sudo rm -rf, or Chronicle of the incident with the GitLab.com database from 2017/01/31
- Transfer

He got drunk slowly, but still got drunk, somehow at once, in a jump; and when, at the moment of enlightenment, he saw in front of him a chopped oak table in a completely unfamiliar room, a drawn sword in his hand and clapping moneyless dons around, he thought it was time to go home. But it was too late.
Arkady and Boris Strugatsky
An important event for the OpenSource world took place on January 31, 2017: one of the GitLab.com admins, trying to fix replication, mixed up consoles and deleted the main PostgreSQL database, as a result of which a large amount of user data was lost and the service itself went offline. Moreover, all 5 different backup / replication methods turned out to be inoperative. They recovered from the LVM image accidentally taken 6 hours before the database was deleted. It, as they say, happens. But we must pay tribute to the project team: they found the strength to treat everything with humor, did not lose their heads and showed amazing openness by writing about everything on Twitter and sharing, in fact, an internal document in which the team in real time Description of unfolding events.
While reading it, you literally feel like you are the place of poor YP, who at 11 o’clock in the evening after a hard working day and unsuccessful struggle with Postgres, squinting tiredly, drives a fatal into the console of the battle server sudo rm -rfand presses Enter. After a second, he realizes what he has done, cancels the deletion, but it's too late - there is no more base ...
Due to the importance and in many ways instructive of this incident, we decided to completely translate into Russian his journal report, made by the GitLab.com staff during the work on the incident. You can find the result under the cut.
So, let's find out in detail how it was.
Incident with the GitLab.com database from 01/31/2017
Note: this incident affected the database (including issues and merge requests); git repositories and wiki pages were not affected.
Live on YouTube - Watch how we discuss and solve the problem!
- Losses incurred
- Timeline (time indicated in UTC)
- Recovery - 2017/01/31 23:00 (backup from approximately 17:20 UTC)
- Problems
- Help from
- HugOps (add twitter posts here and from elsewhere in which people kindly reacted to what happened)
- Stephen frost
- Sam McLeod
Losses incurred
- Lost data in about 6 hours.
- 4,613 ordinary projects, 74 forks and 350 imports lost (roughly); only 5037. Since Git repositories are NOT lost, we will be able to recreate those projects whose users / groups existed before data loss, but we will not be able to restore the issues of these projects.
- Lost about 4979 (we can say about 5000) comments.
- Potentially lost 707 users (it’s hard to say more precisely according to the Kibana logs).
- Web hooks created before January 31 17:20 are restored, created after - are lost.
Timeline (time indicated in UTC)
- 2017/01/31 16: 00/17: 00 - 21:00
- YP is working on configuring pgpool and replication in staging, creates an LVM snapshot to load combat data into staging, and also in the hope that it can use this data to speed up database loading to other replicas. This occurs approximately 6 hours before data loss.
- Setting up replication is problematic and very long (estimated ~ 20 hours only for the initial synchronization of pg_basebackup). YP could not use the LVM snapshot. Work at this stage was interrupted (since YP needed the help of another colleague who was not working that day, and also because of the spam / high load on GitLab.com).
- 2017/01/31 21:00 - Surge in the load on the site due to spammers - Twitter | Slack
- Block users by their IP addresses.
- Removing a user for using the repository as a CDN, as a result of which 47,000 IP users logged in under the same account (causing a high database load). Information was transferred to technical support and infrastructure teams.
- Removing users for spam (using snippets) - Slack
- The load on the database returned to normal, the vacuum of several PostgreSQL tables was manually started to clean a large number of remaining empty rows.
- 2017/01/31 22:00 - Received warning about replication lag - Slack
- Attempts to fix db2, lag at this stage 4 GB.
- db2.cluster refuses to replicate, the directory / var / opt / gitlab / postgresql / data is cleaned up to ensure clean replication.
- db2.cluster refuses to connect to db1, swearing that max_wal_senders is too low. This setting is used to limit the number of WAL (replication) clients.
- YP increments max_wal_senders to 32 by db1, restarts PostgreSQL.
- PostgreSQL swears that too many semaphores are open and does not start.
- YP reduces max_connections from 8000 to 2000, PostgreSQL starts (despite the fact that it worked normally with 8000 for almost a year).
