No free lunch. Introduction to Kaggle Data Analysis Competitions
- Tutorial
The purpose of the article is to introduce the Kaggle data analysis competition to a wide audience . I will talk about my approach to participation using the Outbrain click prediction competition as an example, in which I participated and took the 4th place out of 979 teams, finishing the first of the speakers alone.
To understand the material, knowledge about machine learning is desirable, but not required.
About me - I work as a Data Scientist / Software Engineer in captify.co.uk . This is the second major competition at Kaggle, the previous result is 24/2125, also a solo. I have been studying machine learning for about 5 years, programming - 12. Linkedin profile .
The main task of machine learning is to build models that can predict the result based on input data that differ from those previously reviewed. For example, we want to predict the value of the stocks of a particular company after a given time, given the current value, market dynamics and financial news.
Here, the future value of the shares will be a prediction, and the current value, dynamics and news will be input.
Kaggleit is primarily a competition platform for data analysis and machine learning. The range of tasks is completely different - classification of whales for species, identification of cancerous tumors, assessment of the value of real estate, etc. The organizer company creates a problem, provides data and sponsors a prize fund. At the time of writing, 3 competitions are active, the total prize pool of $ 1.25M is a list of active competitions .
My last competition - Outbrain click prediction, the task is to predict which advertisement the user clicks from those shown to him. Sponsor of the competition - Outbrain promotes various content, such as blogs or news. They place their ad units on many different resources, including cnn.com, washingtonpost.com and others. Since a company that receives money for user clicks, they are interested in showing users potentially interesting content.
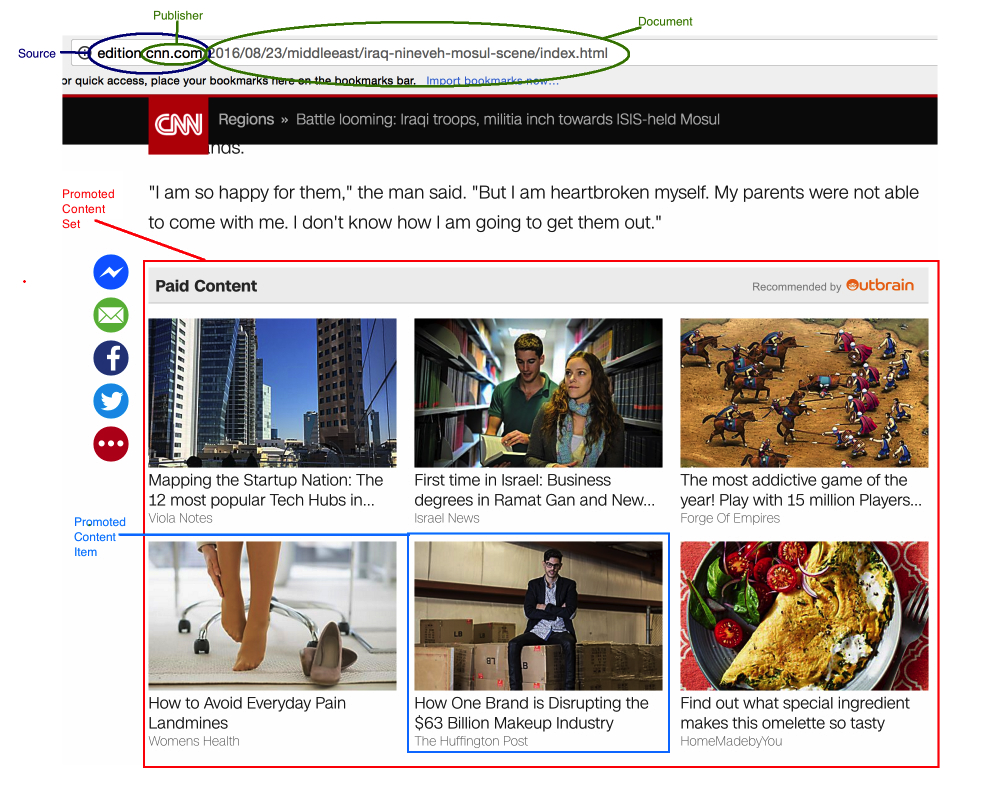
The formal description of the task is to place the advertisement shown to the user in this block in the descending order of probability of clicking on the advertisement.
The amount of data provided is quite large, for example, a clicklog file in the region of 80GB. An exact description of the input data can be obtained on the competition page .
The provided data is divided into 2 parts - those for which the participants know which banner the user will click (training data), and the data for which the result needs to be predicted is test. At the same time, Kaggle knows the real results for the test data.
Competitors use training data to build models that predict the result for test data. In the end, these predictions are loaded back, where the platform, knowing the real results, shows the accuracy of the predictions.
