This is how the search for borrowing in Antiplagiat is arranged.
We have already told you about interesting statisticians of texts , reviewed articles on the use of autocoders in text analysis , surprised us with our fresh search algorithms for translated borrowings and paraphrase . I decided to continue our corporate tradition and, first, to start the article with "T", and secondly, to tell:

In 2005, the rector of one of the major Moscow universities came to us at Forecsys to solve a very serious problem - in schools, students passed totally written off diplomas and term papers. We took several hundred works of excellent students and searched them on the net with simple queries. More than half of the"honors"turned out to be crooks who downloaded a diploma from the Internet and replaced only the title page. More than half the best students, Karl! What happened to ordinary students is difficult to even imagine. The easiest job was to search for a request containing words with "ochepyatkami." We have become clear the scale of the disaster. It was necessary to urgently solve something. Foreign English-speaking universities by that time already used solutions to search for borrowings, but for some reason no one checked the work in Russian.
Foreign players did not want to adapt their decisions under the Russian language. As a result, on March 17, 2005, the development of the first domestic system for borrowing search was launched. The word "Antiplagiat" was coined a little later, and the domain antiplagiat.ru was registered on April 28, 2005. We planned to release the site by September 1, 2005, but, as is often the case with programmers, we didn’t have time to do so. The official birthday of our company is the day when antiplagiat.ru received its first users, namely, on September 4th. You know, I am even happy about this, because during the corporate party on the occasion of the birthday of the company, everyone can safely celebrate and not worry about their children’s first school day.
But something I digress. In 2005, we created a kind of search engine, in which, unlike Yandex and Google, the query is not two or three words, but a whole text consisting of several sentences. Therefore, it is reasonable to use “Anti-plagiarism” if you have text from 1000 characters (about half a page).
During the development of the service, a prototype was made on php (web-part) and Microsoft SQL Server (search engine). It immediately became clear that this would not take off and would slowly work on several million documents. Therefore, I had to cut my search engine. Now the system is written in C # and python, uses PostgreSQL and MongoDB (in fact, a lot more, but more on that in the next article). Our search engine is still completely self-developed.Put likesWrite in the comments if you want to learn about the history of the system, the changing processes of the company and the hardware on which Antiplagiat worked at different points in your life, and it works now.
The word that gave the name of the company, has now become a household word. Often in the search engine you can find such expressions as “check for anti-plagiarism”, “increase anti-plagiarism”. Anyone who is somehow connected with the area of borrowing in Russia and the near abroad, is trying to use the word "anti-plagiarism" for raising in the search results. We are often asked about other "anti-plagiarism". So, Antiplagiat is one, it is a trademark and name of our company.
At the very beginning of the implementation of the borrowing search service, we decided that we would work with the text as a sequence of characters. Immediately, various semantic constructions from texts, the search for meanings, the analysis of sentences, etc. were rejected. The solution chosen by us gives two huge advantages - high search speed and relatively small amount of search indexes.
To date, there are three products in our line. They differ in functionality, but they contain in their basis the same principle of operation of the borrowing search. In this article I will talk about how our classic search for borrowing works - the functionality that became the basis of the service from the very beginning and has not changed conceptually until now. The borrowing search scheme, as you see in the image, is simple and uncomplicated, like drawing an owl. First we get the document from the user, then we extract the text from it. Next we look for borrowing in this text, we get “revisions” (so we call the report on one search module) and, finally, we collect revisions into one big report, which we show as a result to the user.