- db2.cluster still refuses to replicate, but no longer complains about connections, but instead it just hangs and does nothing.
- At this time, YP begins to feel hopeless. Earlier that day, he announced that he was going to finish work, as it was too late (around 23:00 local time), but remained in place due to unexpected replication problems.
- 2017/01/31 around 23:00
- YP thinks that perhaps pg_basebackup is too pedantic about the cleanliness of the data directory, and decides to delete it. After a couple of seconds, he notices that he ran the command on db1.cluster.gitlab.com instead of db2.cluster.gitlab.com .
- 2017/01/31 23:27: YP cancels the deletion, but it's too late. Out of approximately 310 GB, only 4.5 remain - Slack .
Recovery - 2017/01/31 23:00 (backup from ~ 17: 20 UTC)
- Suggested recovery methods:
- Migrate db1.staging.gitlab.com to GitLab.com (about 6 hours backlog).
- CW: There is a problem with web hooks that were deleted during synchronization.
- Restore LVM snapshot (6 hours behind).
- Sid: try to recover files?
- CW: Impossible! rm -Rvf Sid: OK.
- JEJ: It’s probably too late, but can it help if you quickly switch the drive to read-only mode? Also, is it possible to get a file descriptor if it is used by a working process (according to http://unix.stackexchange.com/a/101247/213510 ).
- YP: PostgreSQL does not keep all its files constantly open, so this will not work. It also seems that Azure deletes data very quickly, but forwarding it to other replicas is not so fast. In other words, data from the disk itself cannot be restored.
- SH: It seems that on a db1 staging server, a separate PostgreSQL process pours a stream of production data from db2 into the gitlab_replicator directory. According to the replication lag, db2 was repaid in 2016-01-31 05:53, which caused the gitlab_replicator to stop. The good news is that the data up to this point looks intact, so we may be able to recover web hooks.
- Migrate db1.staging.gitlab.com to GitLab.com (about 6 hours backlog).
- Actions taken:
- 2017/02/01 23:00 - 00:00: A decision was made to restore data from db1.staging.gitlab.com to db1.cluster.gitlab.com (production). Although they are 6 hours behind and do not contain web hooks, this is the only snapshot available. YP says that it’s better for him to no longer run any commands starting with sudo anymore and transfers control to JN.
- 2017/02/01 00:36 - JN: I backup data db1.staging.gitlab.com.
- 2017/02/01 00:55 - JN: Mounting db1.staging.gitlab.com on db1.cluster.gitlab.com.
- I copy the data from staging / var / opt / gitlab / postgresql / data / to production / var / opt / gitlab / postgresql / data /.
- 2017/02/01 01:05 - JN: nfs-share01 server is allocated as temporary storage in / var / opt / gitlab / db-meltdown.
- 2017/02/01 01:18 - JN: I copy the remaining production data, including the packed pg_xlog: '20170131-db-meltodwn-backup.tar.gz'.
- 2017/02/01 01:58 - JN: Starting synchronization from stage to production.
- 2017/02/01 02:00 - CW: The deployment page was updated to explain the situation. Link .
- 2017/02/01 03:00 - AR: rsync is about 50% complete (by the number of files).
- 017/02/01 04:00 - JN: rsync ran about 56.4% (by the number of files). Data transfer is slow for the following reasons: network bandwidth between us-east and us-east-2, as well as limiting disk performance on a staging server (60 Mb / s).
- 2017/02/01 07:00 - JN: Found a copy of the pristine data on db1 staging in / var / opt / gitlab_replicator / postgresql. I launched the db-crutch VM virtual machine on us-east to backup this data to another machine. Unfortunately, it is limited to 120 GB RAM and will not pull the workload. This copy will be used to check the status of the database and upload web hook data.
- 2017/02/01 08:07 - JN: Data transmission is slow: 42% of the data volume is transmitted.
- 2017/02/02 16:28 - JN: Data transfer has ended.
- 2017/02/02 16:45 - Below is the recovery procedure.
- Recovery procedure
- [x] - Take a snapshot of the DB1 server - or 2 or 3 - taken at 16:36 UTC.
- [x] - Update db1.cluster.gitlab.com to PostgreSQL 9.6.1, it still has 9.6.0, and staging uses 9.6.1 (otherwise PostgreSQL might not start).
- Install 8.16.3-EE. 1.
