Kaggle - our excursion to the kingdom of overfit
- Tutorial
Kaggle is a platform for machine learning contests. On Habré often write about it: 1 , 2 , 3 , 4 , etc. Kaggle contests are interesting and practical. First places are usually accompanied by good prizes (top contests - more than $ 100k). Recently at Kaggle they offered to recognize:
And many many others.
I have long wanted to try, but something kept interfering all the time. I have developed many systems related to image processing: the topic is close. Skills lie more in the practical part and classical Computer Vision (CV) algorithms than in modern Machine Learning techniques, so it was interesting to evaluate your knowledge at the world level, plus to enhance understanding of convolution networks.
And suddenly everything turned out. A couple of weeks fell of a not-so-busy schedule. At kaggle there was an interesting competition on related topics. I updated my comp. And most importantly - knocked vasyutka and Nikkolo to make up the company.
I must say right away that we have not achieved enchanting results. But I consider 18th place out of 1.5 thousand participants not bad. And considering that this is our first experience of participating in kaggle, that of the 3 months of the competition, we participated only 2.5 weeks, that all the results were obtained on one single video card - it seems to me that we performed well.
What will this article be about? Firstly, about the problem itself and our method of solving it. Secondly, about the process of solving CV problems. I wrote a lot of articles on the computer science vision hub ( 1 , 2 , 3), but it is always better to back up the writings and theory with an example. And writing articles for some commercial task for obvious reasons is not possible. Now, finally, I will talk about the process. Moreover, here it is the most ordinary, well illustrating how tasks are solved. Thirdly, the article is about what goes after solving the idealized problem in a vacuum: what will happen when the task encounters reality.

The task we started doing was as follows: “Determine the driver’s affiliation in the photo to one of ten groups: neat driving, a phone in his right hand, a phone in his right ear, a phone in his left hand, a phone in his left ear, music tuning, drinking liquid ”, stretches back, correction of a hairdress (paints lips, scratches a nape), conversation with the neighbor". But, it seems to me, it is better to look at the examples once:
0 1
1  2
2 
3 4
4  5
5 
6 7
7  8
8 
9
**********************************************
Everything seems clear and obvious. But it is not so. What class do these two examples belong to?


The first example is grade 9, conversation. The second example is class zero, safe driving.
According to our estimation, the accuracy of a person in recognizing a class by base is about 94%. In this case, the first and tenth grades make the greatest confusion. At the beginning of our participation, the first places had an accuracy of about 97% of correct recognitions. Yes Yes! Robots are already better than humans!
A few details:
Today, convolutional neural networks are the main means for solving problems of such a plan. They analyze the image at many levels, independently identifying key features and their relationships. You can read about convolution networks here , here and here . Convolution networks have a number of disadvantages:
An alternative to convolutional networks may be manual management of low-level features. Highlight hands. Face position. Facial expression. Open / closed visor at the car.
There are a lot of different convolution networks. The classical approach - to use the most widespread network of "Zoo» ( caffe Theano keras ). This is primarily VGG16, VGG19, GoogleNet, ResNet. There are many variations for these networks, plus you can use learning acceleration techniques. Of course, this approach is used by all participants. But a basic good result can only be obtained on it.
All the calculations in our work took place on one single GTX1080. This is the latest game card from NVIDIA. Not the best option from what is on the market, but quite good.
We wanted to use a cluster with three Tesla in one of the works, but due to a number of technical difficulties, this did not work. We also considered the use of some old video card from a laptop on 4Gb, but as a result we decided not to follow this path, there was much less speed.
The framework used is Caffe . Keras could also be used with Theano, which would certainly improve our result due to a slightly different implementation of the training. But we did not have time for this, so it was Caffe that was used to the maximum.
RAM - 16Gb, maximum for training used 10Gb. The processor is the last i5.
I think that most of the readers have never participated in kaggle, so I will give a short excursion into what the rules of the competition are:
Suppose we come up with some kind of recognition engine and recognize all the images. How will they be further checked? In this problem, we used the approach of calculating multiclass logarithmic losses . In short, it can be written as:

y is the matrix of solutions. Unit if the object belongs to the class.
p - response matrix sent by the user. It’s best to record the probability of belonging to a class.
M-number of classes
N-number of objects
In a neighborhood of zero, the value is replaced by a constant.
We figured that a probability of “95%” corresponds to a logloss value of approximately “0.2”, a value of “0.1” corresponds to a probability of “97.5%”. But these are rough estimates.
We will return to this function, but somewhat lower.
The theory is good. But where to start? Let's start with the simplest: take the CaffeNet grid, which is attached to Caffe and for which there is an example.
After I did a similar action, I immediately got the result “0.7786”, which was somewhere in the 500th place. It's funny, but for many the result was much worse. At the same time, it is worth noting that 0.77 approximately corresponds to 80-85% of correct recognitions.
We will not dwell on this grid, which is already quite outdated. Take something standard modern. The following can be considered standard:
About non-standard methods can be read a little lower in the section "Ideas that did not work."
Since we started about two and a half months after the start of the competition, it made sense to explore the forum. The forum advised VGG-16. The author of the post claimed that he received a solution with a loss of "0.23" based on this network.
Consider the author’s decision :
We could not repeat the decision. However, many who did not succeed in doing this. Although the author posted a training script on Keras. Apparently on Keras it could be achieved, but not on caffe. The winner of the third place also considered VGG on Keras, and all other grids on Caffe and Theano.
For us, pure VGG gave 0.4, which, of course, improved our result at that time, but only places up to the 300th.
As a result, we decided to abandon VGG and tested the training of the pre-trained ResNet-50 ( here it is interesting to read what it is). Which immediately gave us 0.3-0.29.
A little remark: we never used the technique of “breaking the base into 8 parts”. Although, most likely, it would bring us a little extra accuracy. But such training would take several days, which was unacceptable to us.
Why is it necessary to split the base into 8 parts and train independent grids? Suppose the first of the grids is always mistaken in favor of situation A, when choosing from A and B. The second grid, on the contrary, makes decision B. Moreover, both grids are often mistaken regarding the real solution. But the sum of the grids will more correctly assess the risk of A / B. In fact, in most controversial situations it will deliver 50% - A, 50% - B. This approach minimizes our losses. We reached it differently.
To increase accuracy with 0.3, we did the following series of actions:
The image changes are as follows: during training, instead of the original training picture, a rotated picture, a cropped picture, a picture noisy, are fed in. This improves stability and improves accuracy.
The final result of adding all the listed grids was at the level of “0.23-0.22”.
The result of 0.22 was somewhere around 100 places. This is already a good result. In fact, the maximum that a correctly configured network gives. But to go further you need to stop, think and comprehend what has been done.
The easiest way to do this is to look at the “Confusion Matrix”. In essence, this concept hides a budget of errors. How and when we are wrong. Here is the matrix that we came up with:
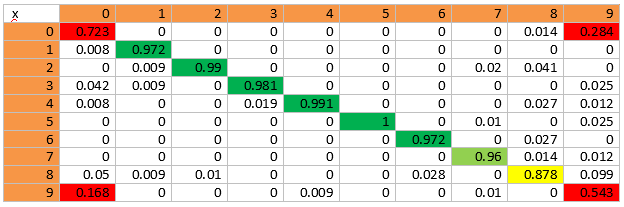
In this matrix, the x-axis is the objects of the original class. The y axis is where they were assigned. For example, out of 100% of objects of the zero class, 72% were successfully assigned to it, 0.8% - to the first class, 16.8% - to the ninth.
The following conclusions can be drawn from the matrix:
Therefore, it is necessary to develop an algorithm that can more correctly distinguish between these three classes.
In order to do this, we used the following ideas:
So, we need to keep the permission near the face and use it to clarify 0-8-9 classes. In total, we had three ideas on how to do this. About two of them will be written below in the section “Ideas That Did Not Drive”. The following idea rolled: We
train a simple Haar classifier for facial selection. In principle, a person can even be distinguished by good color. Given that we know well where the face should be.
Competition rules did not prohibit manual marking of the training base. Therefore, we marked the face somewhere in 400 images. And they got a very good selection of frames recognized in automatic mode (faces were found correctly in 98-99% of frames):



