Is it possible to calculate bitcoins faster, easier or easier?

It all started with the fact that I decided to get to know bitcoins better. I wanted to understand how they get them. Articles about bitcoins and blockchains have often been found recently, but there are not very many of them with all the technical details.
The easiest way to figure out all the details is to study open source. I undertook to study Verilog source codes of the FPGA miner . This is not the only such project, there are several more examples on github, and all of them, although from different authors, seem to work according to approximately the same scheme. It is possible that the author then they all had one, initially, just different developers adapt the same code for different chips and different boards ... At least it seemed to me ...
So I, having studied the source code of Verilog, adapted the project from github to the Mars rover3 board based on the Altera MAX10 FPGA, 50 thousand logic elements. I was able to start my miner and even able to start the process of calculating bitcoins, but I quit this business after half an hour due to futility. My FPGA miner is too slow at present. Well, let.
Honestly, I was not interested in the bitcoins themselves (well, these, these money surrogates), but rather the mathematical side of the SHA256 algorithm. This is what I would like to talk about. I conducted several experiments with the SHA256 algorithm, maybe the results of these experiments will seem interesting to you.
The first thing I needed to do for my experiments was to write a “clean” SHA256 implementation in Verilog.
In fact, there are many implementations of the SHA256 algorithm in Verilog, at least on the same opencores.org , at least on github.com . However, such implementations are not suitable for me for experiments. Existing modules always have a pipeline structure, a pipeline. It would seem that this is correct. Only if there is a pipeline can you get a high speed algorithm. The SHA256 algorithm consists of 64 processing steps, the so-called "rounds". If the FPGA allows, then you can deploy all 64 rounds into a single chain of operations: all stages of the calculations are performed in parallel for one clock cycle of the operating frequency. Something like this:

At the input of the algorithm, eight 32-bit SHA256 machine state words. These are registers A, B, C, D, E, F, G, H. The input data itself, 512 bits, is converted to W coefficients, which are mixed in each round. As new words data are loaded into the registers of the first round, the second round continues to read the data loaded on the previous measure, the third round continues to read what was loaded on the previous-previous measure, and so on. The final latency, that is, the delay in the calculation result will be exactly 64 cycles, but in general, the pipeline allows you to read the entire algorithm in 1 cycle. If the volume of the FPGA is small and does not allow to expand the entire chain of rounds, then it is halved. So it turns out to fit the project into the existing FPGA, but the computational speed naturally halves as well. You can take an even less capacious FPGA and fit it there, but you’ll have to shorten the pipeline again and performance will suffer again. As I understand it, the entire Bitcoin miner, in which two consecutive SHA256-transforms, needs about 80 thousand logic elements in the Altera / Intel FPGA. But I was distracted ...
So, I want to do a completely absurd thing - write in Verilog a “pure” function of the SHA256 algorithm without intermediate registers, leave it without a pipeline. The goal of this strange action is simple - to determine the real amount of logic needed to calculate the SHA256 algorithm. I need a simple combinational circuit that feeds 512 bits of data (well, 256 bits of the initial state) and it produces 256 bits of the result.
I wrote this Verilog module, somewhere I wrote something myself, borrowed something from other open sources. My project is sha256-test.
Here is a pure Raman SHA256, not a single intermediate register
module e0 (x, y);
input [31:0] x;
output [31:0] y;
assign y = {x[1:0],x[31:2]} ^ {x[12:0],x[31:13]} ^ {x[21:0],x[31:22]};
endmodule
module e1 (x, y);
input [31:0] x;
output [31:0] y;
assign y = {x[5:0],x[31:6]} ^ {x[10:0],x[31:11]} ^ {x[24:0],x[31:25]};
endmodule
module ch (x, y, z, o);
input [31:0] x, y, z;
output [31:0] o;
assign o = z ^ (x & (y ^ z));
endmodule
module maj (x, y, z, o);
input [31:0] x, y, z;
output [31:0] o;
assign o = (x & y) | (z & (x | y));
endmodule
module s0 (x, y);
input [31:0] x;
output [31:0] y;
assign y[31:29] = x[6:4] ^ x[17:15];
assign y[28:0] = {x[3:0], x[31:7]} ^ {x[14:0],x[31:18]} ^ x[31:3];
endmodule
module s1 (x, y);
input [31:0] x;
output [31:0] y;
assign y[31:22] = x[16:7] ^ x[18:9];
assign y[21:0] = {x[6:0],x[31:17]} ^ {x[8:0],x[31:19]} ^ x[31:10];
endmodule
module round (idx, in, k, w, out);
input [7:0]idx;
input [255:0]in;
input [ 31:0]k;
input [ 31:0]w;
output [255:0]out;
always @(w)
$display("i=%d k=%8x w=%8x",idx,k,w);
wire [31:0]a; assign a = in[ 31: 0];
wire [31:0]b; assign b = in[ 63: 32];
wire [31:0]c; assign c = in[ 95: 64];
wire [31:0]d; assign d = in[127: 96];
wire [31:0]e; assign e = in[159:128];
wire [31:0]f; assign f = in[191:160];
wire [31:0]g; assign g = in[223:192];
wire [31:0]h; assign h = in[255:224];
wire [31:0]e0_w; e0 e0_(a,e0_w);
wire [31:0]e1_w; e1 e1_(e,e1_w);
wire [31:0]ch_w; ch ch_(e,f,g,ch_w);
wire [31:0]mj_w; maj maj_(a,b,c,mj_w);
wire [31:0]t1; assign t1 = h+w+k+ch_w+e1_w;
wire [31:0]t2; assign t2 = mj_w+e0_w;
wire [31:0]a_; assign a_ = t1+t2;
wire [31:0]d_; assign d_ = d+t1;
assign out = { g,f,e,d_,c,b,a,a_ };
endmodule
module sha256_transform(
input wire [255:0]state_in,
input wire [511:0]data_in,
output wire [255:0]state_out
);
localparam Ks = {
32'h428a2f98, 32'h71374491, 32'hb5c0fbcf, 32'he9b5dba5,
32'h3956c25b, 32'h59f111f1, 32'h923f82a4, 32'hab1c5ed5,
32'hd807aa98, 32'h12835b01, 32'h243185be, 32'h550c7dc3,
32'h72be5d74, 32'h80deb1fe, 32'h9bdc06a7, 32'hc19bf174,
32'he49b69c1, 32'hefbe4786, 32'h0fc19dc6, 32'h240ca1cc,
32'h2de92c6f, 32'h4a7484aa, 32'h5cb0a9dc, 32'h76f988da,
32'h983e5152, 32'ha831c66d, 32'hb00327c8, 32'hbf597fc7,
32'hc6e00bf3, 32'hd5a79147, 32'h06ca6351, 32'h14292967,
32'h27b70a85, 32'h2e1b2138, 32'h4d2c6dfc, 32'h53380d13,
32'h650a7354, 32'h766a0abb, 32'h81c2c92e, 32'h92722c85,
32'ha2bfe8a1, 32'ha81a664b, 32'hc24b8b70, 32'hc76c51a3,
32'hd192e819, 32'hd6990624, 32'hf40e3585, 32'h106aa070,
32'h19a4c116, 32'h1e376c08, 32'h2748774c, 32'h34b0bcb5,
32'h391c0cb3, 32'h4ed8aa4a, 32'h5b9cca4f, 32'h682e6ff3,
32'h748f82ee, 32'h78a5636f, 32'h84c87814, 32'h8cc70208,
32'h90befffa, 32'ha4506ceb, 32'hbef9a3f7, 32'hc67178f2};
genvar i;
generate
for(i=0; i<64; i=i+1)
begin : RND
wire [255:0] state;
wire [31:0]W;
if(i<16)
begin
assign W = data_in[i*32+31:i*32];
end
else
begin
wire [31:0]s0_w; s0 so_(RND[i-15].W,s0_w);
wire [31:0]s1_w; s1 s1_(RND[i-2].W,s1_w);
assign W = s1_w + RND[i - 7].W + s0_w + RND[i - 16].W;
end
if(i == 0)
round R (
.idx(i[7:0]),
.in(state_in),
.k( Ks[32*(63-i)+31:32*(63-i)] ),
.w(W),
.out(state) );
else
round R (
.idx(i[7:0]),
.in(RND[i-1].state),
.k( Ks[32*(63-i)+31:32*(63-i)] ),
.w(W),
.out(state) );
end
endgenerate
wire [31:0]a; assign a = state_in[ 31: 0];
wire [31:0]b; assign b = state_in[ 63: 32];
wire [31:0]c; assign c = state_in[ 95: 64];
wire [31:0]d; assign d = state_in[127: 96];
wire [31:0]e; assign e = state_in[159:128];
wire [31:0]f; assign f = state_in[191:160];
wire [31:0]g; assign g = state_in[223:192];
wire [31:0]h; assign h = state_in[255:224];
wire [31:0]a1; assign a1 = RND[63].state[ 31: 0];
wire [31:0]b1; assign b1 = RND[63].state[ 63: 32];
wire [31:0]c1; assign c1 = RND[63].state[ 95: 64];
wire [31:0]d1; assign d1 = RND[63].state[127: 96];
wire [31:0]e1; assign e1 = RND[63].state[159:128];
wire [31:0]f1; assign f1 = RND[63].state[191:160];
wire [31:0]g1; assign g1 = RND[63].state[223:192];
wire [31:0]h1; assign h1 = RND[63].state[255:224];
wire [31:0]a2; assign a2 = a+a1;
wire [31:0]b2; assign b2 = b+b1;
wire [31:0]c2; assign c2 = c+c1;
wire [31:0]d2; assign d2 = d+d1;
wire [31:0]e2; assign e2 = e+e1;
wire [31:0]f2; assign f2 = f+f1;
wire [31:0]g2; assign g2 = g+g1;
wire [31:0]h2; assign h2 = h+h1;
assign state_out = {h2,g2,f2,e2,d2,c2,b2,a2};
endmodule
Naturally, you need to make sure that the module is working. To do this, you need a simple testbench to submit some data block to the input and see the result.
Here is a testbench Verilog
`timescale 1ns/1ps
module tb;
initial
begin
$dumpfile("tb.vcd");
$dumpvars(0, tb);
#100;
$finish;
end
wire [511:0]data;
assign data = 512'h66656463626139383736353433323130666564636261393837363534333231306665646362613938373635343332313066656463626139383736353433323130;
wire [255:0]result;
sha256_transform s(
.state_in( 256'h5be0cd191f83d9ab9b05688c510e527fa54ff53a3c6ef372bb67ae856a09e667 ),
.data_in(data),
.state_out(result)
);
endmodule
I will compare it with the answer given to me by the sha256_transform function written in C (can I not give the C code? These implementations in C / C ++ are completely complete). Main result: I
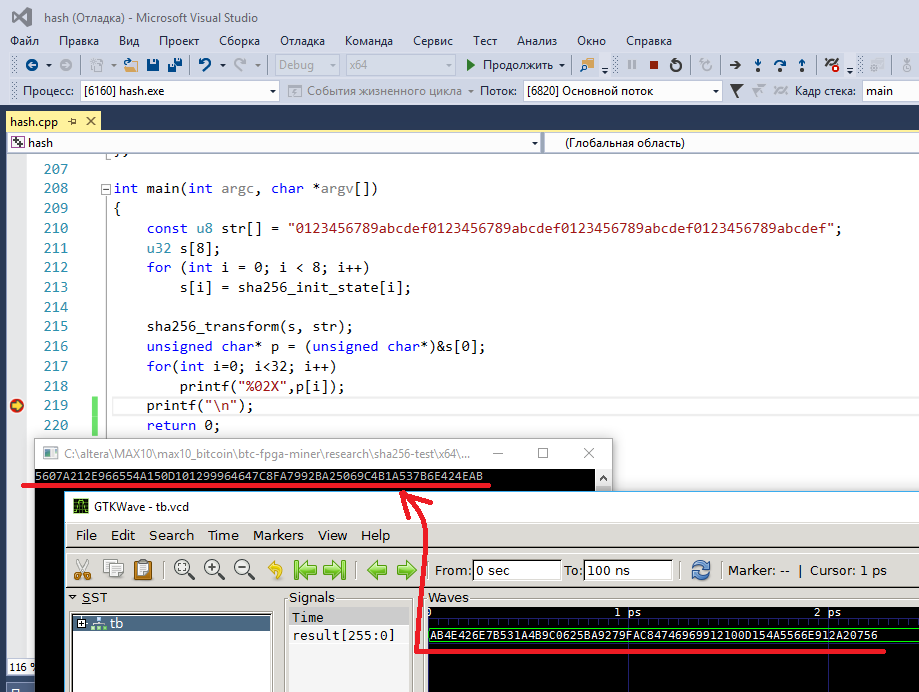
program in C / C ++ in Visual Studio, and I test the Verilog program with icarus verilog and gtkwave. I was convinced that the answers match, so you can move on.
Now you can insert the module into the FPGA and see how many logical elements such a function can occupy.
We make such a project for FPGAs:
module sha256_test(
input wire clk,
input wire data,
output wire [255:0]result
);
reg [511:0]d;
always @(posedge clk)
d <= { d[510:0],data };
sha256_transform s0(
.state_in( 256'h5be0cd191f83d9ab9b05688c510e527fa54ff53a3c6ef372bb67ae856a09e667 ),
.data_in( d ),
.state_out(result)
);
endmodule
Here it is assumed that the input data is pushed into one long register of 512 bits, which is fed as input to my “clean” SHA256_transform. All 256 output bits are output to the output pin of the FPGA.
I am compiling, for the FPGA Cyclone IV, and I see that this thing will take 30.103 logical elements.
We’ll remember this number well: 30103 ...
Let's do the second experiment. The project "sha256-eliminated".
module sha256_test(
input wire clk,
input wire data,
output wire [255:0]result
);
sha256_transform s0(
.state_in( 256'h5be0cd191f83d9ab9b05688c510e527fa54ff53a3c6ef372bb67ae856a09e667 ),
.data_in( 512'h66656463626139383736353433323130666564636261393837363534333231306665646362613938373635343332313066656463626139383736353433323130 ),
.state_out(result)
);
endmodule
Here I do not submit the input data to the FPGA from the outside, but simply set it with a constant, constant input signal for the sha256_transform module.
We compile in FPGA. You know how many logical elements will be involved in this case: ZERO .
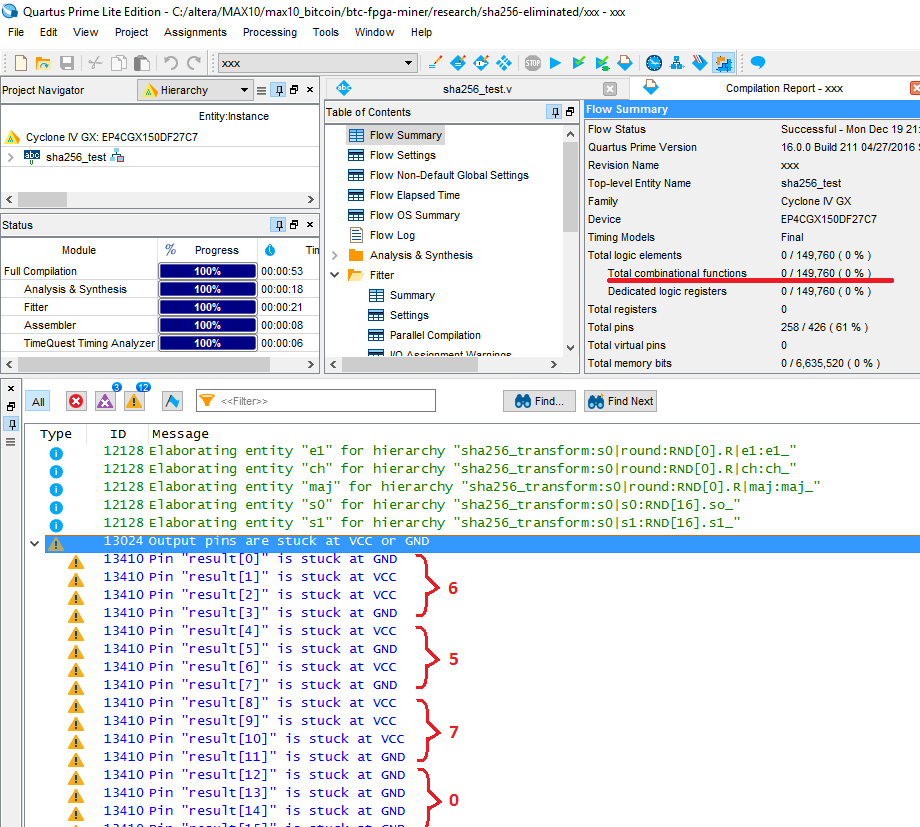
Altera (or is it Intel already? What should I call it right?) Quartus Prime optimizes the entire logic of the device and since there are no registers and there are no input signals on which the result would depend, the entire combination function degenerates, from the input parameters of the SHA256 module the answer is calculated right during compilation. You can see the output signals on the FPGA pins. The compiler immediately writes that some signals will be coupled to ground, and some to VCC, to the supply voltage. So the outputs calculated by the compiler will appear on the outputs: 0x56, 0x70, ... just like in my very first test case.
Hence, such a thought arises. Since the compiler is so smart and can optimize the logic so well, why not consider only one output bit from sha256? How much logic is needed to count only one resulting bit?
Indeed. Bitcoins are considered as follows: there is a data block. There is a variable field in the data block that can be changed - this is a nonce field, 32 bits. The remaining data in the block is fixed. We must change, iterate over the nonce field so that the sha256 result is “special”, namely, so that the high bits of the sha256-transform result are zero.
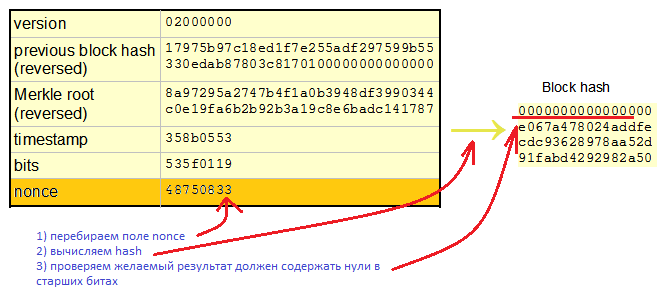
Here we consider sha256 once, then increase nonce by one, again we have the hash, then again and again. Hundreds, thousands of times the same data block but a slightly different nonce field. In this case, all bits of the sha256 result are calculated, that is, all output bits are 256 bits. Is it energetically beneficial? Is this advantageous in terms of the number of logical elements involved?
But what if you count only one of the most significant bits of the result. He thinks it is equally likely to be either zero or one. If it turns out to be one, then the remaining bits do not need to be counted. Why waste precious energy on them?
Having made this assumption, for some reason I immediately decided for myself that the number of logical elements for calculating only one bit of the hash should be 256 times less than for calculating all bits of the result. But I was wrong.
To test this hypothesis, I decided to make a project for a quartus with a top module that looks like this:
module sha256_test(
input wire clk,
input wire data,
output wire result
);
reg [511:0]d;
always @(posedge clk)
d <= { d[510:0],data };
wire [255:0]r;
sha256_transform s0(
.state_in( 256'h5be0cd191f83d9ab9b05688c510e527fa54ff53a3c6ef372bb67ae856a09e667 ),
.data_in( d ),
.state_out(r)
);
assign result = r[187]; //номер бит, который нас интересует
endmodule
Note that it seems that sta256_transform will calculate the entire hash and the response will be in the signal wire [255: 0] r, however, the output of the Verilog module is only one bit, which assign result = r [187]; This will allow the compiler to effectively leave only the logic that is needed to calculate the desired bit. The rest will be optimized and removed from the project.
To conduct my experiment, I just need to fix the penultimate line and recompile the project 256 times. To facilitate this work, I will write a script for a quartus:
#!/usr/bin/tclsh
proc read_rpt { i frpt } {
set fp [open "output_files/xxx.map.summary" r]
set file_data [read $fp]
close $fp
set data [split $file_data "\n"]
foreach line $data {
set half [split $line ":"]
set a [lindex $half 0]
set b [lindex $half 1]
if { $a == " Total combinational functions " } {
puts [format "%d %s" $i $b]
puts $frpt [format "%d %s" $i $b]
}
}
}
proc gen_sha256_src { i } {
set fo [open "sha256_test.v" "w"]
puts $fo "module sha256_test("
puts $fo " input wire clk,"
puts $fo " input wire data,"
puts $fo " output wire result"
puts $fo ");"
puts $fo ""
puts $fo "reg \[511:0]d;"
puts $fo "always @(posedge clk)"
puts $fo " d <= { d\[510:0],data };"
puts $fo ""
puts $fo "wire \[255:0]r;"
puts $fo "sha256_transform s0("
puts $fo " .state_in( 256'h5be0cd191f83d9ab9b05688c510e527fa54ff53a3c6ef372bb67ae856a09e667 ),"
puts $fo " .data_in( d ),"
puts $fo " .state_out(r)"
puts $fo " );"
puts $fo ""
puts $fo "assign result = r\[$i];"
puts $fo ""
puts $fo "endmodule"
close $fo
}
set frpt [open "rpt.txt" "w"]
for {set i 0} {$i < 256} {incr i} {
gen_sha256_src $i
exec x.bat
read_rpt $i $frpt
}
close $frpt
exit
This script re-creates the sha256_test.v module in a loop and each time it outputs the next bit of the sha256 result to the FPGA output pin.
I run the script for a couple of hours and voila. There is a table of values. Now we know for sure which bit from SHA256 is the easiest to compute. Here is a graph of the dependence of the required number of logical elements on the serial number of the calculated SHA256 bit:

From this it becomes clear that the easiest way to calculate the bit number is 224. It requires 27204 logical elements. This is actually almost 10% less than when calculating all 256 output bits.
The graph in the form of a saw is explained by the fact that the SHA256 algorithm has many adders. In the adder, each next most significant bit is more difficult to calculate than the previous least significant one. This is because of the transfer scheme, because adders consist of many full-adder blocks.
Ghostly energy savings have already appeared. I believe that every logical function eats energy. The lower the number of LE gates involved in an FPGA project, the lower the energy consumption. The proposed algorithm is this: consider one simplest bit; if it is zero, then consider the next one. If it is one, then we do not waste energy and strength and time on the remaining bits in the same hash.
Now another thought, also related to the compiler's ability to optimize logic.
Since, when enumerating the nonce field, the main data of the block remains the same, it is logical and obvious that from cycle to cycle, some calculations simply repeat and consider the same thing. Question: how to estimate how much energy is lost there on repeated calculations?
The experiment is simple. We put, for example, two sha256_transform modules side by side and feed them the same input, well, with the exception of one bit. We believe that these two modules consider neighboring nonce differing in one bit.
module sha256_test(
input wire clk,
input wire data,
output wire [1:0]result
);
reg [511:0]d;
always @(posedge clk)
d <= { d[510:0],data };
wire [255:0]r0;
sha256_transform s0(
.state_in( 256'h5be0cd191f83d9ab9b05688c510e527fa54ff53a3c6ef372bb67ae856a09e667 ),
.data_in( { 1'b0, d[510:0] } ),
.state_out(r0)
);
wire [255:0]r1;
sha256_transform s1(
.state_in( 256'h5be0cd191f83d9ab9b05688c510e527fa54ff53a3c6ef372bb67ae856a09e667 ),
.data_in( { 1'b1, d[510:0] } ),
.state_out(r1)
);
assign result = { r0[224], r1[224] };
endmodule
Each of the modules s0 and s1 consider their hash from the same input, only differ by one nonce. From each I take only the “lightest” bit of the result, bit number 224.
How long does this logic take in the FPGA? 47,805 logical elements. Since there are two modules, one takes 47805/2 = 23902. It turns out that starting to read two hashes at once is much more profitable than counting them in turn due to the fact that there are general calculations.
And if you start counting immediately 4 hashes and only 2 bits different on the nonce field? It turns out 89009LE / 4 = 22252 LE / SHA256
And if you count 8 hashes? It turns out 171418LE / 8 = 21427 LE / SHA256
Here you can compare the initial number of logic gates 30103 on the full SHA256_transform with the output of 256 bits of the result and 21427 logic gates on the SHA256_transfrom with the output of one bit of the result (which can be used to predict the feasibility of further calculations). It seems to me that such methods can reduce the energy consumption of a miner by about a third. Well, a quarter ... I do not know how significant this is, but it seems that this is significant.
There is one more thought. The main data in the block for calculation remains fixed and only the nonce field changes during the calculation of the hash. If it were possible to quickly compile for FPGAs, a significant part of the precomputations could be performed at the compilation stage. After all, I showed above how efficiently the compiler calculates everything that can be calculated in advance. Optimized logic with precomputations will be much or much smaller in volume than is required for a full computer, therefore it will consume less energy.
Something like that. In fact, I myself am not completely sure of my research. Maybe I don’t take into account something or do not understand. The proposed methods, of course, do not give a global breakthrough, but something can be saved. So far, these are all rather theoretical considerations. For practical implementation, a “pure” SHA256 is not suitable - it will have a too low operating frequency. It’s necessary to introduce a pipeline.
There is one more factor. In real life, two consecutive SHA256_transform are counted for bitcoin. In this case, my estimated gain in the number of logic elements and energy consumption may not be so significant.
Sources of the bitcon miner project for the Mars rover3 board with the Altera MAX10, 50K LE FPGA here. Here, in the research folder, there are all the sources of my experiments with the SHA256 algorithm.
Description of the miner FPGA project here