Voice Authentication and Identification with Microsoft Cognitive Services
- Tutorial

Cognitive services provide access to various cloud services that allow you to work with visual, voice and text information. In addition, various Bing search features are available.
In order to try cognitive services in action it is not even necessary to have a Microsoft account. You can also get a trial key using your GitHub or LinkedIn account. The trial subscription is not limited in time, but limited in the amount of resources used for the period. To view the online demo, go to: Speaker Recognition API The
following is a description of how to test voice authentication in action. Although the service is also in preview state, but despite this, it is already quite interesting.
The service can be used from various platforms, but I will consider creating a C # / XAML UWP application.
You can go in and get a trial key here: Microsoft Cognitive Services - Get started for free

Press + and select Speaker Recognition - Preview 10,000 transactions per month, 20 per minute .
Alternatively, you can get the key from your Azure account (but what about without it). Find Cognitive Services APIs and create an account with the Speaker Recognition API type.
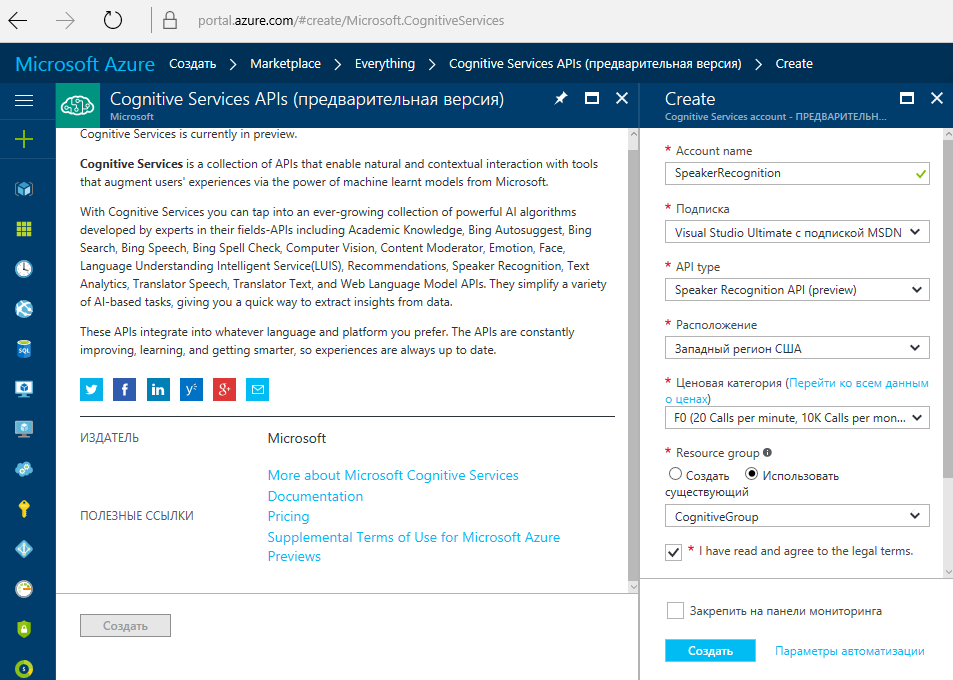
This method is suitable for those who do not plan to stop only on trial functions.
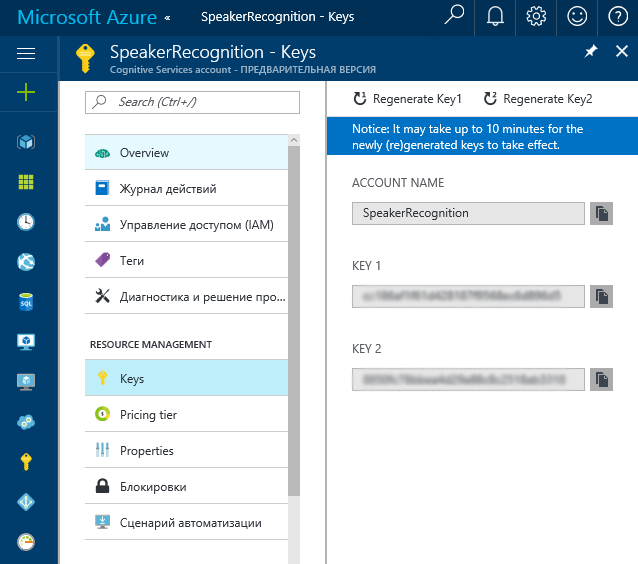
You can find the key here:
Before proceeding, let's define the terminology for the task:
Verification- confirmation that the speech was delivered by a certain person. Verification of the identity of the speaker.
Identification - determination of which of the many users known to us uttered the phrase.
Enrollment - a process during which a service trains to recognize a user's voice. After the service receives a certain number of example phrases, the user profile becomes registered and can be used for recognition.
Description of the configuration and process of voice recognition
A user profile is created
. Enrollment is being produced. Repeatedly repeats of the same phrase are sent to the service several times.
Only the following languages are currently supported: en-US (English US) and zh-CN (Chinese Mandarin).
The phrase for English can be selected from the following list:
"i am going to make him an offer he cannot refuse"
"houston we have had a problem"
"my voice is my passport verify me"
"apple juice tastes funny after toothpaste"
"you can get in without your password "
" you can activate security system now "
" my voice is stronger than passwords "
" my password is not your business "
" my name is unknown to you "
" be yourself everyone else is already taken "
The first spoken phrase is tied to the profile. You can only change the phrase by resetting Enrollment with ResetEnrollmentsAsync.
Let's imagine what a set of phrases in Russian might look like. I'll start, and you suggest options in the comments:
“Is this the apartment of Anton Semenovich Shpak?”
“Calmly, Masha, I am Dubrovsky!”
“I am a smart, handsome, moderately well-fed man, well, in full bloom”
Creating a UWP Application
Let's create the UWP application and add the following Microsoft.ProjectOxford.SpeakerRecognition NuGet package .
Add a microphone to the Capabilities section of the manifest. Internet (client) should be added by default. Configuration is complete and you can proceed to the code. List of required namespaces for working with the service:
using Microsoft.ProjectOxford.SpeakerRecognition;
using Microsoft.ProjectOxford.SpeakerRecognition.Contract;
using Microsoft.ProjectOxford.SpeakerRecognition.Contract.Verification;Required namespaces for working with audio:
using Windows.Media.Capture;
using Windows.Media.MediaProperties;
using Windows.Storage.Streams;To work with the service, you need to create some objects. A line with a subscription key and client verification. The client will interact with the service
private SpeakerVerificationServiceClient _serviceClient;
private string _subscriptionKey; After the page is initialized, these variables must be initialized:
_subscriptionKey = "ec186af1f65d428137f9568ec8d896b5";
_serviceClient = new SpeakerVerificationServiceClient(_subscriptionKey); Use _subscriptionKey to specify your subscription key. Now, logically, you need to create a user profile:
CreateProfileResponse response = await _serviceClient.CreateProfileAsync("en-us");From the response of the service, we can get the profile identifier:
String _profileId=response.ProfileId;The next step in order should be the “training” of voice recognition. Let's see how to create an audio stream. The easiest way is to read the file from disk:
Windows.Storage.Pickers.FileOpenPicker picker = new Windows.Storage.Pickers.FileOpenPicker();
picker.FileTypeFilter.Add(".wav");
Windows.Storage.StorageFile fl = await picker.PickSingleFileAsync();
string _selectedFile = fl.Name;
AudioStream = await fl.OpenAsync(Windows.Storage.FileAccessMode.Read);
The phrase should be recorded in mono at a frequency of 16 kHz.
The second option is to record voice from a microphone. Start voice recording:
MediaCapture CaptureMedia = new MediaCapture();
var captureInitSettings = new MediaCaptureInitializationSettings();
captureInitSettings.StreamingCaptureMode = StreamingCaptureMode.Audio;
await CaptureMedia.InitializeAsync(captureInitSettings);
MediaEncodingProfile encodingProfile = MediaEncodingProfile.CreateWav(AudioEncodingQuality.High);
encodingProfile.Audio.ChannelCount = 1;
encodingProfile.Audio.SampleRate = 16000;
IRandomAccessStream AudioStream = new InMemoryRandomAccessStream();
CaptureMedia.RecordLimitationExceeded += MediaCaptureOnRecordLimitationExceeded;
CaptureMedia.Failed += MediaCaptureOnFailed;
await CaptureMedia.StartRecordToStreamAsync(encodingProfile, AudioStream);The following parameters are required:
encodingProfile.Audio.ChannelCount = 1;
encodingProfile.Audio.SampleRate = 16000;Stop recording after a period of time:
await CaptureMedia.StopRecordAsync();
Stream str = AudioStream.AsStream();
str.Seek(0, SeekOrigin.Begin);and sending the stream to the service for enrollment:
Guid _speakerId = Guid.Parse(_profileId);
Enrollment response = await _serviceClient.EnrollAsync(str, _speakerId);From response we can get the following data:
response.Phrase - the spoken phrase
response.RemainingEnrollments - the number of remaining repetitions of the phrase
Recognition differs from enrollment only in that the VerifyAsync method is used:
Guid _speakerId = Guid.Parse(_profileId);
Verification response = await _serviceClient.VerifyAsync(str, _speakerId);The source code of the resulting application is available on GitHub.
Screenshot of what happened below:
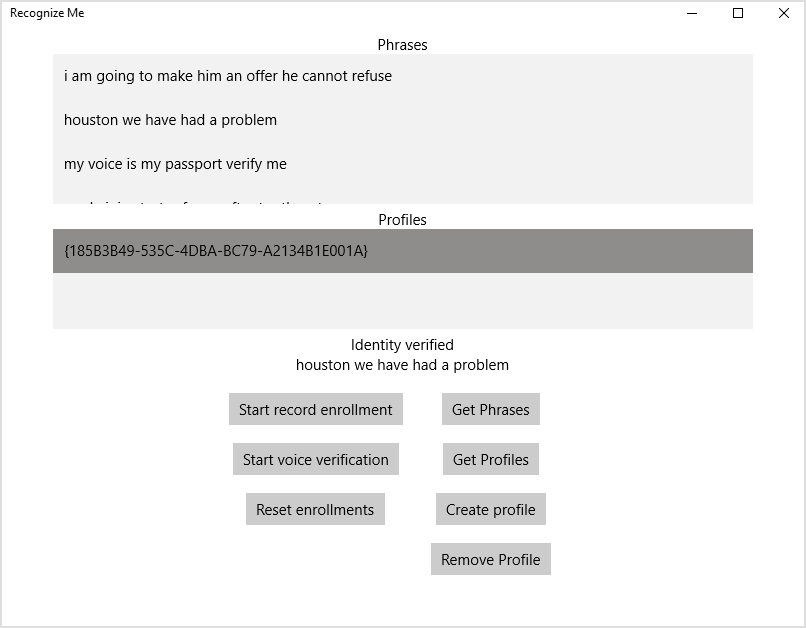
As the only way to protect, voice authentication is probably not the most reliable option. But now, as one of the elements of multi-factor authentication, it can very well be used.
Again, the possibility of identification is interesting, the code of which is similar, but with some changes.
Since the period of time during which recording can be large, in order to give the service time to complete the operation, the check starts in a cycle. An example of an Enrollment operation:
_speakerId = Guid.Parse((lbProfiles.SelectedItem as ListBoxItem).Content.ToString());
OperationLocation processPollingLocation;
processPollingLocation = await _serviceClient.EnrollAsync(str, _speakerId);
EnrollmentOperation enrollmentResult = null;
int numOfRetries = 10;
TimeSpan timeBetweenRetries = TimeSpan.FromSeconds(5.0);
while (numOfRetries > 0)
{
await Task.Delay(timeBetweenRetries);
enrollmentResult = await _serviceClient.CheckEnrollmentStatusAsync(processPollingLocation);
if (enrollmentResult.Status == Status.Succeeded)
{
break;
}
else if (enrollmentResult.Status == Status.Failed)
{
txtInfo.Text = enrollmentResult.Message;
return;
}
numOfRetries--;
}For identification, the same NuGet package is used .
The source code of the identification application is also posted on GitHub .
The official example of a WPF project on GitHub, which can also be useful:
Microsoft Speaker Recognition API: Windows Client Library & Sample
Python example: Microsoft Speaker Recognition API: Python Sample
Android SDK for Microsoft Speaker Recognition API can also be found on GitHub