Having trained ResNet-100 on images, we got accuracy somewhere around 80%. But adding training results to the amount of networks used gave an additional 0.02 in the test sample, moving us to the region of thirties.
We will tear the slender outline of the story and take a small step to the side. Without this step, everything is fine, but with this step it becomes clear what was happening in the head at that time.
There are much more ideas that do not give results in any research task than ideas that give results. And sometimes it happens that ideas for one reason or another cannot be used. Here is a short list of ideas that we have already tried out at the time of entering the thirtieth place.
The first idea was as simple as a log. We already wrote on Habré ( 1 , 2) about networks that can color images according to the class of objects. It seemed to us that this is a very good approach. You can teach the network to detect exactly what you need: phones, hands, an open visor at the car. We even spent two days marking up, configuring and training SegNet. And suddenly we realized that SegNet has a private non-OpenSource license. Therefore, we cannot use it honestly. I had to refuse. And the results of automatic marking were promising (several approaches are shown here at once).
First:

Second:


And this is how the markup process looks like:


The second idea was that we did not have 224 * 224 permissions to make a decision of grade 0 or 9. The greatest problems were the loss of permission on people. But we knew that the face is almost always in the upper left of the image. Therefore, we dragged pictures, getting such cute tadpoles with maximum resolution in interesting places for us:


Not a ride. The result was something like normal training + strongly correlated with what we had.
The next idea was quite large and comprehensive. The posts on the contest forum prompted us to think: what does the network see in reality? What interests her?
There is a whole selection of articles on this topic: 1 , 2 , 3
The Kaggle forum presented such cool pictures:

We, of course, decided to invent our bicycle for this task. Moreover, it is written very simply.
We take the original image and begin to move a black square along it. At the same time, we look at how the response of the system changes.

We will draw the result as a heat map.
The image here shows an example of an incorrect classification of a Class 9 image (conversation with a neighbor). The image is classified as “reaching for music control”. And really, it seems. After all, the network itself does not see 3d. She sees a hand that lies in the direction of the dashboard switch. So what if the hand rests on the foot.
After looking at a few dozen errors, we realized that again everything rests there too: the grid does not look at what is happening on the face.
Therefore, we came up with a different way of learning. A set was supplied to the network entrance, where half of the pictures went directly from the training base, and half were with everything except the face erased:

And lo and behold , the grid began to work much better! For example, by a mistakenly classified peasant:

