Storage for HPC infrastructure, or How we collected 65 PB of storage at the Japanese research center RIKEN

datacenterknowledge.com
Last year, the largest current installation of RAIDIX-based storage systems was implemented. A system of 11 fault-tolerant clusters was deployed at the Center for Computational Sciences of the RIKEN Institute (Japan). The main purpose of the system is the storage for the HPC infrastructure (HPCI), which is implemented as part of a large-scale national project for the exchange of academic information Academic Cloud (based on the SINET network).
A landmark feature of this project is its total volume - 65 PB, of which the useful volume of the system is 51.4 PB. To more accurately understand this value, we add that this is 6512 disks of 10 TB each (the most modern at the time of installation). It's a lot.
Work on the project went on for a year, after that the monitoring of the system’s operation continued for about a year. The obtained indicators met the stated requirements, and now we can talk about the success of this record and significant project for us.
Supercomputer at the Center for Computational Sciences of the RIKEN Institute
For ICT, the RIKEN institute is known primarily for its legendary “K-computer” (from Japanese “kei”, which means 10 quadrillion), which at the time of launch (June 2011) was considered the most productive supercomputer in the world.
Read about K-computer
The supercomputer helps the Center for Computational Sciences in the implementation of the most complex large-scale studies: it allows for modeling climate, weather conditions and molecular behavior, calculating and analyzing reactions in nuclear physics, predicting earthquakes and much more. Supercomputer powers are also used for more “everyday” and applied research — to search for oil fields and predict trends in stock markets.
Similar calculations and experiments generate a huge amount of data, the value and significance of which cannot be overestimated. To extract the maximum benefit from this, Japanese scientists developed the concept of a single information space in which HPC professionals from different research centers will have access to the HPC resources obtained.
High Performance Computing Infrastructure (HPCI)
HPCI operates on the basis of SINET (The Science Information Network) - a backbone network for the exchange of scientific data between Japanese universities and research centers. Currently, SINET brings together about 850 institutes and universities, creating tremendous opportunities for information exchange in research that affects nuclear physics, astronomy, geodesy, seismology and computer science.
HPCI is a unique infrastructure project that forms a unified system for exchanging information in the field of high-performance computing between universities and research centers in Japan.
By combining the capabilities of the “K” supercomputer and other scientific centers in an accessible form, the scientific community receives obvious benefits for working with valuable data generated by supercomputer computing.
In order to ensure efficient user sharing of the HPCI environment, the storage facility was subject to high speed access requirements. And thanks to the “hyper-productivity” of the K-computer, the storage cluster at the Center for Computational Sciences of the RIKEN Institute was calculated to be created with a working volume of at least 50 PB.
The HPCI project infrastructure was built on the basis of the Gfarm file system, which made it possible to provide a high level of performance and integrate disparate storage clusters into a single space for sharing.
Gfarm file system
Gfarm is an open source distributed file system developed by Japanese engineers. Gfarm is the fruit of the development of the Institute of Advanced Industrial Science and Technology (AIST), and the name of the system refers to the used architecture of Grid Data Farm.
This file system combines a number of seemingly incompatible properties:
- Highly scalable in size and performance
- Distribution of the network over long distances with the support of a single namespace for several separated research centers
- POSIX API support
- High level of performance required for parallel computing
- Secure data storage
Gfarm creates a virtual file system using multiple server storage resources. The data is distributed by the metadata server, and the distribution scheme itself is hidden from users. I must say that Gfarm consists not only of a storage cluster, but also a compute grid using the resources of the same servers. The principle of operation of the system resembles Hadoop: the submitted work is “lowered” to the node where the data lies.
The file system architecture is asymmetric. Explicit roles: Storage Server, Metadata Server, Client. But at the same time, all three roles can be performed by the same machine. Storage servers store multiple copies of files, and metadata servers operate in master-slave mode.
Project work
Core Micro Systems, a strategic partner and exclusive RAIDIX supplier in Japan, was responsible for implementation at the RIKEN Institute's Computational Science Center. The project took about 12 months of hard work, in which not only Core Micro Systems employees, but also technical specialists of the Radiks team took an active part.
At the same time, the transition to another storage system looked unlikely: the existing system had a lot of technical bindings that complicated the transition to any new brand.
In the course of long-term tests, checks and improvements, RAIDIX demonstrated consistently high performance and efficiency when working with such impressive amounts of data.
About the improvements should tell a little more. It was necessary not only to create the integration of storage systems with the Gfarm file system, but also to expand some functional characteristics of the software. For example, in order to meet the established technical requirements, it was necessary to develop and implement Automatic Write-Through technology in the shortest possible time.
The deployment itself took place systematically. Engineers from Core Micro Systems carefully and accurately conducted each stage of the test, gradually increasing the scale of the system.
In August 2017, the first deployment phase was completed, when the volume of the system reached 18 PB. In October of the same year, the second phase was implemented, at which the volume rose to a record 51 PB.
Solution Architecture
The solution was created based on the integration of RAIDIX storage systems and the Gfarm distributed file system. In conjunction with Gfarm, create scalable storage using 11 dual-controller RAIDIX systems.
Connection to Gfarm servers is via 8 x SAS 12G.
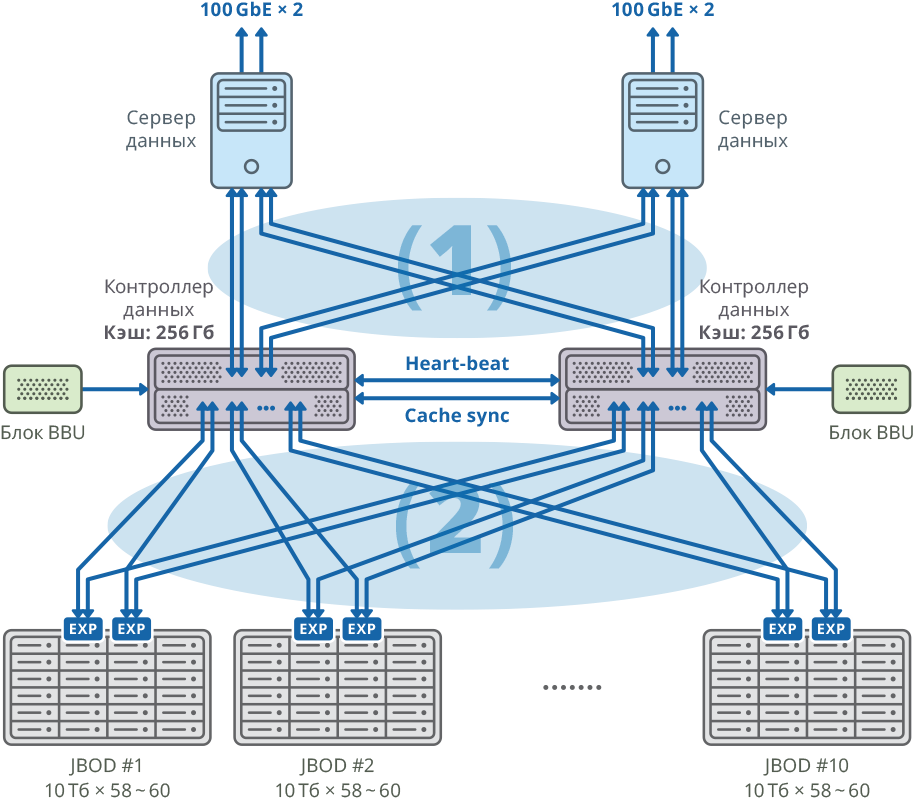
Fig. 1. Image of a cluster with a separate data server for each node
(1) 48Gbps × 8 connections SAN Mesh connection; bandwidth: 384Gbps
(2) 48Gbps × 40 Mesh FABRIC connections; bandwidth: 1920Gbps
Configuration of dual-controller platform
| CPU | Intel Xeon E5-2637 - 4pcs |
| Motherboard | Compatible with processor model with support for PCI Express 3.0 x8 / x16 |
| Internal cache | 256 GB for each node |
| Chassis | 2U |
| SAS controllers for connecting disk shelves, servers and write cache synchronization | Broadcom 9305 16e, 9300 8e |
| HDD | HGST Helium 10TB SAS HDD |
| HeartBeat sync | Ethernet 1 GbE |
| CacheSync sync | 6 x SAS 12G |
Both nodes of the failover cluster are connected to 10 JBODs (60 disks of 10TB each) through 20 SAS 12G ports for each node. On these disk shelves 58 RAID6 arrays of 10TB each were created (8 data disks (D) + 2 parity disks (P)) and 12 disks were allocated for “hot swap”.
10 JBOD => 58 × RAID6 (8 data discs (D) + 2 parity disks (P)), LUN of 580 HDD + 12 HDD for “hot swap” (2.06% of the total)
592 HDD (10TB SAS / 7.2k HDD) per cluster * HDD: HGST (MTBF: 2 500 000 hours)
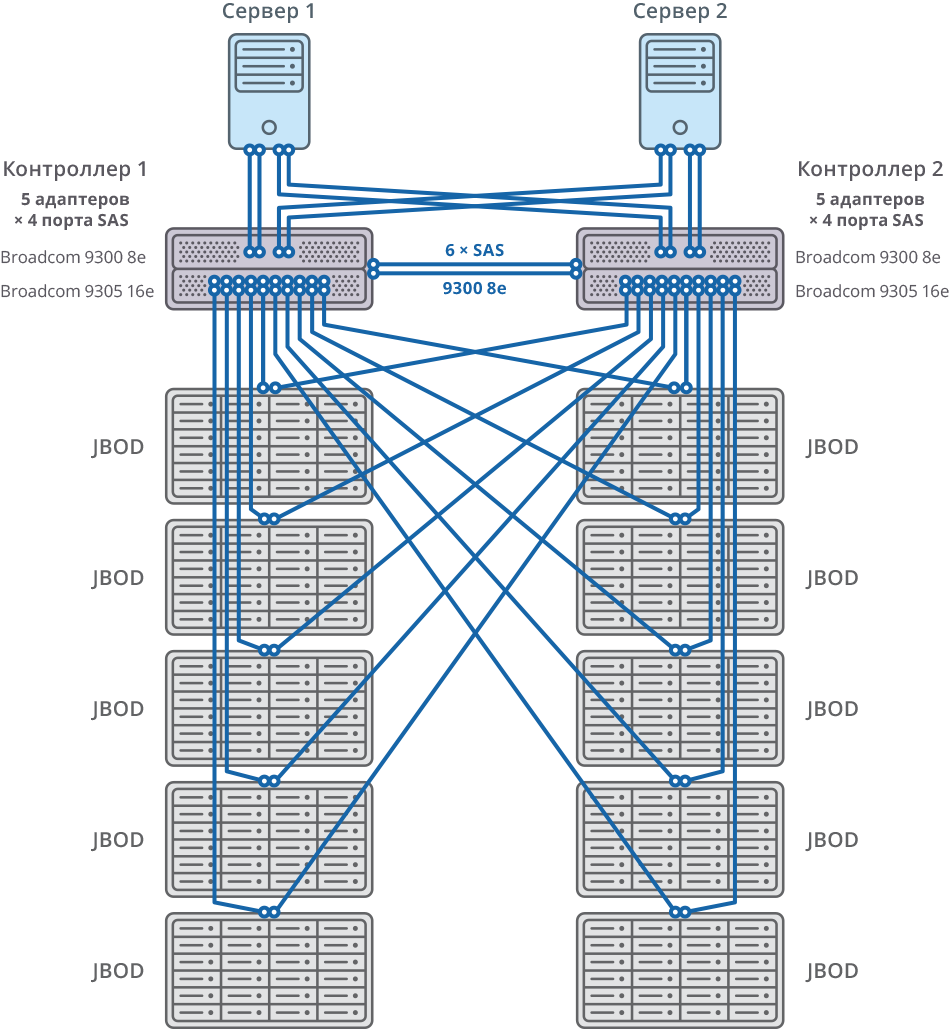
Fig. 2. Failover Cluster with 10 JBOD Connection Diagrams
General scheme of the system and connections
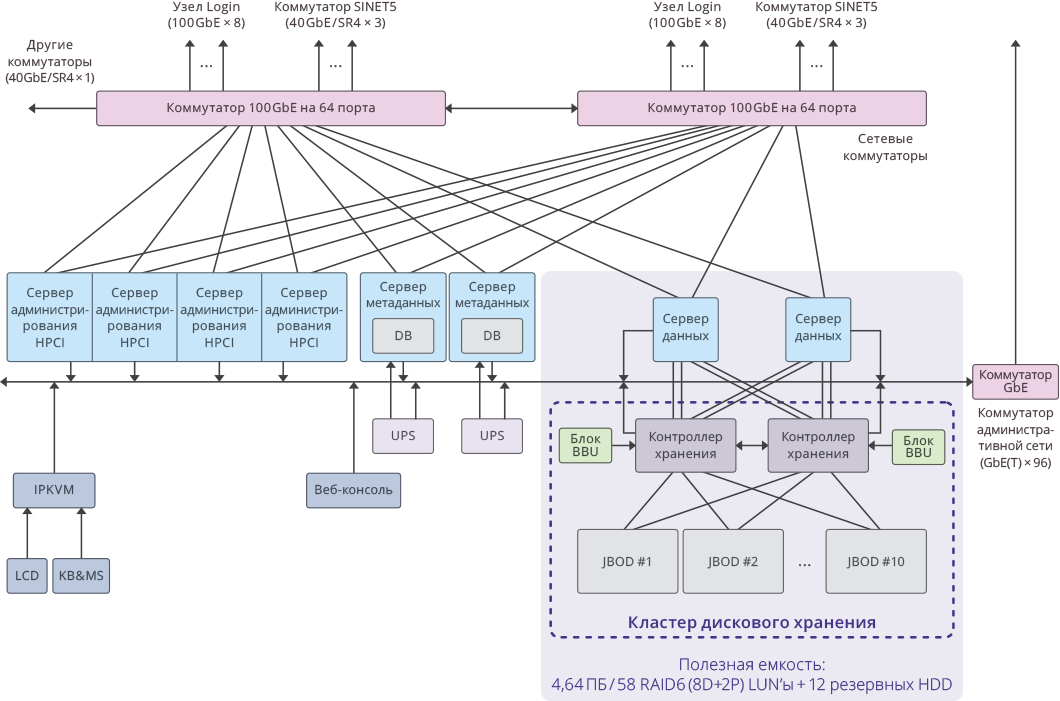
Fig. 3. Image of a single cluster within the HPCI system
Key project indicators
Net capacity per cluster: 4.64 PB ((RAID6 / 8D + 2P) LUN × 58)
Total effective capacity of the entire system: 51.04 PB (4.64 PB × 11 clusters).
Total system capacity: 65 PB .
The system performance was: 17 GB / s for writing, 22 GB / s for reading.
The total performance of the cluster disk subsystem on 11 RAIDIX storage systems: 250 GB / s .