DataGrip 2018.3: Cassandra support, generating SQL files from objects, many improvements in auto-completion, and much more.
Hello! This is a story about what's new in our database plugin. We release it as a separate DataGrip product , and deliver to almost all of our other IDEs. There will be a lot of pictures and gifs. For those who are too lazy to watch them:
Thanks to those who try the EAP version and report problems to our tracker: it helps not to drag them to the release :) Active users have already received free subscriptions for a year.

Slowly mastering NoSQL database. So far, only those that use SQL-like languages for queries. We supported Clickhouse in 2018.2.2 , and added Cassandra in this release.
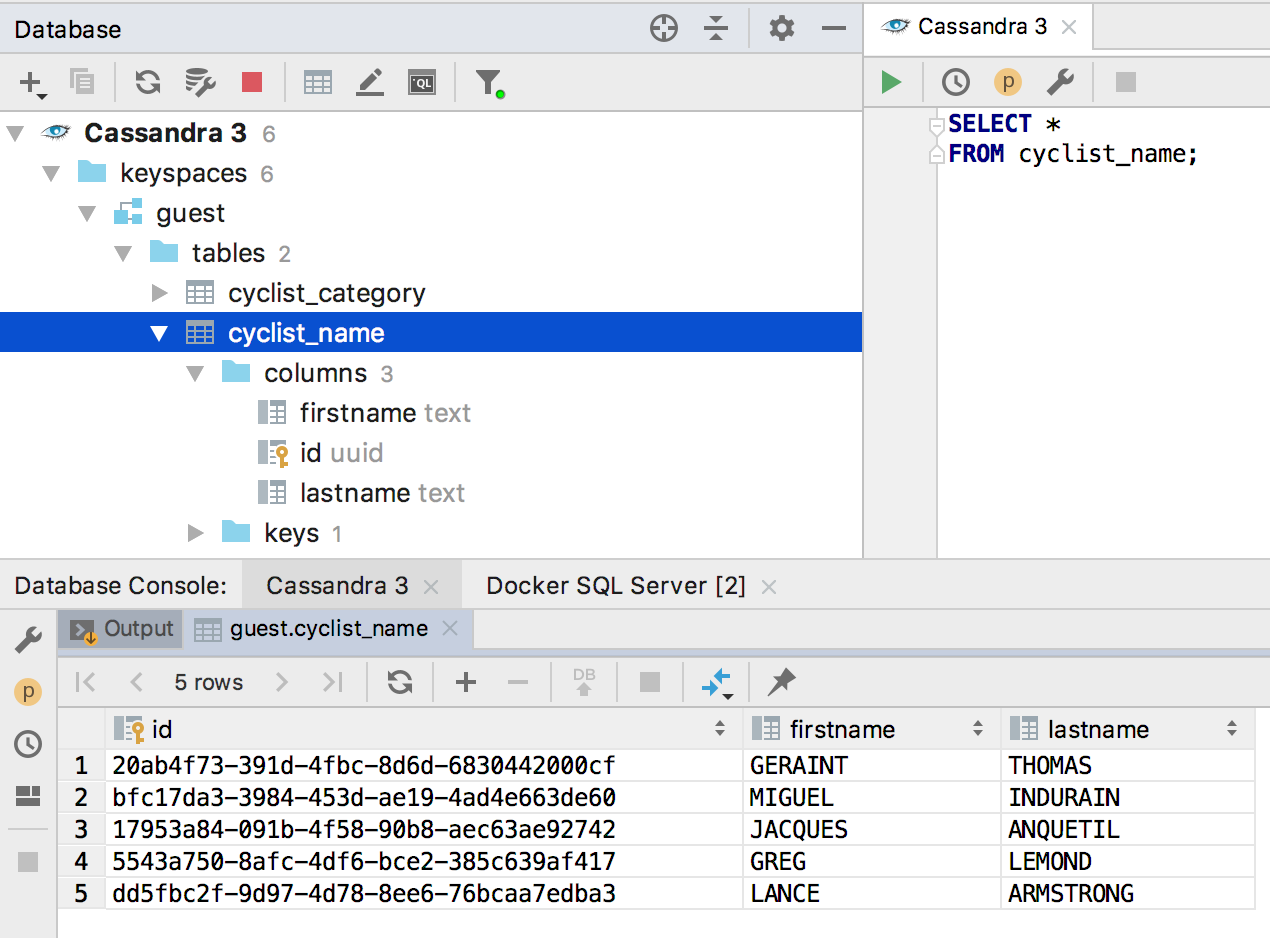
There are a lot of new things in this subsystem.
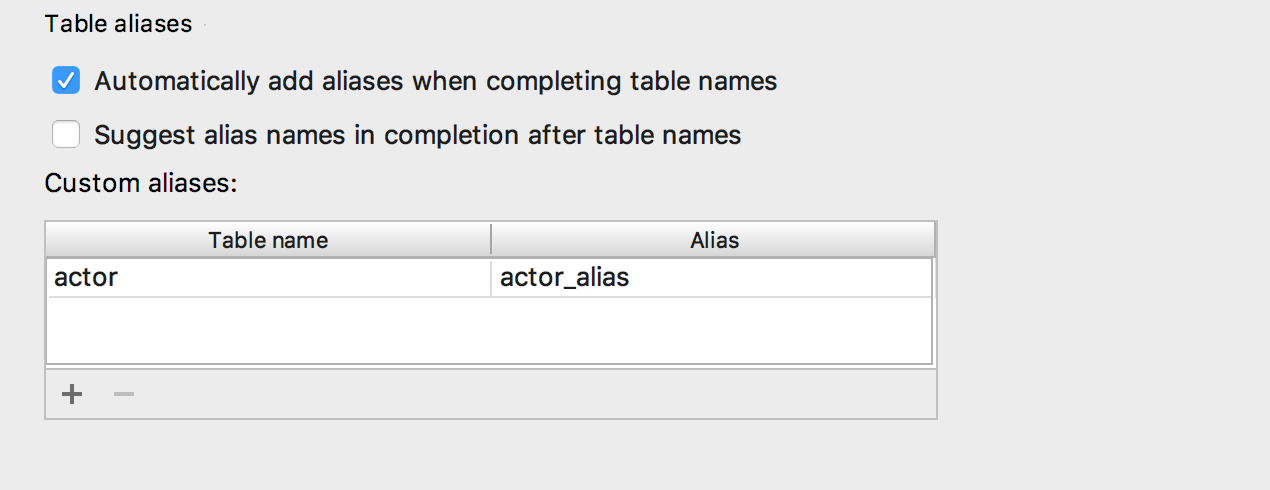
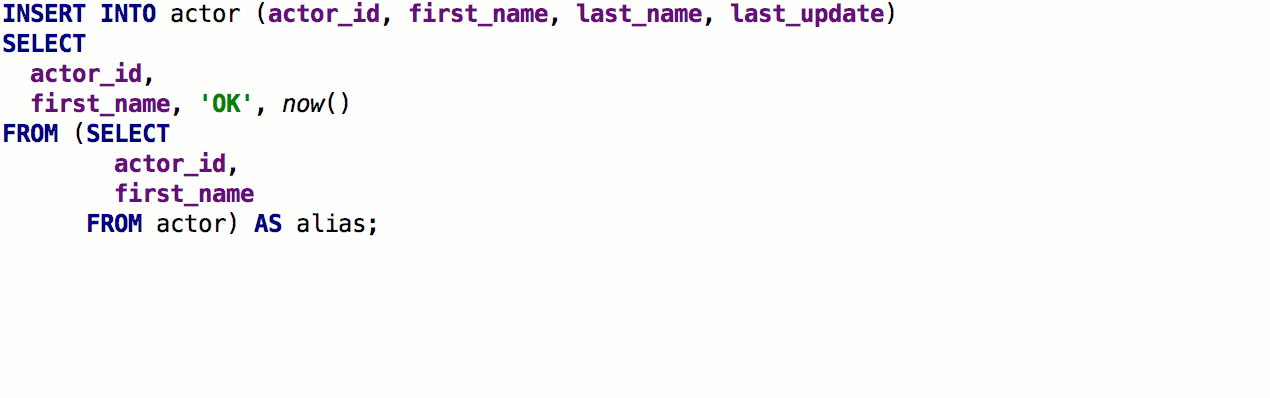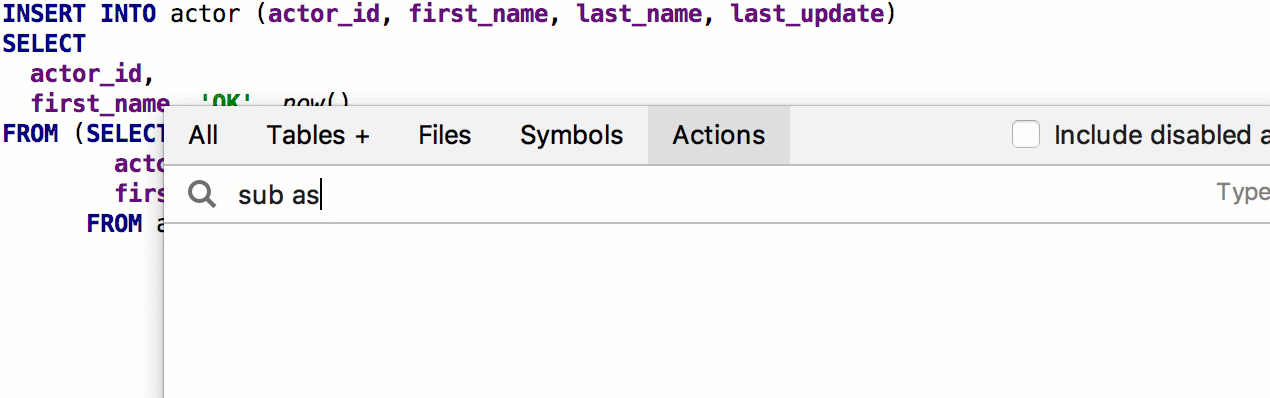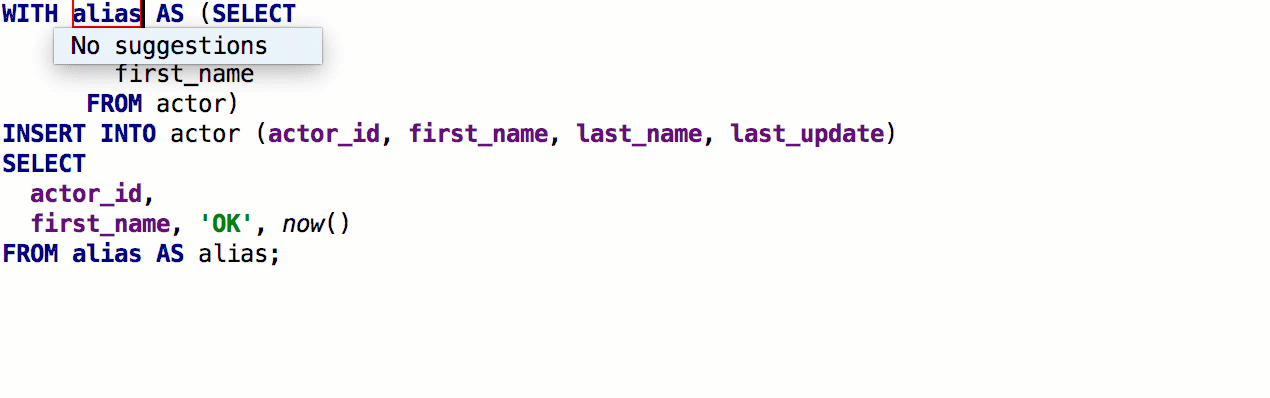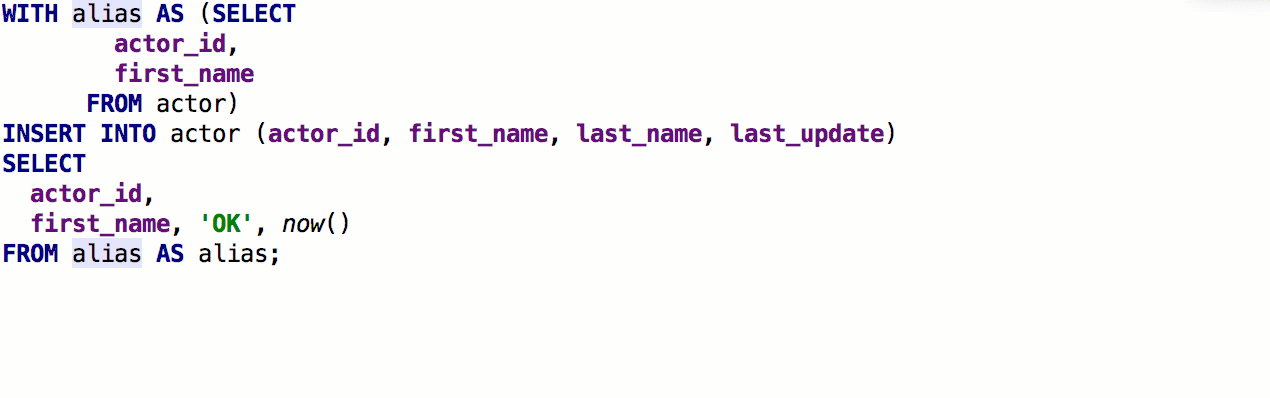
Added the ability to insert pseudonyms automatically after table names. If the nickname proposed by us does not suit you, indicate which nicknames to use for specific names.
