How HBO made the Not Hotdog app for Silicon Valley
- Transfer

The Silicon Valley HBO series has released a real AI application that recognizes hot dogs and non-hot dogs as an application in the fourth episode of the fourth season (the application is now available for Android, as well as for iOS !)
To achieve this, we developed a special neural architecture that works directly on your phone, and trained it using TensorFlow, Keras and Nvidia GPU.
Although its practical use is ludicrous, the application is an affordable example of both deep learning and edge computing. All AI work is 100% provided by the user device, and images are processed without leaving the phone. This gives an instant response (no need to exchange data with the cloud), offline availability and better privacy. It also allows us to keep the app running for $ 0, even with millions of users, which represents a significant cost savings over traditional cloud-based AI approaches.

Developer's computer with an eGPU connected for learning Not Hotdog AI applications
The application was developed by a film studio specifically for the series by one developer, on the same laptop with a connected GPU, using manually selected data. In this regard, it can serve as a demonstration of what can be achieved today with limited time and resources, a non-technical company, individual developers, and the like amateurs. In this spirit, this article attempts to provide a detailed overview of the steps that others can repeat to create their own applications.
application
If you did not watch the series and did not test the application (and it should!), It takes a photo, and then expresses its opinion to you whether the hot dog is shown on the photo or not. This is a straightforward use that pays tribute to the latest AI research and applications, in particular ImageNet.
Although we probably allocated more programmer resources for recognizing hot dogs than anyone in the world, the application is still sometimes mistaken in a terrible and / or sophisticated way.
And vice versa, at times it can recognize hot dogs in difficult situations ... As Engadget writes , “This is unbelievable. In 20 minutes, I successfully recognized more food with this application than I tagged and recognized songs with Shazam in the last two years. ”
From prototype to production
Ever read the Hacker News, you caught yourself thinking: “They raised $ 10 million in the first round for this? I can develop this over the weekend! ”This app is likely to make you feel the same way. In the end, the initial prototype was indeed created over the weekend using the Google Cloud Platform Vision API and React Native. But to create the final version of the application, which eventually entered the application directory, it took months of additional work (several hours a day) to make meaningful improvements that are difficult to evaluate from the outside. We spent weeks optimizing overall accuracy, training time, analysis time, we tried different settings and tools to speed up development, and spent the whole weekend optimizing the user interface taking into account iOS and Android permissions (don’t even start talking about this topic).
Too often, technical blogs and scientific articles skip this part, preferring to immediately show the final version. But in order to help others learn from our mistakes and actions, we will present an abridged list of approaches that did not work for us before we describe the final architecture that we arrived at.
V0: Prototype

An example of the image and the corresponding API output from the Google Cloud Vision documentation
We chose React Native to create the prototype because it provides a simple sandbox for experiments and helps to quickly provide support for many devices. The experience was successful, and we left React Native until the end of the project: it did not always simplify the process, and the application design had to be deliberately limited, but in the end React Native did its job.
From another main component that was used for the prototype - Google Cloud Vision API - we quickly refused. There are three main reasons:
- The first, and most important, is that the recognition accuracy of hot dogs was not very good. Although it does a great job of recognizing a wide variety of objects, it doesn’t recognize one particular thing very well, and there were various examples of a fairly general nature where the service performed poorly during our experiments in 2016.
- By its nature, a cloud service will always be slower than native execution on the device (the network lag hurts!), And does not work offline. The idea of transferring images outside the device potentially has legal and privacy implications.
- In the end, if the application becomes popular, then work on Google Cloud can cost a pretty penny.
For this reason, we started experimenting with what is popularly called “edge computing”. In our case, this means that after training our neural network on a laptop, we will transfer it directly to the mobile application, so that the execution phase of the neural network (or the conclusion of the conclusion) will be performed directly on the user's phone.
V1: TensorFlow, Inception, and Retraining
Thanks to a happy meeting with Pete Warden from the TensorFlow development team, we learned that you can run TensorFlow directly by integrating it into your iOS device, and started experimenting in this direction. After React Native, TensorFlow became the second integral part of our stack.
