High-load distributed control system of a modern NPP
Without electricity there will not be high-loaded Internet services that we love so much. Strangely enough, control systems of objects of generation of electricity, for example atomic power stations, are also distributed, are also subject to high loads, also require a variety of technologies. In addition, the share of nuclear energy in the world will grow, the management of these facilities and their safety is a very important topic.
Therefore, let's understand what is there, how it is all arranged, where the main architectural difficulties are and where modern ML and VR technologies can be applied in NPPs.

Nuclear power plant is:
About the speaker: Vadim Podolny ( electrovenic ) represents the Moscow factory Fizpribor. This is not just a factory - it is primarily an engineering bureau, which develops both hardware and software. The name is a tribute to the history of the company, which has existed since 1942. This is not very fashionable, but very reliable - that's what they wanted to say.
Fizpribor enterprise produces the full range of equipment that is needed to interface all the huge number of subsystems - these are sensors, low-level automation controllers, platforms for building low-level automation controllers, etc.
In a modern design, the controller is just an industrial server that has an expanded number of input ports output for interfacing equipment with special subsystems. These are huge cabinets - the same as server cabinets, only they have special controllers that provide calculations, collection, processing, control.
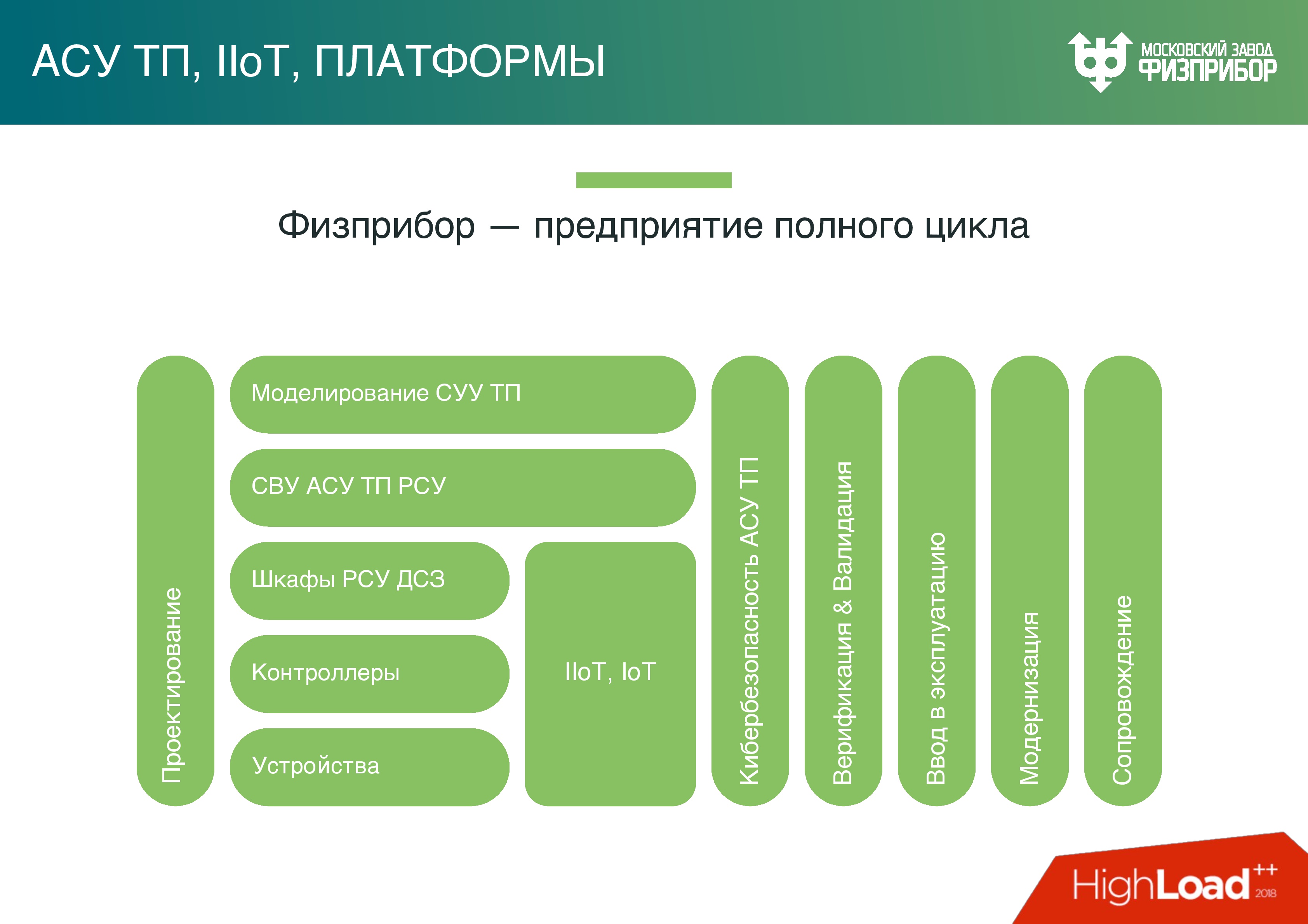
We are developing software that is installed on these controllers on gateway equipment. Further, as well as everywhere else, we have data centers, a local cloud in which calculation, processing, decision making, forecasting takes place, and everything that is necessary for the control object to function.
It should be noted that in our age the equipment decreases, it becomes smarter. On many pieces of equipment, there are already microprocessors — small computers that provide pre-processing, as it is now fashionable to call it — boundary calculations that are made in order not to load the overall system. Therefore, we can say that the modern automated process control system of nuclear power plants is already something like the industrial Internet of things.
The platform that manages this is the IoT platform that many have heard about. There are now a considerable number of them, ours is very tightly tied to real time.
On top of this, end-to-end verification and validation mechanisms are built to ensure compatibility and reliability checks. It also includes load testing, regression testing, unit testing - everything you know. Only this is done with the hardware that we have designed and developed, and the software that works with this hardware. Cybersecurity issues are being addressed (secure by design, etc.).

The figure shows the processor modules that control the controllers. This is a 6-unit platform with a chassis for accommodating motherboards on which we make surface mounting of the equipment we need, including processors. Now we have a wave of import substitution, we are trying to support domestic processors . Someone says that as a result, the security of industrial systems will increase. This is true, a little later I will explain why.
Any automated process control system at nuclear power plants is reserved as a safety system. The power unit of the nuclear power plant is designed for the fact that an aircraft can fall on it. The safety system must ensure the emergency cooling down of the reactor in order to prevent it from melting due to residual heat generation due to beta decay, as happened at the Fukushima nuclear power plant. There was no security system there, a wave of backup diesel generators washed away, and what happened happened. This is impossible at our NPPs because our security systems are located there.
In fact, we are debugging one or more control algorithms that can be combined into a functional-group algorithm, and we solder this whole story directly onto a board without a microprocessor, that is, we get hard logic. If sometime some element of the equipment needs to be replaced, the settings or parameters will change, and it will be necessary to make changes to the algorithm of its operation - yes, you will have to remove the board, on which the algorithm is soldered, and install a new one. But it is safe - expensive, but safe .

Below is an example of a triple divers protection system on which the algorithm for solving one security system task in the two out of three versions is performed. There are three out of four - it's like a RAID.

First, it is important to use different processors. If we make a cross-platform system and type the general system from modules running on different processors, then if malicious software gets into the system at some of the stages of the life cycle (design, development, preventive maintenance), then it will not immediately amaze all the divers' variety of technology.

