Choose a DBMS to store time series

Pavel Filonov ( Kaspersky Lab )
Today we will talk about storing time series. I will try to tell you what approaches I used to try to throw out as much of my subjectivity as possible, replace it with something more objective, and leave the subjective look somewhere at the very end.

Almost always recently in my practice I notice that it is almost never necessary to invent something new to solve standard problems. Almost always you just need to choose - how to choose yogurt in the store. You come, there is a shelf, there these rows are all made up, and you need to decide which one to choose: familiar, try a new one, either the most delicious, or the most useful. And they are all bright, beautiful, with advertising. All of one another is better.
The great ones have long said that this is a big problem. The fact that these bright curtains can slightly overshadow our choice.
How do we try? Anyway, honestly, objectively, it won’t work out completely. There will always be subjectivity in choice, otherwise it cannot be. But maybe it is possible somehow to level this subjectivity? Maybe clamp in some kind of controlled framework, so that some of this came out?
Today I will try to tell you what approaches I used to try to throw out as much of my subjectivity as possible, replace it with something more objective, and leave the subjective look somewhere at the very end.
Before this, however, I want to first talk a little bit about the task that stood. In my opinion, an understanding of the real problem, which in some sense can be felt - it always clarifies the situation. It allows you to better understand those or other decisions that have been made. Therefore, I will start with John McClain.

This is John - my hero. Who in childhood, when he watched him beat the terrorists, wanted to be like John McClain? Not all, yes, I see. So I really wanted to!
I watched him beat the terrorists in the first part, in the second, in the third. And it began to seem to me, most recently, that I was somewhat like him. It's hard to see the resemblance, I understand. Probably not external, but a little bit - what we are starting to do with him. In particular, in the fourth part of his adventures, he was not just fighting terrorists, he was fighting very harmful cyber-terrorists who were not just trying to capture and terrorize someone, who were trying to break into gas stations, trying to break down the power lines, who were trying to rebuild traffic lights in a big city. Imagine what will happen if chaotically rebuild traffic lights in Moscow? Perhaps nothing will change, but there is a suspicion that this should not be done immediately.
The film was released in 2007, it was buffoonery, humorous. What kind of cyber-terrorists are there, what kind of power station management, what kind of destruction?
The problem arose later, after the release of the film, in about 2010, when it seems that many people watched the film. Some even got into it. Unfortunately, not all of those who are infiltrated are good people. In particular, the name that sounds in the middle is one of the rather popular malware, which was discovered about six years ago, which had many skills, many purposes.

One of his most unpleasant assignments was hacking automated process control systems (APCS) and causing not just commercial harm by stealing information or erasing anything, but reprogramming technological processes to cause physical harm. In particular, because of his actions, the uranium enrichment program, in my opinion, in Iran, was thrown back several years ago. He simply disabled some of the enrichment plants. The situation, unfortunately, was repeated. Several cases have been officially reported. Reports were created that confirmed that these plants did not fail on their own, but directly due to the testing of some attacks, targeted attacks on the control system.
This task began to lead to a search for a solution. This is a problem, many believe that this is a problem. In process control systems, not everything is very good with security. It is necessary to introduce new security elements there and try to protect these objects. What kind of objects? Here, so that some kind of image was in front of my eyes, I just took some picture:

Some kind of factory, most likely an oil refinery, which does a very important and useful thing. And we need to try to protect him from those threats that can be viewed from the side of the cyber part. This is a difficult task, it is very multi-layered, I would say.
You can look at this factory from different angles. For example, you can look from the point of view of network behavior: draw a network topology, see who interacts with whom, who can interact with whom, who cannot. This is a single layer solution.
You can go down below and monitor how the end stations behave, what programs are launched on them, these are allowed programs or prohibited programs. You can follow this layer.
I work in the department, which is still on another layer, which monitors how the process itself works, how the relays turn on, the conveyors work, the tanks heat up, the fluid is chased through pipelines. And we, for example, look at this object like this.

Any technological process, in fact, is a dynamic system that changes over time. It is multidimensional, it has many characteristics. Here I drew five rows, for an average object there may be thousands, maybe tens of thousands. This is just some kind of artificial example to imagine how our data will look like with eyes.
Of course, the main task is processing on a stream. Because the historical data on hacking is interesting, but not so much. But in order to implement it, this data not only needs to be processed, but it is also desirable to save it somewhere. For historical investigations, for forensic. For example, it is very important for us to store large amounts of historical data for training our online processing systems.
From here, a concrete technical problem begins to arise. If we have such data (I’ll tell you a little about models), and we have their characteristics with which these data enter the system, how can we most rationally and rationally organize the storage subsystem to which we will access, in order to conduct historical analysis, or to request for our specific research? So we come to the problem.
The problem, however, is a little bit about the data scheme, so that you can get a little concrete idea of what is at stake. Already in such a slightly specific language.

Here one point in one row is usually characterized by three numbers: this is its certain identifier (channel number), 42 - temperature, 14 - pressure, 13 - relay on / off (possibly). The moment in time when something has changed in this dynamic system, and the value for which it has changed. The value can be real-valued, it can be integer, it can be logical. Real-valued describes them all.
A little bit about the characteristics, so that it can be seen that, probably, this has something to do with the subject of the conference. It’s not so simple with volumes.
Unfortunately, for an average object, the number of such rows totals about tens of thousands, in exceptional cases it can be an order of magnitude larger. With intensity, thank God, a little better. Typically, sensor values are collected on average once per second. Maybe a little more often, maybe a little slower, but the characteristics of real objects are about the same.
And we are starting to try a little bit to imagine the volumes in which we have to work. This is a very important point, because, in fact, from these numbers you can start to deduce something without which I, for example, feel very uncomfortable - without non-functional requirements.
When sometimes they say: “Make it fast and good,” but I don’t understand such words. I begin to torture a person: "And what is" fast "? And what is “good”? What is your data? How many volumes do you have? And what are your intensities? ” Only after this checklist has been passed and the main points are known, can I begin to try to at least imagine solutions.

True, it’s also not so simple there, there are many solutions, there is far from one there at all. I’m sure that each of you can now safely add another five of your favorite DBMSs to this list. Of course, everyone here simply does not fit. They are different. Some of them work well in one case, some work better in another case, some probably work well for the task that I talked about.
But which ones? How to understand? How to choose? This is a big problem. I come across her often and constantly. It is already very rare to think up a new one, almost always you just need to reasonably choose somehow from this set.
There are several approaches to this choice. The first - I called it a "non-engineering" approach.

Unfortunately, maybe I don’t know, fortunately, it is sometimes promoted. What are some examples of non-engineering approaches?
- For example, like this - they all stored in X, let's use it here too. It doesn’t matter that the task is different, the subject area is different - we know how X works.
- Or here’s such a painful way, when "We used it there, don’t do this, in any case, please." I have met such.
- The third is my favorite. Yes, I feel, many are in solidarity with me. But dangerous, a little dangerous, but beloved.
- We are at the conference with you, they talk about databases here. I probably don’t remember the conference, where they talk more about databases than here. And of course, the first thing is that people come after the next day to work, they say: "They told us about such a thing, let's try it!"
- I also like this one very much - the article came out somewhere, everything is great: the graphs are simply exponential flying up, the dollar is drawn at the top, everyone is happy. Let's choose this one.
Of course, the slide is humorous, but let's be honest - who will be able to stand up bravely now, introduce themselves and say that “really, I am such and such, and I used the unengineered approach”?
Can I ask any of the assistants? Please microphone.
Please introduce yourself and say so. Dare!
A remark from the audience: I am Vladimir Myasnikov. We used the approach “Let's take X, and we'll figure it out already.”
Thank you very much, Vladimir! Let's applaud!
By the way, we posted publicly available videos of the last five years of the conference of developers of high-loaded systems HighLoad ++ . Watch, study, share and subscribe to the YouTube channel .
This is how such a part of therapy. Do you know yes? To deal with a problem, you must first recognize it and admit to yourself. Vladimir is clearly a brave man, and many here are brave, they are ready to admit that this is a bad approach. Maybe there is another?

Let's call it engineering. He’s probably a little more complicated. It may even be somehow structured and decomposed. I tried my decomposition, it does not claim to be common. Let me tell you about it point by point and, in essence, it will be, at the same time, the content of the further part of the report.
- At first, it’s nice to read all the same. What is what has appeared in recent years? Because I wait with fear when the article “10 new databases that you must learn this week” arrives at me at Fidley. I feel that sooner or later this will happen. Everything appears there at such a speed that it is difficult to keep track of it, and one must constantly get acquainted with the literature. Including, through what you listen to at the conference: who tried what, who is happy with something, who is dissatisfied with something. And so we spread our experience to other people.
- Generally speaking, it would be nice to understand, if we choose, by what criteria - price, speed, scalability? You need to decide on them. It is impossible to select by all criteria. Most likely, your non-functional requirements can tell you which of the criteria in this problem, and only in this task, you should consider first and which second.
- This is the most interesting, such a long-awaited point: you have to choose whom to compare. There must be contestants. Unfortunately, comparing everyone is difficult. There must be some preliminary selection. When even before you get to specific numbers, you realize that this seems to be a solution, but it cannot. Or you just understand that you don’t have enough strength to measure everything, and then you need to choose what seems to you the most adequate so far. But, of course, this list is unlikely to consist of one item, hardly even two.
- I’ll probably talk about the fourth point most of all. If we choose what we measure, and even choose whom we measure, then a very delicate and very interesting question: “How do we do this?” Because, even if you take two people, and they choose that they measure the same thing and the same thing, they can do it completely differently, and the numbers can be very different. Therefore, somewhere, maybe I will go into unnecessary nuances, but, in my opinion, this is the most interesting part: how to measure it, how to reproduce it in one way or another. Here we will devote a lot of time to this.
- This is a rather difficult part, because then it needs to be implemented. She herself is so long, it requires some labor, work. We’ll talk about this later. In general, to conduct this testing, for each of the contestants to understand which numbers correspond to it. You need to do this with your hands, even write code. Oh my God!
- By the way, the results are sometimes not enough. If you bring a beautiful plate with the numbers "yours" and say: "Here is the result." They will say: “Well, good. So what?" There must be an analysis. The numbers are not enough. The numbers should always be followed by normal words that explain them, they reveal them, still try to convey the meaning of this result, and not just leave it in the form of bare numbers, saying: "Everything is clear."
- And in the end, any specific recommendations are required. Moreover, they can hardly be very strict, that "only this will do, and that's it." In fact, of course, there can be several solutions. It must be said, perhaps, with what degree of certainty this or that decision is suitable. For example, in the form of a report and specific recommendations.
- Sophisticated approach. When I wrote it down, more than three points - this is generally difficult, but here it turned out as many as eight. This approach, I see it, but very infrequently and I understand why. It is labor intensive. Indeed, you need to spend time, man-hours, if you want, some effort, although it would seem: "Let's take X, and then we'll figure it out later."
But here, if we spend time, we do it for something. Somewhere we want to save it. For example, I once realized that testing saves a lot of time on parsing "bugs". Maybe here we can save time? It is possible.
Who faced the situation when he had to change the database from release to release in production? Yes, few people came across. And who liked it? There are no hands at all. It is very dangerous.
If the choice was made unreasonable and blind, you have a risk of not falling into the non-functional requirements that you need. Especially if they start to change. Who did they change at one time? Yes, this is also possible. Therefore, these labor costs can be recouped, in the future, of course. That is, it is difficult to predict how much they will pay you back, but believe me, sometimes it’s worth it.
Here is our plan. Let's go over it. Let's start with a critical review of the literature.

I will mainly tell you what I didn’t like when I started reading. Any specific points. For example, a lot of database comparisons for a given task are carried out - who do you think? - The developers of these databases themselves.
I noticed one hundred percent correlation, really one hundred percent. If the developer of the Bingo-Bongo base I just invented makes comparisons, then there he wins - who knows the correct answer? - Bingo-BongoDB wins there. Yes, always. Amazing No matter what comparison goes. I am confused by this result. I am not ready to immediately trust him just like that. In general, I am a very gullible person in life, but when I put on the cap of an engineer, I immediately begin to doubt very much in many ways. For example, here in such reviews.
Another interesting point that made me laugh, but I often saw it. What do we need to do to correctly compare different DBMSs with each other? Of course, take different data. The funny thing is, when one article refers to another article, it says: “There they got that number, and we got that number. They had only data there - we have different data. They have one server - we have other servers. ” In general, what are you comparing? Also not very nice.
There are also better sources, at the end of the slide for those who wish there will be a link to what I liked just.
And most of the authors say that if you really want to choose wisely, solve your problem, do not look at what data they have and what load profiles they have. Take your load profiles, take your data and measure only on them. Only these numbers, and then not 100% certainty, will give you an idea of how this will work further, for a long time. Why not 100%? Most likely, if your system should work for two years, you are unlikely to test it for two years first. Your testing time will be more limited. Therefore, there is still danger, but it, of course, is greatly reduced.
Let's talk about the criteria. What will we compare?

I have chosen the most important for my task. There are not all the criteria by which a comparison can be made. I will not say which I dropped. Let’s, I’ll rather leave this to additional questions: “Why don’t you compare by this criterion?” I’ll tell you about what I’m comparing.
- For example, write bandwidth. It's important for me. I need to have time to keep it, fall on the disk and withstand the loads that I have registered. But the question turned out to be very difficult, incredibly difficult. When I see somewhere an article where they say: “There is so much bandwidth,” I begin to doubt - under what conditions was it tested? Because, in my experience, there are always addictions. For example, it changes with the size of the “batch” (how many in a data packet at a time are we trying to write there). It varies from the number of clients who write to the database. It is even a little different if we write to the database for a long time. For example, if we write 5 minutes, there may be one number, and if 12 hours, then other numbers may appear there that are not always similar to what is usually called “peak performance”. And it seems that this criterion in itself is no longer very trivial. It can already be seen from different angles. These are the three sides (on the slide above) from which I will consider this bandwidth in this report.
- Further, we do not just write there. We will probably ask later. We will read something from there. Therefore, it is important for us that this is fast enough. For my tasks, it’s relatively fast - I’ll tell you a little more when we get there. There, however, it is necessary to single out characteristic queries. What queries are specific to your system? In the task of storing metrics for industrial facilities, it is usually important for what interval we request: we need a sample for a day, we need a sample for a week, if we really need it, we need a sample for two weeks or a month. It is interesting to see how the execution time depends on this value. Maybe short queries will work out quickly. But what if we usually need in a week, and not in one hour? It will be necessary to look at different intervals, so "depending."
- A very important characteristic even for me is the degree of compression. Thank God, even according to the best calculations, this data can fit on one machine. I find myself lucky. It is very lucky that I can potentially record this on one machine. Maybe with backup in addition. But in order to guarantee that the hard drive does not overflow anyway - this is a very unpleasant situation when the hard drive overflows on the DBMS - it is advisable to understand how much you really need. Because if we know the amount of input information, on the hard drive it is completely different. It can sometimes be even a little more due to additional meta-information and indexes, and sometimes much less if good compression is built in. Therefore, this should also be measured.
Here are our criteria, here I will talk about them first of all. And we start with bandwidth, we still have HighLoad. This is one of the most interesting characteristics, not as trivial, however, as it turns out.
Before that, our "contestants". We will compare these four:

Here, I want to immediately describe one interesting point, which, most likely, will pop up among you. Why am I comparing specialized solutions (OpenTSDB and InfluxDB - they are "we are only a time series, this is our patrimony, we can’t store anything else practically") with a general-purpose DBMS? After all, it would seem that most likely the answer will be obvious that in many respects specialized is better.
The answer here, in fact, is, I’ll give it right away: on the one hand, yes, a specialized solution is good, but what if all your solutions fit into non-functional requirements? Should you make a zoo of different systems? Indeed, most likely, you will store not only time series, most likely, you have some other metadata and some richer data according to the model. Most likely, they will also need to be added somewhere. What if you do not produce a zoo of specialized solutions, but show that one solution copes with both the one and the other? Therefore, I was interested in taking solutions that, in principle, are already being used. In order to see how well they cope with this situation. In order, in extreme cases, not to produce a zoo.
Who happened to have several databases in a project? Who had two? Who has three? Who has four? Who has five? There are a few people left ... This, too, is not very good. Yes, my colleagues will agree with me. Thanks. It fits into good requirements, but for administration it is not a very convenient thing.
These are the four we will talk about.
A little bit tsiferok, where without numbers. What we are comparing with. Here, too, this slide is very important, because I want to insert such a disclaimer, and for you to understand it.

I will measure now not a DBMS. I will measure them in a whole bunch, that is, I automatically measure as if the client. Because I’m not very honestly interested in how the DBMS works, I don’t sell them. I am interested in how they will work precisely in my task, in my infrastructure, with my clients, with something close to reality.
Therefore, keep in mind - and this is a very important point - that the numbers that I will give are not pure DBMSs, they still attract everything that is described here. The fact that there is a Docker (where now without it is very convenient, I like it). There are specific clients that have one very interesting feature - they still have not very optimized drivers for storage, so in some places there may be problems with the drivers. And these are the realities of our world - not every programming language has the ideal drivers for all the DBMS that we need. Sometimes in these drivers - oh my goodness! - there are bugs, sometimes these are performance bugs, and we also need to cope with this and understand this.
And now to the most interesting.

The graphs have gone. About bandwidth is a very complicated thing. For a long time I tried to understand what it is, what kind of quantity it is? Is that a number? It is addiction? Is this, God forbid, an integral? Thank God, it turned out, it seems, that no.
At first, I tried to understand what I would measure and how I would do it. Let’s try to clarify what a blue chart is and how it is built. This is about testing methods.
I have a “volume knob”, very simple - how much I will try to record. I actually have two “pens” there: how many sensors I have in the system, and with what frequency they log their values. For example, I can “twist” the number of sensors, recording that each of them logs its values once a second. And then I start to “twist the knob” along the horizontal axis, my expected throughput, that is, 20 thousand is 20 thousand sensors, and each of them logs values once a second.
What is the vertical axis, where, in fact, is the blue graph and is plotted? This we take a "voltmeter" neat and begin to measure: how much we actually recorded in the DBMS? And it can also be done, it turns out, in various ways and cunningly! For example, here each point (well, they, of course, with approximation) is obtained in the following way: we start with such a load for five minutes, every second we log how much we recorded this second, we build a histogram of the distributions of these points and select the median. A very cool value, I like it, it's such a bandwidth, to the left of which exactly half of these points that we measured are located. That is, it guarantees us that at least half the time we wrote with such speed and no less.
Sometimes you can choose the average, but here it will give you a smaller figure. Why? Average, just averaging, it is sensitive to outliers. What if you accidentally had a hard drive busy for some amount of time, or someone else connected to your system and did something there for a couple of seconds? Then you can have such bad dips for a few seconds. Medium - it is very sensitive to these failures. I did not begin to draw it here, but the average is always less, and in this case, in my opinion, it does not show approximately the real state of things. Median shows better. I understand what it means. At least half the time we will write "no more slowly than so much."
We begin to get to the most interesting, you probably noticed. This flat line is the level. That is, we turn the “volume knob”, but does not get “louder". It would seem, probably, that it is. Here it is - bandwidth. It is impossible to write more to this DBMS, it seemed to me at first, but what if we change the way a little, how do we write? What if we start writing not one point at a time, but two points at a time? What will happen then? And we get another graph, red:

When for each insert, we do bulk insert. We insert not one point, but two, and “twist” the same “pen”. It turns out that this threshold is rising. So what is bandwidth? Little blue or red? And, in general, why so?
Here a stupid example comes to my mind, you will excuse me, but it is somehow close to me. Few related to DBMS. Let's suppose that in the evening the company has a good rest, has fun and decides to send someone for a bottle of milk. It seems to me that milk is best suited here. What does a person do? He dresses, shoes, takes the keys, goes out, goes down the elevator, goes to the store, looks for a shelf, takes milk, goes to the checkout counter, makes a “rush!”, Takes a bag, a bottle, rises, undresses, brings everything to the refrigerator! We have made a system with a throughput of "one bottle of milk for the time it went down."
Now we’ll think, “What if we ask him to take two bottles of milk?” What will this time difference be? The fact that at the checkout will be not “peak!”, But “peak-peak!”, And all the rest of the time will be the same. And we get a system that has a bandwidth of almost twice as much.
If we return to the world of DBMS, then how will this scene look like? This is probably preparing a request, opening a socket, establishing a network connection, sending a request, server-side parsing of a request, preparing it, executing, possibly lifting from a hard disk, preparing a response, serializing a response, packing, sending to a socket, client-side deployment and reading. Probably, here, if you also ask to write down two points, and not one, here are the common pieces, this will allow us to start saving a little.
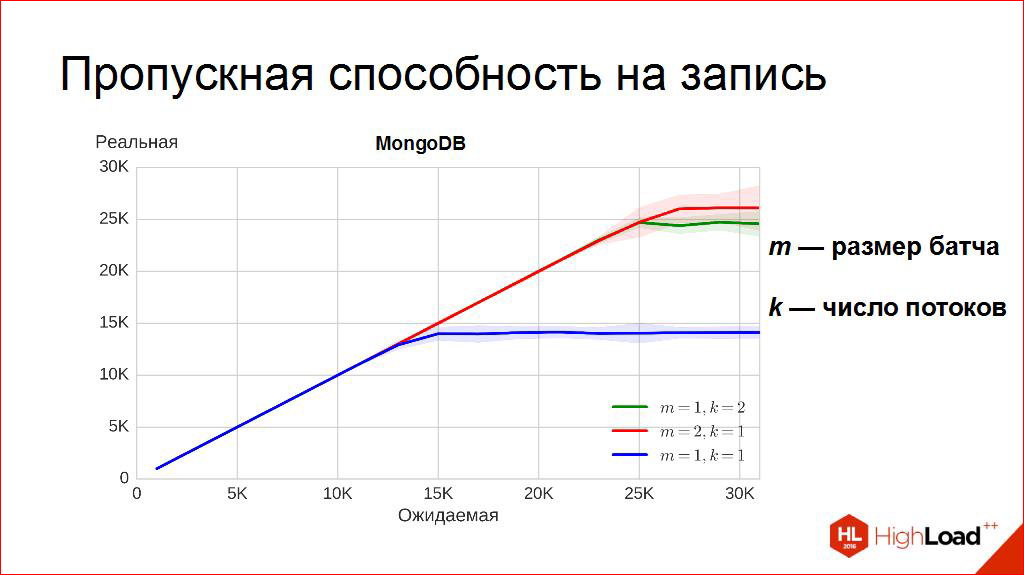
There is another interesting approach, it turns out. Another axis that can be "twisted" - but what if we send two people for a bottle of milk? What if we write in two threads? There is also an interesting effect. We really do it faster than at one point at a time. Zelenenkaya is two streams, but one point at a time. It is curious, by the way, that they did not overlap. The green ones are a little smaller. True, within the limits of fluctuations, but still the characteristic median is less than that of the red one.
That is, there are two axes, you can twist two more “knobs”. You can “twist” how much we write at a time, and you can “twist” how many clients we write in this system.
Let's twist them, it's interesting. These "pens", they can be "twisted", see what happens. For example, we will "twist" the batches. This is one of my favorite “pens”, it is very easy to implement, so I love to “twist” it.
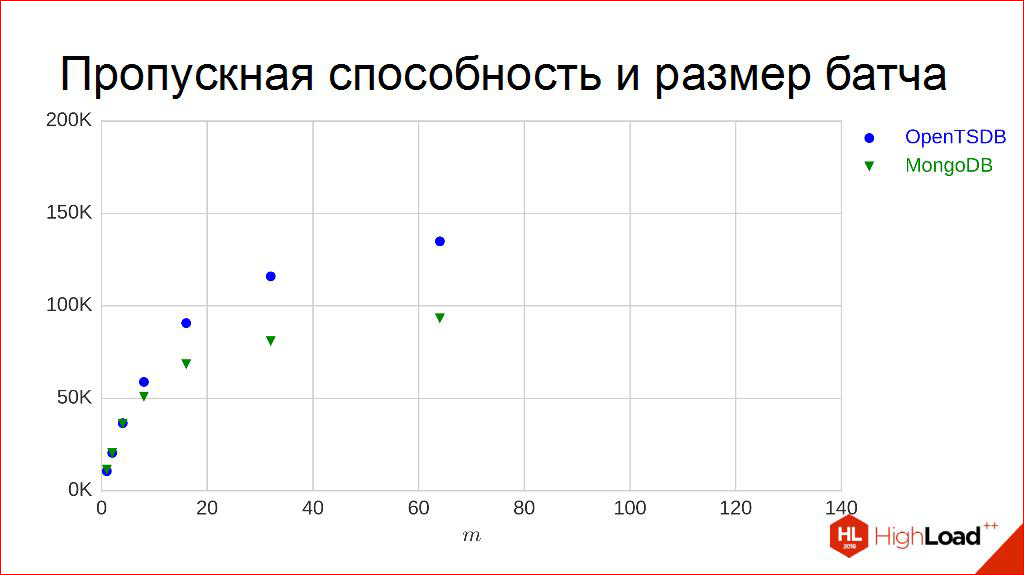
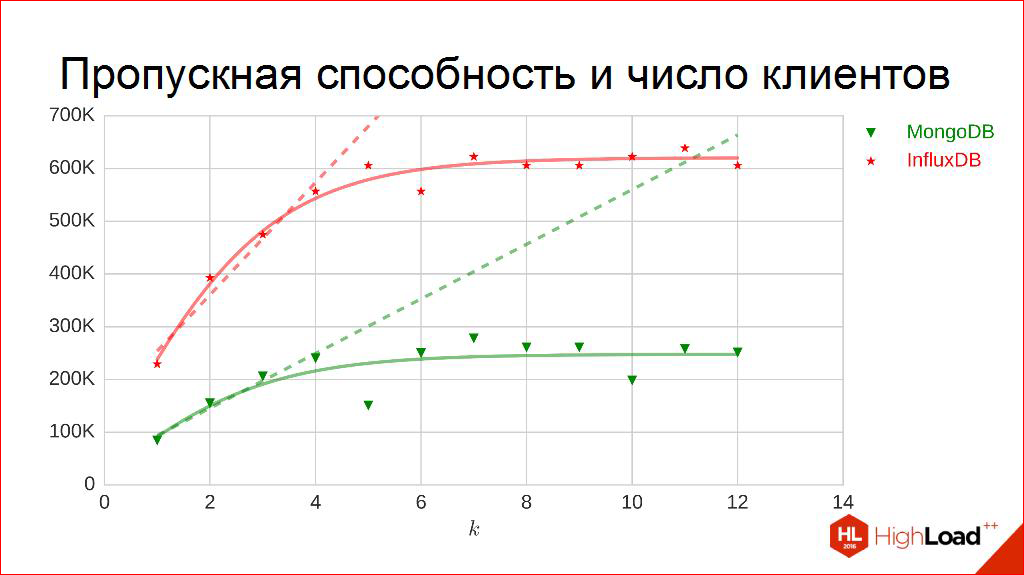
Let's go to other charts. Let's take different batches, emki, and build our points. It can be seen that for degrees two they are taken. The points are constructed in exactly the same way: the experiment lasts for 5 minutes, and the median is calculated from all the bandwidths per second that are received. For two contestants. An interesting pattern is visible that, yes, it grows, but, by the way, somehow it starts to bend a little, that is, it obviously does not grow to infinity, maybe not very linear. Another interesting point is that if at some points they are very similar and behave approximately the same, then at others they begin to differ slightly and behave differently.
Is bandwidth really this curve? Some kind of addiction? Maybe. But working with curves and dependencies is terribly inconvenient. They are inconvenient to enter into tables. It’s convenient to work with numbers. What would we come up with, to take and turn each of them into a digit, into a number that is convenient to measure: more or less. Because everyone on this chart is inconvenient to place, they may begin to intersect. Ambiguities. Let's think about how this can be done.
The first thing, when I see this, my hand begs to take a pen and do it like this - to draw some kind of curvilinear:

Some kind of laws, probably, dependencies. Then a moment of truth arises. It is necessary to strain very much and to guess what kind of curvilinker it can be. You need to pick up something that looks like. There are many selection methods. One of the easiest and most beloved and used by me is to play a little with the axes. What if we start to postpone not batches along the horizontal axis (now we need to strain a little), but logarithms from batches? Logarithmic axis. Rarely, maybe someone knows why it is used, but it is very useful in such situations, because in it this picture looks a little simpler:

It is more convenient to work with straight lines. Which, incidentally, tells us that the graphs before that were really logarithms. The direct ones are clear. Probably, even these angles can be counted. Here the title of the slide even reveals how this is done. There is not a very complicated linear regression method that will give us these angles, or rather, the tangents of these catch.
Further here is a subtle point. It is very debatable, and I really hope that someone will tell me later where I got it from. I am sure that somewhere it was described in due time and well thought out. And here’s the idea: instead of taking these graphs, let's take these angles, or rather, the tangents of these angles. The larger the angle, the better it seems, the better the number. The smaller the angle, the worse it seems, the less tangent. That is, we can try to introduce this relation of order here more strictly.
For example, for our competitors (these are not corners, these are the tangents of the angles I have recorded here), we get roughly the same measured dependencies of bandwidth on the size of the batch. In this case, for two.
Summarize the rest. And we’ll do one more trick.
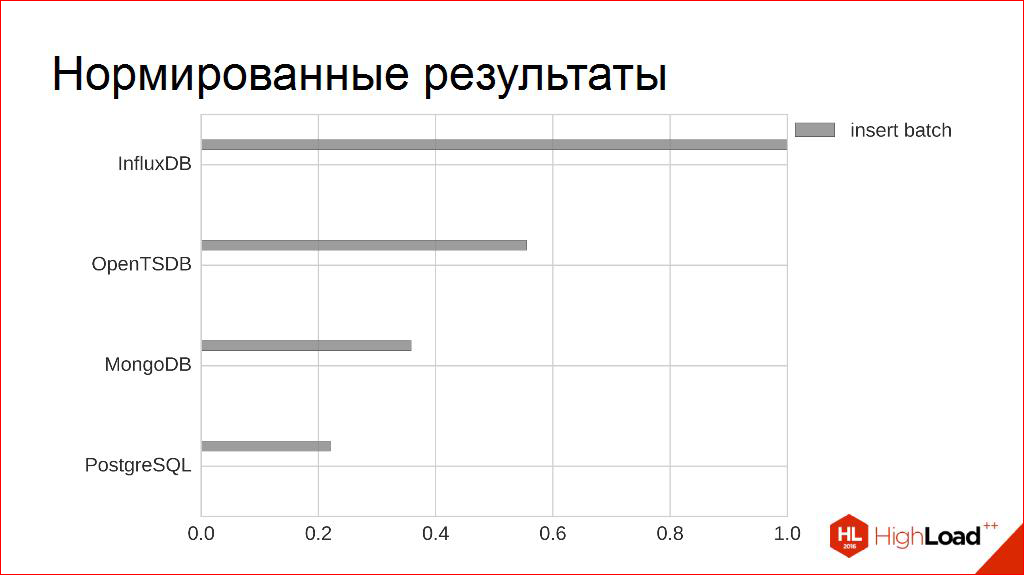
The absolute numbers - 20 thousand, 100 thousand, 200 thousand - they are great for advertising booklets, but I do not really need them. By the way, I only know that I need a minimum. I know, for example, that each of the competitors in terms of peak performance fits into my non-functional requirements, even with a margin, some with a large margin.
In order to compare them with other criteria later, I use a simple technique. I simply normalize them to the maximum one, and I get such a relative value from zero to one - who is more, who is less. Figuratively, by this criterion - who is better, who is worse.
It is clearly seen that there is still room in this plate for other columns to appear according to other criteria. Let's try to finish building them.

For example, bandwidth on the number of customers. Same. We measure. Only now, on the horizontal axis, we postpone how many streams we write, we get these points. It can be seen that they are starting to tremble a little. Here you can guess that curvulines can also be drawn. They will be logistic functions, i.e. with saturation. They really go to such a threshold and do not go any further.
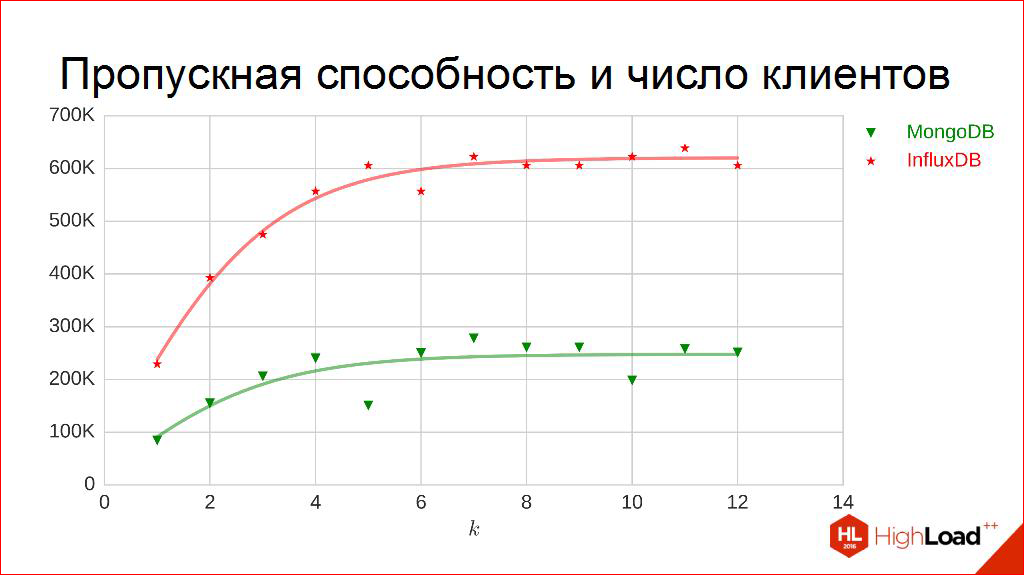
Why, by the way, does it look like this? Why so strange? In fact, our nature is limited and, for example, on the machine on which the number of cores that the DBMS can consume is limited by the environment. And, I think, from this graph you can immediately see how many cores this is.
I suggest. Well, let's try to think it over and let's all together now say how many kernels were issued to this DBMS? One two Three? Four? Some guessed, really four.
As soon as the nuclei end, terrible competition begins, and work in this area is virtually meaningless. We need to work in the field earlier, so here I use a different approach. I do not want to measure these curves as a whole, I want to measure only in those parts where they are linear, where this fierce competition does not yet exist. You never know, I have this machine with four cores, and what if I transfer to 20 cores, and what if someone is very lucky, it has 60 cores. There will probably be other curves, so here I will measure only the linear part. Here, in general, it falls more or less on some linear piece.
And the method is the same - direct, the tangent of the angle of inclination - here it is a digital. We can get figures of dependence, figuratively, bandwidth on the number of clients, as I propose to understand this in this report, and fill the plate with orange rectangles.

Get a measurement from this characteristic. Go further and deeper. For example, to watch, and what happens under load? There, in general, the most interesting thing happens. These are the most expensive experiments, because they last 10, 12 hours each. My longest experiment, in my opinion, is three days. For different DBMSs, how they behave. Some interesting general patterns are observed. For example, here is OpenTSDB under a load of 60 thousand:

In principle, everything is predictable enough, everything is fine. Sometimes a DBMS leaves for its DBMS affairs, does something there. Judging by the logs, she communicates very actively with HBase, that is, HBase does something very active, then returns. This, by the way, means that you need to be prepared for this, customers must be prepared. This, in general, is a good practice, because the DBMS can "recover into itself" a little. If she leaves forever - we don’t need it, but a little bit - maybe. But the rest of the time, everything is fine, everything is stable, well done!

80 thousand. Also. It seems that stability is sufficient, and even I will tell you more - stability here is understood a little formally. If the median (sometimes referred to as a fifty percent quantile) - this means half is to the left, then here I measured the ninety nine percent quantile. That is, I am interested in the fact that in 99% of the whole time the record in the DBMS is at the level at which I want. That is true for 80 thousand. At some points, of course, we can fall out, but they do not exceed 1%.
So, "OpenTSDB of a healthy person" still looks like.
And here is the “OpenTSDB smoker”:
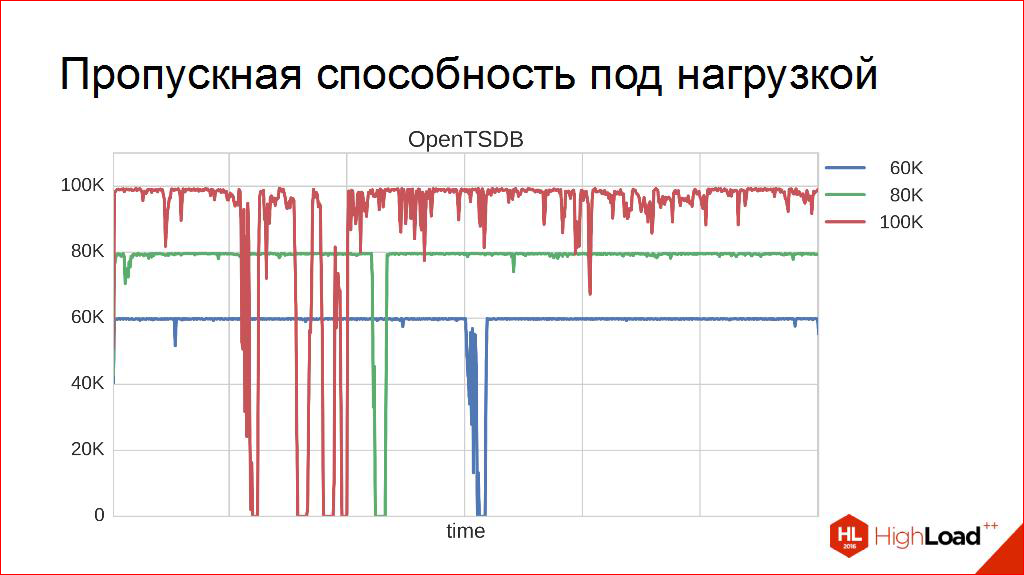
It can work at such a load, but there is clearly the ninety-ninth percentile, you see, this is not a hundred, it will obviously be much less. "Goes into itself" more often - you can understand, it is still necessary to withstand such loads. And this means that, looking at such a schedule, I would say: so, this thing under a hundred does not need to be kept in this installation. Under eighty - hold. One hundred for a long time do not turn on! At the peak load it can withstand even more, but I would not recommend keeping a hundred for 12 hours.
And then this threshold appears. Unfortunately, I could not calculate it exactly. The experiments went with a very large step. I stopped at the last step, at which this characteristic was satisfied. So that for 12 hours the system can work stably under the desired load.
And there were numbers of work under load. Naturally, they are much smaller than peak ones, but in this sense they are slightly more interesting, because they describe how it will last for days, and not how it will work for only five minutes. And here they are blue bars:
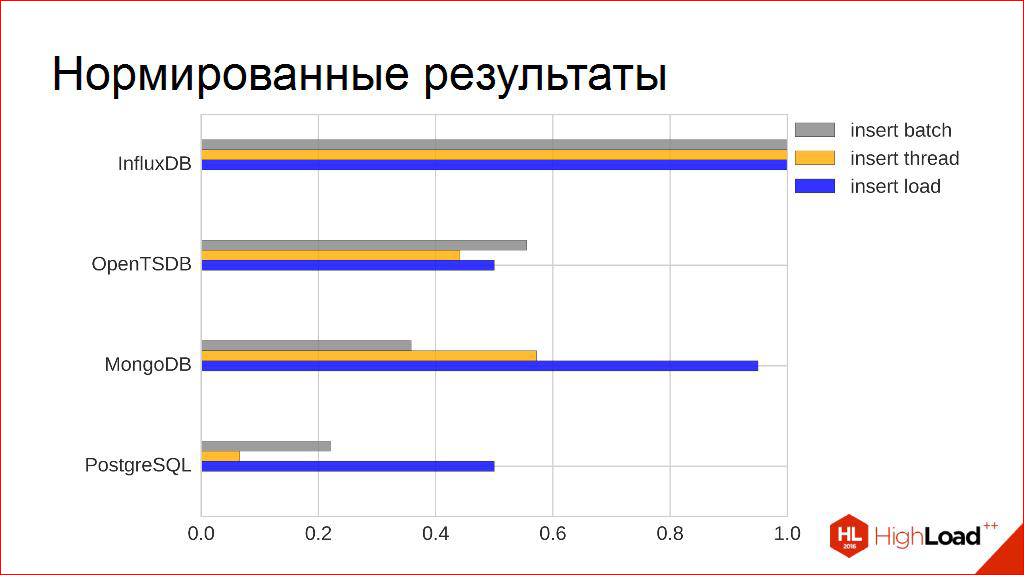
A little bit of "captaincy", probably, is already traced here. Although, if you look at others, you can already see interesting relationships there, we’ll talk about this later.
Let's go further. Query execution time.
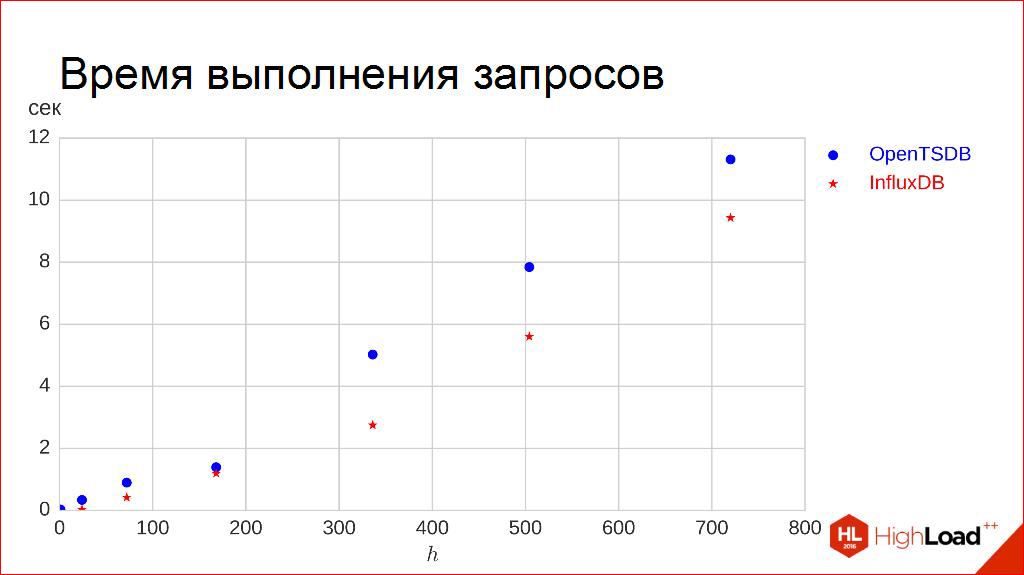
Here, thank God, a little easier. We set aside the length of the interval along the horizontal axis as much as we want. We want to request data - for a day, for three days, for a week we want to upload it to ourselves. We make 100 requests and measure the ninety-fifth percentile of the runtime, that is, I want 95% of my requests to be executed shorter than the time indicated there.
For me, this is more important, so this is not a median. Why? Because this is the most critical thing - the user clicked the button and the circle turns. And I'm not happy here that half of the circle will finish spinning faster than in 5 seconds. I want for 95% of users this circle to finish spinning earlier than in the allotted time.
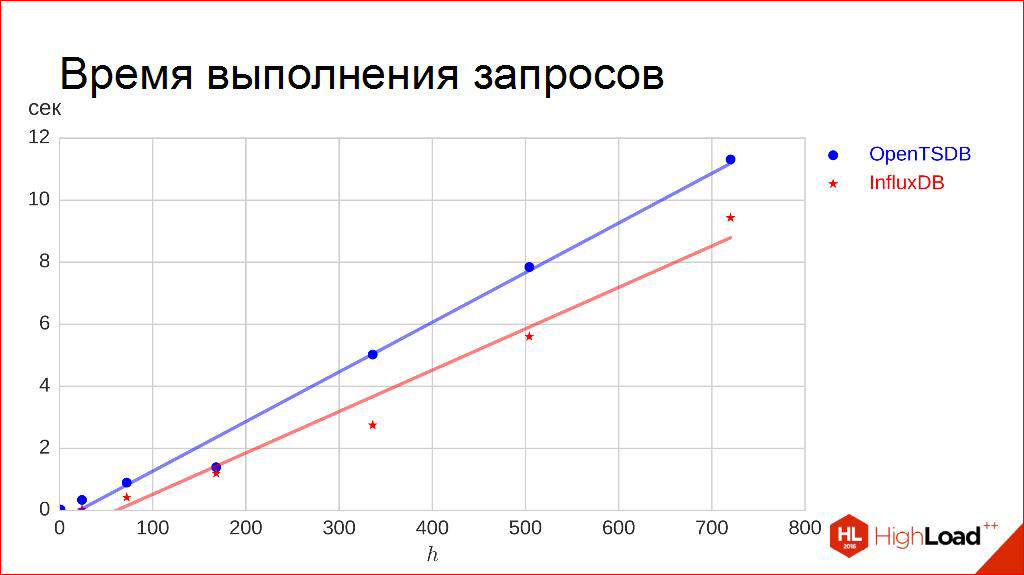
Everything is quite predictable here. The dependence is very linearly approximated, which is quite expected, so the reception goes the same. Here the only thing is that here we need to turn the situation a bit. Here, the more, the longer we wait, the worse. Therefore, here we take not the tangent of the angle of inclination, but the inverse to it. Then the reverse law works, feedback. We get green squares:
Yes, yes, I understand that at first there will be a little "captaincy". I tried to do everything honestly, with myself, at least, to be honest. And just give the results that I honestly received and can even reproduce them. I tried to ensure that these results were reproduced, and these graphs did not tremble. Let us assume that such a schedule on Monday does not differ much from such a schedule on Friday, so that in this sense they settle down.

About compression. I guess I can practically only show the results. The measurement is very simple. We load the approximate amount of traffic per month, we know how much it takes in raw form, we look at how much the DBMS took on the hard drive. Including all meta-information, even I did not consider that it could reserve something for itself additionally. Here I was a little rude. I just take how much she took on the disk extra. Received the ratio. And here it is, compression ratio.
By the way, someone had even more than one, because there is a lot of meta information, you still need to store indexes, you need to store some additional identifiers, service fields. Someone had less than one, it can be seen that good compression works. Especially for those who knew that they would add real numbers. Yes, they shake them very well, really.
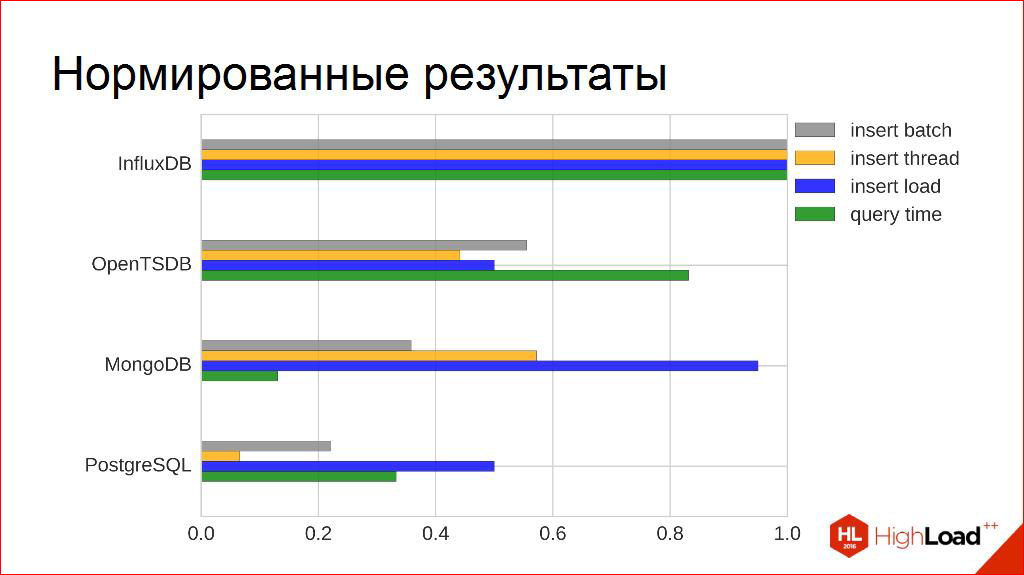
Got our intermediate result. It seems that, yes, the result is obvious, but I still wanted to go further, I did not want to stop on this chart. Although, here you can already draw some conclusions. If you wanted to bring this to some kind of automatism, reproducibility, and think: “If the situation were a little more complicated, what would I do next with these graphs?” What if there was no top, top contestant? After all, it’s very strange there. Someone in one is good, someone wins in another. How can we make this multi-criteria comparison?

Let's get some math involved. Take this tablet and rewrite it. I would not say that this is more convenient, but more convenient for us, the view. Number plate Rows are our competitors, and columns are our criteria that were on the previous chart. Now we’ll add the thing that I have been waiting for a long time and thought about where to add it: which of these criteria is more important to me than the others; more important, less important.
I can, in principle, give way, but my colleagues really know. It seems that this approach is familiar to many.
This we declare out of competition. We introduce our matrix of weights. Further, I think, you guess what will happen. Multiply. We receive. Outside of the competition, we are cleaning up.

Here he is our winner.
What if we slightly change the weight matrix? What if we single out something more important?

I will first show an artificial example, the second criterion is very important to us (this is the dependence of bandwidth on the number of clients). If we then do everything formally, our winner will be different.
Here, of course, this is all a bit of an artificial example. Such a small “captaincy”, because of the one whom I excluded out of competition, he seems to be good. And when I got this result, yes, at first I was a little ashamed - that I would come to people, I would tell them some extra things, is everything clear there?
So I started looking, maybe something that I don’t know.

Maybe find someone who will compete, some dark horse, who can show himself in comparison with our competitor.

He began to study who went out recently. I came across one very interesting project. The last contestant who looked interesting in advertising booklets. The source code could be read, they are sane, I liked it. And it was interesting to drive him through the same chain.
I probably will only show the final result, where unexpected effects began to appear. And I already didn’t see such a certainty in them. If we now leave only the obvious leaders, and try for them the same tale trick, then there it may well make sense.
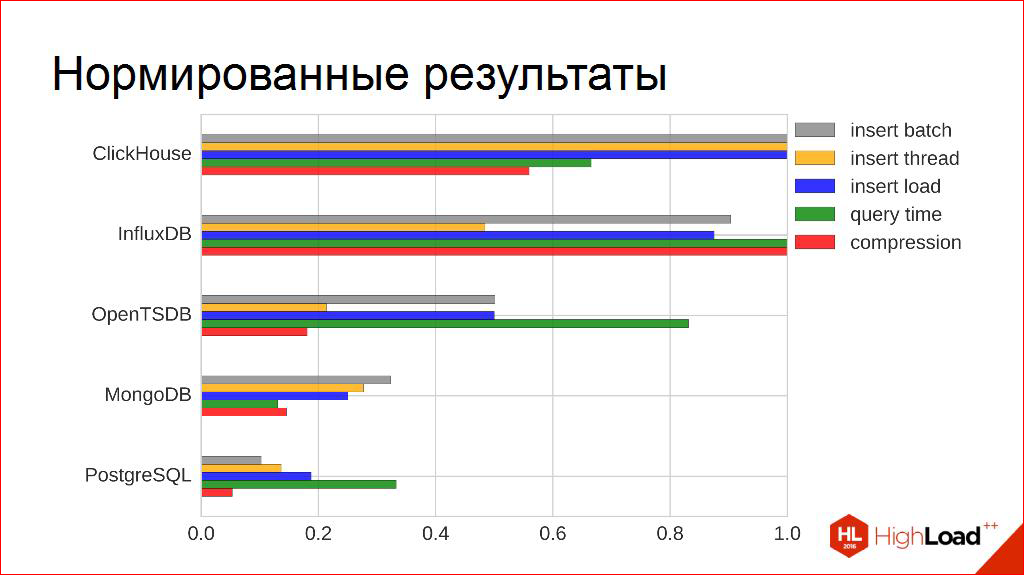
Equally, when it’s all the same, we have one winner.

If we single out some criteria as slightly more important, it is different. They begin to change. And it is here that we are trying to introduce our subjectivity. Look, we subjectively measure non-contestants, we subjectively measure the criteria by which it is important for us to look out. And depending on this we get different results.

In principle, probably these are the main thoughts that I wanted to convey, so I proceed smoothly to the conclusion. In addition, my time is already running out, I think.
My conclusion is “captain's”, which I myself am trying to formulate:
- check on your data, on your systems - this is very useful;
- just a little math never hurts, believe me, it makes you smarter in the eyes of others;
- here is such an interesting point that colleagues, apparently, are well aware - subjective assessment can also be measured. The main thing is to know that you are measuring in it.
In principle, that’s all.

Thanks for attention.
Who cares, you can follow the links below, but I have everything.
Sources:
- Y. Bassil . A Comparative Study on the Performance of the Top DBMS Systems - paper
- C. Pungila, O. Aritoni, TF. Fortis . Benchmarking Database Systems for the Requirements of Sensor Readings - paper
- B. Cooper ,, A. Silberstein, E. Tam, R. Ramakrishnan, and R. Sears . Benchmarking Cloud Serving Systems with YCSB - paper
- T. Goldschmidt, H. Koziolek, A. Jansen. Scalability and Robustness of Time-Series Databases for Cloud-Native Monitoring of Industrial Processes –paper
- T. Person.InfluxDB Markedly Outperforms Elasticsearch in Time-Series Data & Metrics Benchmark – blogpost
- Д. Калугин-Балашов.Как выбрать In-memory NoSQL базу данных с умом? -slides
- B. Schwartz. Time-Series Databases and InfluxDB– blogpost
- K. Eamonn and K. Shruti. On the Need for Time Series Data Mining Benchmarks: A Survey and Empirical Demonstration – paper
- R. Sonnenschein.Why industrial manufactoring data need special considerations –slides
- S.Acreman. Top10 Time Series Databases – blogpost
- J. Guerrero. InfluxDB Tops Cassandra in Time-Series Data & Metrics Benchmark – blogpost
- J.Guerrero.InfluxDB is 27x Faster vs MongoDB for Time-Series Workloads – blogpost
- Яндекс открываетClickHouse -blogpost
Thank you, I am ready to answer your questions.
Question: Hello. Thanks for the report. Such a question: when you measured under load, what did everything rest on? Rested against iron, in memory, in the processor? Or were these the limitations of the engine itself?
Answer: This is, let’s say, auxiliary work that the engine must constantly do. That is, it is clear that, most likely, the recording is constantly constantly first in memory, but it must be periodically flushed to disk. And at that moment subsidence began. This was clearly visible both from the logs and the way the system behaved. Because, I did not begin to draw here, I automatically wrote graphs of the load on the hard drive. They correlated very well with bandwidth failures.
Question:I wanted to ask: and requests for parallel recording, how were things with them?
Answer: Here I tried to imitate the real situation. Here are those timeline graphs of requests. This system was constantly and in a recording load. I approximately put, though not hundreds of thousands, I took my indicators, in my opinion, I took 20 thousand per second record. He held her non-stop. It was at this moment that I made inquiries and measured.
Moreover, there I came across one problem. I will now take the opportunity to tell a little more.
At first, everything was very fast. I did not understand why. And then I realized - I was making the same requests. And as soon as I started randomly choosing the channel for which I request, and randomly choosing the interval for which I request - the numbers immediately returned to normal. And, yes, magic did not happen. It really doesn't always work fast. Especially if we want to upload data for a week.
Question: You said that you are not very interested in how the DBMS works, but, probably, you started them with some parameters, with some settings? I mean, for example, the same OpenTSDB has a lot of things to twist. And the rest, too. Did you take a default, or did you use append mode instead of compaction in OpenTSDB?
Answer: Good question. Thanks a lot. I will answer him like that.
First, of course, part of me is lazy, and does not want to bother in detail with the settings for each of them. I perfectly understand that if you take a good DBA, he will come and say: “You do not understand anything. So now I’ll do it all, and it will work. ” But I do not always have it.
Therefore, of course, I am interested in systems that behave well by default. But somewhere I used mailing lists, wrote to people, asked to explain some facts that I discovered. They advised me. In particular, the PostgreSQL mailing list very well advised that I need to set it up correctly in order for my data to go better and the artifacts that I observed are gone. In particular, they advised me how to use VACUUM correctly, when, in which areas.
OpenTSDB. No, I did not change append / compaction. In my opinion, I have something in the storage settings, but now, unfortunately, I don’t remember exactly what. But, to be honest, there’s a detailed setup, just like that, I’m twisting all the knobs, I just didn’t do it here. Most of them are systems that from their Docker containers are stable, standard, are delivered and put on the system.
I agree with my colleague, yes, the comparison is not very correct, so I say: “I am not comparing a DBMS. I compare how I use them. ” Therefore, maybe this justifies me, but maybe the other way around. Thanks.
Question:Pavel, can you continue with the way you use them, the query (queries) that you gave? What kind of query is this, are indexes and aggregates used, some database features related specifically to working with queries? What did you compare?
Answer: There are several supplies I used.
First of all, which OpenTSDB, InfluxDB - they have built-in indexes, so they immediately use them in time.
For the rest, I went in two ways: the first - I just built the index, the queries worked well, but a little worse - the record. And, moreover, it was very inconvenient, for example, to keep data in one collection or in one table. Clearly, it was growing instantly. Therefore, my colleagues will forgive me, I made a very bad reception, which I really love, I began to split up by the day simply. Each day has its own tablet. And did not use indexes.
After that, of course, requests became very complicated for me, because now I had to push this information into the client, but, for example, my rotation became very simple and very convenient: DROP - everything, DROP - everything. And the queries began to work well for both writing and reading.
Very silly requests, only on a time interval. The maximum is that this is aggregation, for example, the average over a certain interval, that is, not every second, but, say, the average per minute.
Question: Pavel, thanks for the interesting report. I wanted to ask this question: First you said that you need to know your data, you need to know your load profile, and measure on it, yes, and on the hardware that you have? Why not simplify and measure everything on the right throughput, immediately on the right size of batches, to immediately compare in such characteristics? It would not be necessary to derive these tangents, do all the complex math?
Answer:I can answer here is how. Yes, thank God, I have, frankly, a document, non-functional requirements are written there. But I know that they can change. And those 20 thousand that I have to keep time today, in a year can turn into 40 thousand. Therefore, in spite of the fact that each of the contestants fit into them, of course, it would be interesting for me to choose which one will withstand the change in non-functional requirements. This time.
The second one. The size of the batch is a very interesting feature. You have to pay for it. The more you have a batch, the more latency you have. You need to create buffers somewhere that will add extra delay to your data. Therefore, making them very large, if latency is important to you, is, generally speaking, dangerous. Therefore, it would be interesting to look here just from the point of view of the minimum sizes of the batch, but since I’m processing this entire stream online, and not read from the DBMS, latency was not important to me here, so of course I then twisted the sizes of batches almost to the maximum.
Which, incidentally, is different for different systems. For example, OpenTSDB already works well at sixty-four, but InfluxDB starts to behave normally from five thousand at a time when you write. By the way, I then looked, in standard drivers it sometimes costs like a constant: write 5 thousand at a time. And the buffer is located in the driver itself, which, by the way, I really did not like. I want to be able to manage this, generally speaking, that is, how much it is actually stored on the client when it goes to the database. Therefore, for example, for InfluxDB I had to write my driver on top of their HTTP protocol.
Question: Tell me, if I understood correctly, you set up the structure and base scheme for each base individually. And somehow you tried to adjust the applications to the resulting structure?
Answer:Of course. Especially when I started to use this not-so-beautiful approach of cutting each individual plate by the day, when the drivers received a request for range for more than one day, they needed to understand that it really needs to be broken or, if the database allows , make a request at once on several tables.
Question: Trying to use asynchronous access to the database or pools? Something like that?
Answer: I almost always went to recording there asynchronously. Yes, the pool was used, in particular, if it was an HTTP protocol, there I tried to arrange a connection pool, and everyone kept alive, that is, not to repeat them. This is probably all that was used.
Thanks!
Contacts
→ pavel.filonov@kaspersky.com
→ github
Этот доклад — расшифровка одного из лучших выступлений на профессиональной конференции разработчиков высоконагруженных систем Highload++, а конкретно — секции «Базы данных, системы хранения».
Любителям экзотики мы можем порекомендовать доклад "Обзор перспективных баз данных для highload" от Юрия Насретдинова на ближайшей Backend Conf.
В этом докладе Юрий рассмотрит несколько перспективных баз данных, которые пока еще не очень популярны, но которые определенно ждет успех в будущем, особенно для highload-проектов. Юрий расскажет о Tarantool, ClickHouse и CockroachDB, о том, как они устроены, и почему он считает, что они в будущем станут стандартом де-факто, как раньше был MySQL, а сейчас — MongoDB.