Machine Intelligence in Gboard Keyboard
- Transfer
Most people spend most of the time every day using the keyboard on their mobile device: composing letters, chat messages, social networks, etc. However, mobile keyboards are still pretty awkward. The average user types with the mobile keyboard about 35% slower than with the physical one. To change this, we recently introduced many great improvements to Gboard for Android . We strive to create a smart mechanism that allows you to quickly enter text, while at the same time offering tips and correcting errors, in any language of your choice.
Given the fact that the mobile keyboard converts touch to text in much the same way that a speech recognition system translates voice into text, we used the Speech Recognition system. First, we created robust spatial models that match fuzzy touchscreen sequences with keyboard keys, just like acoustic models compare sequences of sound fragments with phonetic units. Then we created a powerful decoding engine based on finite converters(FST) to determine the most likely phrase for a given sequence of touches. We knew that with its mathematical formalism and widespread success in voice applications, the FST decoder will provide the necessary flexibility to support a wide variety of complex input options, as well as language functions. In this article we will describe in detail what was included in the development of both of these systems.
Mobile keyboard input is prone to errors commonly referred to as “fat fingers” (or tracing spatially similar words in a sliding set, as shown below), as well as motor errors and cognitive errors (resulting in typos, inserting extra characters, missing characters, or changing characters in places). A smart keyboard must take these errors into account and predict the implied word quickly and accurately. Essentially, we created a spatial model for Gboard that fixes these character-level errors by matching touch points on the screen with real keys.
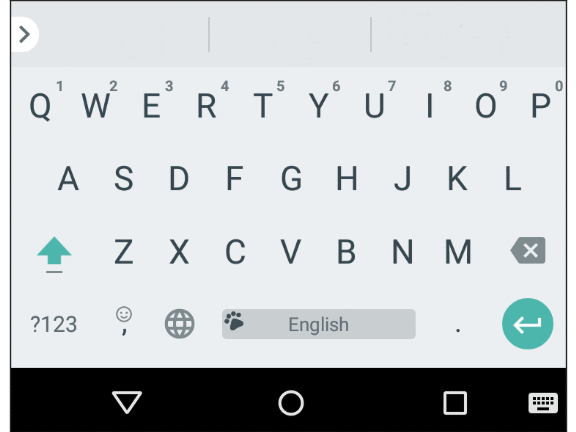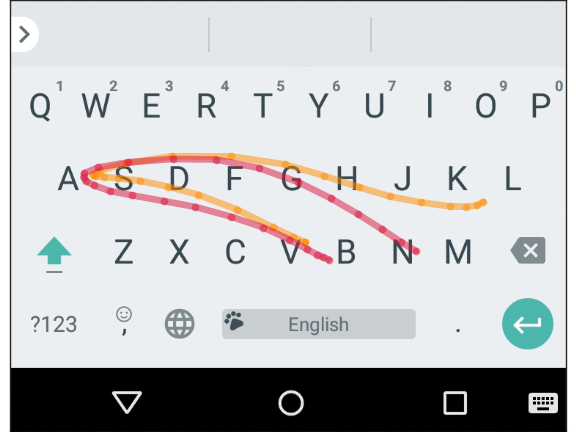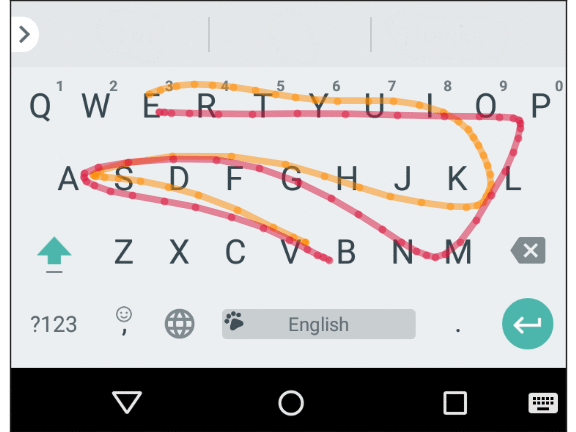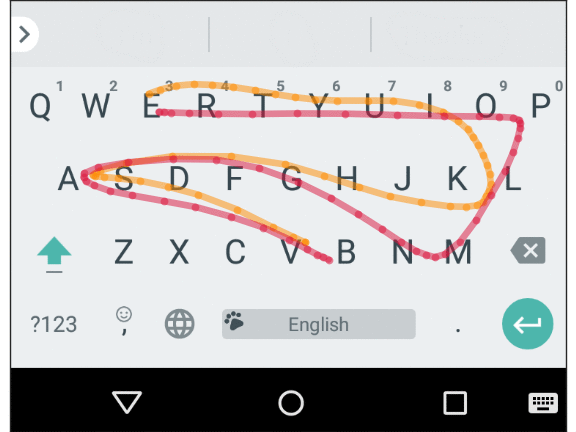
The average path for two spatially similar words: “Vampire” and “Value”
Until recently, Gboard used 1) a Gaussian model to determine the probability of pressing adjacent keys; 2) a rule-based model for representing motor errors and cognitive errors. These models were simple and intuitive, but they did not allow directly optimizing metrics that correlate with the best quality of the set. Based on our experience with the acoustic models Search Voice , we have replaced and Gaussian model, and rules-based model to a single high-performance model of the long term memory (LSTM), trained with the criterion of associative classification transient (connectionist temporal classification, CTC).
However, the training of this model turned out to be much more complicated than we expected. While acoustic models were trained on audio data with accompanying text prepared by a person, it was difficult to prepare an accompanying text for millions of sequences of taps on the touchscreen and finger trajectories on the keyboard. So the developers used interaction signals from the users themselves - corrected auto-corrections and choices of prompts - as negative and positive signals in training with partial involvement of the teacher (semi-supervised learning). Thus, extensive data sets were created for training and testing.

Source data points corresponding to the word “could” (left) and normalized selected trajectories with sampling deviations (right)
A brute force technique has been used to test many techniques from the speech recognition literature on neural spatial models (NSMs) to make them compact and fast enough to work on any device. Hundreds of models trained on the TensorFlow infrastructure , optimizing various keyboard signals: auto-completion, tips, sliding on the touchscreen, etc. After more than a year of work, the finished models became about 6 times faster and 10 times more compact than the original versions. They also reduced the number of incorrect auto-corrections by about 15% and the number of incorrectly recognized gestures on offline data sets decreased by 10%.
While NSMs use spatial information to assist in determining keystrokes or keyboard paths, there are additional language restrictions — lexical and grammatical- which can be used. The lexicon tells us which words exist in the language, and probabilistic grammar - which words may follow which others. To encode this information, we used finite transducers (FST). They have long been a key component of Google’s speech recognition and synthesis systems. FSTs provide a fundamental way of representing various probabilistic models (lexicons, grammars, normalizers, etc.) from natural language processing, as well as the mathematical framework necessary for influencing, optimizing, combining and searching models *.
In Gboard, the character-to-word converter is a compact keyboard vocabulary as shown in the illustration below. It encodes ways to convert key sequences into words, allowing for alternative key sequences and arbitrary spaces.

The converter encodes “I”, “I've”, “If” along the trajectories from the initial state (bold circle with the designation “1”) to the final states (circles in the double circuit with the designations “0” and “1”). Each arc is marked with the input value of the key (before the colon) and the corresponding resulting word (after the colon), where ε denotes an empty character. The apostrophe in “I've” may be omitted. The user can sometimes miss the space. To account for this, a space between words is optional in the transformer. The symbol ε and back arcs allow more than one word.
A probabilistic n-gram converter is used to represent the language model for the keyboard. The state in the model represents the (up to) n-1 vocabulary context. An arc emerging from this state is marked with a winner word and the probability with which it follows this context (based on textual data). In combination with the spatial model, which gives the probabilities of sequences of keystrokes (discrete values in the case of individual keystrokes or continuous gestures in a sliding set), this model is used in the ray search algorithm .
The general principles of FST - streaming, support for dynamic models and others - have allowed far progress in the development of a new keyboard decoder. But it was necessary to add a few additional features. When you speak out loud, you do not need a decoder to guess the end of a word or the next word - and save a few syllables in a speech; but when you type, help with auto-completion and predictions will come in handy. We also wanted the keyboard to provide organic multilingual support, as shown below.

Trilingual set in Gboard.
It took complex efforts to make the new decoder work, but the fundamental nature of the final converters has many advantages. For example, transliteration support for languages like Hindi is a simple extension to the base decoder.
In many languages with complex alphabets, novelization systems have been developed to display characters in the Latin alphabet, often in accordance with their phonetic pronunciations. For example, Pinyin “xièxiè” corresponds to the Chinese characters “谢谢” (“thank you”). Pinyin keyboard allows you to conveniently type words in the QWERTY layout and automatically "translate" them into the desired alphabet. In the same way, the Hindi keyboard allows you to type “daanth” for the word “दांत” (“tooth”). While Pinyin has a generally accepted romanization system, Hindi transliteration is not so clear. For example, “daant” would also be a valid alternative for “दांत”.
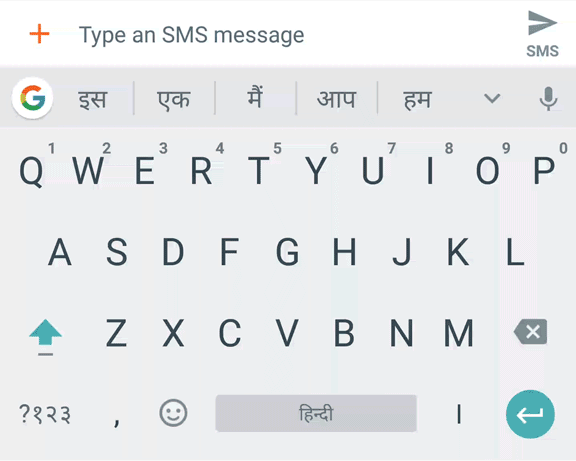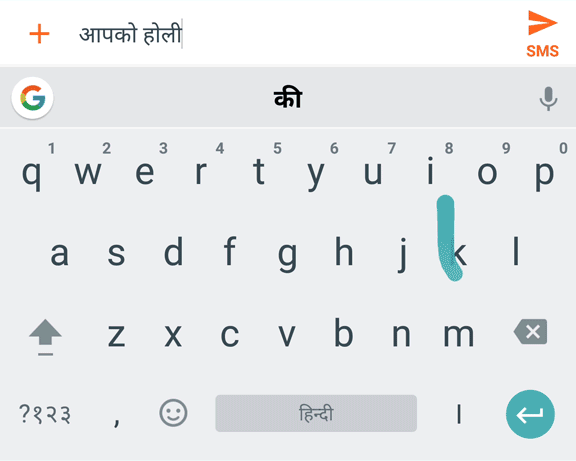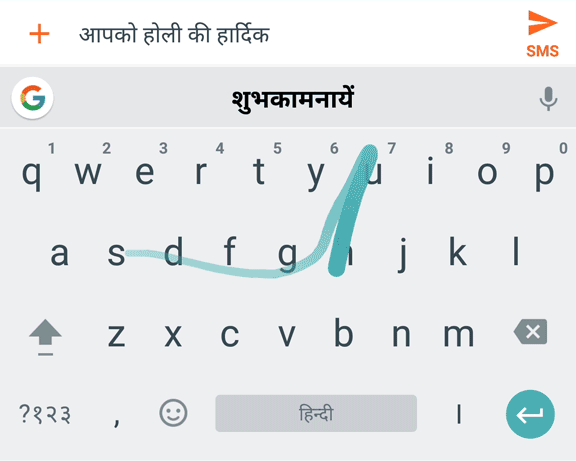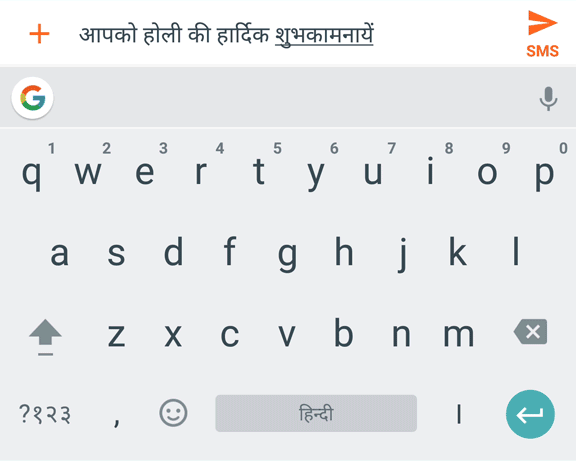
Hindi sliding input transliteration
When we had a converter that converts sequences of letters to words (lexicon) and an automatic weighted language model for sequences of words, we developed a weighted converter to convert between Latin sequences of characters and alphabets of 22 Indian languages. Some languages have several scripts (for example, Bodo can be written in Bengali or Devangari), so between transliteration and native writing we created 57 input methods in just a few months.
The universal nature of the FST decoder allowed us to use all the work done earlier to support auto-completion, predictions, a rolling set and many UI functions without any additional effort, so our Indian users from the very beginning received excellent program quality.
In general, our latest work allowed us to reduce the decoding delay by 50%, reduced the proportion of words that users had to manually correct by 10%, allowed us to start transliteration for 22 official languages of India, and led to the emergence of many new features that you might notice.
We hope that the latest changes will help you type on the keyboard of your mobile device. But we understand that this task is by no means solved. Gboard can still make assumptions that seem strange or of little use, and gestures can be recognized in words that a person would never have typed. However, our transition to powerful machine intelligence algorithms opens up new possibilities that we are actively exploring to create more useful tools and products for our users around the world.
This work was done by Cyril Allausen, Wise Alsharif, Lars Hellsten, Tom Ouyan, Brian Roark and David Rybach, with the assistance of Speech Data Operation. Special thanks to Johan Schalkwick and Corinne Cortes for their help.
* A set of appropriate algorithms is available in the OpenFst free library . ↑
Given the fact that the mobile keyboard converts touch to text in much the same way that a speech recognition system translates voice into text, we used the Speech Recognition system. First, we created robust spatial models that match fuzzy touchscreen sequences with keyboard keys, just like acoustic models compare sequences of sound fragments with phonetic units. Then we created a powerful decoding engine based on finite converters(FST) to determine the most likely phrase for a given sequence of touches. We knew that with its mathematical formalism and widespread success in voice applications, the FST decoder will provide the necessary flexibility to support a wide variety of complex input options, as well as language functions. In this article we will describe in detail what was included in the development of both of these systems.
Neural spatial models
Mobile keyboard input is prone to errors commonly referred to as “fat fingers” (or tracing spatially similar words in a sliding set, as shown below), as well as motor errors and cognitive errors (resulting in typos, inserting extra characters, missing characters, or changing characters in places). A smart keyboard must take these errors into account and predict the implied word quickly and accurately. Essentially, we created a spatial model for Gboard that fixes these character-level errors by matching touch points on the screen with real keys.
The average path for two spatially similar words: “Vampire” and “Value”
Until recently, Gboard used 1) a Gaussian model to determine the probability of pressing adjacent keys; 2) a rule-based model for representing motor errors and cognitive errors. These models were simple and intuitive, but they did not allow directly optimizing metrics that correlate with the best quality of the set. Based on our experience with the acoustic models Search Voice , we have replaced and Gaussian model, and rules-based model to a single high-performance model of the long term memory (LSTM), trained with the criterion of associative classification transient (connectionist temporal classification, CTC).
However, the training of this model turned out to be much more complicated than we expected. While acoustic models were trained on audio data with accompanying text prepared by a person, it was difficult to prepare an accompanying text for millions of sequences of taps on the touchscreen and finger trajectories on the keyboard. So the developers used interaction signals from the users themselves - corrected auto-corrections and choices of prompts - as negative and positive signals in training with partial involvement of the teacher (semi-supervised learning). Thus, extensive data sets were created for training and testing.
Source data points corresponding to the word “could” (left) and normalized selected trajectories with sampling deviations (right)
A brute force technique has been used to test many techniques from the speech recognition literature on neural spatial models (NSMs) to make them compact and fast enough to work on any device. Hundreds of models trained on the TensorFlow infrastructure , optimizing various keyboard signals: auto-completion, tips, sliding on the touchscreen, etc. After more than a year of work, the finished models became about 6 times faster and 10 times more compact than the original versions. They also reduced the number of incorrect auto-corrections by about 15% and the number of incorrectly recognized gestures on offline data sets decreased by 10%.
End converters
While NSMs use spatial information to assist in determining keystrokes or keyboard paths, there are additional language restrictions — lexical and grammatical- which can be used. The lexicon tells us which words exist in the language, and probabilistic grammar - which words may follow which others. To encode this information, we used finite transducers (FST). They have long been a key component of Google’s speech recognition and synthesis systems. FSTs provide a fundamental way of representing various probabilistic models (lexicons, grammars, normalizers, etc.) from natural language processing, as well as the mathematical framework necessary for influencing, optimizing, combining and searching models *.
In Gboard, the character-to-word converter is a compact keyboard vocabulary as shown in the illustration below. It encodes ways to convert key sequences into words, allowing for alternative key sequences and arbitrary spaces.
The converter encodes “I”, “I've”, “If” along the trajectories from the initial state (bold circle with the designation “1”) to the final states (circles in the double circuit with the designations “0” and “1”). Each arc is marked with the input value of the key (before the colon) and the corresponding resulting word (after the colon), where ε denotes an empty character. The apostrophe in “I've” may be omitted. The user can sometimes miss the space. To account for this, a space between words is optional in the transformer. The symbol ε and back arcs allow more than one word.
A probabilistic n-gram converter is used to represent the language model for the keyboard. The state in the model represents the (up to) n-1 vocabulary context. An arc emerging from this state is marked with a winner word and the probability with which it follows this context (based on textual data). In combination with the spatial model, which gives the probabilities of sequences of keystrokes (discrete values in the case of individual keystrokes or continuous gestures in a sliding set), this model is used in the ray search algorithm .
The general principles of FST - streaming, support for dynamic models and others - have allowed far progress in the development of a new keyboard decoder. But it was necessary to add a few additional features. When you speak out loud, you do not need a decoder to guess the end of a word or the next word - and save a few syllables in a speech; but when you type, help with auto-completion and predictions will come in handy. We also wanted the keyboard to provide organic multilingual support, as shown below.
Trilingual set in Gboard.
It took complex efforts to make the new decoder work, but the fundamental nature of the final converters has many advantages. For example, transliteration support for languages like Hindi is a simple extension to the base decoder.
Transliteration Models
In many languages with complex alphabets, novelization systems have been developed to display characters in the Latin alphabet, often in accordance with their phonetic pronunciations. For example, Pinyin “xièxiè” corresponds to the Chinese characters “谢谢” (“thank you”). Pinyin keyboard allows you to conveniently type words in the QWERTY layout and automatically "translate" them into the desired alphabet. In the same way, the Hindi keyboard allows you to type “daanth” for the word “दांत” (“tooth”). While Pinyin has a generally accepted romanization system, Hindi transliteration is not so clear. For example, “daant” would also be a valid alternative for “दांत”.
Hindi sliding input transliteration
When we had a converter that converts sequences of letters to words (lexicon) and an automatic weighted language model for sequences of words, we developed a weighted converter to convert between Latin sequences of characters and alphabets of 22 Indian languages. Some languages have several scripts (for example, Bodo can be written in Bengali or Devangari), so between transliteration and native writing we created 57 input methods in just a few months.
The universal nature of the FST decoder allowed us to use all the work done earlier to support auto-completion, predictions, a rolling set and many UI functions without any additional effort, so our Indian users from the very beginning received excellent program quality.
Smarter keyboard
In general, our latest work allowed us to reduce the decoding delay by 50%, reduced the proportion of words that users had to manually correct by 10%, allowed us to start transliteration for 22 official languages of India, and led to the emergence of many new features that you might notice.
We hope that the latest changes will help you type on the keyboard of your mobile device. But we understand that this task is by no means solved. Gboard can still make assumptions that seem strange or of little use, and gestures can be recognized in words that a person would never have typed. However, our transition to powerful machine intelligence algorithms opens up new possibilities that we are actively exploring to create more useful tools and products for our users around the world.
Acknowledgments
This work was done by Cyril Allausen, Wise Alsharif, Lars Hellsten, Tom Ouyan, Brian Roark and David Rybach, with the assistance of Speech Data Operation. Special thanks to Johan Schalkwick and Corinne Cortes for their help.
* A set of appropriate algorithms is available in the OpenFst free library . ↑