It took only one day to integrate the TensorFlow's Objective-C ++ camera example into our React Native shell. It took a lot longer to learn a script for learning, which helps retrain the Inception architecture to work with more specific machine vision tasks. Inception is the name of the family of neural architectures Google created for image recognition. Inception is available as a pre-trained system, that is, the training phase is completed and the weights are set. Most often, image recognition neural networks are trained on ImageNet, the annual competition for the search for the best neural architecture, which recognizes more than 20,000 different types of objects (and hot dogs among them). However, like the Google Cloud Vision API, the competition encourages the largest possible number of recognizable objects, and the initial accuracy for one particular object of more than 20,000 is not very high. For this reason, retraining (also called “transfer learning,” “transfer learning”) aims to take a fully trained neural network and retrain it to better complete the specific task you are working with. This usually involves some degree of “forgetting” either by excising entire layers from the stack, or by slowly erasing the ability of a neural network to distinguish between individual types of objects (for example, chairs) for the sake of more accuracy in recognizing the object that you need (for example, hot dogs). to take a fully trained neural network and retrain it to better complete the specific task you are working with. This usually involves some degree of “forgetting” either by excising entire layers from the stack, or by slowly erasing the ability of a neural network to distinguish between individual types of objects (for example, chairs) for the sake of more accuracy in recognizing the object that you need (for example, hot dogs). to take a fully trained neural network and retrain it to better complete the specific task you are working with. This usually involves some degree of “forgetting” either by excising entire layers from the stack, or by slowly erasing the ability of a neural network to distinguish between individual types of objects (for example, chairs) for the sake of more accuracy in recognizing the object that you need (for example, hot dogs).
Although the neural network (in this case Inception) could be trained on 14 million ImageNet images, we were able to retrain it on just a few thousand photos of hot dogs in order to dramatically improve the recognition of hot dogs.
The big advantage of transferring training is that you get better results much faster and with less data than if you trained a neural network from scratch. Full training could take several months on multiple GPUs and would require millions of images, while retraining can presumably be done in a few hours on a laptop with a couple of thousand photos.
One of the most difficult tasks that we faced was the exact definition of what to consider a hot dog and what not. The definition of “hot dog” turned out to be surprisingly complex (are cut sausages considered, and if so, what species?) And subject to cultural interpretation.
Similarly, the nature of the “open world” of our problem meant that we would have to deal with an almost infinite amount of input. Some computer vision tasks deal with a relatively limited set of input data (for example, x-rays of bolts with mechanical defects or without defects), but we had to prepare an application for processing selfies, nature images and a wide variety of dishes.
It is enough to say that this approach was promising and led to some improvement in the results, but it had to be abandoned for a number of reasons.
First, the nature of our task meant a strong imbalance in the data for training: there are many more examples of what are not hot dogs than the hot dogs themselves. In practice, this means that if you train your algorithm on three images of hot dogs and 97 images that are not hot dogs, and it recognizes 0% of the first and 100% of the second, then you get a nominal accuracy of 97%! This problem is not directly addressed by the TensorFlow retraining tool and essentially forces us to establish a deep learning model from scratch, import weights and conduct training in a more controlled way.
At this point, we decided to bite the bullet and start working with Keras, a deep learning library that provides better, easier-to-use abstractions on top of TensorFlow, including some pretty cool learning tools, as well as the class_weights option, which is perfect for solving this kind of problem. with an unbalanced dataset like ours.
We used this opportunity to test other neural architectures such as VGG, but there was one problem. None of them provided comfortable work on the iPhone. They consumed too much memory, which led to application crashes, and sometimes took up to 10 seconds to produce the result, which is not ideal from the point of view of UX. We tried a lot to solve the problem, but in the end we recognized that these architectures are too bulky to work on a mobile device.
V2: Keras and SqueezeNet

SqueezeNet vs. AlexNet, the grandfather of computer vision architectures. Source: SqueezeNet scientific article.
To give you the context where we are, is about halfway in the history of the project. By this time, the UI was more than 90% ready, very little remained to be changed. But now it is clear that the neural network was at best 20% ready. We had a good understanding of the problems and a good data set, but 0 lines of code of the finished neural architecture were written, none of our code could work reliably on a mobile phone, and even the accuracy will subsequently be radically improved.
