Program anatomy in memory
- Transfer
Memory management is one of the main tasks of the OS. It is critical for both programming and system administration. I will try to explain how the OS works with memory. The concepts will be general in nature, and I'll take examples from Linux and Windows on 32-bit x86. First, I will describe how programs are located in memory.
Each process in a multi-tasking OS runs in its own “sandbox” in memory. This is a virtual address space, which in 32-bit mode is a 4GB address block. These virtual addresses are mapped to physical memory by the page tables supported by the OS kernel. Each process has its own set of tables. But if we start using virtual addressing, we have to use it for all programs running on the computer - including the kernel itself. Therefore, part of the virtual address space must be reserved for the kernel.

This does not mean that the kernel uses so much physical memory - it just has at its disposal part of the address space that can be matched to the required amount of physical memory. The memory space for the kernel is marked in the page tables as being exclusively used by privileged code, so if a program tries to access it, a page fault occurs. On Linux, memory space for the kernel is always present, and maps the same part of the physical memory of all processes. Kernel code and data always have addresses, and are ready to handle interrupts and system calls at any time. For user programs, on the contrary, the correspondence of the virtual addresses of real memory changes when process switching occurs:
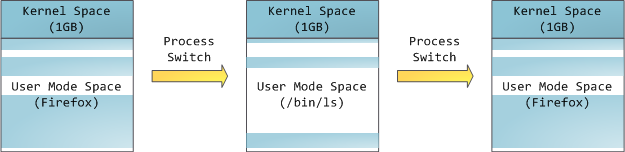
Virtual addresses corresponding to physical memory are marked in blue. White is a space to which no addresses are assigned. In our example, Firefox uses much more virtual memory because of its legendary gluttony. The strips in the address space correspond to memory segments such as heap, stack, and so on. These segments are just memory address ranges, and have nothing to do with Intel segments. Here is the standard segment diagram for a process under Linux:
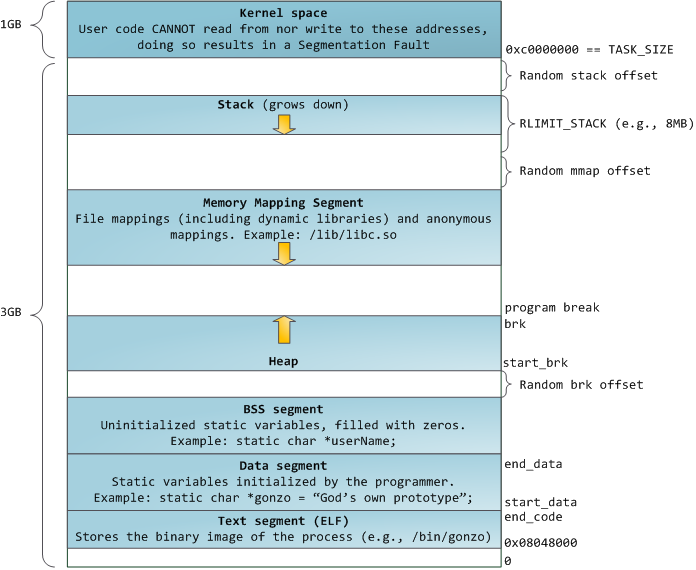
When programming was white and fluffy, the initial virtual addresses of the segments were the same for all processes. This made it easy to remotely exploit security vulnerabilities. A malicious program often needs to access memory at absolute addresses - the address of the stack, the address of the library function, etc. Remote attacks had to be done blindly, relying on the fact that all address spaces remain at constant addresses. In this regard, the random address selection system has gained popularity. Linux randomizes the stack, memory segment, and heap by adding offsets to their starting addresses. Unfortunately, you won’t be especially deployed in the 32-bit address space, and there is not enough space left for assigning random addresses, which makes this system not very efficient.
The topmost segment in the process address space is the stack, which in most languages stores local variables and function arguments. A method or function call adds a new stack frame to an existing stack. After returning from the function, the frame is destroyed. This simple scheme leads to the fact that to track the contents of the stack does not require any complex structure - just a pointer to the beginning of the stack. Adding and removing data becomes a simple and straightforward process. The constant reuse of memory areas for the stack leads to caching of these parts in the CPU, which adds speed. Each thread in the process gets its own stack.
You can come to a situation in which the memory allocated for the stack ends. This results in a page fault error, which is handled by the expand_stack () function on Linux, which in turn calls acct_stack_growth () to check if the stack can still be expanded. If its size does not exceed RLIMIT_STACK (usually it is 8 MB), then the stack grows and the program continues execution, as if nothing had happened. But if the maximum stack size is reached, we get a stack overflow and the program receives a Segmentation Fault error (segmentation error). At the same time, the stack can only grow - like the state budget, it does not decrease back.
Dynamic stack growth is the only situation in which free memory can be accessed, which is shown in white in the diagram. All other attempts to access this memory cause a page fault error, resulting in a Segmentation Fault. And some occupied memory areas are read-only, so trying to write to these areas also leads to Segmentation Fault.
After the stack there is a segment of mapping into memory. Here the kernel places the contents of files directly in memory. Any application can request to do this through the mmap () system call on Linux or CreateFileMapping () / MapViewOfFile () on Windows. This is a convenient and quick way to organize file input and output operations, so it is used to load dynamic libraries. It is also possible to create an anonymous memory location not associated with files that will be used for program data. If you query Linux for a large amount of memory through malloc (), the C library will create such an anonymous mapping instead of using memory from the heap. “Big” means a volume larger than MMAP_THRESHOLD (128 kB by default, it is configured through mallopt ().)
The heap itself is located in the following positions in memory. It provides memory allocation during program execution, as does the stack - but, unlike it, it stores the data that must survive the function that hosts them. Most languages have heap management tools. In this case, the satisfaction of the memory allocation request is performed jointly by the program and the kernel. In With the interface, malloc () is used to work with the heap with friends, and in a language that has automatic garbage collection, such as C #, the new keyword is the interface.
If there is not enough space on the heap to execute the request, the program itself can handle this problem without kernel intervention. Otherwise, the heap is increased by the brk () system call. Managing a bunch is a complicated business; it requires sophisticated algorithms that strive to work quickly and efficiently in order to cater to the chaotic data placement method used by the program. The time it takes to process a request to the heap can vary widely. In real-time systems, there are special tools for working with it. Heaps can also be fragmented:

And so we got to the very bottom of the diagram - BSS, data and program text. BSS and data store static (global) variables in C. The difference is that BSS stores the contents of uninitialized static variables whose values were not set by the programmer. In addition, the BSS area is anonymous; it does not correspond to any file. If you write
The data segment, on the contrary, contains those variables that were initialized in the code. This part of the memory corresponds to the binary image of the program containing the initial static values specified in the code. If you write
The sample data in the chart will be a little more complicated as it uses a pointer. In this case, the contents of the pointer, a 4-byte memory address, live in the data segment. And the line he points to lives in a segment of text that is read-only. All code and various other details are stored there, including string literals. It also stores your binary in memory. Attempts to write to this segment result in a Segmentation Fault error. This prevents pointer errors (although not as efficient as if you hadn’t used C at all). The diagram shows these segments and examples of variables:
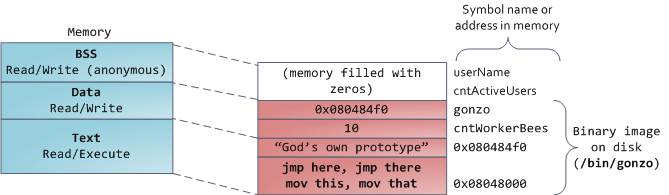
You can examine the memory areas of a Linux process by reading the file / proc / pid_of_process / maps. Note that a single segment may contain many areas. For example, each file duplicated into memory has its own area in the mmap segment, while dynamic libraries have additional areas that resemble BSS and data. By the way, sometimes when people say “data segment”, they mean data + bss + heap.
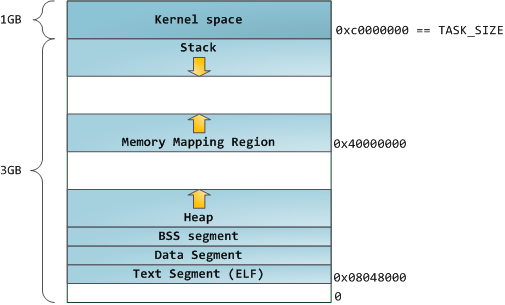
Binary images can be studied using the nm and objdump commands - you will see characters, their addresses, segments, etc. The virtual address scheme described in this article is the so-called “Flexible” scheme, which has been used by default for several years already. It implies that some value is assigned to the RLIMIT_STACK variable. Otherwise, Linux uses the “classic” scheme:
Each process in a multi-tasking OS runs in its own “sandbox” in memory. This is a virtual address space, which in 32-bit mode is a 4GB address block. These virtual addresses are mapped to physical memory by the page tables supported by the OS kernel. Each process has its own set of tables. But if we start using virtual addressing, we have to use it for all programs running on the computer - including the kernel itself. Therefore, part of the virtual address space must be reserved for the kernel.
This does not mean that the kernel uses so much physical memory - it just has at its disposal part of the address space that can be matched to the required amount of physical memory. The memory space for the kernel is marked in the page tables as being exclusively used by privileged code, so if a program tries to access it, a page fault occurs. On Linux, memory space for the kernel is always present, and maps the same part of the physical memory of all processes. Kernel code and data always have addresses, and are ready to handle interrupts and system calls at any time. For user programs, on the contrary, the correspondence of the virtual addresses of real memory changes when process switching occurs:
Virtual addresses corresponding to physical memory are marked in blue. White is a space to which no addresses are assigned. In our example, Firefox uses much more virtual memory because of its legendary gluttony. The strips in the address space correspond to memory segments such as heap, stack, and so on. These segments are just memory address ranges, and have nothing to do with Intel segments. Here is the standard segment diagram for a process under Linux:
When programming was white and fluffy, the initial virtual addresses of the segments were the same for all processes. This made it easy to remotely exploit security vulnerabilities. A malicious program often needs to access memory at absolute addresses - the address of the stack, the address of the library function, etc. Remote attacks had to be done blindly, relying on the fact that all address spaces remain at constant addresses. In this regard, the random address selection system has gained popularity. Linux randomizes the stack, memory segment, and heap by adding offsets to their starting addresses. Unfortunately, you won’t be especially deployed in the 32-bit address space, and there is not enough space left for assigning random addresses, which makes this system not very efficient.
The topmost segment in the process address space is the stack, which in most languages stores local variables and function arguments. A method or function call adds a new stack frame to an existing stack. After returning from the function, the frame is destroyed. This simple scheme leads to the fact that to track the contents of the stack does not require any complex structure - just a pointer to the beginning of the stack. Adding and removing data becomes a simple and straightforward process. The constant reuse of memory areas for the stack leads to caching of these parts in the CPU, which adds speed. Each thread in the process gets its own stack.
You can come to a situation in which the memory allocated for the stack ends. This results in a page fault error, which is handled by the expand_stack () function on Linux, which in turn calls acct_stack_growth () to check if the stack can still be expanded. If its size does not exceed RLIMIT_STACK (usually it is 8 MB), then the stack grows and the program continues execution, as if nothing had happened. But if the maximum stack size is reached, we get a stack overflow and the program receives a Segmentation Fault error (segmentation error). At the same time, the stack can only grow - like the state budget, it does not decrease back.
Dynamic stack growth is the only situation in which free memory can be accessed, which is shown in white in the diagram. All other attempts to access this memory cause a page fault error, resulting in a Segmentation Fault. And some occupied memory areas are read-only, so trying to write to these areas also leads to Segmentation Fault.
After the stack there is a segment of mapping into memory. Here the kernel places the contents of files directly in memory. Any application can request to do this through the mmap () system call on Linux or CreateFileMapping () / MapViewOfFile () on Windows. This is a convenient and quick way to organize file input and output operations, so it is used to load dynamic libraries. It is also possible to create an anonymous memory location not associated with files that will be used for program data. If you query Linux for a large amount of memory through malloc (), the C library will create such an anonymous mapping instead of using memory from the heap. “Big” means a volume larger than MMAP_THRESHOLD (128 kB by default, it is configured through mallopt ().)
The heap itself is located in the following positions in memory. It provides memory allocation during program execution, as does the stack - but, unlike it, it stores the data that must survive the function that hosts them. Most languages have heap management tools. In this case, the satisfaction of the memory allocation request is performed jointly by the program and the kernel. In With the interface, malloc () is used to work with the heap with friends, and in a language that has automatic garbage collection, such as C #, the new keyword is the interface.
If there is not enough space on the heap to execute the request, the program itself can handle this problem without kernel intervention. Otherwise, the heap is increased by the brk () system call. Managing a bunch is a complicated business; it requires sophisticated algorithms that strive to work quickly and efficiently in order to cater to the chaotic data placement method used by the program. The time it takes to process a request to the heap can vary widely. In real-time systems, there are special tools for working with it. Heaps can also be fragmented:
And so we got to the very bottom of the diagram - BSS, data and program text. BSS and data store static (global) variables in C. The difference is that BSS stores the contents of uninitialized static variables whose values were not set by the programmer. In addition, the BSS area is anonymous; it does not correspond to any file. If you write
static int cntActiveUsers, the contents of cntActiveUsers live in BSS. The data segment, on the contrary, contains those variables that were initialized in the code. This part of the memory corresponds to the binary image of the program containing the initial static values specified in the code. If you write
static int cntWorkerBees = 10, then the content of cntWorkerBees lives in the data segment, and begins its life as 10. But, although the data segment corresponds to the program file, it is a private memory mapping — which means that memory updates are not reflected in the corresponding file. Otherwise, changes in the value of the variables would be reflected in a file stored on disk.The sample data in the chart will be a little more complicated as it uses a pointer. In this case, the contents of the pointer, a 4-byte memory address, live in the data segment. And the line he points to lives in a segment of text that is read-only. All code and various other details are stored there, including string literals. It also stores your binary in memory. Attempts to write to this segment result in a Segmentation Fault error. This prevents pointer errors (although not as efficient as if you hadn’t used C at all). The diagram shows these segments and examples of variables:
You can examine the memory areas of a Linux process by reading the file / proc / pid_of_process / maps. Note that a single segment may contain many areas. For example, each file duplicated into memory has its own area in the mmap segment, while dynamic libraries have additional areas that resemble BSS and data. By the way, sometimes when people say “data segment”, they mean data + bss + heap.
Binary images can be studied using the nm and objdump commands - you will see characters, their addresses, segments, etc. The virtual address scheme described in this article is the so-called “Flexible” scheme, which has been used by default for several years already. It implies that some value is assigned to the RLIMIT_STACK variable. Otherwise, Linux uses the “classic” scheme: