How SAP HANA Works with Big Data
Hello, Habr! In a previous article, we talked about the SAP Business One small business solution and briefly mentioned the capabilities of SAP HANA in computing and analytics. Today we will dwell in more detail on how the SAP HANA platform can work with big data and on scenarios for applying these technologies in business.
The main core in SAP HANA is the DBMS component, which allows you to process large amounts of data using In-Memory technology and based on the SQL language tool. The DBMS SAP HANA is based on a relational data model, but it is also possible to access data using the “graph” WIPE query language. The flexibility in choosing the query language is due to the architectural capabilities of SAP HANA and consists in using a single data representation in the In-Memory storage. Thus, the user has the ability to access data using various semantic constructions, using a single copy of the data in the DBMS memory. The classic approach adopted in several other OpenSource DBMSs differs from the above,
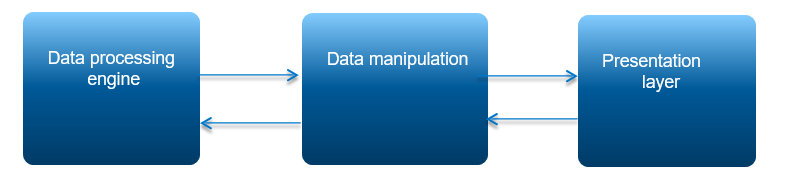
Figure 1. Data management concept
The figure above shows the general data management scheme in SAP HANA and the essence of the concept of managing using various languages - in particular, SQL and WIPE. Using the Data Processing engine, it is possible to form a new semantic level for working with data at the Data Manipulation level, but at the same time a single copy of the source data will be applied, which significantly increases the capabilities of the SAP HANA platform for solving problems where information is required to be presented in the form of graph structures.
In-memory technology in the DBMS SAP HANA allows you to store and process data in memory using unique algorithms [1] developed by SAP and based on the Intel x86 platform. Recently, SAP also announced support for the IBM Power platform for SAP Hana. The uniqueness and high speed of processing data requests lies in the ability to store and execute them. They are compressed in RAM memory. Thanks to the developed data processing algorithm, SAP HANA managed to implement the Unified Tables approach, which provides high speed of reading and writing data to the storage table. Therefore, one of the main advantages of SAP HANA is the ability to perform analytical queries directly on transactional data, which are added in real time. In this case, the system automatically takes care of ensuring transparent access to data. Thus, the new data in the table is immediately available for analysis without preliminary processing.
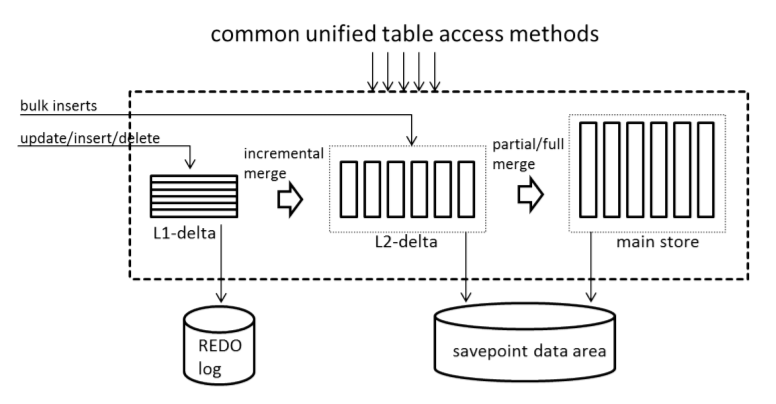
Figure 2. Unified Table concept
architecture Architecturally, SAP HANA supports a configuration in which one or more computing nodes are used as part of a single DBMS instance (Scale-out see Figure 3 and www.hanatutorials.com/p/scale-up-or -scale-out-hana-configuration.html ). This configuration is especially relevant for the tasks of processing large amounts of data in real time. Processing an SQL query in SAP HANA occurs simultaneously over the entire data volume, regardless of the location of the data.
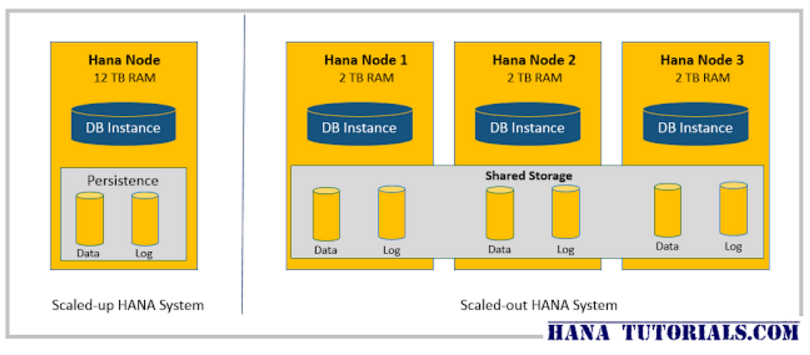
Figure 3. Scale-out configuration of HANA
Unlike Hadoop Spark and Hadoop Hive, the SAP HANA platform allows you to implement a faster and easier mechanism for loading data and executing queries for a large amount of structured data using SQL.
When processing large arrays of unstructured data (for example, video or photo materials), it is recommended to use the ability to integrate SAP HANA and Hadoop Spark using the HANA Vora tool, which is a compact version of the In-Memory DBMS integrated into Hadoop Spark.
The SAP HANA platform also offers various options when choosing a programming language for creating applications within the new Bring your own language concept. Built-in application server SAP HANA XS advanced allows you to create independent application containers based on JavaScript (Google V8 and Node.JS engine), Java (Tomcat Java), Python, Ruby, C ++.
Let us consider one of the examples from the field of machine learning for recognition and classification of images based on the image database using Hadoop, as well as streaming data using the SAP HANA Smart Data Streaming component (see Fig. 4).
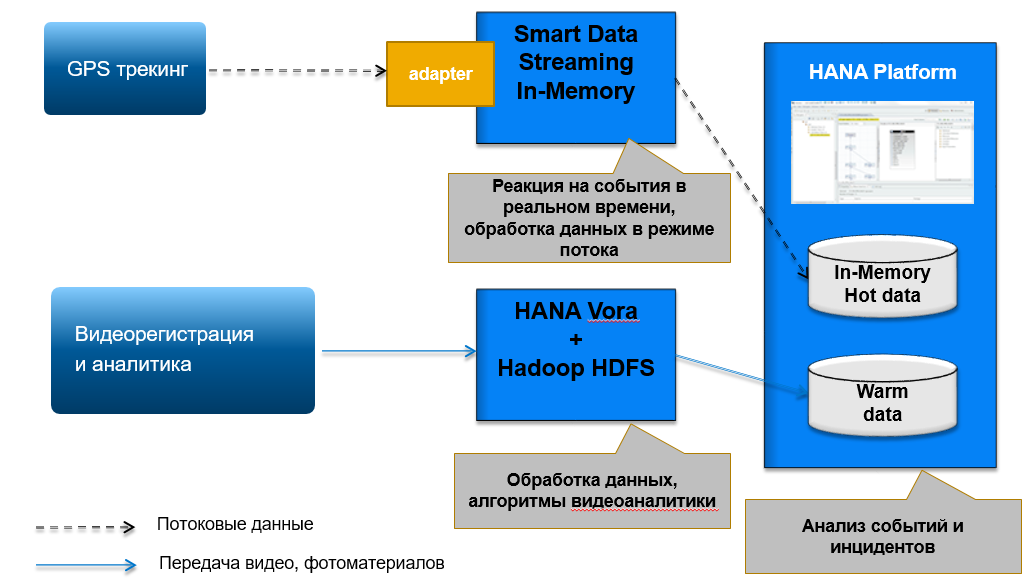
Figure 4. Architecture of a moving object control system based on SAP HANA
When implementing video algorithms in SAP HANA, it is also possible to use the popular Caffe, Theano, Torch, Tensorflow packages and transfer existing applications without changes to containers based on HANA XS Advanced or the Hadoop Spark environment.
In the following articles, we will show real examples of code implementation for machine learning tasks on the SAP HANA platform.
“Digital warehouse” based on SAP HANA
An important task for large distribution companies is to manage the loading and unloading of goods, as well as their routing for placing orders and preparing for shipment. Timely tracking of goods and forklifts, monitoring and managing the process of loading and unloading allows you to quickly plan and adjust plans for preparing goods for shipment, as well as to avoid problems with downtime of goods in the warehouse.
The “digital warehouse” model, built on the basis of SAP HANA and the component for Smart Data Streaming, helps to collect information about the availability of goods loading and unloading, information about the location, manage personnel using timely adjustment of the plan. Using specialized sensors allows you to collect information about the condition of the conveyor belt, staff jobs and track the status of places for loading and unloading goods.
In ordinary warehouses, errors are possible due to human factors during the picking process. To minimize this, the “digital warehouse” uses the built-in capabilities of SAP HANA to recognize specialized tags in the form of QR codes. Labels allow you to automatically determine the order picking and product positions based on the order code and information about it from SAP ERP.
Using SAP HANA and its real-time information analysis capabilities, companies can build a real-time warehouse management system that will take into account changes in plans when processing goods and placing orders, which will reduce the downtime of the goods and ensure adequate workload.
Additionally, within the framework of SAP HANA, using predictive analytics, you can build data analysis based on statistics on completed work in order to optimize the warehouse process.
“Digital parking” for cars
One of the important tasks in city traffic control is tracking available parking spaces to control the loading of city parking lots. Specialized sensors that are installed in parking lots can track the number of available and occupied spaces. The monitoring system based on SAP HANA Smart Data Streaming allows real-time monitoring of the status of sensors and managing a map of parking spaces.
In addition, when using DVRs, in order to comply with the paid parking conditions, it is possible to collect information about car numbers and monitor the parking status.
Digital system for controlling the quality of goods delivery
Managing and monitoring the process of goods delivery is an important task for large urban delivery networks. In large cities, in conditions of limited delivery times and a large number of orders, it is necessary to respond to changes in orders in a timely manner and plan the delivery of goods taking into account changing requirements from customers.
The integration of the SAP HANA Smart Data Streaming system helps to process several million requests for delivery of goods per minute and in the future, using specialized tools, timely adjust plans for the delivery of goods in real time.
[1] Vishal Sikka, Franz Färber, Wolfgang Lehner, Sang Kyun, Thomas Peh, Christof Bornhövd “Effective Transaction Processing in SAP HANA Database - The End of a Column Store Myth”. SIGMOD '12 Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data. Pages 731-742
SAP HANA: how it works
The main core in SAP HANA is the DBMS component, which allows you to process large amounts of data using In-Memory technology and based on the SQL language tool. The DBMS SAP HANA is based on a relational data model, but it is also possible to access data using the “graph” WIPE query language. The flexibility in choosing the query language is due to the architectural capabilities of SAP HANA and consists in using a single data representation in the In-Memory storage. Thus, the user has the ability to access data using various semantic constructions, using a single copy of the data in the DBMS memory. The classic approach adopted in several other OpenSource DBMSs differs from the above,
Figure 1. Data management concept
The figure above shows the general data management scheme in SAP HANA and the essence of the concept of managing using various languages - in particular, SQL and WIPE. Using the Data Processing engine, it is possible to form a new semantic level for working with data at the Data Manipulation level, but at the same time a single copy of the source data will be applied, which significantly increases the capabilities of the SAP HANA platform for solving problems where information is required to be presented in the form of graph structures.
In-memory technology in the DBMS SAP HANA allows you to store and process data in memory using unique algorithms [1] developed by SAP and based on the Intel x86 platform. Recently, SAP also announced support for the IBM Power platform for SAP Hana. The uniqueness and high speed of processing data requests lies in the ability to store and execute them. They are compressed in RAM memory. Thanks to the developed data processing algorithm, SAP HANA managed to implement the Unified Tables approach, which provides high speed of reading and writing data to the storage table. Therefore, one of the main advantages of SAP HANA is the ability to perform analytical queries directly on transactional data, which are added in real time. In this case, the system automatically takes care of ensuring transparent access to data. Thus, the new data in the table is immediately available for analysis without preliminary processing.
Figure 2. Unified Table concept
architecture Architecturally, SAP HANA supports a configuration in which one or more computing nodes are used as part of a single DBMS instance (Scale-out see Figure 3 and www.hanatutorials.com/p/scale-up-or -scale-out-hana-configuration.html ). This configuration is especially relevant for the tasks of processing large amounts of data in real time. Processing an SQL query in SAP HANA occurs simultaneously over the entire data volume, regardless of the location of the data.
Figure 3. Scale-out configuration of HANA
Unlike Hadoop Spark and Hadoop Hive, the SAP HANA platform allows you to implement a faster and easier mechanism for loading data and executing queries for a large amount of structured data using SQL.
When processing large arrays of unstructured data (for example, video or photo materials), it is recommended to use the ability to integrate SAP HANA and Hadoop Spark using the HANA Vora tool, which is a compact version of the In-Memory DBMS integrated into Hadoop Spark.
The SAP HANA platform also offers various options when choosing a programming language for creating applications within the new Bring your own language concept. Built-in application server SAP HANA XS advanced allows you to create independent application containers based on JavaScript (Google V8 and Node.JS engine), Java (Tomcat Java), Python, Ruby, C ++.
Let us consider one of the examples from the field of machine learning for recognition and classification of images based on the image database using Hadoop, as well as streaming data using the SAP HANA Smart Data Streaming component (see Fig. 4).
Figure 4. Architecture of a moving object control system based on SAP HANA
When implementing video algorithms in SAP HANA, it is also possible to use the popular Caffe, Theano, Torch, Tensorflow packages and transfer existing applications without changes to containers based on HANA XS Advanced or the Hadoop Spark environment.
In the following articles, we will show real examples of code implementation for machine learning tasks on the SAP HANA platform.
Examples of scenarios for using SAP HANA for working with big data in control systems for moving objects:
“Digital warehouse” based on SAP HANA
An important task for large distribution companies is to manage the loading and unloading of goods, as well as their routing for placing orders and preparing for shipment. Timely tracking of goods and forklifts, monitoring and managing the process of loading and unloading allows you to quickly plan and adjust plans for preparing goods for shipment, as well as to avoid problems with downtime of goods in the warehouse.
The “digital warehouse” model, built on the basis of SAP HANA and the component for Smart Data Streaming, helps to collect information about the availability of goods loading and unloading, information about the location, manage personnel using timely adjustment of the plan. Using specialized sensors allows you to collect information about the condition of the conveyor belt, staff jobs and track the status of places for loading and unloading goods.
In ordinary warehouses, errors are possible due to human factors during the picking process. To minimize this, the “digital warehouse” uses the built-in capabilities of SAP HANA to recognize specialized tags in the form of QR codes. Labels allow you to automatically determine the order picking and product positions based on the order code and information about it from SAP ERP.
Using SAP HANA and its real-time information analysis capabilities, companies can build a real-time warehouse management system that will take into account changes in plans when processing goods and placing orders, which will reduce the downtime of the goods and ensure adequate workload.
Additionally, within the framework of SAP HANA, using predictive analytics, you can build data analysis based on statistics on completed work in order to optimize the warehouse process.
“Digital parking” for cars
One of the important tasks in city traffic control is tracking available parking spaces to control the loading of city parking lots. Specialized sensors that are installed in parking lots can track the number of available and occupied spaces. The monitoring system based on SAP HANA Smart Data Streaming allows real-time monitoring of the status of sensors and managing a map of parking spaces.
In addition, when using DVRs, in order to comply with the paid parking conditions, it is possible to collect information about car numbers and monitor the parking status.
Digital system for controlling the quality of goods delivery
Managing and monitoring the process of goods delivery is an important task for large urban delivery networks. In large cities, in conditions of limited delivery times and a large number of orders, it is necessary to respond to changes in orders in a timely manner and plan the delivery of goods taking into account changing requirements from customers.
The integration of the SAP HANA Smart Data Streaming system helps to process several million requests for delivery of goods per minute and in the future, using specialized tools, timely adjust plans for the delivery of goods in real time.
Sources
[1] Vishal Sikka, Franz Färber, Wolfgang Lehner, Sang Kyun, Thomas Peh, Christof Bornhövd “Effective Transaction Processing in SAP HANA Database - The End of a Column Store Myth”. SIGMOD '12 Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data. Pages 731-742