How we built a fast and reliable ad views repository
One of the unobtrusive, but important functions of our sites ads - saving and displaying the number of their views. Our sites have been watching ad views for over 10 years. The technical implementation of the functionality has changed several times during this time, and now it is a (micro) service on Go, working with Redis as a cache and task queue, and with MongoDB as a persistent storage. Several years ago, he learned to work not only with the amount of ad views, but also with the statistics for each day. But to do all this really quickly and reliably, he learned recently.

In total for projects, the service processes ~ 300 thousand requests for reading and ~ 9 thousand requests for writing per minute, 99% of which are executed up to 5 ms. This, of course, is not astronomical indicators and not launching rockets to Mars - but also not such a trivial task as simple storage of numbers may seem. It turned out that doing all this, ensuring the preservation of data without loss and reading consistent, actual values requires some effort, which we describe below.
Although viewing counters are not as critical for a business as, say, processing payments or requests for a loan , they are primarily important to our users. People are fascinated by tracking the popularity of their ads: some even call support when they notice inaccurate information about views (this happened with one of the previous implementations of the service). In addition, we store and display detailed statistics in users' personal accounts (for example, to assess the effectiveness of using paid services). All this forces us to carefully treat the saving of each viewing event and the display of the most relevant values.
In general, the functionality and principles of the project look like this:
Although the steps described above look quite simple, the problem here is the organization of the interaction between the database and the microservice instances so that the data is not lost, duplicated, or late.
Using only one repository (for example, only MongoDB) would solve some of these problems. In fact, before the service worked, until we came up against the problem of scaling, stability and speed.
A naive implementation of moving data between storages could lead, for example, to such anomalies:
There may be other errors, the causes of which also lie in the non-atomic nature of operations between databases, for example, a conflict while simultaneously removing and increasing views of the same entity.
Our approach to storing and processing data in this project is based on the expectation that at any point in time MongoDB can refuse more likely than Redis. This, of course, is not an absolute rule - at least not for every project - but in our environment we are really used to observing periodic timeouts to requests in MongoDB caused by the performance of disk operations, which was one of the reasons for losing some of the events.
To avoid many of the problems mentioned above, we use task queues for deferred saving and lua scripts that allow us to atomically change data in several radish structures at once. With this in mind, in detail the scheme of saving views looks like this:
Due to the fact that lua scripts are executed atomically , we avoid a lot of potential problems that could be caused by a competitive entry.
Another important detail is ensuring the safe transfer of updates from the pending queue to MongoDB. To do this, we used the “secure queue” template described in the Redis documentation , which significantly reduces the chances of data loss by creating a copy of the processed items in a separate, one more queue until they are permanently stored in the persistent storage.
To better understand the steps of the entire process, we have prepared a little visualization. First, look at the usual, successful scenario (the steps are numbered in the upper right corner and are described in detail below):
When all subsystems are in order, some of these steps may seem redundant. And the attentive reader may also have a question about what makes the gopher sleeping in the lower left corner.
Everything is explained when considering the script when MongoDB is unavailable:
In this scheme, there are several important timeouts and heuristics derived through testing and common sense: for example, elements are moved back from the processing queue to the pending queue after 15 minutes of inactivity. In addition, Gorutin, who is responsible for this task, performs a blocking before execution , so that several instances of microservice do not attempt to restore hung-up views at the same time.
Strictly speaking, even these measures do not provide theoretically reasonable guarantees (for example, we ignore scenarios like the process hangs for 15 minutes) - but in practice it works quite reliably.
Also in this scheme there are still at least 2 known vulnerabilities that are important to be aware of:
It may seem that the problems turned out more than we would like. However, in fact, it turns out that the scenario from which we were originally protected - the failure of MongoDB - is indeed a much more real threat, and the new data processing scheme successfully ensures the availability of the service and prevents losses.
One of the clearest examples of this was the case when the MongoDB instance on one of the projects was unavailable all night by ridiculous chance. All this time, the viewing counters were accumulated and rotated in radish from one queue to another, until they were finally stored in the database after the incident was resolved; most users fail to even notice.
Read requests are much easier to write than write: microservice first checks the cache in radish; all that is not found in the cache is filled with data from MongoDb and returned to the client.
There is no pass-through to the cache for read operations to avoid the overhead of protecting against concurrent writing. The smarter cache still remains quite good, since most often it already turns out to be warmed up due to other write requests.