The problem immediately before us was simple: if Inception and VGG are too bulky, is there a simpler, pre-trained neural network that we can retrain? On a tip from the always-awesome Jeremy Howard (where was this guy our whole life?) We tried Xception, Enet and SqueezeNet. Very quickly, we decided on SqueezeNet due to the explicit positioning of this system as a solution for embedded deep learning systems and due to the availability of the pre-trained Keras model on GitHub (hurray, open-source).
So how big is the difference? An architecture like VGG uses about 138 million parameters (essentially, this is the number of numbers needed to model the neurons and the values between them). Inception represents significant progress, requiring a total of 23 million parameters. For comparison, SqueezeNet works with 1.25 million parameters.
This has two advantages:
- At the training stage, a smaller neural network is trained much faster. There are fewer parameters for placement in memory, so you can parallelize training a little better (large packet sizes), and the neural network will converge faster (i.e., approach an idealized mathematical function).
- In production, the model is much smaller and much faster. SqueezeNet consumes less than 10 MB of RAM, while architectures like Inception require 100 MB or more. The difference is huge, and it is especially important when working on mobile devices that may have less than 100 MB of available memory for your application. Smaller neural networks also compute the final result much faster than larger ones.
Of course, I had to sacrifice something:
- A smaller neural network architecture has less “memory” available: it will not be as effective in complex situations (such as recognizing 20,000 different objects) or even in handling complex situations in a narrow class of tasks (for example, to understand the difference between hot dogs in New York style and chicago style). As a result, smaller neural networks typically exhibit less accuracy than large networks. When trying to recognize 20,000 ImageNet objects, SqueezeNet shows a recognition accuracy of only 58%, while VGG has a 72% recognition rate.
- A small neural network is more difficult to retrain. Technically, nothing prevents us from using the same approach as in the case of Inception and VGG to make SqueezeNet “forget” something and retrain it specifically to distinguish between hot dogs and non-hot dogs. In practice, we had difficulty adjusting the pace of learning, and the results were always less satisfactory than learning SqueezeNet from scratch. It may also be partially due to the nature of the “open world” of our mission.
- Theoretically, smaller neural networks rarely need to retrain, but we have come across this on several “small” architectures. Overfit means that your network specializes too much, and instead of learning to recognize hot dogs in general, it learns to recognize exactly and only specific photos of the hot dogs in which you trained it. A human analogy would be to remember specific photos with hot dogs that show you, instead of abstraction, that a hot dog usually consists of a sausage in a bun, possibly with seasonings, etc. If you are shown a completely new image of a hot dog, and not what you remember, then you will be inclined to say that it is not a hot dog. Due to the fact that small networks usually have less “memory”, it is easy to understand why it is more difficult for them to specialize. But in some cases, the accuracy of our small networks jumped up to 99% and suddenly it stopped recognizing images that it had not seen at the training stage. The effect usually disappeared when we added augmented data: semi-random stretched / distorted images at the input, and instead of 1.00 times on each of the 1000 images, learning on a certain way changed variations of a thousand images to reduce the likelihood of a neural network memorizing specifically this 1000 images. Instead, it should recognize the “signs” of a hot dog (bun, sausage, seasonings, etc.), while remaining flexible and general enough not to be too attached to the specific pixel values of specific images in the training set. which I did not see at the training stage. The effect usually disappeared when we added augmented data: semi-random stretched / distorted images at the input, and instead of 1.00 times on each of the 1000 images, learning on a certain way changed variations of a thousand images to reduce the likelihood of a neural network memorizing specifically this 1000 images. Instead, it should recognize the “signs” of a hot dog (bun, sausage, seasonings, etc.), while remaining flexible and general enough not to be too attached to the specific pixel values of specific images in the training set. which I did not see at the training stage. The effect usually disappeared when we added augmented data: semi-random stretched / distorted images at the input, and instead of 1.00 times on each of the 1000 images, learning on a certain way changed variations of a thousand images to reduce the likelihood of a neural network memorizing specifically this 1000 images. Instead, it should recognize the “signs” of a hot dog (bun, sausage, seasonings, etc.), while remaining flexible and general enough not to be too attached to the specific pixel values of specific images in the training set. 00 times, in each of the 1000 images, learning on a certain way changed variations of a thousand images in order to reduce the likelihood of a neural network memorizing specifically this 1000 images. Instead, it should recognize the “signs” of a hot dog (bun, sausage, seasonings, etc.), while remaining flexible and general enough not to be too attached to the specific pixel values of specific images in the training set. 00 times, in each of the 1000 images, learning on a certain way changed variations of a thousand images to reduce the likelihood of a neural network memorizing specifically this 1000 images. Instead, it should recognize the “signs” of a hot dog (bun, sausage, seasonings, etc.), while remaining flexible and general enough not to be too attached to the specific pixel values of specific images in the training set.