First of all, it is worthwhile to deal with the data that is available to the participants of the competition. On the Data page, as a rule, there is a description of the structure and semantics, and on the Competition Rules page, a description of whether external data sources can be used, and if so, whether it is worth sharing them with others.
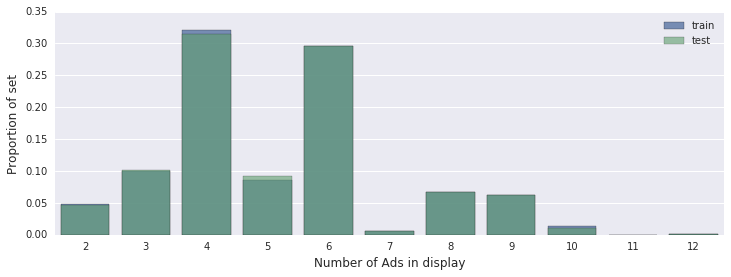
The first thing I usually do is pump out all the data and understand the structure, dependencies, so that they correspond to the statement of the problem. For these purposes, it is convenient to use Jupyter + Python. We build various graphs, statistical metrics, look at the data distribution - we do everything that helps to understand the data.
For example, let's build the distribution of the number of advertisements in one ad unit:
Also, on Kaggle there is a Kernels section where the code can be executed directly on their laptops and usually there are guys who make various visualizations of the available dataset - this is how we begin to use other people's ideas.
If you have questions about the structure, dependencies, or data values, you can search for the answer on the forum, or you can try to guess for yourself and get an advantage over those who (haven't) guessed yet.
Also, often in the data there are Leaks - dependencies, for example, temporary, which allow you to understand the value of the target variable (prediction) for a subset of the tasks.
For example, in Outbrain click prediction, from the data in the click log it was possible to understand that the user clicked on a specific advertisement. Information about such leaks may be published on the forum, or may be used by participants without publicity.
When everything is clear with the statement of the problem and the input data as a whole, I start collecting information - reading books, studying similar competitions, scientific publications. This is a wonderful period of the competition, when it is possible in a very short time frame to significantly expand your knowledge in solving problems like that posed.
Studying such competitions, I review his forum, where winners usually describe their approaches + study the source code of the solutions that are available.
Reading publications introduces the best results and approaches. It’s also great when you can find the original or recreated source code.
For example, the last two Click-Prediction competitions were won by the same team. Description of their decisions + source codes + reading forums of these competitions approximately gave an idea of the direction from which you can start work.
I always start by initializing the version control repository. You can lose important pieces of code even at the very beginning, it is very unpleasant to restore it later. I usually use Git + Bitbucket (free private repositories)
Validation, or testing of predictions, is an assessment of their accuracy based on the chosen metric.
For example, in Outbrain click prediction, you need to predict which of the displayed ads a user clicks on. The data provided is divided into two parts:
Model training takes place on the training data, in the hope that the accuracy on the test data will also improve, while it is assumed that the test and training data are taken from one sample.
In the learning process, a moment often occurs when the accuracy with respect to training data increases, but with respect to test data it begins to decline. This is because the capacity of the model allows you to remember or adjust to the test suite.
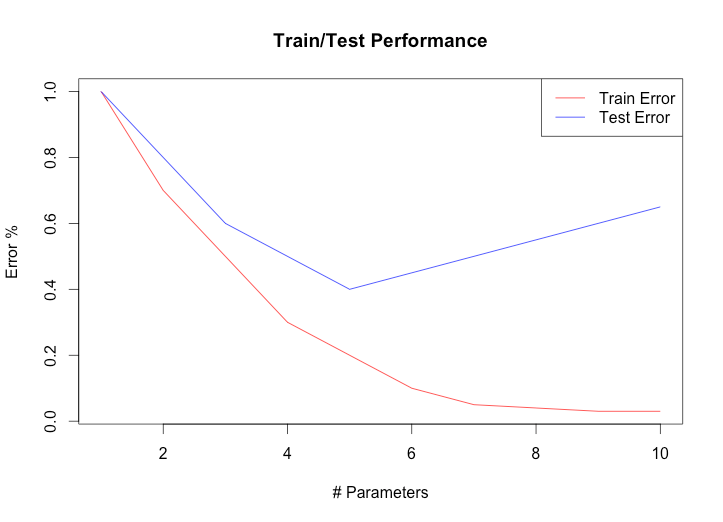
This phenomenon is called overfit. We will discuss how to deal with it below, for now it’s enough to understand that it is necessary to check the accuracy on data that the model has not seen .
