How to create a game AI: guide for beginners
- Transfer

I stumbled upon an interesting material about artificial intelligence in games. With an explanation of basic things about AI on simple examples, and still inside a lot of useful tools and methods for its convenient development and design. How, where and when to use them is also there.
Most examples are written in pseudocode, so deep knowledge of programming is not required. Under the cut there are 35 sheets of text with pictures and gifs, so get ready.
UPD. I apologize, but I already did my own translation of this article on Habré PatientZero . Read his version here., but for some reason the article passed by me (I used the search, but something went wrong). And since I’m writing to a game dev blog, I decided to leave my translation version for subscribers (some of my details are different, some are intentionally missed on the advice of the developers).
What is AI?
The game AI focuses on what actions an object should perform, based on the conditions in which it is located. This is usually called the management of "intelligent agents", where the agent is a game character, a vehicle, a bot, and sometimes something more abstract: a whole group of entities or even civilization. In each case, this is a thing that must see its environment, make decisions on its basis and act in accordance with them. This is called the Sense / Think / Act cycle (Feel / Think / Act):
- Sense: the agent finds or receives information about things in his environment that may affect his behavior (threats nearby, items to collect, interesting places to research).
- Think: the agent decides how to respond (considers whether it is safe enough to collect items or first have to fight / hide).
- Act: the agent performs actions to implement the previous decision (starts moving towards the enemy or object).
- ... now the situation has changed due to the actions of the characters, so the cycle repeats with new data.
AI typically concentrates on the Sense part of the loop. For example, autonomous cars take pictures of the road, combine them with radar and lidar data, and interpret. Usually, it makes machine learning that processes incoming data and gives them meaning, extracting semantic information like “there is another car 20 yards ahead of you”. These are the so-called classification problems.
The game does not need a complex system for extracting information, since most of the data is already an integral part of it. There is no need to run image recognition algorithms to determine whether there is an enemy ahead - the game already knows and conveys information right in the decision-making process. Therefore, part of the Sense cycle is often much simpler than Think and Act.
Game Restrictions AI
AI has a number of restrictions that must be observed:
- AI does not need to train in advance, as if it is an algorithm for machine learning. It makes no sense to write a neural network during development to observe tens of thousands of players and learn the best way to play against them. Why? Because the game is not released, but there are no players.
- The game should entertain and challenge, so agents should not find a better approach against people.
- Agents need to look realistic in order for players to feel like they are playing against real people. The program AlphaGo surpassed the person, but the chosen steps were far from the traditional understanding of the game. If the game imitates the human opponent, there should be no such feeling. The algorithm needs to be changed to make plausible decisions, rather than ideal ones.
- AI should work in real time. This means that the algorithm cannot monopolize the use of the processor for a long time to make decisions. Even 10 milliseconds for this is too long, because for most games it is enough from 16 to 33 milliseconds to complete all the processing and move on to the next frame of graphics.
- Ideally, if at least part of the system is data-driven, so that non-coders can make changes and adjustments take place faster.
Consider the approaches of AI, which cover the entire cycle of Sense / Think / Act.
Making basic decisions
Let's start with the simplest game - Pong. Purpose: to move the platform (paddle) so that the ball bounces off of it, and does not fly past. It's like tennis, in which you lose, if you do not hit the ball. Here, AI has a relatively easy task - to decide in which direction to move the platform.

Conditional statements
For AI in Pong there is the most obvious solution - always try to position the platform under the ball.
A simple algorithm for this, written in pseudo-code:
every frame / the update The while the game is the running:
the if the ball is to the left of the a paddle:
the move a paddle left
the else the if the ball is to the right of the a paddle:
the move a paddle right
If the platform moving with the speed of the ball, then this is the perfect algorithm for AI in Pong. There is no need to complicate anything if there is not so much data and possible actions for the agent.
This approach is so simple that the entire Sense / Think / Act cycle is barely noticeable. But he is:
- The Sense part is in two if statements. The game knows where the ball is and where the platform is, so the AI calls on it for this information.
- The Think part also comes in two if statements. They embody two solutions that are mutually exclusive in this case. As a result, one of the three actions is selected: move the platform to the left, move to the right, or do nothing if it is already properly located.
- The Act part is located in the Move Paddle Left and Move Paddle Right operators. Depending on the design of the game, they can move the platform instantly or at a certain speed.
Such approaches are called reactive — there is a simple set of rules (in this case, if statements in the code) that react to the current state of the world and act.
Decision tree
The example with the game Pong is actually equal to the formal concept of AI, called the decision tree. The algorithm passes it in order to achieve a “sheet” - a decision on what action to take.
Let's make a block diagram of a decision tree for the algorithm of our platform:
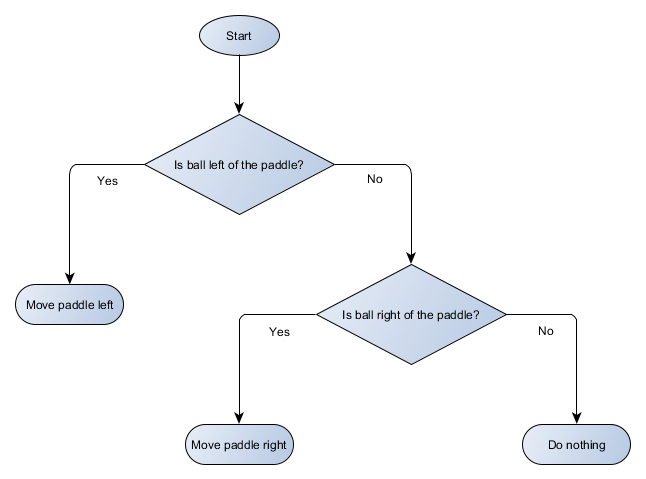
Each part of the tree is called a node (AI) - AI uses graph theory to describe such structures. There are two types of nodes:
- Decision nodes: the choice between two alternatives based on a test of a condition, where each alternative is represented as a separate node.
- End nodes: action to perform, representing the final decision.
The algorithm begins with the first node (the "root" of the tree). It either decides which child node to go to, or performs the action stored in the node and ends.
What is the advantage, if the decision tree, does the same work as the if-operators in the previous section? There is a common system, where each solution has only one condition and two possible results. This allows the developer to create AI from data representing solutions in the tree, avoiding its hard-coding. Let's present in the form of a table:
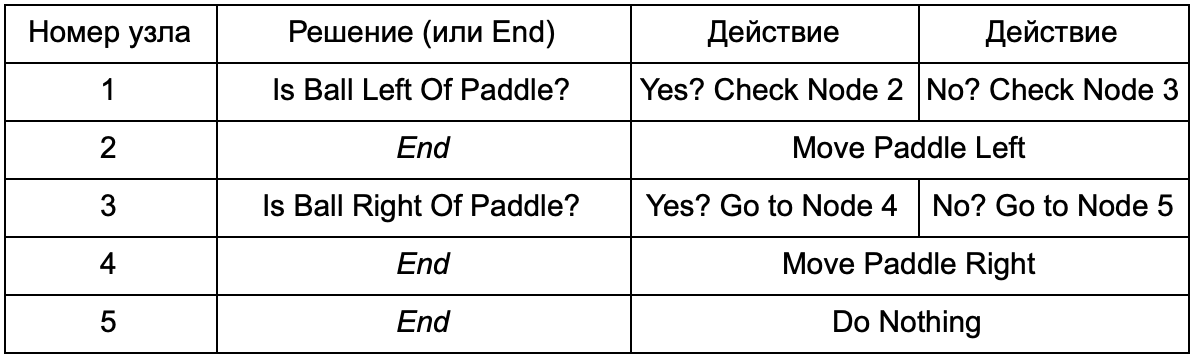
On the code side, you get a system for reading lines. Create a node for each of them, connect the decision logic based on the second column and the child nodes based on the third and fourth columns. You still need to program the conditions and actions, but now the structure of the game will be more difficult. In it, you add additional solutions and actions, and then configure the entire AI, simply by editing the text file with the tree definition. Next, transfer the file to the game designer, who can change the behavior without recompiling the game and changing the code.
Decision trees are very useful when they are built automatically based on a large set of examples (for example, using the ID3 algorithm). This makes them an effective and high-performance tool for classifying situations on the basis of the data obtained. However, we go beyond a simple system for agents to choose actions.
Scenarios
We analyzed the decision tree system, which used pre-created conditions and actions. The person designing the AI can arrange the tree the way he wants, but he still has to rely on the coder who programmed it all. What if we could give the designer the tools to create our own conditions or actions?
To prevent the programmer from writing code for Is Ball Left Of Paddle and Is Ball Right Of Paddle conditions, he can create a system in which the designer will record the conditions for checking these values. Then the decision tree data will look like this:
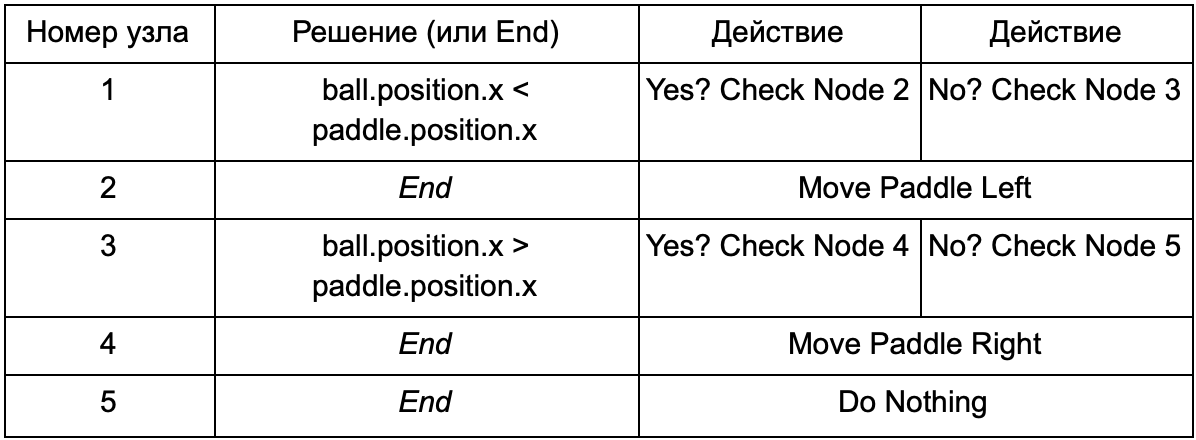
In essence, this is the same as in the first table, but the solutions within themselves have their own code, a bit like the conditional part of an if-operator. On the code side, this would be read in the second column for decision nodes, but instead of searching for a specific condition for execution (Is Ball Left Of Paddle), it evaluates the conditional expression and returns true or false, respectively. This is done using the Lua scripting language or Angelscript. Using them, the developer can take objects in his game (ball and paddle) and create variables that will be available in the script (ball.position). In addition, the scripting language is simpler than C ++. It does not require a complete compilation stage, so it is ideal for quickly adjusting game logic and allows non-coders to create the necessary functions themselves.
In the above example, the scripting language is used only to evaluate the conditional expression, but it can also be used for actions. For example, the Move Paddle Right data can become a script operator (ball.position.x + = 10). So that the action is also defined in the script, without the need to program the Move Paddle Right.
You can go even further and write the decision tree completely in the scripting language. This will be code in the form of hard-coded (hardcoded) conditional statements, but they will be in external script files, that is, they can be changed without recompiling the entire program. Often, you can modify the script file during the game to quickly test different AI reactions.
Event Response
The examples above are perfect for pong. They continuously run the Sense / Think / Act cycle and act on the basis of the last state of the world. But in more complex games you need to respond to individual events, and not to evaluate everything at once. Pong is already a bad example. Choose another.
Imagine a shooter where enemies are still until they find a player, and then act depending on their “specialization”: someone will run “rashit”, someone will attack from afar. This is still a basic reactive system - “if a player is spotted, do something,” but it can be logically divided into the Player Seen event and the reaction (select the answer and execute it).
This brings us back to the Sense / Think / Act cycle. We can pin the Sense part that each frame will check to see if the AI sees the player. If not, nothing happens, but if it sees, then the Player Seen event is raised. The code will have a separate section, which says: “when the Player Seen event occurs, do it”, where is the answer you need to access the Think and Act parts. Thus, you set up reactions to the Player Seen event: ChargeAndAttack to the “bashing” character, and HideAndSnipe to the sniper. These links can be created in a data file for quick editing without having to recompile. And here you can also use the scripting language.
Making difficult decisions
Although simple reaction systems are very effective, there are many situations where they are not enough. Sometimes you need to make various decisions based on what the agent is doing at the moment, but it’s hard to imagine it as a condition. Sometimes there are too many conditions to effectively present them in a decision tree or script. Sometimes you need to assess in advance how the situation will change before deciding on the next step. To solve these problems, more complex approaches are needed.
Finite state machine
Finite state machine or FSM (finite state machine) is a way of saying that our agent is currently in one of several possible states, and that he can move from one state to another. There are a number of such states - hence the name. The best example from life is a traffic light. In different places there are different sequences of lights, but the principle is the same - each state represents something (wait, go, etc.). A traffic light is in only one state at any given time, and moves from one to another based on simple rules.
With the NPC in games a similar story. For example, take guards with such states:
- Patrolling
- Attacking.
- Fleeing.
And such conditions for changing its state:
- If the guard sees the enemy, he attacks.
- If the guardian attacks, but no longer sees the enemy, he returns to patrol.
- If the guardian attacks, but is badly injured, he runs away.
You can also write if-operators with a guardian state variable and various checks: is there an enemy nearby, what is the health level of the NPC, etc. Add some more states:
- Inaction (Idling) - between patrols.
- Search (Searching) - when the observed enemy disappeared.
- Ask for help (Finding Help) - when the enemy is seen, but too strong to fight it alone.
The choice for each of them is limited - for example, the guard will not go looking for a hiding enemy if he has poor health.
In the end, the huge list “if <x and y, but not z> then <p>” can become too cumbersome, so you should formalize the method that allows us to keep in mind the states and transitions between states. To do this, we take into account all the states, and under each state we write into the list all transitions to other states, along with the conditions necessary for them.
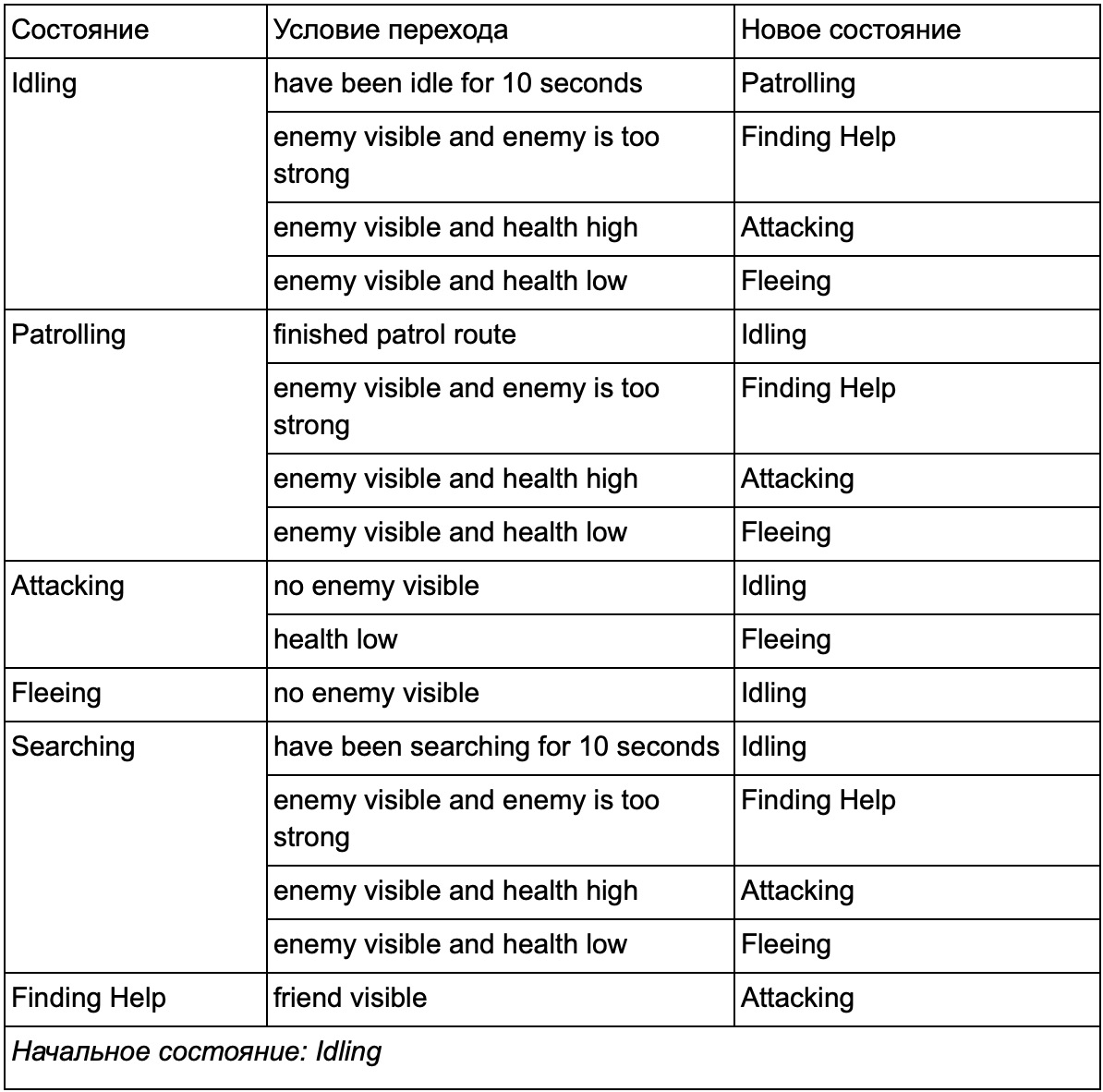
This state transition table is a comprehensive way of representing FSM. Draw a diagram and get a complete overview of how the behavior of the NPC changes.
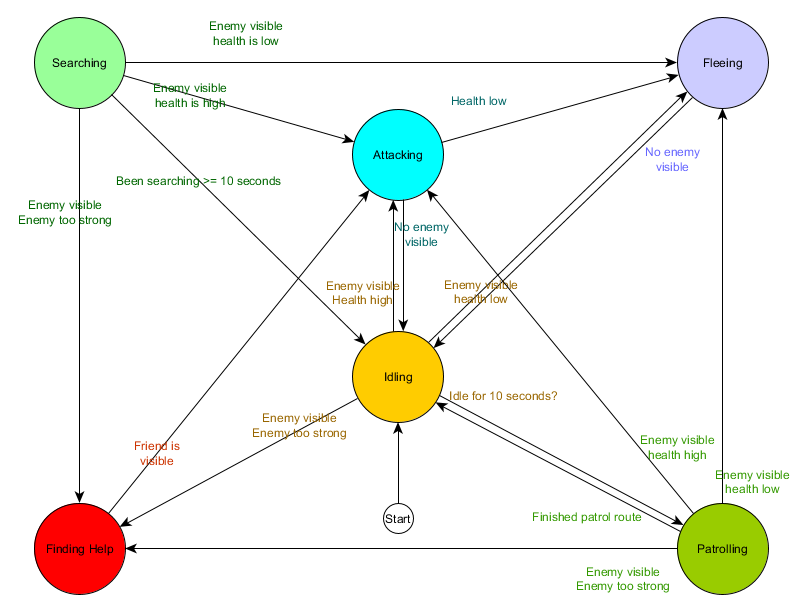
The diagram reflects the essence of decision making for this agent based on the current situation. And each arrow shows the transition between states, if the condition next to it is true.
Each update we check the current state of the agent, review the list of transitions, and if the conditions for the transition are met, it takes a new state. For example, each frame is checked if the 10-second timer has expired, and if so, the guard enters Patrolling from the Idling state. In the same way, the Attacking state checks the health of the agent — if it is low, it goes into the Fleeing state.
This is a state transition processing, but what about the behavior associated with the states themselves? Regarding the implementation of the actual behavior for a particular state, there are usually two types of “hooks” where we assign actions to the FSM:
- Actions that we periodically perform for the current state.
- The actions that we take in the transition from one state to another.
Examples for the first type. The Patrolling state each frame will move the agent along the patrol route. Attacking state Each frame will try to start an attack or go to a state where it is possible.
For the second type, consider the transition “if the enemy is visible and the enemy is too strong, then go to the Finding Help state. The agent must choose where to go for help and save this information so that the Finding Help state knows where to turn. Once assistance is found, the agent goes back to the Attacking state. At this point, he will want to tell the ally about the threat, so the NotifyFriendOfThreat action may occur.
Again, we can look at this system through the lens of the Sense / Think / Act cycle. Sense is embodied in the data used by the transition logic. Think - transitions available in every condition. And Act is carried out by actions performed periodically within a state or on transitions between states.
Sometimes continuous polling of transition conditions can be costly. For example, if each agent performs complex calculations every frame in order to determine whether it sees enemies and see if it is possible to move from the Patrolling state to Attacking - this will take a lot of processor time.
Important changes in the state of the world can be viewed as events that will be processed as they appear. Instead of the FSM checking the transition condition “can my agent see the player?” Each frame, you can configure a separate system to perform checks less frequently (for example, 5 times per second). And the result is to give out Player Seen when the check passes.
This is transmitted to the FSM, which should now go into the condition Player Seen event received and respond accordingly. The resulting behavior is the same except for an almost imperceptible delay before the answer. But the performance has become better as a result of the separation of a part of Sense into a separate part of the program.
Hierarchical finite state machine
However, working with large FSM is not always convenient. If we want to expand the attack state, replacing it with separate MeleeAttacking (melee) and RangedAttacking (ranged combat), we will have to change the transitions from all other states that lead to the Attacking state (current and future).
You probably noticed that in our example there are a lot of duplicate transitions. Most transitions in the Idling state are identical to transitions in the Patrolling state. It would be nice not to repeat, especially if we add more similar states. It makes sense to group Idling and Patrolling under the general label "non-combat", where there is only one common set of transitions to combat states. If we represent this label as a state, then Idling and Patrolling will become substates. An example of using a separate transition table for the new non-combat substate:
Main states:
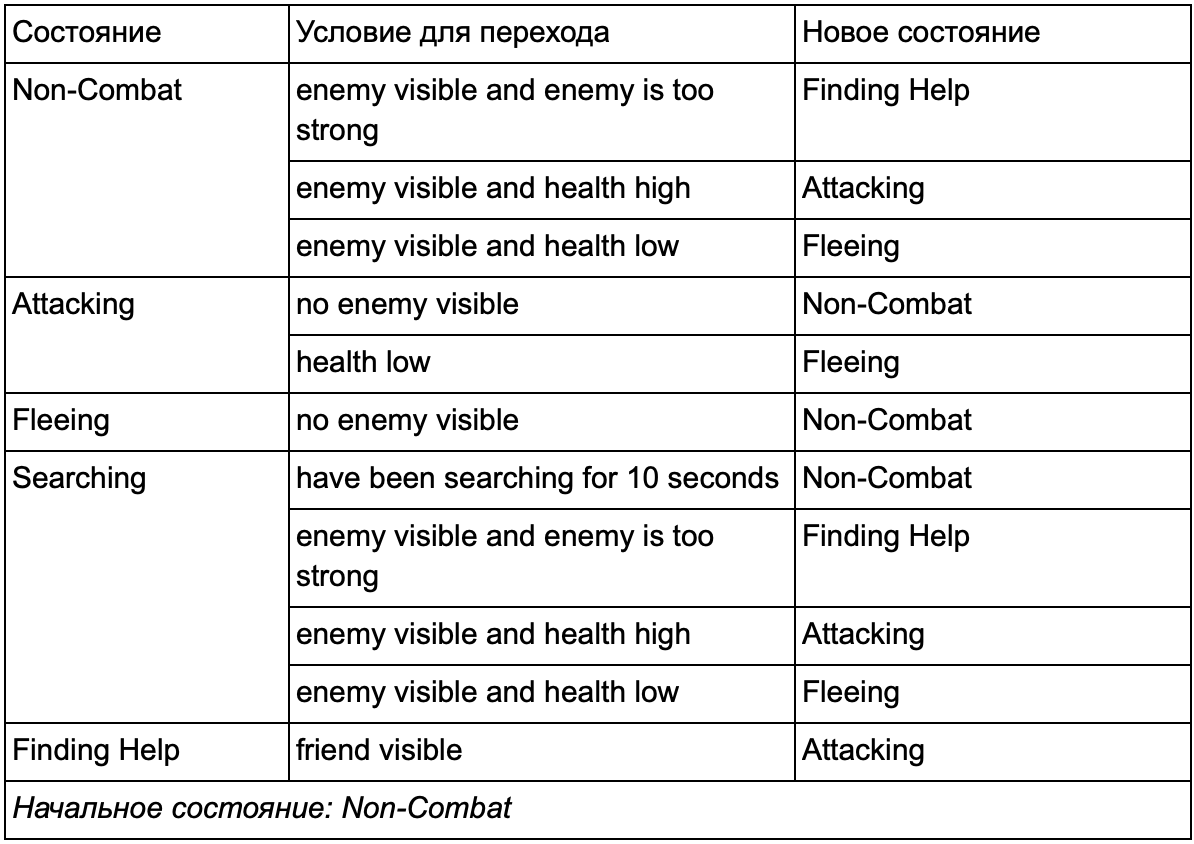
State outside the battlefield:

And in the form of a diagram:
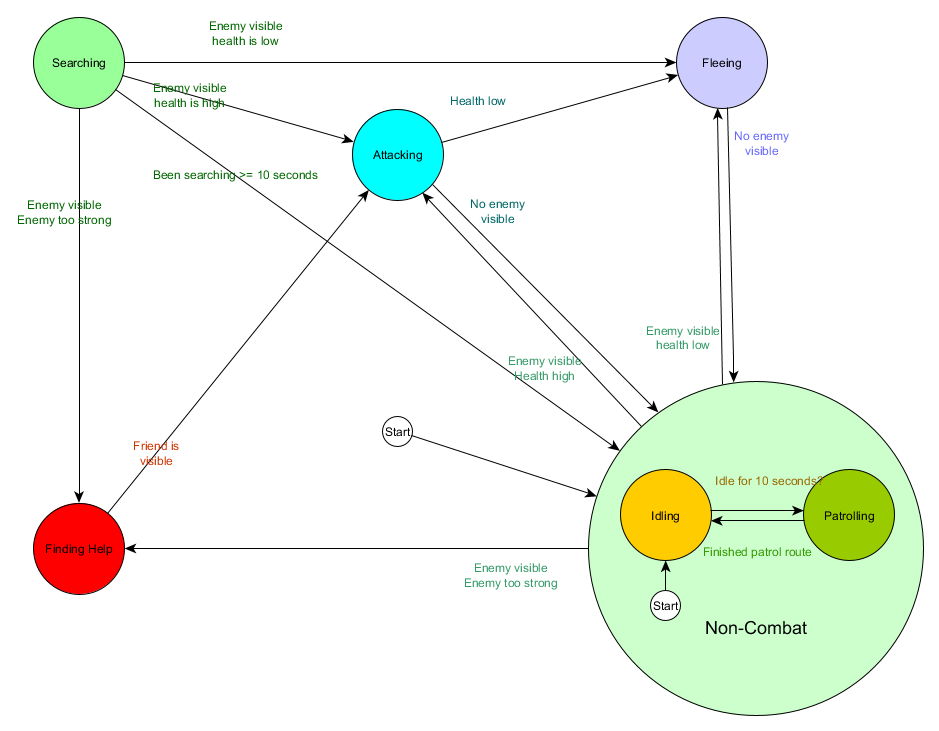
This is the same system, but with a new non-combat condition that includes Idling and Patrolling. With each state containing FSM with substates (and these substates, in turn, contain their own FSM - and so on, as much as you need), we get a Hierarchical Finite State Machine or HFSM (hierarchical finite state machine). Having grouped a non-combat state, we cut out a bunch of redundant transitions. We can do the same for any new states with common transitions. For example, if in the future we expand the Attacking state to the MeleeAttacking and MissileAttacking states, they will be substates, moving between each other based on the distance to the enemy and the availability of ammunition. As a result, complex behaviors and sub-models of behavior can be represented with a minimum of duplicate transitions.
Behavior tree
HFSM creates complex combinations of behaviors in a simple way. However, there is a slight difficulty that decision making in the form of transition rules is closely related to the current state. And in many games this is exactly what you need. A careful use of the state hierarchy can reduce the number of repetitions during a transition. But sometimes you need rules that work no matter what state you are in or that apply in almost any state. For example, if an agent’s health dropped to 25%, you want him to run away regardless of whether he was in a fight, idle or talking - you have to add this condition to each state. And if your designer later wants to change the low health threshold from 25% to 10%, then you’ll have to do it again.
Ideally, this situation requires a system in which decisions “in which state to be” are outside the states themselves, in order to make changes only in one place and not touch the conditions of the transition. Here are trees of behavior.
There are several ways to implement them, but the essence for all is about the same and similar to the decision tree: the algorithm starts with a “root” node, and there are nodes in the tree representing either solutions or actions. True, there are a few key differences:
- Now the nodes return one of three values: Succeeded (if the job is completed), Failed (if it cannot be started) or Running (if it is still running and there is no final result).
- No more decision nodes for choosing between two alternatives. Instead, Decorator nodes that have one child node. If they are Succeed, then they perform their only child node.
- Nodes that perform actions return a Running value to represent the actions they are performing.
This small set of nodes can be combined to create a large number of complex behaviors. Imagine the guardian HFSM from the previous example as a behavior tree:
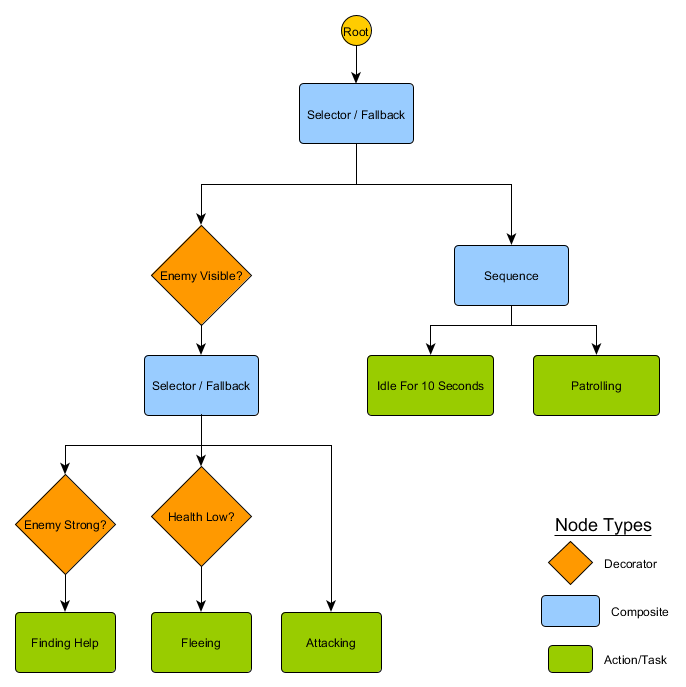
With this structure, there should not be an explicit transition from Idling / Patrolling to Attacking or any other state. If the enemy is visible and the character’s health is low, execution will stop at the Fleeing node, regardless of which node he previously performed — Patrolling, Idling, Attacking, or whatever.
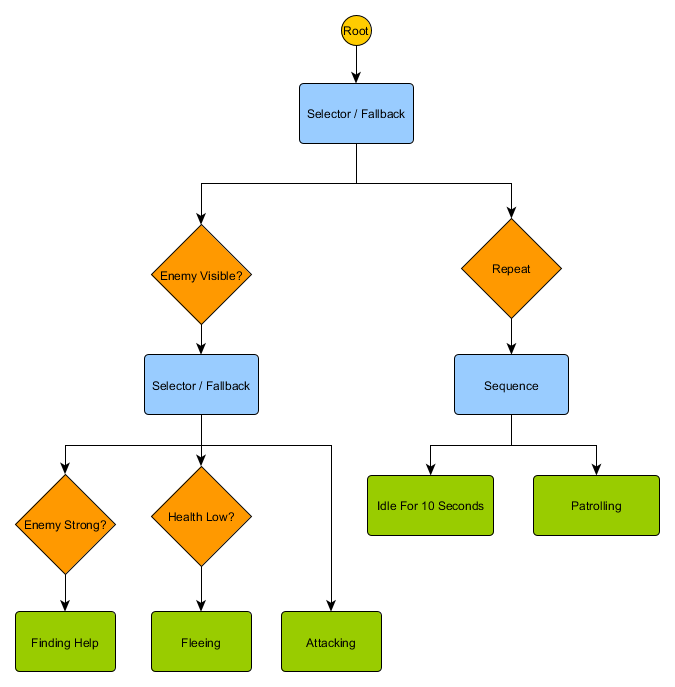
Trees of behavior are complex - there are many ways to create them, and finding the right combination of decorators and composite nodes can be problematic. There are also questions about how often to check a tree - do we want to go through it every part or only when one of the conditions has changed? How to store a node state — how to know when we were in the Idling state for 10 seconds, or how to know which nodes were executed the last time in order to process the sequence correctly?
That is why there are many implementations. For example, on some systems, decorator nodes have been replaced with built-in decorators. They re-evaluate the tree when the conditions of the decorator change, help to join nodes and provide periodic updates.
Utility-based system
Some games have many different mechanics. It is desirable that they receive all the advantages of simple and general rules of transition, but not necessarily in the form of a complete tree of behavior. Instead of having a clear set of choices or a tree of possible actions, it is easier to study all the actions and choose the most suitable at the moment.
Utility-based system (system based on utility) will help with just that. This is a system where an agent has many actions, and he chooses which one to perform, based on the relative utility of each. Where utility is an arbitrary measure of how important or desirable it is for an agent to perform this action.
The calculated utility of the action based on the current state and environment, the agent can check and select the most appropriate other state at any time. This is similar to FSM, except where transitions are determined by the score for each potential state, including the current one. Please note that we choose the most useful action for the transition (or stay if we have already completed it). For more variety, this may be a weighted but random selection from a small list.
The system assigns an arbitrary range of utility values - for example, from 0 (completely undesirable) to 100 (fully desirable). Each action has a number of parameters that affect the calculation of this value. Returning to our example with the guard:

Transitions between actions are ambiguous - any state can follow any other. Action priorities are in return values of utility. If the enemy is visible, and this enemy is strong, and the character’s health is low, then both Fleeing and FindingHelp will return high non-zero values. At the same time FindingHelp will always be higher. Similarly, non-combat actions never return more than 50, so they will always be lower than combat. You need to take this into account when creating actions and calculating their utility.
In our example, actions return either a fixed constant value or one of two fixed values. A more realistic system involves returning the estimate from a continuous range of values. For example, the Fleeing action returns higher utility values if the health of the agent is low, and the Attacking action returns lower if the enemy is too strong. Because of this, Fleeing takes precedence over Attacking in any situation where the agent feels that he does not have enough health to defeat the opponent. This allows you to change the priorities of actions based on any number of criteria, which makes this approach more flexible and variable than the behavior tree or FSM.
Each action has many conditions for the calculation of the program. They can be written in a scripting language or as a series of mathematical formulas. In The Sims, which models the character's daily routine, adds an extra level of computation — the agent gets a number of “motivations” that affect the utility scores. If a character is hungry, then over time he will starve even more, and the result of the usefulness of the action of EatFood will grow until the character performs it, reducing the level of hunger, and returning the value of EatFood to zero.
The idea of choosing actions based on a rating system is quite simple, so the Utility-based system can be used as part of AI's decision-making processes, and not as a complete replacement. A decision tree can request a utility estimate of two children and select a higher one. Similarly, a behavior tree can have a composite Utility node for evaluating the usefulness of actions to decide which child to execute.
Movement and navigation
In previous examples, we had a platform that we moved left or right, and a guard who patrolled or attacked. But how exactly do we handle the moving agent for a specific period of time? How do we set speed, how do we avoid obstacles, and how do we plan a route if it’s harder to get to your destination than just moving in a straight line? Let's take a look at this.
Control
At the initial stage, we will assume that each agent has a value of speed, which includes how fast it moves and in what direction. It can be measured in meters per second, kilometers per hour, pixels per second, etc. Recalling the Sense / Think / Act cycle, we can imagine that the Think part selects the speed, and the Act part applies this speed to the agent. Usually in games there is a physical system that performs this task for you, studying the value of the speed of each object and adjusting it. Therefore, you can leave the AI with one task - to decide what speed the agent should have. If you know where the agent should be, then you need to move it in the right direction at the set speed. Very trivial equation:
desired_travel = destination_position - agent_position
Imagine a 2D world. The agent is at (-2, -2), the destination is somewhere in the northeast at (30, 20), and the necessary way for the agent to be there is (32, 22). Suppose these positions are measured in meters - if we take the agent's speed for 5 meters per second, then we will scale our displacement vector and we will get the speed approximately (4.12, 2.83). With these parameters, the agent would arrive at the destination in almost 8 seconds.
You can recalculate values at any time. If the agent was halfway to the goal, the movement would be half the length, but since the maximum speed of the agent is 5 m / s (we decided above), the speed will be the same. It also works for moving targets, allowing the agent to make small changes as they move.
But we want more variation — for example, slowly increasing our speed to simulate a character moving from a standing state and moving on to a run. The same can be done at the end before stopping. These features are known as steering behaviors, each of which has specific names: Seek (search), Flee (escape), Arrival (arrival), etc. The idea is that the acceleration forces can be applied to the speed of the agent, based on comparing the position of the agent and the current speed with the destination in order to use different ways of moving to the target.
Each behavior has a slightly different purpose. Seek and Arrival are ways to move an agent to a destination. Obstacle Avoidance and Separation adjust the movement of the agent to avoid obstacles to the goal. Alignment and Cohesion keep agents moving together. Any number of different steering behaviors can be summed up to obtain a single path vector, taking into account all factors. An agent that uses Arrival, Separation and Obstacle Avoidance behaviors to keep away from walls and other agents. This approach works well in open locations without unnecessary details.
In more difficult conditions, the addition of different behaviors works worse - for example, the agent may get stuck in the wall due to the conflict Arrival and Obstacle Avoidance. Therefore, you need to consider options that are more complicated than just the addition of all values. The way is this: instead of adding the results of each behavior, you can consider the movement in different directions and choose the best option.
However, in a complex environment with dead ends and a choice of which way to go, we will need something more advanced.
Finding the way
Steering behaviors are great for simple movement in an open area (football field or arena), where getting from A to B is a straight path with minor deviations past obstacles. For complex routes, we need pathfinding, which is a way to explore the world and decide on a route through it.
The easiest is to apply a grid to each square next to the agent and evaluate which of them are allowed to move. If one of them is a destination, then follow from it along the route from each square to the previous one, until you reach the beginning. This is the route. Otherwise, repeat the process with the nearest other squares until you find the destination or the squares run out (this means that there is no possible route). This is what is formally known as Breadth-First Search or BFS (Wide Search Algorithm). At every step he looks in all directions (therefore breadth, "width"). The search space is like a wavefront that moves until it reaches the desired location - the search area expands at each step until it reaches the end point,
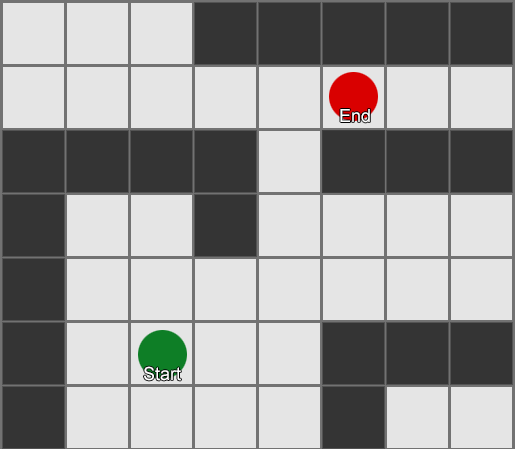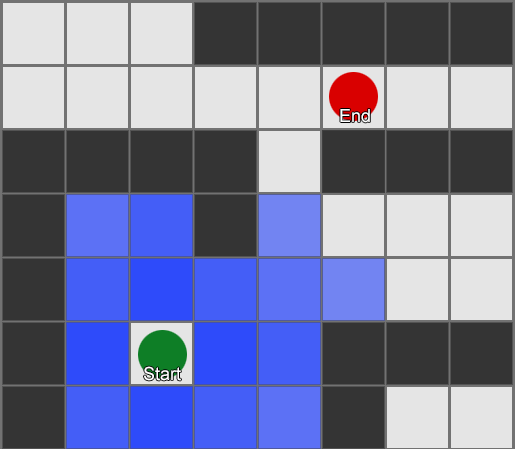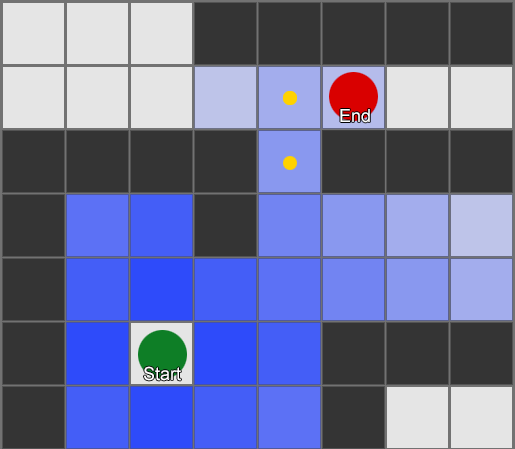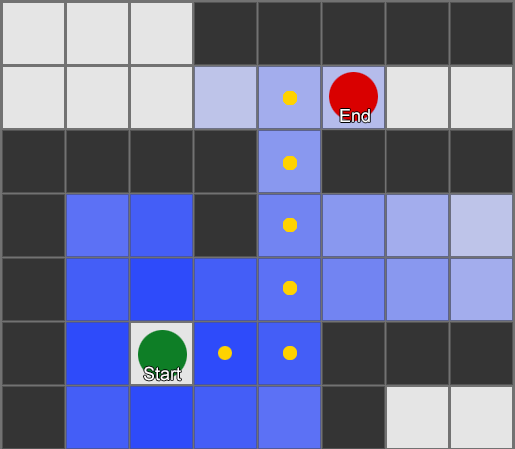
As a result, you will receive a list of squares that make up the desired route. This is the path (from here, pathfinding) - a list of places that the agent will visit, following the destination.
Considering that we know the position of each square in the world, we can use the steering behaviors to move along the path - from node 1 to node 2, then from node 2 to node 3, and so on. The simplest option is to head to the center of the next square, but even better, stop in the middle of the edge between the current square and the next. Because of this, the agent will be able to cut corners at sharp turns.
The BFS algorithm has its drawbacks - it examines as many squares in the “wrong” direction as in the “right” direction. A more complex algorithm called A * (A star) appears here. It also works, but instead of blindly examining the squares of the neighbors (then neighbors of neighbors, then neighbors of neighbors of neighbors, and so on), it assembles the nodes into a list and sorts them so that the next node to be investigated is always the one that will lead to the shortest route. Nodes are sorted based on heuristics, which takes into account two things - the “cost” of a hypothetical route to the desired square (including any movement costs) and an assessment of how far this square is from the destination (shifting the search in the right direction).
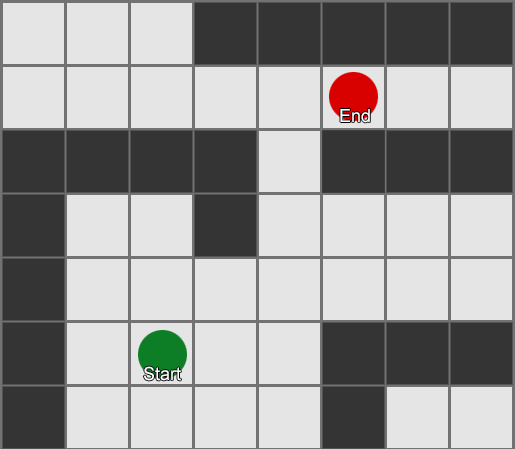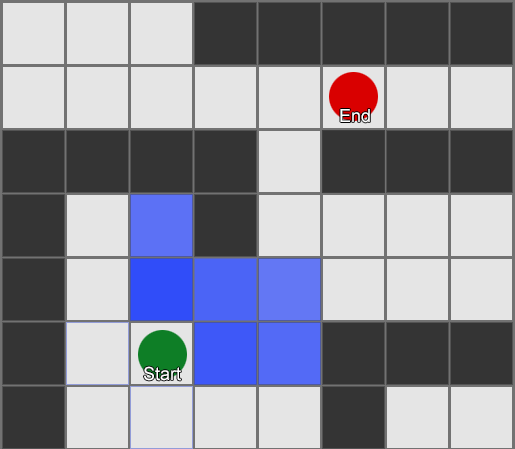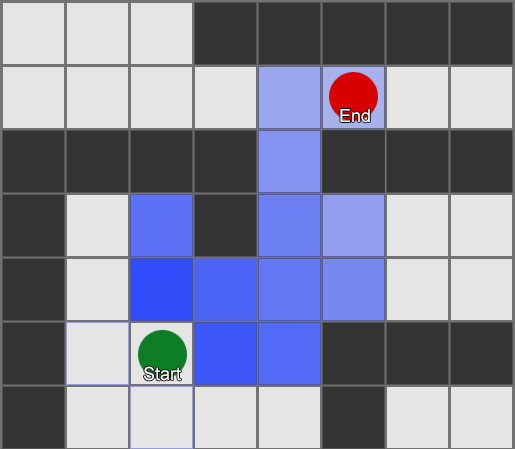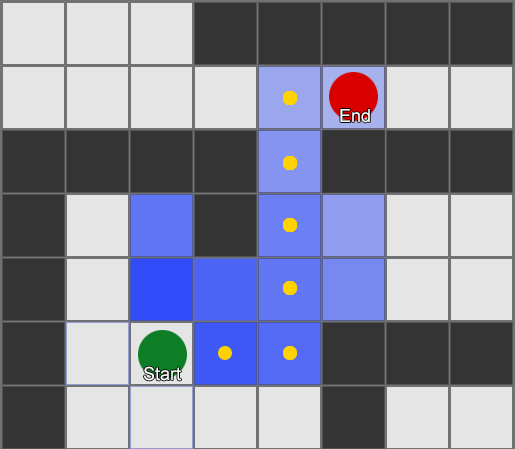
In this example, it is shown that the agent examines one square at a time, each time choosing the next one, which is the most promising. The resulting path is the same as with BFS, but in the process less squares were considered - and this is of great importance for the performance of the game.
Motion without mesh
But most games are not laid out on the grid, and often it can not be done without sacrificing realism. Compromises are needed. What sizes should be squares? Too large - and they will not be able to correctly present small corridors or turns, too small - there will be too many squares to search for, which in the end will take a lot of time.
The first thing to understand is the grid gives us a graph of connected nodes. Algorithms A * and BFS actually work on charts and do not care about our grid at all. We could put the nodes in any place of the game world: if there is a connection between any two connected nodes, as well as between the starting and ending points and at least one of the nodes, the algorithm will work as well as before. This is often called a waypoint system, since each node represents a significant position in the world that can be part of any number of hypothetical paths.
Example 1: a node in each square. The search starts from the node where the agent is located, and ends at the node of the desired square.
Example 2: a smaller set of nodes (waypoints). The search begins in the square with the agent, passes through the required number of nodes, and then continues to the destination.
It is quite flexible and powerful system. But some caution is needed in the solutions, where and how to place the waypoint, otherwise agents may simply not see the nearest point and will not be able to start the way. It would be easier if we could automatically place waypoints based on the geometry of the world.
A navigation mesh or navmesh appears. This is usually a 2D mesh of triangles that is superimposed on the geometry of the world — wherever the agent is allowed to walk. Each of the triangles in the grid becomes a node in the graph and has up to three adjacent triangles that become adjacent nodes in the graph.
This picture is an example from the Unity engine - he analyzed the geometry in the world and created navmesh (in the screenshot in light blue). Each polygon in navmesh is an area where an agent can stand or move from one polygon to another polygon. In this example, the polygons are smaller than the floors on which they are located — made to take into account the size of the agent, which will go beyond its nominal position.

We can search for a route through this grid, again using the A * algorithm. This will give us an almost perfect route in the world, which takes into account all the geometry and does not require unnecessary nodes and the creation of waypoints.
Pathfinding is too broad a topic about which one section of the article is not enough. If you want to study it in more detail, then the site of Amit Patel will help ..
Planning
We were convinced with the pathfinding that sometimes it’s not enough just to choose a direction and move - we have to choose a route and take a few turns to get to the desired destination. We can summarize this idea: achieving the goal is not just the next step, but a whole sequence, where sometimes you need to look ahead a few steps to find out what the first one should be. This is called planning. Pathfinding can be considered as one of several planning additions. From the point of view of our Sense / Think / Act cycle, this is where the Think part is planning several parts of the Act for the future.
Let's look at the example of the board game Magic: The Gathering. We go first with such a set of cards on hand:
- Swamp - gives 1 black mana (earth map).
- Forest - gives 1 green mana (map of the earth).
- Fugitive Wizard - requires 1 blue mana to summon.
- Elvish Mystic - requires 1 green mana to summon.
The remaining three cards are ignored to make it easier. According to the rules, a player is allowed to play 1 land card per turn, he can tap this card to extract mana from it, and then use spells (including summoning a creature) by the amount of mana. In this situation, the human player knows that he needs to play Forest, “tap” 1 green mana, and then call Elvish Mystic. But how to guess this game AI?
Simple planning
The trivial approach is to try each action in turn, until it remains suitable. Looking at the cards, the AI sees that Swamp can play. And plays it. Are there any other actions on this turn? He cannot call either the Elvish Mystic or the Fugitive Wizard, because their summoning requires green and blue mana, respectively, and Swamp only gives black mana. And he will not be able to play Forest, because he has already played Swamp. Thus, the AI game went by the rules, but did it badly. Can be improved.
Planning can find a list of actions that lead the game to the desired state. Also, as each square on the way had neighbors (in pathfinding), each action in the plan also has neighbors or successors. We can search for these actions and subsequent actions until we reach the desired state.
