We learn a pig on monoids to believe in yourself and fly
- Tutorial
In one of the previous articles, I talked about how to build a program executor for a virtual stack machine using the approaches of functional and language-oriented programming. The mathematical structure of the language suggested the basic structure for the implementation of its translator, based on the concept of semigroups and monoids. This approach allowed us to build a beautiful and expandable implementation and thwart the applause, but the very first question from the audience made me get off the podium and climb into Emacs again.

I spent a simple test and made sure that on simple tasks using only the stack, the virtual machine works smartly, and when using the “memory” - an array with random access - big problems start. How we managed to solve them without changing the basic principles of the program architecture and achieve a thousand-fold acceleration of the program’s work, and the article will be discussed.

Haskell is a peculiar language with a special niche. The main purpose of its creation and development was the need for lingua franca to express and test the ideas of functional programming. This justifies its brightest features: laziness, utmost purity, emphasis on types and manipulations with them. It was not designed for everyday development, not for industrial programming, not for widespread use. The fact that it is really used to create large-scale projects in the network industry and in data processing is the goodwill of developers, proof of concept, if you will. But so far, the most important, widely used and amazingly powerful product written in Haskell is ... the ghc compiler. And it is completely justified in terms of its purpose - to be a tool for research in the field of computer science. The principle proclaimed by Simon Peyton-Johnson: "Avoid success at all costs" requires the language in order to remain such an instrument. Haskell is similar to a sterile chamber in the laboratory of a research center that develops semiconductor technology or nanomaterials. It is terribly inconvenient to work in, and for everyday practice it too restricts freedom of action, but without these inconveniences, without uncompromising adherence to restrictions, it will not be possible to observe and study the subtle effects that will later become the basis of industrial development. At the same time, in industry, sterility will already be needed only in the most necessary volume, and the results of these experiments will appear in our pockets in the form of gadgets. We study stars and galaxies not because we expect to receive direct benefits from them, but because on the scale of these impractical objects, quantum and relativistic effects become observable and studied, so much so that later we can use this knowledge to develop something very utilitarian. So Haskell with its "wrong" lines, impractical laziness of calculations, the rigidity of some type inference algorithms, with an extremely steep entry curve, finally, does not allow you to easily create a smart application on your knee or an operating system. However, from this laboratory came into the practical world of lenses, monads, combinatorial parsing, wide use of monoids, methods of automatic proof of theorems, declarative functional package managers, on the way linear and dependent types. It finds application in less sterile conditions in the languages of Python, Scala, Kotlin, F #, Rust, and many others. But I wouldn’t use any of these wonderful languages to teach the principles of functional programming: I would take a student to the lab, show with bright and clean examples how it works, and then you can “see” these principles in action in the factory big and incomprehensible, but very fast machine. Avoiding success at any cost is protection against attempts to shove a coffee maker into an electron microscope in order to popularize it. And in competitions which language is cooler, Haskell will always be outside the usual nominations. Kotlin, F #, Rust and many others. But I wouldn’t use any of these wonderful languages to teach the principles of functional programming: I would take a student to the lab, show with bright and clean examples how it works, and then you can “see” these principles in action in the factory big and incomprehensible, but very fast machine. Avoiding success at any cost is protection against attempts to shove a coffee maker into an electron microscope in order to popularize it. And in competitions which language is cooler, Haskell will always be outside the usual nominations. Kotlin, F #, Rust and many others. But I wouldn’t use any of these wonderful languages to teach the principles of functional programming: I would take a student to the lab, show with bright and clean examples how it works, and then you can “see” these principles in action in the factory big and incomprehensible, but very fast machine. Avoiding success at any cost is protection against attempts to shove a coffee maker into an electron microscope in order to popularize it. And in competitions which language is cooler, Haskell will always be outside the usual nominations.
