Fast data recovery. How will the LRC help us?

In the modern world there is an exponential increase in data volumes. Storage vendors face a whole series of tasks related to colossal volumes of information. Among them are the protection of user data from loss and the fastest data recovery in the event of a server or disk failure.
In our article, the task of rapid reconstruction will be considered. It would seem that the best solution for data protection is replication, but the amount of overhead in this scenario is 100% or more. It is not always possible to allocate such a volume. Therefore, a compromise must be sought between redundancy and recovery rate.
A widely known approach that provides less overhead is local parity (LRC) codes andregenerating codes . These solutions work for both distributed systems and local disk arrays.
In this article, we will consider the features of using LRC codes for disk arrays and propose scenarios for accelerated data recovery of a failed disk.
We tested performance at the same time for both LRC and regenerating codes, but we will talk about the latter in more detail in one of the following articles.
Data availability
RAID technology (Redundant Array of Independent Disks) is used in data storage systems to provide high speed data access and fault tolerance. High speed is achieved by parallelizing the processes of reading and writing data to disks, and fault tolerance - due to the use of noise-resistant coding.
Over time, the requirements for volume and reliability of storage systems have increased. This led to the emergence of new RAID levels (RAID-1 ... 6, RAID-50, RAID-60, RAID-5E, etc.) and the use of different classes of noise-resistant codes, like MDS (Maximum distance separable - codes with maximum code distance) and non-MDS.
We will consider how the placement of data with a certain encoding method affects the recovery speed of a failed disk, and, as a result, the availability of disk array data.
Availability is the likelihood that a system will be available upon request. High availability is achieved, in particular, due to coding, i.e. part of the system’s disk space is allocated not for user data, but for storing checksums. In the event of a system drive failure, lost data can be recovered using these checksums, thereby ensuring data availability. As a rule, availability is calculated by the formula:

MTTF - Mean Time To Failure (MTBF), MTTR - Mean Time To Repair (average recovery time). The shorter the time required to restore a particular system component, in this case, a disk or cluster node, the higher the data availability.
Component recovery speed depends on:
- recording speed of recovered data;
- reading speed;
- the amount of data read necessary to restore;
- decoding algorithm performance.
Each of the options for organizing data storage and calculating checksums has its advantages and disadvantages. For example, Reed-Solomon codes (RS codes) provide high fault tolerance. RS codes are codes with the maximum code distance (MDS) and appear to be optimal in terms of excess space for storing checksums. The disadvantage of RS-codes is that they are quite complicated from the point of view of coding and require a lot of readings to recover a failure.
Among other possible solutions are modified Rotated RS-codes or WEAVER codes (a kind of XOR-codes). The latter are fairly simple in terms of coding and require very few readings to recover from failure. However, with this encoding method, checksums need to be allocated a much larger amount of storage than with MDS codes.
A good solution to the above problems was the emergence of LRC (Local Reconstruction Codes). Erasure Coding in Windows Azure Storage provides a detailed description of these codes, which are essentially the conversion of RS codes to non-MDS. The same paper compares LRC with other codes and shows the benefits of LRC. In this article, we will look at how the location of LRC strip blocks affects recovery speed.
Problems Using LRC in RAID
Next, we briefly describe the ideology of the LRC, consider emerging issues and possible solutions. Consider the sequence of blocks stored on disks forming one strip. In the future, unless otherwise indicated, we will understand stripe as a set of blocks located on different disks and united by a common checksum.
If the data of this strip is encoded with RS code, as is done, for example, in RAID-6 with two checksums, then the code information contains two blocks of strip. In fig. 1 on top is a strip of 19 blocks, including 2 blocks
 and
and  - checksums. If a disk containing, for example, block number 2 fails, to restore this block, you will need to read 17 blocks from each strip (16 not failed and one checksum).
- checksums. If a disk containing, for example, block number 2 fails, to restore this block, you will need to read 17 blocks from each strip (16 not failed and one checksum). The local reconstruction codes in this case will require splitting the stripe into several local groups, for each of which a local checksum is calculated (local syndrome). For all data blocks, a global checksum is also calculated. In fig. 1, an example is considered in which blocks are divided into 3 local groups of size 5. For each of them, local checksums are calculated
 And also designed one global checksum G.