There is also a quantitative variety . The view of the fields from the satellite reflects the model well, when we maximize the variety of crops in terms of budget, space, understanding and operation, we realize redundancy, copying systems as much as possible.
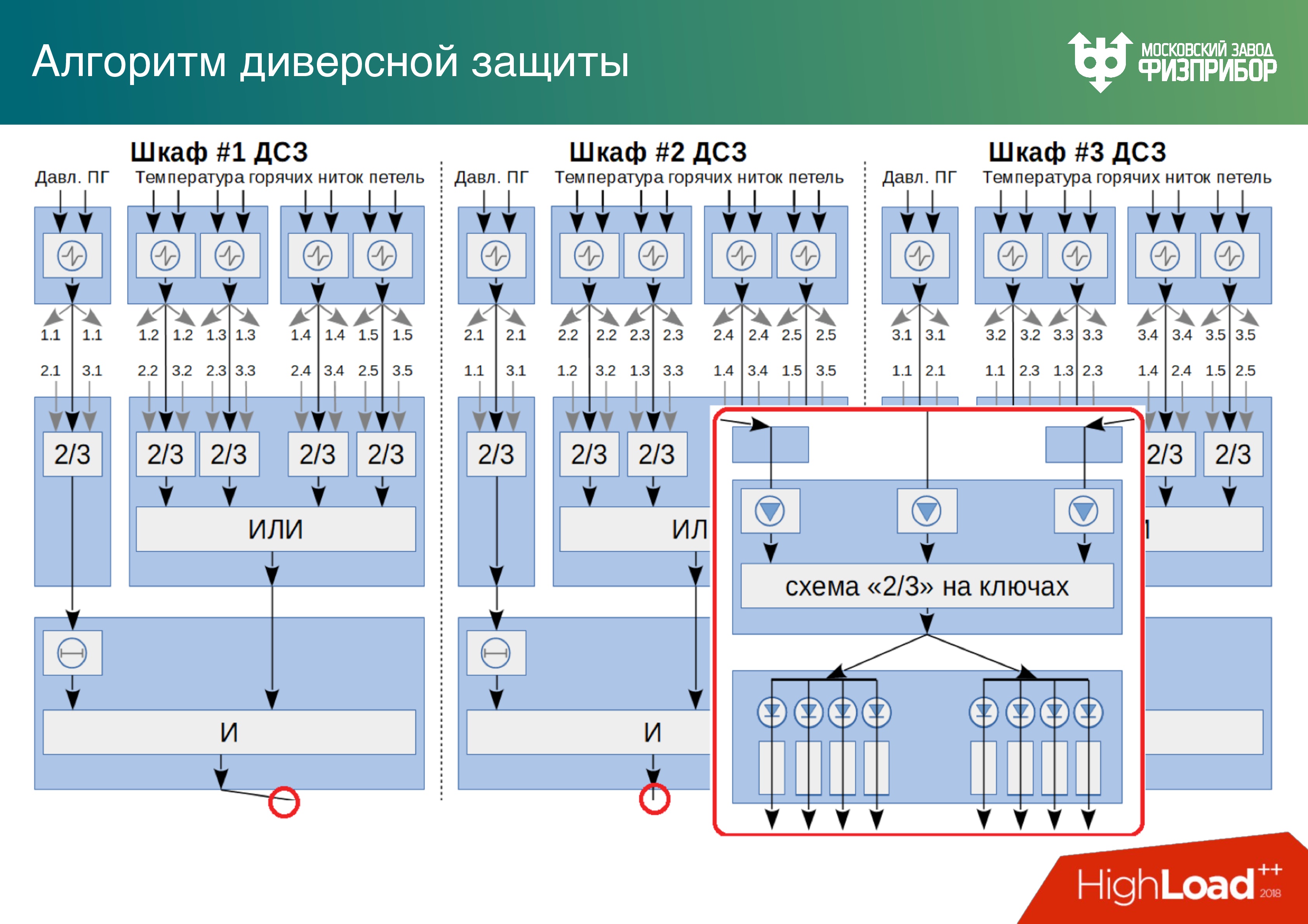
Below is an exemplary algorithm for selecting a solution based on a triple system of divers protection. The algorithm is considered correct based on two of the three responses. We believe that if one of the cabinets fails, we will, firstly, find out about it, and secondly, the other two will work normally. Such cabinets on nuclear power plants whole fields.

We talked about iron, let's move on to what's more interesting for everyone - to the software.
Software. Vershok and Spine
This is how the monitoring system of these cabinets looks like.

The upper level system (after low-level automation) ensures reliable collection, processing, and delivery of information to the operator and other interested services. It must first of all solve the main task - at the time of peak loads be able to handle everything, so in normal operation the system can be loaded by 5-10%. The remaining capacities are actually idling and are designed so that in the event of a contingency, we can balance, distribute and process all overloads.
The most typical example is the turbine. It gives the most information, and if it starts working unstable, DDoS actually happens, because the entire information system is clogged with diagnostic information from this turbine. In the event that QoS does not work well, serious problems may arise: the operator simply will not see some of the important information.
In fact, everything is not so scary. The operator can work on the physical reactimeter for 2 hours, but at the same time lose some equipment. To prevent this from happening, we are developing our new software platform. The previous version now serves 15 power units built in Russia and abroad.

The software platform is a cross-platform microservice architecture.which consists of several layers:
There are several options for client nodes:
Based on these nodes, we are building a cloud . It consists of classic reliable servers that are managed using common operating systems. We use mostly Linux, sometimes QNX.
The cloud is sliced into virtual machines, containers are running somewhere. As part of container virtualization, various types of nodes are launched that, if necessary, perform different tasks. For example, you can run a report generator once a day, when all the necessary reporting materials for the day will be ready, virtual machines will be unloaded, and the system will be ready for other tasks.
We called our system Vershok , and the core of the root system is clear why.

Having enough powerful computing resources on gateway controllers, we thought - why not use their power not only for preprocessing? We can turn this cloud and all border nodes into a fog, and load these powers with tasks, for example, such as detecting errors.

Sometimes it happens that the sensors have to be tared. Over time, the readings are floating, we know on which schedule in time they change their readings, and instead of changing these sensors, we update the data and make corrections - this is called sensor calibration.
We got a full Fog platform. Yes, it performs a limited number of tasks in the fog, but we will gradually increase their number and unload the common cloud.
In addition, we have a computing core. We enable the scripting language, we can work with Lua, with Python (for example, with the PyPy library), with JavaScript and TypeScript to solve problems with user interfaces. We can perform these tasks equally well both inside the cloud and at the boundary nodes. Each microservice can run on a processor of absolutely any amount of memory and of any capacity. It will simply process the amount of information that is possible at current capacities. But the system works equally well on any node. It is also suitable for placement on simple IoT devices.
Now, information from several subsystems gets into this platform: the level of physical protection, access control systems, information from video cameras, fire safety data, automated process control systems, IT infrastructures, information security events.
On the basis of this data, Behavior Analytics - behavioral analytics is built. For example, the operator cannot be logged in if the camera has not recorded that he has passed into the camera room. Or another case: we see that some communication channel is not working, while fixing that at this point in time the temperature of the rack has changed, the door has been opened. Someone came in, opened the door, pulled out or touched the cable. This, of course, should not be, but it is still necessary to monitor it. It is necessary to describe as many cases as possible so that when something suddenly happens, we know for sure.

The above examples of the equipment on which it all works, and its parameters:
Our controller works with passive cooling , and from our point of view it is much more reliable, so we try to transfer the maximum number of tasks to systems with passive cooling. Any fan will fail at some point, and the service life of a nuclear power plant is 60 years with the possibility of extension to 80. It is clear that scheduled preventive repairs will be made during this time, the equipment will be replaced. But if you now take an object that was launched in the 90s or in the 80s, then it is even impossible to find a computer to run the software that works there. Therefore, everything has to be rewritten and changed, including algorithmic.
Our services operate in Multi-Master mode, there is no single point of failure, it’s all cross-platform. Nodes are self-defined, you can do Hot Swap, due to which you can add and change equipment, and there is no dependence on the failure of one or several elements.

There is such a thing as a degradation of the system . To a certain extent, the operator should not notice that something is wrong with the system: the processor module burned down, or the server power supply was lost and it turned off; The communication channel has rebooted because the system can not cope. These and similar problems are solved by backing up all the components and the network. Now we have a double star topology and mesh. If a node fails, the topology of the system allows you to continue normal operation.