In our example, the desired result is “summon a creature, if possible.” At the beginning of the turn, we see only two possible actions allowed by the rules of the game:
1. Play Swamp (result: Swamp in the game)
2. Play Forest (result: Forest in the game)
Each accepted action can lead to further actions and close others, again depending on the rules of the game. Imagine that we played Swamp - this will remove Swamp as the next step (we have already played it), it will also delete Forest (because according to the rules you can play one land card per turn). After this, the AI adds as the next step - getting 1 black mana, because there are no other options. If he goes further and selects Tap the Swamp, he will receive 1 unit of black mana and cannot do anything with it.
1. Play Swamp (result: Swamp in the game)
1.1 “Tap” Swamp (result: Swamp “tapnuta”, +1 black mana unit)
No action available - END
2. Play Forest (result: Forest in the game) The
list of actions is short we are at a dead end. Repeat the process for the next step. We play Forest, open the action "get 1 green mana", which in turn will open the third action - the call of Elvish Mystic.
1. Play Swamp (result: Swamp in the game)
1.1 "Tap out" Swamp (result: Swamp "tap out", +1 black mana unit)
No action available - END
2. Play Forest (result: Forest in the game)
2.1 "Tap" Forest (result: Forest taped, +1 green mana)
2.1.1 Summon Elvish Mystic (result: Elvish Mystic in the game, -1 green mana unit)
No action available - END
Finally, we studied all the possible actions and found a plan that calls a creature.
This is a very simplified example. It is advisable to choose the best possible plan, rather than any one that meets some criteria. As a rule, it is possible to evaluate potential plans based on the final result or the cumulative benefit of their implementation. You can earn 1 point for playing a map of the earth and 3 points for calling a creature. Playing Swamp would be a plan giving 1 point. And to play Forest → Tap the Forest → to call on Elvish Mystic - immediately gives 4 points.
This is how planning in Magic: The Gathering works, but according to the same logic, this also applies in other situations. For example, move the pawn to make room for the bishop in chess. Or hide behind a wall to safely shoot XCOM like that. In general, you understand the essence.
Improved planning
Sometimes there are too many potential actions to consider every possible option. Returning to the example of Magic: The Gathering: let's say that in the game and on your hands you have several maps of the earth and creatures - the number of possible combinations of moves can be calculated in dozens. There are several solutions to the problem.
The first method is backwards chaining. Instead of going through all the combinations, it is better to start with the final result and try to find a direct route. Instead of going from the root of a tree to a specific leaf, we move in the opposite direction - from leaf to root. This method is easier and faster.
If the enemy has 1 health unit, you can find a plan to “inflict 1 or more damage points”. To achieve this you need to fulfill a number of conditions:
1. Damage can cause a spell - it should be in hand.
2. To cast a spell, you need mana.
3. To get mana - you need to play a map of the earth.
4. To play a land card, you need to have it in your hand.
Another is best-first search. Instead of going through all the ways, we choose the most appropriate. Most often, this method gives an optimal plan without extra costs for searches. A * is a form of the best first search - by exploring the most promising routes from the very beginning, he can already find the best way without having to check the other options.
An interesting and increasingly popular option for best-first search is Monte Carlo Tree Search. Instead of guessing which plans are better than others when choosing each subsequent action, the algorithm selects random successors at each step until it reaches the end (when the plan led to victory or defeat). Then the final result is used to increase or decrease the assessment of the "weight" of the previous options. Repeating this process several times in a row, the algorithm gives a good assessment of which next step is better, even if the situation changes (if the opponent takes measures to prevent the player).
In the story about planning in games you will not do without Goal-Oriented Action Planning or GOAP (purposeful action planning). This is a widely used and discussed method, but besides a few distinctive details, this is, in fact, a backwards chaining method that we talked about earlier. If the task was to “destroy the player” and the player is behind cover, the plan might be: destroy with a grenade → get it → drop it.
Usually there are several goals, each with its own priority. If the goal with the highest priority cannot be completed (no combination of actions creates a plan to “destroy the player” because the player is not visible), the AI will return to the goals with a lower priority.
Training and adaptation
We have already said that gaming AI usually does not use machine learning, because it is not suitable for controlling agents in real time. But this does not mean that you cannot borrow anything from this area. We want such an opponent in a shooter from whom you can learn something. For example, find out about the best positions on the map. Or an opponent in a fighting game that would block combo tricks used by the player, motivating others to use. So machine learning in such situations can be quite helpful.
Statistics and probabilities
Before we move on to complex examples, let's estimate how far we can go, taking a few simple measurements and using them to make decisions. For example, a real-time strategy - how can we determine whether a player will be able to launch an attack in the first few minutes of the game and what defense against this to prepare? We can study the past experience of the player to understand what the future reaction may be. Let's start with the fact that we do not have such initial data, but we can collect them - every time the AI plays against a person, he can record the time of the first attack. After a few sessions, we will get an average time for the player to attack in the future.
Mean values also have a problem: if a player “rashil” 20 times, and played 20 times slowly, then the necessary values will be somewhere in the middle, and this will not give us anything useful. One solution is to limit the input data - you can consider the last 20 pieces.
A similar approach is used in assessing the likelihood of certain actions, assuming that the player’s past preferences will be the same in the future. If a player attacks us five times with a fireball, twice with lightning and once hand to hand, it is obvious that he prefers a fireball. We extrapolate and see the probability of using different weapons: fireball = 62.5%, lightning = 25% and hand-to-hand = 12.5%. Our game AI needs to prepare for fire protection.
Another interesting method is to use the Naive Bayes Classifier (a naive Bayes classifier) to study large amounts of input data and classify the situation so that the AI responds as needed. Bayesian classifiers are best known for using email in spam filters. There they investigate words, compare them with the place where these words appeared earlier (in spam or not), and draw conclusions about incoming letters. We can do the same with even less input. Based on all the useful information that the AI sees (for example, which enemy units are created, or what spells they use, or what technologies they explored), and the final result (war or peace, "crush" or defend, etc.) - we will select the desired behavior of the AI.
All of these learning methods are sufficient, but it is advisable to use them on the basis of data from testing. AI will learn to adapt to the different strategies that your playters used. An AI that adapts to the player after release may become too predictable or, on the contrary, too difficult to win.
Value based adaptation
Given the content of our game world and rules, we can change the set of values that influence decision making, and not just use the input data. We do this:
- Let AI collect data on the state of the world and key events during the game (as indicated above).
- Change some important values based on this data.
- We implement our solutions based on the processing or evaluation of these values.
For example, an agent has several rooms to choose from a first-person shooter map. Each room has its own value, which determines how desirable it is to visit. The AI randomly selects which room to go to based on the value value. Then the agent remembers which room he was killed in and reduces its value (the probability that he will return there). Similarly, for the reverse situation - if the agent destroys many opponents, then the value of the room increases.
Markov model
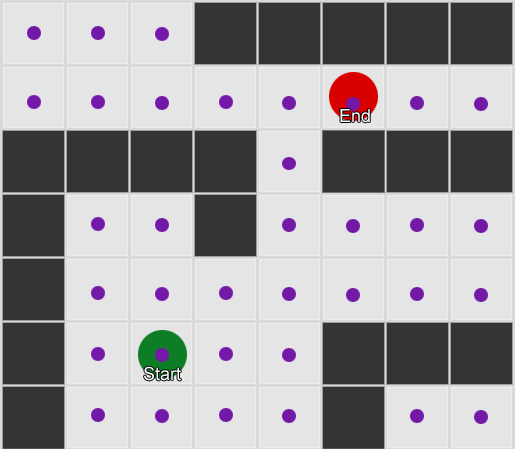
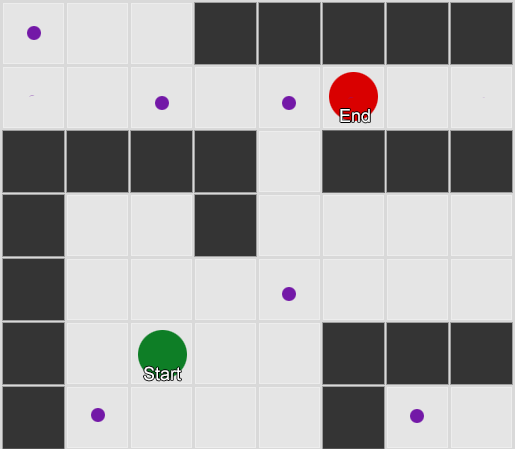
What if we use the collected data for forecasting? If you remember every room in which we see a player for a certain period of time, we will predict which room the player can go to. Having tracked and recorded the player's movement through the rooms (values), we can predict them.