Or, differently (as it was - as it became):
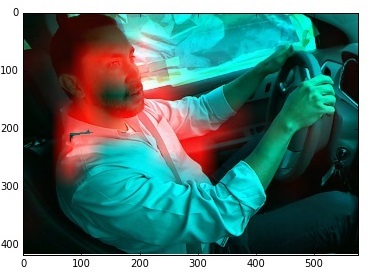
At the same time, the network worked well for the other classes (noted the correct zones of interest).
We already wanted to celebrate the victory. Loaded the network for verification - worse. Combined with our best - the final result has not improved. I don’t even remember if we began to add it to our best answer. They thought for a long time that we had some kind of mistake, but found nothing.
It seems like on the one hand - the network began to look more correct and correct a lot of errors. On the other hand, somewhere I started to do new ones. But at the same time, it did not give a significant statistical difference.
There were much more ideas that didn’t work. There was Dropout, which gave us almost nothing. There were additional different noises: it did not help either. But you can’t write anything beautiful about it.
We stayed somewhere around 30 places. Left a little. Many ideas have already failed, on the computer accumulated pieces of 25 test projects. There were no improvements. Our knowledge of neural networks gradually began to be exhausted. Therefore, we went to google the forum of the current competition and the old kaggle forums. And a solution was found. It was called "pseudo labeling" and "Semi-supervised learning . " And it leads to the dark side. Rather, gray. But it was announced by the admins of the contest as legal.
In short: we use a test sample for training, marking it with an algorithm trained in a training sample. It sounds weird and messy. But if you think about it, it’s funny. By driving objects that are marked into it into the network, we do not improve anything in the local perspective. But. First, we learn to highlight those signs that give the same result, but easier. In fact, we train convolutional levels in such a way that they learn to highlight new signs. Maybe in some next image they stand out and help better. Secondly, we protect the network from retraining and overfit by introducing pseudo-arbitrary data that obviously will not worsen the network.
Why does this path lead to the gray side? Because formally using a test sample for training is prohibited. But we are not using it here for training. Only for stabilization. Especially admins allowed.
Result: + 10 positions. We get into the twenty.
The final graph of the walk of the results was approximately as follows (at the beginning we did not spend all the attempts per day):
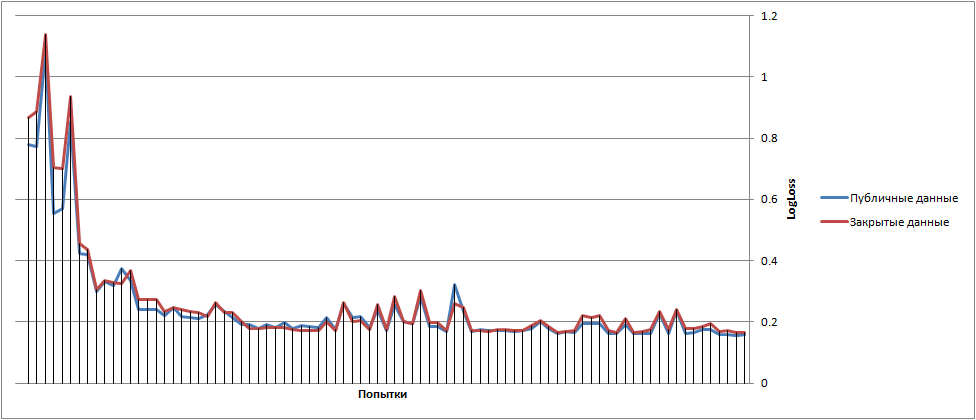
Somewhere at the beginning of the article I mentioned that I will return to LogLoss. With him, everything is not so simple. You can see that log (0) is minus infinity => if you suddenly put 0 in the class where the answer is one, then we get minus infinity.
Unpleasant. But the organizers protected us from this. They say that they replace the value under the log with max (a, 10 ^ (- 15)). So we get an addition of -15 / N to the result. That is equal to -0.000625 to the result for each erroneous image for public inspection and -0.0003125 for closed. Ten images affect the error in the third digit. And this is the position.
But the error can be reduced. Suppose instead of 10 ^ (- 15) we put 10 ^ (- 4). Then if we make a mistake we get -4 / N. But if we guess correctly, then we will also have losses. Instead of log (1) = 0, we take log (0.9999), which is -4 * 10 ^ (- 5). If we make a mistake every 10 attempts, then it is certainly more profitable for us than a loss of 10 ^ (- 15).
And then the magic begins. We need to combine 6-7 results to optimize the LogLoss metric.
In total, we did 80 submissions of the result. Of these, somewhere around 20-30 was devoted specifically to loss optimization.
I think that 5-6 places have been won back at this expense. Although, it seems to me, everyone is doing this.
All this magic was done by Vasyutka. I don’t even know how the last option looked. Only his description, which we have kept for ourselves, reached two paragraphs.
At the end of the contest, we still have a small stack of ideas. Probably, if we had time, then it would cost us another five positions. But we understood that this was clearly not a way to the top 3, so we did not throw all the remaining forces into the fight.
After the end of the contest, many participants publish their decisions. Here there is carried out the statistics on the top 20 of them. Now about half of the top 20 have published decisions.
Let's start with the best published. Third place .


I will say right away. I don’t like the solution and it seems to be a violation of the competition rules.
The authors of the solution noted that all the examples were filmed sequentially. To do this, they analyzed the test sample in automatic mode and found neighboring frames. Neighboring frames are images with minimal change => they belong to the same class => you can make a single answer for all close decisions.
And yes, that helps terribly. If you are talking on the phone holding it in your left hand - there are frames where the phone is not visible and it is not clear whether you are talking or scratching your head. But looking at the next frame you can clarify everything.
I would not mind if statistics were accumulated in this way and the background machine was subtracted. But reverse engineering video is for me beyond good and evil. Why, I will explain below. But, of course, the decision is up to the organizers.
I really like the fifth solution. It is so cool and so trivial. A thought came to my mind about ten times during the competition. But every time I swept it. "What for?!". "Why will this even work ?!" "Too lazy to waste time on this futility."
I did not even discuss it with my comrades. As it turned out - in vain. The idea is:

Take two pictures of the same class. Break in half and glue. Submit to training. All.
I don’t really understand why this works (besides the fact that it stabilizes the sample: 5 million samples is cool, it's not 22 thousand). And the guys had 10 TitanX cards. Maybe this played an important role.
The sixth solution is poorly described, I did not understand it. The ninth is very similar to ours. And the accuracy is not very different. Apparently, the guys were able to train the network better and better. They did not describe in detail due to which a small increase.
The tenth solution implemented part of our ideas, but in a slightly different way:
Cut the area with a person to increase the resolution -> apply for training. The same problems that we solved by face cutting are being solved. But, apparently, better.
15 solution - everything is like ours. Even the faces were also cut out (plus the steering wheel area, which we refused).
But ... They trained 150 models and stacked them. 150 !!!
19, 20 decision - everything is like ours but only without faces. And 25 trained models.
Suppose you are an insurance company that wants to implement a system for determining what the driver is doing. You have compiled a database, several teams suggested algorithms. What do we have:
But, still got some nice and interesting models.
Let's move on. And we will understand how these models work. Unfortunately, I do not have them, so I will test on ours, which gave the 18th result, which, in principle, is not so bad.
Of all the articles that I wrote on Habr, my beloved about how to collect the base. This is where we come to the analysis. What do we know about the collected base?
Four situations are enough for the first time. But there are much more of them. All situations can never be foreseen. That is why the base needs to be typed real and not simulated.
Go. I made the frames below myself.
How influenced by the fact that when recruiting the base, the drivers did not drive. Driving is a rather complicated process. You need to turn your head by 120 degrees, look at traffic lights, turn sharply at intersections. All this is not in the database. And therefore, such situations are defined as a “conversation with a neighbor”. Here is an example:



Daytime hours. This is a very big problem. Of course, you can make a system that will look at the driver at night including IR illumination. But in IR illumination, a person looks completely different. It will be necessary to completely redo the algorithm. Most likely to train one for a day and one for a night. But there is not only the problem of the night. Evening - when it’s still light but already dark for the camera, there are noises. The grid begins to get confused. Weights on neurons walk. The first picture is recognized as a conversation with a neighbor. The second picture is jumping between “reaching back”, “make-up” (which is logical within the network, because I reach for a visor), “conversation with a neighbor”, “safe driving”. The sun on the face is a very unpleasant factor, you know ...