These are comparisons of the Supermicro parameters (above) and our controller (below), which we get from updates on the real-time database. Figures 4 and 8 are the number of replicas, that is, the database maintains the current state of all nodes in real time — this is multicast and real-time. In the test configuration, there are approximately 10 million tags, that is, sources of signal changes.
Supermicro shows an average of 7 M / c or 5 M / s, with an increase in the number of replicas. We are fighting not to lose the power of the system, with an increase in the number of nodes. Unfortunately, when the need arises to handle setpoints and other parameters, we lose speed with an increase in the number of nodes, but the more nodes, the smaller the losses.
On our controller (on Atom), the parameters are a whole order less.
The user for the construction of the trend displays a set of tags. Below is a touch-oriented interface for the operator in which he can select options. Each client node has a copy of the database. The developer of the client application works with local memory and does not think about data synchronization over the network, it simply does Get, Set through the API.
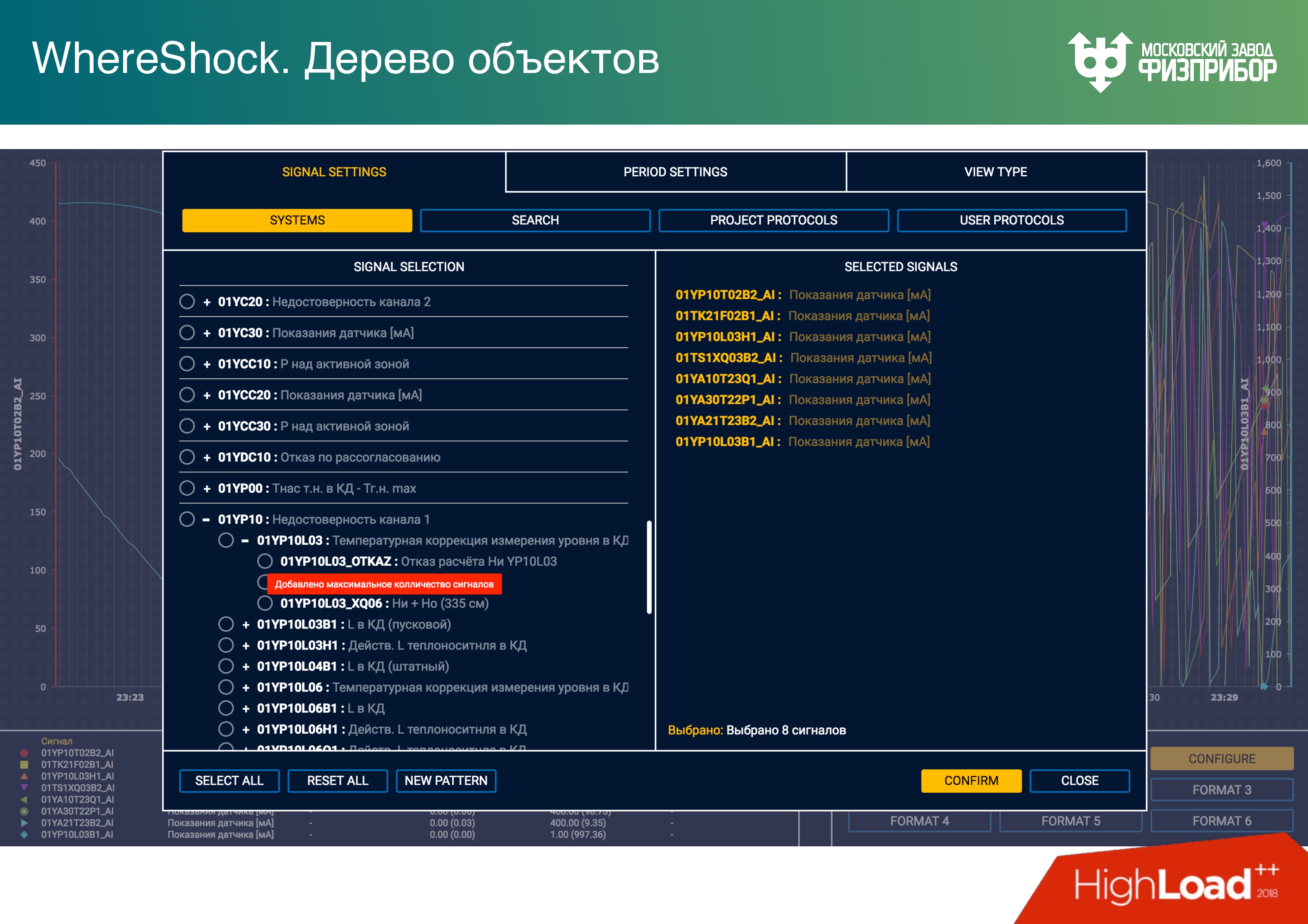
The development of the client interface of the automated process control system is no more difficult than the development of the site. Previously, we fought for real-time on the client, used C ++, Qt. Now we have abandoned this and done everything on Angular. Modern processors allow you to maintain the reliability of such applications. The web is already quite reliable, although the memory, of course, floats.
The task to ensure the operation of the application for a year without restarting is no longer relevant. All this is packaged in Electron. and in fact gives platform independence, that is, the ability to run the interface on tablets and panels.
Anxiety
An alarm is the only dynamic object that appears in the system. After the system is started, the entire tree of objects is fixed, nothing can be removed from there. That is, the CRUD model does not work, you can only make a mark “mark as deleted”. If you need to delete a tag, it is simply marked and hidden from all, but not deleted, because the delete operation is complex and can damage the state of the system, its integrity.
An alarm is a certain object that appears when the signal parameter from a particular equipment goes beyond the limits of the settings. Setpoints are the lower and upper warning limits of values: emergency, critical, supercritical, etc. When a parameter falls into a certain scale value, the corresponding alarm appears.
The first question that arises when an alarm occurs, to whom to show a message about it. Show alarm to two operators? But our system is universal, there may be more operators. At the NPP, “slightly” the databases of the turbinist and the reactor man differ, because the equipment is different. It is clear, of course, if the signal level went beyond the limits in the reactor compartment, then it will be seen by the lead reactor control engineer, by the turbine in the turbine.
But imagine that there are a lot of operators. Then the alarm can not be shown to everyone. Or if someone takes it for handshaking, it should be immediately blocked for handshaking on all other nodes. This is a real-time operation, and when the two operators take to acknowledge the same alarm, they will immediately begin to control the equipment and algorithms. All this is connected with network multi-threaded programming and can lead to serious system conflicts. Therefore, any dynamic object needs to be shown, allowed to manage and “extinguish” the alarm only to one operator.
Moreover, all alarms depend on each other. Some equipment starts to “fail” - a thousand alarms pop up. In fact, in order to extinguish them all, you need to find only one of them, acknowledge it, and then the “tree” of the remaining alarms disappears. This is a separate science and we are working on how to represent such anxieties. There is no consensus yet: either a tree or hide as an attachment. Now the alarm module looks like this, with nested data.
I give examples of video frames that the operator sees for a general presentation.

Yellow links - transitions to other video frames.
We have a stand at the factory. Dashboards look like this on the panel, the operator is about the same.

system configuration
We provide a fairly universal database mode.

The editor that allows you to create objects, delete them, set parameters that are transferred to the real-time database and metadata database.
Video frames are user interface elements with the most problems. Each SCADA / HMI vendor tries to make its editor, and then, when the developers quit, you won’t find any ends - bugs appear, everything falls, it is impossible to manage. We are tired of it, so we decided: “Do what you want! Though on Illustrator, at least in Sketch - in any program that will issue the canonical SVG. ” We give the opportunity to open SVG and attach it to the tags BDRV. If the primitives in the editor are correctly called, then nothing else is needed and everything will work fine right away.
Creating a user interface in a process control system or platform looks no more difficult than creating a website. We give all the necessary APIs to make it so. No other system, which is currently used at such facilities, does not work this way, everywhere there are complex editors and poor interfaces. Imagine what the operators who look at them every day. Of course, many people think that it’s not as important as it looks, the main thing is safety. But we want it to look beautiful, because, in our opinion, this is important.
Like everywhere else, we have an access control system . We support several modes to be reliable and cheap. In addition to container and conventional virtualization, we give the opportunity to make Data Lake. Then all fit into one large RAM, and the modemultitenancy provides the ability to share access to elements of the tree (objects, data). Therefore, it is possible to keep several projects on actually quite inexpensive hardware.
Also, the more iron, the more expensive the synchronization and the more likely the error. Therefore, if we can simply copy this base on more nodes, even in this mode, the total reliability of the entire system grows .
Moreover, it should be noted one thing: in real time and a large number of objects in memory, we can not work with the processor cache. It turned into a pumpkin, because when you need to provide navigation and search for 10 or 100 million objects, then there is no cache — all by hand.
Forecasting
We make predictive analytics using neural networks, machine learning. I'll tell you how it works and how much it costs in money.
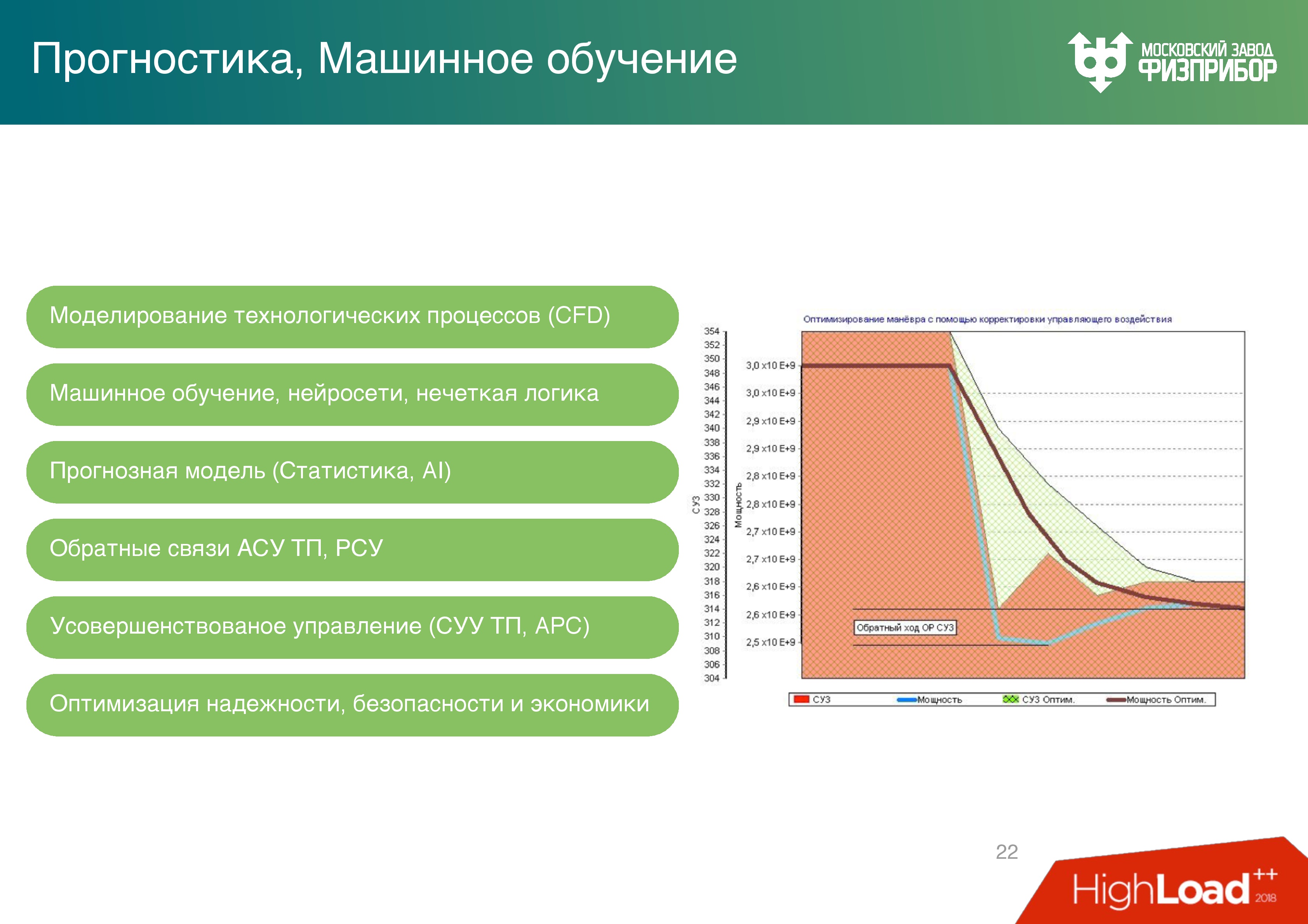
On the right is a graph of the change in reactor power during the movement of the regulatory control system of the protection control system - control rods. In general, the reactor is governed by the concentration of boric acid in water, but when power maneuvers are made, rods are used. Each movement of the rods is fuel burns, and the fuel is quite expensive: the load on the modern VVER-1200 reactor is about 10 tons of uranium dioxide.
The graph, which gives a return, shows how the operator manages everything manually, that is, changes the power parameters, sees that the power is slightly lower than necessary, slightly adds, etc. ... Focusing on the feedback, the operator eventually brings the power to the desired level
We trained the neural network in the previous testimony. But just a neural network will never exactly predict the physical process. There are 5 physical processes in the reactor: neutron kinetics, hydrodynamics, chemistry and radiochemistry due to various transformations, and physics of strength. Any calculation looks like a simulation of each of this process.
Basically there are two methods:
These methods are extremely slow, they cannot be used in a real-time system. We increased the space-time step, and made the adjustment on neural networks, and got quite a serious optimization (the upper graph). Now there is no need to reverse the rods.
According to the calculated characteristics, optimizing for the absence of a reverse stroke will save up to $ 60 million per year for a three-year fuel campaign (this means that every year a third of the fuel changes). This is a good figure for the total KPI of employees who work on the unit.
Remote Control
The usual block control panel looks like this.

On the left - Novovoronezh NPP, on the right - Kalinin NPP and model.
But we went further. Block control panel is a very expensive story. There are many developers who produce both hardware and software, which comes down to it - these are dozens and hundreds of companies. We made a cameraman , loaded our system into it.

You put on glasses and get the same picture as on the block, only without a shield. There used to be a control room (control unit block) - the operator walked, twisted some pieces. Then they put a computer to him, he looked at it, but still got up to the shield and twisted. Then we made the ability to control from the monitor - the control room (control unit), and now - the control unit (virtual control unit), for which the future.
Although the future, of course, is behind the unit without operators — artificial intelligence. The operator will become a supervisor. Then it will be possible to control the entire station entirely from the common control panel. And then the operator will be able to be outside the plant.
Such an ITER project is already being implemented . The station itself is located in the city of Cadarache in France, and the control panel is in Japan in the city of Rokasho. This is done to debug technologies, using quantum communication and quantum cryptography. You can say the future is here!
Therefore, let's understand what is there, how it is all arranged, where the main architectural difficulties are and where modern ML and VR technologies can be applied in NPPs.
Nuclear power plant is:
- On average, 3-4 power units with an average capacity of 1000 MW per NPP, because physical systems must be backed up, as well as services on the Internet.
- About 150 special subsystems that ensure the functioning of this object. For example, it is an in-reactor control system, a turbine control system, a water cleaning control system, etc. Each of these subsystems is integrated into a huge system of the upper block level (AHU) of an automated process control system (ACS TP).
- 200-300 thousand tags, that is, sources of signals that change in real time. We need to understand what is a change, what is not, whether we have missed something, and if we missed, then what to do with it. These parameters are monitored by two operators, the lead reactor control engineer (VIUR) and the lead turbine control engineer (VIUT).
- Two buildings in which most subsystems are concentrated: the reactor and turbine compartments. Two people have to make a decision in real time if non-standard, or standard, events occur. Such a high responsibility is imposed on only two people, because if there are more of them, they will have to agree among themselves.
About the speaker: Vadim Podolny ( electrovenic ) represents the Moscow factory Fizpribor. This is not just a factory - it is primarily an engineering bureau, which develops both hardware and software. The name is a tribute to the history of the company, which has existed since 1942. This is not very fashionable, but very reliable - that's what they wanted to say.
IIoT at nuclear power plants
Fizpribor enterprise produces the full range of equipment that is needed to interface all the huge number of subsystems - these are sensors, low-level automation controllers, platforms for building low-level automation controllers, etc.
In a modern design, the controller is just an industrial server that has an expanded number of input ports output for interfacing equipment with special subsystems. These are huge cabinets - the same as server cabinets, only they have special controllers that provide calculations, collection, processing, control.
We are developing software that is installed on these controllers on gateway equipment. Further, as well as everywhere else, we have data centers, a local cloud in which calculation, processing, decision making, forecasting takes place, and everything that is necessary for the control object to function.
It should be noted that in our age the equipment decreases, it becomes smarter. On many pieces of equipment, there are already microprocessors — small computers that provide pre-processing, as it is now fashionable to call it — boundary calculations that are made in order not to load the overall system. Therefore, we can say that the modern automated process control system of nuclear power plants is already something like the industrial Internet of things.
The platform that manages this is the IoT platform that many have heard about. There are now a considerable number of them, ours is very tightly tied to real time.
On top of this, end-to-end verification and validation mechanisms are built to ensure compatibility and reliability checks. It also includes load testing, regression testing, unit testing - everything you know. Only this is done with the hardware that we have designed and developed, and the software that works with this hardware. Cybersecurity issues are being addressed (secure by design, etc.).
The figure shows the processor modules that control the controllers. This is a 6-unit platform with a chassis for accommodating motherboards on which we make surface mounting of the equipment we need, including processors. Now we have a wave of import substitution, we are trying to support domestic processors . Someone says that as a result, the security of industrial systems will increase. This is true, a little later I will explain why.
Safety system
Any automated process control system at nuclear power plants is reserved as a safety system. The power unit of the nuclear power plant is designed for the fact that an aircraft can fall on it. The safety system must ensure the emergency cooling down of the reactor in order to prevent it from melting due to residual heat generation due to beta decay, as happened at the Fukushima nuclear power plant. There was no security system there, a wave of backup diesel generators washed away, and what happened happened. This is impossible at our NPPs because our security systems are located there.
The basis of security systems is hard logic.
In fact, we are debugging one or more control algorithms that can be combined into a functional-group algorithm, and we solder this whole story directly onto a board without a microprocessor, that is, we get hard logic. If sometime some element of the equipment needs to be replaced, the settings or parameters will change, and it will be necessary to make changes to the algorithm of its operation - yes, you will have to remove the board, on which the algorithm is soldered, and install a new one. But it is safe - expensive, but safe .
Below is an example of a triple divers protection system on which the algorithm for solving one security system task in the two out of three versions is performed. There are three out of four - it's like a RAID.