An example of augmented data from the Keras blog
At this point, we started experimenting with tuning the architecture of the neural network. In particular, we began to use Batch Normalization and try different activation functions.
- Batch Normalization helps the neural network learn faster by “smoothing” values at various stages in the stack. It’s still not clear exactly why this works, but the effect is well-known: the neural network converges much faster, which means it achieves greater accuracy with less training or more accuracy with the same training volume, often of far greater accuracy.
- Activation functions are internal mathematical functions that determine whether to activate your "neurons" or not. In many scientific articles, ReLU (Rectified Linear Unit) is still mentioned, but we got the best results on ELU.
After adding Batch Normalization and ELU to SqueezeNet, we were able to train a neural network that achieved accuracy above 90% when learning from scratch, but it was rather fragile, that is, the same neural network in some cases could retrain or under-learn in other situations, when faced with testing in real conditions. Even adding additional examples to the data set and experiments with data augmentation did not help to set up a network that shows a normal result.
So although this stage was promising and for the first time gave us a functioning application that worked entirely on the iPhone and calculated the result in less than a second, but in the end we moved on to our fourth and final architecture.
3. DeepDog architecture
from keras.applications.imagenet_utils import _obtain_input_shape
from keras import backend as K
from keras.layers import Input, Convolution2D, SeparableConvolution2D, \
GlobalAveragePooling2d \
Dense, Activation, BatchNormalization
from keras.models import Model
from keras.engine.topology import get_source_inputs
from keras.utils import get_file
from keras.utils import layer_utils
def DeepDog(input_tensor=None, input_shape=None, alpha=1, classes=1000):
input_shape = _obtain_input_shape(input_shape,
default_size=224,
min_size=48,
data_format=K.image_data_format(),
include_top=True)
if input_tensor is None:
img_input = Input(shape=input_shape)
else:
if not K.is_keras_tensor(input_tensor):
img_input = Input(tensor=input_tensor, shape=input_shape)
else:
img_input = input_tensor
x = Convolution2D(int(32*alpha), (3, 3), strides=(2, 2), padding='same')(img_input)
x = BatchNormalization()(x)
x = Activation('elu')(x)
x = SeparableConvolution2D(int(32*alpha), (3, 3), strides=(1, 1), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('elu')(x)
x = SeparableConvolution2D(int(64 * alpha), (3, 3), strides=(2, 2), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('elu')(x)
x = SeparableConvolution2D(int(128 * alpha), (3, 3), strides=(1, 1), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('elu')(x)
x = SeparableConvolution2D(int(128 * alpha), (3, 3), strides=(2, 2), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('elu')(x)
x = SeparableConvolution2D(int(256 * alpha), (3, 3), strides=(1, 1), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('elu')(x)
x = SeparableConvolution2D(int(256 * alpha), (3, 3), strides=(2, 2), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('elu')(x)
for _ in range(5):
x = SeparableConvolution2D(int(512 * alpha), (3, 3), strides=(1, 1), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('elu')(x)
x = SeparableConvolution2D(int(512 * alpha), (3, 3), strides=(2, 2), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('elu')(x)
x = SeparableConvolution2D(int(1024 * alpha), (3, 3), strides=(1, 1), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('elu')(x)
x = GlobalAveragePooling2D()(x)
out = Dense(1, activation='sigmoid')(x)
if input_tensor is not None:
inputs = get_source_inputs(input_tensor)
else:
inputs = img_input
model = Model(inputs, out, name='deepdog')
return modelDesign
Our final architecture was largely influenced by a scientific article published on April 17, 2017 by Google on MobileNets , which described the new architecture of neural networks with the accuracy of Inception on simple tasks like ours and using only 4 million parameters or so. This means that it occupies an advantageous position between SqueezeNet, which was perhaps too simple for our task, and the overloaded Inception and VGG architectures, which are unnecessarily heavy for mobile use. This article describes some possibilities for adjusting the size and complexity of a neural network, specifically for choosing a balance between memory / CPU consumption and accuracy, and this is exactly what we were thinking about at that time.