Statistics of views by day is read from MongoDB directly, since it is requested less often, and it is more difficult to cache it. It also means that when the database is unavailable, reading the statistics stops working; but it only affects a small part of users.
The MongoDB collection scheme for the project is based on these recommendations from the database developers themselves , and looks like this:
We don’t use the transactional capabilities of MongoDb to update several collections at the same time, which means we run the risk that data can be written only into one collection. For the time being, we are just logging such cases; there are a few of them, and so far this does not present the same significant problem as other scenarios.
I would not trust my own words about the fact that the described scripts really work if they were not covered with tests.
Since most of the project code works closely with radish and MongoDb, most of the tests in it are integration tests. The test environment is supported through docker-compose, which means it is deployed quickly, provides reproducibility by resetting and restoring state every time it starts, and allows you to experiment without affecting other people's databases.
There are 3 main areas of testing in this project:
To check for failed scenarios, the service business logic code works with the database client interfaces, which in the necessary tests are replaced with implementations that return errors and \ or simulate network delays. We also simulate the parallel operation of several instances of the service using the pattern " environment objectThis is a variant of the well-known “inversion of control” approach, where functions do not address dependencies independently, but receive them through the environment object passed in the arguments. Among other advantages, the approach allows simulating several independent copies of the service in one test, each of which has its own connection pool to the database and more or less effectively reproduces the production environment. Some tests run each such instance in parallel and make sure that they all see the same data, and race conditions are missing.
We also they conducted a rudimentary, but still quite useful
siege- based stress test , which helped to estimate roughly the allowable load and speed of response from the service.
For 90% of requests, the processing time is very insignificant, and most importantly, stable; Here is an example of measurements on one of the projects over several days:
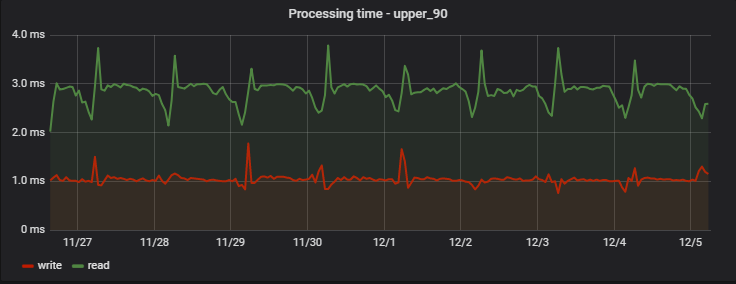
Interestingly, the record (which is actually a write + read operation, because it returns updated values) is slightly faster than the read (but only from the point of view of a client who does not observe actual deferred entry).
A regular morning increase in delays is a side effect of the work of our analytics team, which daily collects its own statistics based on service data, creating an “artificial highload” for us.
The maximum processing time is relatively long: among the slowest requests, new and unpopular ads show themselves (if the ad was not viewed and displayed only in the lists - its data does not fall into the cache and are read from MongoDB), group requests for multiple ads at once (they were worth to make a separate schedule), as well as possible network delays:
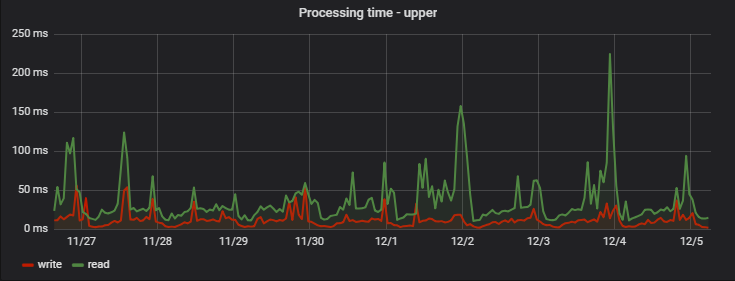
Practice, to some extent, counterintuitively, showed that using Redis as the main repository for the display service increased overall stability and improved its overall speed.
The main load of the service is read requests, 95% of which are returned from the cache, and therefore they work very quickly. Write requests are deferred, although from the end user's point of view, they also work quickly and become visible to all clients immediately. In general, almost all customers receive responses in less than 5ms.
As a result, the current version of microservice based on Go, Redis and MongoDB successfully works under load and is able to survive the periodic inaccessibility of one of the data stores. Based on previous experience with infrastructure problems, we identified the main error scenarios and successfully defended against them, so that most users are not inconvenienced. And we, in turn, receive much less complaints, alerts and messages in the logs - and are ready for further increase in attendance.
In total for projects, the service processes ~ 300 thousand requests for reading and ~ 9 thousand requests for writing per minute, 99% of which are executed up to 5 ms. This, of course, is not astronomical indicators and not launching rockets to Mars - but also not such a trivial task as simple storage of numbers may seem. It turned out that doing all this, ensuring the preservation of data without loss and reading consistent, actual values requires some effort, which we describe below.
Tasks and project overview
Although viewing counters are not as critical for a business as, say, processing payments or requests for a loan , they are primarily important to our users. People are fascinated by tracking the popularity of their ads: some even call support when they notice inaccurate information about views (this happened with one of the previous implementations of the service). In addition, we store and display detailed statistics in users' personal accounts (for example, to assess the effectiveness of using paid services). All this forces us to carefully treat the saving of each viewing event and the display of the most relevant values.
In general, the functionality and principles of the project look like this:
- A web page or application screen makes a request for ad counters (the request is usually asynchronous to prioritize the output of basic information). And if the page of the ad itself is displayed, the client will instead ask to increase and return the updated amount of views.
- By processing read requests, the service tries to retrieve information from the Redis cache, and the missing one completes by executing a request to MongoDB.
- Write requests are sent to 2 structures in radish: a queue of incremental updates (processed in the background, asynchronously) and a cache of total views.
- The background process in the same service reads items from the queue, accumulates them in a local buffer, and periodically writes it to MongoDB.
View counters recording: pitfalls
Although the steps described above look quite simple, the problem here is the organization of the interaction between the database and the microservice instances so that the data is not lost, duplicated, or late.
Using only one repository (for example, only MongoDB) would solve some of these problems. In fact, before the service worked, until we came up against the problem of scaling, stability and speed.
A naive implementation of moving data between storages could lead, for example, to such anomalies:
- Loss of data during competitive write to cache:
- Process A increases the Redis cache view counter, but discovers that there is no data for this entity (it can be either a new ad or an old one that has been pushed out of the cache), so the process must first get this value from MongoDB.
- Process A receives a view counter from MongoDB — for example, the number 5; then adds 1 to it and is about to write to Redis 6 .
- Process B (initiated, say, by another site user who simultaneously approached the same ad) does the same thing in parallel.
- Process A writes the value 6 to Redis .
- Process B writes the value 6 to Redis .
- As a result, one view is lost due to race while recording data.
The scenario is not so unlikely: we, for example, have a paid service that places an ad on the home page of the site. For a new announcement, such a course of events may lead to the loss of multiple views at once due to their sudden influx.
- Process A increases the Redis cache view counter, but discovers that there is no data for this entity (it can be either a new ad or an old one that has been pushed out of the cache), so the process must first get this value from MongoDB.
- An example of another scenario is data loss when moving views from Redis to MongoDb:
- The process takes the pending value from Redis and saves it to its memory for later writing to MongoDB.
- The write request ends with an error (or the process crashes before it is executed).
- The data is lost again, which will become obvious the next time the cached value is preempted and replaced with the value from the database.
There may be other errors, the causes of which also lie in the non-atomic nature of operations between databases, for example, a conflict while simultaneously removing and increasing views of the same entity.
View counters recording: solution
Our approach to storing and processing data in this project is based on the expectation that at any point in time MongoDB can refuse more likely than Redis. This, of course, is not an absolute rule - at least not for every project - but in our environment we are really used to observing periodic timeouts to requests in MongoDB caused by the performance of disk operations, which was one of the reasons for losing some of the events.
To avoid many of the problems mentioned above, we use task queues for deferred saving and lua scripts that allow us to atomically change data in several radish structures at once. With this in mind, in detail the scheme of saving views looks like this:
- When a write request gets into microservice, it executes the lua-script IncrementIfExists to increase the counter only if it already exists in the cache. The script immediately returns -1 if there is no data for the viewed entity in the radish; otherwise, it increases the value of the cached hits in HINCRBY , adds an event to the queue for later saving to MongoDB (we call it pending queue ) via LPUSH , and returns the updated amount of hits.
- If the IncrementIfExists returns a positive number, this value is returned to the client and the request is completed.
Otherwise, microservice takes the view counter from MongoDb, increases it by 1 and sends it to radishes. - Writing to radishes is done through another lua script, Upsert , which saves the amount of views to the cache if it is still empty, or increments them by 1 if someone else managed to fill the cache between steps 1 and 3.
- Upsert also adds a viewing event to the pending queue, and returns the updated amount, which is then sent to the client.
Due to the fact that lua scripts are executed atomically , we avoid a lot of potential problems that could be caused by a competitive entry.
Another important detail is ensuring the safe transfer of updates from the pending queue to MongoDB. To do this, we used the “secure queue” template described in the Redis documentation , which significantly reduces the chances of data loss by creating a copy of the processed items in a separate, one more queue until they are permanently stored in the persistent storage.
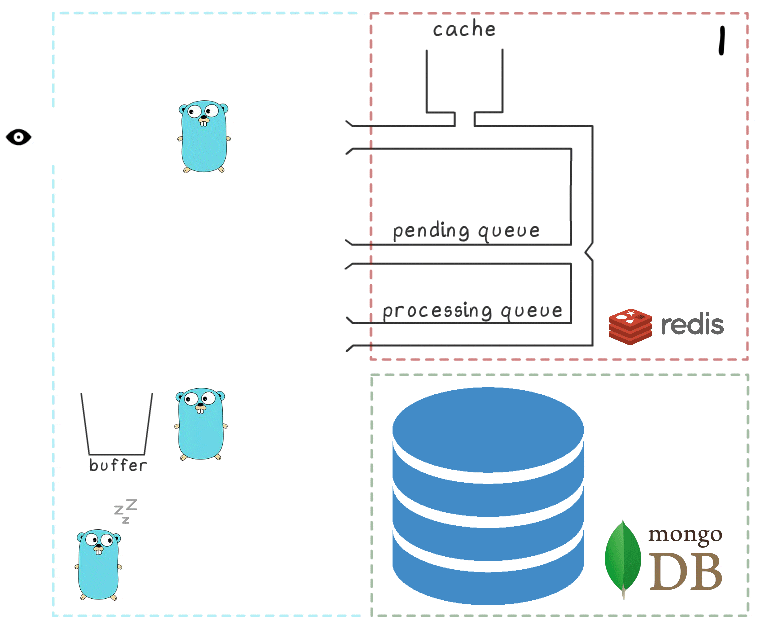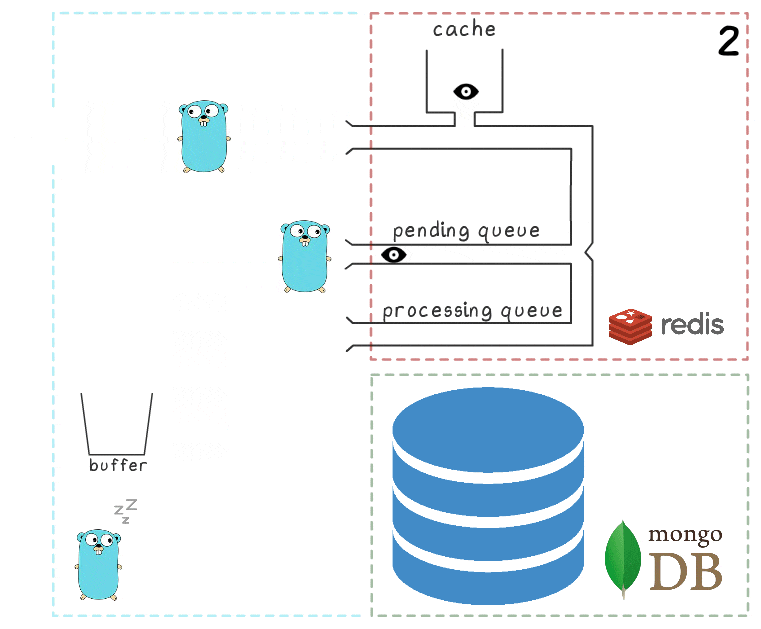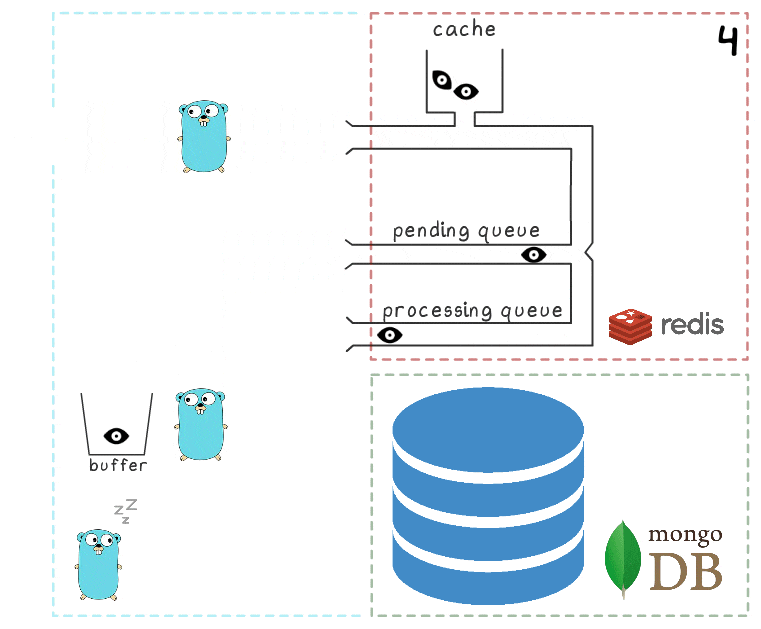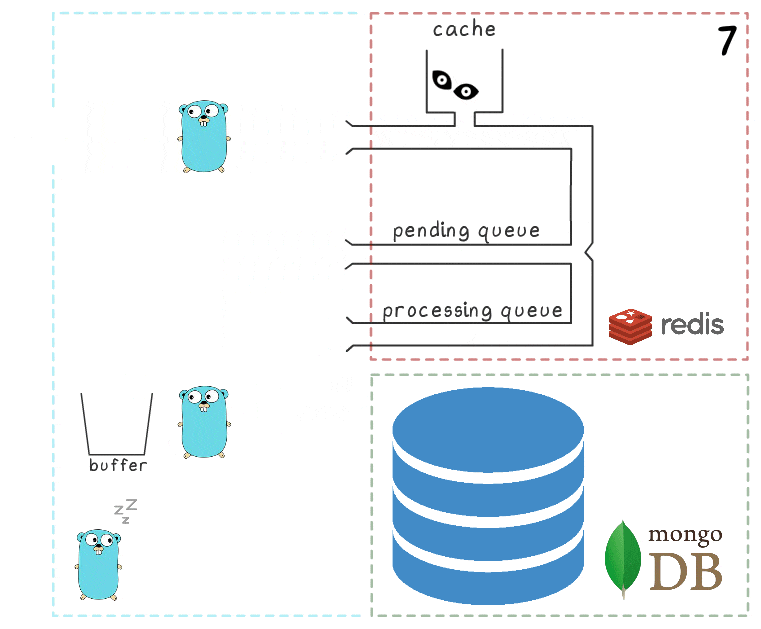
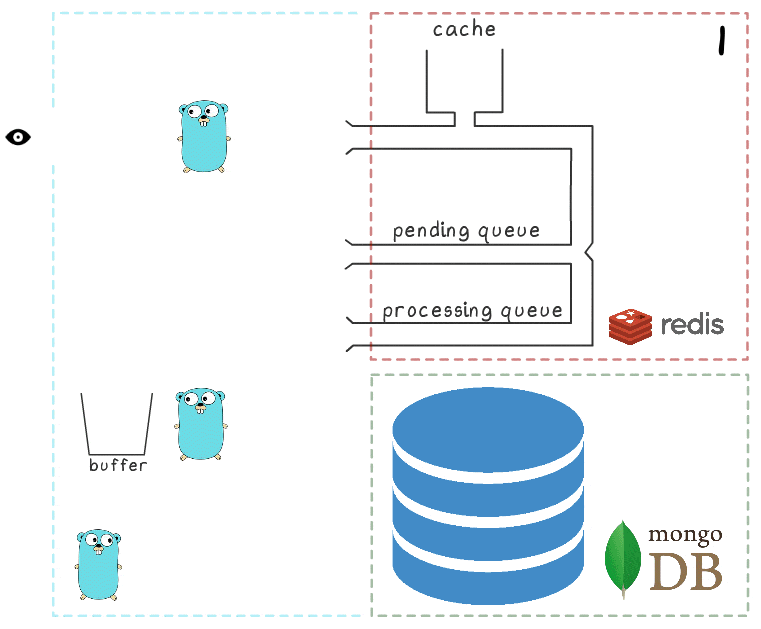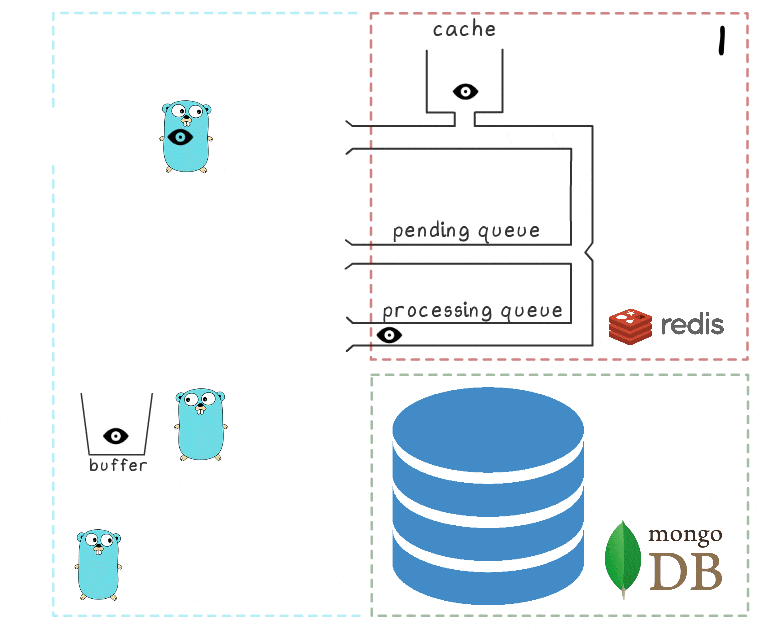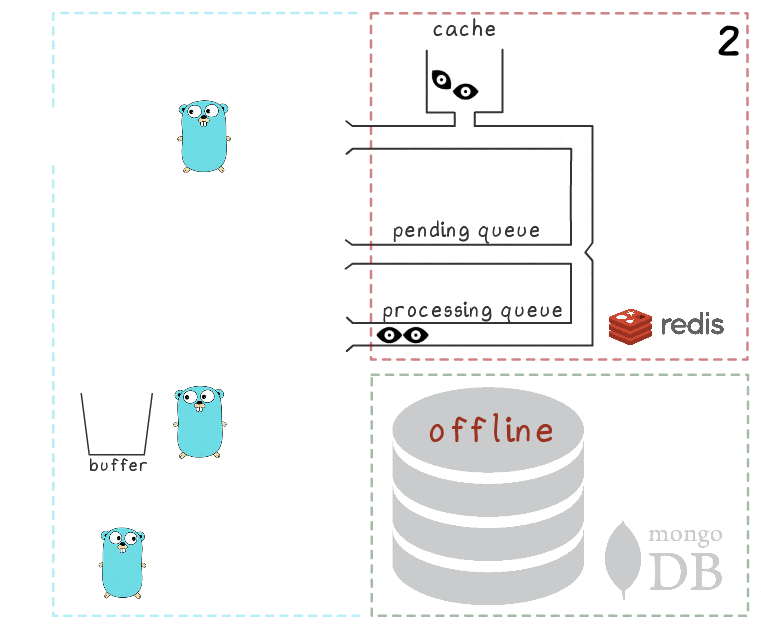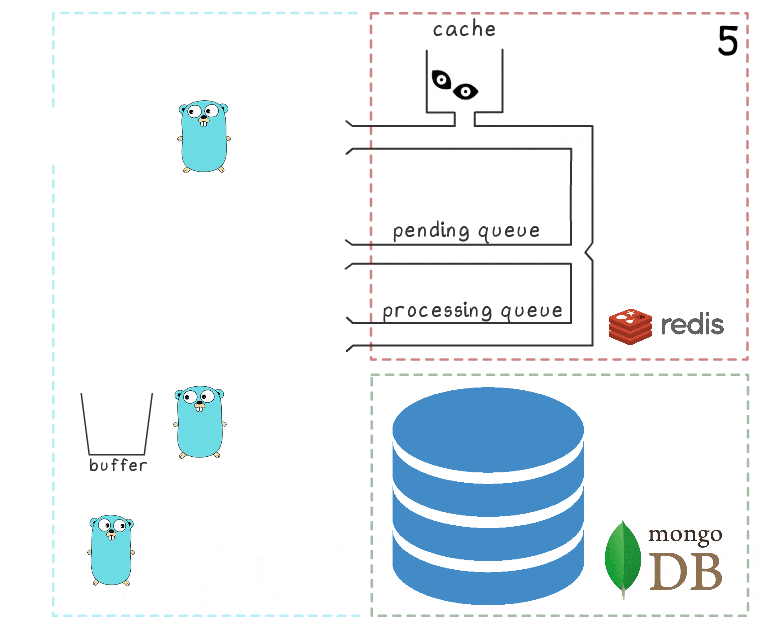
To better understand the steps of the entire process, we have prepared a little visualization. First, look at the usual, successful scenario (the steps are numbered in the upper right corner and are described in detail below):
- Microservice receives a write request
- The request handler sends it to the lua script, which writes the scan to the cache (immediately making it readable) and to the queue for subsequent processing.
- Background gorutina (periodically) performs the BRPopLPush operation , which atomically moves an element from one queue to another (we call it the “processing queue” - the queue with the elements currently being processed). The same element is then stored in a buffer in the process memory.
- Another write request is received and processed, which leaves us with 2 items in the buffer and 2 items in the processing queue.
- After some timeout, the background process decides to flush the buffer in MongoDB. Writing a set of values from the buffer is performed in one request, which has a positive effect on throughput. Also, before recording, the process tries to combine several views into one, summing up their values for the same ads.
On each of our projects, we use 3 instances of microservice, each with its own buffer, which is saved to the database every 2 seconds. During this time, about 100 elements accumulate in one buffer. - After successful writing, the process removes the items from the processing queue, signaling that the processing has been completed successfully.
When all subsystems are in order, some of these steps may seem redundant. And the attentive reader may also have a question about what makes the gopher sleeping in the lower left corner.
Everything is explained when considering the script when MongoDB is unavailable:
- The first step is identical to the events from the previous scenario: the service receives 2 requests for recording views and processes them.
- The process lost connection with MongoDB (the process itself, of course, still does not know about it).
The handler, as before, tries to flush its buffer into the database, but this time without success. It returns to the expectation of the next iteration. - Another background gorutin wakes up and checks the processing queue. She discovers that elements have been added to her for a long time; concluding that their processing failed, she moves them back to the pending queue.
- After some time, the connection with MongoDB is restored.
- The first background gorutin tries again to perform the write operation — this time successfully — and eventually eventually removes the elements from the processing queue.
In this scheme, there are several important timeouts and heuristics derived through testing and common sense: for example, elements are moved back from the processing queue to the pending queue after 15 minutes of inactivity. In addition, Gorutin, who is responsible for this task, performs a blocking before execution , so that several instances of microservice do not attempt to restore hung-up views at the same time.
Strictly speaking, even these measures do not provide theoretically reasonable guarantees (for example, we ignore scenarios like the process hangs for 15 minutes) - but in practice it works quite reliably.
Also in this scheme there are still at least 2 known vulnerabilities that are important to be aware of:
- If microservice fell immediately after successfully saving to MongoDb, but before clearing the processing queue list, then this data will be considered unsaved - and after 15 minutes will be saved again.
To reduce the likelihood of such a scenario, we have provided repeated attempts to remove from the processing queue in case of errors. In reality, we have not yet observed such cases in production. - When the radish is reloaded, it can lose not only the cache, but also some of the unsaved scans from the queues, since it is configured to periodically save the RDB snapshots every few minutes.
Although in theory this can be a serious problem (especially if the project deals with really critical data), in practice the nodes are restarted extremely rarely. At the same time, according to monitoring, the elements are held in queues for less than 3 seconds, that is, the possible amount of losses is severely limited.
It may seem that the problems turned out more than we would like. However, in fact, it turns out that the scenario from which we were originally protected - the failure of MongoDB - is indeed a much more real threat, and the new data processing scheme successfully ensures the availability of the service and prevents losses.
One of the clearest examples of this was the case when the MongoDB instance on one of the projects was unavailable all night by ridiculous chance. All this time, the viewing counters were accumulated and rotated in radish from one queue to another, until they were finally stored in the database after the incident was resolved; most users fail to even notice.
Reading view counters
Read requests are much easier to write than write: microservice first checks the cache in radish; all that is not found in the cache is filled with data from MongoDb and returned to the client.
There is no pass-through to the cache for read operations to avoid the overhead of protecting against concurrent writing. The smarter cache still remains quite good, since most often it already turns out to be warmed up due to other write requests.
Statistics of views by day is read from MongoDB directly, since it is requested less often, and it is more difficult to cache it. It also means that when the database is unavailable, reading the statistics stops working; but it only affects a small part of users.
Data storage scheme in MongoDB
The MongoDB collection scheme for the project is based on these recommendations from the database developers themselves , and looks like this:
- Views are saved in 2 collections: one contains their total amount, the other contains statistics by day.
- The data in the collection with statistics is organized according to the principle of one document per advertisement per month . For new listings, a document is inserted in the collection, filled with thirty-one zero for the current month; According to the article mentioned above, this allows you to immediately allocate enough space for a document on disk so that the database does not have to move it when adding data.
This item makes the process of reading statistics a bit awkward (requests have to be formed by months on the side of microservice), but in general the scheme remains quite intuitive. - For recording, an upsert operation is used to update and, if necessary, create a document for the required entity within a single request.
We don’t use the transactional capabilities of MongoDb to update several collections at the same time, which means we run the risk that data can be written only into one collection. For the time being, we are just logging such cases; there are a few of them, and so far this does not present the same significant problem as other scenarios.
Testing
I would not trust my own words about the fact that the described scripts really work if they were not covered with tests.
Since most of the project code works closely with radish and MongoDb, most of the tests in it are integration tests. The test environment is supported through docker-compose, which means it is deployed quickly, provides reproducibility by resetting and restoring state every time it starts, and allows you to experiment without affecting other people's databases.
There are 3 main areas of testing in this project:
- Validation of business logic in typical scenarios, so-called. happy-path. These tests answer the question - when all subsystems are in order, does the service work according to functional requirements?
- Check negative scenarios in which it is expected that the service will continue its work. For example, does the service really lose data when MongoDb crashes?
Are we confident that the information remains consistent with periodic timeouts, freezes, and concurrent write operations? - Checking negative scenarios in which we do not expect the service to continue, but the minimum level of functionality should still be provided. For example, there is no chance that the service will continue to store and give away data when neither radish nor Mongo is available - but we want to be sure that in such cases it does not fall, it waits for the system to recover and then returns to work.
To check for failed scenarios, the service business logic code works with the database client interfaces, which in the necessary tests are replaced with implementations that return errors and \ or simulate network delays. We also simulate the parallel operation of several instances of the service using the pattern " environment objectThis is a variant of the well-known “inversion of control” approach, where functions do not address dependencies independently, but receive them through the environment object passed in the arguments. Among other advantages, the approach allows simulating several independent copies of the service in one test, each of which has its own connection pool to the database and more or less effectively reproduces the production environment. Some tests run each such instance in parallel and make sure that they all see the same data, and race conditions are missing.
We also they conducted a rudimentary, but still quite useful
siege- based stress test , which helped to estimate roughly the allowable load and speed of response from the service.
About performance
For 90% of requests, the processing time is very insignificant, and most importantly, stable; Here is an example of measurements on one of the projects over several days:
Interestingly, the record (which is actually a write + read operation, because it returns updated values) is slightly faster than the read (but only from the point of view of a client who does not observe actual deferred entry).
A regular morning increase in delays is a side effect of the work of our analytics team, which daily collects its own statistics based on service data, creating an “artificial highload” for us.
The maximum processing time is relatively long: among the slowest requests, new and unpopular ads show themselves (if the ad was not viewed and displayed only in the lists - its data does not fall into the cache and are read from MongoDB), group requests for multiple ads at once (they were worth to make a separate schedule), as well as possible network delays:
Conclusion
Practice, to some extent, counterintuitively, showed that using Redis as the main repository for the display service increased overall stability and improved its overall speed.
The main load of the service is read requests, 95% of which are returned from the cache, and therefore they work very quickly. Write requests are deferred, although from the end user's point of view, they also work quickly and become visible to all clients immediately. In general, almost all customers receive responses in less than 5ms.
As a result, the current version of microservice based on Go, Redis and MongoDB successfully works under load and is able to survive the periodic inaccessibility of one of the data stores. Based on previous experience with infrastructure problems, we identified the main error scenarios and successfully defended against them, so that most users are not inconvenienced. And we, in turn, receive much less complaints, alerts and messages in the logs - and are ready for further increase in attendance.