As a result, it works like this:
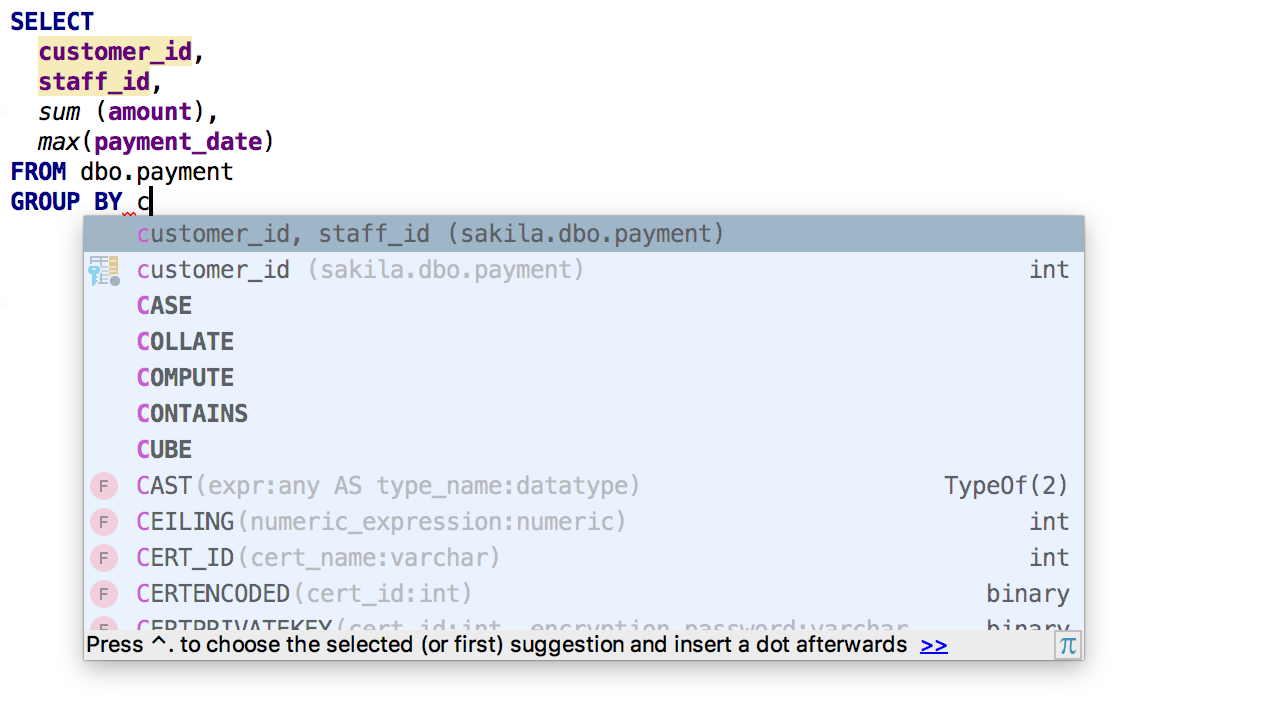
When using GROUP BY, DataGrip will suggest a list of non-aggregated columns .
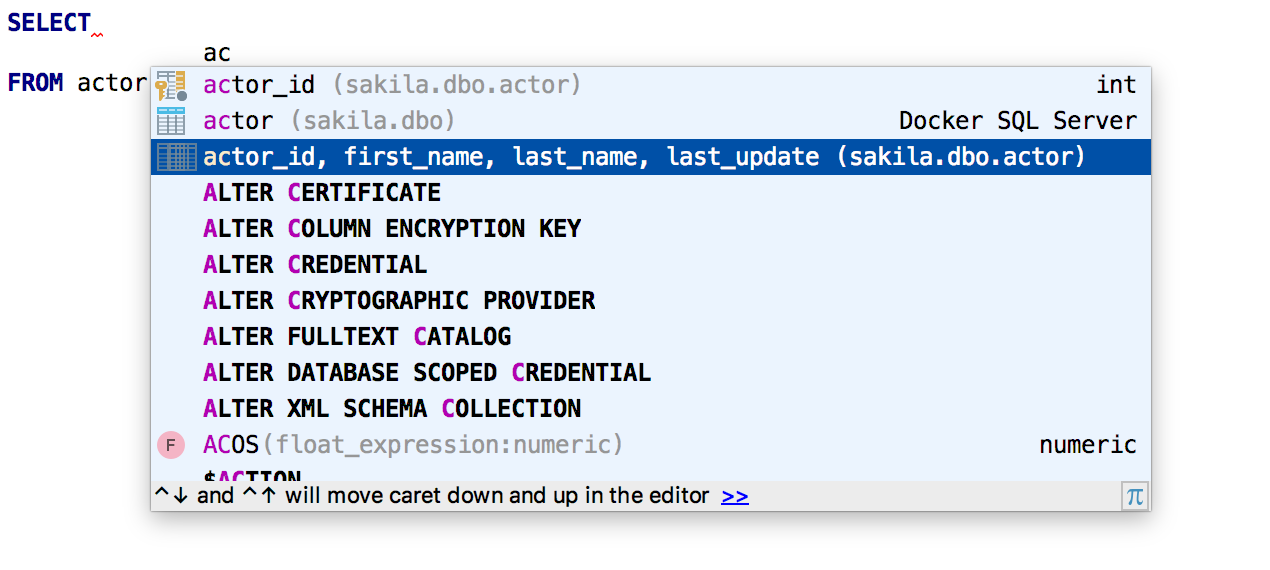
The SELECT clause offers a list of all columns .
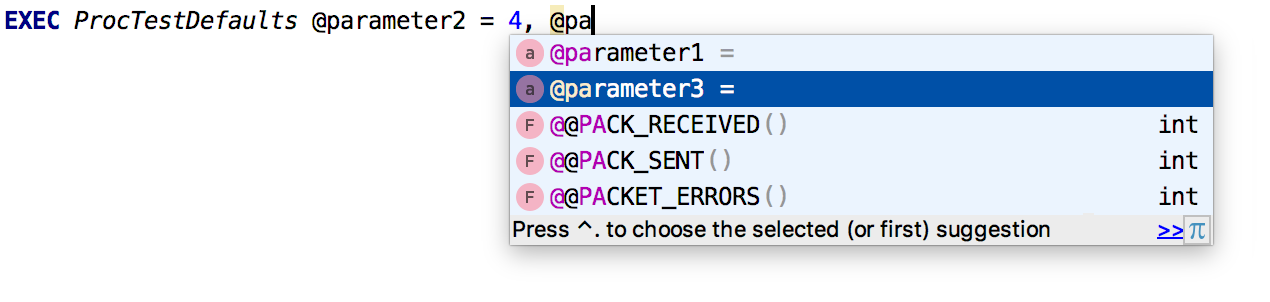
Autocompletion works for named parameters .
Also added contextual information for identical names.
Finally done postfix completion: this is when something is written through the dot relating to an object.

For example, if after SELECT you write the name of the Table.afrom, it will open into the list of columns and the FROM clause . Or, in our opinion the most convenient, you can add .cast to the column or variable.
It

’s better to see once: Auto-completion has become better for window functions : OVER () is automatically added and the carriage is put in the right place.

An important thing that it was time to do was to use a pseudonym instead of a table. Click on the table Alt + Enter → Introduce alias. The uses of the table will be replaced by pseudonyms.

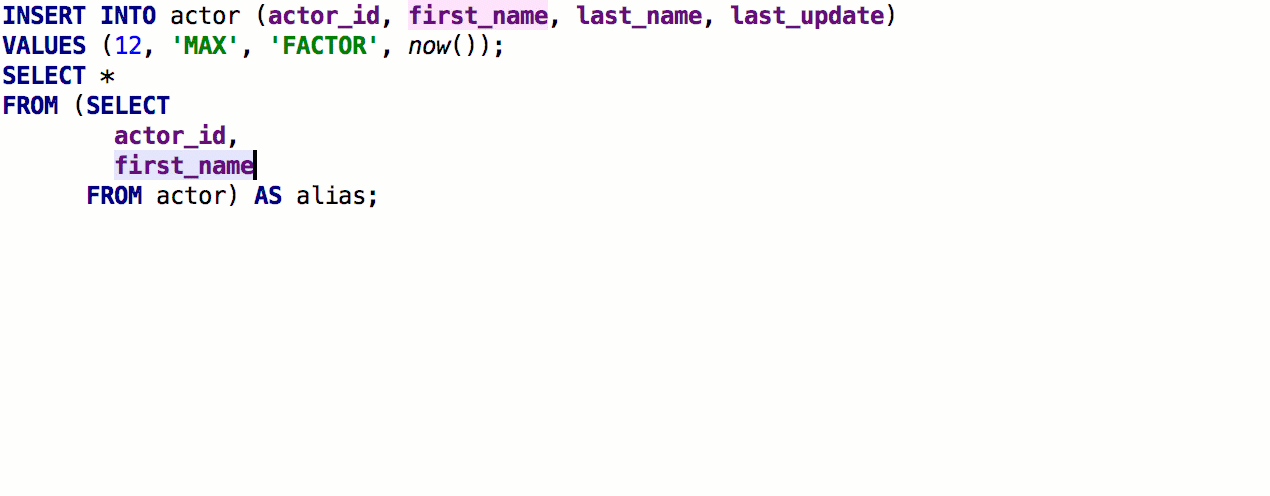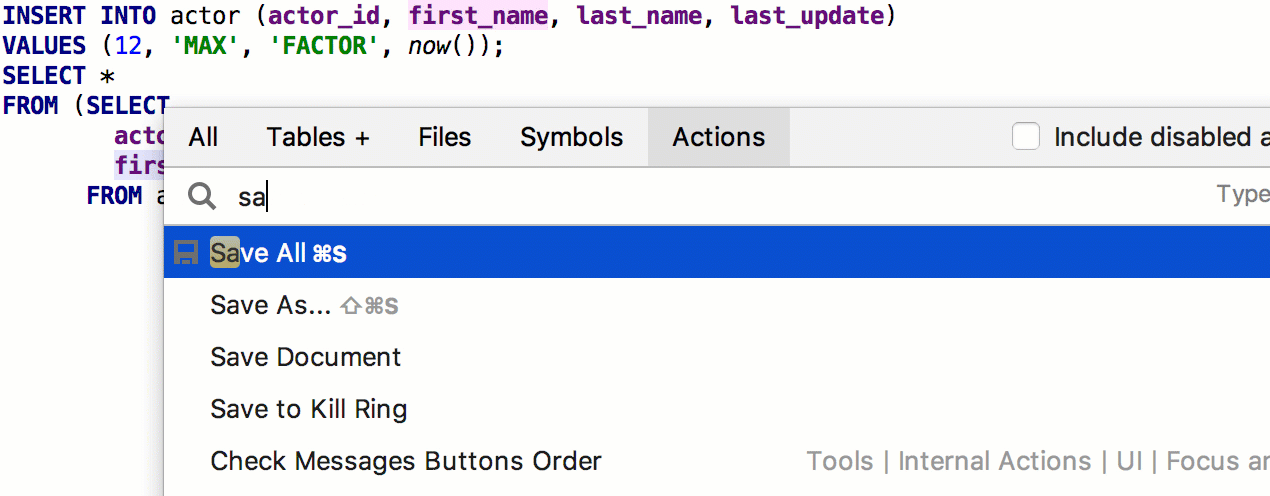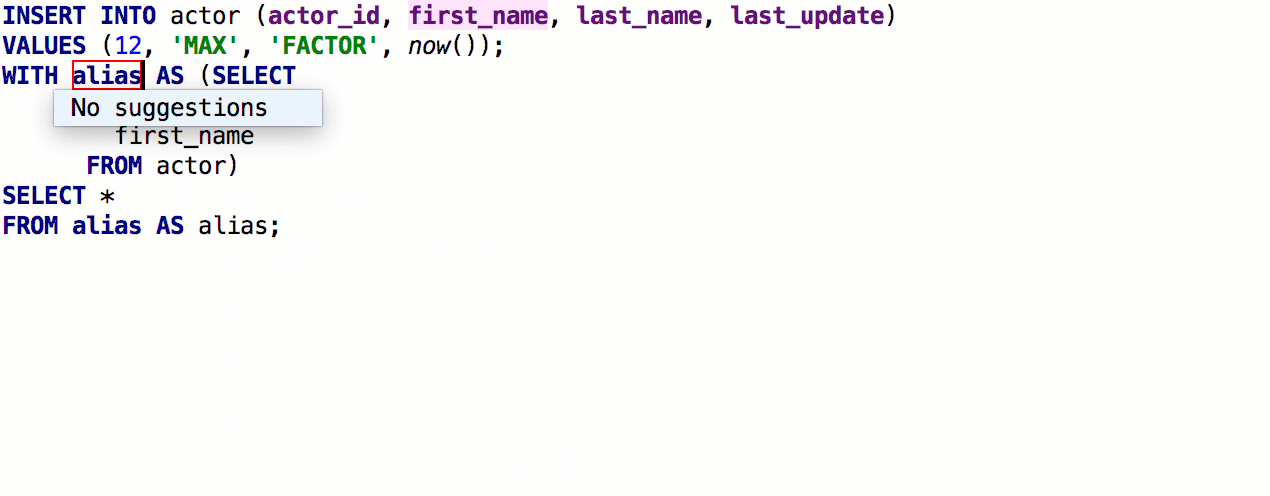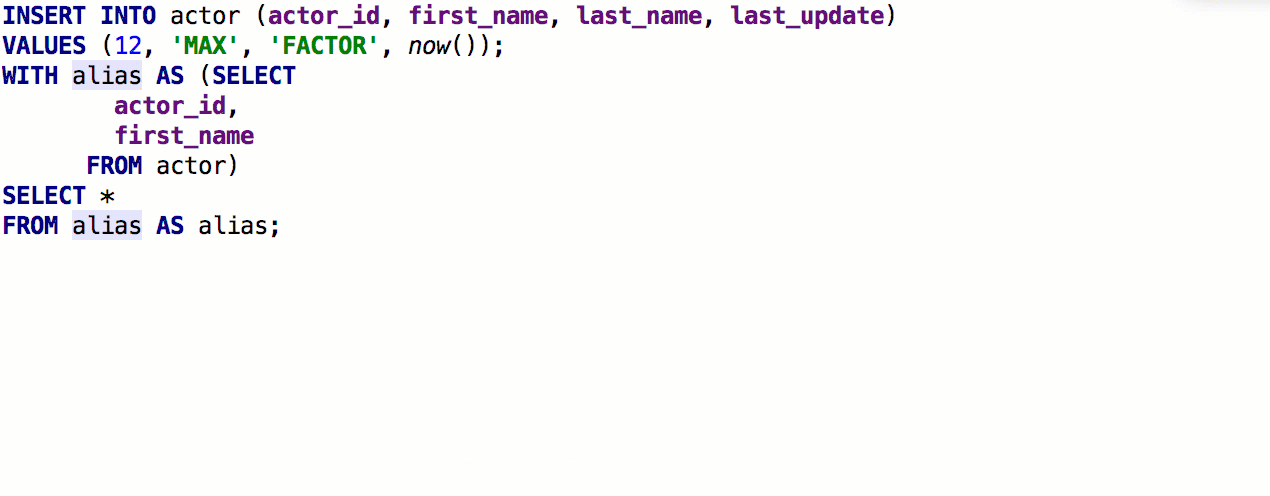
After the previous release, we received detailed feedback from speshuric . For example, he found a lot of unobvious scripts for Extract subquery as a CTE. This refactoring is called via the menu Refactor → Extract → Subquery as CTE , but we advise you to get used to Find Action (Ctrl + Shift + A).
What we did:
- The new name for the CTE does not conflict with the existing ones: DBE-6496
- Correctly determine the context if the request is wrapped in another expression: DBE-6503, DBE-6517
- We do not offer refactoring in the case of AS TableName : DBE-6490
- Supported for MySQL 8.
- Works as it should with deep subqueries. DBE-7332 , DBE-7333
Code templates can be tied to dialects - a template can work for some bases, and not work for others.
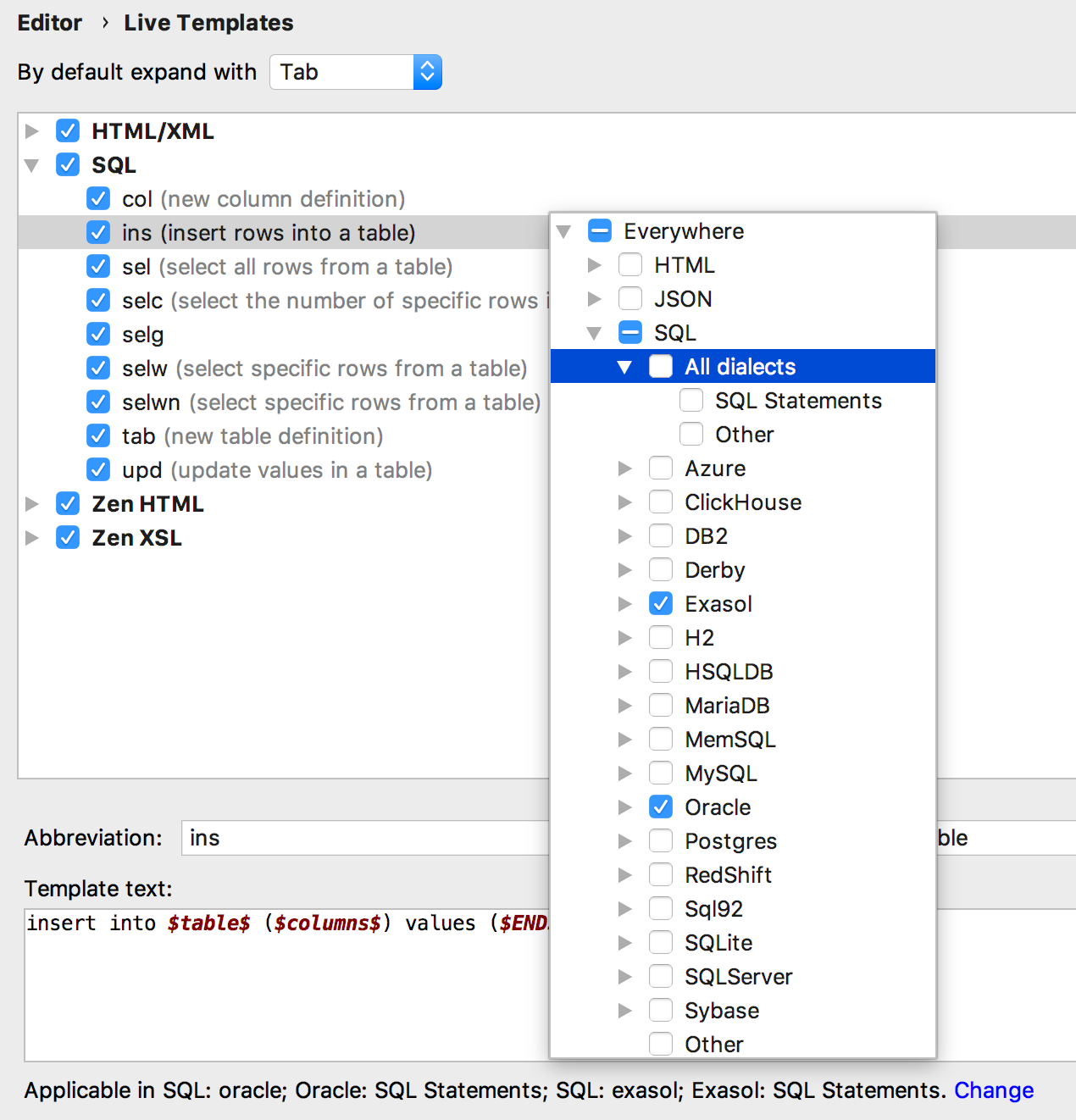
What is more important: the same template can generate different code for different databases. To do this, create template groups for each dialect, because the same template names are not supported within the same group (by default, we store templates in the SQL group).
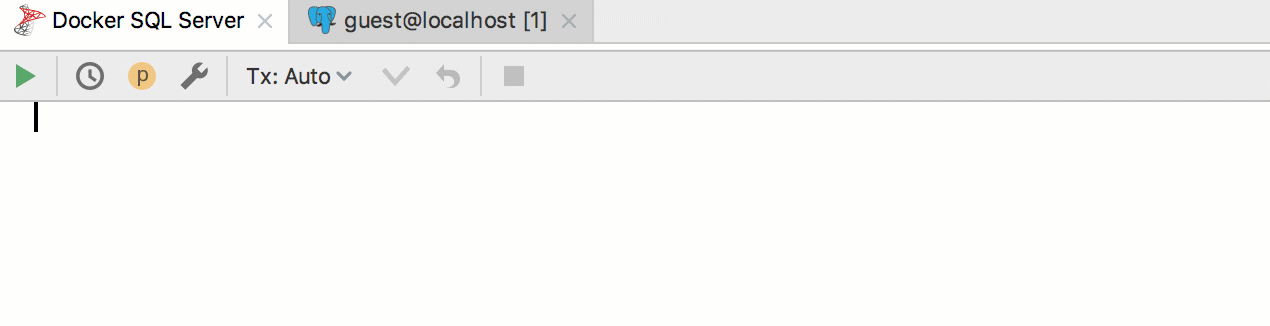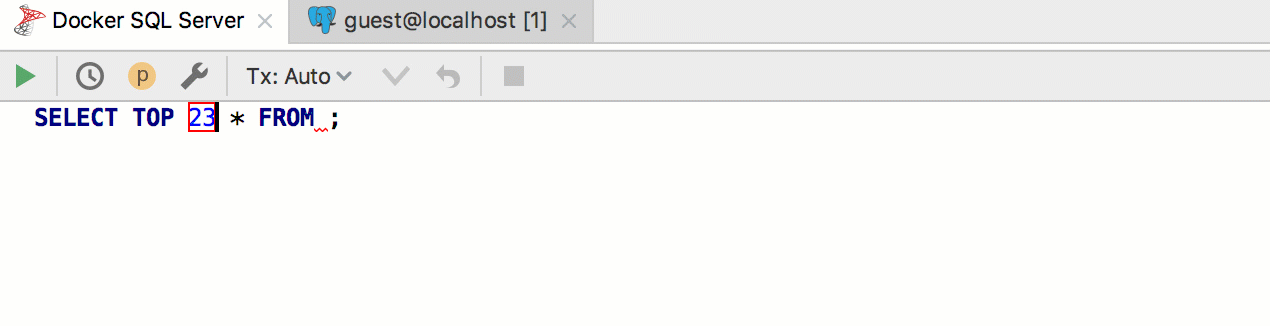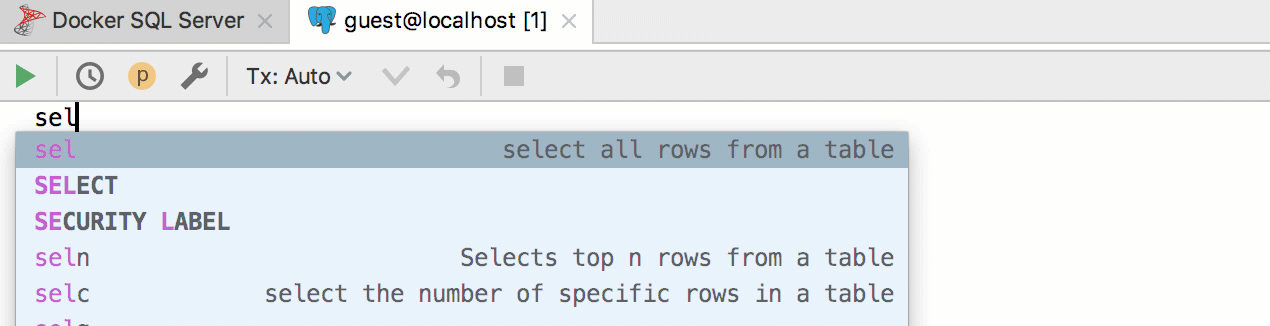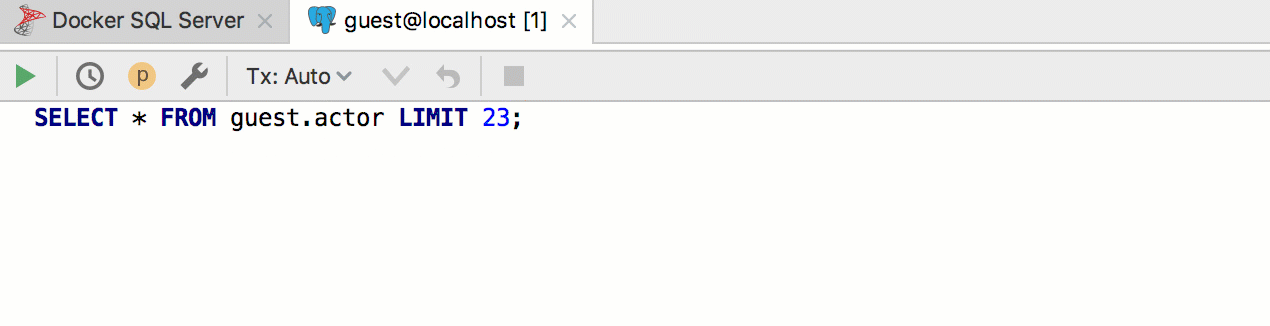
For example, we want to create a template for pulling out the first n rows from the table. PostgreSQL and SQL Server use a different syntax for this, and we will always use a template

It turns out like this:
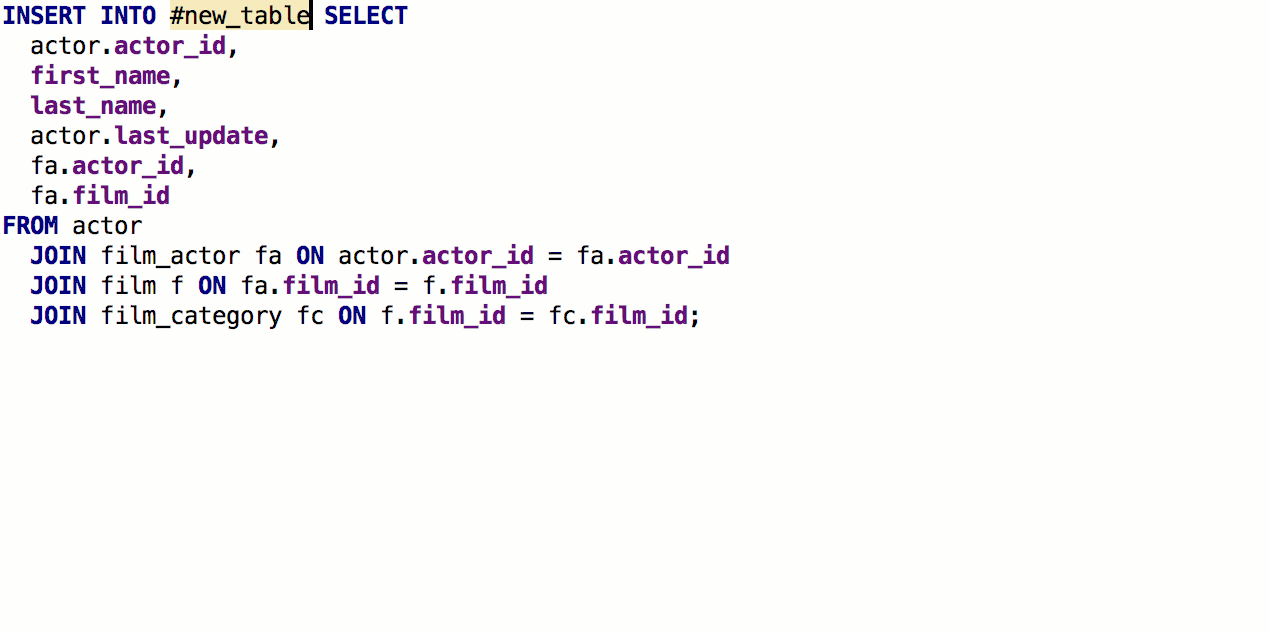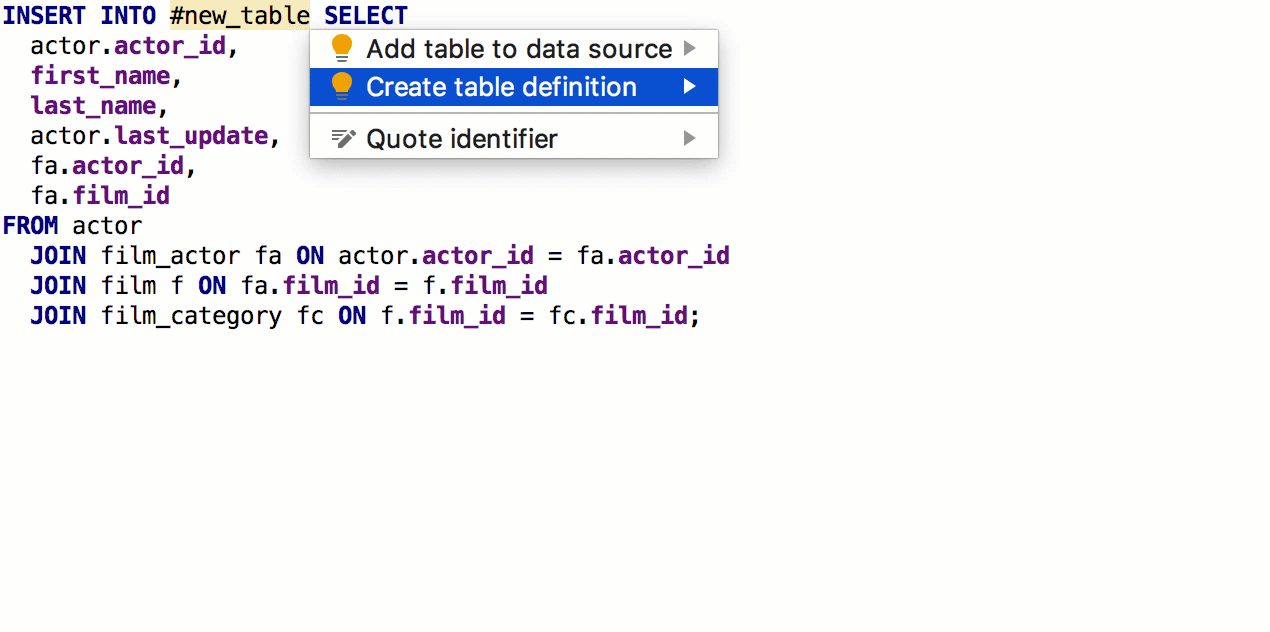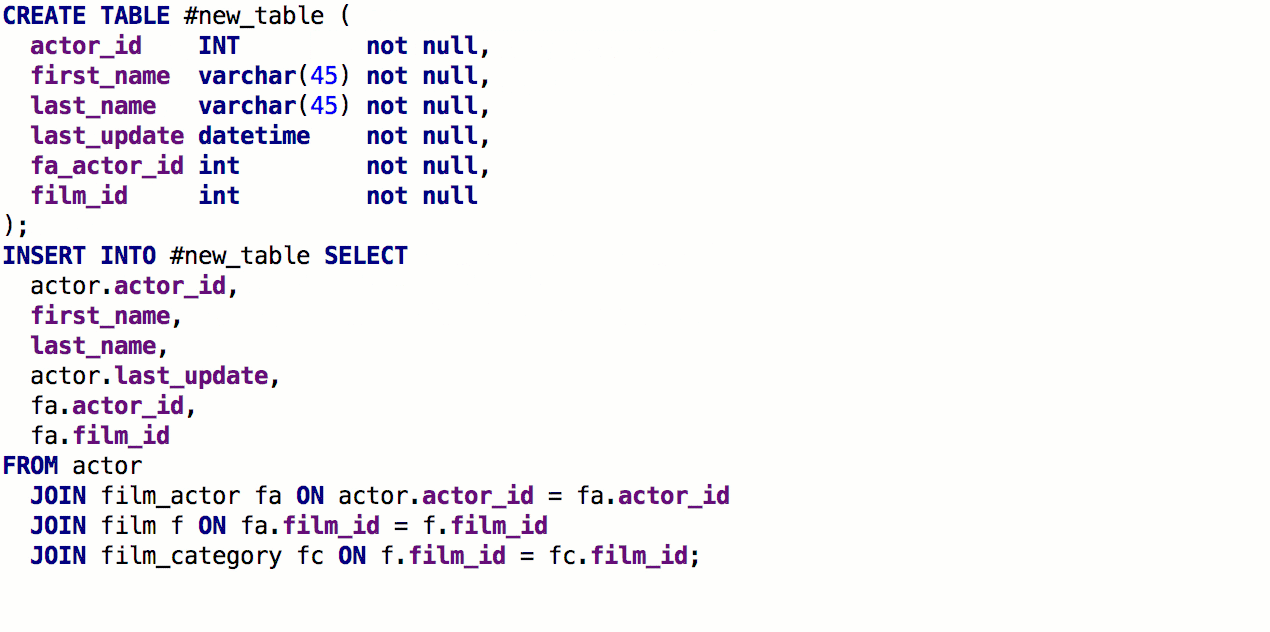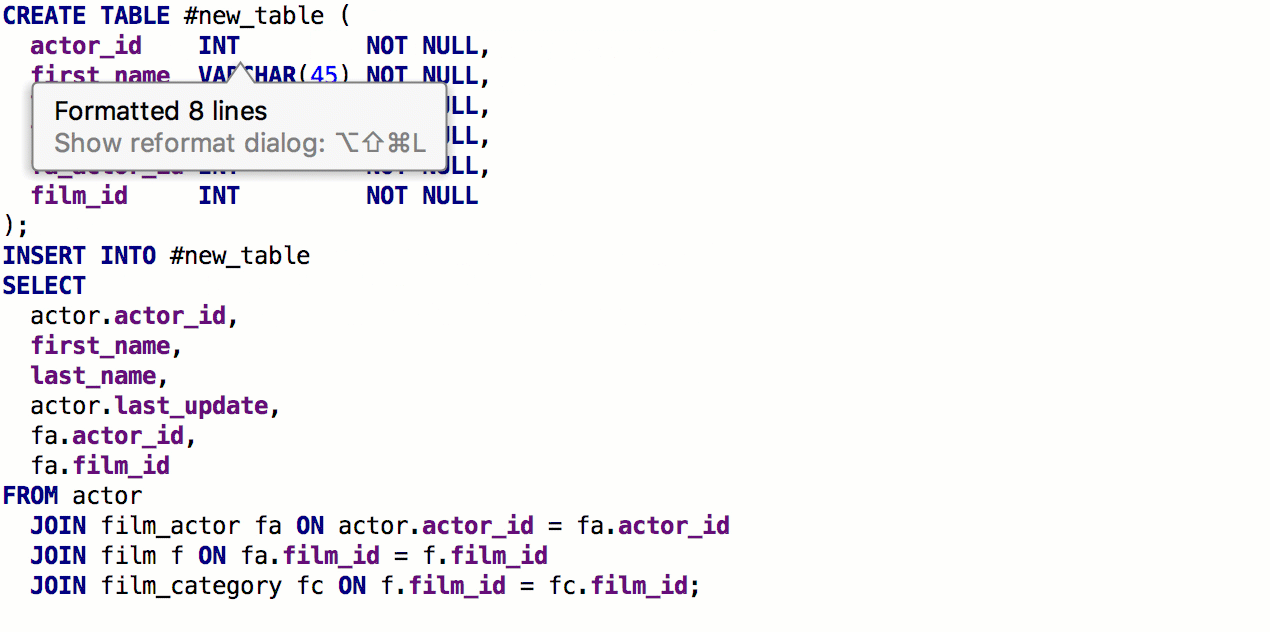
From the SELECT clause you can now generate the creation of a tablewith the same signature. To do this, press Alt + Enter → Create table definition