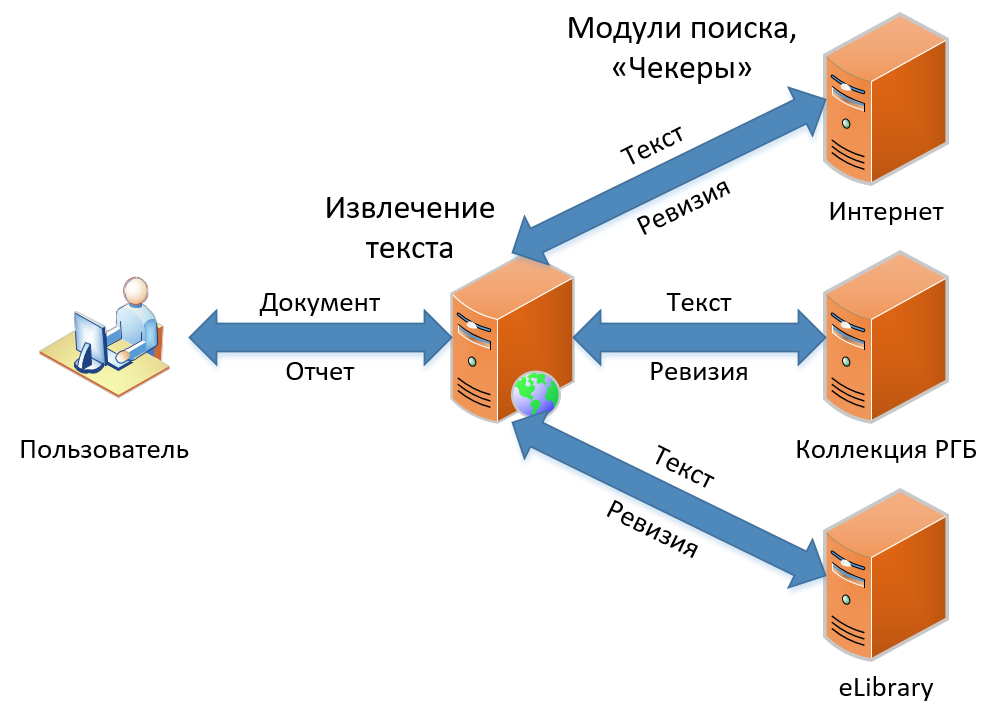
Let's see how it all happens in detail.
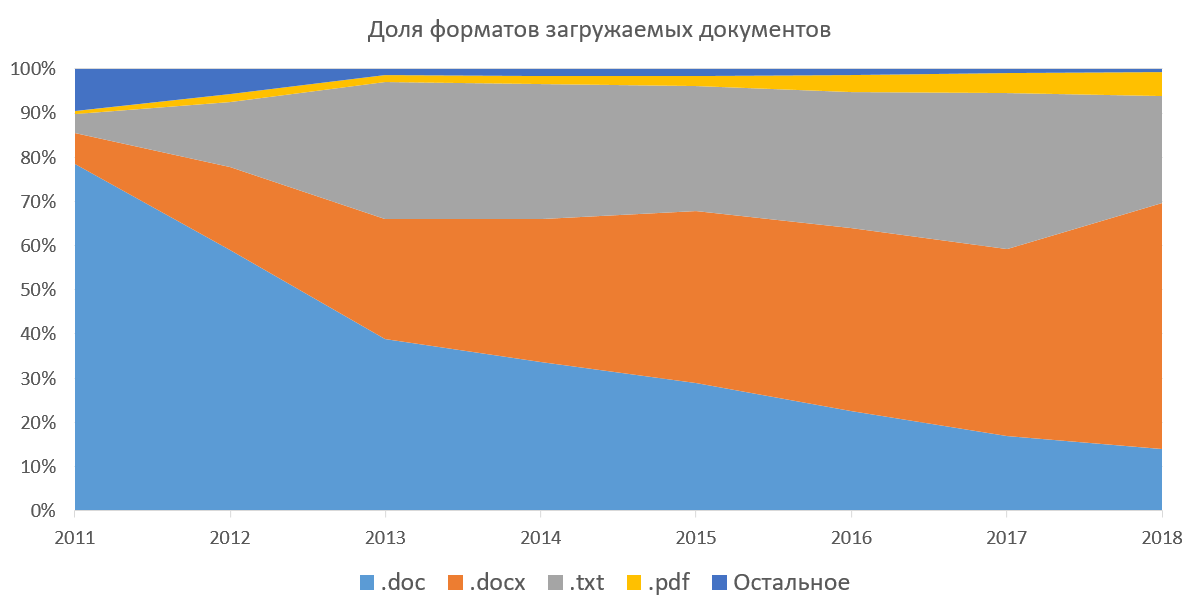
First of all, Antiplagiat is a text- only search service.borrowing, which means we need to extract the text from all the documents in order to continue working with it. The system supports the ability to download documents in docx, doc, txt, pdf, rtf, odt, html, pptx and a few more (never used) formats. Also, all these documents you can download in the archives (7z, zip, rar). This method was popular when we did not have the opportunity to download several documents at once through a web interface. Below is a graph of the popularity of downloadable document formats in the corporate part of our system. It shows how, over several years, doc is supplanted by docx, and the share of pdf is gradually increasing. If not to consider txt (extraction of the text for it is trivial), then for us the most pleasant is pdf. Abroad pdf is a de facto standard, it publishes articles, preparing student papers. According to our statistics, pdf is gradually gaining popularity in Russia and the CIS countries. We ourselves are promoting this format to the masses, recommending to upload documents in it.
We have limited the document download formats for private clients to pdf and txt, which is why we have reduced resource consumption, reduced the cost of supporting a free service. You do need to check the text, and not test the system? So what's the difference in what format to download it?
The next easiest way to extract text is docx, because, in fact, it is a zip-archive with xml inside, it is quite simple to process it, and much can be done at a low level.
The most difficult for us is doc. This format has been closed for a long time, and now there is a bunch of its implementations. The latest Microsoft Word, which did not support .docx (albeit through the Microsoft Office Compatibility Pack), was already released 20 years ago and was included in Microsoft Office 97. The format uses OLE inside itself, which later grew in COM and ActiveX, everything is binary, incompatible in some places between versions. In general, a terrible dream of a modern programmer. It’s good that the .doc format is gradually disappearing from the scene. I think the time has come for us to help him retire. Soon we will begin to purposefully warn users that this format is outdated.
So back to the report. We got the file and started extracting the text. Together with the text, the system also extracts the positions of words on the pages in order to be able to show our users the markup of the borrowing report on the document itself. In addition, at the same stage, we are looking for technical bypasses of Antiplagiat.
As soon as “Anti-plagiarism” appeared, showing the percentage of originality, there were also those who wanted to undergo a borrowing test with minimal effort, as well as people offering this service for money. The problem is that the numeric parameter asks for evaluation. It's so easy - instead of reading the work using the system as a tool, do not read it, but evaluate it by the percentage of originality! It was this trouble that gave rise to such a direction as tuning works (a change in the text in order to increase the percentage of originality of the work). Read more about problems in university processes in the article “On the practice of detection of borrowings in Russian universities” .
In foreign systems, searching for the problem of detecting technical rounds and countering them is practically not worth it. The fact is that a very tough punishment will follow the one detected by the “feint with the ears” - a deduction, and an indelible stain on scientific reputation, incompatible with a further career. In our case, the situation before the comic is simple: “Oh, this is a system that screwed up something!”, “Oh, it's not me, it is itself!”. The student will most likely be sent to rework. The fact is that write off, alas, is not something embarrassing.
But again distracted. Another way to extract text is OCR. We print the document on a virtual printer, and then we recognize it. Read more about this in the article "Recognition of images in the service of" Antiplagiat " .
Now a little of our story about text extraction. First we extracted the texts with the help of IFilters. They are slow, only under Windows, and do not return formatting information (it’s not clear where the white text is on a white background, you can’t then markup the borrowing blocks directly in the user's document). We thought that these problems would be solved if we began to use paid libraries, but even here we found limitations: still under Windows, they do not see formulas, sometimes they fall on specially prepared documents (different libraries on different!). The next idea was to OCR all incoming documents, but this approach is very resource intensive (processing only 10 pages per minute on a single core), and the text is not precisely extracted in some places.
We did not find a silver bullet, although a couple of times we thought that this was it, Happiness. However, later, having lived a little with it, we understood that it was an Experience again. Extracting text balances on a fine line between performance (you need to extract text from hundreds of documents per minute), reliability (you need to extract text from everything), functionality (formatting, workarounds, this is all). Now all of the above and a little more work for us. We are constantly experimenting with this area and continue to look for our happiness.
The text is extracted, bypasses are found and partially eliminated, we go to look for borrowings!
The idea implemented in the search procedure was proposed by Ilya Segalovich and Yuri Zelenkov (you can read, for example, in the article: Comparative analysis of methods for determining fuzzy duplicates for Web documents ). I'll tell you how it works for us. Take, for example, the sentence: "Decree of the President of the Russian Federation of May 7, 2012 N 596" On the long-term state economic policy "."
Now for the search we need a magic function, which, according to such a list of hashes, turns documents, ranked by decrease in the number of matched hashes, into a source document. This function should work quickly, because we want to search for billions of documents. In order to quickly find such a set, we need a reverse index, which according to the hash returns a list of documents in which this hash exists. We have implemented such a giant hash table. Unlike our older search engines, we store this table in ssd, not in memory. We have enough of this performance. Index search takes a small part of the time from the entire document processing cycle. See how the search goes:
Stage 1. Search by index
For each hash of the query text, we obtain a list of identifiers of the source documents in which it occurs. Next, we rank the list of identifiers of source documents according to the number of hashes encountered from the query text. We get a ranked list of documents candidates for the source of borrowing.
Stage 2. Build a revision
For a large text, the request of candidates may be about 10 thousand. This is still a lot to compare each document with the text of the request. We act greedily, but decisively. We take the first document source, make a comparison with the text-request and exclude from all other candidates those hashes that were already in this first document. Remove from the list of candidates those who have zero hashes, re-sort the candidates according to the new number of hashes. We take the first document from the new list, compare it with the source text, delete the hashes, delete the zero candidates, re-sort the candidates. We do so 10-20 times, usually this is enough for the list to dry up or there are only documents left in it that have a match for several hashes.
Using hashes of words allows us to perform comparison operations faster, save on memory and store not the texts of source documents, but their digital snapshots (TextSpirit, as we affectionately call them) obtained during indexing, thereby not violating copyright. Selection of specific fragments of borrowing is done using a suffix tree.
As a result of checking with a single search module, we get a revision in which there is a list of sources, their metadata and coordinates of borrowing blocks relative to the query text.
By the way, what if one of the 10-15 modules did not respond on time? We are looking for collections of the RSL, eLibrary and the Guarantor. These search modules are located on the territory of third parties and cannot be transferred to our site for copyright reasons. The point of failure here can always be a communication channel and various force majeure in data centers that are not controlled by us. On the one hand, borrowing can be found in any search module, on the other hand, if one of the system components is not available, you can worsen the search quality, but give most of the result, warning the user that the result for some search modules is not yet ready. Which option would you apply? We use both of these options as appropriate.

Finally, all revisions are received, we begin to build the report. It uses a similar approach to the preparation of one audit. It seems to be nothing complicated, but there are interesting problems here. We have borrowings of two types. Greens denote “Citations” - correctly issued (according to GOST) quotations from the “Citation” module, expressions like “required to be proved” from the “Commonly used expressions” module, normative legal documents from the Garant and Lekspro bases. Orange marks all other borrowings. Greens have priority over orange, unless they are included entirely in the orange block.
As a result, the report can be compared with the text printed on paper lying on the table, over which multicolored stripes (blocks of borrowing and citations) are fancifully overlapping each other. What we see above is a report. We have two indicators for each source:
Share in the report - the ratio of borrowing, which is taken into account from this source, to the total volume of the document. If the same text was found in several sources, then it is taken into account only in one of them. If you change the configuration of the report (enable or disable sources), this indicator of the source may change. In total, it gives the percentage of borrowings and citations (depending on the color of the source).
Text share- the ratio of the volume borrowed from this source text to the total volume of the document. Shares in the text by source summing up does not make sense, it is easy to get 146% or even more. This indicator does not change when the report changes.
Naturally, the report can be edited. This is a special function so that the expert checking the work turns off the borrowing of the author’s own work (it can be revealed that this fragment is not only in the author’s own work, but also somewhere else) and individual borrowing blocks changed the source type from borrowing on citation. As a result of editing the report, the expert gets the real value of borrowing. Any work for verification must be read. It is convenient to do this by looking at the original document view, in which the blocks of borrowing are marked, and immediately, as you read, edit the report. Unfortunately, this is quite a logical action, not all is committed, many are content with a percentage of originality, even without looking at the report.
However, let us go back a step and find out what falls into the index of the Internet search module created by Antiplagiat.
Anti-plagiarism is largely focused on student work, scientific publications, final qualifying works, theses, etc. We index the Internet in a directed way - we are looking for large accumulations of scientific texts, abstracts, articles, dissertations, scientific journals, etc. Indexing is as follows:
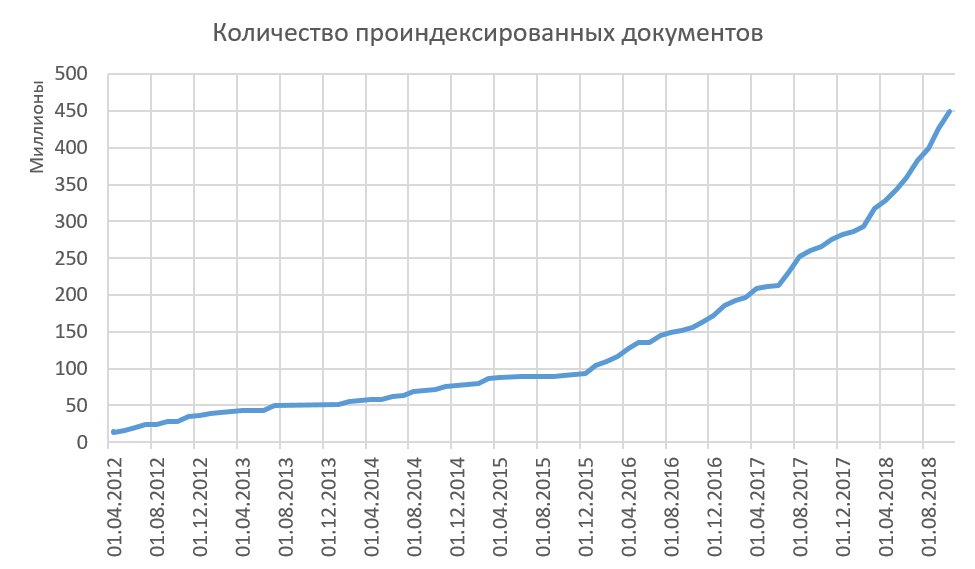
Thus, we index quality texts, and all indexed texts are significantly different. The growth in the volume indexed on the Internet is shown in the figure below. Now, on average, we add 15-20 million documents per month to the index.
Notice that there is no description of the removal procedure from the index? And she is not! We basically do not remove documents from the index. We believe that if we were able to see something on the Internet, then other people could see this text and use it in one way or another. In this regard, there is an interesting statistic of what was once on the Internet, and now it is no longer there. Yes, just imagine, the expression “Gone on the Internet will remain there forever,” is not true! Something disappears from the Internet forever. Are you interested in learning about our statistics on this issue?
It's amazing how technical decisions made more than 10 years ago still remain relevant. We are now preparing to release the 4th version of the index, it is faster, more technologically, better, but it is based on all the same solutions. New directions of search have appeared - transferable borrowing, paraphrasing, but even there our index finds use, performing even a small but important part of the work.
Dear readers, that you would be interested to learn more about our service?
- how to quickly find a paragraph of text among hundreds of millions of articles;
- what the document turns into after downloading to the Antiplagiat system, and what to do with it further;
- how a report is formed that almost no one looks, but it would be worth it;
- how to index not everything, but enough.
How it all began
In 2005, the rector of one of the major Moscow universities came to us at Forecsys to solve a very serious problem - in schools, students passed totally written off diplomas and term papers. We took several hundred works of excellent students and searched them on the net with simple queries. More than half of the
Foreign players did not want to adapt their decisions under the Russian language. As a result, on March 17, 2005, the development of the first domestic system for borrowing search was launched. The word "Antiplagiat" was coined a little later, and the domain antiplagiat.ru was registered on April 28, 2005. We planned to release the site by September 1, 2005, but, as is often the case with programmers, we didn’t have time to do so. The official birthday of our company is the day when antiplagiat.ru received its first users, namely, on September 4th. You know, I am even happy about this, because during the corporate party on the occasion of the birthday of the company, everyone can safely celebrate and not worry about their children’s first school day.
But something I digress. In 2005, we created a kind of search engine, in which, unlike Yandex and Google, the query is not two or three words, but a whole text consisting of several sentences. Therefore, it is reasonable to use “Anti-plagiarism” if you have text from 1000 characters (about half a page).
During the development of the service, a prototype was made on php (web-part) and Microsoft SQL Server (search engine). It immediately became clear that this would not take off and would slowly work on several million documents. Therefore, I had to cut my search engine. Now the system is written in C # and python, uses PostgreSQL and MongoDB (in fact, a lot more, but more on that in the next article). Our search engine is still completely self-developed.
The word that gave the name of the company, has now become a household word. Often in the search engine you can find such expressions as “check for anti-plagiarism”, “increase anti-plagiarism”. Anyone who is somehow connected with the area of borrowing in Russia and the near abroad, is trying to use the word "anti-plagiarism" for raising in the search results. We are often asked about other "anti-plagiarism". So, Antiplagiat is one, it is a trademark and name of our company.
At the very beginning of the implementation of the borrowing search service, we decided that we would work with the text as a sequence of characters. Immediately, various semantic constructions from texts, the search for meanings, the analysis of sentences, etc. were rejected. The solution chosen by us gives two huge advantages - high search speed and relatively small amount of search indexes.
To date, there are three products in our line. They differ in functionality, but they contain in their basis the same principle of operation of the borrowing search. In this article I will talk about how our classic search for borrowing works - the functionality that became the basis of the service from the very beginning and has not changed conceptually until now. The borrowing search scheme, as you see in the image, is simple and uncomplicated, like drawing an owl. First we get the document from the user, then we extract the text from it. Next we look for borrowing in this text, we get “revisions” (so we call the report on one search module) and, finally, we collect revisions into one big report, which we show as a result to the user.
Let's see how it all happens in detail.
Extract text
First of all, Antiplagiat is a text- only search service.borrowing, which means we need to extract the text from all the documents in order to continue working with it. The system supports the ability to download documents in docx, doc, txt, pdf, rtf, odt, html, pptx and a few more (never used) formats. Also, all these documents you can download in the archives (7z, zip, rar). This method was popular when we did not have the opportunity to download several documents at once through a web interface. Below is a graph of the popularity of downloadable document formats in the corporate part of our system. It shows how, over several years, doc is supplanted by docx, and the share of pdf is gradually increasing. If not to consider txt (extraction of the text for it is trivial), then for us the most pleasant is pdf. Abroad pdf is a de facto standard, it publishes articles, preparing student papers. According to our statistics, pdf is gradually gaining popularity in Russia and the CIS countries. We ourselves are promoting this format to the masses, recommending to upload documents in it.
We have limited the document download formats for private clients to pdf and txt, which is why we have reduced resource consumption, reduced the cost of supporting a free service. You do need to check the text, and not test the system? So what's the difference in what format to download it?
The next easiest way to extract text is docx, because, in fact, it is a zip-archive with xml inside, it is quite simple to process it, and much can be done at a low level.
The most difficult for us is doc. This format has been closed for a long time, and now there is a bunch of its implementations. The latest Microsoft Word, which did not support .docx (albeit through the Microsoft Office Compatibility Pack), was already released 20 years ago and was included in Microsoft Office 97. The format uses OLE inside itself, which later grew in COM and ActiveX, everything is binary, incompatible in some places between versions. In general, a terrible dream of a modern programmer. It’s good that the .doc format is gradually disappearing from the scene. I think the time has come for us to help him retire. Soon we will begin to purposefully warn users that this format is outdated.
So back to the report. We got the file and started extracting the text. Together with the text, the system also extracts the positions of words on the pages in order to be able to show our users the markup of the borrowing report on the document itself. In addition, at the same stage, we are looking for technical bypasses of Antiplagiat.
As soon as “Anti-plagiarism” appeared, showing the percentage of originality, there were also those who wanted to undergo a borrowing test with minimal effort, as well as people offering this service for money. The problem is that the numeric parameter asks for evaluation. It's so easy - instead of reading the work using the system as a tool, do not read it, but evaluate it by the percentage of originality! It was this trouble that gave rise to such a direction as tuning works (a change in the text in order to increase the percentage of originality of the work). Read more about problems in university processes in the article “On the practice of detection of borrowings in Russian universities” .
In foreign systems, searching for the problem of detecting technical rounds and countering them is practically not worth it. The fact is that a very tough punishment will follow the one detected by the “feint with the ears” - a deduction, and an indelible stain on scientific reputation, incompatible with a further career. In our case, the situation before the comic is simple: “Oh, this is a system that screwed up something!”, “Oh, it's not me, it is itself!”. The student will most likely be sent to rework. The fact is that write off, alas, is not something embarrassing.
But again distracted. Another way to extract text is OCR. We print the document on a virtual printer, and then we recognize it. Read more about this in the article "Recognition of images in the service of" Antiplagiat " .
Now a little of our story about text extraction. First we extracted the texts with the help of IFilters. They are slow, only under Windows, and do not return formatting information (it’s not clear where the white text is on a white background, you can’t then markup the borrowing blocks directly in the user's document). We thought that these problems would be solved if we began to use paid libraries, but even here we found limitations: still under Windows, they do not see formulas, sometimes they fall on specially prepared documents (different libraries on different!). The next idea was to OCR all incoming documents, but this approach is very resource intensive (processing only 10 pages per minute on a single core), and the text is not precisely extracted in some places.
We did not find a silver bullet, although a couple of times we thought that this was it, Happiness. However, later, having lived a little with it, we understood that it was an Experience again. Extracting text balances on a fine line between performance (you need to extract text from hundreds of documents per minute), reliability (you need to extract text from everything), functionality (formatting, workarounds, this is all). Now all of the above and a little more work for us. We are constantly experimenting with this area and continue to look for our happiness.
The text is extracted, bypasses are found and partially eliminated, we go to look for borrowings!
Borrowing search
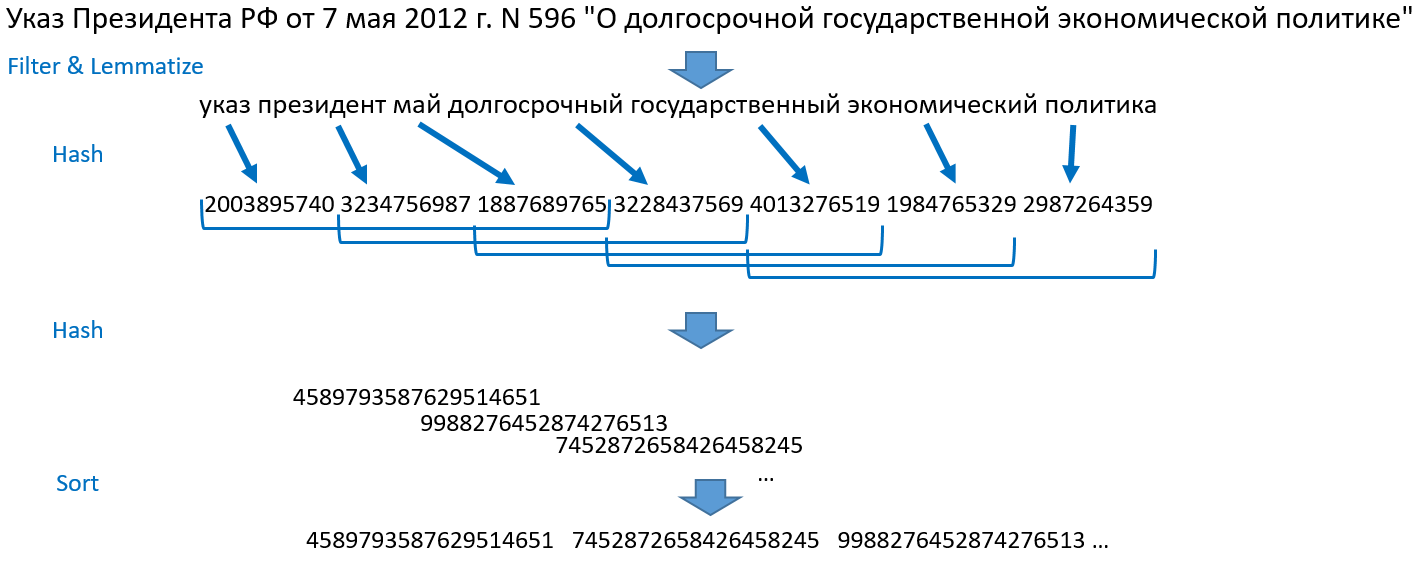
The idea implemented in the search procedure was proposed by Ilya Segalovich and Yuri Zelenkov (you can read, for example, in the article: Comparative analysis of methods for determining fuzzy duplicates for Web documents ). I'll tell you how it works for us. Take, for example, the sentence: "Decree of the President of the Russian Federation of May 7, 2012 N 596" On the long-term state economic policy "."
- We break sentences into words, throw out numbers, punctuation, stop words. We lemmatize (normalize) all the words.
- Turning words into integers by hashing, we get an array of numbers.
- We take the first three hashes, then 2, 3, 4th hash, then 3, 4, 5th and so on until the end of the array of hashes. These are shingles - tiles. This method got its name because of such a tiled overlap of sets. Each tile is merged into one object and hashed again.
- Sort the resulting numbers, we get an ordered array of integers. This is the basis for the search.
Now for the search we need a magic function, which, according to such a list of hashes, turns documents, ranked by decrease in the number of matched hashes, into a source document. This function should work quickly, because we want to search for billions of documents. In order to quickly find such a set, we need a reverse index, which according to the hash returns a list of documents in which this hash exists. We have implemented such a giant hash table. Unlike our older search engines, we store this table in ssd, not in memory. We have enough of this performance. Index search takes a small part of the time from the entire document processing cycle. See how the search goes:
Stage 1. Search by index
For each hash of the query text, we obtain a list of identifiers of the source documents in which it occurs. Next, we rank the list of identifiers of source documents according to the number of hashes encountered from the query text. We get a ranked list of documents candidates for the source of borrowing.
Stage 2. Build a revision
For a large text, the request of candidates may be about 10 thousand. This is still a lot to compare each document with the text of the request. We act greedily, but decisively. We take the first document source, make a comparison with the text-request and exclude from all other candidates those hashes that were already in this first document. Remove from the list of candidates those who have zero hashes, re-sort the candidates according to the new number of hashes. We take the first document from the new list, compare it with the source text, delete the hashes, delete the zero candidates, re-sort the candidates. We do so 10-20 times, usually this is enough for the list to dry up or there are only documents left in it that have a match for several hashes.
Using hashes of words allows us to perform comparison operations faster, save on memory and store not the texts of source documents, but their digital snapshots (TextSpirit, as we affectionately call them) obtained during indexing, thereby not violating copyright. Selection of specific fragments of borrowing is done using a suffix tree.
As a result of checking with a single search module, we get a revision in which there is a list of sources, their metadata and coordinates of borrowing blocks relative to the query text.
Report assembly
By the way, what if one of the 10-15 modules did not respond on time? We are looking for collections of the RSL, eLibrary and the Guarantor. These search modules are located on the territory of third parties and cannot be transferred to our site for copyright reasons. The point of failure here can always be a communication channel and various force majeure in data centers that are not controlled by us. On the one hand, borrowing can be found in any search module, on the other hand, if one of the system components is not available, you can worsen the search quality, but give most of the result, warning the user that the result for some search modules is not yet ready. Which option would you apply? We use both of these options as appropriate.
Finally, all revisions are received, we begin to build the report. It uses a similar approach to the preparation of one audit. It seems to be nothing complicated, but there are interesting problems here. We have borrowings of two types. Greens denote “Citations” - correctly issued (according to GOST) quotations from the “Citation” module, expressions like “required to be proved” from the “Commonly used expressions” module, normative legal documents from the Garant and Lekspro bases. Orange marks all other borrowings. Greens have priority over orange, unless they are included entirely in the orange block.
As a result, the report can be compared with the text printed on paper lying on the table, over which multicolored stripes (blocks of borrowing and citations) are fancifully overlapping each other. What we see above is a report. We have two indicators for each source:
Share in the report - the ratio of borrowing, which is taken into account from this source, to the total volume of the document. If the same text was found in several sources, then it is taken into account only in one of them. If you change the configuration of the report (enable or disable sources), this indicator of the source may change. In total, it gives the percentage of borrowings and citations (depending on the color of the source).
Text share- the ratio of the volume borrowed from this source text to the total volume of the document. Shares in the text by source summing up does not make sense, it is easy to get 146% or even more. This indicator does not change when the report changes.
Naturally, the report can be edited. This is a special function so that the expert checking the work turns off the borrowing of the author’s own work (it can be revealed that this fragment is not only in the author’s own work, but also somewhere else) and individual borrowing blocks changed the source type from borrowing on citation. As a result of editing the report, the expert gets the real value of borrowing. Any work for verification must be read. It is convenient to do this by looking at the original document view, in which the blocks of borrowing are marked, and immediately, as you read, edit the report. Unfortunately, this is quite a logical action, not all is committed, many are content with a percentage of originality, even without looking at the report.
However, let us go back a step and find out what falls into the index of the Internet search module created by Antiplagiat.
Internet indexing
Anti-plagiarism is largely focused on student work, scientific publications, final qualifying works, theses, etc. We index the Internet in a directed way - we are looking for large accumulations of scientific texts, abstracts, articles, dissertations, scientific journals, etc. Indexing is as follows:
- Our robot comes, it seems, and, guided by robots.txt (we have a good robot), loads documents with a reasonable load on each host (there are hundreds of sites working at the same time, so we can wait some time between page loads);
- The robot sends the document and its metadata to the processing queue, the text is extracted from the document;
- The text is analyzed for "quality" - as you remember from the article about the dump, we are able to determine the genre of the document, add simple heuristics here for the volume and we understand whether the text came to us or some kind of rubbish;
- Quality text goes on and turns into hashes. Hashes and metadata are sent to the main index of the Internet;
- We compare the incoming text with the texts previously indexed by us. A newbie is added only if he is really new , i.e. 90% of its hashes are not contained entirely in some other already indexed text. If we already have the document, we add the url of this document to the attributes of our archive.
Thus, we index quality texts, and all indexed texts are significantly different. The growth in the volume indexed on the Internet is shown in the figure below. Now, on average, we add 15-20 million documents per month to the index.
Notice that there is no description of the removal procedure from the index? And she is not! We basically do not remove documents from the index. We believe that if we were able to see something on the Internet, then other people could see this text and use it in one way or another. In this regard, there is an interesting statistic of what was once on the Internet, and now it is no longer there. Yes, just imagine, the expression “Gone on the Internet will remain there forever,” is not true! Something disappears from the Internet forever. Are you interested in learning about our statistics on this issue?
Conclusion
It's amazing how technical decisions made more than 10 years ago still remain relevant. We are now preparing to release the 4th version of the index, it is faster, more technologically, better, but it is based on all the same solutions. New directions of search have appeared - transferable borrowing, paraphrasing, but even there our index finds use, performing even a small but important part of the work.
Dear readers, that you would be interested to learn more about our service?