Postgresql monitoring: queries
 In 2008, a discussion began on the pgsql-hackers mailing list on the expansion of query statistics. Starting with version 8.4, the pg_stat_statements extension is part of the postgres and allows you to get various statistics about requests that the server processes.
In 2008, a discussion began on the pgsql-hackers mailing list on the expansion of query statistics. Starting with version 8.4, the pg_stat_statements extension is part of the postgres and allows you to get various statistics about requests that the server processes.
Typically, this extension is used by database administrators as a data source for reports (this data is actually the sum of the indicators since the counters were reset). But based on these statistics, you can monitor requests - look at the statistics over time. This is extremely useful for finding the causes of various problems and in general for understanding what is happening on the database server.
I’ll tell you what metrics on requests our agent collects, how we group them, visualize them, I’ll also tell you about some rakes we went through.
pg_stat_statements
So, what do we have in view pg_stat_statements (my example from 9.4):
postgres=# \d pg_stat_statements;
View"public.pg_stat_statements"Column | Type | Modifiers
---------------------+------------------+-----------
userid | oid |
dbid | oid |
queryid | bigint |
query | text |
calls | bigint |
total_time | double precision |
rows | bigint |
shared_blks_hit | bigint |
shared_blks_read | bigint |
shared_blks_dirtied | bigint |
shared_blks_written | bigint |
local_blks_hit | bigint |
local_blks_read | bigint |
local_blks_dirtied | bigint |
local_blks_written | bigint |
temp_blks_read | bigint |
temp_blks_written | bigint |
blk_read_time | double precision |
blk_write_time | double precision |Here, all requests are grouped, that is, we do not get statistics for each request, but for a group of requests that are identical in terms of pg (I will tell you more about this). All counters grow from the moment of start or from the moment of reset of counters (pg_stat_statements_reset).
- query - query text
- calls - the number of request calls
- total_time - the sum of the query execution times in milliseconds
- rows - the number of rows returned (select) or modified during the request (update)
- shared_blks_hit - the number of shared memory blocks received from the cache
shared_blks_read - the number of shared memory blocks read not from the cache
In the documentation, it is not obvious whether this is the total number of blocks read or only what was not found in the cache, we check by the code/* * lookup the buffer. IO_IN_PROGRESS issetif the requested block is * not currently in memory. */ bufHdr = BufferAlloc(smgr, relpersistence, forkNum, blockNum, strategy, &found); if (found) pgBufferUsage.shared_blks_hit++; else pgBufferUsage.shared_blks_read++;- shared_blks_dirtied - the number of shared memory blocks marked as "dirty" during the request (the request changed at least one tuple in the block and this block must be written to disk, this is done either by checkpointer or bgwriter)
- shared_blks_written - the number of shared memory blocks written to disk synchronously during request processing. Postgres tries to write a block synchronously if it has already returned "dirty . "
- local_blks - similar counters for backend-local blocks, used for temporary tables
- temp_blks_read - the number of temporary file blocks read from disk.
Temporary files are used to process the request when there is not enough memory limited by the setting work_mem - temp_blks_written - the number of temporary file blocks written to disk
- blk_read_time - the amount of time to wait for reading blocks in milliseconds
- blk_write_time - the amount of time to wait for writing blocks to disk in milliseconds (only synchronous recording is taken into account, the time spent by checkpointer / bgwriter is not taken into account here)
blk_read_time and blk_write_time are only collected when track_io_timing is enabled .
Separately, it is worth noting that only completed requests get into pg_stat_statements. That is, if you have some kind of request for an hour doing something heavy and still have not finished, it will only be visible in pg_stat_activity .
How queries are grouped
For a long time I thought that requests are grouped according to a real execution plan. The only embarrassment was that requests with a different number of arguments in IN are displayed separately, the plan should be the same for them.
The code shows that in fact the hash is taken from the "significant" parts of the request after parsing. Starting from 9.4 it is displayed in the queryid column .
In practice, we have to additionally normalize and group requests already in the agent. For example, a different number of arguments in IN we collapse into one placeholder "(?)". Or the arguments that arrived in pg inline into the request, we ourselves replace with placeholders. The task is complicated by the fact that the request text may not be complete.
Until 9.4, the query text is trimmed to track_activity_query_size , since 9.4 the query text is stored outside of shared memory and the restriction is removed, but in any case, we trim the request to 8Kb, because if the query contains very heavy lines, requests from the agent significantly load the postgres.
Because of this, we cannot parse the query with the SQL parser for additional normalization; instead, we had to write a set of regular expressions for additional cleaning of the queries. This is not a very good solution, because you constantly have to add new scenarios, but nothing better has been invented so far.
Another problem is that in the query field postgres records the first incoming request in the group before normalization while maintaining the original formatting, and if the counters are reset, the request may be different for the same group. Still very often, developers use comments in queries, for example, to indicate the name of the function that pulls this query or the user query ID), they are also stored in query .
In order not to produce new metrics for the same queries each time, we cut out comments and extra whitespace characters.
Formulation of the problem
We did postgres monitoring with the help of our friends from postgresql consulting . They suggested that the most useful thing in finding problems with the database, which metrics are not particularly useful and advised on the internals of postgresql.
As a result, we want to receive answers from monitoring to the following questions:
- how the database now works as a whole compared to another period
- what requests load the server (cpu, disks)
- what requests how many
- what are the execution times of different requests
Collecting metrics
In fact, pouring counters for all monitoring requests is quite expensive. We decided that we are only interested in TOP-50 queries, but you can’t just get top by total_time, because if we have a new query, its total_time will catch up with the old queries for a long time to come.
We decided to take top on the derivative (rate) total_time per minute. To do this, once a minute, the agent reads the entire pg_stat_statements and stores the previous counter values. Rate is calculated for each counter of each request, then we try to additionally combine the same requests, which pg considered different, their statistics are summarized. Next we take top, we make separate metrics from them, summarize the remaining queries into a certain query = "~ other".
As a result, we get 11 metrics for each request from the top. Each metric has a set of refinement parameters (labels):
{"database": "<db>", "user": "<user>", "query": "<query>"}- postgresql.query.time.cpu (we just subtracted disk latencies from total_time for convenience)
- postgresql.query.time.disk_read
- postgresql.query.time.disk_write
- postgresql.query.calls
- postgresql.query.rows
- postgresql.query.blocks.hit
- postgresql.query.blocks.read
- postgresql.query.blocks.written
- postgresql.query.blocks.dirtied
- postgresql.query.temp_blocks.read
- postgresql.query.temp_blocks.written
Interpreting Metrics
Very often, users have questions about the physical meaning of the metrics "postgresql.query.time. *". Indeed, it is not very clear what the sum of the response times shows, but such metrics usually show the ratio of some processes to each other well.
But if we agree not to take into account the locks, we can very roughly assume that during the whole time the request is processed, the postgres utilizes some kind of resource (processor or disk). Such metrics have a dimension: the number of spent resource seconds per second. You can also bring this to percent utilization by querying the processor core, if multiplied by 100%.
We look what happened
Before relying on metrics, you need to check if they show the truth. For example, let's try to figure out what causes an increase in the number of write operations on the database server:
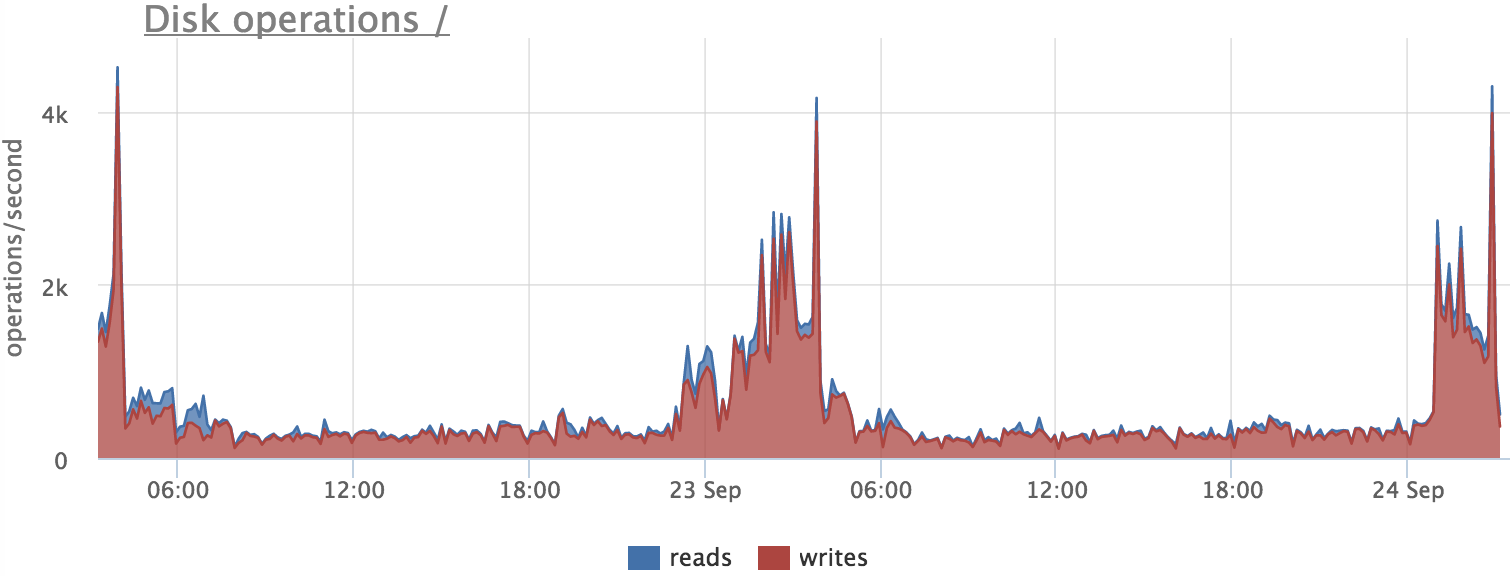
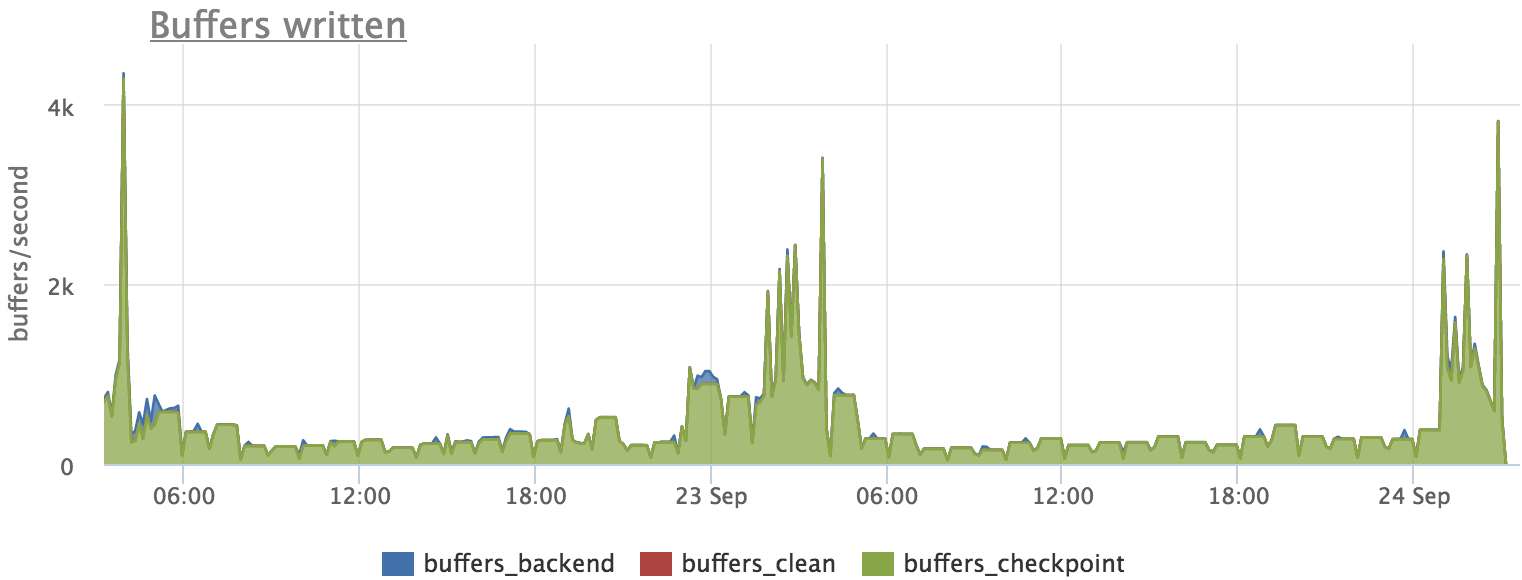
See if postgres wrote to disk at this time:
Next, we find out what queries "dirty" the page:
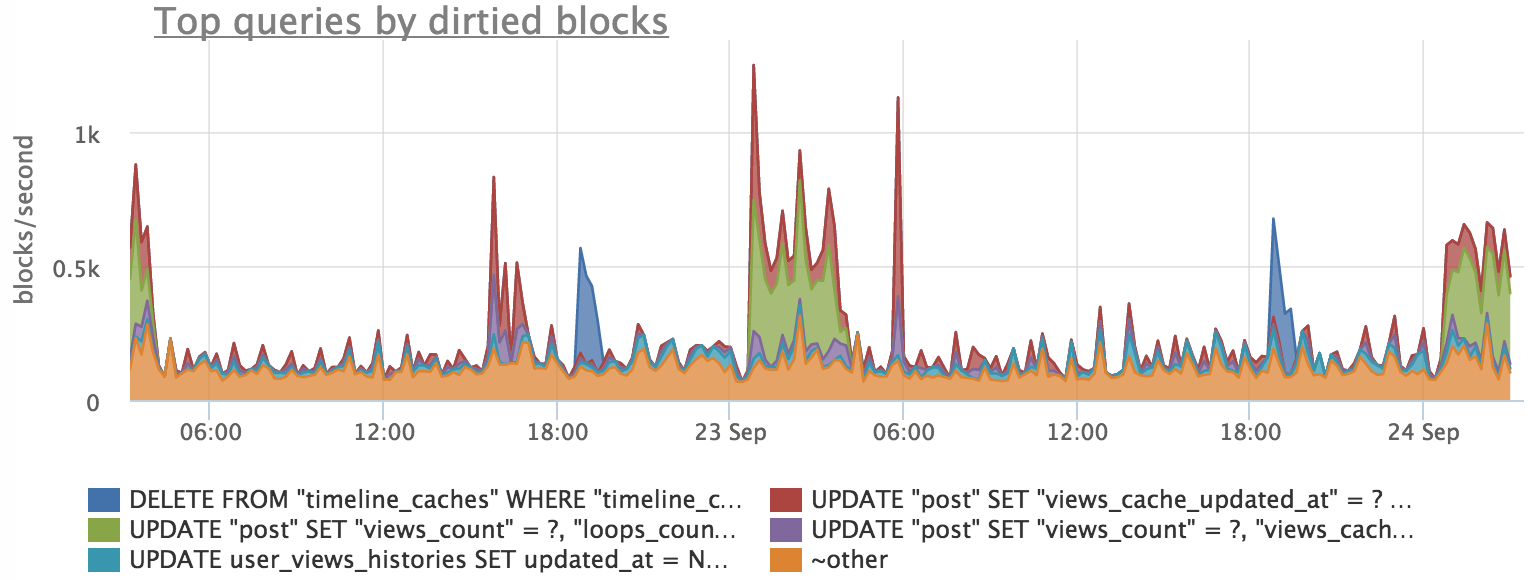
We see that there is an approximate coincidence, but the schedule for requests does not exactly repeat the schedule for flushing buffers. This is due to the fact that the process of writing blocks occurs in the background and the profile of the load on the disk changes slightly.
Now let's see what picture we got with reading:
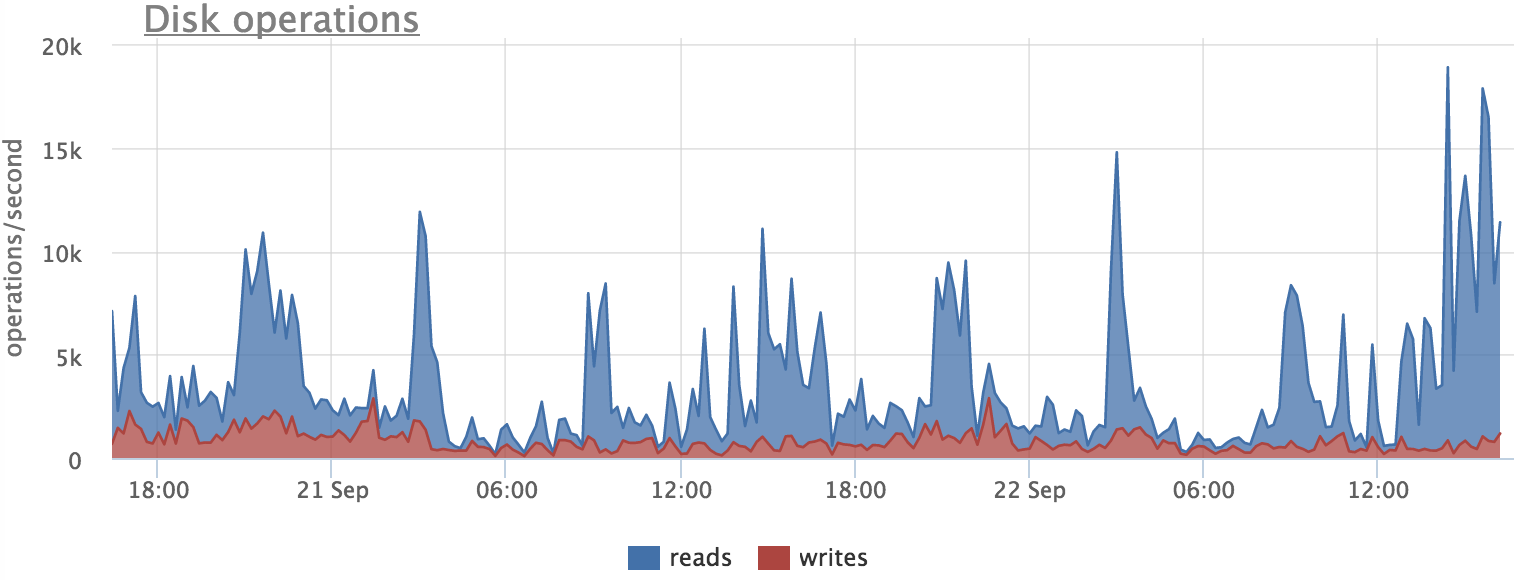
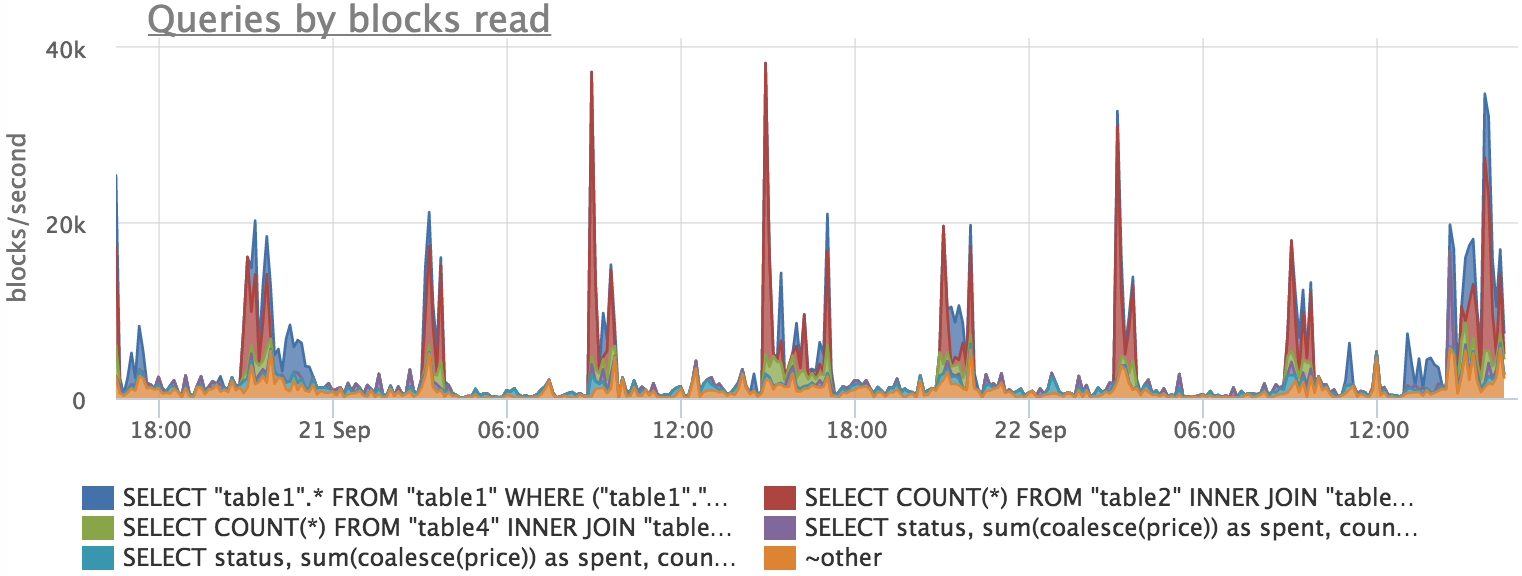
Here we also see that there is a correlation, but there is no exact match. This can be explained by the fact that postgres does not read blocks from the disk directly, but through the file system cache. Thus, we do not see part of the load on the disk, as part of the blocks are read from the cache.
CPU utilization can also be explained by specific requests, but absolute accuracy cannot be expected, since there are expectations of various locks, etc.
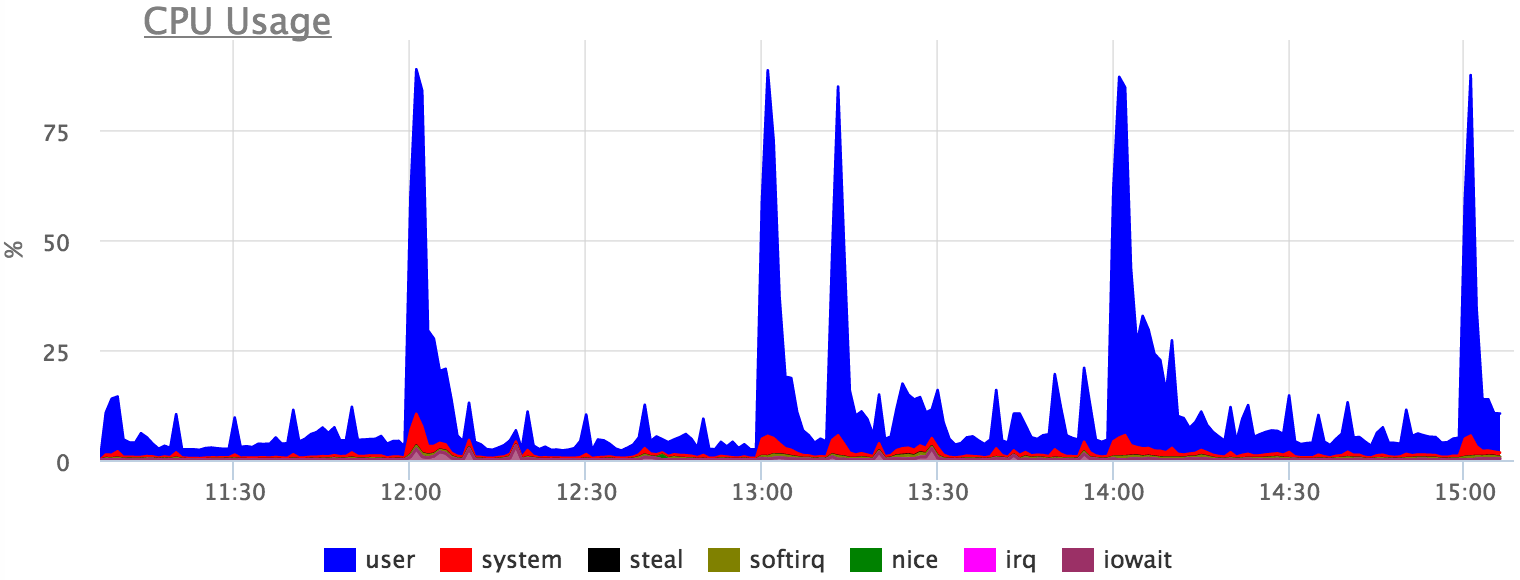
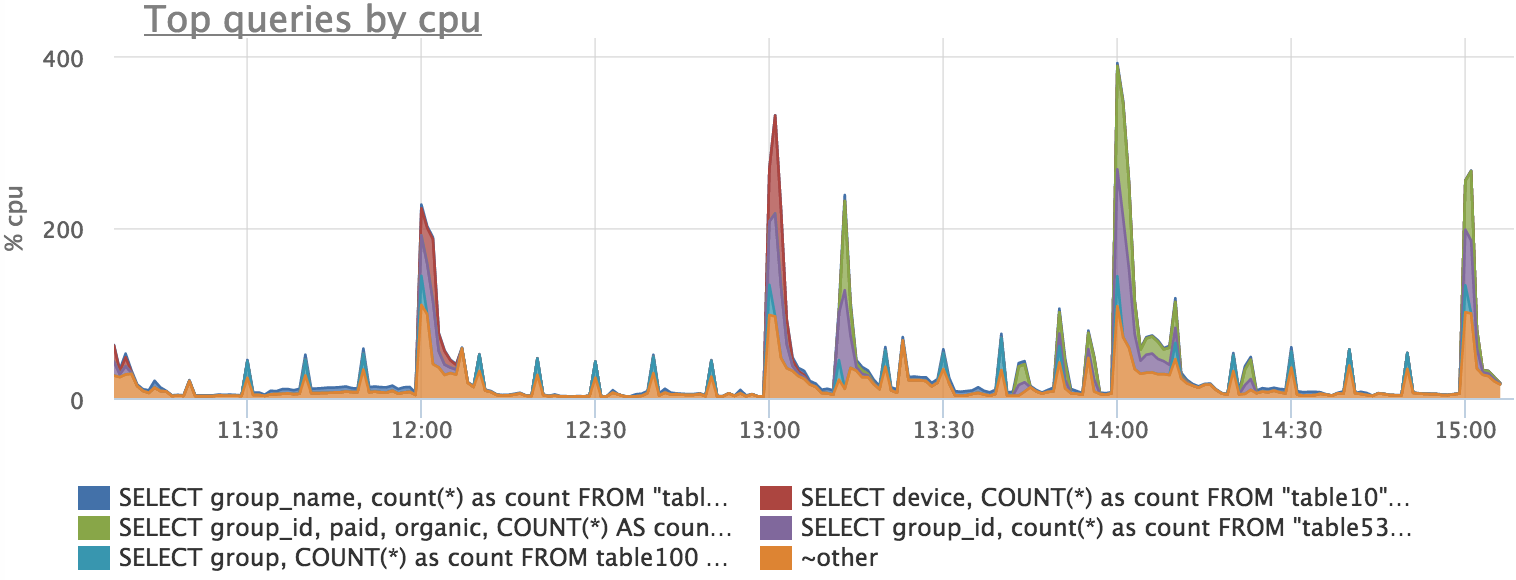
Total
- pg_stat_statements is a very cool thing that gives detailed statistics, but does not kill the server
- there are a number of assumptions and inaccuracies, they need to be understood for the correct interpretation of metrics
Our demo booth has an example of metrics on request, but the load there is not very interesting and it is better to see it on your metrics (we have a free, non-binding two-week trial)