Neural networks for beginners. Part 1

Hello to all Habrahabr readers, in this article I want to share with you my experience in studying neural networks and, as a result, their implementation, using the Java programming language, on the Android platform. My acquaintance with neural networks happened when the Prisma application came out. It processes any photo using neural networks, and reproduces it from scratch, using the selected style. Having become interested in this, I rushed to look for articles and "tutorials", first of all, on Habré. And to my great surprise, I did not find a single article that clearly and stage-by-stage described the algorithm of neural networks. The information was fragmented and lacked key points. Also, most authors rush to show the code in one or another programming language, without resorting to detailed explanations.
Therefore, now that I have mastered neural networks well enough and found a huge amount of information from various foreign portals, I would like to share this with people in a series of publications where I will collect all the information that you need if you are just starting to get acquainted with neural networks. In this article, I will not place a strong emphasis on Java and will explain everything with examples so that you yourself can transfer this to any programming language you need. In subsequent articles, I will talk about my application, written for android, which predicts the movement of stocks or currencies. In other words, everyone who wants to plunge into the world of neural networks and longing for a simple and accessible presentation of information or just those who do not understand something and want to pull it up, welcome to cat.
My first and most important discovery was the playlist of the American programmer Jeff Heaton, in which he analyzes in detail and clearly the principles of operation of neural networks and their classification. After watching this playlist, I decided to create my neural network, starting with the simplest example. You probably know that when you are just starting to learn a new language, your first program will be Hello World. This is a kind of tradition. In the world of machine learning, there is also its own Hello world and this neural network solves the problem of the exclusive or (XOR). The table is exclusive or looks like this:
| a | b | c |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
What is a neural network?
A neural network is a sequence of neurons interconnected by synapses. The structure of the neural network came into the world of programming directly from biology. Thanks to this structure, the machine gains the ability to analyze and even remember various information. Neural networks are also capable of not only analyzing incoming information, but also reproducing it from their memory. Those interested must watch 2 videos from TED Talks: Video 1 , Video 2 ). In other words, a neural network is a machine interpretation of the human brain, in which there are millions of neurons transmitting information in the form of electrical impulses.
What are neural networks?
So far, we will consider examples on the most basic type of neural networks - this is a direct distribution network (hereinafter referred to as SPR). Also in subsequent articles I will introduce more concepts and tell you about recurrent neural networks. SPR, as the name implies, is a network with a serial connection of neural layers, in it information always goes in only one direction.
What are neural networks for?
Neural networks are used to solve complex problems that require analytical calculations similar to what the human brain does. The most common applications of neural networks are:
Classification - distribution of data by parameters. For example, a set of people is given to enter and it is necessary to decide which of them to give a loan to and who not. This work can be done by a neural network, analyzing information such as: age, solvency, credit history, etc.
Prediction is the ability to predict the next step. For example, the rise or fall of stocks based on the situation in the stock market.
Recognition- At present, the widest application of neural networks. Used by Google when you are looking for a photo or in the cameras of phones, when it determines the position of your face and highlights it and much more.
Now, to understand how neural networks work, let's take a look at its components and their parameters.
What is a neuron?
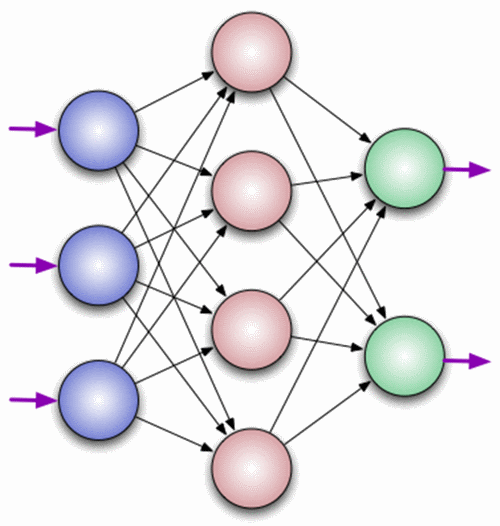
A neuron is a computing unit that receives information, performs simple calculations on it, and passes it on. They are divided into three main types: input (blue), hidden (red) and output (green). There is also a displacement neuron and a contextual neuron which we will discuss in the next article. In the case when the neural network consists of a large number of neurons, the term layer is introduced. Accordingly, there is an input layer that receives information, n hidden layers (usually no more than 3) that process it, and an output layer that displays the result. Each of the neurons has 2 main parameters: input data (input data) and output data (output data). In the case of an input neuron: input = output. In the rest, the total information of all neurons from the previous layer gets into the input field, after which it is normalized,
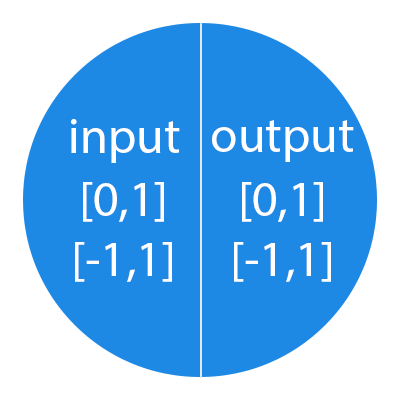
It is important to remember that neurons operate with numbers in the range [0,1] or [-1,1]. But what, you ask, then handle numbers that fall outside this range? At this stage, the simplest answer is to divide 1 by this number. This process is called normalization, and it is very often used in neural networks. More on this later.
