheduling principles can affect the accuracy of comparisons.
A few years ago in our company, thanks to the DevOps team, it became possible to create microservices. It became possible to implement new functionality separately from the monolith in its service.
So there was a microservice that stores all the data of schedules from the MCC in the same format that the database responds to and implements APIs that respond to search queries (where-to-date, station schedule, and the route of a specific electric train). This is a microservice that responds to search queries with data from our repository, compares two data sets, stores data about discrepancies in models.
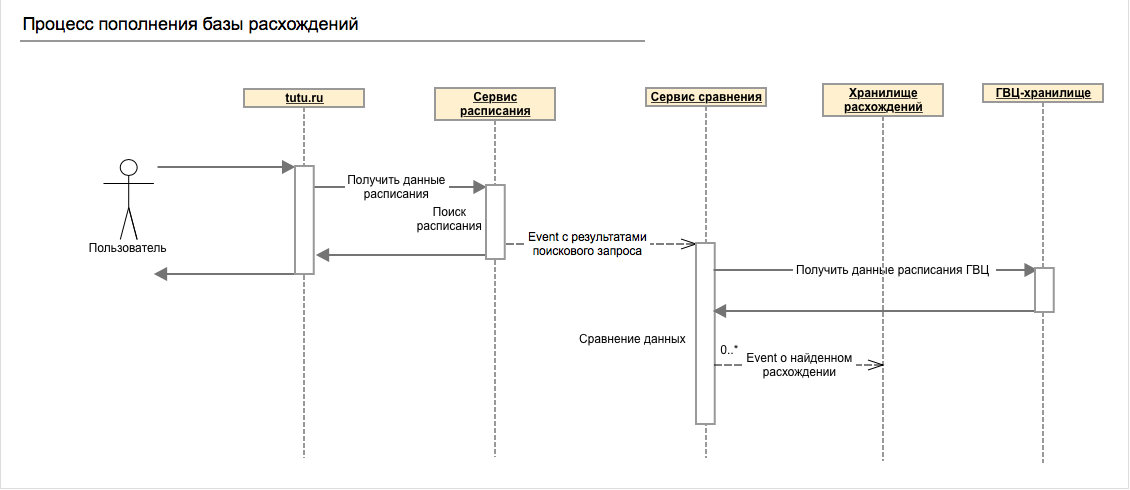
When searching for trains on any route on the site, the schedule service is called, and before returning the result, an event with the calculated data is sent to the bus from it. The comparison service listens for these events, when receiving data, requests the same data from the data storage service from the MCC and compares the two sets received.
If there is a discrepancy in data on trains with already established connections, then another event is generated about this, which is listened to in the non-conformance storage service. If for some trains there is no connection, but according to the data it can be seen that they are very similar, then they are connected.
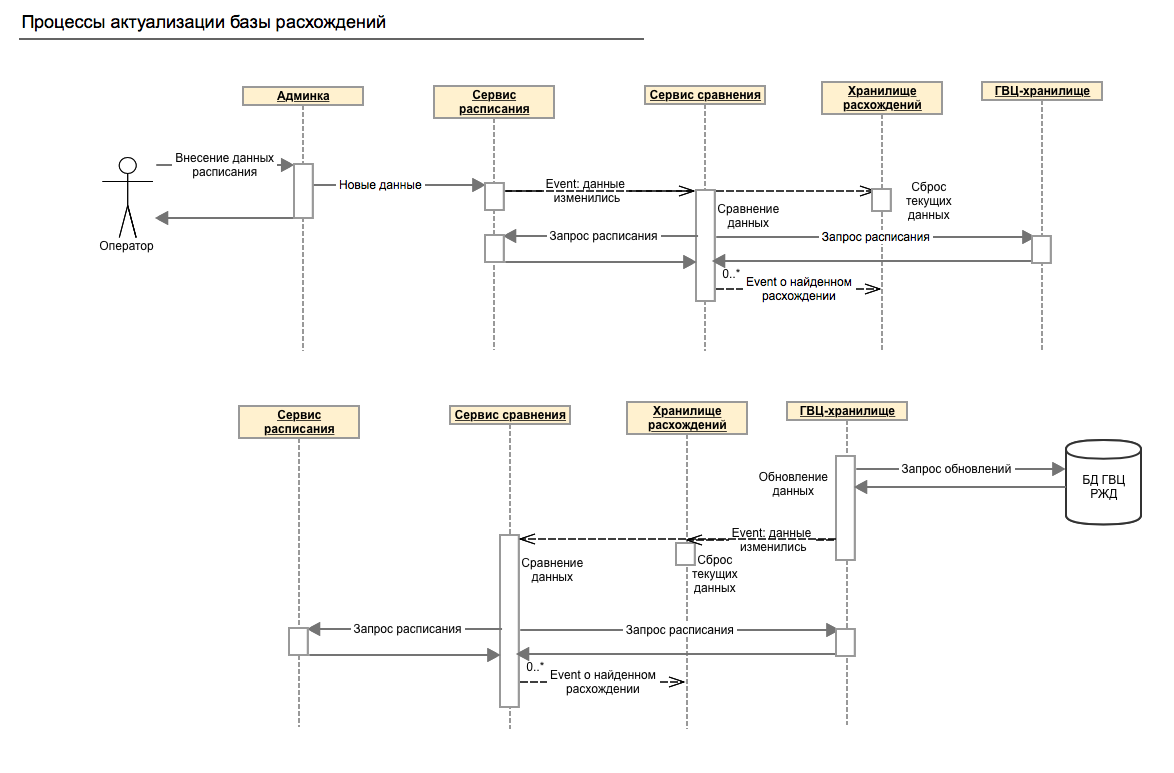
The system does not stand still and we are constantly developing it. There are still differences in the methods of generating and filling out the schedule data models. Because of them, a significant number of entries accumulate in the final list of differences, which do not need to be taken into account, which greatly complicates the orientation in it and, as a result, it is more difficult to respond to problems. But we are working on it.
We continue to work on the automatic installation of correspondences between the facilities of stations and trains. The "Electric Train Team" is constantly working to improve the service so that it is convenient for you to use it.
In the next article I plan to tell in detail about the structure of models, I will dwell in more detail on the algorithm for their comparison. In addition, I will describe the differences identified and how the system evolves based on them. If you have questions about the topic of the article or suggestions and wishes on the product itself , then be sure to write.
The availability, accessibility and accuracy of the timetable for electric trains excites every passenger, and for those who shape it and convey it to people, it is an important and very difficult task.
My name is Alexander Podlevskikh, I’m the lead development engineer for Tutu.ru, a team leader in the electric train, and in the article I’ll talk about the technical details and the difficulties of building an online schedule, how it all works, how we use the data provided by Russian Railways, and how our users help us keep the schedule up to date without realizing it.
