Python transpiler chain → 11l → C ++ [to speed up Python code and more]




This article discusses the most interesting transformations that a chain of two transpilers (the first translates the Python code into the code in the new 11l programming language , and the second - the 11l code in C ++), and compares the performance with other acceleration tools / code execution in Python (PyPy, Cython, Nuitka).
Replacing "slices" \ slices on ranges \ ranges
| Python | 11l |
| |
s[(len)-2]instead of just s[-2]need to exclude the following errors:- When it is required, for example, to get the previous character by
s[i-1], but if i = 0, such / this record instead of an error will silently return the last character of the string [ and I encountered this error in practice - commit ] . - Expression
s[i:]afteri = s.find(":")will not work properly when the character is not found in the string [ instead of '' part of the string from the first character:and then '' will be taken the last character string ] (and, in general, return-1functionfind()in Python-is, I believe is also wrong [ should return null / None [ and if -1 is required, then you should write explicitly:i = s.find(":") ?? -1] ] ). - Writing
s[-n:]to get thenlast characters of the string will not work correctly when n = 0.
Chains of comparison operators
At first glance, an outstanding feature of the Python language, but in practice it can be easily abandoned / dispensed with using the operator
inand ranges:a < b < c | b in a<..<c |
a <= b < c | b in a..<c |
a < b <= c | b in a<..c |
0 <= b <= 9 | b in 0..9 |
List inclusion (list comprehension)
Similarly, as it turned out, you can opt out of another interesting Python feature - list comprehensions.
While some glorify list comprehension and even offer to give up `filter ()` and `map ()` , I found that:
- In all places where I met Python's list comprehension, you can easily get away with the functions `filter ()` and `map ()`.
dirs[:] = [d for d in dirs if d[0] != '.'and d != exclude_dir] dirs[:] = filter(lambda d: d[0] != '.'and d != exclude_dir, dirs) '[' + ', '.join(python_types_to_11l[ty] for ty in self.type_args) + ']''[' + ', '.join(map(lambda ty: python_types_to_11l[ty], self.type_args)) + ']'# Nested list comprehension: matrix = [ [1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], ] [[row[i] for row in matrix] for i in range(4)] list(map(lambda i: list(map(lambda row: row[i], matrix)), range(4))) - `filter ()` and `map ()` in 11l look prettier than in Pythonand therefore the need for list comprehensions in 11l is virtually eliminated [the replacement of list comprehension with
dirs[:] = filter(lambda d: d[0] != '.' and d != exclude_dir, dirs) dirs = dirs.filter(d -> d[0] != ‘.’ & d != @exclude_dir) '[' + ', '.join(map(lambda ty: python_types_to_11l[ty], self.type_args)) + ']' ‘[’(.type_args.map(ty -> :python_types_to_11l[ty]).join(‘, ’))‘]’ outfile.write("\n".join(x[1] for x in fileslist if x[0])) outfile.write("\n".join(map(lambda x: x[1], filter(lambda x: x[0], fileslist)))) outfile.write(fileslist.filter(x -> x[0]).map(x -> x[1]).join("\n"))filter()and / ormap()is done automatically in the process of converting Python code to 11l ] .
Convert the if-elif-else chain to switch
While Python does not contain a switch statement, this is one of the most beautiful constructions in the 11l language, and so I decided to insert the switch automatically:
| Python | 11l |
| |
For completeness, here is the generated C ++ code.
switch (instr[i])
{
case u'[':
nesting_level++;
break;
case u']':
if (--nesting_level == 0)
goto break_;
break;
case u'‘':
ending_tags.append(u"’"_S);
break; // ‘‘
case u'’':
assert(ending_tags.pop() == u'’');
break;
}
Converting small dictionaries to native code
Consider this line of Python code:
tag = {'*':'b', '_':'u', '-':'s', '~':'i'}[prev_char()]
In 11l, the entry corresponding to this line [ and received by the Python transpiler → 11l ] is not only convenient [ however, not as elegant as in Python ] , but also fast:
var tag = switch prev_char() {‘*’ {‘b’}; ‘_’ {‘u’}; ‘-’ {‘s’}; ‘~’ {‘i’}}
The line above is shipped to:
auto tag = [&](const auto &a){return a == u'*' ? u'b'_C : a == u'_' ? u'u'_C : a == u'-' ? u's'_C : a == u'~' ? u'i'_C : throw KeyError(a);}(prev_char());
?/:. ]When assigning a variable, the dictionary is left as is:
| Python | |
| 11l | |
| C ++ | |
Capture \ Ca pture external variables
In Python, to indicate that a variable is not local, but should be taken outside [ of the current function ] , the nonlocal keyword is used [ otherwise, for example, it
found = Truewill be interpreted as creating a new local variable found, rather than assigning a value to an already existing external variable ] . In 11l, the prefix @ is used for this:
| Python | 11l |
| |
auto writepos = 0;
auto write_to_pos = [..., &outfile, &writepos](const auto &pos, const auto &npos)
{
outfile.write(...);
writepos = npos;
};
Global variables
Similar to external variables, if you forget to declare a global variable in Python [ via the global keyword ] , you get an inconspicuous bug:
| |
break_label_index' error at compile time .Index / number of the current container item
I always forget the order of the variables that the Python function returns
enumerate{first comes the value and then the index or vice versa}. Analogous behavior in Ruby - - each.with_indexis much easier to remember: with index means that index comes after value, and not before. But in 11l, the logic is even easier to memorize:| Python | 11l |
| |
Performance
As a test, the program uses the conversion of PC markup to HTML , and the source data is taken from the source code of the article on PC markup [ since this article is currently the largest written on PC markup ] , and is repeated 10 times, i.e. It turns out from 48.8 kilobyte article a file of 488Kb in size.
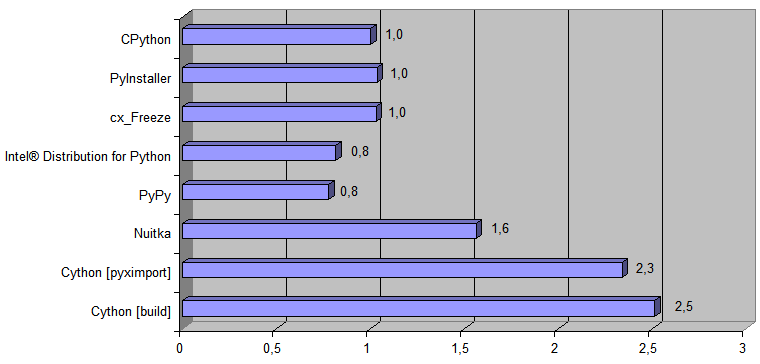
Here is a diagram showing how many times the appropriate way to execute Python code is faster than the original [ CPython ] implementation :
And now let's add to the diagram the implementation generated by the Python transpiler → 11l → C ++: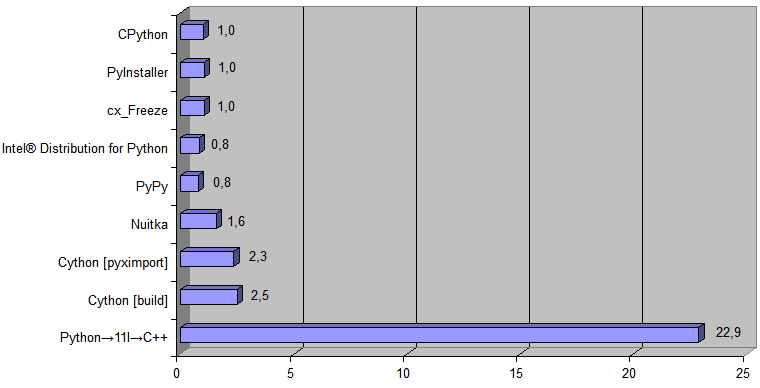
Время выполнения [время преобразования файла размером 488Кб] составило 868 мс для CPython и 38 мс для сгенерированного C++ кода [это время включает в себя полноценный [т.е. не просто работу с данными в оперативной памяти] запуск программы операционной системой и весь ввод/вывод [чтение исходного файла [.pq] и сохранение нового файла [.html] на диск]].
Я хотел ещё попробовать Shed Skin, но он не поддерживает локальные функции.
Numba использовать также не получилось (выдаёт ошибку ‘Use of unknown opcode LOAD_BUILD_CLASS’).
Вот архив с использовавшейся программой для сравнения производительности [под Windows] (требуются установленный Python 3.6 или выше и следующие Python-пакеты: pywin32, cython).
Время выполнения [время преобразования файла размером 488Кб] составило 868 мс для CPython и 38 мс для сгенерированного C++ кода [это время включает в себя полноценный [т.е. не просто работу с данными в оперативной памяти] запуск программы операционной системой и весь ввод/вывод [чтение исходного файла [.pq] и сохранение нового файла [.html] на диск]].
Я хотел ещё попробовать Shed Skin, но он не поддерживает локальные функции.
Numba использовать также не получилось (выдаёт ошибку ‘Use of unknown opcode LOAD_BUILD_CLASS’).
Вот архив с использовавшейся программой для сравнения производительности [под Windows] (требуются установленный Python 3.6 или выше и следующие Python-пакеты: pywin32, cython).
Python source and output of Python → 11l and 11l → C ++ transpilers:
| Python | Generated 11l (with keywords instead of letters) | 11l (with letters) | C ++ generated |