And also designed one global checksum G. 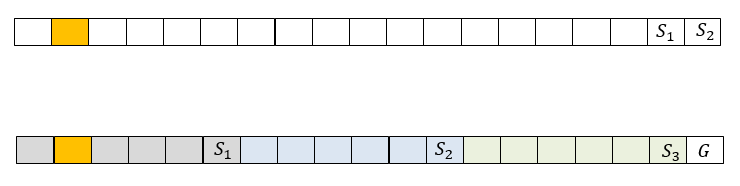
Fig. 1. Representation of RAID6 and LRC stripe representations.
Local checksums are calculated as XOR data blocks on which they depend. There can be several global checksums; they are calculated as checksums of RS codes. In this case, to restore block number 2, you need to read 6 blocks. This is 3 times less compared to the previous case, but it will take more space to store checksums here. It should be noted that in case of failure of 2 disks of the same group, the LRC is easily converted to the classic RS when adding (XOR) all 3 local checksums.
Using LRC can perfectly solve the problem of the number of reads required to restore one drive. Nevertheless, if all strips are placed on disks or cluster nodes in the same way and the sequence of blocks is not changed in them, it turns out that when changing data in any block of a local group, the local checksum of this group and the global checksum of the stripe will always be recounted. Thus, components with checksums will be subject to high loads and wear. Therefore, the performance of such an array will be lower. Classically, such a problem in RAID is solved by cyclic shift of stripes on disks, see fig. 2.
So that during data recovery, the recovery speed is not limited by the write speed to one component of the storage system, the so-called Empty Block (E) can be added to each stripe, as is done in RAID-5E and RAID-6E. Thus, the recovered data in each strip is written to its empty block, and therefore to a separate disk. The presence of an empty block in the strip is optional. In our further discussion, we will consider stripes with such a block for completeness.
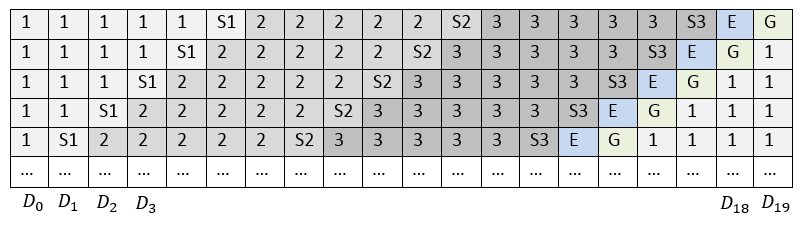
Fig. 2. Arrangement of stripe blocks with a shift
Thus, when using a cyclic shift and having an empty block, the arrangement of strips on the disks will take the form as in Fig. 2.
The use of LRC also imposes a slight restriction on the number of disks on which the stripe can be located. So, if the number of local groups is equal
 , the size of one local group is
, the size of one local group is  , the number of global checksums is
, the number of global checksums is  and there is an empty block, then the total size of the stripe will be equal
and there is an empty block, then the total size of the stripe will be equal  . If the number of disks differs from the stripe length, then two options are possible:
. If the number of disks differs from the stripe length, then two options are possible:- Create local groups of different sizes. In this case, some local checksums will often be updated when the stripe data changes, which can lead to a slower recording.
- Do not place each stripe on all disks, and where one stripe ends, immediately start the second, see fig. 3. This approach leads to the fact that all local groups can be the same size, and a cyclic shift is introduced automatically according to the location of the strips. If the stripe length matches the number of disks, then for each stripe a cyclic shift is performed, as is done for RAID-6.
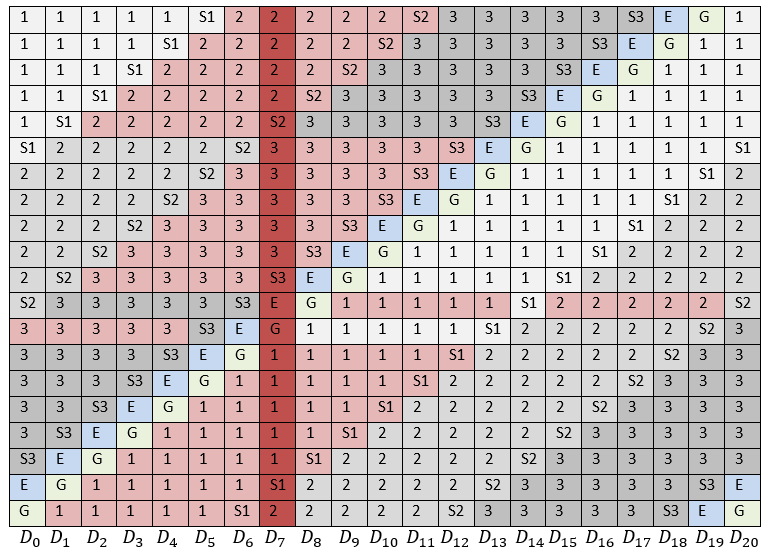
Fig. 3. The blocks necessary to rebuild one failed drive
in Fig. 3 the case of a single drive failure is considered -
 . Pink indicates all the blocks that need to be read in order to restore it.
. Pink indicates all the blocks that need to be read in order to restore it. 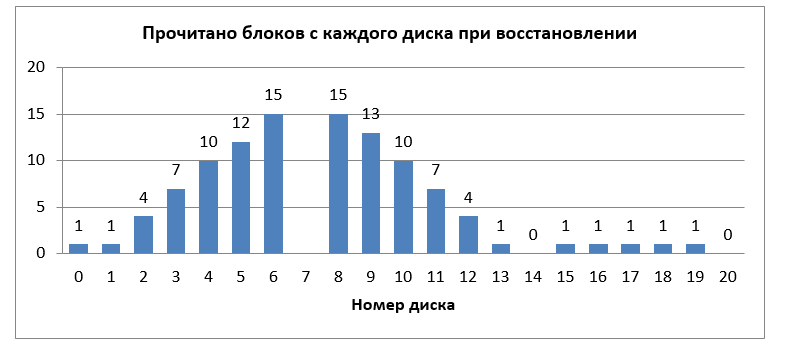
Fig. 4. The number of blocks read from each disk to restore one failed disk
In total, 105 blocks were required to be read. If RAID-6 were used instead of LRC, then 340 read blocks would be needed. To understand whether this arrangement of blocks is optimal, we calculate the number of blocks read from each disk, see Fig. 4.
You may notice that the disks located closer to the failed one will be much more loaded compared to the rest. Thus, when recovering data in the event of a failure, it is these most loaded disks that will become the bottleneck. However, the location of the LRC strip blocks, when the first local group blocks go first, then the second, then the third, is not a strict restriction. Thus, our task is to determine the arrangement of blocks at which the load on all disks in the event of a failure would be minimal and uniform.
Randomized algorithms for large disks
Leaving aside various solutions to a similar problem for RAID-6, consider a possible scenario in the case of LRC:
- For each LRC-strip, we take the classic arrangement of blocks (similar to Fig. 1). We use the number of the selected stripe as the initial value (seed) for the random number generator. For all strips, the same random number generator is used, but with a different seed.
- Using the initiated random number generator and the initial arrangement of blocks, we obtain a random arrangement of blocks in the current strip. In our case, the Fisher – Yates shuffle algorithm was applied.
- We perform this procedure for each strip.
With this approach, each stripe will have some random structure, which is uniquely determined by its number. Since the cryptographic strength of the random number generator is not required in this problem, we can use a fairly simple and quick version of it. Thus, it is possible to estimate the mathematical expectation of the average load of each disk in case of failure.
We introduce the following notation:
 - the volume of each disk in the array,
- the volume of each disk in the array,  - the size of one stripe block,
- the size of one stripe block,  - the length of one stripe,
- the length of one stripe,  - number of disks, - the size of the local group. - the number of local groups, - the number of global checksums. Then the mathematical expectation of the average load of each disk will be calculated as follows:
- number of disks, - the size of the local group. - the number of local groups, - the number of global checksums. Then the mathematical expectation of the average load of each disk will be calculated as follows:
Having such an assessment and knowing the speed of reading blocks from a disk, you can make an approximate estimate of the recovery time of one failed disk.
Performance testing
To test performance, we created RAID from 22 disks with various layouts. The RAID device was created using the device-mapper modification, which changed the addressing of the data block according to a specific algorithm.
Data was written to the RAID for which checksum was calculated for subsequent recovery. A failed disk was selected. Data recovery was performed either on the corresponding empty blocks, or on a hot spare disk.
We compared the following schemes:
- RAID-6 - classic RAID-6 with two checksums; data recovery on hot spare disk;
- RAID-6E - RAID6 with empty block at the end of the strip; data recovery on empty blocks of the corresponding stripes;
- Classic LRC + E - LRC-scheme in which local groups go sequentially and end with a checksum (see Fig. 3); recovery to empty block;
- LRC rand - to generate each LRC-strip, its number is used as a random number generator core, data recovery on an empty block.
For testing, 22 disks with the following characteristics were used:
- MANUFACTURER: IBM
- PART NUMBER: ST973452SS-IBM
- CAPACITY: 73GB
- INTERFACE: SAS
- SPEED: 15K RPM
- SIZE FORM FACTOR: 2.5IN
When testing performance, the size of the stripe blocks plays a large role. Reading from disks during data recovery is carried out at increasing addresses (sequentially), but due to declustering in random layouts, some blocks are skipped. This means that when working with small blocks, the positioning of the magnetic disk head will be performed very often, which will adversely affect performance.
Since the specific values of the data recovery speed may depend on the model of hard drives, manufacturer, RPM, etc., we presented the results in relative terms. Figure 5 demonstrates the performance gain in the considered circuits (RAID6 with empty block, Classic LRC, LRC rand) in comparison with the classic RAID-6.
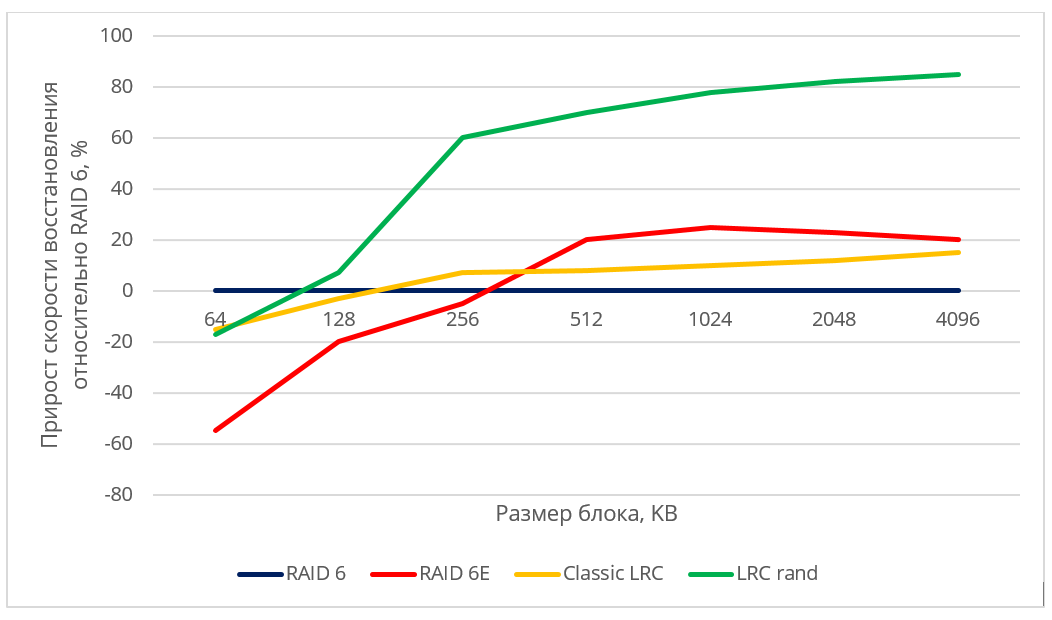
Fig. 5. Relative performance of various allocation algorithms.