The train schedule is a display of the process of train movement in a Cartesian coordinate system. In this form, the train schedule on the railway is presented.
In Russia there are about 30 suburban passenger companies (PPC), each of which is responsible for passenger service in a certain territory. On the basis of the transport order of the regions, the wishes of passengers and studies, each PPC forms proposals for changing the schedule, which are sent to JSC Russian Railways once a year (around the beginning of summer).
Having received applications for the schedule of electric trains, passenger and freight trains, Russian Railways, within a few months, develops a new train schedule (new schedule) and puts it into effect at the end of the year. Such a schedule, valid from the second Sunday of December of each year to the second Saturday of December of the following year, is called normative or basic. It is it, as a rule, that is hung out on large stands at stations and platforms; it is it that is printed in books that can be bought at the box office at a number of stations.
At the same time, most passengers of large railway junctions (for example, Moscow) know that in areas with heavy traffic there is little sense in the base schedule. The fact is that the railway regularly needs to carry out repairs, which in most cases cannot be carried out without partially closing the movement of trains. And then JSC Russian Railways develops a variant train schedule, providing, for example, alternate train movements along one track in both directions on one of the stages. In other words, temporary changes are made to the base schedule. And such changes are made to the schedule constantly, and not only due to repair work.
Before the advent of online resources with a schedule, it was possible to learn about temporary changes mainly only from announcements at stations. Moreover, the announcement is not a schedule for a specific day, but, as a rule, an A4 leaflet with changes to the base schedule. And there could be several such leaflets for one day. For example, according to one of them, the electric train went at 15:50 instead of 15:30, on the other, the same train went with a number of stops, and on the third - with changes to late evening, where few people watched (for example, the electric train started, which went at 15:40 instead of 22:00). By the way, many stations still have such announcements. An example from life can serve as an illustration: once my colleague from Tutu.ru decided to go from Moscow to the Rzhevsky district with a change, he took an electric train from Moscow to Volokolamsk and found out
With the advent of online resources, it’s become much easier to find out the schedule - just go to the website or mobile application , enter the departure and destination stations, date, and the system will show which trains will be on that day, taking into account all planned temporary changes known to date . No need to study a bunch of pieces of paper with changes. And Tutu.ru became the first online resource in Russia, on which back in 2003, not only the basic schedule, but also temporary changes began to be published.