About perfectionism. Here is a more or less real situation:

And weights on neurons: 0.04497785 0.00250986 0.23483475 0.05593431 0.40234038 0.01281587 0.00142132 0.00118973 0.19188504 0.0520909 The
maximum on that the phone is near the left ear. But the network got a little crazy.
I’m silent about Russia in general. Almost all the frames with the hand on the gear knob are recognized as “reaching back”:


It can be seen that there are a lot of problems. I did not add pictures here where I tried to deceive the network (by turning on the flashlight on the phone, strange hats, etc.). It is real and it is cheating on the network.
And the problem is that NO computer vision system is done from the first iteration. There should always be a startup process. Starting with a simple test sample. With a set of statistics. With the correction of emerging problems. And they will always be. At the same time, 90% need to be corrected not programmatically, but administratively. Caught on the fact that I tried to trick the system - get a pie. Is someone fixing the camera wrong? Be kind, hold on humanly. And not that fool himself.
When doing development, you need to be prepared that before you get the perfect result, you will need to redo everything 2-3 times.
And it seems to me that for this task, everything is not bad, but rather good. The 95-97% performance shown by the test is good and means that the system is promising. This means that the final system can be brought to plus or minus the same accuracy. You just need to invest another 2-3 times more effort into the development.
By the way. About the camera mount. Apparently, how the camera was mounted, gaining statistics prevents the passenger. The way I mounted the camera gives a slightly different picture, according to which statistics fall. But it does not interfere with the passenger. I think that the solution with a camera interfering with the passenger will be unsuitable, most likely they will reassemble the base. Or strongly add.
It is also not clear where the images are planned to be processed. In the module that will shoot? Then you need to have decent computing power there. Send to server? Then these are clearly single frames. Save on a card and transfer once a week from a home computer? Inconvenient form factor.
Dohrena. I have never seen a task brought to release faster than half a year. Probably, applications of the Prism type, of course, can be deployed in a month, or even faster if there is an infrastructure. But any task where the result is important and which is not an art project is a long time.
Specifically for this task. A minimum of 70 people were involved in the recruitment of the base. Of these, at least 5 people were attendants who drove the truck and sat with a notebook. And people 65-100 are people who entered the base (I don’t know how many there are). It’s unlikely that the organizers managed to organize such a move, collect and verify everything in less than 1-2 months. The contest itself lasted 3 months, but it is possible to make a good decision on the dialed base in 2-3 weeks (which we did). But to bring this decision to a working sample may come out in 1-3 months. It is necessary to optimize the solution for hardware, build transmission algorithms, modify the solution so that it does not drive anything when idle, in the absence of a driver. And so on. Such things always depend on the statement of the problem and on where and how the solution should be used.
And then the second stage begins: trial operation. You need to put the system for 40-50 people in the car for a couple of days each and see how it works. Draw conclusions when it does not work, generalize and rework the system. And then the swamp will begin, where it is almost impossible to estimate the implementation dates a priori before the start of work. It will be necessary to make the right decisions: in what situations the system is being finalized, in which a stub is put, and in which we will fight administratively. This is the most difficult, few people know how.

Conclusions will be on kaggle. I like it. I rejoiced at our level. From time to time, it seemed to me that we were behind the times, choosing not optimal methods in our work. And the campaign is all normal. On the part of self-assessment in the surrounding world, kaggle is very good.
On the part of solving problems, kaggle is an interesting tool. This is probably one of the correct and comprehensive methods that allows you to conduct a good research. You just need to understand that the finished product does not smell like that. But to understand and evaluate the complexity and ways of solving the problem is normal.
Will we participate yet - I don’t know. Forces to fight for the first places you need to spend a lot. But, if there is an interesting problem - why not.
- PS They asked to repeat this whole story at Yandex training. And there it turns out they are writing a video. If anyone needs:
And many many others.
I have long wanted to try, but something kept interfering all the time. I have developed many systems related to image processing: the topic is close. Skills lie more in the practical part and classical Computer Vision (CV) algorithms than in modern Machine Learning techniques, so it was interesting to evaluate your knowledge at the world level, plus to enhance understanding of convolution networks.
And suddenly everything turned out. A couple of weeks fell of a not-so-busy schedule. At kaggle there was an interesting competition on related topics. I updated my comp. And most importantly - knocked vasyutka and Nikkolo to make up the company.
I must say right away that we have not achieved enchanting results. But I consider 18th place out of 1.5 thousand participants not bad. And considering that this is our first experience of participating in kaggle, that of the 3 months of the competition, we participated only 2.5 weeks, that all the results were obtained on one single video card - it seems to me that we performed well.
What will this article be about? Firstly, about the problem itself and our method of solving it. Secondly, about the process of solving CV problems. I wrote a lot of articles on the computer science vision hub ( 1 , 2 , 3), but it is always better to back up the writings and theory with an example. And writing articles for some commercial task for obvious reasons is not possible. Now, finally, I will talk about the process. Moreover, here it is the most ordinary, well illustrating how tasks are solved. Thirdly, the article is about what goes after solving the idealized problem in a vacuum: what will happen when the task encounters reality.
Task analysis
The task we started doing was as follows: “Determine the driver’s affiliation in the photo to one of ten groups: neat driving, a phone in his right hand, a phone in his right ear, a phone in his left hand, a phone in his left ear, music tuning, drinking liquid ”, stretches back, correction of a hairdress (paints lips, scratches a nape), conversation with the neighbor". But, it seems to me, it is better to look at the examples once:
0
1 2 3
4 5 6
7 8 9
English
- c0: safe driving
- c1: texting - right
- c2: talking on the phone - right
- c3: texting - left
- c4: talking on telephone - left
- c5: operating the radio
- c6: drinking
- c7: reaching behind
- c8: hair and makeup
- c9: talking to passenger
**********************************************
Everything seems clear and obvious. But it is not so. What class do these two examples belong to?
The first example is grade 9, conversation. The second example is class zero, safe driving.
According to our estimation, the accuracy of a person in recognizing a class by base is about 94%. In this case, the first and tenth grades make the greatest confusion. At the beginning of our participation, the first places had an accuracy of about 97% of correct recognitions. Yes Yes! Robots are already better than humans!
A few details:
- The size of the base for training is 22 thousand images.
- About 2 thousand per class.
- There are 27 drivers in the training base.
- Test base - 79 thousand images.
Today, convolutional neural networks are the main means for solving problems of such a plan. They analyze the image at many levels, independently identifying key features and their relationships. You can read about convolution networks here , here and here . Convolution networks have a number of disadvantages:
- You need a lot of diverse data for training. Two thousand per class is more or less enough, although not enough. But the fact that there are only 27 drivers is very limited.
- Convolutional networks are prone to overfit. During training, they can catch on to some insignificant feature characteristic of several images, but which does not carry significant weight. We have such a sign was the opening of the sun visor. All photos with him went automatically to grade 8. Anyway: with an overfit, the grid can simply remember all 22 thousand input images. Here is a good example of overfit.
- Convolutional networks are ambiguous due to the fact that they are complex. Approximately the same solution on different frameworks can give fundamentally different results. A few slightly changed network parameters fundamentally change the result. Many people call networking something akin to art.
An alternative to convolutional networks may be manual management of low-level features. Highlight hands. Face position. Facial expression. Open / closed visor at the car.
There are a lot of different convolution networks. The classical approach - to use the most widespread network of "Zoo» ( caffe Theano keras ). This is primarily VGG16, VGG19, GoogleNet, ResNet. There are many variations for these networks, plus you can use learning acceleration techniques. Of course, this approach is used by all participants. But a basic good result can only be obtained on it.
Our setup
All the calculations in our work took place on one single GTX1080. This is the latest game card from NVIDIA. Not the best option from what is on the market, but quite good.
We wanted to use a cluster with three Tesla in one of the works, but due to a number of technical difficulties, this did not work. We also considered the use of some old video card from a laptop on 4Gb, but as a result we decided not to follow this path, there was much less speed.
The framework used is Caffe . Keras could also be used with Theano, which would certainly improve our result due to a slightly different implementation of the training. But we did not have time for this, so it was Caffe that was used to the maximum.
RAM - 16Gb, maximum for training used 10Gb. The processor is the last i5.
If suddenly anyone is interested, but nothing special
A few words about the rules
I think that most of the readers have never participated in kaggle, so I will give a short excursion into what the rules of the competition are:
- Two data sets are presented to participants. Training - on which the target results are signed. Test - by which you need to make recognition.
- The participant must recognize all the images from the test set and send them to the site in csv format (text file of the form “image number” - first class probability, second class probability, ....).
- In total, 5 sending attempts can be made per day.
- After each sending, the user is told the current percentage on the test base. But, you need to consider one interesting point. The user is told the result is not for the entire database, but only for a small part of it. In our task, it was 39%.
- The final result of the competition is considered for the remaining piece of the base (61%) after the close of the competition. This can lead to serious rearrangements of the participants.
- The first three places are prize-winning. If a participant falls into them, he must publish his decision and the organizer will check it.
- The decision should not:
- Contain proprietary data
- Use user-tagged test sample for training. At the same time, additional training is allowed.
A few words about the metric
Suppose we come up with some kind of recognition engine and recognize all the images. How will they be further checked? In this problem, we used the approach of calculating multiclass logarithmic losses . In short, it can be written as:
y is the matrix of solutions. Unit if the object belongs to the class.
p - response matrix sent by the user. It’s best to record the probability of belonging to a class.
M-number of classes
N-number of objects
In a neighborhood of zero, the value is replaced by a constant.
We figured that a probability of “95%” corresponds to a logloss value of approximately “0.2”, a value of “0.1” corresponds to a probability of “97.5%”. But these are rough estimates.
