Our way to the centralized storage of logs
Greetings to all! I work as a system engineer in the company "Onlanta . " On one of our projects I was involved in the implementation and maintenance of the Elastic Stack. We have gone all the way from collecting logs to a centralized, automated process. For two years now we have practically not changed the solution architecture and plan to use a convenient tool in other projects. I share with you our history of its implementation, as well as some strengths and weaknesses in this post.
 A source
A source
At the beginning of 2016, the logs of our administrators and developers were, as they say, “at their fingertips”, that is, the engineer to work with them was connected using SSH to the host where the service of interest was located, uncovered a universal set of tail / grep / sed / awk and hoped that the necessary data can be found on this particular host.
 Source
Source
We also had a separate server, where all directories with logs from all servers were mounted via NFS, and which sometimes took a long time to reflect on what everyone wanted to do with it. Well, tmux with several panels with running tail to some actively updated logs looked very impressive to outsiders on a large monitor and created an exciting atmosphere of participation in the sacraments of production.
All of this even worked, but exactly until a large amount of data was required to be quickly processed, and this was most often required at times when something had already collapsed during the sale.
Sometimes it was a very indecent time to investigate incidents. Its significant part was spent on manual aggregation of logs, start ofcrutchesvarious scripts in Bash and Python, waiting for uploading logs somewhere for analysis, etc.
In a word, all this was very slow, casting gloom and unequivocally hinting that it was time to attend to the centralized storage of logs.
To be honest, there was no complicated process of selecting candidates for the role of the technological stack, which we could provide, then: the ELK bundle at that time was already popular, had good documentation, there were a large number of articles on all components on the Internet. The decision was immediate: you need to try.
 Source
Source
The very first installation of the stack was made after viewing the “Logstash: 0-60 in 60” webinar on three virtual machines, each of which started with a copy of Elasticsearch, Logstash and Kibana.
Next, we encountered some problems with logging from end hosts to Logstash servers. The fact is that at that time Filebeat (a standard stack solution for delivering logs from text files) worked much worse with large and quickly updated files, regularly flowed into RAM, and in our case as a whole did not cope with its task.
To this was added the need to find a way to deliver application server logs from machines running IBM AIX: most of the applications we then ran in WebSphere Application Server, which worked under this OS. Filebeat was written in Go, a more or less workable Go compiler for AIX in 2016 did not exist, and I really didn’t want to use Logstash as an agent for delivery.
We tested several log shipping agents: Filebeat, logstash-forwarder-java, log-courier , python-beaver, and NXLog. We expected agents to have high performance, low system resource consumption, easy integration with Logstash, and the ability to perform basic manipulations with the data provided by the agent (for example, building multi-line events).
About the assembly of multiline (multiline) events should be said separately. Effectively, it can be performed only on the side of the agent that reads a specific file. Despite the fact that Logstash once had a multiline filter, but now it has a multiline codec, all our attempts to combine event balancing across multiple Logstash servers with multiline processing on them failed. This configuration makes the effective balancing of events almost impossible, so for us almost the most important factor in choosing agents was multiline support.
The winners were distributed as follows: log-courier for machines with Linux, NXLog for machines with AIX. With this configuration, we lived for almost a year without any problems: the logs were delivered, the agents did not fall (well, almost), everyone was happy.
In October 2016, the fifth version of the Elastic Stack components, including the Beats 5.0, was released. In this version, a lot of work has been done on all the Beats agents, and we were able to replace log-courier (which by that time had its problems) with Filebeat, which we are still using.
In the transition to version 5.0, we began to collect not only logs, but also some metrics: Packetbeat we began to be used here and there as an alternative to writing logs of HTTP requests to files, and Metricbeat collected system metrics and metrics of some services.
At this point, the work of our engineers with logs has become much simpler: now you didn’t need to know which server to go to to see the log you were interested in, the exchange of the information found was simplified to simply sending a link to Kibana in chat rooms or mail, and the reports that were previously built in a few hours, they began to be created in a few seconds. It cannot be said that it was just a matter of comfort: we noticed changes in the quality of our work, in the quantity and quality of closed tasks, in the speed of response to problems at our stands.
At some point, we started using the ElastAlert utility from Yelp to send alerts to engineers. And then they thought: why not integrate it with our Zabbix, so that all the alerts have a standard format and are sent centrally? The solution was found quite quickly: ElastAlert allows, instead of sending, actually, notifications to execute any commands that we used.
Now, our ElastAlert rules, when triggered, execute a bash script for several lines, to which the arguments are passed the necessary data from the event that triggered the rule, and from the script, in turn, zabbix_sender is called, which sends the data to Zabbix for the desired node.
Since all the information about who generated the event and where, in Elasticsearch, is always there, there were no difficulties with integration. For example, we had a mechanism for automatic detection of WAS application servers before, and in the events they generate, the server name, cluster, cell, etc. are always recorded. This allowed us to use the query_key option in the ElastAlert rules so that the conditions of the rules are processed for each server separately. The script with zabbix_sender then leaves the exact "coordinates" of the server and the data is sent to Zabbix for the corresponding node.
Another solution, which we like very much and which was made possible by the centralized collection of logs, is a script for automatic establishment of tasks in JIRA: once a day, it scoops up all errors from the logs and, if there are no tasks for them, gets them. At the same time, from different indexes, by a unique request ID, all information that might be useful during an investigation is pulled up in a task. The result is such a standard blank with the necessary minimum of information, which then engineers can add if necessary.
Of course, we faced the issue of monitoring the stack itself. This is partially implemented using Zabbix, partly using the same ElastAlert, and we get the main performance metrics for Elasticsearch, Logstash and Kibana using standard monitoring integrated into the stack (Monitoring component in the X-Pack). We also installed netdata from Firehol on the servers with stack services themselves. It is useful when you need to see what is happening with a particular node right now, in real time and in high resolution.
Once the module for monitoring Elasticsearch was a little broken in it, we found it, repaired it, added all sorts of useful metrics and made a pull-request. So now netdata can monitor the latest versions of Elasticsearch, including basic JVM metrics, indexing performance, search performance, transaction log statistics, index segments, and so on. We like Netdata, and we are pleased that we were able to make a small contribution to it.
Today, after almost three years, our Elastic Stack looks like this:
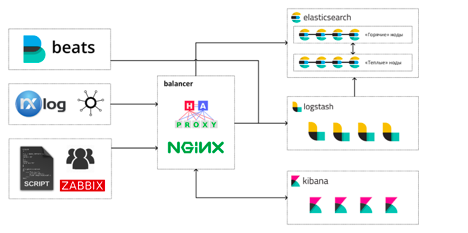
Engineers work with the stack in three main ways:
In total, all of these resources are allocated: 146 CPU, 484GB RAM, 17TB allocated for Elasticsearch data storage.
In total, we have 13 virtual machines in our Elastic Stack: 4 machines for “hot” Elasticsearch nodes, 4 for “warm”, 4 machines with Logstash and one balancer machine. On each hot node, Elasticsearch runs a Kibana instance. It happened from the very beginning, and so far we have not had to move Kibana to separate cars.
But the decision to bring Logstash to individual machines turned out to be one of the most correct and effective during the operation of the stack: the high competition for processor time between JVM Elasticsearch and Logstash led to not very pleasant special effects during load spikes. Garbage collectors suffered the most.
 Source
Source
We store data in the cluster for the last 30 days: now it is about 12 billion events. Per day, “hot” nodes write to the disk 400-500GB of new data with the maximum degree of compression (including shard-replica data). Our Elasticsearch cluster has hot / warm architecture, but we switched to it relatively recently, so less data is stored on the “warm” nodes than on the “hot” ones.
Our typical workload load is:
We try to maintain a 40-50% CPU margin on hot Elasticsearch nodes, so that we can easily experience sudden surges in the number of indexed events and heavy requests from Kibana / Grafana or external monitoring systems. About 50% of RAM on hosts with Elasticsearch nodes is always available for page cache and off-heap JVM needs.
During the time since the launch of the first cluster, we have managed to identify for ourselves some of the positive and negative sides of the Elastic Stack as a means of log aggregation and a search and analysis platform.
What we especially like about the stack:
 Source
Source
What we don't like:
In general, we are very pleased with the choice made in 2016, and we plan to transfer the operating experience of the Elastic Stack to our other projects: the tools provided by the stack were very tightly incorporated into our workflow and it would be very difficult to abandon them now.
{kind=link}
At the beginning of 2016, the logs of our administrators and developers were, as they say, “at their fingertips”, that is, the engineer to work with them was connected using SSH to the host where the service of interest was located, uncovered a universal set of tail / grep / sed / awk and hoped that the necessary data can be found on this particular host.
{kind=link}
We also had a separate server, where all directories with logs from all servers were mounted via NFS, and which sometimes took a long time to reflect on what everyone wanted to do with it. Well, tmux with several panels with running tail to some actively updated logs looked very impressive to outsiders on a large monitor and created an exciting atmosphere of participation in the sacraments of production.