Technological diversity
First, it is important to use different processors. If we make a cross-platform system and type the general system from modules running on different processors, then if malicious software gets into the system at some of the stages of the life cycle (design, development, preventive maintenance), then it will not immediately amaze all the divers' variety of technology.
There is also a quantitative variety . The view of the fields from the satellite reflects the model well, when we maximize the variety of crops in terms of budget, space, understanding and operation, we realize redundancy, copying systems as much as possible.
Below is an exemplary algorithm for selecting a solution based on a triple system of divers protection. The algorithm is considered correct based on two of the three responses. We believe that if one of the cabinets fails, we will, firstly, find out about it, and secondly, the other two will work normally. Such cabinets on nuclear power plants whole fields.
We talked about iron, let's move on to what's more interesting for everyone - to the software.
Software. Vershok and Spine
This is how the monitoring system of these cabinets looks like.
The upper level system (after low-level automation) ensures reliable collection, processing, and delivery of information to the operator and other interested services. It must first of all solve the main task - at the time of peak loads be able to handle everything, so in normal operation the system can be loaded by 5-10%. The remaining capacities are actually idling and are designed so that in the event of a contingency, we can balance, distribute and process all overloads.
The most typical example is the turbine. It gives the most information, and if it starts working unstable, DDoS actually happens, because the entire information system is clogged with diagnostic information from this turbine. In the event that QoS does not work well, serious problems may arise: the operator simply will not see some of the important information.
In fact, everything is not so scary. The operator can work on the physical reactimeter for 2 hours, but at the same time lose some equipment. To prevent this from happening, we are developing our new software platform. The previous version now serves 15 power units built in Russia and abroad.
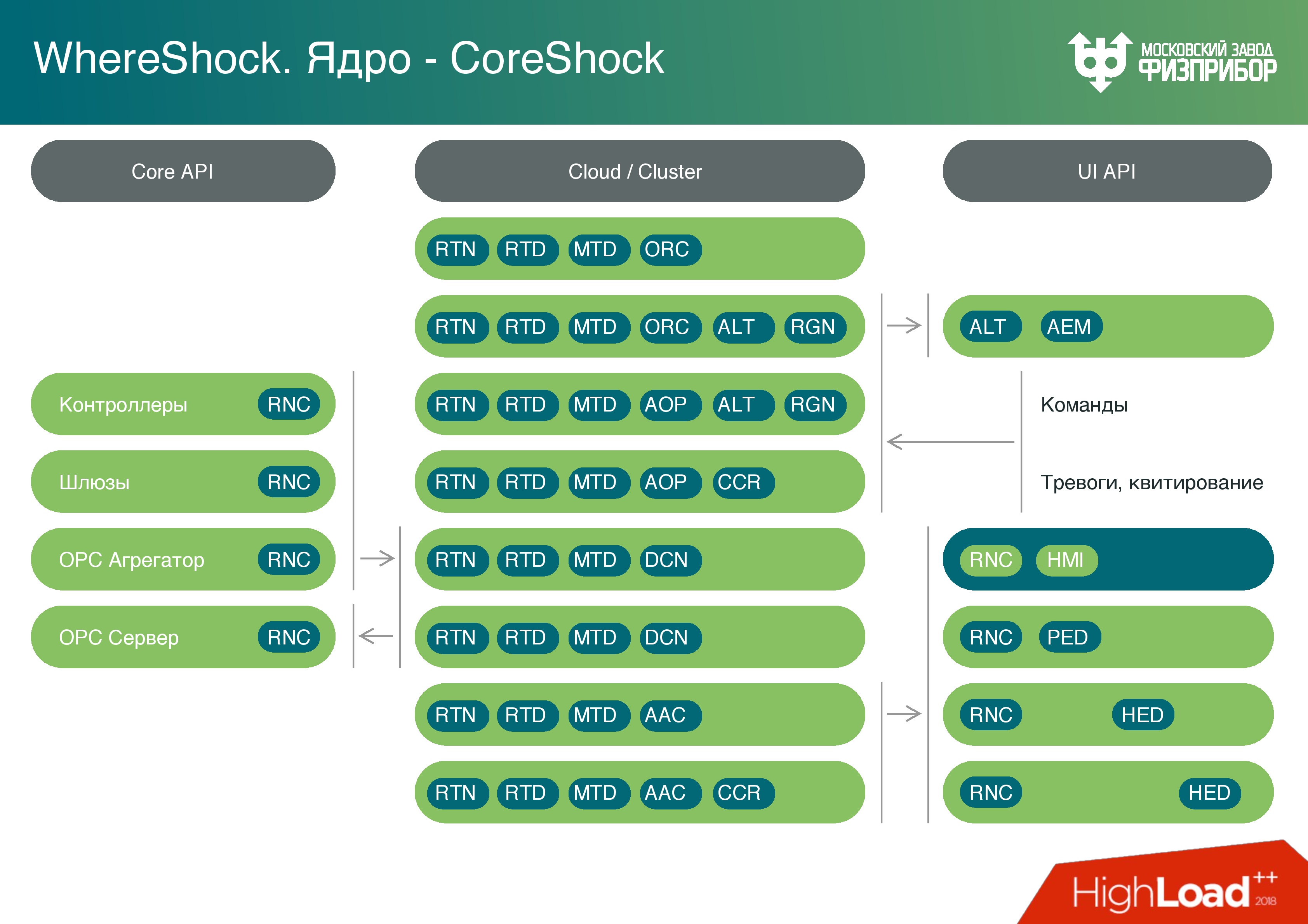
The software platform is a cross-platform microservice architecture.which consists of several layers:
- The data layer is a real-time database. It is very simple - something like Key-value, but value can only be double. No other objects are stored there to completely remove the possibility of buffer overflow, stack or something else.
- Separate database to store metadata. We use PostgreSQL and other technologies, in principle, any technology is configured, because there is no hard real time.
- Archive layer This is an online archive (approximately 24 hours) for processing current information and, for example, reports.
- Long-term archive.
- An emergency archive is a black box that will be used if an accident occurs and the long-term archive is damaged. Key indicators, alarms, alarm acknowledgment are recorded in it ( acknowledgment means that the operator saw the alarm and something starts to be done ).
- The logical layer in which the script execution language is located. The computational core is based on it, and after the computational core, just like the module, a report generator is located. Nothing unusual: you can print a graph, make a request, see how the parameters have changed.
- The client layer is a node that allows you to develop client services based on code, contains an API.
There are several options for client nodes:
- Optimized to write . It develops device drivers, but this is not a classic driver. This is a program that collects information from the low-level automation controllers, carries out preliminary processing, parses all the information and any protocols through which the low-level automation equipment operates - OPC, HART, UART, Profibus.
- Optimized for reading - for building user interfaces, handlers and everything that goes on.
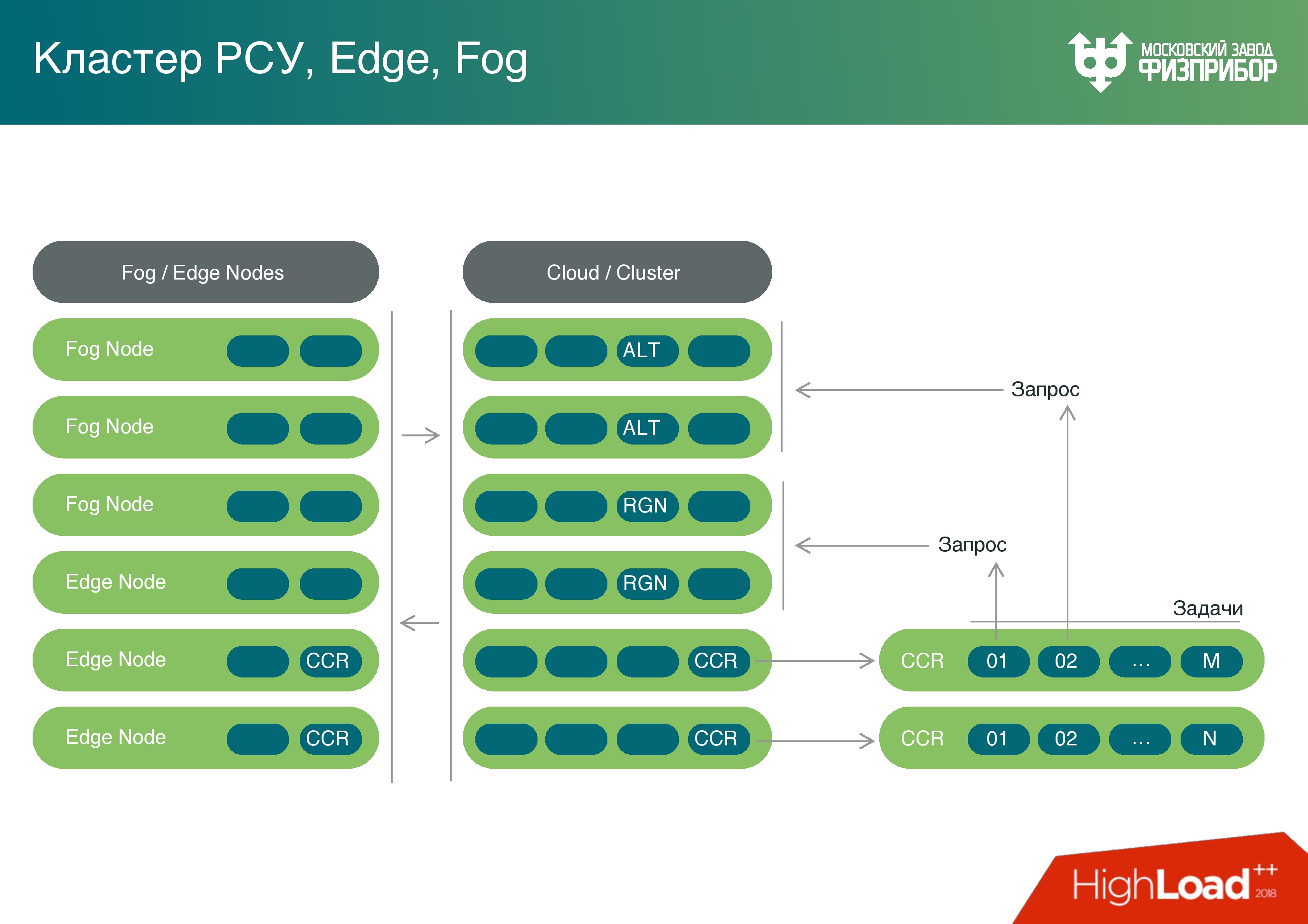
Based on these nodes, we are building a cloud . It consists of classic reliable servers that are managed using common operating systems. We use mostly Linux, sometimes QNX.
The cloud is sliced into virtual machines, containers are running somewhere. As part of container virtualization, various types of nodes are launched that, if necessary, perform different tasks. For example, you can run a report generator once a day, when all the necessary reporting materials for the day will be ready, virtual machines will be unloaded, and the system will be ready for other tasks.
We called our system Vershok , and the core of the root system is clear why.
Having enough powerful computing resources on gateway controllers, we thought - why not use their power not only for preprocessing? We can turn this cloud and all border nodes into a fog, and load these powers with tasks, for example, such as detecting errors.
Sometimes it happens that the sensors have to be tared. Over time, the readings are floating, we know on which schedule in time they change their readings, and instead of changing these sensors, we update the data and make corrections - this is called sensor calibration.
We got a full Fog platform. Yes, it performs a limited number of tasks in the fog, but we will gradually increase their number and unload the common cloud.
In addition, we have a computing core. We enable the scripting language, we can work with Lua, with Python (for example, with the PyPy library), with JavaScript and TypeScript to solve problems with user interfaces. We can perform these tasks equally well both inside the cloud and at the boundary nodes. Each microservice can run on a processor of absolutely any amount of memory and of any capacity. It will simply process the amount of information that is possible at current capacities. But the system works equally well on any node. It is also suitable for placement on simple IoT devices.
Now, information from several subsystems gets into this platform: the level of physical protection, access control systems, information from video cameras, fire safety data, automated process control systems, IT infrastructures, information security events.
On the basis of this data, Behavior Analytics - behavioral analytics is built. For example, the operator cannot be logged in if the camera has not recorded that he has passed into the camera room. Or another case: we see that some communication channel is not working, while fixing that at this point in time the temperature of the rack has changed, the door has been opened. Someone came in, opened the door, pulled out or touched the cable. This, of course, should not be, but it is still necessary to monitor it. It is necessary to describe as many cases as possible so that when something suddenly happens, we know for sure.
The above examples of the equipment on which it all works, and its parameters:
- On the left is the normal Supermicro server. The choice fell on Supermicro, because with it all the capabilities of iron are immediately available, the use of domestic equipment is possible.
- On the right - the controller, which is produced in our factory. We completely trust him and understand what is happening there. On the slide, it is fully loaded with computing modules.
Our controller works with passive cooling , and from our point of view it is much more reliable, so we try to transfer the maximum number of tasks to systems with passive cooling. Any fan will fail at some point, and the service life of a nuclear power plant is 60 years with the possibility of extension to 80. It is clear that scheduled preventive repairs will be made during this time, the equipment will be replaced. But if you now take an object that was launched in the 90s or in the 80s, then it is even impossible to find a computer to run the software that works there. Therefore, everything has to be rewritten and changed, including algorithmic.
Our services operate in Multi-Master mode, there is no single point of failure, it’s all cross-platform. Nodes are self-defined, you can do Hot Swap, due to which you can add and change equipment, and there is no dependence on the failure of one or several elements.
There is such a thing as a degradation of the system . To a certain extent, the operator should not notice that something is wrong with the system: the processor module burned down, or the server power supply was lost and it turned off; The communication channel has rebooted because the system can not cope. These and similar problems are solved by backing up all the components and the network. Now we have a double star topology and mesh. If a node fails, the topology of the system allows you to continue normal operation.
These are comparisons of the Supermicro parameters (above) and our controller (below), which we get from updates on the real-time database. Figures 4 and 8 are the number of replicas, that is, the database maintains the current state of all nodes in real time — this is multicast and real-time. In the test configuration, there are approximately 10 million tags, that is, sources of signal changes.
Supermicro shows an average of 7 M / c or 5 M / s, with an increase in the number of replicas. We are fighting not to lose the power of the system, with an increase in the number of nodes. Unfortunately, when the need arises to handle setpoints and other parameters, we lose speed with an increase in the number of nodes, but the more nodes, the smaller the losses.
On our controller (on Atom), the parameters are a whole order less.
The user for the construction of the trend displays a set of tags. Below is a touch-oriented interface for the operator in which he can select options. Each client node has a copy of the database. The developer of the client application works with local memory and does not think about data synchronization over the network, it simply does Get, Set through the API.
The development of the client interface of the automated process control system is no more difficult than the development of the site. Previously, we fought for real-time on the client, used C ++, Qt. Now we have abandoned this and done everything on Angular. Modern processors allow you to maintain the reliability of such applications. The web is already quite reliable, although the memory, of course, floats.
The task to ensure the operation of the application for a year without restarting is no longer relevant. All this is packaged in Electron. and in fact gives platform independence, that is, the ability to run the interface on tablets and panels.
Anxiety
An alarm is the only dynamic object that appears in the system. After the system is started, the entire tree of objects is fixed, nothing can be removed from there. That is, the CRUD model does not work, you can only make a mark “mark as deleted”. If you need to delete a tag, it is simply marked and hidden from all, but not deleted, because the delete operation is complex and can damage the state of the system, its integrity.
An alarm is a certain object that appears when the signal parameter from a particular equipment goes beyond the limits of the settings. Setpoints are the lower and upper warning limits of values: emergency, critical, supercritical, etc. When a parameter falls into a certain scale value, the corresponding alarm appears.
The first question that arises when an alarm occurs, to whom to show a message about it. Show alarm to two operators? But our system is universal, there may be more operators. At the NPP, “slightly” the databases of the turbinist and the reactor man differ, because the equipment is different. It is clear, of course, if the signal level went beyond the limits in the reactor compartment, then it will be seen by the lead reactor control engineer, by the turbine in the turbine.
But imagine that there are a lot of operators. Then the alarm can not be shown to everyone. Or if someone takes it for handshaking, it should be immediately blocked for handshaking on all other nodes. This is a real-time operation, and when the two operators take to acknowledge the same alarm, they will immediately begin to control the equipment and algorithms. All this is connected with network multi-threaded programming and can lead to serious system conflicts. Therefore, any dynamic object needs to be shown, allowed to manage and “extinguish” the alarm only to one operator.
Moreover, all alarms depend on each other. Some equipment starts to “fail” - a thousand alarms pop up. In fact, in order to extinguish them all, you need to find only one of them, acknowledge it, and then the “tree” of the remaining alarms disappears. This is a separate science and we are working on how to represent such anxieties. There is no consensus yet: either a tree or hide as an attachment. Now the alarm module looks like this, with nested data.
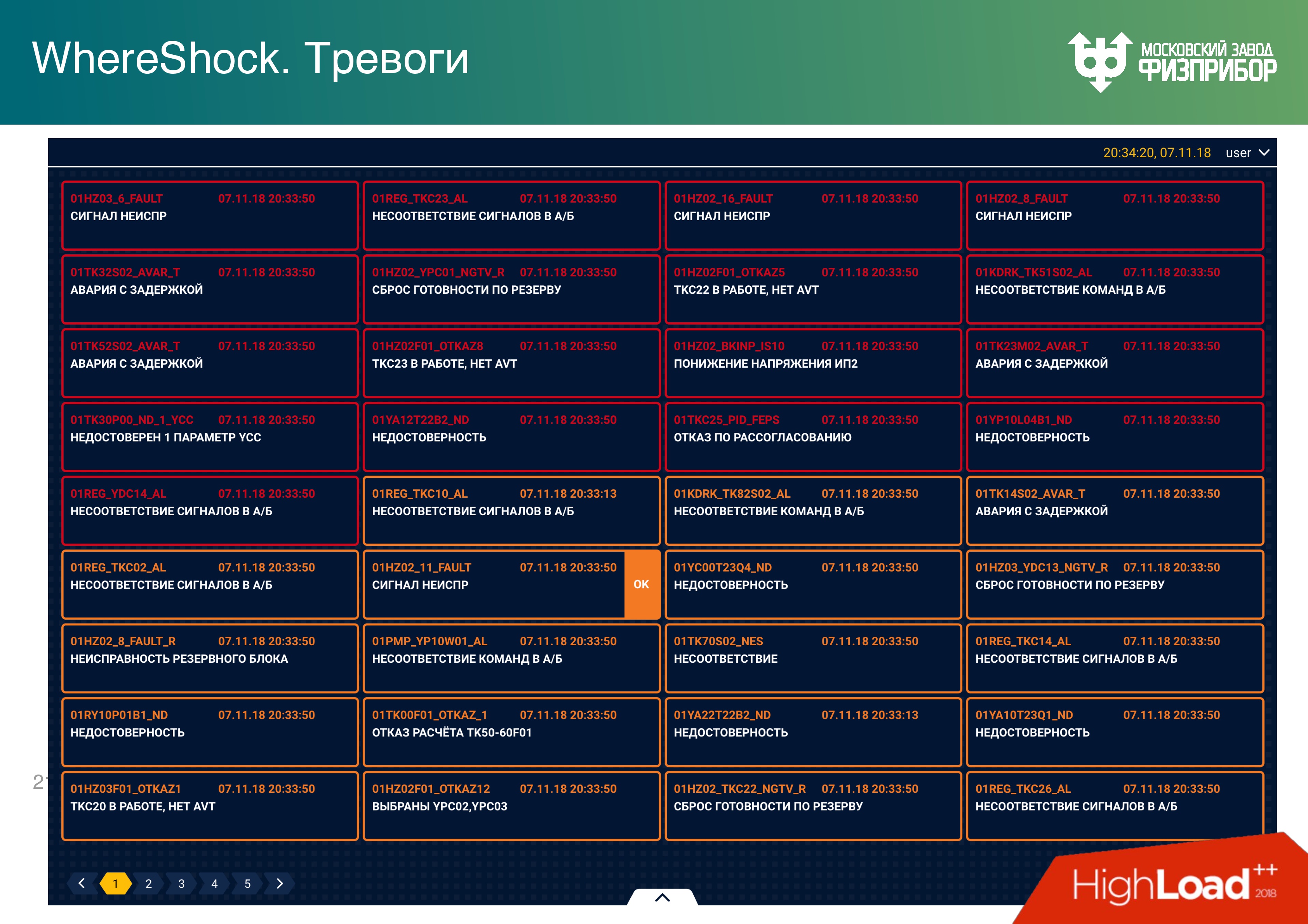
I give examples of video frames that the operator sees for a general presentation.
- At the top left - the reactor compartment,
- bottom left - video frame for wind farm,
- bottom right is a graph
- At the top right are the steam generators of the reactor compartment.
Yellow links - transitions to other video frames.
We have a stand at the factory. Dashboards look like this on the panel, the operator is about the same.
system configuration
We provide a fairly universal database mode.
The editor that allows you to create objects, delete them, set parameters that are transferred to the real-time database and metadata database.
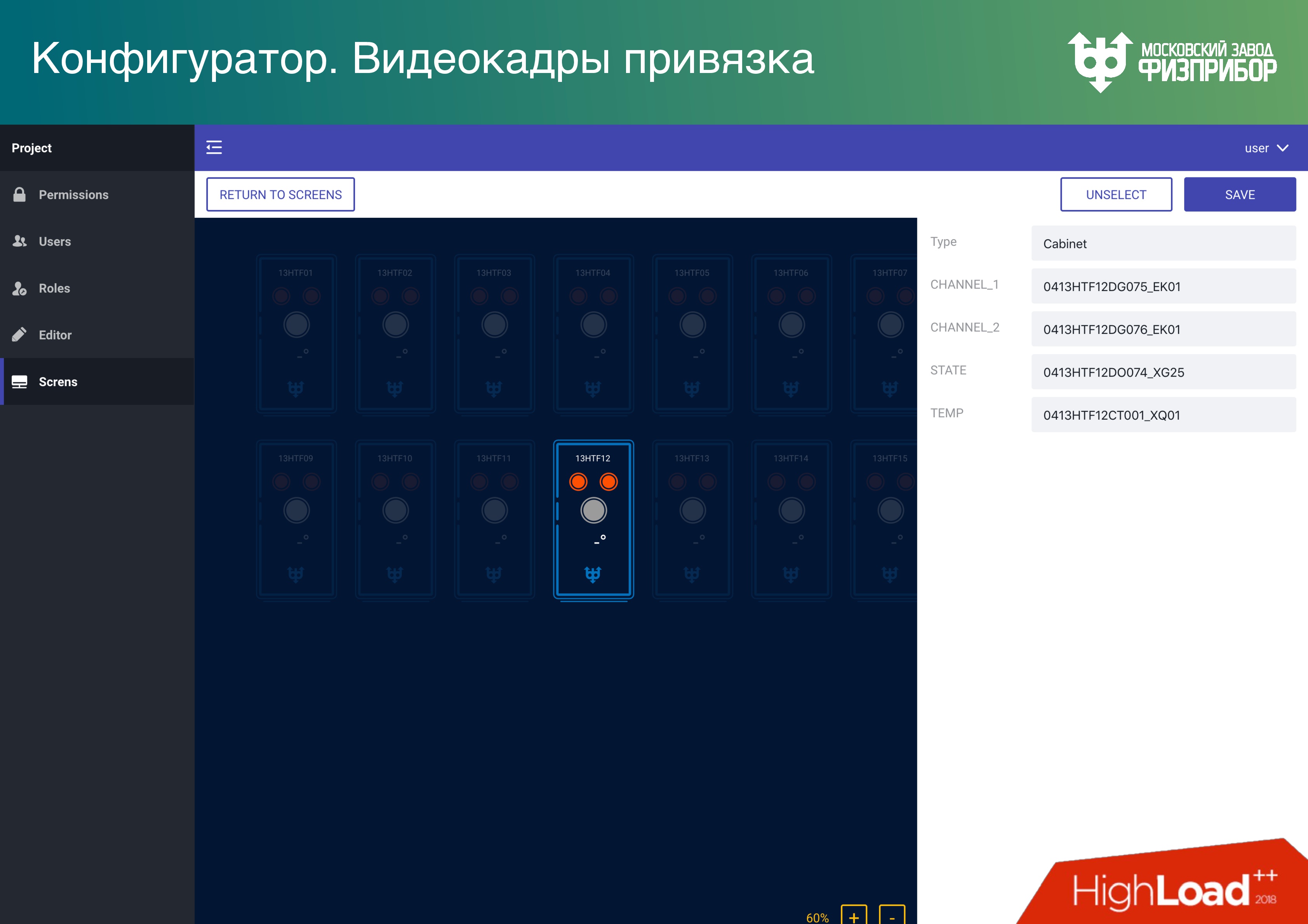
Video frames are user interface elements with the most problems. Each SCADA / HMI vendor tries to make its editor, and then, when the developers quit, you won’t find any ends - bugs appear, everything falls, it is impossible to manage. We are tired of it, so we decided: “Do what you want! Though on Illustrator, at least in Sketch - in any program that will issue the canonical SVG. ” We give the opportunity to open SVG and attach it to the tags BDRV. If the primitives in the editor are correctly called, then nothing else is needed and everything will work fine right away.
Creating a user interface in a process control system or platform looks no more difficult than creating a website. We give all the necessary APIs to make it so. No other system, which is currently used at such facilities, does not work this way, everywhere there are complex editors and poor interfaces. Imagine what the operators who look at them every day. Of course, many people think that it’s not as important as it looks, the main thing is safety. But we want it to look beautiful, because, in our opinion, this is important.
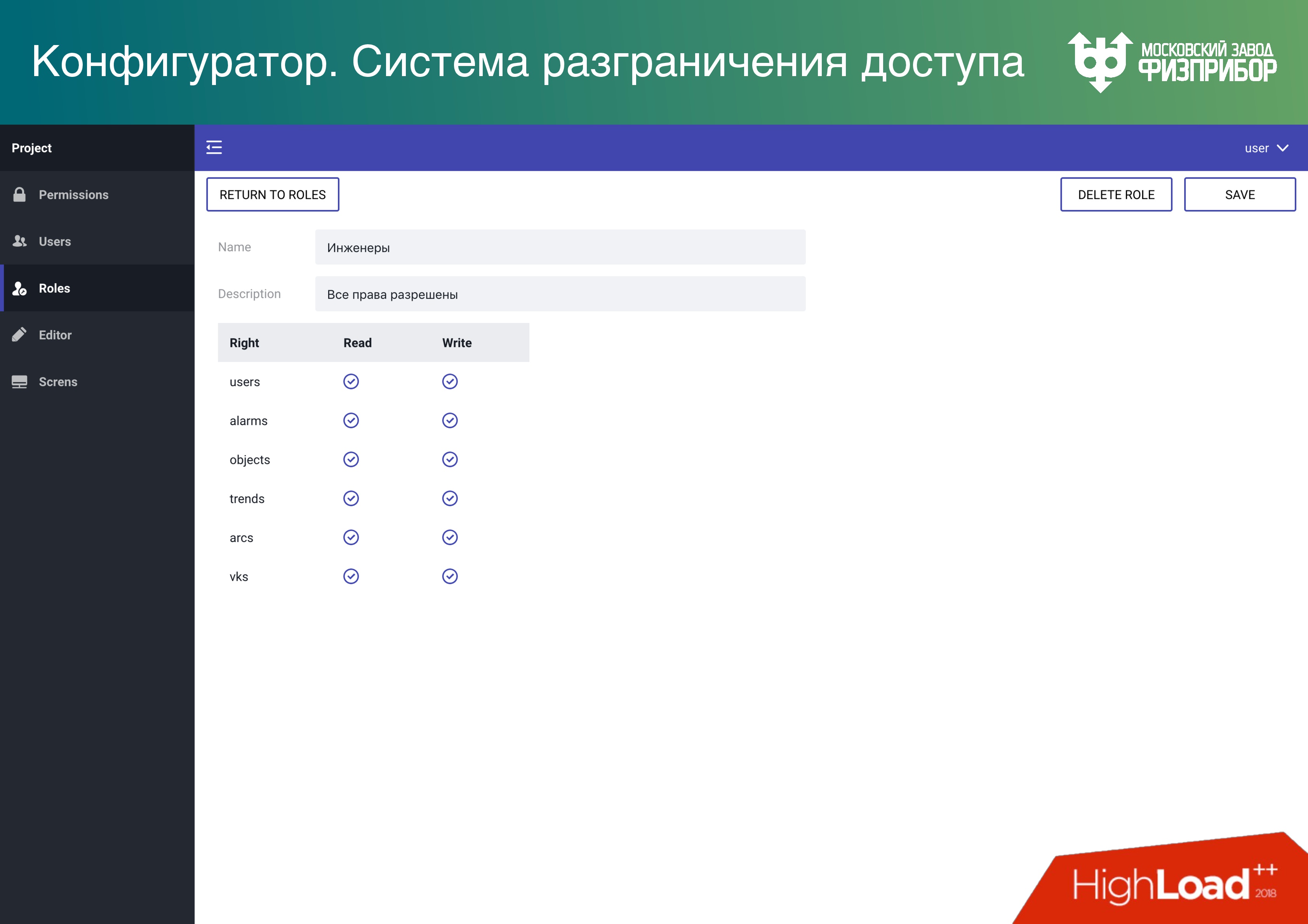
Like everywhere else, we have an access control system . We support several modes to be reliable and cheap. In addition to container and conventional virtualization, we give the opportunity to make Data Lake. Then all fit into one large RAM, and the modemultitenancy provides the ability to share access to elements of the tree (objects, data). Therefore, it is possible to keep several projects on actually quite inexpensive hardware.
Also, the more iron, the more expensive the synchronization and the more likely the error. Therefore, if we can simply copy this base on more nodes, even in this mode, the total reliability of the entire system grows .
Moreover, it should be noted one thing: in real time and a large number of objects in memory, we can not work with the processor cache. It turned into a pumpkin, because when you need to provide navigation and search for 10 or 100 million objects, then there is no cache — all by hand.
Forecasting
We make predictive analytics using neural networks, machine learning. I'll tell you how it works and how much it costs in money.
On the right is a graph of the change in reactor power during the movement of the regulatory control system of the protection control system - control rods. In general, the reactor is governed by the concentration of boric acid in water, but when power maneuvers are made, rods are used. Each movement of the rods is fuel burns, and the fuel is quite expensive: the load on the modern VVER-1200 reactor is about 10 tons of uranium dioxide.
The graph, which gives a return, shows how the operator manages everything manually, that is, changes the power parameters, sees that the power is slightly lower than necessary, slightly adds, etc. ... Focusing on the feedback, the operator eventually brings the power to the desired level
We trained the neural network in the previous testimony. But just a neural network will never exactly predict the physical process. There are 5 physical processes in the reactor: neutron kinetics, hydrodynamics, chemistry and radiochemistry due to various transformations, and physics of strength. Any calculation looks like a simulation of each of this process.
Basically there are two methods:
- Monte Carlo for neutrons and radiochemistry (on the CPU);
- Computational Fluid Dynamics (CFD) for everything else (on the GPU).
These methods are extremely slow, they cannot be used in a real-time system. We increased the space-time step, and made the adjustment on neural networks, and got quite a serious optimization (the upper graph). Now there is no need to reverse the rods.
According to the calculated characteristics, optimizing for the absence of a reverse stroke will save up to $ 60 million per year for a three-year fuel campaign (this means that every year a third of the fuel changes). This is a good figure for the total KPI of employees who work on the unit.
Remote Control
The usual block control panel looks like this.
On the left - Novovoronezh NPP, on the right - Kalinin NPP and model.
But we went further. Block control panel is a very expensive story. There are many developers who produce both hardware and software, which comes down to it - these are dozens and hundreds of companies. We made a cameraman , loaded our system into it.
You put on glasses and get the same picture as on the block, only without a shield. There used to be a control room (control unit block) - the operator walked, twisted some pieces. Then they put a computer to him, he looked at it, but still got up to the shield and twisted. Then we made the ability to control from the monitor - the control room (control unit), and now - the control unit (virtual control unit), for which the future.
Although the future, of course, is behind the unit without operators — artificial intelligence. The operator will become a supervisor. Then it will be possible to control the entire station entirely from the common control panel. And then the operator will be able to be outside the plant.
Such an ITER project is already being implemented . The station itself is located in the city of Cadarache in France, and the control panel is in Japan in the city of Rokasho. This is done to debug technologies, using quantum communication and quantum cryptography. You can say the future is here!
Больший уклон в разработку программного и аппаратного обеспечения для интернета вещей мы сделаем на InoThings Conf 4 апреля. В прошлом году были доклады и про IIoT, и про электроэнергию. В этом году планируем сделать программу еще более насыщенной. Пишите заявки, если готовы нам в этом помочь.