However, the person is weak, and a demon lives in me too, which urges me to compare, evaluate and protect “my favorite language” in front of others. So, having written an elegant implementation of a stack machine based on a monoidal composition, with the sole purpose of seeing whether this is my idea, I was immediately disappointed to find that the implementation works brilliantly, but terribly inefficient! It’s as if I’m really going to use it for serious tasks, or to sell my stack machine on the same market where Python or Java virtual machines are offered. But, damn it, in the article about the pig with which the whole conversation began, such tasty figures are given: hundreds of milliseconds for the piglet, seconds for Python ... and my beautiful monoid cannot do this task in an hour! I have to succeed! My microscope will make an espresso no worse than a coffee machine in the hallway of the institute! The Crystal Palace can be accelerated and launched into space!
But what are you ready to sacrifice, the mathematician asks me? Clean and transparent palace architecture? The flexibility and extensibility that homomorphisms provide from programs to other solutions? The demon and the angel are both stubborn, and the wise Taoist, whom I also allow myself to live with, offered to take the path that suits both, and walk along it as long as possible. However, not with the aim of identifying the winner, but in order to know the path itself, find out how far it leads, and get a new experience. And so I came to know the vain sadness and joy of optimization.
Before we begin, let's add that language comparisons in terms of effectiveness are meaningless. It is necessary to compare translators (interpreters or compilers), or the performance of a programmer using a language. In the end, the statement that C programs are the fastest is easy to refute by writing a full-fledged C interpreter on BASIC, for example. So, we compare not Haskell and javascript, but the performance of programs executed by the compiler, compiled ghcand programs executed, say, in a particular browser. All swine terminology comes from an inspirational article about stack machines. All Haskell code accompanying the article can be explored in the repository .
We leave from the comfort zone
The starting point will be the implementation of a monoidal stack machine in the form of EDSL - a small simple language that allows combining two dozen primitives to build programs for a virtual stack machine. Once he got into the second article, give him a name monopig. It is based on the fact that languages for stack machines form a monoidwith a concatenation operation and an empty operation as a unit. Accordingly, he himself is built in the form of a monoid transformation of the state of the machine. The state includes the stack, vector memory (a structure that provides random access to the elements), an emergency stop flag, and a monoid battery for accumulating debug information. This whole structure is transmitted along the chain of endomorphisms from operation to operation, carrying out the computational process. From the structure, which form the program was built isomorphic structure codesprograms, and from it homomorphisms into other useful structures representing the requirements for the program in terms of the number of arguments and memory. The final stage of construction was the creation of transformation monoids in the Kleisley category, which allow you to load the calculations into an arbitrary monad. So the machine has the possibility of input-output and ambiguous calculations. With this implementation we will begin. Its code can be found here .
We will test the effectiveness of the program on the naive implementation of the sieve of Eratosthenes, which fills the memory (array) with zeros and ones, denoting primes by zero. The procedural code of the algorithm is given in the language javascript:
var memSize = 65536;
var arr = [];
for (var i = 0; i < memSize; i++)
arr.push(0);
functionsieve()
{
var n = 2;
while (n*n < memSize)
{
if (!arr[n])
{
var k = n;
while (k < memSize)
{
k+=n;
arr[k] = 1;
}
}
n++;
}
}The algorithm is immediately optimized. There is no bad striding around already filled memory cells. My mathematician angel did not agree to a really naive version of the example in the project PorosenokVM, since this optimization costs only five stack-language instructions. Here is how the algorithm translates into monopig:
sieve = push 2 <>
while (dup <> dup <> mul <> push memSize <> lt)
(dup <> get <> branch mempty fill <> inc) <>
pop
fill = dup <> dup <> add <>
while (dup <> push memSize <> lt)
(dup <> push 1 <> swap <> put <> exch <> add) <>
popBut how can you write the equivalent implementation of this algorithm on the idiomatic Haskell, using the same types as in monopig:
sieve' :: Int -> VectorInt -> VectorIntsieve' k m
| k*k < memSize =
sieve' (k+1) $ if m ! k == 0then fill' k (2*k) m else m
| otherwise = m
fill' :: Int -> Int -> VectorInt -> VectorIntfill' k n m
| n < memSize = fill' k (n+k) $ m // [(n,1)]
| otherwise = mIt uses the type Data.Vectorand tools for working with it, not too ordinary for everyday work in Haskell. The expression m ! kreturns the kfirst element of the vector m, and m // [(n,1)]sets the element with the number nto 1. I am writing this here because I had to go after them in the certificate, moreover, that I work at Haskell almost every day. The fact is that structures with random access in the functional implementation are inefficient and for this reason are not popular.