- Move chef-noop to chef-client (it was manually disabled).
- Run chef-client on the host (done at 16:45).
- [x] - Run DB - 16:53 UTC
- Monitor the launch and make sure everything went fine.
- Make a backup.
- [x] - Update Sentry DSN so that errors do not get into staging.
- [x] - Increase identifiers in all tables by 10k to avoid problems when creating new projects / comments. Done using https://gist.github.com/anonymous/23e3c0d41e2beac018c4099d45ec88f5 , which reads a text file containing all the sequences (one per line).
- [x] - Clear Rails / Redis cache.
- [x] - Try to restore web hooks whenever possible.
- [x] Run staging using a snapshot taken before deleting web hooks.
- [x] Make sure web hooks are in place.
- [x] Create an SQL dump (data only) of the web_hooks table (if there is data).
- [x] Copy the SQL dump to the production server.
- [x] Import SQL dump into the working database.
- [x] - Check through the Rails Console whether workers can connect.
- [x] - Gradually start workflows.
- [x] - Disable the deployment page.
- [x] - Flush with @gitlabstatus.
- [x] - Create crash-related tasks describing further plans / actions Hidden text
- https://gitlab.com/gitlab-com/infrastructure/issues/1094
- https://gitlab.com/gitlab-com/infrastructure/issues/1095
- https://gitlab.com/gitlab-com/infrastructure/issues/1096
- https://gitlab.com/gitlab-com/infrastructure/issues/1097
- https://gitlab.com/gitlab-com/infrastructure/issues/1098
- https://gitlab.com/gitlab-com/infrastructure/issues/1099
- https://gitlab.com/gitlab-com/infrastructure/issues/1100
- https://gitlab.com/gitlab-com/infrastructure/issues/1101
- https://gitlab.com/gitlab-com/infrastructure/issues/1102
- https://gitlab.com/gitlab-com/infrastructure/issues/1103
- https://gitlab.com/gitlab-com/infrastructure/issues/1104
- https://gitlab.com/gitlab-com/infrastructure/issues/1105
[] - Create new Project Git repository entries that do not have Project entries in cases where the namespace matches an existing user / group.- PC -
I am creating a list of these repositories so that we can check in the database if they exist.
[] - Delete repositories with unknown (lost) namespaces.- AR - working on a script based on data from a previous point.
[x] - Delete spam users again (so that they do not create problems again).- [x] CDN user with 47,000 IP addresses.
- Make after data recovery:
- Create a task for changing the PS1 format / colors in the terminals so that it is immediately clear which environment is used: production or staging (production is red, staging is yellow). For all users, by default, at the bash prompt, show the fully qualified host name (for example, “db1.staging.gitlab.com” instead of “db1”): https://gitlab.com/gitlab-com/infrastructure/issues/1094
- How to disable rm -rf for the data PostgreSQL directory? I’m not sure if this is feasible or necessary (if there are normal backups).
- Add alerts for backups: check S3 storage, etc. Add a graph showing changes in backup sizes, give a warning when the size decreases by more than 10%: https://gitlab.com/gitlab-com/infrastructure/issues/1095 .
Consider adding the time of the last successful backup to the database so that admins can easily see this information(suggested by the client at https://gitlab.zendesk.com/agent/tickets/58274 ).- Understand why PostgreSQL suddenly had problems with max_connections set to 8000, despite the fact that it worked from 2016-05-13. The unexpected appearance of this problem is largely responsible for the heaped despair and hopelessness: https://gitlab.com/gitlab-com/infrastructure/issues/1096 .
- Looking at the increase in replication thresholds through WAL / PITR archiving will also be useful after unsuccessful updates: https://gitlab.com/gitlab-com/infrastructure/issues/1097 .
- Create a guide for users to solve problems that may arise after the launch of the service.
- Experiment with moving data from one data center to another using AzCopy: Microsoft says this should run faster than rsync:
- This seems to be a Windows-specific thing, and we do not have experts on Windows (or anyone at least remotely, but sufficiently familiar with the question to correctly test this).
Problems
- By default, LVM snapshots are taken only once every 24 hours. Luckily, YP did one manually 6 hours before the crash.
- Regular backups also seem to be done only once a day, although YP has not yet figured out where they are stored. According to JN, they do not work: files of several bytes in size are created.
- SH: It seems that pg_dump does not work correctly, since binaries from PostgreSQL 9.2 instead of 9.6 are executed. This is due to the fact that omnibus uses only Pg 9.6 if data / PG_VERSION is set to 9.6, but this file is not on the work nodes. As a result, 9.2 starts by default and quits silently without doing anything. As a result, SQL dumps are not created. Fog-gem may have cleaned up old backups.
- Azure disk snapshots are included for the NFS server, but not for database servers.
- The synchronization process deletes web hooks after it has synchronized data on staging. If we cannot pull them out of a regular backup made within 24 hours, they will be lost.
- The replication procedure turned out to be very fragile, prone to errors, depending on random shell scripts and poorly documented.
- SH: We later found out that updating the staging database works by taking a snapshot of the gitlab_replicator directory, deleting the replication configuration, and starting a separate PostgreSQL server.
- Our S3 backups also do not work: the folder is empty.
- We do not have a reliable notification system about failed attempts to create backups, we now see the same problems on the dev-host.
In other words, of the 5 backup / replication methods used, none work. => now we are restoring a working backup made 6 hours ago.
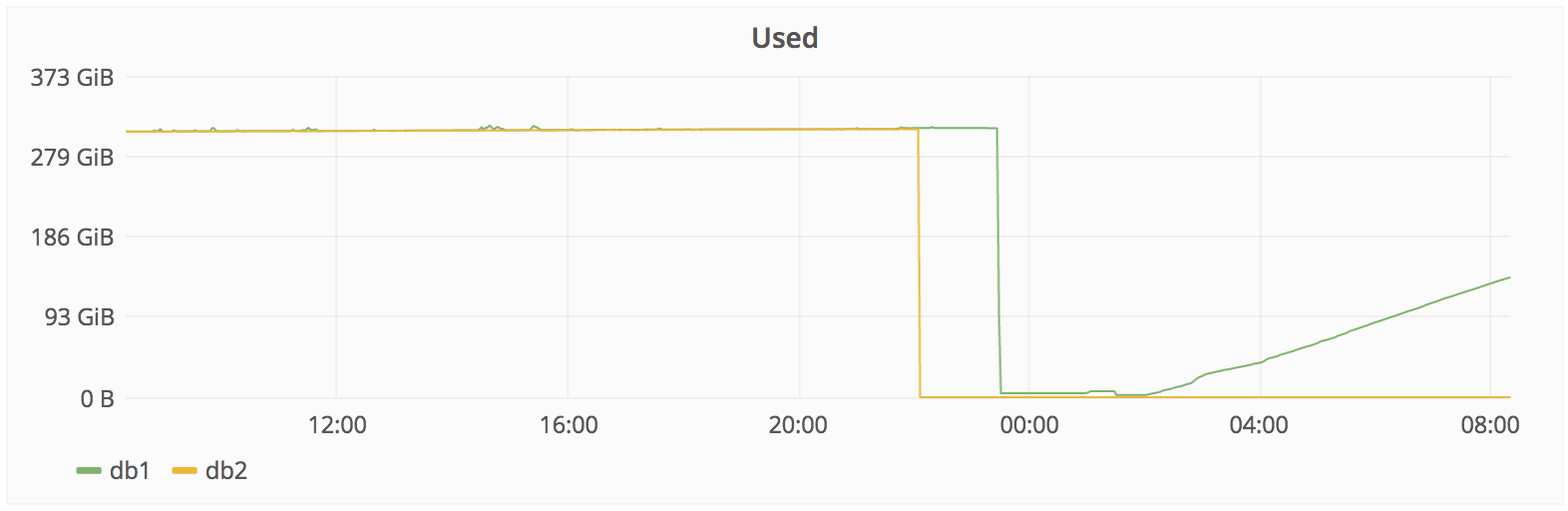
http://monitor.gitlab.net/dashboard/db/postgres-stats?panelId=10&fullscreen&from=now-24h&to=now
Help from
Hugops (add here posts from twitter or from somewhere else in which people kindly reacted to what happened)- A Twitter Moment for all the kind tweets: https://twitter.com/i/moments/826818668948549632
- Jan Lehnardt https://twitter.com/janl/status/826717066984116229
- Buddy CI https://twitter.com/BuddyGit/status/826704250499633152
- Kent https://twitter.com/kentchenery/status/826594322870996992
- Lead off https://twitter.com/LeadOffTeam/status/826599794659450881
- Mozair https://news.ycombinator.com/item?id=13539779
- Applicant https://news.ycombinator.com/item?id=13539729
- Scott Hanselman https://twitter.com/shanselman/status/826753118868275200
- Dave Long https://twitter.com/davejlong/status/826817435470815233
- Simon Slater https://twitter.com/skslater/status/826812158184980482
- Zaim M Ramlan https://twitter.com/zaimramlan/status/826803347764043777
- Aaron Suggs https://twitter.com/ktheory/status/826802484467396610
- danedevalcourt https://twitter.com/danedevalcourt/status/826791663943241728
- Karl https://twitter.com/irutsun/status/826786850186608640
- Zac Clay https://twitter.com/mebezac/status/826781796318707712
- Tim Roberts https://twitter.com/cirsca/status/826781142581927936
- Frans Bouma https://twitter.com/FransBouma/status/826766417332727809
- Roshan Chhetri https://twitter.com/sai_roshan/status/826764344637616128
- Samuel Boswell https://twitter.com/sboswell/status/826760159758262273
- Matt Brunt https://twitter.com/Brunty/status/826755797933756416
- Isham Mohamed https://twitter.com/Isham_M_Iqbal/status/826755614013485056
- Adriå Galin https://twitter.com/adriagalin/status/826754540955377665