When recovering data to a hot spare disk, the recovery rate was limited by the write speed to disk for all schemes using hot spare. You may notice that the randomized LRC scheme gives a rather high increase in recovery speed compared to a non-optimal scheme and RAID-6.
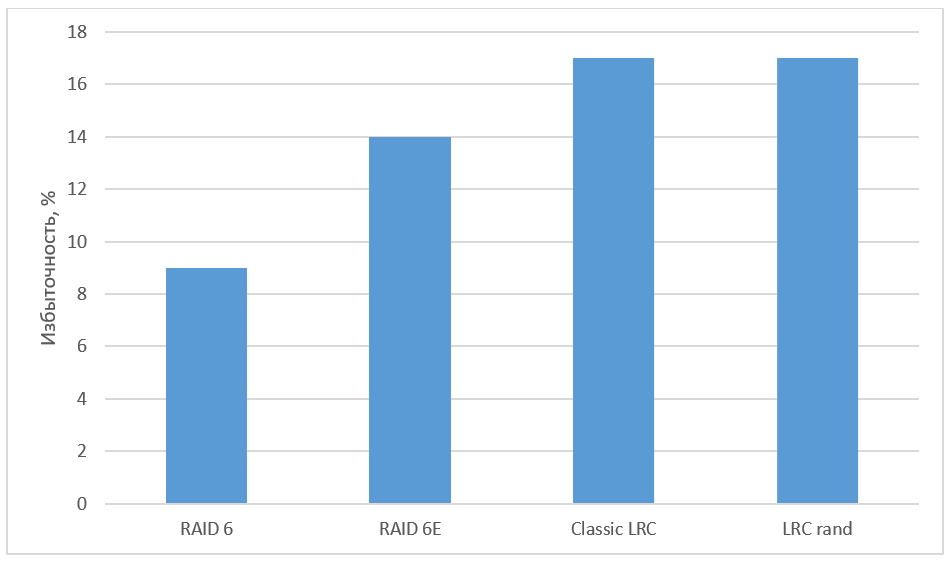
Fig. 6. Redundancy of various algorithms
Conclusion
We gave possible options for the location of the blocks, and also tested various schemes and saw a noticeable increase in recovery speed. Due to the high scalability of LRC codes, this approach can also be used when building arrays from a large number of disks, by increasing the number of local groups. Improving reliability can be achieved by increasing the number of global checksums.
LRC interference coding significantly reduces storage redundancy compared to replication. Coding schemes other than Reed-Solomon codes are most often examined in practice in the context of LRC. Xorbas — the implementation of LRC in HDFS — required a 14% increase in redundancy over RS encoding. The recovery rate increased by 25-45%. The number of reads and transfers over the network has also been significantly reduced. For further study of optimal LRCs, we recommend referring to the work “A Family of Optimal Locally Recoverable Codes” (Itzhak Tamo, Alexander Barg).
Used sources:
- Hafner, JL, WEAVER Codes: Highly Fault Tolerant Erasure Codes for Storage Systems, FAST-2005: 4th Usenix Conference on File and Storage Technologies
- Khan, O., Burns, R., Plank, JS, Pierce, W., Huang, C. Rethinking Erasure Codes for Cloud File Systems: Minimizing I / O for Recovery and Degraded Reads, FAST-2012: 10th Usenix Conference on File and storage technologies
- Huang, C., Simitci, H., Xu, Y., Ogus, A., Calder, B., Gopalan, P., Li, J., Yekhanin, S., Erasure Coding in Windows Azure Storage, USENIX Annual Technical Conference
- M. Sathiamoorthy, M. Asteris, D. Papailiopoulos, AG Dimakis, R. Vadali, S. Chen, and D. Borthakur. XORing Elephants: Novel Erasure Codes for Big Data. In Proceedings of the VLDB Endowment, volume 6, pages 325–336. VLDB Endowment, 2013.
- Itzhak Tamo, Alexander Barg. A Family of Optimal Locally Recoverable Codes. arXiv preprint arXiv: 1311.3284, 2013.