Java's place in the world of HFT
In the article, the author tries to analyze why there are trading systems written in Java. How can Java compete in high performance with C and C ++? The following are some small reflections on the pros and cons of using Java as a programming language / platform for developing HFT systems.
A small disclaimer: the Java world is wide, and in the article I will refer to the HotSpot implementation of Java, unless otherwise stated.
1. Introduction
I would like to talk a lot about the place of Java in the world of HFT. To begin with, let's decide what HFT (High Frequency Trading) is. This term has several definitions that explain its various aspects. In the context of this article, I will stick with the explanation given by Peter Lawrey, creator of the Java Performance User's Group: “HFT is a trade that is faster than a human can see.”
HFT trading platforms can analyze various markets at the same time and are programmed to conduct transactions in the most suitable market conditions. Applied advanced technology makes it possible to incredibly quickly process data from thousands of transactions per day, while extracting only a small profit from each transaction.
This definition covers all electronic automated trading with characteristic times of hundreds of milliseconds and less, up to microseconds. But if speeds of a few microseconds have been achieved, then why then need systems that work an order of magnitude slower? And how can they make money? The answer to this question consists of two parts:
- The faster the system should be, the simpler the model should be in it. Those. if our trading logic is implemented on FPGA, then you can forget about complex models. And vice versa, if we are writing code not on FPGA or plain assembler, then we should lay more complex models in the code.
- Network delays. It makes sense to optimize microseconds only when it can significantly reduce the total processing time, which includes network delays. It is one thing when network delays are tens and hundreds of microseconds (in the case of working with only one exchange), and completely different - 20ms in each direction to London (and to New York even further!). In the second case, the optimization of microseconds spent on data processing will not bring a tangible reduction in the total reaction time of the system, which includes network delay.
Optimization of HFT systems in the first place is aimed not at reducing the overall speed of information processing (throughput), but at the response time of the system to external influence (latency). What does this mean in practice?
For throughput optimization, the resulting performance over a long time interval (minutes / hours / days / ...) is important. Those. for such systems, it is normal to stop processing for some appreciable period of time (milliseconds / second), for example, on the Garbage Collection in Java (hi, Enterprise Java!) if this does not entail a significant decrease in performance over a long period of time.
When optimizing for latency, the fastest response to an external event is primarily of interest. Such optimization leaves its mark on the tools used. For example, if OS core level synchronization primitives (for example, mutexes) are usually used for throughput optimization, then busy-spin often has to be used for latency optimization, since this minimizes the response time to the event.
Having determined what HFT is, we will move on. Where is Java in this "brave new world"? And how can Java compete in speed with titans such as C, C ++?
2. What is included in the concept of "performance"
In a first approximation, we divide all aspects of performance into 3 baskets:
- CPU performance as such, or the speed of the generated code,
- Memory subsystem performance,
- Network performance.
Consider each component in more detail.
2.1. CPU performance
Firstly , in the Java arsenal there is the most important tool for generating really fast code: a real application profile, that is, understanding which parts of the code are “hot” and which are not. This is critical for low-level code layout planning.
Consider the following small example:
int doSmth(int i) {
if (i == 1) {
goo();
} else {
foo();
}
return …;
}When generating code, the static compiler (which works in compile-time) physically has no way to determine (if PGO is not taken into account) which option is more frequent: i == 1 or not. Because of this, the compiler can only guess which generated code is faster: # 1, # 2, or # 3. In the best case, the static compiler will be guided by some kind of heuristic. And at worst, just the location in the source code.
Option 1
cmpl $1, %edi
je .L7
call goo
NEXT:
...
ret
.L7:
call foo
jmp NEXTOption # 2
cmpl $1, %edi
jne .L9
call foo
NEXT:
...
ret
.L9:
call goo
jmp NEXTOption # 3
cmpl $1, %edi
je/jne .L3
call foo/goo
jmp NEXT:
.L3:
call goo/foo
NEXT:
…
retIn Java, due to the presence of a dynamic profile, the compiler always knows which option to prefer and generates code that maximizes performance specifically for the real load profile.
Secondly , in Java there are so-called speculative optimizations. I will explain with an example. Let's say we have a code:
void doSmth(IMyInterface impl) {
impl.doSmth();
}Everything seems to be clear: a call to the virtual function doSmth should be generated. The only thing that static C / C ++ compilers can do in this situation is to try to do call virtualization. However, in practice, this optimization is relatively rare, since its implementation requires complete confidence in the correctness of this optimization.
The Java compiler, which is running at the time the application is running, has additional information:
- A complete tree of currently loaded classes, on the basis of which you can effectively carry out devirtualization,
- Statistics about which implementation was called in this place.
Even if there are other implementations of the IMyInterface interface in the class hierarchy, the compiler will inline the implementation code, which will, on the one hand, get rid of the relatively expensive virtual call and perform additional optimizations on the other hand.
Thirdly , the Java compiler optimizes the program for the specific hardware on which it was run.
Static compilers are forced to use only instructions of enough ancient iron to provide backward compatibility. As a result, all of the modern extensions available in x86 extensions are left overboard. Yes, you can compile under several sets of instructions and do runtime-dispatching (for example, using ifuncs in LINUX) while the program is running, but who does it?
The Java compiler knows on which particular hardware it is running and can optimize the code for this particular system. For example, if the system supports AVX, then new instructions will be used, operating with new vector registers, which greatly speeds up the work of floating-point calculations.
2.2. Memory subsystem performance
There are several aspects of the performance of the memory subsystem: the pattern of access to memory, the speed of allocation and deallocation (release) of memory. Obviously, the performance issue of the memory subsystem is extremely extensive and cannot be completely exhausted by the 3 aspects under consideration.
2.2.1 Memory access pattern
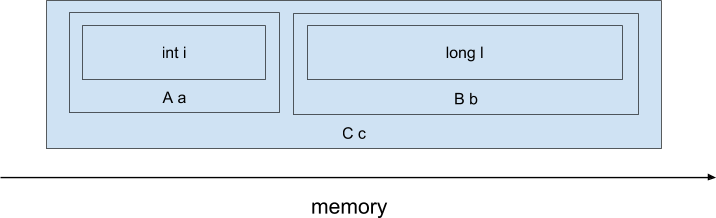
In the context of the memory access pattern, the most interesting question is the difference in the physical arrangement of objects in memory or data layout. And here the C and C ++ languages have a huge advantage - because we can explicitly control the location of objects in memory, and differences from Java. For example, consider the following C ++ code):
class A {
int i;
};
class B {
long l;
};
class C {
A a;
B b;
};
C c;When compiling this code compiler C / C ++, field-subobjects fields are physically disposed in series, thus approximately (not consider possible padding between the fields and the possible transformation of the data-layout produced by the compiler):
Ie an expression like 'return cai + cbl' will be compiled into such x86 assembler instructions:
mov (%rdi), %rax ; << чтение c.a.i
add ANY_OFFSET(%rdi), %rax ; << чтение c.b.l и сложение с c.a.i
retSuch simple code was achieved due to the fact that the object is linearly in memory and the compiler at the stage of compiling the offset of the required fields from the beginning of the object. Moreover, when accessing the cai field, the processor will load the entire cache line with a length of 64 bytes, which is likely to include neighboring fields, for example cbl. Thus, access to several fields will be relatively quick.
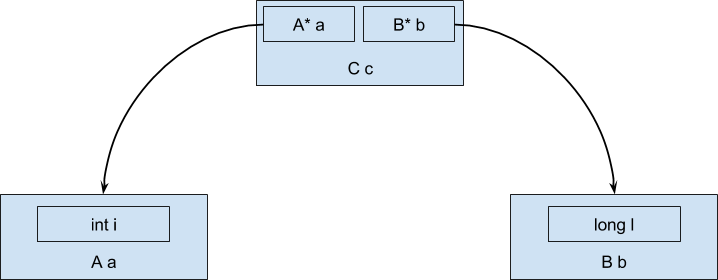
How will this object be located in case of using Java? In view of the fact that objects cannot be values (unlike primitive types), but are always referenced, during execution the data will be located in memory in the form of a tree structure, not a sequential memory region:
And then the expression 'cai + cbl' will compile at best into something similar to this x86 assembler code:
mov (%rdi), %rax ; << загружаем адрес объекта a
mov 8(%rdi), %rdx ; << загружаем адрес объекта b
mov (%rax), %rax ; << загружаем значение поля i объекта a
add (%rdx), %rax ; << загружаем значение поля l объекта bWe got an additional level of indirection when accessing data inside field objects, since an object of type C contains only links to field objects. An additional level of indirection significantly increases the number of data downloads from memory.
2.2.2. Allocation (allocation) rate
Here Java has a significant advantage over traditional languages with manual memory management (if you do not take the artificial case that all memory is allocated on the stack).
Usually for allocation in Java, so-called TLABs (Thread local allocation buffer) are used, that is, memory areas unique to each thread. Allocation looks like a decrease in the pointer indicating the beginning of free memory.
For example, a pointer to the beginning of free memory in a TLAB indicates 0x4000. For allocation, say, 16 bytes, you need to change the value of the pointer to 0x4010. Now you can use the newly allocated memory in the range 0x4000: 0x4010. Moreover, since access to TLAB is possible only from one thread (after all, this is thread-local buffer, as the name implies), there is no need for synchronization!
In languages with manual memory management, the operator new / malloc / realloc / calloc functions are usually used to allocate memory. Most implementations contain resources shared between threads, and are much more complex than the described method of allocating memory in Java. In some cases of running out of memory or fragmentation of the heap, memory allocation operations may take a considerable amount of time, which will impair latency.
2.2.3. Memory release speed
Java uses automatic memory management, and the developer no longer has to manually release the previously allocated memory, as Garbage collector does. The advantages of this approach include the simplification of writing code, because there is less cause for headache.
However, this leads to not quite expected consequences. In practice, the developer has to manage various resources, not just memory: network connections, DBMS connections, open files.
And now, due to the lack of intelligible syntax tools for controlling the life cycle of resources in the language, it is necessary to use rather bulky constructions like try-finally or try-with-resources.
Compare:
Java:
{
try (Connection c = createConnection()) {
...
}
}or so:
{
Connection c = createConnection();
try {
...
} finally {
c.close();
}
}With what you can write in C ++
{
Connection c = createConnection();
} // деструктор будет автоматически вызван при вызоде из scope'аBut back to freeing up memory. All garbage collectors shipped with Java are characterized by a Stop-The-World pause. The only way to minimize its impact on the performance of the trading system (do not forget that we need optimization not throughput but latency) is to reduce the frequency of any stops at the Garbage Collection.
At the moment, the most common way to do this is to “reuse” objects. That is, when we don’t need the object (in C / C ++, we need to call the delete operator), we write the object to some pool of objects. And when we need to create an object instead of the new operator, we turn to this pool. And if the pool has a previously created object, then we get it and use it as if it had just been created. Let's see how it will look at the source code level:
Automatic memory management:
{
Object obj = new Object();
.....
// Здесь объект уже не нужен, просто забываем про него
}And with reusing objects:
{
Object obj = Storage.malloc(); // получаем объект из пула
...
Storage.free(obj); // возвращаем объект в пул
}The topic of reusing objects, as it seems to me, is not sufficiently covered and, of course, deserves a separate article.
2.3. Network performance
Here Java positions are quite comparable to traditional C and C ++ languages. Moreover, the network stack (level 4 of the OSI model and below) located in the kernel of the OS is physically the same when using any programming language. All network stack performance settings relevant to C / C ++ are also relevant to a Java application.
3. Development and debugging speed
Java allows you to develop logic much faster due to the much faster speed of writing code. Last but not least, this is a consequence of the rejection of manual memory management and pointer-number dualism. Indeed, it is often faster and easier to set up the Garbage Collection to a satisfactory level than to catch numerous dynamic memory management errors. Recall that errors in C ++ development often take a completely mystical turn: they are reproduced in the release build or only on Wednesdays (hint: in English, “Wednesday” is the longest spelling day of the week). Development in Java in the vast majority of cases dispenses with such occultism, and for every error you can get a normal stack trace (even with line numbers!).
4. Summary
In the HFT world, how successful a trading system is depends on the sum of two parameters: the speed of the trading system itself and the speed of its development and development. And if the speed of the trading system is a relatively simple and understandable criterion (at least it’s clear how to measure it), then the speed of the system’s development is significantly more difficult to evaluate. You can imagine the speed of development as the sum of countless factors, among which are the speed of writing code and the speed of debugging and the speed of profiling and the convenience of tools and the threshold of entry. Also, important factors are the speed of integration of ideas received from Quantitative Researchers, who, in turn, can reuse the code of the product trading system for data analysis. It seems to me that Java is a reasonable compromise between all these factors.
- good enough performance;
- relatively low entry threshold;
- simplicity of the tools (Unfortunately, for C ++ there are no development environments comparable to IDEA);
- the ability to easily reuse code by analysts;
- ease of operation under large technically complex systems.
Summarizing the above, we can summarize the following: Java in HFT has its own significant niche. Using Java, not C ++, significantly accelerates the development of the system. In terms of performance, Java performance may be comparable to C ++ performance and, in addition, Java has a set of unique optimization capabilities not available for C / C ++.