What is a synapse?

A synapse is a connection between two neurons. Synapses have 1 parameter - weight. Thanks to him, the input information changes when it is transmitted from one neuron to another. Suppose there are 3 neurons that transmit information to the next. Then we have 3 weights corresponding to each of these neurons. That neuron, whose weight will be more, that information will be dominant in the next neuron (an example - color mixing). In fact, a set of weights of a neural network or a matrix of weights is a kind of brain of the whole system. Thanks to these scales, the input information is processed and turned into a result.
It is important to remember that during initialization of the neural network, weights are placed in random order.
How does a neural network work?
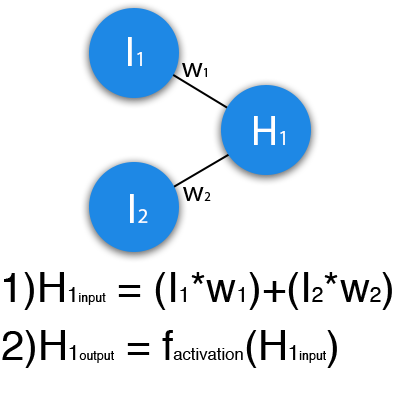
In this example, a part of the neural network is depicted, where the letters I denote the input neurons, the letter H is the hidden neuron, and the letter w is the weight. The formula shows that the input information is the sum of all input data multiplied by the corresponding weights. Then we give 1 and 0 to the input. Let w1 = 0.4 and w2 = 0.7. The input data of the neuron H1 will be as follows: 1 * 0.4 + 0 * 0.7 = 0.4. Now that we have the input, we can get the output by substituting the input value into the activation function (more on that later). Now that we have the output, we pass it on. And so, we repeat for all layers until we reach the output neuron. By launching such a network for the first time, we will see that the answer is far from correct, because the network is not trained. To improve the results, we will train her. But before you know how to do it,
Activation function
The activation function is a way to normalize input data (we already talked about this earlier). That is, if you have a large number at the input, passing it through the activation function, you will get an output in the range you need. There are a lot of activation functions, therefore we will consider the most basic ones: Linear, Sigmoid (Logistic) and Hyperbolic tangent. Their main differences are a range of values.
Linear function
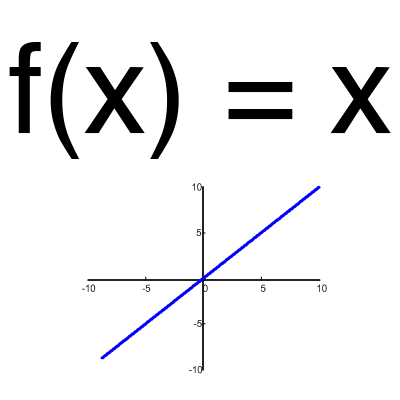
This function is almost never used, unless you need to test a neural network or pass a value without conversion.
Sigmoid
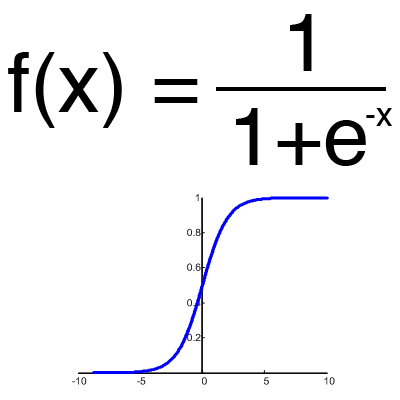
This is the most common activation function, its range of values is [0,1]. It shows the majority of examples on the network, it is also sometimes called the logistic function. Accordingly, if in your case there are negative values (for example, stocks can go not only up, but also down), then you need a function that captures negative values.
Hyperbolic tangent
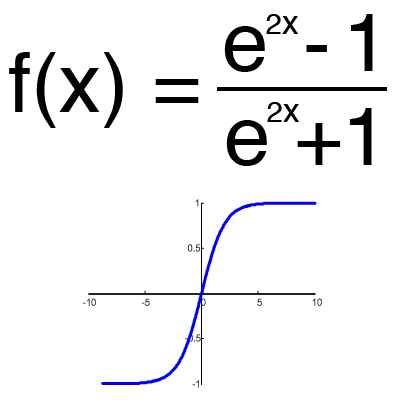
It makes sense to use hyperbolic tangent only when your values can be both negative and positive, since the range of the function is [-1,1]. Using this function only with positive values is impractical since it will significantly worsen the results of your neural network.
Training set
A training set is a sequence of data operated by a neural network. In our case of eliminating or (xor), we have only 4 different outcomes, that is, we will have 4 training sets: 0xor0 = 0, 0xor1 = 1, 1xor0 = 1,1xor1 = 0.
Iteration
This is a kind of counter that increases every time a neural network goes through one training set. In other words, this is the total number of training sets passed by the neural network.
Era
When the neural network is initialized, this value is set to 0 and has a manually defined ceiling. The larger the era, the better trained the network and, accordingly, its result. The era increases every time we go through the entire set of training sets, in our case, 4 sets or 4 iterations.

It is important not to confuse the iteration with the era and understand the sequence of their increment. First
, the iteration increases n times, and then the era, and not vice versa. In other words, you cannot first train a neural network on only one set, then on another, and so on. You need to train each set once per era. So, you can avoid errors in the calculations.
Error
Error is a percentage that reflects the discrepancy between the expected and received responses. A mistake is formed every era and should decline. If this does not happen, then you are doing something wrong. The error can be calculated in different ways, but we will consider only three main methods: Mean Squared Error (hereinafter MSE), Root MSE and Arctan. There is no restriction on use, as in the activation function, and you are free to choose any method that will bring you the best result. It is only worth considering that each method considers errors differently. At Arctan, the error will almost always be greater, since it works on the principle: the greater the difference, the greater the error. Root MSE will have the smallest error, therefore, most often, they use MSE, which maintains balance in error calculation.
MSE
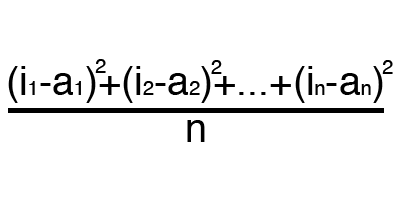
Root MSE
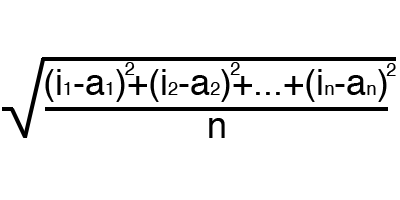
Arctan
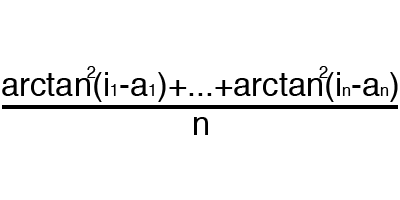
The principle of error calculation is the same in all cases. For each set, we consider the error, taking away from the ideal answer received. Next, we either square or calculate the square tangent of this difference, after which we divide the resulting number by the number of sets.
Task
Now, to test yourself, calculate the result of a given neural network using a sigmoid and its error using MSE.
Data: I1 = 1, I2 = 0, w1 = 0.45, w2 = 0.78, w3 = -0.12, w4 = 0.13, w5 = 1.5, w6 = -2.3.

Decision
H1input = 1 * 0.45 + 0 * -0.12 = 0.45
H1output = sigmoid (0.45) = 0.61
H2input = 1 * 0.78 + 0 * 0.13 = 0.78
H2output = sigmoid (0.78) = 0.69
O1input = 0.61 * 1.5 + 0.69 * -2.3 = -0.672
O1output = sigmoid (-0.672) = 0.33
O1ideal = 1 (0xor1 = 1)
Error = ((1-0.33) ^ 2) /1=0.45
The result is 0.33, the error is 45%.
H1output = sigmoid (0.45) = 0.61
H2input = 1 * 0.78 + 0 * 0.13 = 0.78
H2output = sigmoid (0.78) = 0.69
O1input = 0.61 * 1.5 + 0.69 * -2.3 = -0.672
O1output = sigmoid (-0.672) = 0.33
O1ideal = 1 (0xor1 = 1)
Error = ((1-0.33) ^ 2) /1=0.45
The result is 0.33, the error is 45%.
Thank you very much for your attention! Hope this article has been able to help you learn about neural networks. In the next article, I will talk about displacement neurons and how to train a neural network using the backpropagation and gradient descent method.
Resources used:
- One
- Two
- Three