Despite the fact that Kaggle makes it possible to evaluate the accuracy of the solution (regarding test data) by uploading it to the site, this assessment approach has several disadvantages:
It would be nice to have a local accuracy assessment system, which will allow:
Local (cross) validation is perfect for these purposes. The idea is simple - we divide the training set into training and validation and we will use validation to evaluate accuracy, compare algorithms, but not for training.
There are many validation methods, as well as ways to separate data; it is important to follow a few simple rules:
The adequacy of local validation can be checked by comparing the improvement shown locally with the real improvement obtained after downloading the solution to Kaggle. It is good when changes in the local assessment give an idea of a real improvement.
The model can be represented as a black box or a function that receives data at the input and returns a result. The results can be of various types, the most commonly used:
In Outbrain competition, it was necessary to rank ads by the probability of a user clicking on it. A simple and effective way to achieve this is to use the classification task, predict the probability of a click, and sort the ad in the block according to the probabilities issued by the classifier:
Classifier predictions:
The format in which decisions are made:
Evaluation metric is a function that shows how accurately the prediction corresponds to real data. For each type of task, there are many metrics - for example, regression is often based on the difference of the squared values. The competition used MEAP (Mean Average Precision) - a metric that takes into account not only the number of correct answers, but also the difference in sorting order.
Consider the simplest algorithm, when we consider that most likely the user will click on the most popular advertisement - the one with the maximum number of clicks / views (Click-through Rate - CTR). In this case, we have 2 values for the input parameters to the model - the ad id and whether the ad was clicked. There is no special machine learning here, the usual statistical metric.
Suppose this is our training data, let us group ads under displayId that are shown to one user in one block:
To form the first sign, we use the formula adClicked = max adId sum (adId, clicked == 1) / sum (adId) It is
convenient to represent the input values as a vector for one case (often called a feature vector), and a matrix for the entire data set is denoted by X . The target variable (in our case, Clicked) is y
Now, when forming the answer, for each displayId, we sort the displayed ads by feature_1 and get the answer in the form:
display_id, ad_id
1,2 1
2,1 3
The first thing to do is to check the accuracy of the model using the validation mechanism that we have already developed. A frequency-based model with smoothing returns a result significantly better than random predictions:
You can expand the model, and calculate CTR based on the user's region, and count statistics for all encountered combinations adId * country * state:
adClicked = max adId sum (adId, clicked == 1, country == displayCountry, state == displayState) / sum (adId)
It is important to build traits for training only from the training data set, excluding validation and test sets, otherwise we will not be able to adequately evaluate the accuracy of the model. If k-fold cross validation is used, it will be necessary to build such signs k times.
Another approach is to generate attributes in such a way as to reduce the retraining of the model. For example, I added statistics on the frequency of clicks only for those ads where the number of views is N> 10 (the value is selected during validation). Motivation - if we add frequencies where the number of ad views == 1, an algorithm with sufficient complexity (for example, a decision tree) will determine the possibility of this feature to unambiguously predict the answer and can only use it to predict, it is clear that this solution will be quite naive.
The entire process of generating features from input data is often called Feature Engineering, and is often a decisive factor in successful competition, since algorithms and meta-algorithms for model training are generally public.
I considered several general groups of signs that define:
Let's consider each group in more detail:
Using a training data set and a pageview log, you can choose a lot of interesting things about the user - which advertisements / advertising campaigns he clicked and which ones he always ignored. Since the meta-information about the pages to which the advertisement leads was provided (landing page), it is possible to identify which categories of pages or topics / entities the user is interested in - if the landing page is sport.cnn, and the user reads sports news often at this time of day or this day of the week , you can try to use it as a sign.
Such and similar signs will help later to find users with similar preferences and through them to predict whether the user will click on the advertisement.
I did the selection of signs manually - based on the change in the accuracy of the assessment before / after adding.
Here it’s worth starting with a simple listing of meta-information about advertising / landing-page | advertising campaign + CTR similar signs based on geolocation, time of day, day of the week - for example, stateCTRCamp: frequency of clicks on an advertising campaign (combines ads) in some state
By context, I mean both the page on which the advertisement is displayed and the time of display + user information: geo + device type. Knowing the time, you can list all the ads and pages that the user visited \ clicked yesterday \ day ago \ for the last hour. You can define content that is currently popular, and so on.
country, state, platform, county, pageDocumentCategories, countryCTRAdv, campaignId, advertiserId, userDocsSeenFromLogYesterday, userClickedThisAdvertiserTimes, hourOfDay, userDocsClickedToday, lastAdvUserClicked
The total number of user-generated documents is about 120 targeted ad serving). more extended (incomplete) list in the technical description of the solution on the competition forum.
Most of the features used are categorized - for example, country, and one-hot-encoding is used to turn into a binary feature. Some numerical signs were also converted into binary ones by referring to the numerical interval, and the formula log (x + 1) was used to smooth some.
Coded characters occurring less than 10 times were not taken into account. The total number of encoded features is> 5M; hashing was not used to reduce the dimension.
Let’s build a logistic regression model that receives simple numerical signs - the frequency of clicks in the country and state:
countryAdCTR = sum (adId, clicked == 1, country == displayCountry) / sum (adId)
stateAdCTR = sum (adId, clicked == 1, state == displayState) / sum (adId) The
formula for the probability of clicking on an ad will be:
y * = f (z), z = w1 * countryAdCTR + w2 * stateAdCTR, f (z) = 1 / (1 + e (- z))
f (z) - logistic function , returns values in the interval [0: 1]. The learning algorithm selects the coefficients w1 and w2 in such a way as to reduce the difference between y * and y - i.e. will achieve maximum similarity of predictions and real values.
Add the categorization attributes advertiser and view_page_domain to the model, after converting them to binary using the one-hot-encoding method, example:
Categorical:
One-hot-encoded:
The formula will be:
z = w1 * countryAdCTR + w2 * stateAdCTR + w3 * advertiser + w4 * view_page_domain
Since advertiser and view_page is a vector, w3 and w4 will also be vectors.
In CTR prediction, it is very important to take into account the interaction of signs, for example, the page on which the advertisement is displayed and advertiser - the probability of clicking on Gucci ads on a Vogue page is completely different than on Adidas ads., the model can be supplemented by the interaction between advertiser and view_page:
z = w1 * countryAdCTR + w2 * stateAdCTR + w3 * advertiser + w4 * view_page_domain + w5 * advertiser * view_page_domain
We already know that advertiser and view_page are vectors, which means the dimension of the w5 vector will be the length of the advertise vector r * length of the view_page vector.
Several problems are associated with this - firstly, it will be a very large vector - all the possible domains on which the ad is shown multiplied by the number of all possible advertisers. Secondly - it will be very sparse and most values will never take the value 1 - most combinations we will never meet in real life.
FMs are great for CTR prediction tasks, since they explicitly take into account the interaction of features, while solving the problem of sparseness of data. A great description can be found in the original publication , here I will describe the main idea - each attribute value receives an integer vector of length k, and the result of the interaction of the characteristics is the scalar product (dot-product) of vectors - see the formula in the publication in the Model Equation section for the formula.
During the analysis of the best models, I found that the last 2 CTR prediction competitions were won by guys with the Field-aware Factorization Machines (FFM) model (ensemble ) . This is a continuation of FM, but now the signs are divided into n fields - a kind of group of signs, such as a group of signs consisting of documents viewed earlier, a group of other advertisements in this ad unit, etc. Now each sign is presented in the form of n vectors of dimension k - it has a different representation in each other group of signs, which allows for more accurate consideration of the interaction between groups of signs. Description and details also see in the publication .
FFMs are very prone to retraining, an early stop is used to deal with this - after each iteration of the model improvement, the accuracy is evaluated on the validation set. If accuracy drops, training stops. I made several changes to the code of the standard library, the most important of which was to add a quality assessment based on the MEAP metric that was used to calculate the result on Kaggle, instead of the standard logloss.
One of the teams that took a place in the top 3 also added the possibility of pairwise optimization in FFM.
To allow an early stop when teaching the whole model, I randomly divided the training set in the 95/5 distribution and used 5% as a validation one.
The final result is a simple average of the results of 5 models on different random distributions with slightly different sets of attributes.
This method of mixing results on training set subsamples is called bagging (bootstrap aggregation) and often allows you to reduce variance, which improves the result. Also, it usually works well for mixing the results of gradient boost models (xgboost / lightGBM)
Models based on gradient boosting stably gave worse results (comparable to FM), pairwise optimization did not improve the picture much. Also, the feature generation for FFM based on the leaves of trees from boosting did not work for me . The FFM → FFM or XGBOOST → FFM stack was consistently worse than the FFM on the entire data set.
Финальные результаты
The initial file merge was done using Python, and I usually use Jupyter for data mining and analysis. It also filtered the click log only for users found in the training / test sets, which allowed it to be reduced from 80 to 10GB.
The original Feature engineering was also written in Python, however, given the huge amount of data, which means the time it takes to process it, I quickly switched to Scala. The difference in speed, according to a rough estimate, was about 40 times.
To quickly iterate and evaluate the improvement in accuracy, I used a subset of the data, about 1/10 of the total.
This allowed us to get the result in about 5-10 minutes after launch + models were placed in the laptop's memory.
Generating input files for the final model takes about 3 hours on a 6-core machine. Total recorded files> 500GB. The approximate training and prediction time was 10-12 hours, the memory usage was about 120GB.
The whole process is automated using scripts.
Most of the work was done on a Dell Alienware laptop (32GB RAM). Over the past few weeks, I have also used a workstation (i7-6800, 128GB RAM) and in the last week the memory optimized x4large and x8large AWS machines, up to 2x in parallel.
The article is dedicated to my dear wife, who is very difficult to worry about when her husband is at home, but at the same time he is not.
Also thanks to Artem Zaik for comments and review.
From my point of view, participating in competitions on Kaggle and the like is a great way to get acquainted with ways to solve real problems using real data and evaluating your decisions against real competitors. Performing at a high level also often requires the allocation of a lot of time and effort, especially with full-time work and no one has canceled his personal life, so such competitions can be considered as competitions with yourself too - to defeat yourself first.
To understand the material, knowledge about machine learning is desirable, but not required.
About me - I work as a Data Scientist / Software Engineer in captify.co.uk . This is the second major competition at Kaggle, the previous result is 24/2125, also a solo. I have been studying machine learning for about 5 years, programming - 12. Linkedin profile .
About Machine Learning and the Kaggle Platform
The main task of machine learning is to build models that can predict the result based on input data that differ from those previously reviewed. For example, we want to predict the value of the stocks of a particular company after a given time, given the current value, market dynamics and financial news.
Here, the future value of the shares will be a prediction, and the current value, dynamics and news will be input.
Kaggleit is primarily a competition platform for data analysis and machine learning. The range of tasks is completely different - classification of whales for species, identification of cancerous tumors, assessment of the value of real estate, etc. The organizer company creates a problem, provides data and sponsors a prize fund. At the time of writing, 3 competitions are active, the total prize pool of $ 1.25M is a list of active competitions .
My last competition - Outbrain click prediction, the task is to predict which advertisement the user clicks from those shown to him. Sponsor of the competition - Outbrain promotes various content, such as blogs or news. They place their ad units on many different resources, including cnn.com, washingtonpost.com and others. Since a company that receives money for user clicks, they are interested in showing users potentially interesting content.
The formal description of the task is to place the advertisement shown to the user in this block in the descending order of probability of clicking on the advertisement.
The amount of data provided is quite large, for example, a clicklog file in the region of 80GB. An exact description of the input data can be obtained on the competition page .
The provided data is divided into 2 parts - those for which the participants know which banner the user will click (training data), and the data for which the result needs to be predicted is test. At the same time, Kaggle knows the real results for the test data.
Competitors use training data to build models that predict the result for test data. In the end, these predictions are loaded back, where the platform, knowing the real results, shows the accuracy of the predictions.
General plan for participation in competitions
- Analysis of the task and available data
- Search and study of possible solutions
- Development of a local accuracy assessment mechanism
- Generating features for a model
- Implementation (if there is no ready-made algorithm) + model building
- Accuracy rating
- Iterating paragraphs 4-6, adding new models (most of the time)
- Ensemble and stack of models (optional)
- Teaming (optional)
Beginning of work
Input data
First of all, it is worthwhile to deal with the data that is available to the participants of the competition. On the Data page, as a rule, there is a description of the structure and semantics, and on the Competition Rules page, a description of whether external data sources can be used, and if so, whether it is worth sharing them with others.
The first thing I usually do is pump out all the data and understand the structure, dependencies, so that they correspond to the statement of the problem. For these purposes, it is convenient to use Jupyter + Python. We build various graphs, statistical metrics, look at the data distribution - we do everything that helps to understand the data.
For example, let's build the distribution of the number of advertisements in one ad unit:
Also, on Kaggle there is a Kernels section where the code can be executed directly on their laptops and usually there are guys who make various visualizations of the available dataset - this is how we begin to use other people's ideas.
If you have questions about the structure, dependencies, or data values, you can search for the answer on the forum, or you can try to guess for yourself and get an advantage over those who (haven't) guessed yet.
Also, often in the data there are Leaks - dependencies, for example, temporary, which allow you to understand the value of the target variable (prediction) for a subset of the tasks.
For example, in Outbrain click prediction, from the data in the click log it was possible to understand that the user clicked on a specific advertisement. Information about such leaks may be published on the forum, or may be used by participants without publicity.
Analysis of approaches to solving the problem
When everything is clear with the statement of the problem and the input data as a whole, I start collecting information - reading books, studying similar competitions, scientific publications. This is a wonderful period of the competition, when it is possible in a very short time frame to significantly expand your knowledge in solving problems like that posed.
Studying such competitions, I review his forum, where winners usually describe their approaches + study the source code of the solutions that are available.
Reading publications introduces the best results and approaches. It’s also great when you can find the original or recreated source code.
For example, the last two Click-Prediction competitions were won by the same team. Description of their decisions + source codes + reading forums of these competitions approximately gave an idea of the direction from which you can start work.
