Limit the speed of traffic transmission. Policer or shaper, what to use on the network?

When it comes to limiting bandwidth on network equipment, two technologies first come to mind: policer and shaper. Policer limits the speed by discarding "extra" packets, which lead to exceeding the specified speed. Shaper tries to smooth the speed to the desired value by buffering packets. I decided to write this article after reading the notes on the blog of Ivan Pepelnjak (Ivan Pepelnjak). Once again, the question arose in it: which is better - policer or shaper. And as often happens with such questions, the answer to it: it all depends on the situation, since each of the technologies has its pros and cons. I decided to deal with this a little more in detail, by conducting simple experiments. The results obtained by rolling.
And so, let's start with the general picture of the difference between policer and shaper.
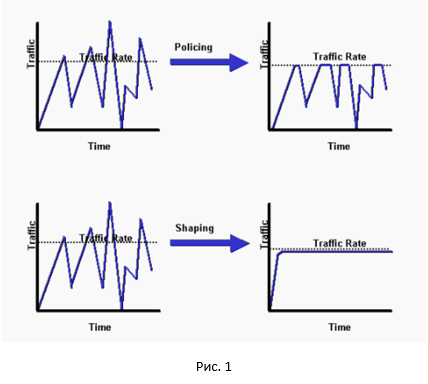
As you can see, policer cuts off all peaks, while shaper does smoothing of our traffic. A pretty good comparison between policer and shaper can be found here .
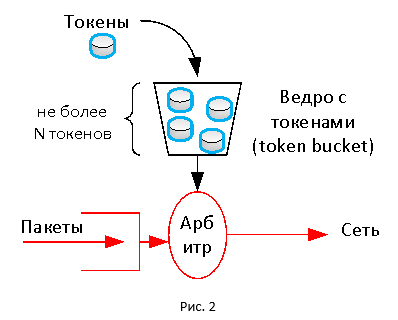
Both technologies basically use the token mechanism. In this mechanism, there is a virtual token bucket of limited size, into which tokens arrive with some regularity. A token, like a travel card, is used to transfer packets. If there are no tokens in the bucket, then the packet is discarded (other actions can be performed). Thus, we get a constant traffic transfer rate, as tokens enter the bucket in accordance with a given speed.
Maybe it should be easier?
Session speed is usually measured in the allotted time period, for example, in 5 seconds or 5 minutes. It is pointless to take the instantaneous value, since data is always transmitted at the channel speed. Moreover, if we do averaging over different time intervals, we will get different graphs of the data transfer speed, since the traffic on the network is not uniform. I think anyone has come across this when building graphs in a monitoring system.
The token mechanism allows for flexibility in setting the speed limit. The size of the bucket affects how we average our speed. If the bucket is large (that is, there can be a lot of tokens accumulated there), we will allow traffic to “jump out” more for the allotted restrictions at certain points in time (the equivalent of averaging over a longer period of time). If the bucket size is small, then the traffic will be more uniform, extremely rarely exceeding the specified threshold (the equivalent of averaging over a short period of time).
The token mechanism allows for flexibility in setting the speed limit. The size of the bucket affects how we average our speed. If the bucket is large (that is, there can be a lot of tokens accumulated there), we will allow traffic to “jump out” more for the allotted restrictions at certain points in time (the equivalent of averaging over a longer period of time). If the bucket size is small, then the traffic will be more uniform, extremely rarely exceeding the specified threshold (the equivalent of averaging over a short period of time).
In the case of the policer, the bucket is filled every time a new package arrives. The number of tokens that are loaded into the bucket depends on the set policer speed and the time elapsed since the last packet arrived. If there are no tokens in the bucket, policer can drop packets or, for example, re-mark them (assign new DSCP or IPP values). In the case of shaper, filling the bucket occurs at regular intervals regardless of the arrival of the packages. If there are not enough tokens, the packets fall into a special queue where they wait for the tokens to appear. Due to this, we have smoothing. But if there are too many packets, the shaper's queue eventually overflows and packets begin to be discarded. It is worth noting that the above description is simplified,
Experiment
And what does it look like in practice? To do this, collect a test bench and conduct the following experiment . Our stand will include a device that supports policer and shaper technologies (in my case, it is Cisco ISR 4000; any vendor’s hardware or software device that supports these technologies is suitable), an iPerf traffic generator and Wireshark traffic analyzer .
First, let's take a look at policer. Set the speed limit to 20 Mbps.
Device configuration
policy-map Policer_20
class class-default
police 20000000
interface GigabitEthernet0/0/1
service-policy output Policer_20In iPerf, we start generating traffic within four streams using the TCP protocol.
C:\Users\user>iperf3.exe -c 192.168.115.2 -t 20 -i 20 -P 4
Connecting to host 192.168.115.2, port 5201
[ 4] local 192.168.20.8 port 55542 connected to 192.168.115.2 port 5201
[ 6] local 192.168.20.8 port 55543 connected to 192.168.115.2 port 5201
[ 8] local 192.168.20.8 port 55544 connected to 192.168.115.2 port 5201
[ 10] local 192.168.20.8 port 55545 connected to 192.168.115.2 port 5201
[ ID] Interval Transfer Bandwidth
[ 4] 0.00-20.01 sec 10.2 MBytes 4.28 Mbits/sec
[ 6] 0.00-20.01 sec 10.6 MBytes 4.44 Mbits/sec
[ 8] 0.00-20.01 sec 8.98 MBytes 3.77 Mbits/sec
[ 10] 0.00-20.01 sec 11.1 MBytes 4.64 Mbits/sec
[SUM] 0.00-20.01 sec 40.9 MBytes 17.1 Mbits/sec
The average speed was 17.1 Mbps. Each session received a different bandwidth. This is due to the fact that the policer configured in our case does not distinguish between streams and discards any packets that exceed the specified speed value.
Using Wireshark, we collect a traffic dump and build a data transfer schedule received on the sender side.