And a small fix for the INS template - hints for column names are displayed automatically.

Added inspections about unsafe DELETE and UPDATE - we warn you that you will lose data.


And if you run, we will specify :)

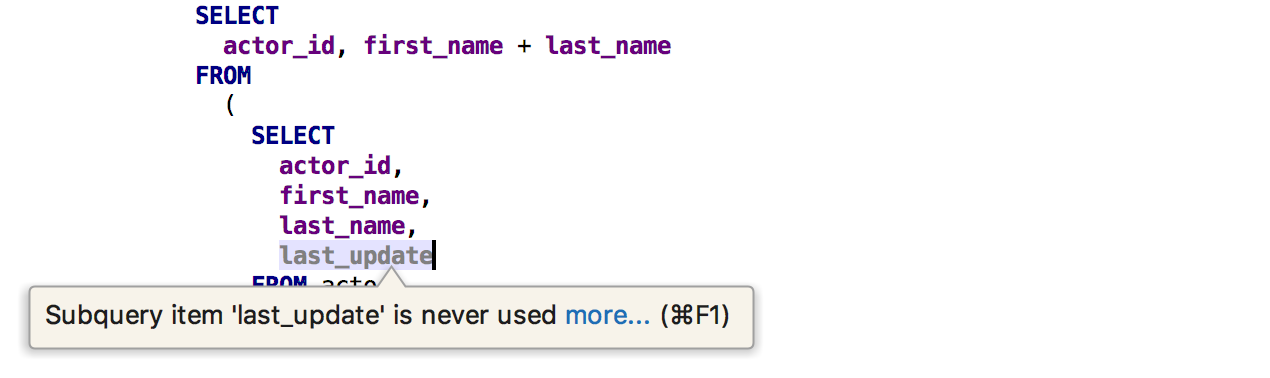
Another inspection will find unused columns from the subquery .
And the other is unused code.

SQL Generator ( Ctrl / Cmd + Alt + G ) learned to write the results to a file : to do this, click the Save button .
By default, there are two ways to organize files, but if you need any more, write in the comments.
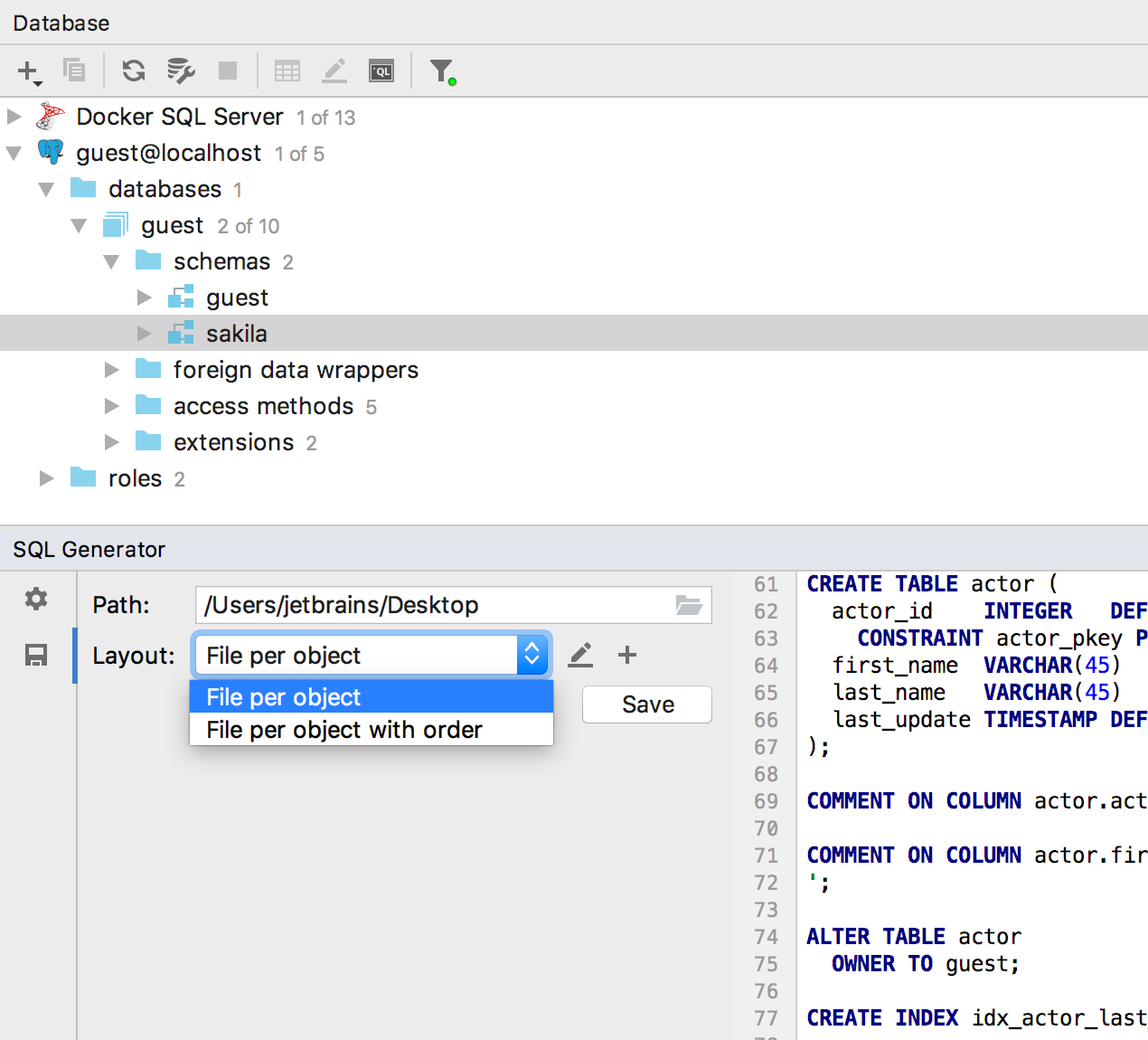
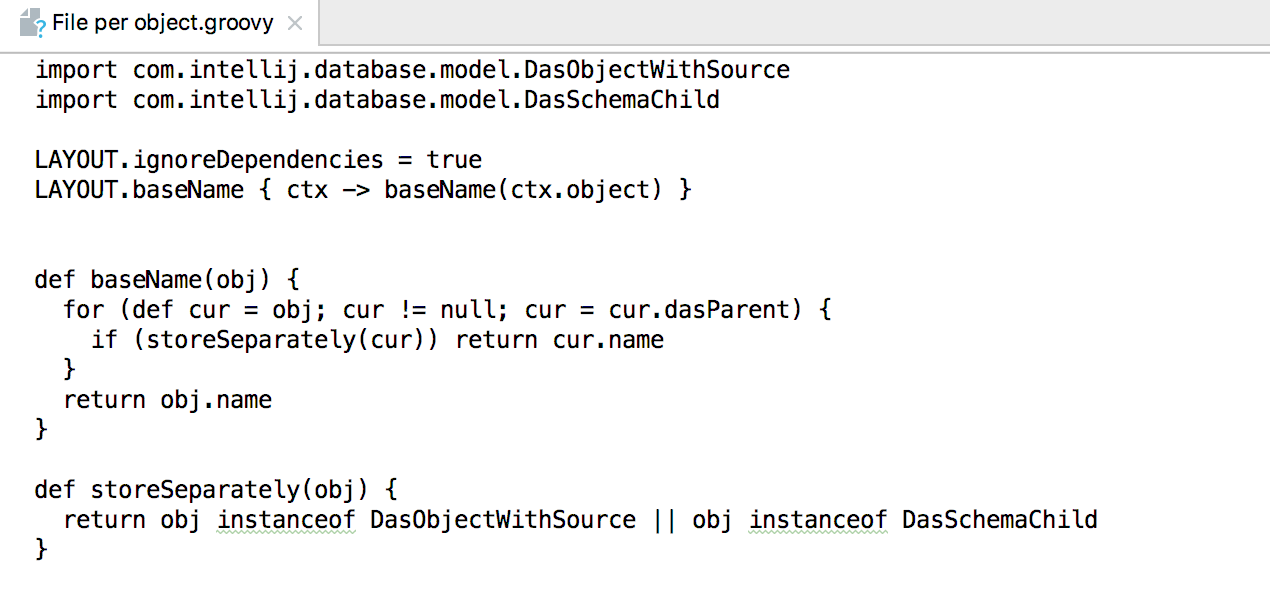
Or now, if you click on the pencil on the right, you can edit the corresponding groovy scripts. Or create your own.
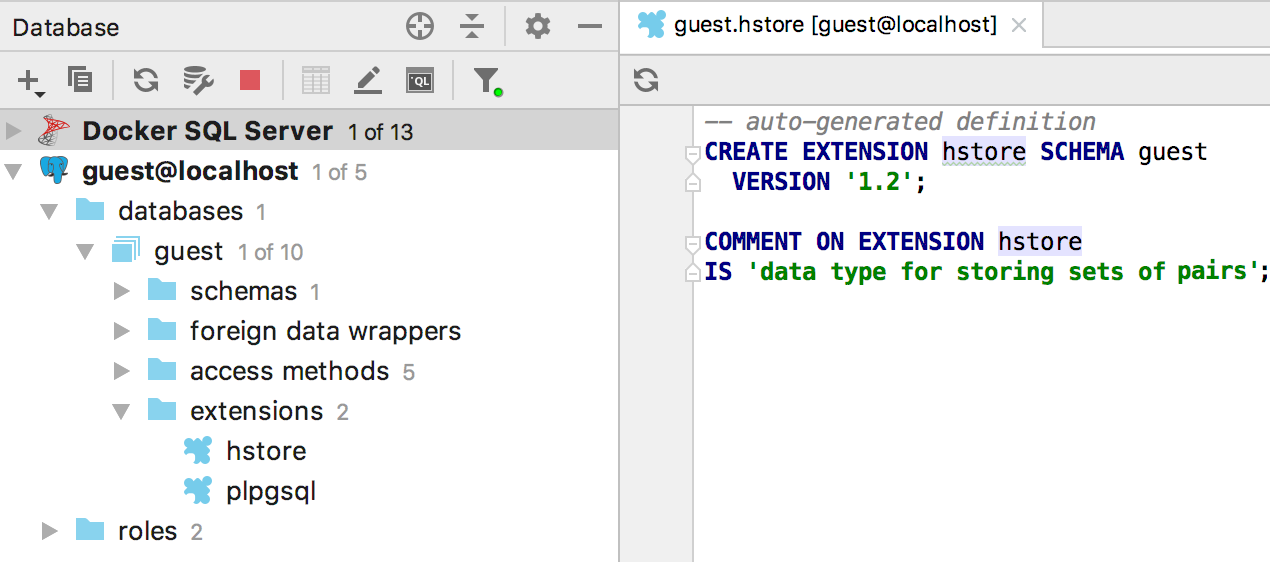
Supported extensions in PostgreSQL.
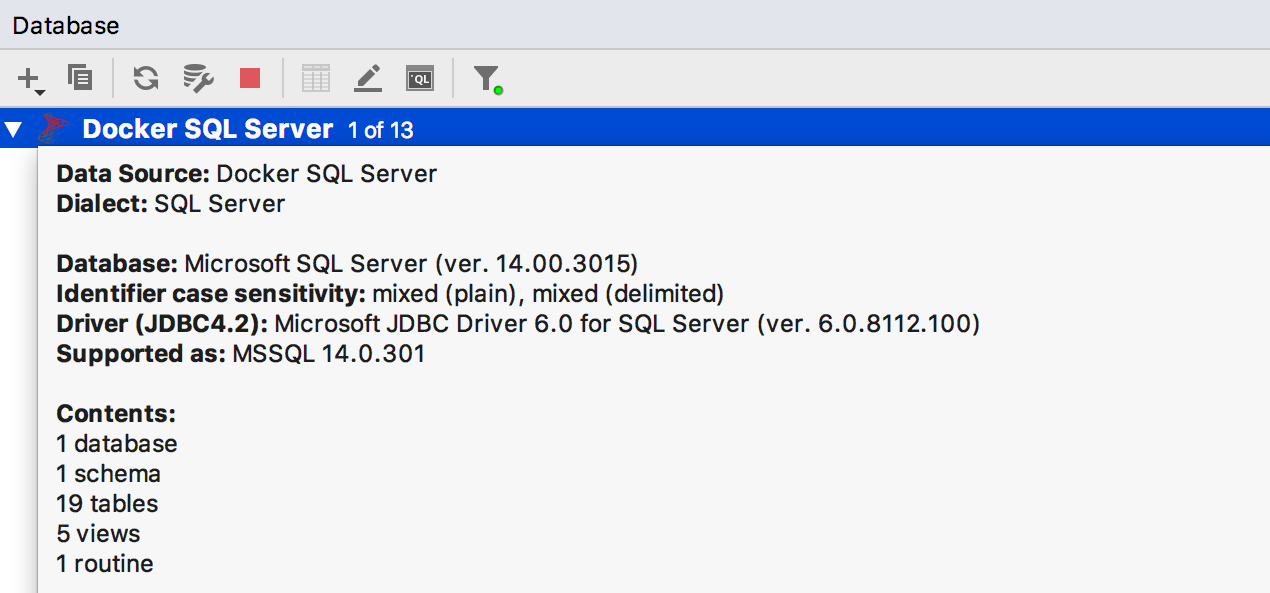
We show statistics in the information window for the data source (Ctrl + Q for Windows / Linux, F1 for OSX), including the number of different objects.
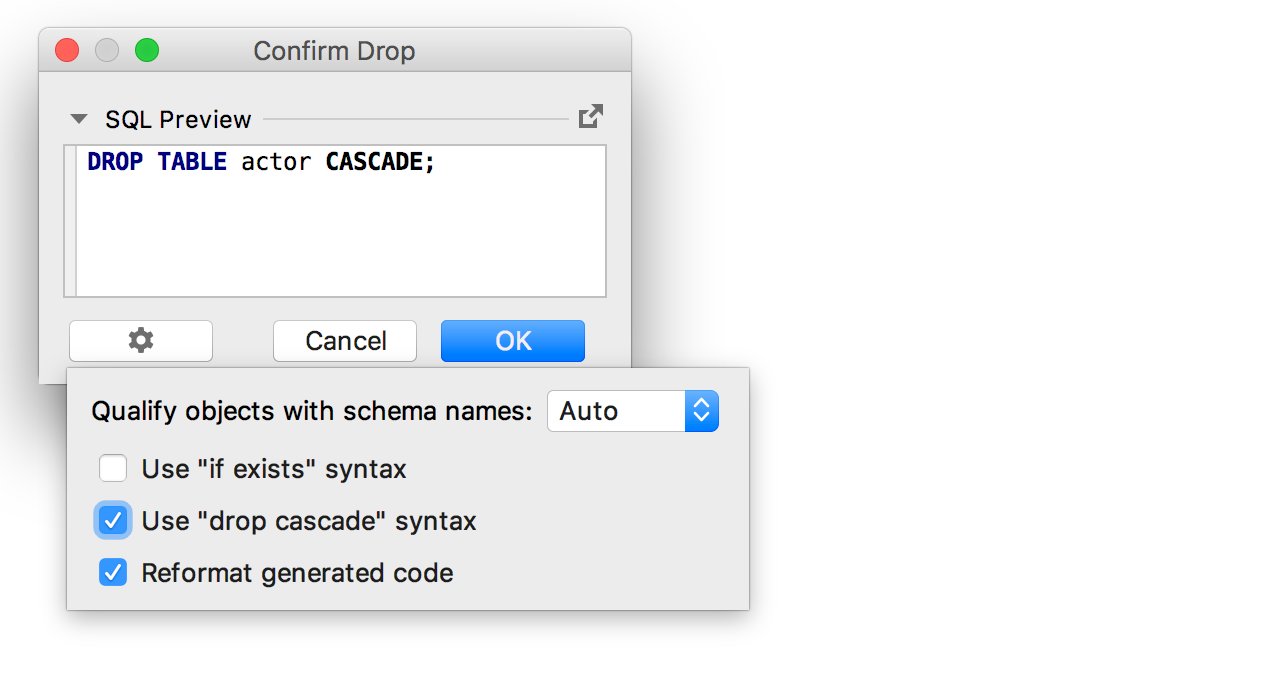
And when generating code to remove an object, the option ' Use drop cascade syntax ' was added ..
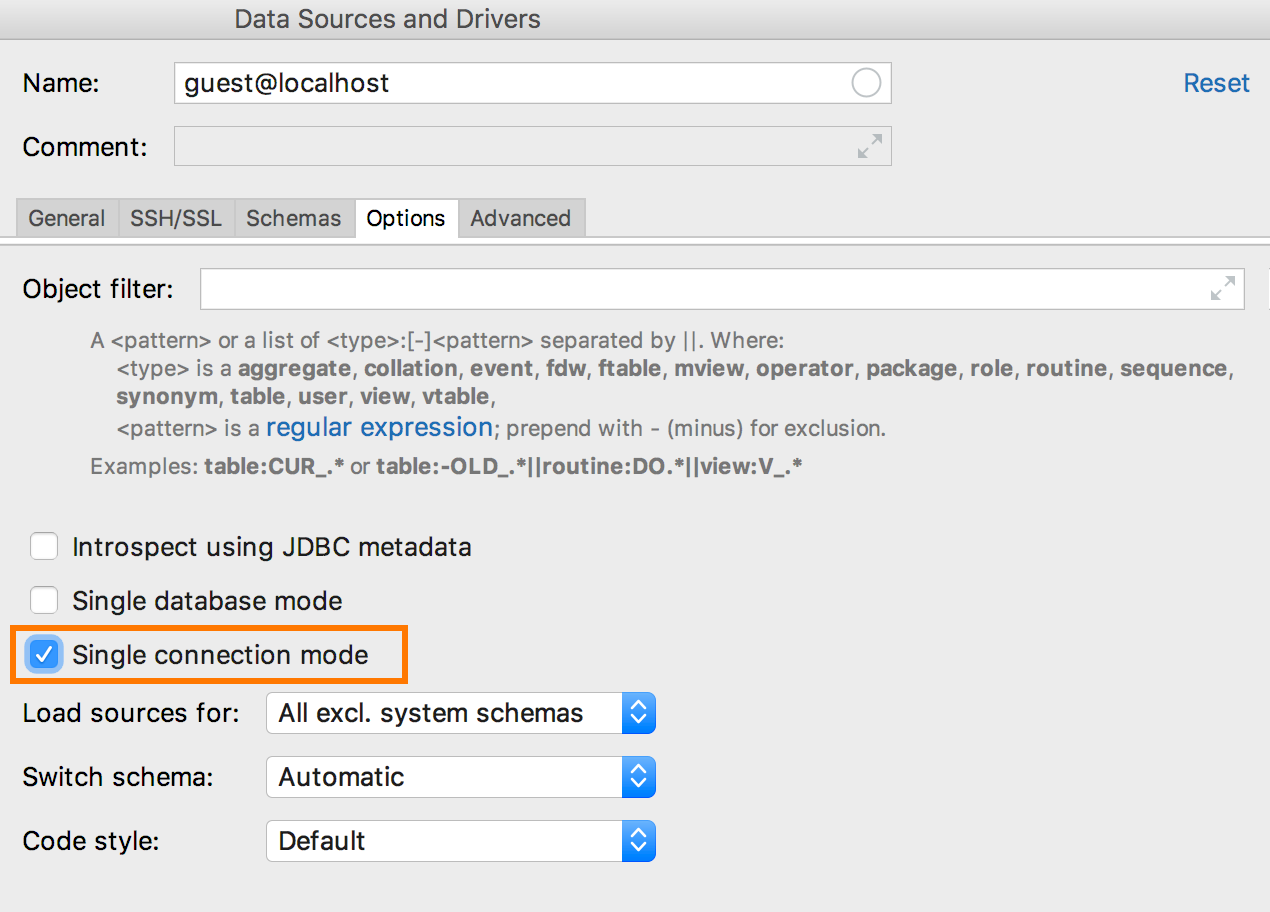
Prior to the current version, each new console meant a new connection. Other things that did not require the console, also created separate connections: running scripts, importing, graphical interface for creating tables. In 2018.3, if you enable Single connection mode in the properties of the data source, all work with it will occur through one connection.