We will return to this function, but somewhat lower.
First steps
The theory is good. But where to start? Let's start with the simplest: take the CaffeNet grid, which is attached to Caffe and for which there is an example.
After I did a similar action, I immediately got the result “0.7786”, which was somewhere in the 500th place. It's funny, but for many the result was much worse. At the same time, it is worth noting that 0.77 approximately corresponds to 80-85% of correct recognitions.
We will not dwell on this grid, which is already quite outdated. Take something standard modern. The following can be considered standard:
- VGG Family :
- VGG-16
- VGG-19
- ResNet Family :
- ResNet-50
- ResNet-101
- ResNet-152
- Inception Family
About non-standard methods can be read a little lower in the section "Ideas that did not work."
Since we started about two and a half months after the start of the competition, it made sense to explore the forum. The forum advised VGG-16. The author of the post claimed that he received a solution with a loss of "0.23" based on this network.
Consider the author’s decision :
- He used the VGG pre-trained network. This greatly increases the speed of learning.
- He trained not one, but 8 nets. When training each grid, only 1/8 of the input database (22/8 thousand images) was input.
- The resulting solution gave a level of 0.3-0.27
- He got the final result by adding the result of these 8 grids.
We could not repeat the decision. However, many who did not succeed in doing this. Although the author posted a training script on Keras. Apparently on Keras it could be achieved, but not on caffe. The winner of the third place also considered VGG on Keras, and all other grids on Caffe and Theano.
For us, pure VGG gave 0.4, which, of course, improved our result at that time, but only places up to the 300th.
As a result, we decided to abandon VGG and tested the training of the pre-trained ResNet-50 ( here it is interesting to read what it is). Which immediately gave us 0.3-0.29.
A little remark: we never used the technique of “breaking the base into 8 parts”. Although, most likely, it would bring us a little extra accuracy. But such training would take several days, which was unacceptable to us.
Why is it necessary to split the base into 8 parts and train independent grids? Suppose the first of the grids is always mistaken in favor of situation A, when choosing from A and B. The second grid, on the contrary, makes decision B. Moreover, both grids are often mistaken regarding the real solution. But the sum of the grids will more correctly assess the risk of A / B. In fact, in most controversial situations it will deliver 50% - A, 50% - B. This approach minimizes our losses. We reached it differently.
To increase accuracy with 0.3, we did the following series of actions:
- We trained several ResNet-50 grids with various hyperparameters. All of them gave somewhere 0.3-0.28, but their sum was greater.
- We trained the ResNet-101 grid, which in itself gave somewhere 0.25
- We trained the ResNet-50 grid with image changes, which gave somewhere 0.26
The image changes are as follows: during training, instead of the original training picture, a rotated picture, a cropped picture, a picture noisy, are fed in. This improves stability and improves accuracy.
The final result of adding all the listed grids was at the level of “0.23-0.22”.
To new heights
The result of 0.22 was somewhere around 100 places. This is already a good result. In fact, the maximum that a correctly configured network gives. But to go further you need to stop, think and comprehend what has been done.
The easiest way to do this is to look at the “Confusion Matrix”. In essence, this concept hides a budget of errors. How and when we are wrong. Here is the matrix that we came up with:
In this matrix, the x-axis is the objects of the original class. The y axis is where they were assigned. For example, out of 100% of objects of the zero class, 72% were successfully assigned to it, 0.8% - to the first class, 16.8% - to the ninth.
The following conclusions can be drawn from the matrix:
- The largest number of errors is zero and ninth grade. This is logical. Often I myself can’t understand whether a person says or not. There was an example above.
- Second in terms of errors is the eighth grade. Any class where the hand is next to the head can be assigned to the eighth grade if there is insufficient information. These are phone conversations. This is a conversation with a neighbor, with active gestures. In some situations, when a person drinks liquid, he may also be similar.
Therefore, it is necessary to develop an algorithm that can more correctly distinguish between these three classes.
In order to do this, we used the following ideas:
- In the opinion of a person, 90% of the information allowing to distinguish between grade 0 and grade 9 is contained on the face. Moreover, in most cases, when assignment to the 8th grade was mistaken, the final decision is also made in the area around the face.
- All grids given above were sharpened at a resolution of 224 * 224. At the same time, the quality of the face is greatly sagged.
So, we need to keep the permission near the face and use it to clarify 0-8-9 classes. In total, we had three ideas on how to do this. About two of them will be written below in the section “Ideas That Did Not Drive”. The following idea rolled: We
train a simple Haar classifier for facial selection. In principle, a person can even be distinguished by good color. Given that we know well where the face should be.
Competition rules did not prohibit manual marking of the training base. Therefore, we marked the face somewhere in 400 images. And they got a very good selection of frames recognized in automatic mode (faces were found correctly in 98-99% of frames):
Having trained ResNet-100 on images, we got accuracy somewhere around 80%. But adding training results to the amount of networks used gave an additional 0.02 in the test sample, moving us to the region of thirties.
Ideas that didn’t work
We will tear the slender outline of the story and take a small step to the side. Without this step, everything is fine, but with this step it becomes clear what was happening in the head at that time.
There are much more ideas that do not give results in any research task than ideas that give results. And sometimes it happens that ideas for one reason or another cannot be used. Here is a short list of ideas that we have already tried out at the time of entering the thirtieth place.
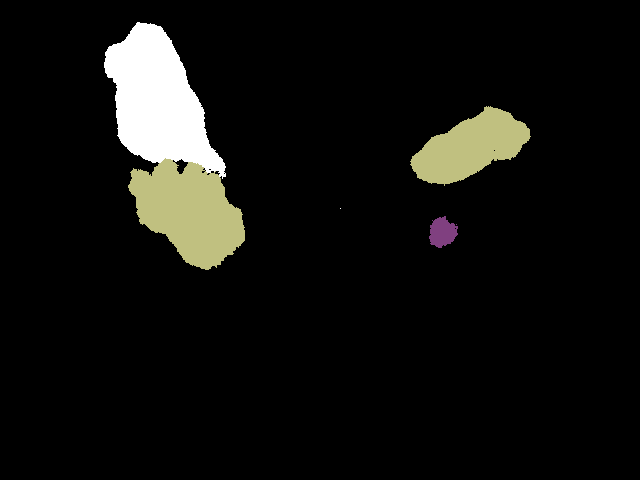
The first idea was as simple as a log. We already wrote on Habré ( 1 , 2) about networks that can color images according to the class of objects. It seemed to us that this is a very good approach. You can teach the network to detect exactly what you need: phones, hands, an open visor at the car. We even spent two days marking up, configuring and training SegNet. And suddenly we realized that SegNet has a private non-OpenSource license. Therefore, we cannot use it honestly. I had to refuse. And the results of automatic marking were promising (several approaches are shown here at once).
First:
Second:
And this is how the markup process looks like:
The second idea was that we did not have 224 * 224 permissions to make a decision of grade 0 or 9. The greatest problems were the loss of permission on people. But we knew that the face is almost always in the upper left of the image. Therefore, we dragged pictures, getting such cute tadpoles with maximum resolution in interesting places for us:
Not a ride. The result was something like normal training + strongly correlated with what we had.
The next idea was quite large and comprehensive. The posts on the contest forum prompted us to think: what does the network see in reality? What interests her?
There is a whole selection of articles on this topic: 1 , 2 , 3
The Kaggle forum presented such cool pictures:
We, of course, decided to invent our bicycle for this task. Moreover, it is written very simply.
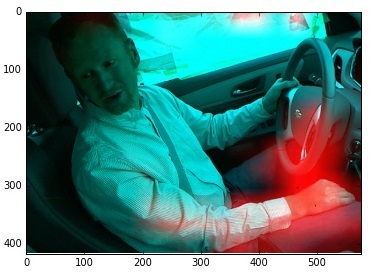
We take the original image and begin to move a black square along it. At the same time, we look at how the response of the system changes.
We will draw the result as a heat map.
The image here shows an example of an incorrect classification of a Class 9 image (conversation with a neighbor). The image is classified as “reaching for music control”. And really, it seems. After all, the network itself does not see 3d. She sees a hand that lies in the direction of the dashboard switch. So what if the hand rests on the foot.
After looking at a few dozen errors, we realized that again everything rests there too: the grid does not look at what is happening on the face.
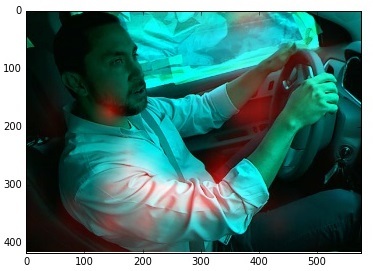
Therefore, we came up with a different way of learning. A set was supplied to the network entrance, where half of the pictures went directly from the training base, and half were with everything except the face erased:
And lo and behold , the grid began to work much better! For example, by a mistakenly classified peasant:
Or, differently (as it was - as it became):
At the same time, the network worked well for the other classes (noted the correct zones of interest).
We already wanted to celebrate the victory. Loaded the network for verification - worse. Combined with our best - the final result has not improved. I don’t even remember if we began to add it to our best answer. They thought for a long time that we had some kind of mistake, but found nothing.
It seems like on the one hand - the network began to look more correct and correct a lot of errors. On the other hand, somewhere I started to do new ones. But at the same time, it did not give a significant statistical difference.
There were much more ideas that didn’t work. There was Dropout, which gave us almost nothing. There were additional different noises: it did not help either. But you can’t write anything beautiful about it.
Back to our rams
We stayed somewhere around 30 places. Left a little. Many ideas have already failed, on the computer accumulated pieces of 25 test projects. There were no improvements. Our knowledge of neural networks gradually began to be exhausted. Therefore, we went to google the forum of the current competition and the old kaggle forums. And a solution was found. It was called "pseudo labeling" and "Semi-supervised learning . " And it leads to the dark side. Rather, gray. But it was announced by the admins of the contest as legal.
In short: we use a test sample for training, marking it with an algorithm trained in a training sample. It sounds weird and messy. But if you think about it, it’s funny. By driving objects that are marked into it into the network, we do not improve anything in the local perspective. But. First, we learn to highlight those signs that give the same result, but easier. In fact, we train convolutional levels in such a way that they learn to highlight new signs. Maybe in some next image they stand out and help better. Secondly, we protect the network from retraining and overfit by introducing pseudo-arbitrary data that obviously will not worsen the network.
Why does this path lead to the gray side? Because formally using a test sample for training is prohibited. But we are not using it here for training. Only for stabilization. Especially admins allowed.
Result: + 10 positions. We get into the twenty.
The final graph of the walk of the results was approximately as follows (at the beginning we did not spend all the attempts per day):
And again about LogLoss
Somewhere at the beginning of the article I mentioned that I will return to LogLoss. With him, everything is not so simple. You can see that log (0) is minus infinity => if you suddenly put 0 in the class where the answer is one, then we get minus infinity.
Unpleasant. But the organizers protected us from this. They say that they replace the value under the log with max (a, 10 ^ (- 15)). So we get an addition of -15 / N to the result. That is equal to -0.000625 to the result for each erroneous image for public inspection and -0.0003125 for closed. Ten images affect the error in the third digit. And this is the position.
But the error can be reduced. Suppose instead of 10 ^ (- 15) we put 10 ^ (- 4). Then if we make a mistake we get -4 / N. But if we guess correctly, then we will also have losses. Instead of log (1) = 0, we take log (0.9999), which is -4 * 10 ^ (- 5). If we make a mistake every 10 attempts, then it is certainly more profitable for us than a loss of 10 ^ (- 15).
And then the magic begins. We need to combine 6-7 results to optimize the LogLoss metric.
In total, we did 80 submissions of the result. Of these, somewhere around 20-30 was devoted specifically to loss optimization.
I think that 5-6 places have been won back at this expense. Although, it seems to me, everyone is doing this.
All this magic was done by Vasyutka. I don’t even know how the last option looked. Only his description, which we have kept for ourselves, reached two paragraphs.
What we did not
At the end of the contest, we still have a small stack of ideas. Probably, if we had time, then it would cost us another five positions. But we understood that this was clearly not a way to the top 3, so we did not throw all the remaining forces into the fight.
- We did not investigate the division of the base into small pieces and their independent training. In theory, this adds stability. We used a similar approach for Semi-supervised learning, but also without fully exploring the entire field of possibilities.
- There was another gray mechanism that we still did not decide to use, but thought for a long time. Although there was no explicit ban on him from the administration. Mechanism: find photos on the test sample that correspond to different machines, build their model and subtract the background from the photos. Work here somewhere for 2-3 days. But I didn’t want to: they didn’t believe in what would lead to the top ten, nor in the idea that they would not be banned.
- We did not investigate the formation of the batch (a small array by which the learning step takes place). Only the general principle that it is statistically correct. It was possible to create batches from different drivers, from the same, etc. The people on the forum were having fun. In principle, the idea is sound. But they decided not to do it for reasons of time.
- A couple of days before the end, I remembered the existence of such a method. This method allows you to make the network learn on the common features of classes, and not on the same. Essentially, eliminate background noise, driver identity and type of vehicle. There are no sources for this method, I would have to make a network from scratch. The issue of openness / closeness is also not clear. Since there was 2 days left, they refused.
Analysis of decisions of other participants
After the end of the contest, many participants publish their decisions. Here there is carried out the statistics on the top 20 of them. Now about half of the top 20 have published decisions.
Let's start with the best published. Third place .
I will say right away. I don’t like the solution and it seems to be a violation of the competition rules.
The authors of the solution noted that all the examples were filmed sequentially. To do this, they analyzed the test sample in automatic mode and found neighboring frames. Neighboring frames are images with minimal change => they belong to the same class => you can make a single answer for all close decisions.
And yes, that helps terribly. If you are talking on the phone holding it in your left hand - there are frames where the phone is not visible and it is not clear whether you are talking or scratching your head. But looking at the next frame you can clarify everything.
I would not mind if statistics were accumulated in this way and the background machine was subtracted. But reverse engineering video is for me beyond good and evil. Why, I will explain below. But, of course, the decision is up to the organizers.
I really like the fifth solution. It is so cool and so trivial. A thought came to my mind about ten times during the competition. But every time I swept it. "What for?!". "Why will this even work ?!" "Too lazy to waste time on this futility."
I did not even discuss it with my comrades. As it turned out - in vain. The idea is:
Take two pictures of the same class. Break in half and glue. Submit to training. All.
I don’t really understand why this works (besides the fact that it stabilizes the sample: 5 million samples is cool, it's not 22 thousand). And the guys had 10 TitanX cards. Maybe this played an important role.
The sixth solution is poorly described, I did not understand it. The ninth is very similar to ours. And the accuracy is not very different. Apparently, the guys were able to train the network better and better. They did not describe in detail due to which a small increase.
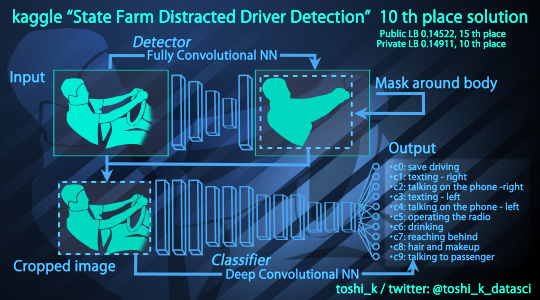
The tenth solution implemented part of our ideas, but in a slightly different way:
Cut the area with a person to increase the resolution -> apply for training. The same problems that we solved by face cutting are being solved. But, apparently, better.
15 solution - everything is like ours. Even the faces were also cut out (plus the steering wheel area, which we refused).
But ... They trained 150 models and stacked them. 150 !!!
19, 20 decision - everything is like ours but only without faces. And 25 trained models.
From toys to action
Suppose you are an insurance company that wants to implement a system for determining what the driver is doing. You have compiled a database, several teams suggested algorithms. What do we have:
- Алгоритм, который использует данные о соседних кадрах. Это странно. Если бы вы хотели, чтобы ваш алгоритм так работал — вы бы предложили анализировать не фотографии, а видео. Более того. Такой алгоритм почти невозможно завязать с видео как таковым. Если у вас есть алгоритмы, которые распознают отдельный кадр — его очень легко можно надстроить до алгоритма работающего с видео. Алгоритм, который использует «5 ближайших кадров» — очень сложно.
- Алгоритмы, которые используют по 150 нейронных сетей. Это огромные вычислительные мощности. Такой продукт не получиться делать массовым. 2-3 сети это по хорошему максимум. Ок, пусть 10 — предел. Одно дело, если бы ваша задача была детектировать рак. Там такие затраты допустимы. Там нужно бороться за каждый процент. Но ваша цель — массовый продукт.
But, still got some nice and interesting models.
Let's move on. And we will understand how these models work. Unfortunately, I do not have them, so I will test on ours, which gave the 18th result, which, in principle, is not so bad.
Of all the articles that I wrote on Habr, my beloved about how to collect the base. This is where we come to the analysis. What do we know about the collected base?
- When dialing the base, the drivers did not drive the car. The car was driving a truck, drivers were given tasks to do.
- The entire base was typed in the daytime. Apparently the workers. There is no low sun. No evening shots.
- All situations are perfected. People do not hold the phone with their left hands near their right ear. All phones have the same plus or minus.
- The base was recruited in America. You ask how I understand? There are no cars with a manual box ...
Four situations are enough for the first time. But there are much more of them. All situations can never be foreseen. That is why the base needs to be typed real and not simulated.
Go. I made the frames below myself.
How influenced by the fact that when recruiting the base, the drivers did not drive. Driving is a rather complicated process. You need to turn your head by 120 degrees, look at traffic lights, turn sharply at intersections. All this is not in the database. And therefore, such situations are defined as a “conversation with a neighbor”. Here is an example:
Daytime hours. This is a very big problem. Of course, you can make a system that will look at the driver at night including IR illumination. But in IR illumination, a person looks completely different. It will be necessary to completely redo the algorithm. Most likely to train one for a day and one for a night. But there is not only the problem of the night. Evening - when it’s still light but already dark for the camera, there are noises. The grid begins to get confused. Weights on neurons walk. The first picture is recognized as a conversation with a neighbor. The second picture is jumping between “reaching back”, “make-up” (which is logical within the network, because I reach for a visor), “conversation with a neighbor”, “safe driving”. The sun on the face is a very unpleasant factor, you know ...
About perfectionism. Here is a more or less real situation:
And weights on neurons: 0.04497785 0.00250986 0.23483475 0.05593431 0.40234038 0.01281587 0.00142132 0.00118973 0.19188504 0.0520909 The
maximum on that the phone is near the left ear. But the network got a little crazy.
I’m silent about Russia in general. Almost all the frames with the hand on the gear knob are recognized as “reaching back”:
It can be seen that there are a lot of problems. I did not add pictures here where I tried to deceive the network (by turning on the flashlight on the phone, strange hats, etc.). It is real and it is cheating on the network.
Panic. Why is everything so bad? You promised 97% !!
And the problem is that NO computer vision system is done from the first iteration. There should always be a startup process. Starting with a simple test sample. With a set of statistics. With the correction of emerging problems. And they will always be. At the same time, 90% need to be corrected not programmatically, but administratively. Caught on the fact that I tried to trick the system - get a pie. Is someone fixing the camera wrong? Be kind, hold on humanly. And not that fool himself.
When doing development, you need to be prepared that before you get the perfect result, you will need to redo everything 2-3 times.
And it seems to me that for this task, everything is not bad, but rather good. The 95-97% performance shown by the test is good and means that the system is promising. This means that the final system can be brought to plus or minus the same accuracy. You just need to invest another 2-3 times more effort into the development.
By the way. About the camera mount. Apparently, how the camera was mounted, gaining statistics prevents the passenger. The way I mounted the camera gives a slightly different picture, according to which statistics fall. But it does not interfere with the passenger. I think that the solution with a camera interfering with the passenger will be unsuitable, most likely they will reassemble the base. Or strongly add.
It is also not clear where the images are planned to be processed. In the module that will shoot? Then you need to have decent computing power there. Send to server? Then these are clearly single frames. Save on a card and transfer once a week from a home computer? Inconvenient form factor.
How much time is spent on the task of such a plan from scratch
Dohrena. I have never seen a task brought to release faster than half a year. Probably, applications of the Prism type, of course, can be deployed in a month, or even faster if there is an infrastructure. But any task where the result is important and which is not an art project is a long time.
Specifically for this task. A minimum of 70 people were involved in the recruitment of the base. Of these, at least 5 people were attendants who drove the truck and sat with a notebook. And people 65-100 are people who entered the base (I don’t know how many there are). It’s unlikely that the organizers managed to organize such a move, collect and verify everything in less than 1-2 months. The contest itself lasted 3 months, but it is possible to make a good decision on the dialed base in 2-3 weeks (which we did). But to bring this decision to a working sample may come out in 1-3 months. It is necessary to optimize the solution for hardware, build transmission algorithms, modify the solution so that it does not drive anything when idle, in the absence of a driver. And so on. Such things always depend on the statement of the problem and on where and how the solution should be used.
And then the second stage begins: trial operation. You need to put the system for 40-50 people in the car for a couple of days each and see how it works. Draw conclusions when it does not work, generalize and rework the system. And then the swamp will begin, where it is almost impossible to estimate the implementation dates a priori before the start of work. It will be necessary to make the right decisions: in what situations the system is being finalized, in which a stub is put, and in which we will fight administratively. This is the most difficult, few people know how.
conclusions
Conclusions will be on kaggle. I like it. I rejoiced at our level. From time to time, it seemed to me that we were behind the times, choosing not optimal methods in our work. And the campaign is all normal. On the part of self-assessment in the surrounding world, kaggle is very good.
On the part of solving problems, kaggle is an interesting tool. This is probably one of the correct and comprehensive methods that allows you to conduct a good research. You just need to understand that the finished product does not smell like that. But to understand and evaluate the complexity and ways of solving the problem is normal.
Will we participate yet - I don’t know. Forces to fight for the first places you need to spend a lot. But, if there is an interesting problem - why not.
- PS They asked to repeat this whole story at Yandex training. And there it turns out they are writing a video. If anyone needs: