Localization of Unity games in Hindi
- Tutorial

By publishing my game on the Play-Market, I localized it only in two languages: English and Russian. I also posted review articles on the game, respectively, only on Russian-language and English-language forums. The statistics of the first month made it possible to determine the list of countries in which the game began to be actively downloaded. Therefore, it was decided to consolidate the success of adding localization to a number of languages. Among others, India showed interest in the game.
For help in localizing the Hindi game, I turned to my old Indian friend, Dr. Rudra Narayan Pandey, who kindly agreed to help me with this. I provided Rudra with a table of game phrases, he quickly translated everything into Hindi, and I, without any back thought, just as quickly copied the translation into the localization JSON file. And, pleased, he sent Rudre a build for verification. Oh, how naive I was then!
Rudra only condescendingly smiled at my naivety and said that the text contains a huge number of inaccuracies, which were not in his translation. According to Rudra’s description, the text in the game looked as if by analogy in Russian instead of “” there would be “YO”, and instead of “» ”-“ TS ”. And for me, who was completely uninitiated in the intricacies of Hindi, everything looked the same: that the translation was in an MS Word document, that the text was in the game. But, carefully following the drawing of the text, I really noticed the difference: as if in some places the letters were rearranged, and in some places they looked different. Neither my friend nor I was privy to the secrets of fonts, and we could only guess about the reasons for this behavior of the text.
Search for a solution
After some wandering through the vast expanses of the Internet, the reason was found out. The problem turned out to be that Unity does not support working with GSUB tables and GPOS fonts. The first, GSUB (Glyph Substitution Table), is responsible for replacing the sequence of characters with one ligature , and the second, GPOS (Glyph Positioning Table), for adjusting the relative position of the characters.
If for the Russian text, as an example of the GSUB operation, I immediately recall only replacing three dots in a row with one ellipse in MS Word, then the Hindi text almost half consists of ligatures.
For example, this is how the self-name of the language looks:

In this word there are 2 ligatures:
 and
and 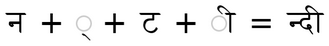
And so this word is displayed in Unity:

Unity simply draws characters in the order they appear in the word, without changing according to GSUB rules.
So, we found out the reason, but there was no unequivocal solution to the issue. Basically, on the forums, everyone recognized the fact that there is a problem and something needs to be done with it. We managed to find some useful ideas on this topic.
First idea
Taken here . Before displaying the text, programmatically swap the vowel sign
 (s) and the letter preceding it.
(s) and the letter preceding it. Yes, this solution makes text in Unity more like Hindi. But it affects only a small part of the GSUB rules, and besides, it does not allow you to adjust the width of the "cap" of the sign depending on the width of the "covered" letter. One could write such replacements for all GSUB rules, but there is one more trouble: Unity does not import font characters if they do not have a Unicode number. The standard Hindi font in Windows is Mangal - in it all ligatures do not have Unicode numbers, so Unity "does not see them". Therefore, using Mangal, it is not possible to programmatically make all replacements.
Before transposition:

After transposition:
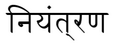
It should be:

Second idea
From this discussion, starting at comment # 20. To translate text in Hindi, use a text editor written in Unity, and a font that includes all possible ligatures, but with Unicode numbers.
The guys have already created such an editor - you can download and try it. But, unfortunately, he was very uncomfortable in his work. The lower part of the editor’s screen contains a huge virtual keyboard with all the ligatures from this font, on which the translator must manually find the necessary characters and insert them into the text with the mouse, which is extremely inconvenient and long, because there are more than a thousand of them!
Idea three
From the same discussion, comment # 38. Use the Chanakya font and text converter for this font.
This font contains the Hindi alphabet, as well as a small number (several dozen) of the most commonly used ligatures that have Unicode numbers, and therefore can be imported and displayed in Unity. The Web converter converts Unicode text to Chanakya font encoding while replacing sequences of characters forming ligatures with characters from the font with images of these ligatures.
Having tested this method, I was convinced of its working capacity.
The localization process in this way looks like this:
1) We make Hindi translation in any convenient Unicode editor, for example, MS Word.
2) Convert Unicode text from an MS Word document to Chanakya font encoding using a web converter.
3) The resulting sequence of characters is stored in the localization file.
4) In Unity, this sequence is displayed in the Chanakya font, as a result of which we visually get beautiful and correct Hindi.
But not everything is as simple as we would like. This method turned out to have a large number of pitfalls to deal with.
At first, a huge drawback of this method is that the Chanakya font does not contain standard Latin characters, not to mention the Cyrillic alphabet. Because of this, it is not possible to display in one text field the text in Hindi and text in any other language.
Secondly , the font does not contain all the standard punctuation marks, and those that contain are not under their Unicode numbers. If there are any punctuation marks in the source text, they will be replaced by unwanted Hindi characters in the converter. Therefore, for the correct result, you need to remove all punctuation marks in the source text before converting, and add to the result those Unicode characters that contain the required punctuation marks in Chanakya.
For example, there are quotation marks in the source text. Before converting, we delete them, and add the symbols Ò and Ó, respectively, to the places of the opening and closing quotation marks, respectively, because instead of these characters in Chanakya are quotation marks (only single).
Thirdly , since the Chanakya font contains a limited number of ligatures, some non-convertible sequences are possible - this can be seen by the fact that on the converter page in the result field the text contains Latin characters instead of Hindi characters. In this case, you should ask the translator to choose synonyms for those words that have not been converted.
Illustration of the localization process:
Hindi

translation : Translation prepared for conversion - punctuation marks removed:

Converted text in a Unicode view:
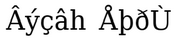
Converted text with added quotation marks and periods:
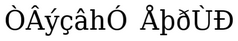
Converted text displayed in Unity using the Chanakya font:

This is how I localized the game through dancing with a tambourine. In my game, the language switches "on the fly", so I wrote a wrapper on the text field, which, on the event of switching to Hindi, changes the Unicode font to Chanakya and vice versa, respectively, when switching to another language. Also, the wrapper increases the font size of the text field, because Chanakya characters are small.
When preparing screenshots for the Play-Market and adding captions to them, it turned out that Photoshop, like Unity, also does not know how to work with GPOS and GSUB tables. This method helped here. To do this, it was necessary to install the Chanakya font into the system, convert the text of the signatures by a web converter, and in Photoshop display the received text in the Chanakya font.
My friend Rudra was very pleased with the result. He proudly told Facebook about our collaboration, recalling the long-forgotten slogan "Hindi Rus Bhai Bhai." The reward was a smooth but steady increase in the number of downloads and a large number of fives with comments about localization.
However, my internal perfectionist was not satisfied. The above shortcomings did not allow me to recognize this method as convenient for further use in my games, especially, to recommend it to a wide audience of Unity developers.
A universal method for localizing a Unity game in Hindi.
Then another idea was born, namely: from idea number two, take the Siddhanta font containing the full set of ligatures with Unicode numbers, and write a text converter in C # emulating the action of GSUB and GPOS.
The main obstacle to the implementation of this idea was that I did not have a complete list of sequences of characters displayed as ligatures. On the Internet, I could not find such a list. I had to independently study the issue and collect information from disparate sources. As a result, if I did not start reading in Hindi, then, as the classics say, at least I began to see “blondes, brunettes, redheads” ...
I also wrote to the author of the Siddhanta font, Mikhail Boyarin, who allowed me to use my font and advised me on some issues. I express my gratitude to Mikhail for his help. And the amount of work done by Michael in creating such a comprehensive font is amazing and respects!
The result of my research was the HindiCorrector script containing a table of correspondence of character sequences to ligatures, and the font Siddhanta Unity .
You can download the project here: HindiCorrector .
GSUB table record format of the script HindiCorrector following:
{source = "\ u091F \ u094D \ u091F", dest = "\ uF5A2 \ uF61F"}
characters in the source fields - this is basically a simple letter, sign halantand vowels , which the translator enters from the keyboard in a text editor. Symbols in dest fields are trailing ligatures, which, unlike the Mangal font, in the Siddhanta font have Unicode numbers, so they can be imported and displayed in Unity.
The Correct script method replaces all occurrences of source with dest in the source code.
In addition to replacing sequences of characters with ligatures, the script also solves the problem of adjusting the width of the "caps" of the vowel
(s) and  (s) signs . The Siddhanta font has lines of these symbols with “caps” of different widths. The script selects the character with the desired width depending on the letter in front of that character.
(s) signs . The Siddhanta font has lines of these symbols with “caps” of different widths. The script selects the character with the desired width depending on the letter in front of that character.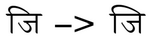
Similarly, the remaining vowel characters are modified if the letters turn out to be very wide and the vowel signs do not coincide with the vertical line of the letters.
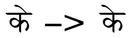
This localization method does not require any manual modifications of the source text in Hindi. The script does everything.
If you want to “teach” Hindi another font used in the game, just copy the character ranges 0900-097F and F000-F633 from the Siddhanta Unity font to the desired font.
The Siddhanta Unity font differs from the original font of Mikhail Boyarin in that all ligatures not participating in the GSUB table of the HindiCorrector script are removed from the second one. This has significantly reduced the size of the final font, which is extremely important for mobile development. The character range F000-F01B has also been added to which some existing characters with adjusted positions are placed.
My GSUB table does not pretend to be complete, but it is definitely more than what is implemented in the Chanakya font from the third idea. If you need to add a new ligature that is not in my GSUB table, then you need to do the following:
1) find the desired ligature in the Siddhanta source font and copy it under your Unicode number into the Siddhanta Unity font;
2) add a record about replacing a sequence of characters with this ligature into the GSUB table of the HindiCorrector script.
There is one more important point: Unity cannot recognize the Hindi language installed on the phone in the standard way - the Application.systemLanguage method returns Unknown, which makes all localization efforts half senseless, because not all players will look at the options for choosing a language in the settings. The solution described here came to the rescue - request the system language directly from the JAVA environment.
In conclusion, I thank my friend Dr. Rudra Narayan Pandey for fruitful collaboration, interesting communication and new knowledge. "Hindi Rus Bhai Bhai"!