VP8, VP9 and H265. Hardware acceleration of video encoding and decoding in 6th generation Skylake processors
More than six years ago, on September 13, 2010, Intel introduced the microarchitecture of Sandy Bridge processors, the second generation of Intel Core processors, at the IDF forum. The processor and the graphics core were combined on one chip, and the graphics core itself was significantly updated and the clock speed increased. It was in Sandy Bridge that the “secret weapon” appeared - Intel Quick Sync Video (QSV) technology for hardware acceleration of video encoding and decoding. A small section of SoC was specially allocated to accommodate specialized integrated circuits that deal only with video. It was a real hardware transcoder .
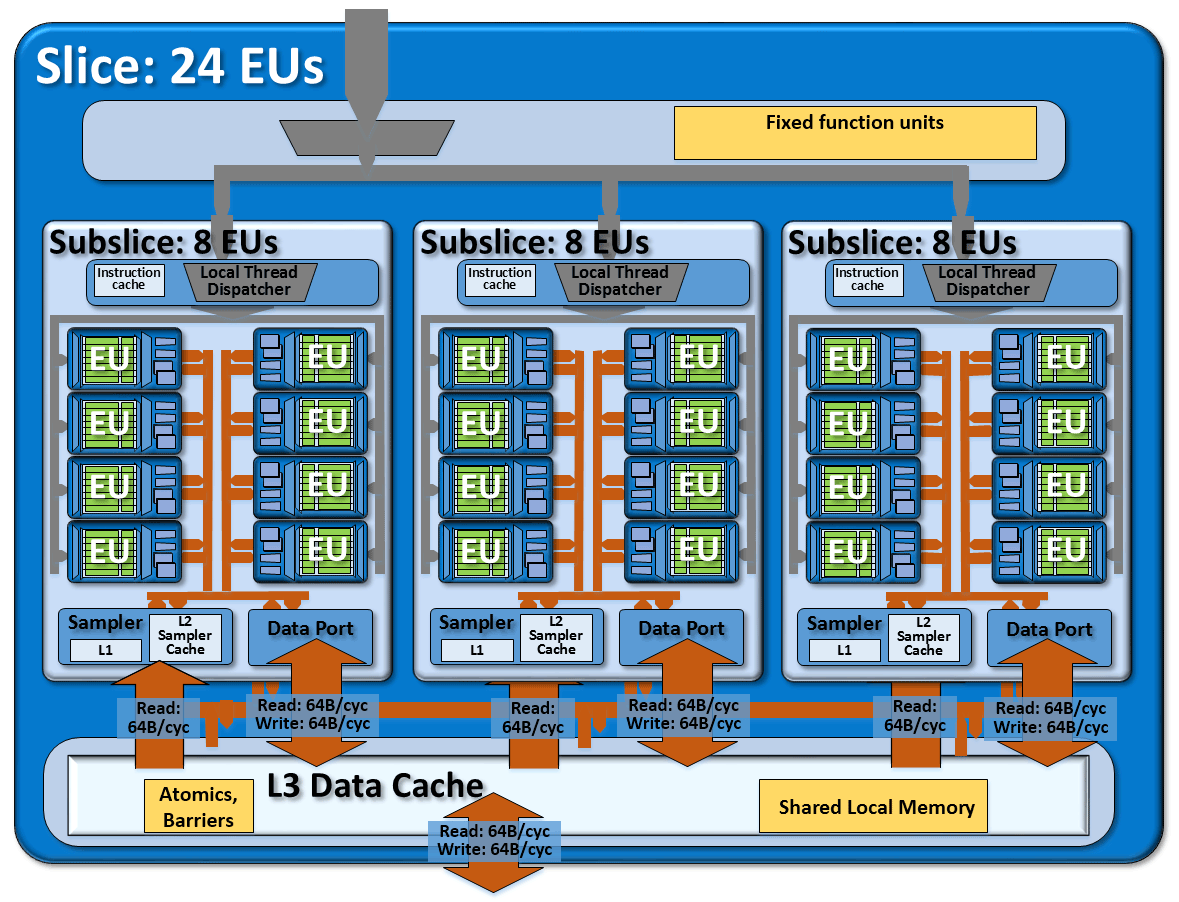
Integrated 9th generation HD Graphics 530 in the Intel Core i7 6700K processor with 24 instruction execution units (EU) organized in three fragments of 8 blocks.
Surprisingly, Intel managed to get around both AMD and Nvidia in implementing hardware-accelerated video coding: similar AMD Video Codec Engine and Nvidia NVENC technologies appeared in AMD and Nvidia video cards with a considerable delay (compression algorithms require serious adaptation for video card processors). This is why the idea and development of QSV has been kept secret for five years .
To say that QSV was in demand is to say nothing. Playing back (decoding) video with hardware support has become much less consuming resources from other tasks in the OS, less heat up the CPU and consume less power.
In addition, in recent years, video encoding has become one of the most demanding tasks on a PC. The popularity of YouTube has turned millions of people into cameramen and directors. And then there's the ubiquity of smartphones that require transcoding from DVD to compressed AVC MP4 / H.264. As a result, almost every PC has become a video studio. IPTV and video streaming on the Internet are widespread. The computer began to play the role of a television. Video has become ubiquitous and has become one of the most popular types of content on PC. It is encoded and transcoded constantly and everywhere: at different bitrates, depending on the type of device, screen size and Internet speed. In such a situation, the ability to quickly encode and decode video in processors was self-evident. So in the Intel GPU integrated hardware encoder / decoder.
The modern codec processes each frame individually, but also analyzes the sequence of frames for repetitions in time (between frames) and space (within one frame). This is a difficult computing task. The following is an example frame from a video encoded with the latest HEVC codec. For a particular area near the hare’s ear, it is shown how exactly different parts of the frame were encoded. Also shows the position and type of frame in the overall structure of the video stream. Without going into details of video compression algorithms, this gives a general idea of how much information needs to be analyzed in order to effectively encode and decode video.
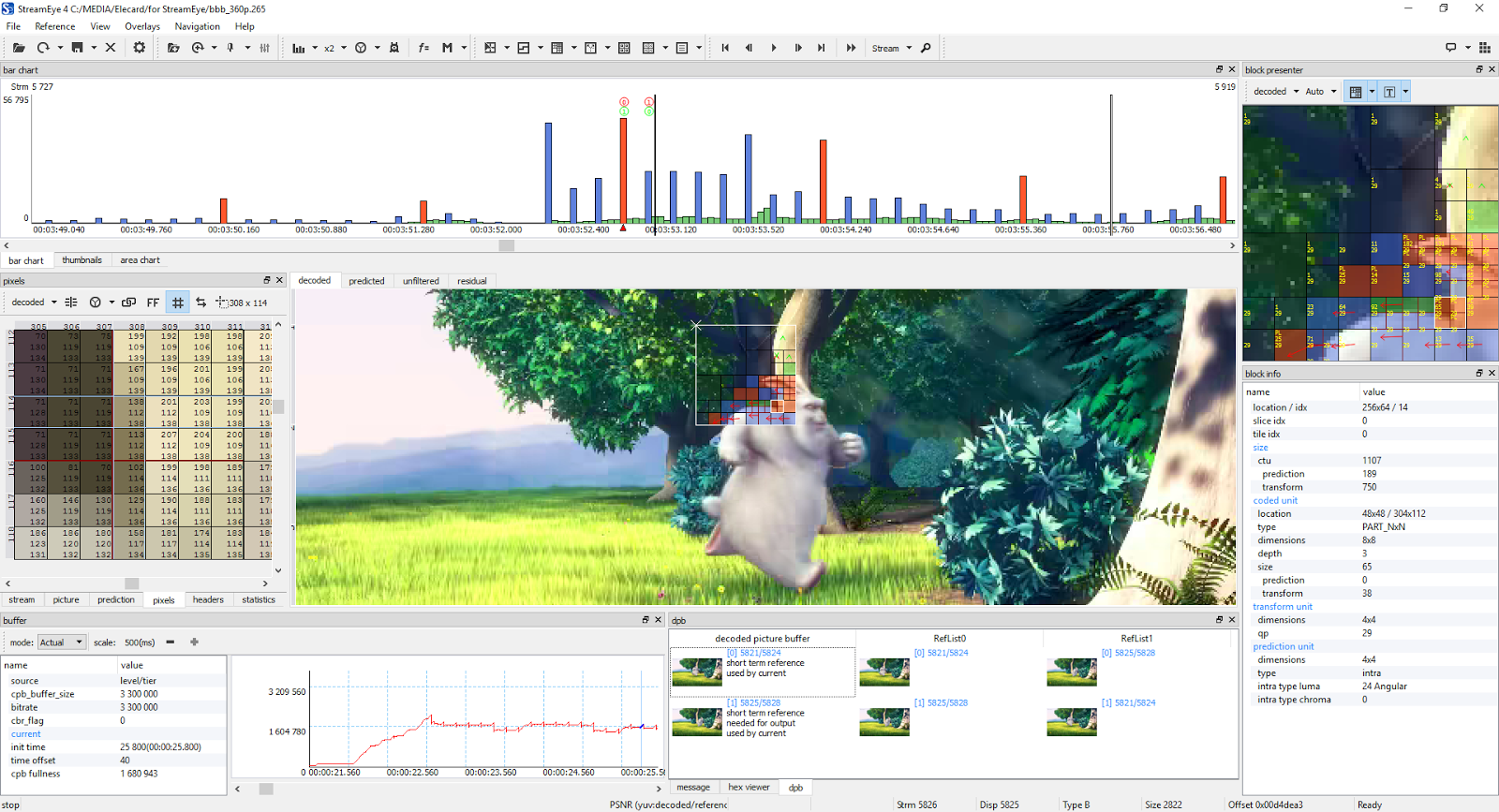
Screenshot of an open video in the Elecard StreamEye program , 1920 × 1040
Hardware support for encoding and decoding means that integrated circuits are implemented directly in the processor, specialized for specific tasks of encoding and decoding. For example, the discrete cosine transform (DCT) is performed during encoding, and the inverse discrete cosine transform is performed during decoding.
Over the past five years, Intel QSV technology has advanced significantly. Added support for free VP8 and VP9 video codecs, updated drivers for Linux, etc.
Technology has improved with each new generation of Intel Core, right up to the current 6th generation of Skylake.
The latest version of QSV 5.0 was released along with the sixth generation core microarchitecture Skylake. This version of the GPU in the official documentation of Intel is classified as Gen9, that is, 9th generation graphics.

The Intel Core i7 6700K desktop processor contains 4 CPU cores and 9th generation integrated graphics HD Graphics 530
With each new microarchitecture in the GPU, the number of command execution units (EU) has increased. It grew from 6 in Sandy Bridge to 72 in the top-end Iris Pro Graphics 580 on Skylake crystals. Including due to this, the performance of the GPU increased tenfold without increasing the clock frequency. Throughout the latest generation of Iris and Iris Pro graphics, there is an integrated Level 4 cache of 64 or 128 MB.
The basic building block of the Gen9 microarchitecture is the command execution unit (EU). Each EU combines simultaneous multithreading (SMT) and carefully tuned alternating multithreading (IMT). Here arithmetic-logic devices with a single stream of commands, multiple data stream (SIMD ALU) work. They are built on the conveyors of numerous threads for high-speed floating-point calculations and integer operations.
The essence of alternating multithreading in the EU is to guarantee a continuous flow of ready-to-execute instructions, but at the same time to queue with a minimum delay more complex operations, such as placing vectors in memory, sampler requests or other system communications.

Command Execution Unit (EU)
Each thread in the Gen9 instruction block contains 128 general purpose registers. Each register has 32 bytes of memory available as an 8-element SIMD vector or 32-bit data elements. Thus, for every thread, there is a 4 KB general purpose registry file (GRF). In total, there are 7 threads per EU with a total of 28 KB GRF per EU. A flexible addressing system allows you to address multiple registers together. The thread status is currently stored in a separate registry architecture file (ARF).
Depending on the load, the hardware threads in the EU can execute in parallel one code from one computing core or can execute code from completely different computing cores. The execution status in each thread, including its own instruction pointers, is stored in its independent ARF. On each cycle, the EU can issue up to four different instructions, which should be from four different threads. A special thread arbiter (Thread Arbiter) sends these instructions to one of four function blocks for execution. Typically, an arbiter can choose from dissimilar instructions to simultaneously load all function blocks and thus provide parallelism at the instruction level.
The pair of FPUs in the circuit actually performs both floating point and integer calculations. In Gen9, these modules can process not only up to four operations with 32-bit numbers per cycle, but also up to eight operations with 16-bit ones. Addition and multiplication operations are performed simultaneously, that is, the EU unit is capable of performing a maximum of 16 operations with 32-bit numbers in one cycle: 2 FPUs with 4 operations × 2 (addition + multiplication).
The compilers, such as RenderScript, OpenCL, Microsoft DirectX Compute Shader, OpenGL Compute and C ++ AMP, generate the SPMD code for the EU multi-threaded download. The compiler itself heuristically selects the thread loading mode (SIMD-width): SIMD-8, SIMD-16 or SIMD-32. So, in the case of SIMD-16, 112 (16 × 7) threads can be executed simultaneously on one EU.
The exchange of data within one instruction within the EU block can be, for example, 96 bytes to read and 32 bytes to write. When scaling to the entire GPU, taking into account several levels of the memory hierarchy, it turns out that the maximum theoretical data exchange limit between the FPU and GRF reaches several terabytes per second.
GPU microarchitecture is scalable at all levels. Scalability at the thread level goes into scalability at the level of command execution blocks. In turn, these blocks of command execution will be combined into groups of eight pieces (8 EU = 1 subslice).
At each zoom level, there are local modules that work only here. For example, each group of 8 EU blocks has its own local thread manager, data port and texture sampler.

A group of 8 EU blocks (subslice)
In turn, groups of 8 EU are united into groups of 24 EU (3 sublices = 1 slice). These 24 block slices, in turn, are also scalable: the existing Gen9 graphics contains 24, 48, or 72 EU.
Gen9 graphics increased L3 L3 cache to 768 KB for each group of 24 EU. All samplers and data ports have their own L3 access interface, which allows you to read and write 64 bytes per cycle. Thus, a group of 24 EU has three data ports with a data transfer band to the L3 cache of 192 bytes per cycle. If the cache does not have data on demand, then the data is requested or sent for writing to the system memory, also 64 bytes per cycle.

Gen9 microarchitecture from two groups of 24 (3 × 8) EU.
This scalability allows you to effectively reduce power consumption by disabling those modules that are not currently involved.
Gen9 has full support for hardware acceleration for H.265 / HEVC encoding and decoding , partial support for hardware encoding and decoding with the free VP9 codec. Significant improvements in QSV technology have been made. They improved the quality and efficiency of encoding and decoding, as well as the performance of filters in transcoding and video editing programs that use hardware acceleration.
Skylake's integrated graphics support DirectX 12 Feature Level 12_1, OpenGL 4.4, and OpenCL 2.0 standards. It was decided to completely abandon VGA monitors, but Skylake GPUs support up to three monitors with HDMI 1.4, DisplayPort 1.2 or Embedded DisplayPort (eDP) 1.3 interfaces.
Hardware video decoding acceleration is available for the graphics driver via Direct3D Video API (DXVA2), Direct3d11 Video API or Intel Media SDK, as well as through MFT (Media Foundation Transform) filters.
Gen9 graphics support hardware acceleration for decoding AVC, VC1, MPEG2, HEVC (8 bits), VP8, VP9 and JPEG.
Source: 6th Generation Intel Processor Datasheet for S-Platforms
The estimated video decoding performance with hardware acceleration is more than 16 simultaneous 1080p video streams. Actual performance will vary by GPU model, bit rate, and clock speed. H264 SVC hardware decoding is not supported in Skylake.
Hardware encoding acceleration is available only through the Intel Media SDK interfaces, as well as through the MFT (Media Foundation Transform) filters.
Source: 6th Generation Intel Processor Datasheet for S-Platforms
In addition to hardware acceleration of encoding and decoding, Gen9 graphics also include hardware acceleration of video processing, including the following functions: deinterlacing, cadence detection, video scaling (Advanced Video Scaler), improved detail, stabilization images, gamut compression, adaptive HD contrast enhancement, skin tone enhancement, color rendering control, noise reduction in the channel color component (chroma de-noise), SFC conversion (Scalar and Format Conversion), compression names, LACE (Localized Adaptive Contrast Enhancement), spatial noise reduction, Out-Of-Loop De-blocking (for AVC decoder), etc.
The Gen9 hardware transcoder supports the following specific transcoding features:
In terms of video analytics applications, Gen9 supports hardware acceleration for a number of filters that can be useful in applications like face recognition, facial recognition, gesture recognition, object tracking, etc. (see table).

Source: 6th Generation Intel Processor Datasheet for S-Platforms
Gen9 implements hardware support for processing video from digital cameras (Camera Processing Pipeline), including some functions of this processing: white balance, restoring a full-color image from an array of color filters on the camera sensor (de-mosaic), correction of defective pixels, correction of black level , gamma correction, elimination of vignetting, color space converter (Front end Color Space Converter, CSC), color enhancement (Image Enhancement Color Processing, IECP).
Skylake GPU
To use hardware acceleration, each program must explicitly implement support for specific Gen9 features. Many do it. Intel publishes open access Media SDK 2.0 , so that support for hardware acceleration of encoding and decoding can be implemented in any program. In addition, there are ready-made applications for transcoding live video on Intel codecs, such as Elecard CodecWorks 990 . Unlike the SDK, CodecWorks 990 does not require the participation of programmers for use in real tasks, it already contains the most popular transcoding profiles and it is much easier for a non-programmer engineer to work with it than with the SDK. How software transcoders with hardware acceleration work, we will describe in the next part.
( Continued should ...)
Integrated 9th generation HD Graphics 530 in the Intel Core i7 6700K processor with 24 instruction execution units (EU) organized in three fragments of 8 blocks.
Surprisingly, Intel managed to get around both AMD and Nvidia in implementing hardware-accelerated video coding: similar AMD Video Codec Engine and Nvidia NVENC technologies appeared in AMD and Nvidia video cards with a considerable delay (compression algorithms require serious adaptation for video card processors). This is why the idea and development of QSV has been kept secret for five years .
To say that QSV was in demand is to say nothing. Playing back (decoding) video with hardware support has become much less consuming resources from other tasks in the OS, less heat up the CPU and consume less power.
In addition, in recent years, video encoding has become one of the most demanding tasks on a PC. The popularity of YouTube has turned millions of people into cameramen and directors. And then there's the ubiquity of smartphones that require transcoding from DVD to compressed AVC MP4 / H.264. As a result, almost every PC has become a video studio. IPTV and video streaming on the Internet are widespread. The computer began to play the role of a television. Video has become ubiquitous and has become one of the most popular types of content on PC. It is encoded and transcoded constantly and everywhere: at different bitrates, depending on the type of device, screen size and Internet speed. In such a situation, the ability to quickly encode and decode video in processors was self-evident. So in the Intel GPU integrated hardware encoder / decoder.
The modern codec processes each frame individually, but also analyzes the sequence of frames for repetitions in time (between frames) and space (within one frame). This is a difficult computing task. The following is an example frame from a video encoded with the latest HEVC codec. For a particular area near the hare’s ear, it is shown how exactly different parts of the frame were encoded. Also shows the position and type of frame in the overall structure of the video stream. Without going into details of video compression algorithms, this gives a general idea of how much information needs to be analyzed in order to effectively encode and decode video.
Screenshot of an open video in the Elecard StreamEye program , 1920 × 1040
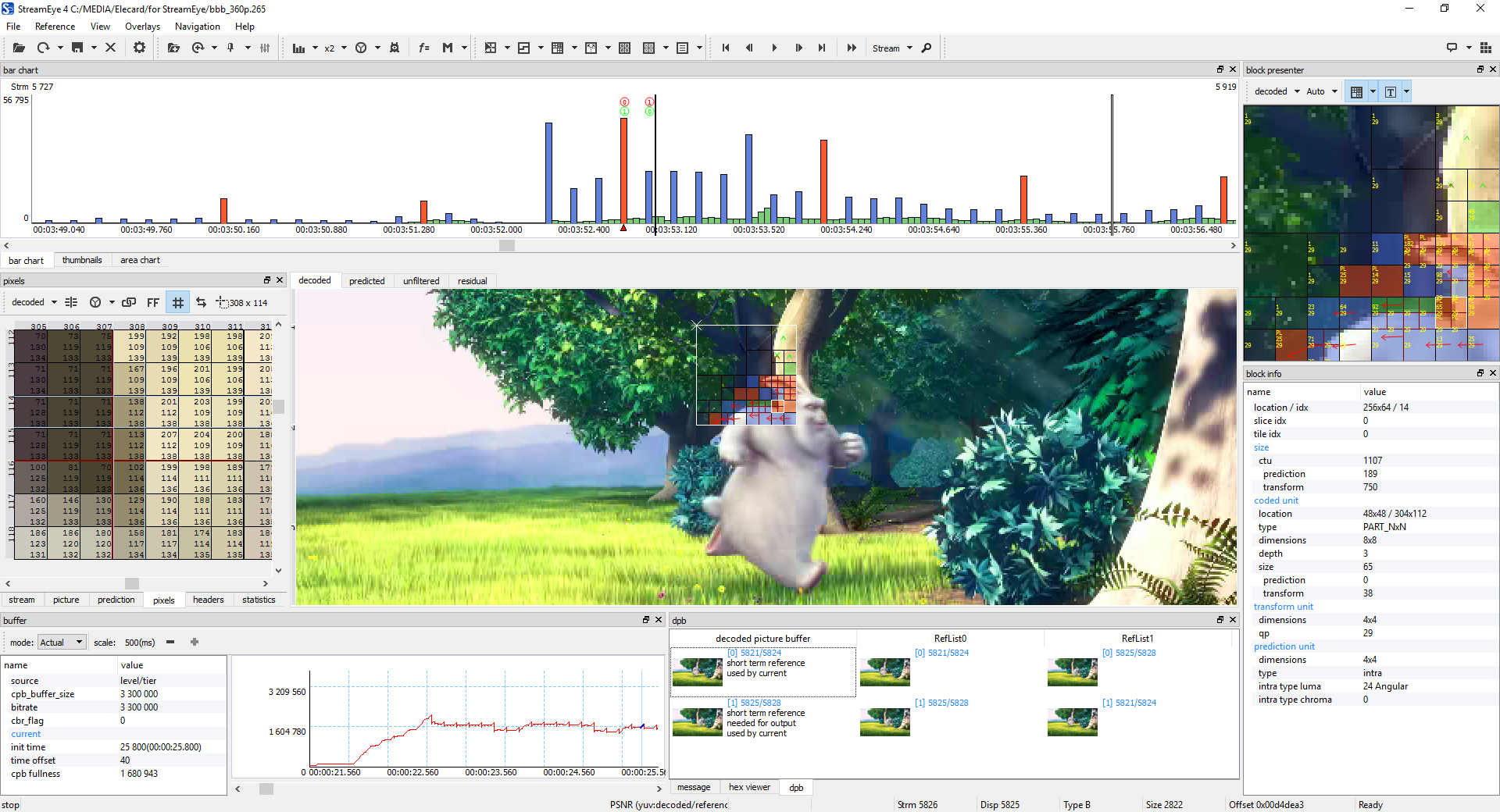{kind=link}
Hardware support for encoding and decoding means that integrated circuits are implemented directly in the processor, specialized for specific tasks of encoding and decoding. For example, the discrete cosine transform (DCT) is performed during encoding, and the inverse discrete cosine transform is performed during decoding.
Over the past five years, Intel QSV technology has advanced significantly. Added support for free VP8 and VP9 video codecs, updated drivers for Linux, etc.
Technology has improved with each new generation of Intel Core, right up to the current 6th generation of Skylake.
9th Gen GPU Microarchitecture
The latest version of QSV 5.0 was released along with the sixth generation core microarchitecture Skylake. This version of the GPU in the official documentation of Intel is classified as Gen9, that is, 9th generation graphics.
The Intel Core i7 6700K desktop processor contains 4 CPU cores and 9th generation integrated graphics HD Graphics 530
With each new microarchitecture in the GPU, the number of command execution units (EU) has increased. It grew from 6 in Sandy Bridge to 72 in the top-end Iris Pro Graphics 580 on Skylake crystals. Including due to this, the performance of the GPU increased tenfold without increasing the clock frequency. Throughout the latest generation of Iris and Iris Pro graphics, there is an integrated Level 4 cache of 64 or 128 MB.
▍ Microarchitecture of command execution units (EU)
The basic building block of the Gen9 microarchitecture is the command execution unit (EU). Each EU combines simultaneous multithreading (SMT) and carefully tuned alternating multithreading (IMT). Here arithmetic-logic devices with a single stream of commands, multiple data stream (SIMD ALU) work. They are built on the conveyors of numerous threads for high-speed floating-point calculations and integer operations.
The essence of alternating multithreading in the EU is to guarantee a continuous flow of ready-to-execute instructions, but at the same time to queue with a minimum delay more complex operations, such as placing vectors in memory, sampler requests or other system communications.
Command Execution Unit (EU)
Each thread in the Gen9 instruction block contains 128 general purpose registers. Each register has 32 bytes of memory available as an 8-element SIMD vector or 32-bit data elements. Thus, for every thread, there is a 4 KB general purpose registry file (GRF). In total, there are 7 threads per EU with a total of 28 KB GRF per EU. A flexible addressing system allows you to address multiple registers together. The thread status is currently stored in a separate registry architecture file (ARF).
Depending on the load, the hardware threads in the EU can execute in parallel one code from one computing core or can execute code from completely different computing cores. The execution status in each thread, including its own instruction pointers, is stored in its independent ARF. On each cycle, the EU can issue up to four different instructions, which should be from four different threads. A special thread arbiter (Thread Arbiter) sends these instructions to one of four function blocks for execution. Typically, an arbiter can choose from dissimilar instructions to simultaneously load all function blocks and thus provide parallelism at the instruction level.
The pair of FPUs in the circuit actually performs both floating point and integer calculations. In Gen9, these modules can process not only up to four operations with 32-bit numbers per cycle, but also up to eight operations with 16-bit ones. Addition and multiplication operations are performed simultaneously, that is, the EU unit is capable of performing a maximum of 16 operations with 32-bit numbers in one cycle: 2 FPUs with 4 operations × 2 (addition + multiplication).
The compilers, such as RenderScript, OpenCL, Microsoft DirectX Compute Shader, OpenGL Compute and C ++ AMP, generate the SPMD code for the EU multi-threaded download. The compiler itself heuristically selects the thread loading mode (SIMD-width): SIMD-8, SIMD-16 or SIMD-32. So, in the case of SIMD-16, 112 (16 × 7) threads can be executed simultaneously on one EU.
The exchange of data within one instruction within the EU block can be, for example, 96 bytes to read and 32 bytes to write. When scaling to the entire GPU, taking into account several levels of the memory hierarchy, it turns out that the maximum theoretical data exchange limit between the FPU and GRF reaches several terabytes per second.
▍ Scalability
GPU microarchitecture is scalable at all levels. Scalability at the thread level goes into scalability at the level of command execution blocks. In turn, these blocks of command execution will be combined into groups of eight pieces (8 EU = 1 subslice).
At each zoom level, there are local modules that work only here. For example, each group of 8 EU blocks has its own local thread manager, data port and texture sampler.
A group of 8 EU blocks (subslice)
In turn, groups of 8 EU are united into groups of 24 EU (3 sublices = 1 slice). These 24 block slices, in turn, are also scalable: the existing Gen9 graphics contains 24, 48, or 72 EU.
Gen9 graphics increased L3 L3 cache to 768 KB for each group of 24 EU. All samplers and data ports have their own L3 access interface, which allows you to read and write 64 bytes per cycle. Thus, a group of 24 EU has three data ports with a data transfer band to the L3 cache of 192 bytes per cycle. If the cache does not have data on demand, then the data is requested or sent for writing to the system memory, also 64 bytes per cycle.
Gen9 microarchitecture from two groups of 24 (3 × 8) EU.
This scalability allows you to effectively reduce power consumption by disabling those modules that are not currently involved.
What QSV can do in Skylake
Gen9 has full support for hardware acceleration for H.265 / HEVC encoding and decoding , partial support for hardware encoding and decoding with the free VP9 codec. Significant improvements in QSV technology have been made. They improved the quality and efficiency of encoding and decoding, as well as the performance of filters in transcoding and video editing programs that use hardware acceleration.
Skylake's integrated graphics support DirectX 12 Feature Level 12_1, OpenGL 4.4, and OpenCL 2.0 standards. It was decided to completely abandon VGA monitors, but Skylake GPUs support up to three monitors with HDMI 1.4, DisplayPort 1.2 or Embedded DisplayPort (eDP) 1.3 interfaces.
Hardware video decoding acceleration is available for the graphics driver via Direct3D Video API (DXVA2), Direct3d11 Video API or Intel Media SDK, as well as through MFT (Media Foundation Transform) filters.
Gen9 graphics support hardware acceleration for decoding AVC, VC1, MPEG2, HEVC (8 bits), VP8, VP9 and JPEG.
▍Hardware video decoding acceleration
| Codec | Profile | Level | Maximum resolution |
| MPEG2 | Main | Main high | 1080p |
| VC1 / WMV9 | Advanced main simple | L3 High Simple | 3840 × 3840 |
| AVC / H264 | High Main MVC & stereo | L5.1 | 2160p (4K) |
| VP8 | 0 | Unified level | 1080p |
| JPEG / MJPEG | Baseline | Unified level | 16k × 16k |
| HEVC / H265 | Main | L5.1 | 2160 (4K) |
| VP9 | 0 (4: 2: 0 Chroma 8-bit) | Unified level | ULT, 4k 24fps @ 15Mbps ULX, 1080p 30fps @ 10Mbps |
The estimated video decoding performance with hardware acceleration is more than 16 simultaneous 1080p video streams. Actual performance will vary by GPU model, bit rate, and clock speed. H264 SVC hardware decoding is not supported in Skylake.
Hardware encoding acceleration is available only through the Intel Media SDK interfaces, as well as through the MFT (Media Foundation Transform) filters.
▍Hardware video encoding acceleration
| Codec | Profile | Level | Maximum resolution |
| MPEG2 | Main | High | 1080p |
| AVC / H264 | Main high | L5.1 | 2160p (4K) |
| VP8 | Unified profile | Unified level | - |
| Jpeg | Baseline | - | 16K × 16K |
| HEVC / H265 | Main | L5.1 | 2160p (4K) |
| VP9 | 8-bit 4: 2: 0 BT2020 | - | - |
In addition to hardware acceleration of encoding and decoding, Gen9 graphics also include hardware acceleration of video processing, including the following functions: deinterlacing, cadence detection, video scaling (Advanced Video Scaler), improved detail, stabilization images, gamut compression, adaptive HD contrast enhancement, skin tone enhancement, color rendering control, noise reduction in the channel color component (chroma de-noise), SFC conversion (Scalar and Format Conversion), compression names, LACE (Localized Adaptive Contrast Enhancement), spatial noise reduction, Out-Of-Loop De-blocking (for AVC decoder), etc.
The Gen9 hardware transcoder supports the following specific transcoding features:
- Real-time, fast and energy-efficient AVC encoder for video conferencing
- Lossless memory compression for media engine to reduce power consumption
- Video Scaling (Advanced Video Scaler)
- Energy efficient SFC converter (Scalar and Format Conversion)
In terms of video analytics applications, Gen9 supports hardware acceleration for a number of filters that can be useful in applications like face recognition, facial recognition, gesture recognition, object tracking, etc. (see table).
Source: 6th Generation Intel Processor Datasheet for S-Platforms
Gen9 implements hardware support for processing video from digital cameras (Camera Processing Pipeline), including some functions of this processing: white balance, restoring a full-color image from an array of color filters on the camera sensor (de-mosaic), correction of defective pixels, correction of black level , gamma correction, elimination of vignetting, color space converter (Front end Color Space Converter, CSC), color enhancement (Image Enhancement Color Processing, IECP).
Skylake GPU
- HD Graphics 510 (GT1, 12 EU, 950 MHz, 182.4 GFlops)
- HD Graphics 515 (GT2, 24 EU, 1000 MHz, 384 GFlops)
- HD Graphics 520 (GT2, 24 EU, 1050 MHz, 403.2 GFlops)
- HD Graphics 530 (GT2, 24 EU, 1150 MHz, 441.6 GFlops)
- Iris Graphics 540 (GT3e, 48 EU, 64 MB eDRAM, 1050 MHz, 806.4 GFlops)
- Iris Graphics 550 (GT3e, 48 EU, 64 MB eDRAM, 1100 MHz, 844.8 GFlops)
- Iris Pro Graphics 580 (GT4e, 72 EU, 128 MB eDRAM, 1000 MHz, 1152 GFlops)
- HD Graphics P530, server (GT2, 24 EU, 1150 MHz, 441.6 Gflops)
- Iris Pro Graphics P555, server (GT3e, 48 EU, 128 MB eDRAM, 1000 MHz, 768 Gflops)
- Iris Pro Graphics P580, server (GT4e, 72 EU, 128 MB eDRAM, 1000 MHz, 1152 Gflops)
How programs use hardware acceleration
To use hardware acceleration, each program must explicitly implement support for specific Gen9 features. Many do it. Intel publishes open access Media SDK 2.0 , so that support for hardware acceleration of encoding and decoding can be implemented in any program. In addition, there are ready-made applications for transcoding live video on Intel codecs, such as Elecard CodecWorks 990 . Unlike the SDK, CodecWorks 990 does not require the participation of programmers for use in real tasks, it already contains the most popular transcoding profiles and it is much easier for a non-programmer engineer to work with it than with the SDK. How software transcoders with hardware acceleration work, we will describe in the next part.
( Continued should ...)