All of this even worked, but exactly until a large amount of data was required to be quickly processed, and this was most often required at times when something had already collapsed during the sale.
Sometimes it was a very indecent time to investigate incidents. Its significant part was spent on manual aggregation of logs, start of
In a word, all this was very slow, casting gloom and unequivocally hinting that it was time to attend to the centralized storage of logs.
To be honest, there was no complicated process of selecting candidates for the role of the technological stack, which we could provide, then: the ELK bundle at that time was already popular, had good documentation, there were a large number of articles on all components on the Internet. The decision was immediate: you need to try.
{kind=link}
The very first installation of the stack was made after viewing the “Logstash: 0-60 in 60” webinar on three virtual machines, each of which started with a copy of Elasticsearch, Logstash and Kibana.
Next, we encountered some problems with logging from end hosts to Logstash servers. The fact is that at that time Filebeat (a standard stack solution for delivering logs from text files) worked much worse with large and quickly updated files, regularly flowed into RAM, and in our case as a whole did not cope with its task.
To this was added the need to find a way to deliver application server logs from machines running IBM AIX: most of the applications we then ran in WebSphere Application Server, which worked under this OS. Filebeat was written in Go, a more or less workable Go compiler for AIX in 2016 did not exist, and I really didn’t want to use Logstash as an agent for delivery.
We tested several log shipping agents: Filebeat, logstash-forwarder-java, log-courier , python-beaver, and NXLog. We expected agents to have high performance, low system resource consumption, easy integration with Logstash, and the ability to perform basic manipulations with the data provided by the agent (for example, building multi-line events).
About the assembly of multiline (multiline) events should be said separately. Effectively, it can be performed only on the side of the agent that reads a specific file. Despite the fact that Logstash once had a multiline filter, but now it has a multiline codec, all our attempts to combine event balancing across multiple Logstash servers with multiline processing on them failed. This configuration makes the effective balancing of events almost impossible, so for us almost the most important factor in choosing agents was multiline support.
The winners were distributed as follows: log-courier for machines with Linux, NXLog for machines with AIX. With this configuration, we lived for almost a year without any problems: the logs were delivered, the agents did not fall (well, almost), everyone was happy.
In October 2016, the fifth version of the Elastic Stack components, including the Beats 5.0, was released. In this version, a lot of work has been done on all the Beats agents, and we were able to replace log-courier (which by that time had its problems) with Filebeat, which we are still using.
In the transition to version 5.0, we began to collect not only logs, but also some metrics: Packetbeat we began to be used here and there as an alternative to writing logs of HTTP requests to files, and Metricbeat collected system metrics and metrics of some services.
At this point, the work of our engineers with logs has become much simpler: now you didn’t need to know which server to go to to see the log you were interested in, the exchange of the information found was simplified to simply sending a link to Kibana in chat rooms or mail, and the reports that were previously built in a few hours, they began to be created in a few seconds. It cannot be said that it was just a matter of comfort: we noticed changes in the quality of our work, in the quantity and quality of closed tasks, in the speed of response to problems at our stands.
At some point, we started using the ElastAlert utility from Yelp to send alerts to engineers. And then they thought: why not integrate it with our Zabbix, so that all the alerts have a standard format and are sent centrally? The solution was found quite quickly: ElastAlert allows, instead of sending, actually, notifications to execute any commands that we used.
Now, our ElastAlert rules, when triggered, execute a bash script for several lines, to which the arguments are passed the necessary data from the event that triggered the rule, and from the script, in turn, zabbix_sender is called, which sends the data to Zabbix for the desired node.
Since all the information about who generated the event and where, in Elasticsearch, is always there, there were no difficulties with integration. For example, we had a mechanism for automatic detection of WAS application servers before, and in the events they generate, the server name, cluster, cell, etc. are always recorded. This allowed us to use the query_key option in the ElastAlert rules so that the conditions of the rules are processed for each server separately. The script with zabbix_sender then leaves the exact "coordinates" of the server and the data is sent to Zabbix for the corresponding node.
Another solution, which we like very much and which was made possible by the centralized collection of logs, is a script for automatic establishment of tasks in JIRA: once a day, it scoops up all errors from the logs and, if there are no tasks for them, gets them. At the same time, from different indexes, by a unique request ID, all information that might be useful during an investigation is pulled up in a task. The result is such a standard blank with the necessary minimum of information, which then engineers can add if necessary.