First code
Version control
I always start by initializing the version control repository. You can lose important pieces of code even at the very beginning, it is very unpleasant to restore it later. I usually use Git + Bitbucket (free private repositories)
Local (cross) validation
Validation, or testing of predictions, is an assessment of their accuracy based on the chosen metric.
For example, in Outbrain click prediction, you need to predict which of the displayed ads a user clicks on. The data provided is divided into two parts:
| Data type | Clicked ad ID for each impression |
| Training | Everyone knows |
| Test | Only known to competition organizers |
Model training takes place on the training data, in the hope that the accuracy on the test data will also improve, while it is assumed that the test and training data are taken from one sample.
In the learning process, a moment often occurs when the accuracy with respect to training data increases, but with respect to test data it begins to decline. This is because the capacity of the model allows you to remember or adjust to the test suite.
This phenomenon is called overfit. We will discuss how to deal with it below, for now it’s enough to understand that it is necessary to check the accuracy on data that the model has not seen .
Despite the fact that Kaggle makes it possible to evaluate the accuracy of the solution (regarding test data) by uploading it to the site, this assessment approach has several disadvantages:
- Limit on the number of solution downloads per day. Often 2-5
- Latency of this approach - counting solutions for a test suite, writing to a file, downloading a file
- Nontriviality of automation
- Probability of retraining regarding test data
It would be nice to have a local accuracy assessment system, which will allow:
- Quickly evaluate accuracy based on selected metrics
- Automate enumeration of algorithms and / or hyperparameters
- Save assessment results with other information for later analysis
- Exclude retraining regarding test sample
Local (cross) validation is perfect for these purposes. The idea is simple - we divide the training set into training and validation and we will use validation to evaluate accuracy, compare algorithms, but not for training.
There are many validation methods, as well as ways to separate data; it is important to follow a few simple rules:
- Separation should not change over time to exclude influence on the result. For this, for example, you can save the validation and training sets separately, save the row indices or use the standard random.seed
- If you have features that are built on the entire data set - for example, the frequency of clicks on a specific advertisement depending on time, such signs should only be calculated using a training set, but not valid, so knowledge about the answer will not “flow” »To model
- If the data is located depending on the time - for example, in the test set there will be data from the future, relative to the training set, it is necessary to observe the same distribution in the division of the training / validation set
The adequacy of local validation can be checked by comparing the improvement shown locally with the real improvement obtained after downloading the solution to Kaggle. It is good when changes in the local assessment give an idea of a real improvement.
Building models
Introduction
The model can be represented as a black box or a function that receives data at the input and returns a result. The results can be of various types, the most commonly used:
| Model type | Return Type | Example |
| Regression | Real number | The value of a company’s share in 1 minute |
| Classification | Category | Solvent / insolvent borrower |
In Outbrain competition, it was necessary to rank ads by the probability of a user clicking on it. A simple and effective way to achieve this is to use the classification task, predict the probability of a click, and sort the ad in the block according to the probabilities issued by the classifier:
Classifier predictions:
| Displayid | Adid | Clickprob |
| 5 | 55 | 0.001 |
| 5 | 56 | 0.03 |
| 5 | 57 | 0.05 |
| 5 | 58 | 0.002 |
The format in which decisions are made:
| Displayid | Adids |
| 5 | 57 56 58 55 |
Evaluation metric is a function that shows how accurately the prediction corresponds to real data. For each type of task, there are many metrics - for example, regression is often based on the difference of the squared values. The competition used MEAP (Mean Average Precision) - a metric that takes into account not only the number of correct answers, but also the difference in sorting order.
Input parameters
Consider the simplest algorithm, when we consider that most likely the user will click on the most popular advertisement - the one with the maximum number of clicks / views (Click-through Rate - CTR). In this case, we have 2 values for the input parameters to the model - the ad id and whether the ad was clicked. There is no special machine learning here, the usual statistical metric.
Suppose this is our training data, let us group ads under displayId that are shown to one user in one block:
| displayId | adId | clicked |
| 1 | 1 | 0 |
| 1 | 2 | 1 |
| 2 | 1 | 1 |
| 2 | 3 | 0 |
To form the first sign, we use the formula adClicked = max adId sum (adId, clicked == 1) / sum (adId) It is
convenient to represent the input values as a vector for one case (often called a feature vector), and a matrix for the entire data set is denoted by X . The target variable (in our case, Clicked) is y
| displayId | adId | feature_1 |
| 1 | 1 | 0.5 |
| 1 | 2 | 1 |
| 2 | 1 | 0.5 |
| 2 | 3 | 0 |
Now, when forming the answer, for each displayId, we sort the displayed ads by feature_1 and get the answer in the form:
display_id, ad_id
1,2 1
2,1 3
The first thing to do is to check the accuracy of the model using the validation mechanism that we have already developed. A frequency-based model with smoothing returns a result significantly better than random predictions:
| Model name | Result |
| Random guess | 0.47793 |
| Frequency with smoothing | 0.63380 |
You can expand the model, and calculate CTR based on the user's region, and count statistics for all encountered combinations adId * country * state:
| adId | Country | State | clicked |
| 1 | US | CA | 0 |
| 2 | US | TX | 1 |
| 1 | UK | 1 | 1 |
adClicked = max adId sum (adId, clicked == 1, country == displayCountry, state == displayState) / sum (adId)
It is important to build traits for training only from the training data set, excluding validation and test sets, otherwise we will not be able to adequately evaluate the accuracy of the model. If k-fold cross validation is used, it will be necessary to build such signs k times.
Another approach is to generate attributes in such a way as to reduce the retraining of the model. For example, I added statistics on the frequency of clicks only for those ads where the number of views is N> 10 (the value is selected during validation). Motivation - if we add frequencies where the number of ad views == 1, an algorithm with sufficient complexity (for example, a decision tree) will determine the possibility of this feature to unambiguously predict the answer and can only use it to predict, it is clear that this solution will be quite naive.
The entire process of generating features from input data is often called Feature Engineering, and is often a decisive factor in successful competition, since algorithms and meta-algorithms for model training are generally public.
Outbrain competition features
I considered several general groups of signs that define:
- User - to whom the advertisement is shown
- Advertiser
- Context + Time
Let's consider each group in more detail:
Custom tags
Using a training data set and a pageview log, you can choose a lot of interesting things about the user - which advertisements / advertising campaigns he clicked and which ones he always ignored. Since the meta-information about the pages to which the advertisement leads was provided (landing page), it is possible to identify which categories of pages or topics / entities the user is interested in - if the landing page is sport.cnn, and the user reads sports news often at this time of day or this day of the week , you can try to use it as a sign.
Such and similar signs will help later to find users with similar preferences and through them to predict whether the user will click on the advertisement.
I did the selection of signs manually - based on the change in the accuracy of the assessment before / after adding.
Advertiser Signs
Here it’s worth starting with a simple listing of meta-information about advertising / landing-page | advertising campaign + CTR similar signs based on geolocation, time of day, day of the week - for example, stateCTRCamp: frequency of clicks on an advertising campaign (combines ads) in some state
Context
By context, I mean both the page on which the advertisement is displayed and the time of display + user information: geo + device type. Knowing the time, you can list all the ads and pages that the user visited \ clicked yesterday \ day ago \ for the last hour. You can define content that is currently popular, and so on.
Features Used
country, state, platform, county, pageDocumentCategories, countryCTRAdv, campaignId, advertiserId, userDocsSeenFromLogYesterday, userClickedThisAdvertiserTimes, hourOfDay, userDocsClickedToday, lastAdvUserClicked
The total number of user-generated documents is about 120 targeted ad serving). more extended (incomplete) list in the technical description of the solution on the competition forum.
Most of the features used are categorized - for example, country, and one-hot-encoding is used to turn into a binary feature. Some numerical signs were also converted into binary ones by referring to the numerical interval, and the formula log (x + 1) was used to smooth some.
Coded characters occurring less than 10 times were not taken into account. The total number of encoded features is> 5M; hashing was not used to reduce the dimension.
An example of a simple model - logistic regression
Let’s build a logistic regression model that receives simple numerical signs - the frequency of clicks in the country and state:
countryAdCTR = sum (adId, clicked == 1, country == displayCountry) / sum (adId)
stateAdCTR = sum (adId, clicked == 1, state == displayState) / sum (adId) The
formula for the probability of clicking on an ad will be:
y * = f (z), z = w1 * countryAdCTR + w2 * stateAdCTR, f (z) = 1 / (1 + e (- z))
f (z) - logistic function , returns values in the interval [0: 1]. The learning algorithm selects the coefficients w1 and w2 in such a way as to reduce the difference between y * and y - i.e. will achieve maximum similarity of predictions and real values.
Add the categorization attributes advertiser and view_page_domain to the model, after converting them to binary using the one-hot-encoding method, example:
Categorical:
| Sample | Advertiser |
| 1 | Adidas |
| 2 | Nike |
| 3 | BMW |
One-hot-encoded:
| Sample | Isadidas | Isnike | IsBMW |
| 1 | 1 | 0 | 0 |
| 2 | 0 | 1 | 0 |
| 3 | 0 | 0 | 1 |
The formula will be:
z = w1 * countryAdCTR + w2 * stateAdCTR + w3 * advertiser + w4 * view_page_domain
Since advertiser and view_page is a vector, w3 and w4 will also be vectors.