According to the competition conditions given in the article about the pig, the algorithm is run 100 times. And in order to get rid of a specific computer, let's compare the speeds of these three programs, attributing them to the performance of the program on javascriptChrome.
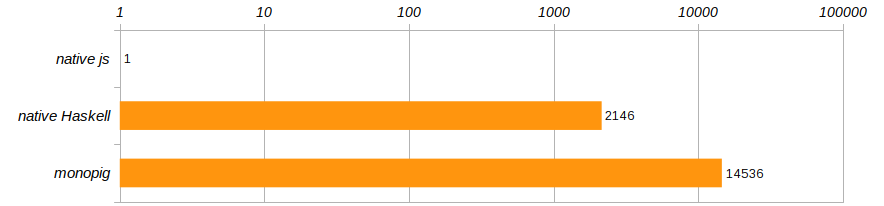
Horror-horror !!! Not only does it monopigslow down hopelessly, the native version isn't much better either! Haskell, of course, is cool, but not enough to give in to a program running in a browser ?! As coaches teach us, you can't live like this anymore, it's time to leave the comfort zone that Haskell provides us with!
Overcome laziness
Let's figure it out. To do this, we compile a program monopigwith a flag -rtsoptsto keep track of runtime statistics and see what we should do to get rid of the Eratosthenes sieve once:
$ ghc -O -rtsopts ./Monopig4.hs
[1 of 1] Compiling Main ( Monopig4.hs, Monopig4.o )
Linking Monopig4 ...
$ ./Monopig4 -RTS -sstderr
"Ok"
68,243,040,608 bytes allocated in the heap
6,471,530,040 bytes copied during GC
2,950,952 bytes maximum residency (30667 sample(s))
42,264 bytes maximum slop
15 MB total memory in use (7 MB lost due to fragmentation)
Tot time (elapsed) Avg pause Max pause
Gen 0 99408 colls, 0 par 2.758s 2.718s 0.0000s 0.0015s
Gen 1 30667 colls, 0 par 57.654s 57.777s 0.0019s 0.0133s
INIT time 0.000s ( 0.000s elapsed)
MUT time 29.008s ( 29.111s elapsed)
GC time 60.411s ( 60.495s elapsed) <-- утечка времени здесь!
EXIT time 0.000s ( 0.000s elapsed)
Total time 89.423s ( 89.607s elapsed)
%GC time 67.6% (67.5% elapsed)
Alloc rate 2,352,591,525 bytes per MUT second
Productivity 32.4% of total user, 32.4% of total elapsedThe last line tells us that the program was engaged in productive computing only a third of the time. All the rest of the time, the garbage collector ran from memory and cleaned up after lazy calculations. How many times have we been repeated in childhood that it is not good to be lazy! Here, the main feature of Haskell has done us a disservice in trying to create several billion deferred vector and stack transformations.
A mathematician angel raises his finger in this place and happily talks about the fact that since Alonzo Church, there is a theorem stating that the computing strategy does not affect their result, which means that we are free to choose from efficiency considerations. It is quite simple to change calculations to strict ones - we put a mark !in the declaration of the type of stack and memory, and thereby make these fields strict.
dataVM a = VM { stack :: !Stack
, status :: MaybeString
, memory :: !Memory
, journal :: !a }We will not change anything else and immediately check the result:
$ ./Monopig41 +RTS -sstderr
"Ok"
68,244,819,008 bytes allocated in the heap
7,386,896 bytes copied during GC
528,088 bytes maximum residency (2 sample(s))
25,248 bytes maximum slop
16 MB total memory in use (14 MB lost due to fragmentation)
Tot time (elapsed) Avg pause Max pause
Gen 0 129923 colls, 0 par 0.666s 0.654s 0.0000s 0.0001s
Gen 1 2 colls, 0 par 0.001s 0.001s 0.0006s 0.0007s
INIT time 0.000s ( 0.000s elapsed)
MUT time 13.029s ( 13.048s elapsed)
GC time 0.667s ( 0.655s elapsed)
EXIT time 0.001s ( 0.001s elapsed)
Total time 13.700s ( 13.704s elapsed)
%GC time 4.9% (4.8% elapsed)
Alloc rate 5,238,049,412 bytes per MUT second
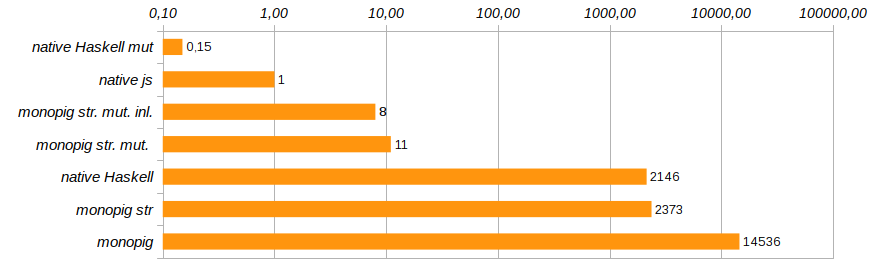
Productivity 95.1% of total user, 95.1% of total elapsedProductivity has increased significantly. The total memory costs are still impressive because of the immutability of the data, but most importantly, now that we have limited the laziness of the data, the garbage collector has the opportunity to be lazy, and only 5% of the total work remains. Record a new entry in the rating.

Well, well, rigorous calculations brought us closer in speed to the work of the Haskell native code, which shamefully slows down without any virtual machine. This means that the overhead of using an immutable vector substantially exceeds the cost of maintaining the stack machine. And that means it's time to say goodbye to the immutability of memory.
Letting changes in life
The type Data.Vectoris good, but using it, we spend a lot of time copying, in the name of preserving the purity of the computational process. Replacing it with the type Data.Vector.Unpackedwe at least save on the packaging structure, but this does not fundamentally change the picture. The right decision would be to remove the memory from the state of the machine and provide access to the external vector using the Kleisley category. In this case, along with pure vectors, you can use the so-called mutable (mutable) vectors Data.Vector.Mutable.
We will connect the appropriate modules and think about how we deal with variable data in a pure functional program.
import Control.Monad.Primitive
importqualified Data.Vector.Unboxed as V
importqualified Data.Vector.Unboxed.Mutable as MThese dirty types are supposed to be isolated from the public. They are contained in the monads of the class PrimMonad(they are referred to as STor IO), where clean programs neatly push the instructions to actions written in crystal functional language on precious parchment. Thus, the behavior of these unclean animals is determined by strictly orthodox scenarios and is not dangerous. Not all programs for our machine use memory, so IOthere is no need to condemn the whole architecture for immersion into the monad . Along with a pure subset of the language, monopigwe will create four instructions that provide access to the memory and only they will have access to the dangerous territory.
The type of clean machine becomes shorter:
dataVM a = VM { stack :: !Stack
, status :: MaybeString
, journal :: !a }The program designers and the programs themselves will hardly notice this change, but their types will change. In addition, it makes sense to define several types of synonyms to simplify signatures.
typeMemory m = M.MVector (PrimStatem) InttypeLogger m a = Memory m -> Code -> VM a -> m (VMa)typeProgram' m a = Logger m a -> Memory m -> Program m aConstructors will have another argument representing memory access. The executors will change significantly, especially those who are leading the journal of computations, because now they need to ask its state for changeable vector. The full code can be seen and studied in the repository, and here I will give the most interesting thing: the implementation of the basic components for working with memory to show how this is done.