Of course, we faced the issue of monitoring the stack itself. This is partially implemented using Zabbix, partly using the same ElastAlert, and we get the main performance metrics for Elasticsearch, Logstash and Kibana using standard monitoring integrated into the stack (Monitoring component in the X-Pack). We also installed netdata from Firehol on the servers with stack services themselves. It is useful when you need to see what is happening with a particular node right now, in real time and in high resolution.
Once the module for monitoring Elasticsearch was a little broken in it, we found it, repaired it, added all sorts of useful metrics and made a pull-request. So now netdata can monitor the latest versions of Elasticsearch, including basic JVM metrics, indexing performance, search performance, transaction log statistics, index segments, and so on. We like Netdata, and we are pleased that we were able to make a small contribution to it.
Today, after almost three years, our Elastic Stack looks like this:
Engineers work with the stack in three main ways:
- viewing and analyzing logs and metrics in Kibana;
- Dashboards in Grafana and Kibana;
- direct queries to Elasticsearch using SQL or embedded query DSL.
In total, all of these resources are allocated: 146 CPU, 484GB RAM, 17TB allocated for Elasticsearch data storage.
In total, we have 13 virtual machines in our Elastic Stack: 4 machines for “hot” Elasticsearch nodes, 4 for “warm”, 4 machines with Logstash and one balancer machine. On each hot node, Elasticsearch runs a Kibana instance. It happened from the very beginning, and so far we have not had to move Kibana to separate cars.
But the decision to bring Logstash to individual machines turned out to be one of the most correct and effective during the operation of the stack: the high competition for processor time between JVM Elasticsearch and Logstash led to not very pleasant special effects during load spikes. Garbage collectors suffered the most.
{kind=link}
We store data in the cluster for the last 30 days: now it is about 12 billion events. Per day, “hot” nodes write to the disk 400-500GB of new data with the maximum degree of compression (including shard-replica data). Our Elasticsearch cluster has hot / warm architecture, but we switched to it relatively recently, so less data is stored on the “warm” nodes than on the “hot” ones.
Our typical workload load is:
- indexing - an average of 13,000 rps with peaks up to 30,000 (excluding indexation into shards-replicas);
- search - 5200 rps.
We try to maintain a 40-50% CPU margin on hot Elasticsearch nodes, so that we can easily experience sudden surges in the number of indexed events and heavy requests from Kibana / Grafana or external monitoring systems. About 50% of RAM on hosts with Elasticsearch nodes is always available for page cache and off-heap JVM needs.
During the time since the launch of the first cluster, we have managed to identify for ourselves some of the positive and negative sides of the Elastic Stack as a means of log aggregation and a search and analysis platform.
What we especially like about the stack:
- A single ecosystem of products well integrated with each other, in which there is almost everything needed. The Beats were once not very good, but now we have no complaints against them.
- Logstash, for all its monstrosity, is a very flexible and powerful preprocessor and allows you to do a lot with raw data (and if it doesn't allow something, you can always write a Ruby snippet).
- Elasticsearch with plugins (and more recently out of the box) supports SQL as a query language, which makes it easy to integrate with other software and people to whom SQL is closer as a query language.
- High-quality documentation that allows you to quickly introduce new employees on the project to stay informed. Operation of the stack, therefore, does not become a matter for one person who has some specific experience and “secret knowledge”.
- No need to know in advance about the structure of the received data much to start collecting them: you can start to aggregate events as they are, and then, as you understand what useful information you can extract from them, change the approach to processing them without losing backward compatibility. There are many convenient tools for this in the stack: field aliases in indexes, scripted fields, etc.
{kind=link}
What we don't like:
- X-Pack components are distributed only on the subscription model and nothing else: if from Gold, for example, only RBAC support or PDF reports, then you will have to pay for everything in Gold. This is especially frustrating when, for example, only Graph is needed from Platinum, and in the appendix you can buy Machine Learning and another package of other functionality that you may not really need. Our attempts about a year ago to communicate with the Elastic sales department about licensing individual components of the X-Pack have come to naught, but perhaps something has changed since then.
- Quite frequent releases, in which in some way (every time new) break backward compatibility. You have to read the changelog very carefully and prepare for updates in advance. Every time you need to choose: stay on the old version, which works stably or try to upgrade for the sake of new features and performance gains.
In general, we are very pleased with the choice made in 2016, and we plan to transfer the operating experience of the Elastic Stack to our other projects: the tools provided by the stack were very tightly incorporated into our workflow and it would be very difficult to abandon them now.
And in our company a number of vacancies are open.