As a result, temporary objects will appear in the tree, and also consoles and data editors will work within a single transaction. This is the first step to complete connection management, which we are going to do.
They also made it so that the IDE itself reconnects after idle time.
The IntelliJ platform introduced a new search : it combined different types of search that were scattered: Search Everywhere , Find Action , Go to table / view / procedure / , Go to File and Go to Symbol . In DataGrip, the second tab is called Tables, and in other IDE Classes. But it does the same thing: it searches for both database objects and classes. Tab key toggles tabs.
We seriously did not change the search algorithms: if suddenly you looked for something well before, and now it is searched badly, please write.
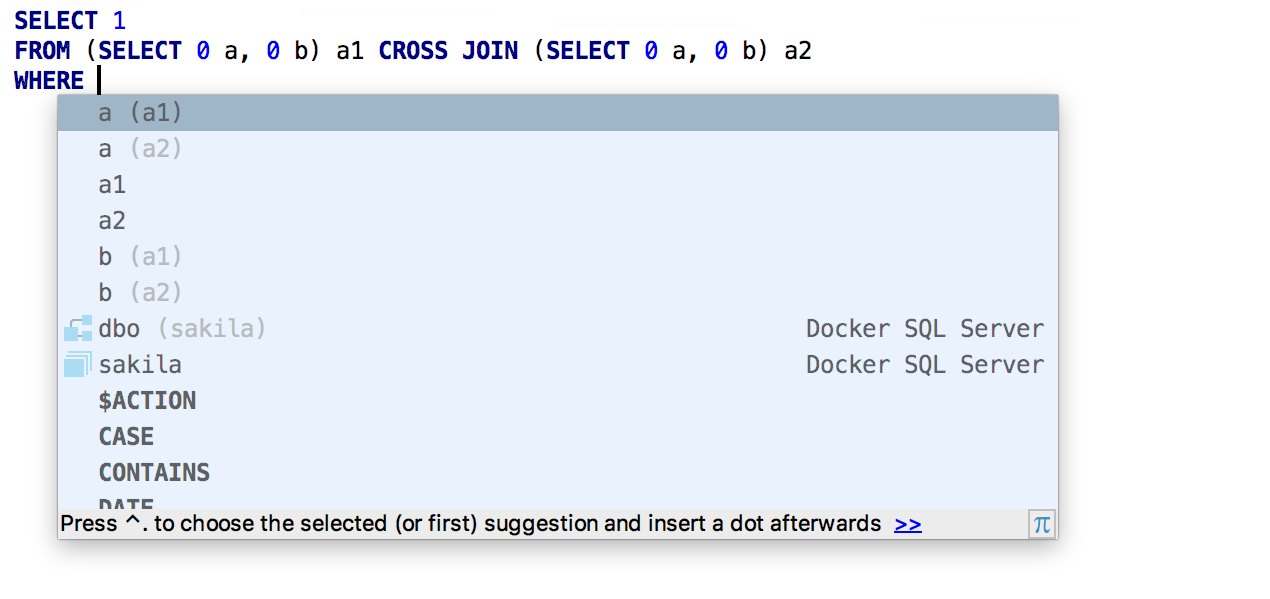
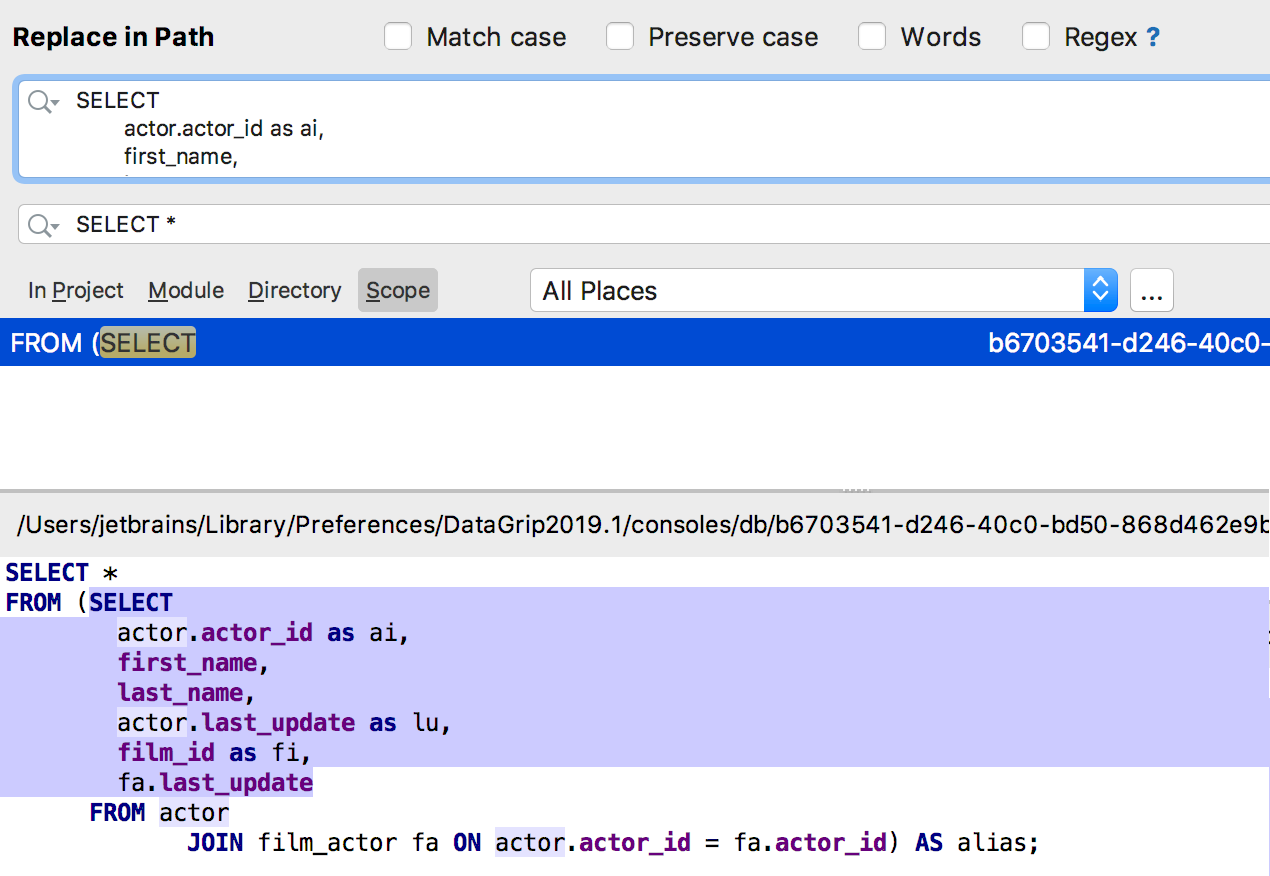
Several lines at once can now be found in the Find in path. For SQL it is especially useful - the query is found inside the source of objects.
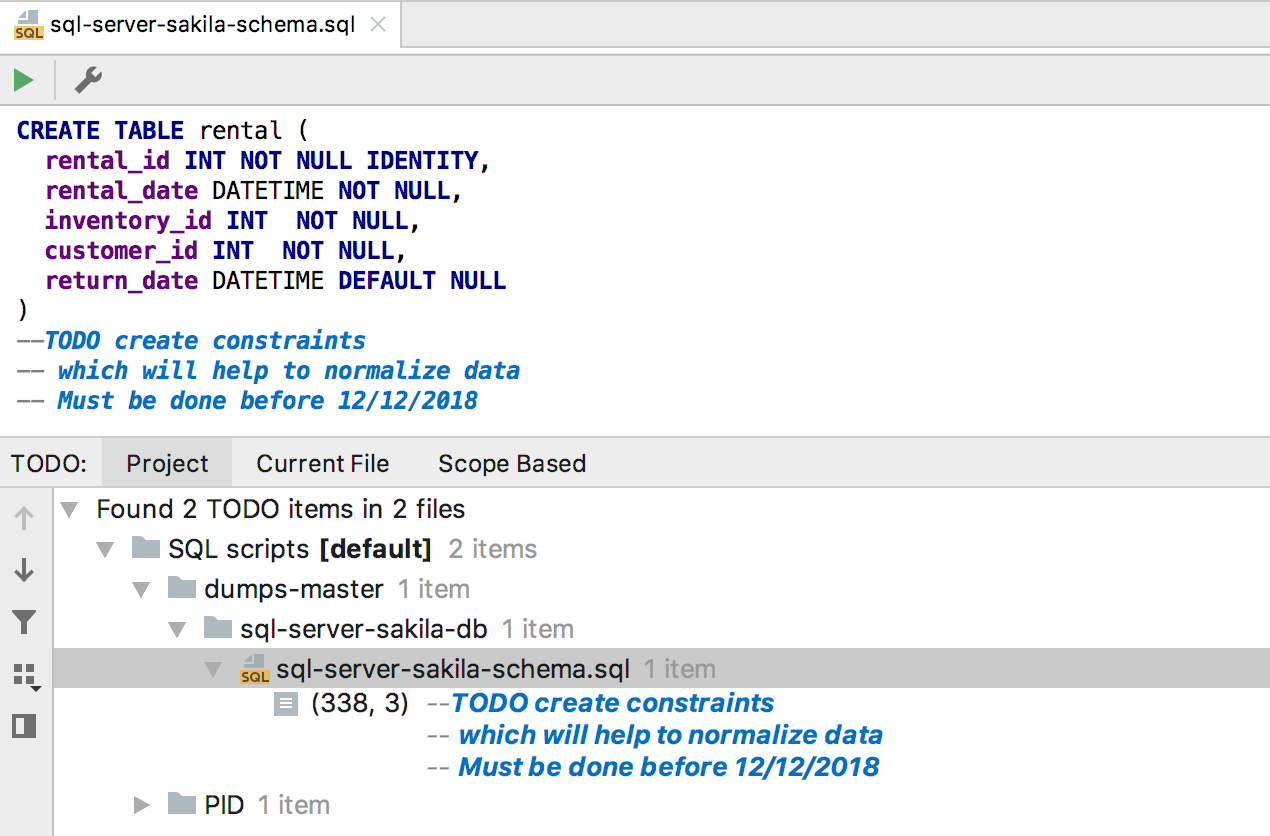
TODO comments can now be multi-line. To add the following lines to such a comment, separate them with a space from the comment character. Tasks designed like this fall into the TODO Tool Window .
The picture is clearer:
New color scheme - very contrast.
Switch schemes like this: Press Ctrl + `and select Look and Feel.
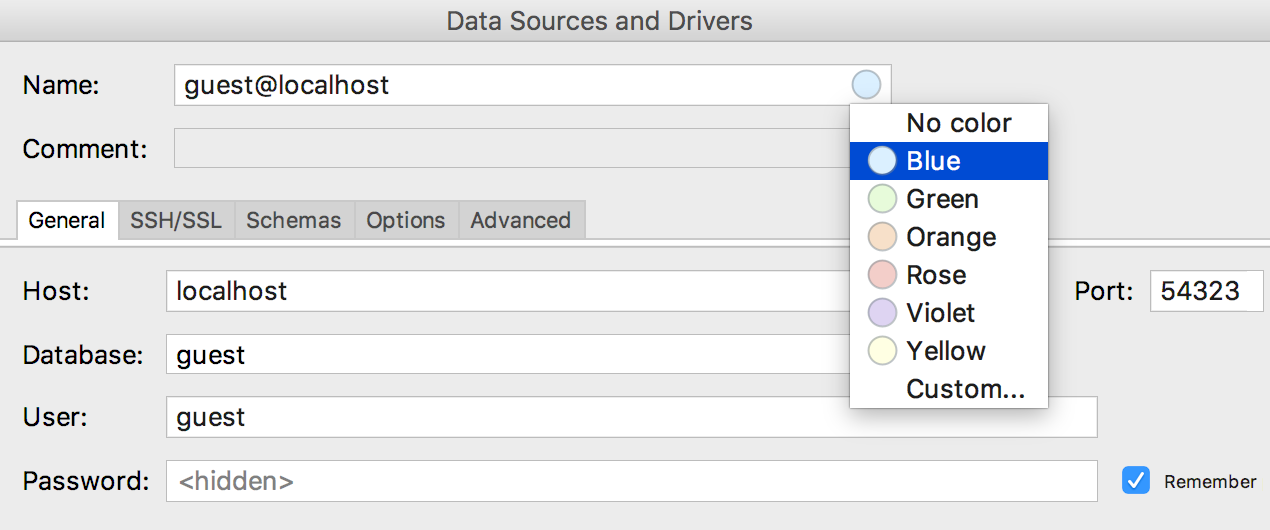
A menu appears to select the color of the data source in its properties window.
And a little friendliness was added to the line selection field per page. Previously, in order for the result to show all the lines, it was necessary to write -1 here :)
Now there is a flag.

Everything!
→ More details here
→ Download trial for a month
→ Tweeter, which we read
→ Mail, which we read
→ Bug tracker
DataGrip team
- Cassandra support
- Creating SQL files from schema objects
- New inspections
- Many new pieces in autocompletion
- Work with data source through one connection
- New search
- High contrast color scheme
Thanks to those who try the EAP version and report problems to our tracker: it helps not to drag them to the release :) Active users have already received free subscriptions for a year.
Cassandra support
Slowly mastering NoSQL database. So far, only those that use SQL-like languages for queries. We supported Clickhouse in 2018.2.2 , and added Cassandra in this release.
Autocompletion
There are a lot of new things in this subsystem.
Added the ability to insert pseudonyms automatically after table names. If the nickname proposed by us does not suit you, indicate which nicknames to use for specific names.
As a result, it works like this:
When using GROUP BY, DataGrip will suggest a list of non-aggregated columns .
The SELECT clause offers a list of all columns .
Autocompletion works for named parameters .
Also added contextual information for identical names.
Finally done postfix completion: this is when something is written through the dot relating to an object.
For example, if after SELECT you write the name of the Table.afrom, it will open into the list of columns and the FROM clause . Or, in our opinion the most convenient, you can add .cast to the column or variable.
It
’s better to see once: Auto-completion has become better for window functions : OVER () is automatically added and the carriage is put in the right place.
Refactoring
An important thing that it was time to do was to use a pseudonym instead of a table. Click on the table Alt + Enter → Introduce alias. The uses of the table will be replaced by pseudonyms.
After the previous release, we received detailed feedback from speshuric . For example, he found a lot of unobvious scripts for Extract subquery as a CTE. This refactoring is called via the menu Refactor → Extract → Subquery as CTE , but we advise you to get used to Find Action (Ctrl + Shift + A).
What we did:
- The new name for the CTE does not conflict with the existing ones: DBE-6496
- Correctly determine the context if the request is wrapped in another expression: DBE-6503, DBE-6517
- We do not offer refactoring in the case of AS TableName : DBE-6490
- Supported for MySQL 8.
- Works as it should with deep subqueries. DBE-7332 , DBE-7333
Code generation
Code templates can be tied to dialects - a template can work for some bases, and not work for others.
What is more important: the same template can generate different code for different databases. To do this, create template groups for each dialect, because the same template names are not supported within the same group (by default, we store templates in the SQL group).
For example, we want to create a template for pulling out the first n rows from the table. PostgreSQL and SQL Server use a different syntax for this, and we will always use a template
seln. Accordingly, implement the two patterns in two different groups and assign them the appropriate dialects. It turns out like this:
From the SELECT clause you can now generate the creation of a tablewith the same signature. To do this, press Alt + Enter → Create table definition
And a small fix for the INS template - hints for column names are displayed automatically.
Code analysis
Added inspections about unsafe DELETE and UPDATE - we warn you that you will lose data.
And if you run, we will specify :)
Another inspection will find unused columns from the subquery .
And the other is unused code.
Database Objects
SQL Generator ( Ctrl / Cmd + Alt + G ) learned to write the results to a file : to do this, click the Save button .
{kind=link}
By default, there are two ways to organize files, but if you need any more, write in the comments.
Or now, if you click on the pencil on the right, you can edit the corresponding groovy scripts. Or create your own.
Supported extensions in PostgreSQL.
We show statistics in the information window for the data source (Ctrl + Q for Windows / Linux, F1 for OSX), including the number of different objects.
And when generating code to remove an object, the option ' Use drop cascade syntax ' was added ..
Compound
Prior to the current version, each new console meant a new connection. Other things that did not require the console, also created separate connections: running scripts, importing, graphical interface for creating tables. In 2018.3, if you enable Single connection mode in the properties of the data source, all work with it will occur through one connection.
As a result, temporary objects will appear in the tree, and also consoles and data editors will work within a single transaction. This is the first step to complete connection management, which we are going to do.
They also made it so that the IDE itself reconnects after idle time.
Search and Navigation
The IntelliJ platform introduced a new search : it combined different types of search that were scattered: Search Everywhere , Find Action , Go to table / view / procedure / , Go to File and Go to Symbol . In DataGrip, the second tab is called Tables, and in other IDE Classes. But it does the same thing: it searches for both database objects and classes. Tab key toggles tabs.
We seriously did not change the search algorithms: if suddenly you looked for something well before, and now it is searched badly, please write.
Several lines at once can now be found in the Find in path. For SQL it is especially useful - the query is found inside the source of objects.
TODO comments can now be multi-line. To add the following lines to such a comment, separate them with a space from the comment character. Tasks designed like this fall into the TODO Tool Window .
The picture is clearer:
Interface
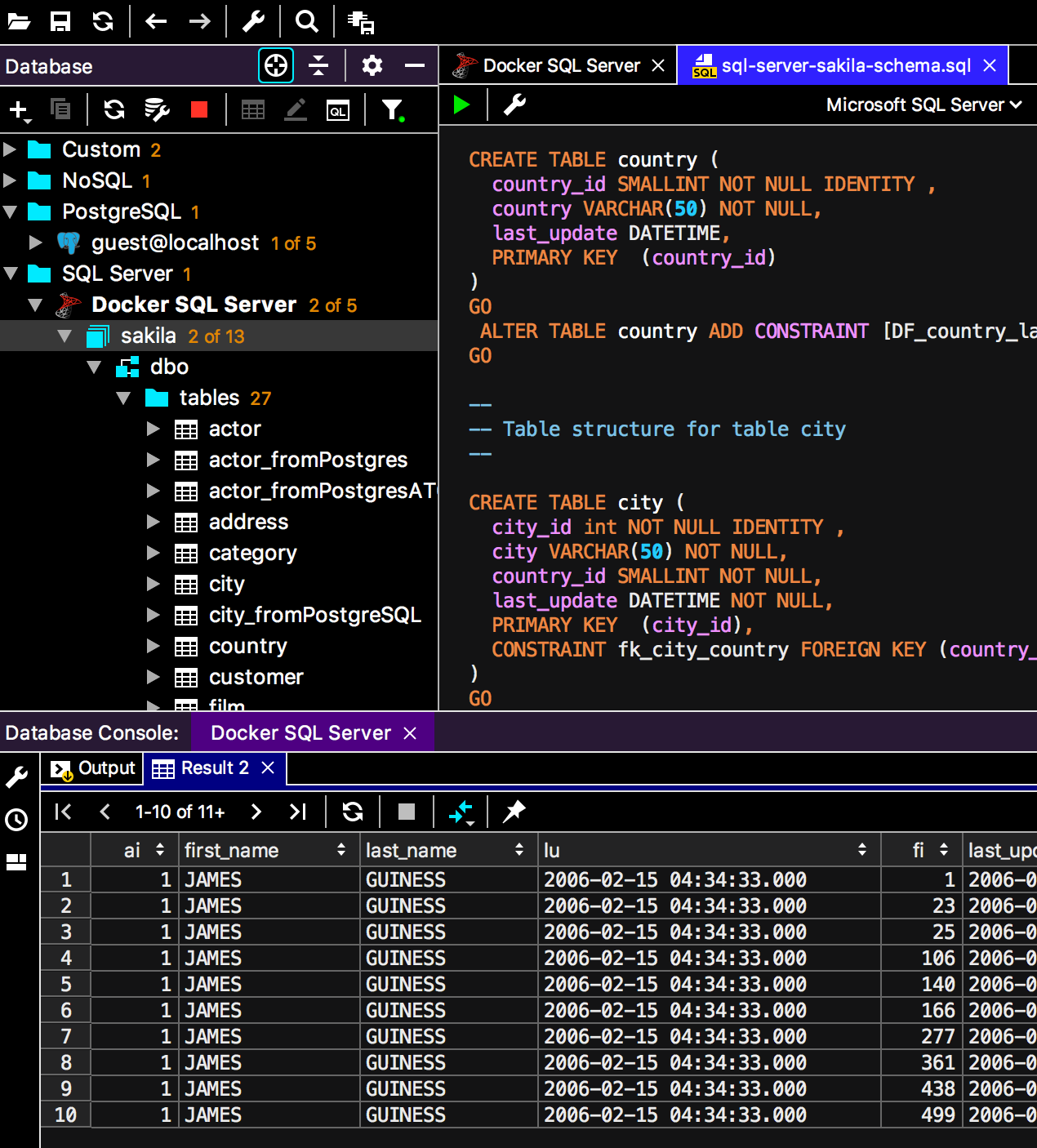
New color scheme - very contrast.
Switch schemes like this: Press Ctrl + `and select Look and Feel.
A menu appears to select the color of the data source in its properties window.
And a little friendliness was added to the line selection field per page. Previously, in order for the result to show all the lines, it was necessary to write -1 here :)
Now there is a flag.
Everything!
→ More details here
→ Download trial for a month
→ Tweeter, which we read
→ Mail, which we read
→ Bug tracker
DataGrip team