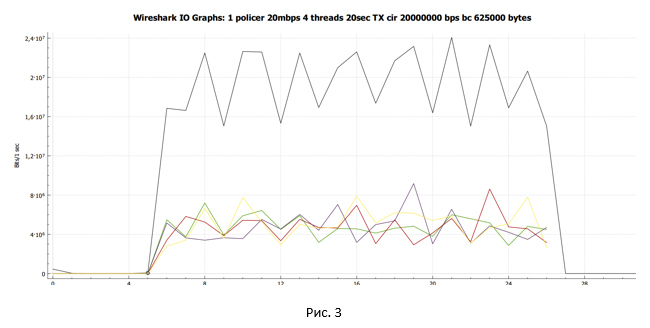
The black line shows the total traffic. Multi-colored lines - traffic of each TCP stream. Before we draw any conclusions and delve into the question, let's see what we can do if we replace the policer with a shaper.
Set the shaper to a speed limit of 20 Mbps.
Device configuration
When setting up, we use the automatically set value of the bucket size of the BC and BE tokens equal to 8000. But we change the queue size from 83 (by default in IOS XE version 15.6 (1) S2) to 200. This was done deliberately to get a clearer picture typical of shaper 'a. We will dwell on this question in more detail in the subcategory “Does the depth of the queue affect our session?”.
policy-map Shaper_20
class class-default
shape average 20000000
queue-limit 200 packets
interface GigabitEthernet0/0/1
service-policy output Shaper_20When setting up, we use the automatically set value of the bucket size of the BC and BE tokens equal to 8000. But we change the queue size from 83 (by default in IOS XE version 15.6 (1) S2) to 200. This was done deliberately to get a clearer picture typical of shaper 'a. We will dwell on this question in more detail in the subcategory “Does the depth of the queue affect our session?”.
cbs-rtr-4000#sh policy-map interface gigabitEthernet 0/0/1
Service-policy output: Shaper_20
Class-map: class-default (match-all)
34525 packets, 50387212 bytes
5 minute offered rate 1103000 bps, drop rate 0000 bps
Match: any
Queueing
queue limit 200 packets
(queue depth/total drops/no-buffer drops) 0/0/0
(pkts output/bytes output) 34525/50387212
shape (average) cir 20000000, bc 80000, be 80000
target shape rate 20000000
In iPerf, we start generating traffic within four streams using the TCP protocol.
C:\Users\user>iperf3.exe -c 192.168.115.2 -t 20 -i 20 -P 4
Connecting to host 192.168.115.2, port 5201
[ 4] local 192.168.20.8 port 62104 connected to 192.168.115.2 port 5201
[ 6] local 192.168.20.8 port 62105 connected to 192.168.115.2 port 5201
[ 8] local 192.168.20.8 port 62106 connected to 192.168.115.2 port 5201
[ 10] local 192.168.20.8 port 62107 connected to 192.168.115.2 port 5201
[ ID] Interval Transfer Bandwidth
[ 4] 0.00-20.00 sec 11.6 MBytes 4.85 Mbits/sec
[ 6] 0.00-20.00 sec 11.5 MBytes 4.83 Mbits/sec
[ 8] 0.00-20.00 sec 11.5 MBytes 4.83 Mbits/sec
[ 10] 0.00-20.00 sec 11.5 MBytes 4.83 Mbits/sec
[SUM] 0.00-20.00 sec 46.1 MBytes 19.3 Mbits/sec
The average speed was 19.3 Mbps. In addition, each TCP stream received approximately the same throughput.
Using Wireshark, we collect a traffic dump and build a data transfer schedule received on the sender side.
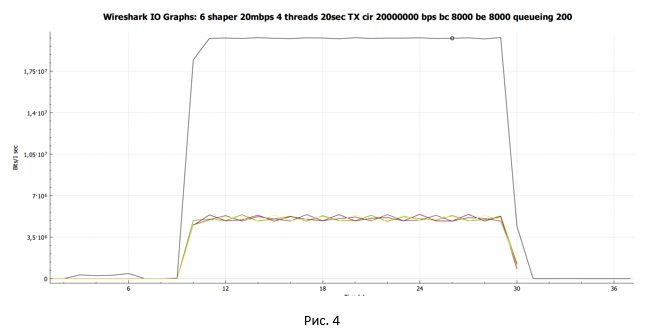
The black line shows the total traffic. Multi-colored lines - the traffic of each TCP stream.
Let's make the first intermediate conclusions:
- In the case of policer, the useful bandwidth was 17.1 Mbps. Each stream at different points in time had a different throughput.
- In the case of shaper, the usable throughput was 19.3 Mbit / s. All threads had approximately the same throughput.
Let's take a closer look at the behavior of a TCP session when policer and shaper work. Fortunately, there are enough tools in Wireshark to do such an analysis.
Let's start with the graphs on which the packets are displayed with reference to the time of their transmission. The first chart is policer, the second is shaper.
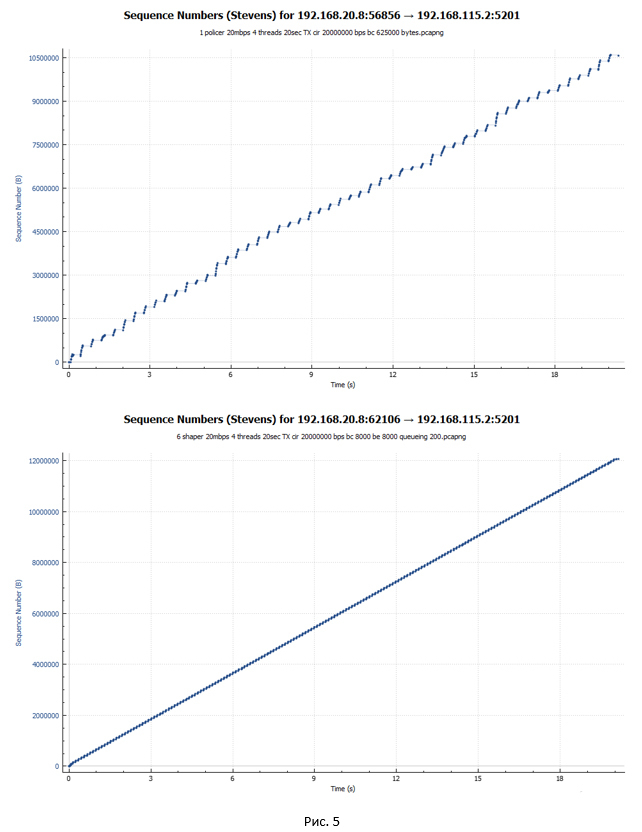
The graphs show that packets in the case of shaper are transmitted more evenly in time. Moreover, in the case of policer, spasmodic acceleration of the session and periods of pauses are visible.
Analysis of TCP session when working policer
Let's take a closer look at the TCP session. We will consider the case of the policer.
TCP in its work relies on a fairly large set of algorithms. Among them, the most interesting for us are the algorithms responsible for congestion control. They are responsible for the data transfer rate within the session. The PC running iPerf runs on Windows 10. In Windows 10, Compound TCP (CTCP) is used as such an algorithm . CTCP borrowed quite a lot from the TCP Reno algorithm in its work . Therefore, when analyzing a TCP session, it is quite convenient to look at the picture with the session states when running the TCP Reno algorithm.
{kind=link}
The following picture shows the initial data transfer segment.
- At the first stage, we set up a TCP session (a triple handshake occurs).
- Next, overclocking of the TCP session begins. The TCP slow-start algorithm works . By default, the congestion window (cwnd) value for a TCP session in Windows 10 is equal to the volume of the ten maximum TCP session data segments (MSS). This means that this PC can send 10 packets at once, without waiting for confirmation on them in the form of ACK. The initial value of the slow-start (ssthresh) termination threshold and the transition to congestion avoidence mode is the maximum window that the receiver provided (advertised window - awnd). In our case, ssthresh = awnd = 64K. Awnd - the maximum value of the data that the recipient is ready to receive in the buffer.Where to see the initial session data?You can use PowerShell to view TCP parameters.
We look at which global TCP template is used in our system by default.
Next, we execute the Get-NetTCPSetting Internet request and look for the value of the InitialCongestionWindow (MSS) value.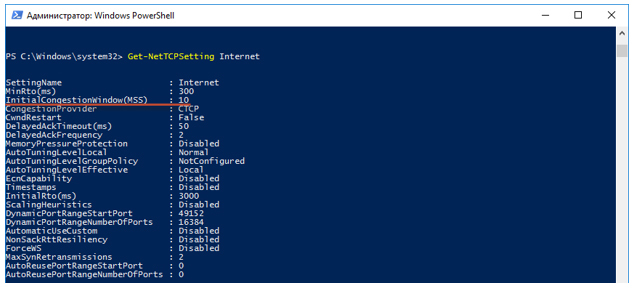
The awnd value can be found in the ACK packets received from the receiver: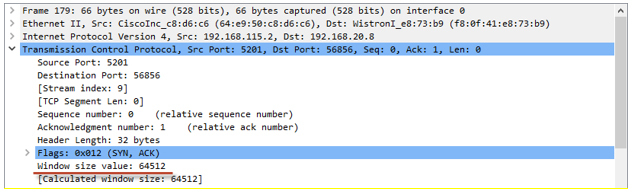
In TCP slow-start mode, the window size (cwnd) increases each time an ACK is received. However, it cannot exceed the awnd value. Due to this behavior, we have an almost exponential increase in the number of transmitted packets. Our TCP session accelerates quite aggressively.TCP packet transfer slow-start- The PC establishes a TCP connection (No. 1-3).
- It sends 10 packets (No. 4-13) without waiting for confirmation (ACK), since cwnd = 10 * MSS.
- Receives ACK (No. 14), which confirms two packets at once (No. 4-5).
- Increases window size Cwnd = (10 + 2) * MSS = 12 * MSS.
- Sends an additional three packets (No. 15-17). In theory, the PC was supposed to send four packets: two, since it received confirmation of two packets that were transmitted earlier; plus two packages due to window enlargement. But in reality, at the very first stage, the system sends (2N-1) packets. I could not find the answer to this question. If someone tells me, I will be grateful.
- Gets two ACKs (No. 18-19). The first ACK confirms that the remote side received four packets (No. 6-9). The second - three (No. 10-12).
- Increases window size Cwnd = (12 + 7) * MSS = 19 * MSS.
- It sends 14 packets (No. 20-33): seven new packets, because they received ACK for seven previously transmitted packets, and seven more new packets, as the window increased.
- Etc.
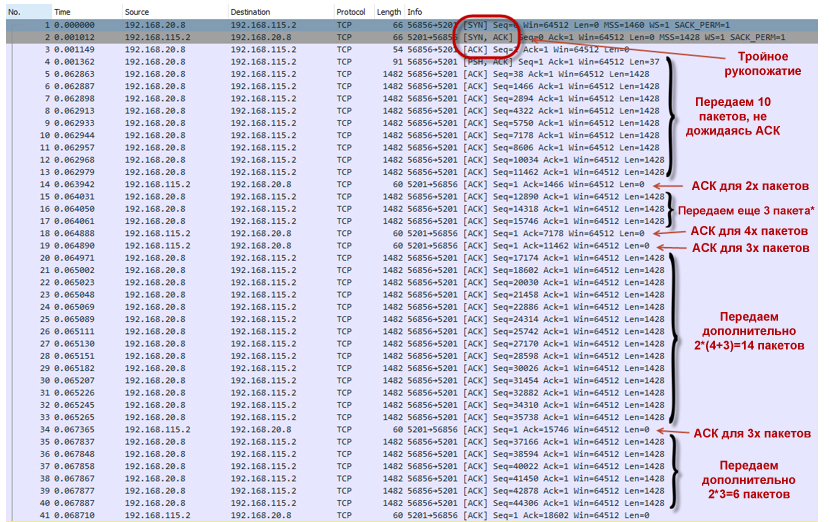
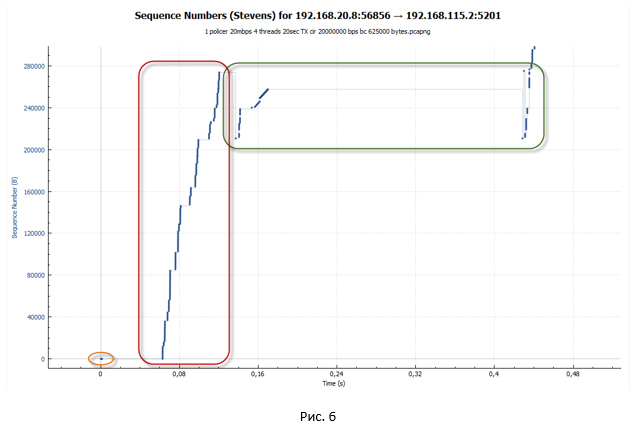
- Policer does not interfere with the dispersal of the session. There are many tokens in the bucket (when the policer is initialized, the bucket is completely filled with tokens). For a speed of 20 Mbps, the default bucket size is set to 625,000 bytes. Thus, a session is accelerated at a point in time to almost 18 Mbps (and we remember that we have four such sessions). The size of the cwnd window reaches its maximum value and becomes equal to awnd, which means cwnd = ssthersh.cwnd = ssthershWhen cwnd = ssthersh the exact answer, whether there will be a change of algorithm from slow-start to congestion avoidance algorithm, I could not find. The RFC does not give an exact answer. From a practical point of view, this is not very important, since the size of the window cannot grow further.
- Since our session was dispersed quite strongly, tokens are spent very quickly and eventually end. The bucket does not have time to fill up (filling with tokens is for a speed of 20 Mbit / s, while the total utilization by all four sessions at a point in time is close to 80 Mbit / s). Policer begins to drop packets. So, they do not reach the far side. The recipient sends a Duplicate ACK (Dup ACK), which signals the sender that there has been a loss of packets and you need to transfer them again.
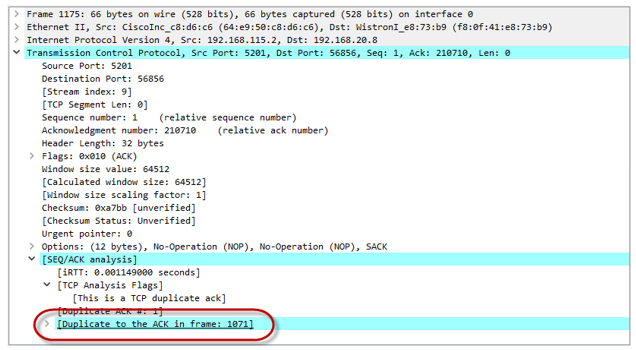
After receiving three Dup ACKs, our TCP session goes into the recovery phase after loss (loss recovery, including Fast Retransmit / Fast Recovery algorithms). The sender sets the new value ssthresh = cwnd / 2 (32K) and makes the window cwnd = ssthresh + 3 * MSS.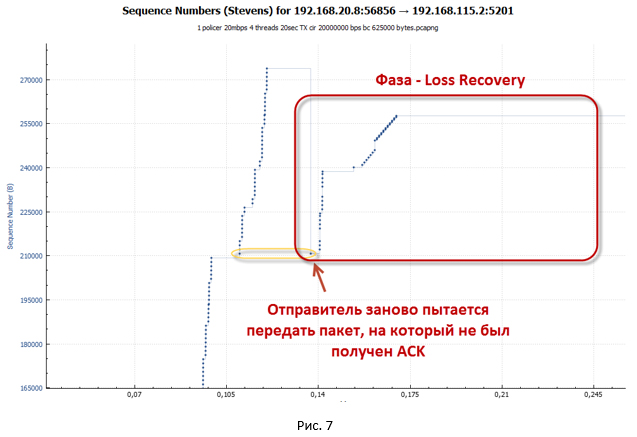
- The sender immediately tries to re-transmit the lost packets (the TCP Fast Retransmission algorithm works). At the same time, the Dup ACKs continue to come, the purpose of which is to artificially increase the cwnd window. This is necessary to restore the session speed as soon as possible due to packet loss. Due to the Dup ACK, the cwnd window grows to its maximum value (awnd).
As soon as the number of packets that fit into the cwnd window has been sent, the system stops. To continue data transfer she needs new ACKs (not Dup ACKs). But ACK does not come. All repeated packets are discarded by the policer, so the tokens have run out in the bucket, and too little time has passed to fill them up. - In this state, the system waits until the timeout for receiving a new ACK from the remote side (Retransmission timeout - RTO ) has worked . Our big pauses, which are visible on the charts, are precisely connected with this.
- After the RTO timer is triggered, the system goes into slow-start mode and sets ssthresh = FlightSize / 2 (where FlightSize is the number of unconfirmed data), and the window cwnd = 1 * MSS. Then again an attempt is made to transfer the lost packets. True, now only one packet is sent, since cwnd = 1 * MSS.
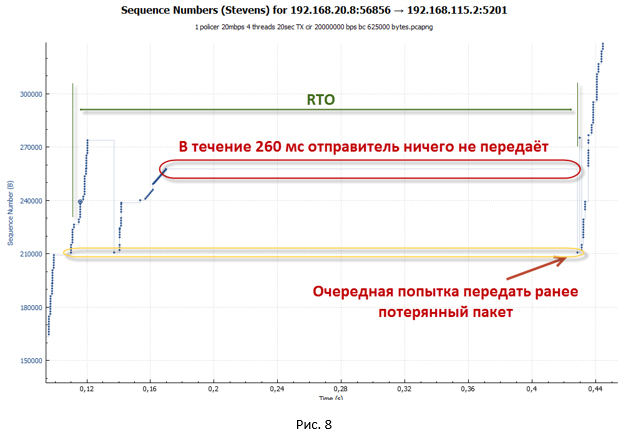
- Since for some time the system did not transmit anything, tokens managed to accumulate in our bucket. Therefore, in the end, the packet reaches the recipient. So, we will get a new ACK. From this moment, the system starts transmitting previously lost packets in slow-start mode. There is an acceleration of the session. As soon as the cwnd window is larger than ssthresh, the session enters congestion avoidance mode.
In the Compound TCP algorithm, the sending window (wnd) is used to control the transmission speed, which depends on two weighted values: the overload window (cwnd) and the delay window (dwnd). Cwnd, as before, depends on the received ACK, dwnd depends on the amount of RTT delay (round trip time). The wnd window grows only once per RTT time period. As we recall, in the case of slow-start, the cwnd window grew upon receipt of each ACK. Therefore, in congestion avoidance mode, the session does not accelerate so quickly. - As soon as the session accelerates strongly enough (when there are more packets transmitted than there are tokens in the bucket), policer is triggered again. Packets are discarded. This is followed by the loss recovery phase. Those. the whole process is repeated anew. And this continues until we complete the transfer of all data.
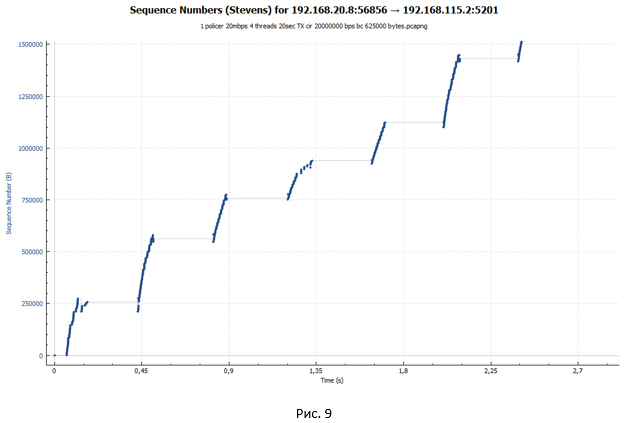
A policer TCP session looks like a ladder (there is a transmission phase followed by a pause).
Analysis of TCP session when working shaper
Now let's take a closer look at the data segment for the shaper case. For clarity, we take a similar scale as for the policer graph in Fig. 6.
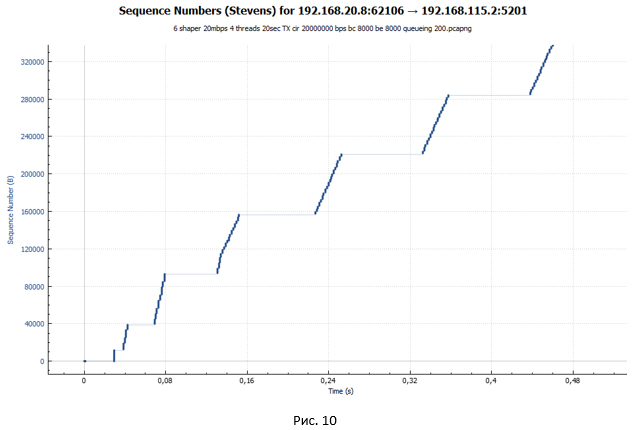
From the graph we see the same ladder. But the size of the steps has become significantly smaller. However, if you look closely at the graph in Fig. 10, we will not see small “waves” at the end of each step, as it was in Fig. 9. Such “waves” were the result of packet loss and attempts to retransmit them.
Consider the initial data transfer segment for the shaper case.
The session is being established. Next, overclocking starts in TCP slow-start mode. But this acceleration is more gentle and has pronounced pauses, which increase in size. A more gentle overclocking is due to the fact that the default bucket size for shaper total (BC + BE) = 20,000 bytes. While for policer, the bucket size is 625,000 bytes. Therefore, shaper works much earlier. Packets start to queue. The delay increases from sender to receiver, and ACKs come later than in the case of policer. The window grows much more slowly. It turns out that the more the system transmits packets, the more they accumulate in the queue, which means that the greater the delay in receiving the ACK. We have a process of self-regulation.
After a while, the cwnd window reaches awnd. But at this point, we are accumulating a fairly noticeable delay due to the presence of the queue. Ultimately, upon reaching a certain RTT value, an equilibrium state occurs when the session speed does not change anymore and reaches its maximum value for a given RTT. In my example, the average RTT is 107 ms, awnd = 64512 bytes, therefore, the maximum session speed will correspond to awnd / RTT = 4.82 Mbit / s. Approximately this value was given to us by iPerf during measurements.
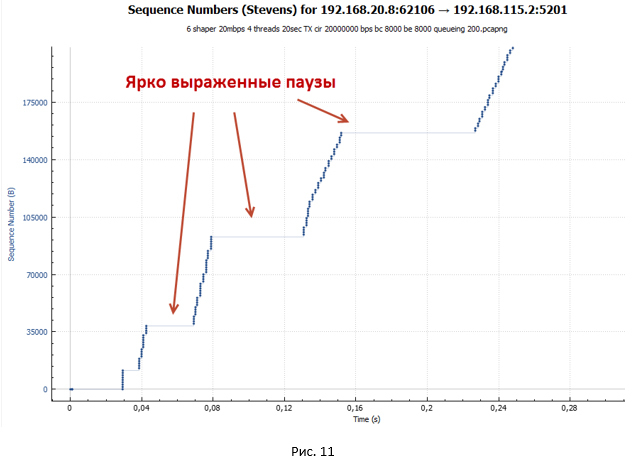
But where do the pronounced pauses in the transmission come from? Let's look at the schedule of packet transmission through a device with shaper in case we have only one TCP session (Fig. 12). Let me remind you that in our experiment, data transfer occurs within four TCP sessions.
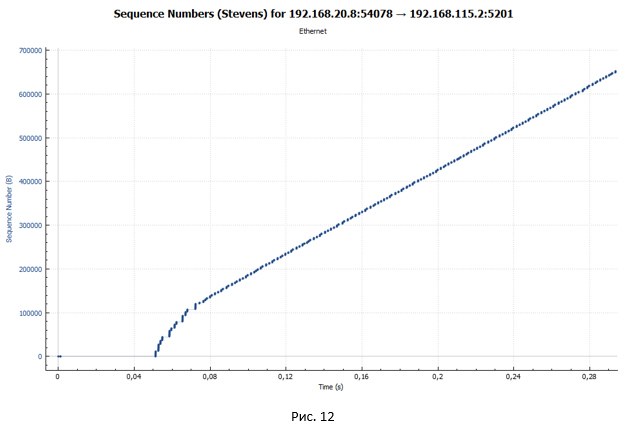
On this graph it is very clearly seen that there are no pauses. From this we can conclude that the pauses in Figs. 10 and 11 are due to the fact that we have four streams transmitted simultaneously, and there is only one queue in the shaper (type of FIFO queue).
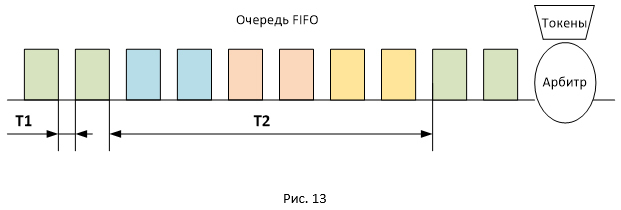
Figure 13 shows the location of packets of different sessions in the FIFO queue. Since packets are transmitted in batches, they will be queued in the same way. In this regard, the delay between receipt of packets on the receiving side will be of two types: T1 and T2 (where T2 significantly exceeds T1). The total RTT value for all packets will be the same, but packets will arrive in packets separated in time by the value of T2. So, pauses are obtained, since at time T2 no ACKs come to the sender, while the session window remains unchanged (has a maximum value equal to awnd).
WFQ Queue
It is logical to assume that if you replace one common FIFO queue with several for each session, there will be no pronounced pauses. For such a task, for example, a queue of the type Weighted Fair Queuing ( WFQ ) is suitable for us . For each session, it creates its own packet queue.
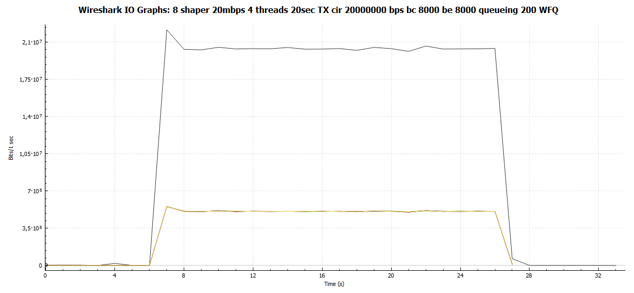
From the general graph, we immediately see that the graphs of all four TCP sessions are identical. Those. they all got the same bandwidth.
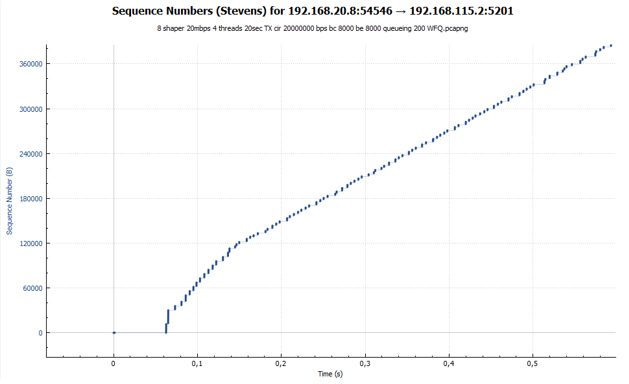
And here is our graph of the distribution of packets by transmission time on exactly the same scale as in Fig. 11. There are no pauses.
It is worth noting that a queue of the WFQ type will allow us to obtain not only a more even distribution of throughput, but also prevent the "clogging" of one type of traffic by another. We talked about TCP all the time, but UDP traffic is also present on the network. UDP has no mechanisms for adjusting the transmission rate (flow control, congestion control). Because of this, UDP traffic can easily clog our shared FIFO queue in the shaper, which will dramatically affect TCP transmission. Let me remind you that when the FIFO queue is completely filled with packets, the tail-drop mechanism starts working by default, in which all newly arrived packets are discarded. If we have configured the WFQ queue, each session waits for the moment of buffering in its queue, which means that TCP sessions will be separated from UDP sessions.
policy-map Shaper
class shaper_class
shape average 20000000
queue-limit 200 packets
fair-queueFrom the general graph, we immediately see that the graphs of all four TCP sessions are identical. Those. they all got the same bandwidth.
And here is our graph of the distribution of packets by transmission time on exactly the same scale as in Fig. 11. There are no pauses.
It is worth noting that a queue of the WFQ type will allow us to obtain not only a more even distribution of throughput, but also prevent the "clogging" of one type of traffic by another. We talked about TCP all the time, but UDP traffic is also present on the network. UDP has no mechanisms for adjusting the transmission rate (flow control, congestion control). Because of this, UDP traffic can easily clog our shared FIFO queue in the shaper, which will dramatically affect TCP transmission. Let me remind you that when the FIFO queue is completely filled with packets, the tail-drop mechanism starts working by default, in which all newly arrived packets are discarded. If we have configured the WFQ queue, each session waits for the moment of buffering in its queue, which means that TCP sessions will be separated from UDP sessions.
The most important conclusion that can be made after analyzing packet transfer schedules when working with shaper is that we have no lost packets. Due to the increase in RTT, the session speed adapts to the shaper's speed.
Does queue depth affect our session?
Of course! Initially (if someone else remembers this), we changed the queue depth from 83 (the default value) to 200 packets. We did this so that the queue is enough to get a sufficient RTT value, at which the total speed of the sessions becomes approximately equal to 20 Mbps. So, the packages do not "fall out" of the shaper's queue.
At a depth of 83 packets, the queue overflows faster than the desired RTT value is reached. Packets are discarded. This is especially pronounced at the initial stage when the TCP slow-start mechanism works for us (the session accelerates as aggressively as possible). It is worth noting that the number of dropped packets is incomparably smaller than in the case of policer, since an increase in RTT leads to the fact that the session speed grows more smoothly. As we recall, in the CTCP algorithm, the window size also depends on the RTT value.
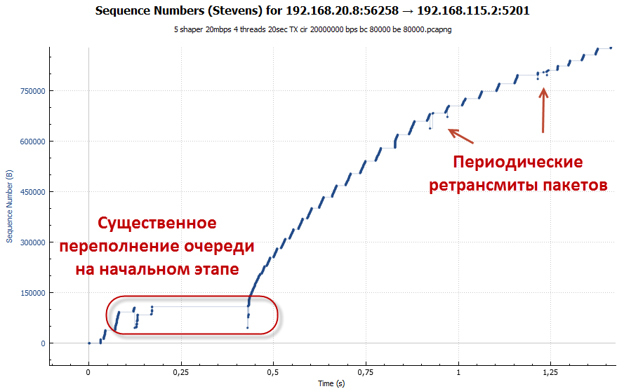
At a depth of 83 packets, the queue overflows faster than the desired RTT value is reached. Packets are discarded. This is especially pronounced at the initial stage when the TCP slow-start mechanism works for us (the session accelerates as aggressively as possible). It is worth noting that the number of dropped packets is incomparably smaller than in the case of policer, since an increase in RTT leads to the fact that the session speed grows more smoothly. As we recall, in the CTCP algorithm, the window size also depends on the RTT value.
Schedules of bandwidth utilization and delays during policer and shaper operation
In conclusion of our little research, we will build some more general graphs, after which we will proceed to the analysis of the received data.
Bandwidth utilization schedule:
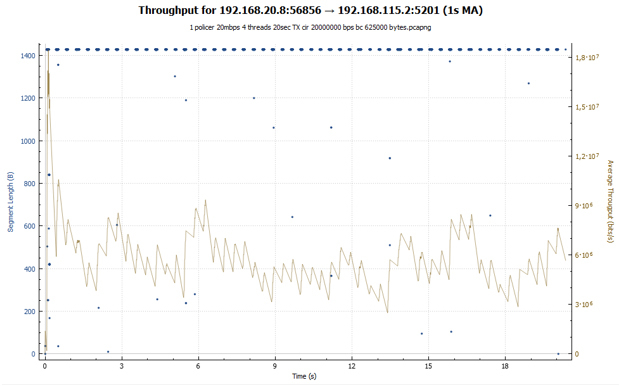
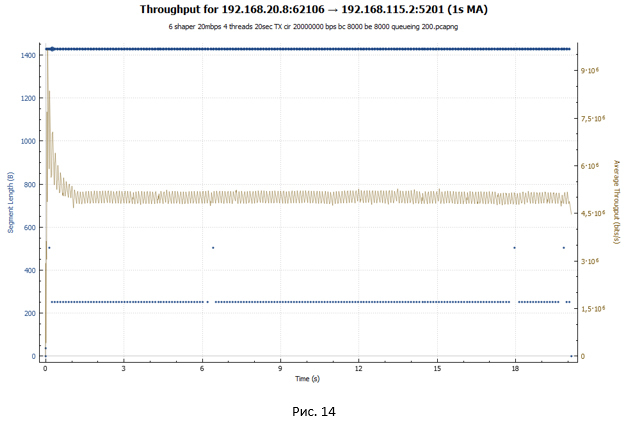
In the case of policer, we see an abrupt graph: the session accelerates, then losses occur, and its speed drops. Then everything repeats again. In the case of shaper, our session receives approximately the same throughput throughout the transmission. Session speed is adjusted by increasing the RTT value. In both charts, explosive growth can be observed at first. It is due to the fact that our buckets are initially completely filled with tokens and the TCP session, which is not restrained by anything, accelerates to relatively large values (in the case of shaper this value is 2 times less).
RTT delay graph for policer and shaper (in a good way, this is the first thing we remember when we talk about shaper):
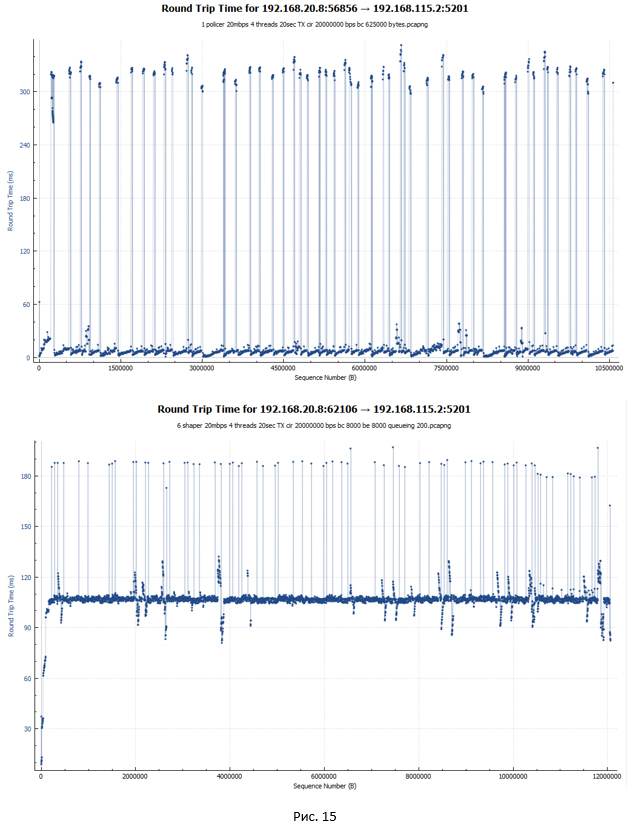
In the case of policer (first graph), the RTT delay for most packets is minimal, on the order of 5 ms. Significant leaps (up to 340 ms) are also present on the chart. These are just the moments when packets were discarded and transmitted again. It is worth noting how Wireshark considers RTT for TCP traffic. RTT is the time between sending the original packet and receiving an ACK on it. In this regard, if the original packet was lost and the system retransmitted the packet, the RTT value increases, since the starting point is in any case the moment the original packet was sent.
In the case of shaper, the RTT delay for most packets was 107 ms, since they are all delayed in the queue. There are peaks up to 190 ms.
conclusions
So, what are the final conclusions that can be made. Someone may notice that this is understandable. But our goal was to dig a little deeper. Let me remind you that the experiment analyzed the behavior of TCP sessions.
- Shaper provides us with 13% more useful bandwidth than a policer (19.3 versus 17.1 Mbps) with a given limit of 20 Mbps.
- In the case of shaper'a bandwidth is distributed more evenly between sessions. The best performance can be obtained by enabling the WFQ queue. When working policer'a there are significant peaks and drops in speed for each session.
- When shaper is working, there are practically no packet losses (of course, this depends on the situation and queue depth). During the work of the policer, we have significant packet loss - 12.7%.
If the policer is configured closer to the recipient, our network is actually engaged in pumping useless traffic, which will eventually be discarded by the policer. For example, in the context of the global Internet, this can be a problem, since traffic is often cut closer to the recipient. - In the case of shaper, we get a delay (in our experiment, this is an additional 102 ms). If the traffic is approximately the same, without significant spikes, the shaper's queue is in a relatively stable state and there will be no large variations in the delay (jitter). If the traffic is explosive, we can get an increased jitter value.
In general, the presence of a queue can adversely affect the operation of applications - the so-called effect of excessive network buffering ( Bufferbloat ). Therefore, with the depth of the queue, one must be careful. - Thanks to different types of queues, shaper allows us to consider prioritizing traffic while limiting speed. And if there is a need to drop packets, first of all do it for less priority ones. In policer it is more difficult to achieve this, but for some schemes it is impossible.
- Policer and shaper are prone to situations where UDP traffic can clog TCP. When configuring these technologies, this fact must be taken into account.
- The work of the shaper creates a greater load on the network device than the work of the policer. At least memory is required in turn.
One more fact can be noted, although not directly related to the problem of speed limitation. Shaper allows us to configure various types of queues (FIFO, WFQ, etc.), thereby providing various levels of prioritization of traffic when it is sent through the device. This is very convenient in cases where the actual traffic transmission rate differs from the channel (for example, this is often the case with Internet access or WAN channels).
Study of the impact of policer on the Internet
This year, with the support of Google, a study was conducted in which the negative effect of the policer’s work on the Internet was analyzed. It was determined that from 2% to 7% of video traffic losses around the world are caused by the operation of the policer. Packet losses during the direct operation of the policer amounted to about 21%, which is 6 times more than for traffic that is not subject to the operation of this technology. The quality of video traffic that has been processed by the policer is worse than if the policer did not work.
To combat the negative effect of policer’s work, the following measures are proposed depending on the point of their application.
For Internet Service Providers:
There are no clear recommendations for shaper configuration in the document. Shaper can provide a positive effect for both large and small bucket sizes (even if BC = 8,000 bytes). There is also no definite recommendation regarding the depth of the queue. A shallow depth leads to unnecessary losses, a large one can adversely affect network delays. In all cases, there are pros and cons.
For content providers, it is proposed to limit the speed of sending traffic to the server in order to avoid the inclusion of a policer. But in practice, estimating the real channel speed is not always easy. The second method is to avoid explosive traffic transmission by modifying TCP algorithms: use TCP Pacing (send packets with binding to RTT, and not by the time the ACK is received) and change the scheme of the loss recovery phase (send only one new packet for each received ACK).
To combat the negative effect of policer’s work, the following measures are proposed depending on the point of their application.
For Internet Service Providers:
- In policer, reduce the size of the bucket (burst size). This will lead to the fact that the TCP session will not be able to accelerate too much while there are free tokens, and will quickly begin adapting to the real bandwidth.
- Instead of a policer, use a shaper (with a small queue depth).
- Use both shaper and policer at the same time. In this case, the shaper is located a little earlier than the policer. Shaper delays packets, smoothing out vibrations. Due to this delay, policer manages to accumulate enough tokens to transmit traffic. Losses are then minimized.
There are no clear recommendations for shaper configuration in the document. Shaper can provide a positive effect for both large and small bucket sizes (even if BC = 8,000 bytes). There is also no definite recommendation regarding the depth of the queue. A shallow depth leads to unnecessary losses, a large one can adversely affect network delays. In all cases, there are pros and cons.
For content providers, it is proposed to limit the speed of sending traffic to the server in order to avoid the inclusion of a policer. But in practice, estimating the real channel speed is not always easy. The second method is to avoid explosive traffic transmission by modifying TCP algorithms: use TCP Pacing (send packets with binding to RTT, and not by the time the ACK is received) and change the scheme of the loss recovery phase (send only one new packet for each received ACK).
Thus, there is no single answer to the question of which is better to use: shaper or policer. Each technology has its pros and cons. For some, the additional delay and load on the equipment is not as critical as for another. So the choice is made towards shaper. It is important for someone to minimize network buffering to combat jitter - that means our policer technology. In some cases, both of these technologies can be used simultaneously. Therefore, the choice of technology depends on each specific situation on the network.