Less than a month before the deadline, we tried to reproduce the results from a scientific article. It was an absolute disappointment when, within a day after the publication of the article, the implementation of Keras already became publicly available on GitHub thanks to Refik Kan Mully, a student at Istanbul Technical University, whose fruits we already used when we took its magnificent implementation of Keras SqueezeNet. The size, qualifications and openness of the deep learning community, as well as the presence of such talents as REFIC - this is what makes deep learning suitable for use in modern applications, but it also makes work in this industry more exciting than in any other technical industry in which I was involved in my life.
In our final architecture, we have significantly moved away from the original MobileNets architecture and from generally accepted rules, in particular:
- We do not use Batch Normalization & Activation between collapses pointwise and in depth, because a scientific article on XCeption (which discusses depth convolution in detail) suggests that this in reality leads to a decrease in accuracy on this type of architecture (as Reddit obligingly noted on Reddit author of a scientific article on QuickNet). Our method also helps reduce the size of the neural network.
- We used ELU instead of ReLU. Just like in experiments with SqueezeNet, here ELU provides better convergence speed and final accuracy compared to ReLU.
- We did not use PELU. Although promising, this activation function tends to fall into a binary state, no matter how we use it. Instead of gradually improving, the accuracy of our neural network alternated between about 0% and about 100% from one packet to another. It is not clear why this happens, and this may be due to some kind of implementation error or user error. The merging of the axes of the width and height of our images did not change the situation.
- We did not use SELU. A small investigation between the release of versions for iOS and Android showed results very similar to PELU. We suspect that SELU cannot be used in isolation by itself as a kind of silver bullet of activation functions, and it should be used - as indicated by the title of a scientific article - as part of a narrowly defined SNN architecture.
- We continued to use Batch Normalization with ELU. There are many indicators that this is optional, but in every experiment that we did without Batch Normalization, the neural network completely refused to converge. The reason may be the small size of our architecture.
- We applied Batch Normalization before activation. Although this is the subject of some controversy these days, there were no convergence in experiments with BN placement after activation of convergence either.
- To optimize the neural network, we used Cyclical Learning Rates and the excellent Keras implementation from (classmate) Brad Kenstler. CLR plays a game trying to guess the optimal learning pace for a neural network. More importantly, by raising and lowering the pace of learning, the CLR helps to achieve recognition accuracy, which in our experience is higher than that of the traditional optimizer. For both of these reasons, we cannot understand why to use something other than the CLR for training neural networks in the future.
- For our task, we did not see the need to adjust the values
 or from MobileNets architecture. Our model is small enough for our tasks when
or from MobileNets architecture. Our model is small enough for our tasks when , and the calculations are fast enough when , so we preferred to focus on achieving maximum accuracy. However, these changes can be useful when trying to run the application on older mobile phones or embedded platforms.
, and the calculations are fast enough when , so we preferred to focus on achieving maximum accuracy. However, these changes can be useful when trying to run the application on older mobile phones or embedded platforms.
So how exactly does this stack work? Deep learning often has a bad black box reputation, and although many components may indeed be cryptic, our neural networks often display information on how some of their magic tricks work. We can take individual layers from this stack and see how they are activated on specific input images, which gives us an idea of the ability of each layer to recognize sausages, rolls or other most noticeable signs of a hot dog.

Training
The quality of the source data was the most important. A neural network can only be as good as the input data, and improving the quality of the training set is probably one of the three things that we spent most of the time on while working on this project. To improve it, we took the following key steps:
- Search for more images and more diverse images (height / width, background, lighting conditions, cultural features, perspective, composition, etc.).
- Match image types to expected photos in production. We assumed that people would mainly take pictures of real hot dogs, other food, or try to outwit the system with random objects in every way, so our data set reflected this assumption.
- Give as many examples of similar objects as possible. Some dishes are more like hot dogs than others (for example, hamburgers and sandwiches or, in the case of naked hot dogs, this is a young carrot or even cooked cherry tomatoes). Our data set reflected this.
- Expected Distortion: Most photos taken on a mobile phone will be worse than the “average” photo taken with a digital SLR or under ideal lighting conditions. Mobile photos are dull, noisy, shot at an angle. Aggressive data augmentation was a key tool to solve this problem.
- In addition, we found out that users may not have access to real hot dogs, so they will try to photograph hot dogs from Google search results, which leads to special types of distortion (angular displacement if the photo is taken at an angle, the reflection of the flash from the screen, the moire effect from LCD screen shot with a mobile camera). These specific reflections had an almost uncanny ability to deceive our neural network, in many ways as described in recently published scientific papers on the (absence) of noise resistance from convolutional neural networks . Using Channel Shift in Keras has solved most of these problems.

Example of distortion due to moire and flash. Original photo: Wikimedia Commons
{kind=link}
- Some borderline cases were hard to catch. For example, images of hot dogs with spherical aberrations (soft focus) or a large number of blurring in the background sometimes misled our neural network. It’s hard to defend yourself against this, because a) there are not many photos of soft focus hot dogs (we are hungry at the very thought of this) and b) it is dangerous to spend too much of our neural network’s capacity on soft focus, when in reality most photos are from a mobile phones will not have such a sign. In the end, we decided to leave this problem, by and large, unresolved.
In its final form, our data set consisted of 150 thousand images, of which only 3,000 were hot dogs. An unbalanced 49: 1 ratio was specified in the Keras 49: 1 class weight settings in favor of hot dogs. Most of the remaining 147 thousand photographs were different dishes, and only 3000 were not food to help the neural network make slightly better generalizations and not to take for a hot dog an image of a man in red clothes.
Our data augmentation rules are as follows:
- We applied rotation within ± 135 ° - much stronger than average, because we programmed the application to not pay attention to the orientation of the phone.
- Height and width distorted by 20%.
- Circumcision in the range of 30%.
- Zooming in the range of 10%.
- Channel shifts by 20%.
- Random horizontal flips to help neural networks make generalizations.
These parameters are derived intuitively, based on experiments and our understanding of how the application will be used in real conditions, as opposed to accurate experiments.
At the last stage of our data processing pipeline, we used a multiprocess image generator for Keras from Patrick Rodriguez. Although Keras has a built-in implementation of multi-threading and multi-process, the Patrick library worked consistently faster in our experiments for reasons that we did not have time to find out. This library has reduced learning time by a third.
The network was trained on a 2015 MacBook Pro laptop with an external GPU (eGPU) connected, namely the Nvidia GTX 980 Ti (we would probably buy 1080 Ti if we started today). We were able to train the neural network in packages of 128 images. The network trained a total of 240 eras. This means that we passed through it all 150 thousand images 240 times. It took about 80 hours.
We trained the neural network in three stages:
- The first stage lasted 112 eras (7 full CLR cycles with a step size of 8 eras), with a learning rate between 0.005 and 0.03, with the rule of triangle 2 (this means that the maximum learning rate was halved every 16 eras).
- The second stage continued for another 64 eras (4 CLR cycles with a step size of 8 eras), with a learning rate between 0.0004 and 0.0045, with triangle rule 2.
- The third stage continued for 64 more eras (4 CLR cycles with a step size of 8 eras), with a learning rate between 0.000015 and 0.0002, with the rule of triangle 2.

Although the pace of training was determined by conducting the linear experiment recommended by the authors of the CLR scientific article, they seem to be intuitive, here the maximum indicator at each stage is approximately two times less than the previous minimum, which corresponds to the industry standard for halving the learning rate if the recognition accuracy is the learning process has stopped growing.
To save time, we spent part of the training on the Paperspace P5000 instance under Ubuntu. In some cases, it turned out to double the size of the packages, and the optimal learning rate at each stage also doubled.
Launching neural networks on mobile phones
Even having designed a relatively compact neural architecture and trained it to cope with specific situations in a mobile context, there was still much work to be done to make the application work correctly. If you run a first-class neural network architecture unchanged, then it will quickly consume hundreds of megabytes of RAM, which few modern mobile devices will withstand. In addition to optimizing the network itself, it turned out that the image processing method and even the loading method of TensorFlow itself have a huge effect on the speed of the neural network, the amount of RAM used and the number of failures.
This is probably the most mysterious part of the project. It’s quite difficult to find information on this topic, possibly due to the small number of deep learning applications that work on mobile devices today. However, we are grateful to the TensorFlow development team, and especially Pete Warden, Andrew Harp, and Chad Whipka for the existing documentation and their goodwill in answering our questions.
- Rounding weights in our neural network helped squeeze it by about 25% in size. In fact, instead of using arbitrary stock values obtained during training, this optimization selects the N most common values and brings all the parameters of the neural network to these values, which drastically reduces the size of the neural network in the zip archive. However, this does not affect the size after unzipping or memory consumption. We did not implement this improvement in production, because the neural network was already small enough for our tasks, and we did not have time to investigate how rounding would affect the recognition accuracy in the application.
- Optimization of the TensorFlow library by compiling it for production with a key
-Os. - Removing unnecessary fragments from TensorFlow: the library initially supports virtual machines, is able to interpret a large number of arbitrary TensorFlow operations, including addition, multiplication, concatenation, etc. You can significantly save in size (and memory consumption) by deleting unnecessary fragments from the TensorFlow library before compilation for iOS.
- Other improvements are possible. For example, in another project, the author managed to reduce the binary for Android by 1 MB with a relatively simple technique , so there may be other areas where the TensorFlow code for iOS can be optimized for your tasks.
Instead of using TensorFlow on iOS, we explored Apple's built-in deep learning libraries (BNNS, MPSCNN, and later CoreML). We would design a neural network on Keras, train it using TensorFlow, export all weight values, re-implement the neural network on BNNS or MPSCNN (or import via CoreML) and load the parameters into a new implementation. However, the biggest obstacle was that the new Apple libraries are only available under iOS 10+, and we wanted to support older versions of iOS. As iOS 10+ spreads and these frameworks improve, you may not need to run TensorFlow on a mobile device in the future.
Change application behavior by deploying a neural network on the fly
If you think that embedding JavaScript in your application on the fly is cool, then try to implement a neural network on the fly! The last trick we used in production was the use of CodePush and the relatively liberal terms of use from Apple to lively introduce new versions of our neural networks after they were published in the application directory. This is mainly done to improve recognition accuracy after release, but this method, theoretically, can be used to drastically improve the functionality of your application without the need for a second review in the AppStore.
#import
…
NSString* FilePathForResourceName(NSString* name, NSString* extension) {
// NSString* file_path = [[NSBundle mainBundle] pathForResource:name ofType:extension];
NSString* file_path = [[[[CodePush.bundleURL.URLByDeletingLastPathComponent URLByAppendingPathComponent:@"assets"] URLByAppendingPathComponent:name] URLByAppendingPathExtension:extension] path];
if (file_path == NULL) {
LOG(FATAL) << "Couldn't find '" << [name UTF8String] << "."
<< [extension UTF8String] << "' in bundle.";
}
return file_path;
}
… import React, { Component } from 'react';
import { AppRegistry } from 'react-native';
import CodePush from "react-native-code-push";
import App from './App';
class nothotdog extends Component {
render() {
return (
)
}
}
require('./deepdog.pdf')
const codePushOptions = { checkFrequency: CodePush.CheckFrequency.ON_APP_RESUME };
AppRegistry.registerComponent('nothotdog', () => CodePush(codePushOptions)(nothotdog)); What would we do otherwise
There are many things that did not work or did not have time to test them, and here are some ideas that we would study in the future:
- More thorough adjustment of our augmentation options.
- Измерение точности от начала до конца, в том числе окончательное измерение уровня абстракций вроде того, различает ли наше приложение две или более категории объектов, каков финальный предел распознавания хотдогов (мы пришли к тому, что приложение говорит «хотдог», если предел распознавания выше 0,90, по сравнению с показателем по умолчанию 0,5), после округления весов и т. д.
- Встраивание в приложение механизма обратной связи — чтобы пользователи могли выразить своё разочарование ошибочными результатами работы программы, или для активного улучшения нейросети.
- Использовать большее разрешение при распознавании изображений, чем нынешние 224×224 пикселя — конкретно, путём повышения значения

UX/DX, предвзятость и эффект «зловещей долины» ИИ
In the end, it would be inexcusable not to mention the obvious and important impact of user interaction (UX), with the developer (DX) and built-in bias in the development of an AI application. Perhaps each of these topics deserves a separate article (or a separate book), but here is what the very concrete impact of these three factors on our work was.
UX (user interaction)may be more important at every stage of the development of an AI application than a regular application. Right now there are no deep learning algorithms that will give you perfect results, but there are many situations where the right combination of deep learning and UX will give a result indistinguishable from ideal. Correct expectations regarding UX are invaluable when it comes to working out the right direction for neural network design and gracefully handling cases of unavoidable AI failures. Creating AI applications without the thought of interacting with the user is like learning a neural network without stochastic gradient descent: you will be stuck in a local minimum of the sinister valley on your way to creating a perfectly working AI.
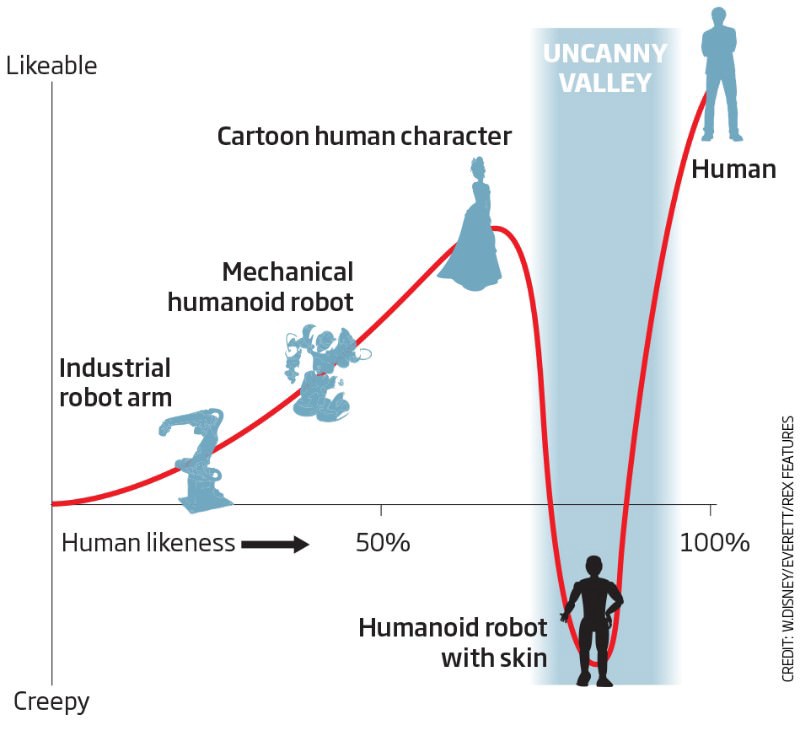
Source: New Scientist
DX (interaction with the developer) is also extremely important, because the training time of the neural network is a new hemorrhoids, along with the expectation of compilation of the program. We believe that you will definitely put DX in the first place in the priority list (therefore, choose Keras), because there is always the opportunity to optimize the environment for subsequent execution (manual parallelization of the GPU, data augmentation for multiprocessing, the TensorFlow pipeline, even re-implementation for caffe2 / pyTorch).
Even projects with relatively stupid documentation like TensorFlow greatly facilitate the interaction with the developer by providing a well-tested, widely used and superbly supported environment for training and running neural networks.
For the same reason, it’s hard to find something cheaper and more convenient than your own development GPU. The ability to locally view and edit images, edit the code in your favorite editor without delay - this greatly improves the quality and speed of development of AI projects.
Most AI applications will face more cultural biasthan our application. But for example, even in our simplest case, initially thinking about cultural features, we trained the neural network to recognize French hot dogs, Asian hot dogs and even more oddities that we had no idea about before. It is important to remember that AI does not make “better” decisions than humans - they are affected by the same biases as humans, and infection occurs during human learning.