In CTR prediction, it is very important to take into account the interaction of signs, for example, the page on which the advertisement is displayed and advertiser - the probability of clicking on Gucci ads on a Vogue page is completely different than on Adidas ads., the model can be supplemented by the interaction between advertiser and view_page:
z = w1 * countryAdCTR + w2 * stateAdCTR + w3 * advertiser + w4 * view_page_domain + w5 * advertiser * view_page_domain
We already know that advertiser and view_page are vectors, which means the dimension of the w5 vector will be the length of the advertise vector r * length of the view_page vector.
Several problems are associated with this - firstly, it will be a very large vector - all the possible domains on which the ad is shown multiplied by the number of all possible advertisers. Secondly - it will be very sparse and most values will never take the value 1 - most combinations we will never meet in real life.
Factorization Machines (FM)
FMs are great for CTR prediction tasks, since they explicitly take into account the interaction of features, while solving the problem of sparseness of data. A great description can be found in the original publication , here I will describe the main idea - each attribute value receives an integer vector of length k, and the result of the interaction of the characteristics is the scalar product (dot-product) of vectors - see the formula in the publication in the Model Equation section for the formula.
Outbrain competition model
Field-aware Factorization Machines (FFM)
During the analysis of the best models, I found that the last 2 CTR prediction competitions were won by guys with the Field-aware Factorization Machines (FFM) model (ensemble ) . This is a continuation of FM, but now the signs are divided into n fields - a kind of group of signs, such as a group of signs consisting of documents viewed earlier, a group of other advertisements in this ad unit, etc. Now each sign is presented in the form of n vectors of dimension k - it has a different representation in each other group of signs, which allows for more accurate consideration of the interaction between groups of signs. Description and details also see in the publication .
FFM Training
FFMs are very prone to retraining, an early stop is used to deal with this - after each iteration of the model improvement, the accuracy is evaluated on the validation set. If accuracy drops, training stops. I made several changes to the code of the standard library, the most important of which was to add a quality assessment based on the MEAP metric that was used to calculate the result on Kaggle, instead of the standard logloss.
One of the teams that took a place in the top 3 also added the possibility of pairwise optimization in FFM.
To allow an early stop when teaching the whole model, I randomly divided the training set in the 95/5 distribution and used 5% as a validation one.
The final result is a simple average of the results of 5 models on different random distributions with slightly different sets of attributes.
This method of mixing results on training set subsamples is called bagging (bootstrap aggregation) and often allows you to reduce variance, which improves the result. Also, it usually works well for mixing the results of gradient boost models (xgboost / lightGBM)
What didn't work
Models based on gradient boosting stably gave worse results (comparable to FM), pairwise optimization did not improve the picture much. Also, the feature generation for FFM based on the leaves of trees from boosting did not work for me . The FFM → FFM or XGBOOST → FFM stack was consistently worse than the FFM on the entire data set.
| Model name | Result |
| My best single model result | 0.69665 |
| My best result (mix of 5 models) | 0.69778 |
| 1st place best result | 0.70145 |
Финальные результаты
Код, инфраструктура и железо
Код
The initial file merge was done using Python, and I usually use Jupyter for data mining and analysis. It also filtered the click log only for users found in the training / test sets, which allowed it to be reduced from 80 to 10GB.
The original Feature engineering was also written in Python, however, given the huge amount of data, which means the time it takes to process it, I quickly switched to Scala. The difference in speed, according to a rough estimate, was about 40 times.
To quickly iterate and evaluate the improvement in accuracy, I used a subset of the data, about 1/10 of the total.
This allowed us to get the result in about 5-10 minutes after launch + models were placed in the laptop's memory.
Generating input files for the final model takes about 3 hours on a 6-core machine. Total recorded files> 500GB. The approximate training and prediction time was 10-12 hours, the memory usage was about 120GB.
The whole process is automated using scripts.
Iron
Most of the work was done on a Dell Alienware laptop (32GB RAM). Over the past few weeks, I have also used a workstation (i7-6800, 128GB RAM) and in the last week the memory optimized x4large and x8large AWS machines, up to 2x in parallel.
Thanks
The article is dedicated to my dear wife, who is very difficult to worry about when her husband is at home, but at the same time he is not.
Also thanks to Artem Zaik for comments and review.
Conclusion
From my point of view, participating in competitions on Kaggle and the like is a great way to get acquainted with ways to solve real problems using real data and evaluating your decisions against real competitors. Performing at a high level also often requires the allocation of a lot of time and effort, especially with full-time work and no one has canceled his personal life, so such competitions can be considered as competitions with yourself too - to defeat yourself first.