- Jonathan Burke https://twitter.com/imprecision/status/82674955656613134784
- Christo https://twitter.com/xho/status/826748578240544768
- Linux Australia https://twitter.com/linuxaustralia/status/826741475731976192
- Emma Jane https://twitter.com/emmajanehw/status/826737286725455872
- Rafael Dohms https://twitter.com/rdohms/status/826719718539194368
- Mike San Romån https://twitter.com/msanromanv/status/826710492169269248
- Jono Walker https://twitter.com/WalkerJono/status/826705353265983488
- Tom Penrose https://twitter.com/TomPenrose/status/826704616402333697
- Jon Wincus https://twitter.com/jonwincus/status/826683164676521985
- Bill Weiss https://twitter.com/BillWeiss/status/826673719460274176
- Alberto Grespan https://twitter.com/albertogg/status/826662465400340481
- Wicket https://twitter.com/matthewtrask/status/826650119042957312
- Jesse Dearing https://twitter.com/JesseDearing/status/826647439587188736
- Franco Gilio https://twitter.com/fgili0/status/826642668994326528
- Adam DeConinck https://twitter.com/ajdecon/status/826633522735505408
- Luciano Facchinelli https://twitter.com/sys0wned/status/826628970150035456
- Miguel Di Ciurcio F. https://twitter.com/mciurcio/status/826628765820321792
- ceej https://twitter.com/ceejbot/status/826617667884769280
Stephen frost
- https://twitter.com/net_snow/status/826622954964393984 @gitlabstatus Hello, I am a PG developer and I like what you do. Let me know if I can help with something, I would be glad to be of service.
Sam McLeod
- Hi Sid, it is unfortunate that you have problems with the / LVM database, this is pretty damn unpleasant. We have several PostgreSQL clusters (master / slave), and I noticed a few things in your report:
- You use Slony, and this is the piece you yourself know what, and this is not an exaggeration, here http://howfuckedismydatabase.com even laughs at it , while the built-in PostgreSQL binary responsible for streaming replication is very reliable and fast, I suggest switch to it.
- The use of connection pools is not mentioned, but it speaks of thousands of connections in postgresql.conf - it is very bad and inefficient in terms of performance, I suggest using pg_bouncer and not setting max_connection in PostgreSQL above 512-1024; in practice, if you have more than 256 active connections, you need to scale horizontally, not vertically.
- The report says how unreliable your failover and backup processes are, we wrote and documented a simple script for postgresql failover - if you want, I will forward it to you. As for backups, for incremental backups during the day we use pgbarman, and we also make full backups twice a day using barman and pg_dump, it is important from the point of view of performance and reliability to store your backups and the directory with postgresql data on different disks.
- Are you still in Azure?!?! I would suggest moving out of there as quickly as possible, since there are a lot of strange problems with internal DNS, NTP, routing, and storage, and I also heard several frightening stories about how everything is arranged inside.
Long correspondence between Sid and Sam with emphasis on PostgreSQL setup- Let me know if you need help setting up PostgreSQL, I have decent experience in this matter.
- Capt. McLeod: another question: how much disk space does your database (s) take? Is it a terabyte or is it still gigabytes?
- Capt. McLeod: posted my failover / replication script:
- I also see that you are looking at pgpool - I would suggest pgbouncer in return
- Capt. McLeod: pgpool has a lot of problems, we tested it well and threw it away.
- Capt. McLeod: Also let me know if I can say something publicly via twitter or something else in support of GitLab and your transparency in working on this issue, I know how hard it is; when I started, we had a SAN split-brain in infoxchange, and literally vomited me - I was so nervous!
- Sid Sijbrandij: Hi Sam, thanks for the help. Do you mind if I copy this into a public document so that the rest of the team can do this?
- Capt. McLeod: Failover script?
- Sid Sijbrandij: Everything you wrote.
- Of course, in any case, this is a public repository, but it is not perfect, it is very far from this, but it does its job well, I constantly confuse hosts without any consequences, but everything can be different for you.
- Yes, of course, you can forward my recommendations as well.
If you can send me information about your VM running PostgreSQL and your PostgreSQL.conf, I will give recommendations on how to improve it.
Sid: we used Slony only for updating from 9.2 to 9.6, in other cases we have streaming replication.
Comment: OK, this is good, for information: in the framework of the major versions of PostgreSQL, you can use built-in replication to perform updates.- Rails already creates connection pools (25 per process). With 20 processes on 20 hosts, somewhere around 10,000 connections are obtained, with about 400 active connections (since Unicorn is a single-threaded application).
Comment: Each PostgreSQL connection uses memory; keeping many open connections at once is inefficient; pg_bouncer, a fantastically simple and quick tool for creating connection pools, can help here. It does only one thing, but it does it well, while pgpool complicates things. He can rewrite requests, some of which start to work not as expected. Pgpool is not designed for use with ORM / db frameworks.
Worth reading: https://wiki.postgresql.org/wiki/Number_Of_Database_Connections
- For load balancing, creating connection pools, quality failover, etc., we look at pgpool + streaming replication with synchronous commits (for data consistency). Pgbouncer, as far as we know, does not balance the load (at least out of the box). Thishttps://github.com/awslabs/pgbouncer-rr-patch worth considering as one option.
Question: Are you currently using several active / active PostgreSQL nodes, and if not, how do you balance the load?
Question: What is the daily load on the site? How many page loads and requests per second?
* In all likelihood, the section with questions from Sam, the answers of the GitLab.com team and the final recommendations will be replenished for some more time and is no longer directly related to the incident itself. We have not yet begun to include it in the translation, since the original has not yet stabilized.
Conclusion
Significantly, the guys from GitLab managed to turn their grossest error into an instructive story and, I think, not only not to lose, but also to gain the respect of many IT people. Also, due to openness, having written about the problem on Twitter and posting a log in Google Docs, they very quickly received qualified assistance from the outside, and it seems that it was completely free of charge.
As always, people with a good sense of humor delight: the main culprit of the incident now calls himself "Database (removal) specialist", some jokers suggested on February 1 to make http: // checkyourbackups a day for checking backups . work / , and Habr users remembered a wonderful thematic picture:
What conclusions can be drawn?
- It is necessary to check backups.
- Additional difficulties must be considered when restoring files in the cloud (at least in Azure).
- LVM is not so bad, and even such prominent companies as GitLab.com use it to host the database, despite the loss in performance.
- Do not give dev / stage / prod servers similar names.
- Make dev / stage / prod server interfaces different in color / format.
- Do not be afraid to tell the whole world about your mistake - there are more good people, and they will help.
- Remember that even the most severe defeat can be turned into a victory.
Related links:
- Original document: GitLab.com Database Incident - 2017/01/31: https://docs.google.com/document/d/1GCK53YDcBWQveod9kfzW-VCxIABGiryG7_z_6jHdVik/pub
- GitLab.com blog post: https://about.gitlab.com/2017/02/01/gitlab-dot-com-database-incident/
- The first article on Habré: https://habrahabr.ru/post/320988/