Creating such a resource and keeping the schedule up to date was not easy. The changes had to be monitored manually: the creators of the service themselves traveled to stations, took pictures and rewritten the schedule and announcements. It is clear that it was physically impossible to go around all-all stations, so changes to the schedule were made with inaccuracies. And here our users helped a lot - they wrote and called Tutu.ru, provided us with first-hand information.
But still there were errors in the schedule, so we began to look for additional sources of information. So, shortly after the advent of suburban passenger companies (PPC), which were also interested in correctly informing passengers about the schedule, we agreed with them to receive data on the schedule and changes to it for all trains at all stations. The appearance of this source of information has significantly improved the quality of the schedule. If back in 2005, almost every user encountered at least one error on the site, then after 10 years the vast majority of users always saw an accurate and reliable schedule.
Since errors in the data from the control panel, although rare, occur, and our operators also sometimes make mistakes, we did not stop and connected another source - the Central database of the suburban schedule of the Main Computing Center of Russian Railways , to which the employees of Russian Railways make the schedule of suburban trains and changes to it throughout Russia.
How Tutu.ru service maintains the relevance of the schedule
Now on Tutu.ru you can find information about timetables, routes and schedules of electric trains for 17 “regions” (conditional breakdown of the territory, approximately according to the limits of responsibility of the relevant control centers). Tutu.ru receives the data of the main schedule before putting it into effect, as well as information about temporary changes in the schedule (options for the movement of trains on specific days).
This information gets into our database by operators who, in semi-manual mode, enter it through the interface. In those areas with which we do not have partnerships, specialists manually browse schedule sites and enter data manually. This approach requires a lot of labor and can lead to errors, as a result of which our schedule does not completely coincide with the real one.
When we decided to connect the MCC database, we did not know exactly how to use it. It was originally supposed to be an additional data source for obtaining more data, possibly more accurate. It was known that some of the details in the timetable model here and in the GVC system are different: for example, the train moves along one route, reaches the end station, stands at this station for some time, then it changes its number and it continues to move on, but on a different schedule and route. As a rule, in the MCC system these two trains appear as different, and on the Russian Railways website there will be no such train in the schedule from the station from the first section to the station from the second. We have such situations handled individually, and if you have confidence, Since this structure simply stands at the station and then continues to move on, changing the number, it starts up as one object. It will have a composite number — the numbers of the original trains indicated through the “/” separator — and this train will be present as a result of the search for trains between stations from different sections.
Changes that are sent from some control stations (for example, CPPC or SZ PPK) to partners / subscribers do not contain data about all stops of the electric train, but only about individual points (railway station, checkpoint, road crossing, waypoint, etc.), and the time it takes for the train to go through intermediate points (such as a stopping point, platform, and others), at which it nonetheless stops, each partner calculates in his own way.
Consider an example: the electric train No. 6600 in the Riga direction, according to the usual schedule, follows daily and has stops in Nakhabino at 5:04, Opaliha 5:10, Krasnogorsk 5:14, Pavshino 5:18 onwards. On July 9, the train’s schedule changes and information comes from the carrier’s company that the train will leave Nakhabino at 4:57, and Pavshino will continue to operate according to the standard schedule.
The data in the MCC are as follows: at Nakhabino and Pavshino stations, 4:57 and 5:18, respectively, are entered, and the transit time of the intermediate stations is calculated in proportion to the initial walking schedule, i.e., in the ratio of 6: 4: 4 (as if the train was in this section goes slower) and it turns out that the stop in Opaliha is postponed to 5:06, and the train will go to the Krasnogorsk station at 5:12. For a long time, the calculation algorithm on the Tutu.ru website was similar, and in 99% of cases the train will have just such a movement. But there were cases when the cause of the change disappeared (for example, repair) and the train moved in the area at the usual speed. In our example, this would mean that she would have reached Opaliha in 6 minutes (5:03), then to Krasnogorsk in 4 minutes (5:07), and to Pavshino in 4 minutes (5:11). Then, to follow the schedule,
What would this mean for users? A user who arrived at the Krasnogorskaya station at 5:10 would end up waiting for the next train. Because of such cases, the time for stopping points at which the exact time is not known on the Tutu.ru website is now entered using an algorithm different from the MCC. The time is calculated on the basis of the initial schedule of movement or, in general, the minimum transit time of the train between given stations. We give the user, with a high degree of probability, the time is less by a few minutes than the train will go. It’s better to come to the platform a couple of minutes earlier than a couple of minutes later.
In addition, errors related to the human factor that were made when making the schedule in the MCC system were noticed. For these and other reasons, it was decided that directly importing data from the MCC is undesirable. Instead, it is more important to find out how the data stored in the MCC and ours differs. Based on these data, as well as on the basis of other sources (including actual inspections of trains at stations in difficult cases), specialists will decide which data is “more accurate” (or will be more useful to users).
But before you compare something, you need to establish at least some kind of connection between the objects. Initially, we had neither train correspondences nor station correspondences and there were no fields by which this correspondence could be strictly established. About 25 thousand objects of stations and 15 thousand objects of trains were found in the MCC base, which made it difficult to search for relevant trains “head-on”, that is, by searching and comparing each station with each station and each train with each train.
Given the possible discrepancies described above in the algorithm for populating the models, the comparison would have to be fuzzy. This means that we would not look for the exact equality of objects, but objects with slight differences in one of the data fields, for example, the difference in departure time by 2-3 minutes on one of the dates. Fuzzy comparison is a rather expensive action, and given the fact that pairs of objects for comparison would be hundreds of millions, such a method would not produce results in a reasonable amount of time. And in the end, there would be few established correspondences, because initially all the features were not known.
Matching station and train facilities
This was done in several stages and several passes. The first step was to establish correspondence between the objects of the stations. According to the identifiers that we had and in the MCC database, it was not possible to unambiguously establish compliance. For example, in Russia there are 9 stopping points “105 KM” and 17 stopping points “106 KM”. So, comparing the names was not very effective: there were about 10% of stations with unique names for which it was possible to find unique stations in the MCC base.
In this regard, our schedule database specialist Aleksey Derkachev helped a lot, who somewhere dug up the correspondence between the seven-digit codes of Express-3 stations (which we widely use as one of the station identifiers) and the station code from the MCC database. Using this table, we managed to find a pair for about half of the stations that we participate in train schedules. After it was possible to compare at least such a number of stations, it was possible to proceed to the next stage: try to find the same trains.
To do this, an automatic script went through all the pairs of stations found and made a selection of train schedules for a particular station. Next, each set of received trains was compared, and when finding the exact match (i.e. the number of stations on the route is the same, the arrival / departure times of the train at each station are the same, the train number is similar, the weekly schedule is the same), duplicates were deleted and in our schedule there was only one train.
Thus, for some of the trains it was possible to find pairs. After the correspondence between the trains was established, it was possible to return to the stations again - to go through the pairs of trains found and, since they are the same, then the stations in the route are most likely the same. This gave some more matching stations. After which it was possible again to try to look for matching trains. Along the way, it was possible to experiment with different search parameters, different assumptions, take into account more and more new features of the formation and storage of the schedule. After a dozen iterations, the correspondence database could already be used.
Continuous Schedule Discrepancy Search
Schedule data of trains change quite often: hundreds of changes are made per day, and before the start and end of the summer season, changes can reach several thousand per day. In addition, changes do not always simultaneously fall both in our database and in the MCC database, all the more so according to the rules of interaction, we can upload data updates only at a certain time twice a day. And experts can enter data into their database around the clock.
Each time, reconciling all trains is quite time-consuming operation, comparison criteria may change (for example, part of the discrepancies in one minute may be considered insignificant and you may not pay attention to these discrepancies) and the data itself may change during this time, new trains may be added for which no matches have yet been found. Our customers help us find the discrepancies. Every second, an average of 10 schedule searches occur on the site.
For each search in the background, data from a local copy of the MCC data is requested and a comparison is made. If the trains are similar (by number, weekly schedule and transit time of the station), but there is no match for them, then it is installed. If there is a match, but the data diverge, then the found discrepancy is saved. And in the future, schedule specialists will be able to look at the general list of discrepancies, discrepancies for a specific pair of trains and find out why the data diverge, and then decide whether to change them on our website or not.
At the moment, the whole system is still being finalized, both in terms of comparing models, and in terms of display convenience and working with it, because there are a lot of discrepancies, most of them are insignificant and do not need to be shown in the first place. Differences between models and used scheduling principles can affect the accuracy of comparisons.
Technical implementation
A few years ago in our company, thanks to the DevOps team, it became possible to create microservices. It became possible to implement new functionality separately from the monolith in its service.
So there was a microservice that stores all the data of schedules from the MCC in the same format that the database responds to and implements APIs that respond to search queries (where-to-date, station schedule, and the route of a specific electric train). This is a microservice that responds to search queries with data from our repository, compares two data sets, stores data about discrepancies in models.
Replenishment of the discrepancy base
When searching for trains on any route on the site, the schedule service is called, and before returning the result, an event with the calculated data is sent to the bus from it. The comparison service listens for these events, when receiving data, requests the same data from the data storage service from the MCC and compares the two sets received.
If there is a discrepancy in data on trains with already established connections, then another event is generated about this, which is listened to in the non-conformance storage service. If for some trains there is no connection, but according to the data it can be seen that they are very similar, then they are connected.
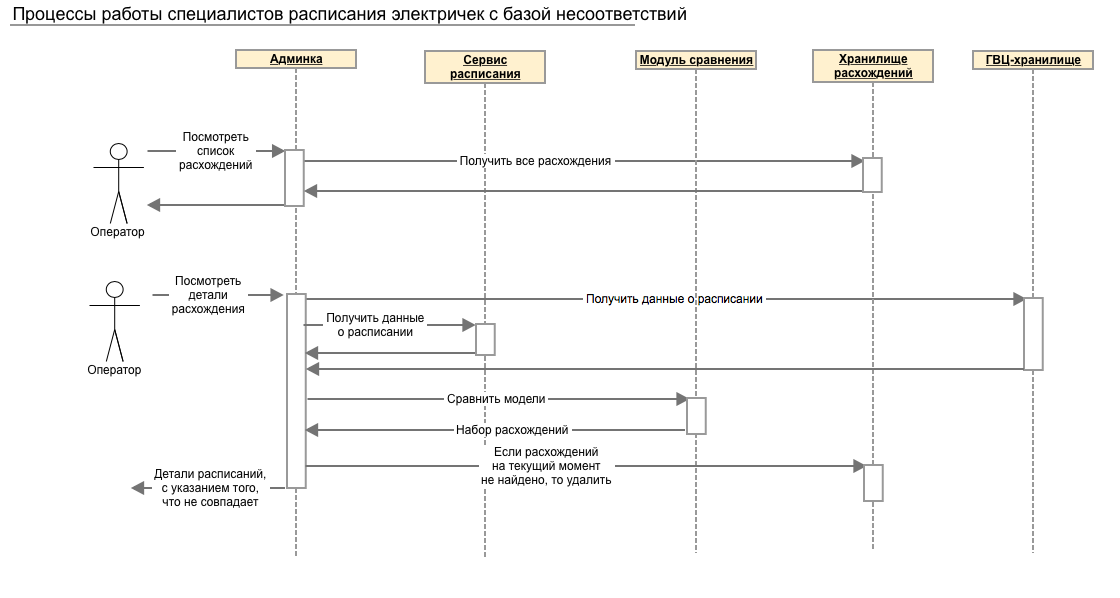
The processes of work of specialists in the schedule of electric trains with a database of inconsistencies
Processes for updating these discrepancies
Conclusion
The system does not stand still and we are constantly developing it. There are still differences in the methods of generating and filling out the schedule data models. Because of them, a significant number of entries accumulate in the final list of differences, which do not need to be taken into account, which greatly complicates the orientation in it and, as a result, it is more difficult to respond to problems. But we are working on it.
We continue to work on the automatic installation of correspondences between the facilities of stations and trains. The "Electric Train Team" is constantly working to improve the service so that it is convenient for you to use it.
In the next article I plan to tell in detail about the structure of models, I will dwell in more detail on the algorithm for their comparison. In addition, I will describe the differences identified and how the system evolves based on them. If you have questions about the topic of the article or suggestions and wishes on the product itself , then be sure to write.