geti :: PrimMonad m => Int -> Program' m a
geti i = programM (GETI i) $
\mem -> \s -> if (0 <= i && i < memSize)
then \vm -> do x <- M.unsafeRead mem i
setStack (x:s) vm
else err "index out of range"puti :: PrimMonad m => Int -> Program' m a
puti i = programM (PUTI i) $
\mem -> \case (x:s) -> if (0 <= i && i < memSize)
then \vm -> doM.unsafeWrite mem i x
setStack s vm
else err "index out of range"
_ -> err "expected an element"get :: PrimMonad m => Program' m a
get = programM (GET) $
\m -> \case (i:s) -> \vm -> do x <- M.read m i
setStack (x:s) vm
_ -> err "expected an element"put :: PrimMonad m => Program' m a
put = programM (PUT) $
\m -> \case (i:x:s) -> \vm -> M.write m i x >> setStack s vm
_ -> err "expected two elemets"The daemon optimizer suggested immediately saving a little more on checking the permissible values of the index in memory, for commands putiand getiindexes are known at the program creation stage and incorrect values can be eliminated in advance. Dynamically defined indices for teams putand getdo not guarantee security and the angel of mathematics did not allow them to carry out dangerous treatment.
All this fuss with memory deduction in a separate argument seems complicated. But it very clearly shows the changeable data of their place - they should be outside . I remind you that we are trying to take the pizza peddler to the sterile laboratory. Pure functions know what to do with them, but these objects will never become first-class citizens, and you should not make pizza directly in the laboratory.
Let's check what we bought with these changes:
$ ./Monopig5 +RTS -sstderr
"Ok"
9,169,192,928 bytes allocated in the heap
2,006,680 bytes copied during GC
529,608 bytes maximum residency (2 sample(s))
25,248 bytes maximum slop
2 MB total memory in use (0 MB lost due to fragmentation)
Tot time (elapsed) Avg pause Max pause
Gen 0 17693 colls, 0 par 0.094s 0.093s 0.0000s 0.0001s
Gen 1 2 colls, 0 par 0.000s 0.000s 0.0002s 0.0003s
INIT time 0.000s ( 0.000s elapsed)
MUT time 7.228s ( 7.232s elapsed)
GC time 0.094s ( 0.093s elapsed)
EXIT time 0.000s ( 0.000s elapsed)
Total time 7.325s ( 7.326s elapsed)
%GC time 1.3% (1.3% elapsed)
Alloc rate 1,268,570,828 bytes per MUT second
Productivity 98.7% of total user, 98.7% of total elapsedThis is progress! The memory usage was reduced eight times, the program execution speed increased 180 times, and the garbage collector was left almost completely out of work.

In the ranking appeared solution monopig st. mut. which jsis ten times slower than the native solution , but apart from it is the Haskell native solution using variable vectors. Here is his code:
fill' :: Int -> Int -> MemoryIO -> IO (MemoryIO)
fill' k n m
| n > memSize-k = return m
| otherwise = M.unsafeWrite m n 1 >> fill' k (n+k) m
sieve' :: Int -> MemoryIO -> IO (MemoryIO)
sieve' k m
| k*k < memSize =
do x <- M.unsafeRead m k
if x == 0then fill' k (2*k) m >>= sieve' (k+1)
else sieve' (k+1) m
| otherwise = return mIt runs as follows
main = do m <- M.replicate memSize 0
stimes 100 (sieve' 2 m >> return ())
print "Ok"And now Haskell finally shows that he is not a toy language. You just need to use it wisely. By the way, in the above code, the type is used to IO ()form a semigroup with the operation of sequential program execution (>>), and with the help stimeswe repeated 100 times the calculation of the test problem.
Now it’s clear why such a dislike for functional arrays occurs and why no one remembers how to work with them: as soon as a Haskell programmer seriously needs structures with random access, he reorients to changeable data and works in ST or IO monads.
Derivation of a part of the teams into a special zone calls into question the legitimacy of isomorphism code the program . After all, we cannot simultaneously convert code into pure and monadic programs, this is not allowed by the type system. However, the type classes are flexible enough for this isomorphism to exist. Homomorphism code
the program . After all, we cannot simultaneously convert code into pure and monadic programs, this is not allowed by the type system. However, the type classes are flexible enough for this isomorphism to exist. Homomorphism code the program is now divided into several homomorphisms for different subsets of the language. How exactly this is done can be seen in the full [code] () program.
the program is now divided into several homomorphisms for different subsets of the language. How exactly this is done can be seen in the full [code] () program.
Don't stop there
A little more to change the productivity of the program will help exclude unnecessary function calls and embed their code directly using the pragma {-# INLINE #-}. This method is not suitable for recursive functions, but it is great for basic components and setter functions. It reduces the execution time of the test program by another 25% (see Monopig51.hs ).
The next sensible step would be to get rid of logging tools when there is no need for them. At the stage of the formation of the endomorphism representing the program, we use an external argument, which is determined at launch. Smart designers programand programMyou can warn that the argument logger may not be. In this case, the converter code does not contain anything superfluous: only the functionality and checking the status of the machine.
program code f = programM code (const f)
programM code f (Just logger) mem = Program . ([code],) . ActionM $
\vm -> case status vm ofNothing -> logger mem code =<< f mem (stack vm) vm
_ -> return vm
programM code f _ mem = Program . ([code],) . ActionM $
\vm -> case status vm ofNothing -> f mem (stack vm) vm
_ -> return vmNow executing functions must explicitly indicate the presence or absence of logging, not using a stub none, but using the type Maybe (Logger m a). Why should this work, because whether there is logging or not, program components will be recognized "at the last moment", just before execution? Will not the unnecessary code be sewn at the stage of forming the composition of the programs? Haskell is a lazy language and here it plays into our hands. It is exactly before the execution that the final code is generated that is optimized for a specific task. This optimization has reduced the program execution time by another 40% (see Monopig52.hs ).
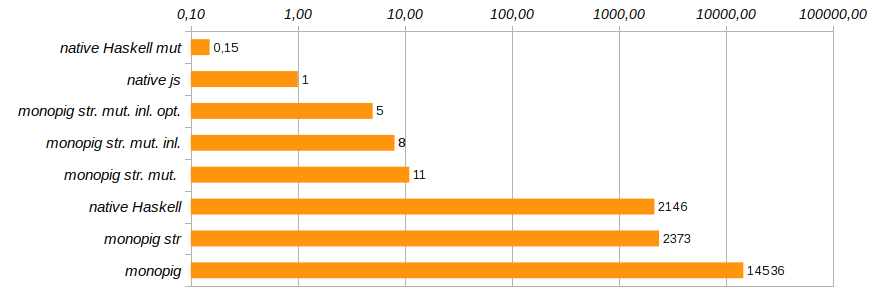
This concludes the work on the acceleration of the monoidal pig. He is already quite smartly worn, so that both the angel and the demon can calm down. This, of course, is not C, we still use a clean list as a stack, but replacing it with an array will lead to a thorough rewinding of the code, and refusing to use elegant templates in the definitions of basic commands. I also wanted to get by with minimal changes and, basically, at the level of types.
Some problems remain when logging. Simple counting the number of steps or using the stack works quite well (we made the journal field strict), but their pairing is already beginning to eat memory, you have to mess around with kicks with help seq, which is pretty annoying. But tell me, who will log the 14 billion steps, if you can debug the task on the first hundreds? So I will not waste my time on acceleration for the sake of acceleration.
It remains only to add that in the article about the piglet, as one of the methods for optimizing calculations, the following is given: selection of linear sections of code, traces , inside which calculations can be made bypassing the main command dispatch cycle (block switch). In our case, the monoidal composition of the program components creates such traces either during the formation of the program from the EDSL components or when the homomorphism is working fromCode. This method of optimization comes to us for free, so to speak, by construction.
There are many elegant and fast solutions in the Haskell ecosystem, such as streams Conduitsor Pipes, there are excellent replacements for the type Stringand nimble XML creators, such as blaze-html, and the parser attoparsecis a reference for combinatorial analysis for LL (∞) grammar. All this is necessary for normal operation. But even more necessary - research leading to these solutions. Haskell was and remains a research tool that meets specific requirements not needed by the general public. I saw in Kamchatka how the aces of a Mi-4 helicopter closed a box of matches onto the dispute, pushing the chassis wheel on it, hanging in the air. This can be done, and it is cool, but not necessary.
But, after all, it's cool !!