"Descendant" AlphaGo independently learned to play chess, shogi and go

DeepMind creates truly amazing algorithms that are capable of something that machine systems could not achieve earlier. In particular, the AlphaGo neural network was able to beat go the best players in the world. According to experts, now the capabilities of the system have increased so much that it makes no sense to try to defeat it - the result is predetermined.
However, the company does not stop there, but continues to work. Thanks to the research of its employees, an improved version of AlphaGo, called AlphaZero, was born. As indicated in the title, the system itself was able to learn how to play three logical games at once - chess, shogi and go.
Difference between the new version of all the previous was the fact that the system is practically learned everything myself. She started from scratch and quickly learned how to play all three games perfectly. Nobody helped AlphaZero - the system has “reached itself”.
Chess was included in the package, rather, according to tradition - nothing is difficult to teach a computer to play chess, no. For the first time a computer system was brought to play in the 1950s. Then, in the 60s, the Mac Hack IV program was created , which began to beat the human rivals. Over time, chess programs gradually improved, and in 1997, IBM developed the “chess computer” Deep Blue, which managed to beat grandmaster and world champion Garry Kasparov.
As he himself points out, nowadays many applications on the smartphone play chess better than Deep Blue. Having achieved perfection in creating systems that can play chess, the developers began to create new versions of human computer rivals - in particular, they managed to teach the computer to play go. Previously, this game with a thousand-year history was considered one of the most inaccessible for "understanding" of a computer. But times have changed. As mentioned above, AlphaGo reached such a high level of mastery of the game of go that a person did not stand nearby.
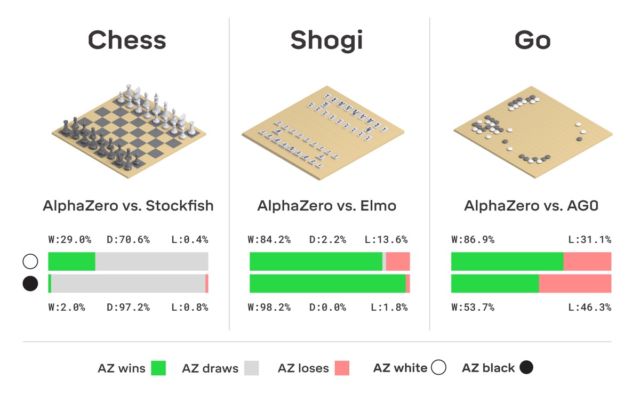
By the way, this year AlphaGo received an update, thanks to which the neural network can now learn various strategies of the go game without human intervention. Playing with itself over and over again, AlphaGo is improving. AlphaGo's “descendant” system, AlphaZero neural network, uses precisely this kind of training system. In just three days, she reached such a level of skill in go that plays the original version of AlphaGo with a score of 100 to 0. The only thing that the system initially receives is the rules of the game.
No fiction here, DeepMind uses a well-known machine learning system with reinforcements. The computer seeks to win, because for each victory receives a reward (points). And AlphaZero loses millions of combinations in the learning process. AlphaZero spends just 0.4 seconds to calculate the next move and estimate the probability of winning. As for the AlphaGo of the original version, the neural network consisted of two elements, two neural networks - one determined the next possible course, and the second calculated the probabilities.
To achieve the master level in Go AlphaZero, you need to "scroll" about 4.5 million games when playing with yourself. But AlphaGo required 30 million games.
It is worth noting that AlphaZero was created specifically for the game of go. The company has not forgotten about it. But besides go, the system is able to learn the other two games, which were mentioned above. The system used is the same - machine learning with reinforcements. It is worth noting that AlphaZero only works with tasks that have a certain number of solutions. Also, the system needs a model of the environment (virtual).
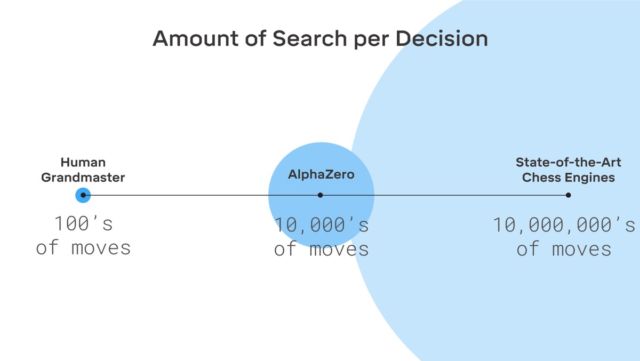
Interestingly, the same Kasparov believes that a person can get a lot from systems like AlphaGo - a lot can be learned from them.
Nowadays, developers are faced with the task of training a computer to play poker better than any other person, and also to create a system that can beat any cyber sportsman in an honest fight. In any case, it is clear that neural networks and AI are capable of much.