Take three rooms: red, green and blue. As well as the observations that we recorded when watching a game session: The
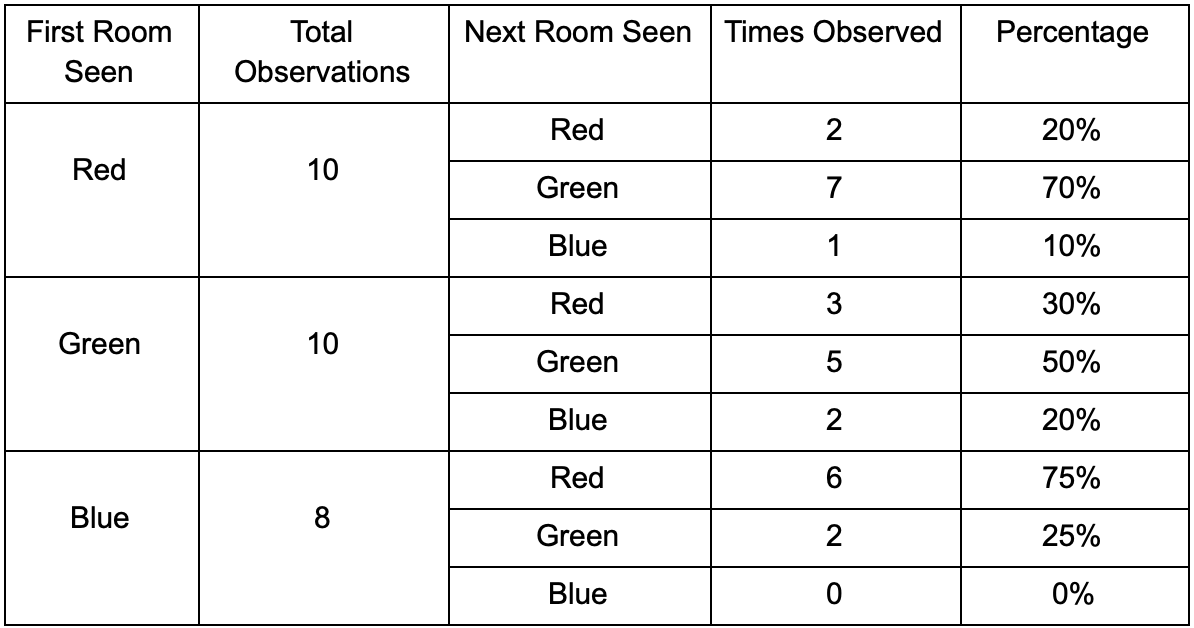
number of observations for each room is almost equal - we still do not know where to make a good place for an ambush. Statistics collection is also complicated by players respawn, which appear evenly throughout the map. But the data on the next room, which they enter after appearing on the map, is already useful.
It can be seen that the green room suits the players - most of the people from the red move into it, 50% of which remain there and further. The blue room, on the contrary, does not enjoy popularity, they almost don’t go to it, and if they do, they don’t linger.
But the data tells us something more important - when a player is in the blue room, the next room in which we will likely see him will be red, not green. Despite the fact that the green room is more popular than red, the situation changes if the player is in the blue. The next state (that is, the room into which the player will move) depends on the previous state (that is, the room in which the player is now). Because of the study of dependencies, we will make predictions more accurately than if we simply calculated the observations independently of each other.
Predicting the future state based on past data is called the Markov model, and such examples (with rooms) are called Markov chains. Since models represent the probability of changes between successive states, they are visually displayed as FSM with a probability around each transition. Previously, we used FSM to represent the behavioral state in which the agent was located, but this concept applies to any state, regardless of whether it is related to the agent or not. In this case, the states represent the room occupied by the agent:
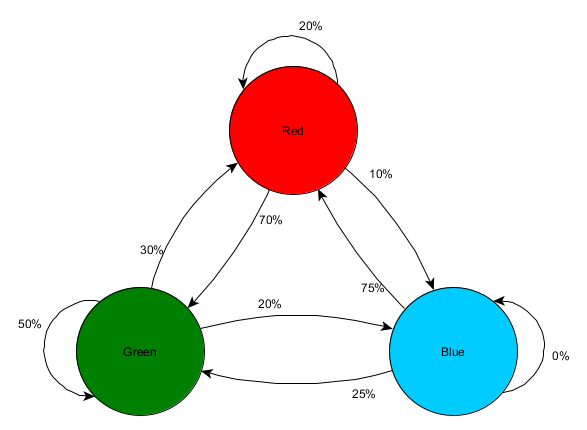
This is a simple variant of representing the relative probability of state changes, which gives the AI some possibility to predict the next state. You can predict a few steps forward.
If the player is in the green room, then there is a 50% chance that he will remain there on the next observation. But what is the likelihood that he will still be there even after? There is not only a chance that the player remained in the green room after two observations, but also a chance that he left and returned. Here is a new table with new data:
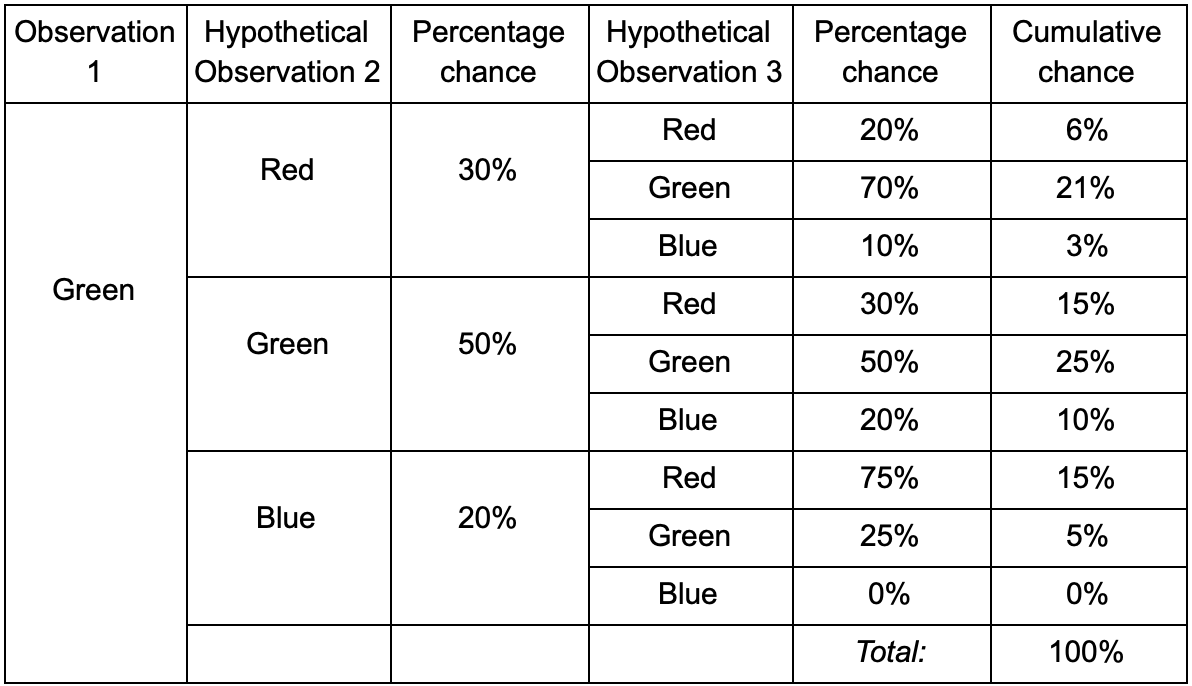
It is clear that the chance to see a player in the green room after two observations will be 51% - 21%, that he will have from the red room, 5% of them, that the player will visit the blue room between them, and 25% that the player does not leave the green room at all.
The table is simply a visual tool - the procedure only requires multiplying the probabilities at each step. This means that you can look far into the future with one amendment: we assume that the chance to enter the room depends entirely on the current room. This is called the Markov Property - the future state depends only on the present. But it is not absolutely accurate. Players can change decisions depending on other factors: the level of health or the amount of ammunition. Since we do not fix these values, our predictions will be less accurate.
N-grams
And what about the example of the fighting game and the prediction of the player's combo tricks? Same! But instead of a single state or event, we will explore the whole sequences that make up the combo strike.
One way to do this is to save each input (for example, Kick, Punch or Block) into a buffer and record the entire buffer as an event. So, the player repeatedly presses Kick, Kick, Punch to use the SuperDeathFist attack, the AI system stores all entries in the buffer and stores the last three used in each step.
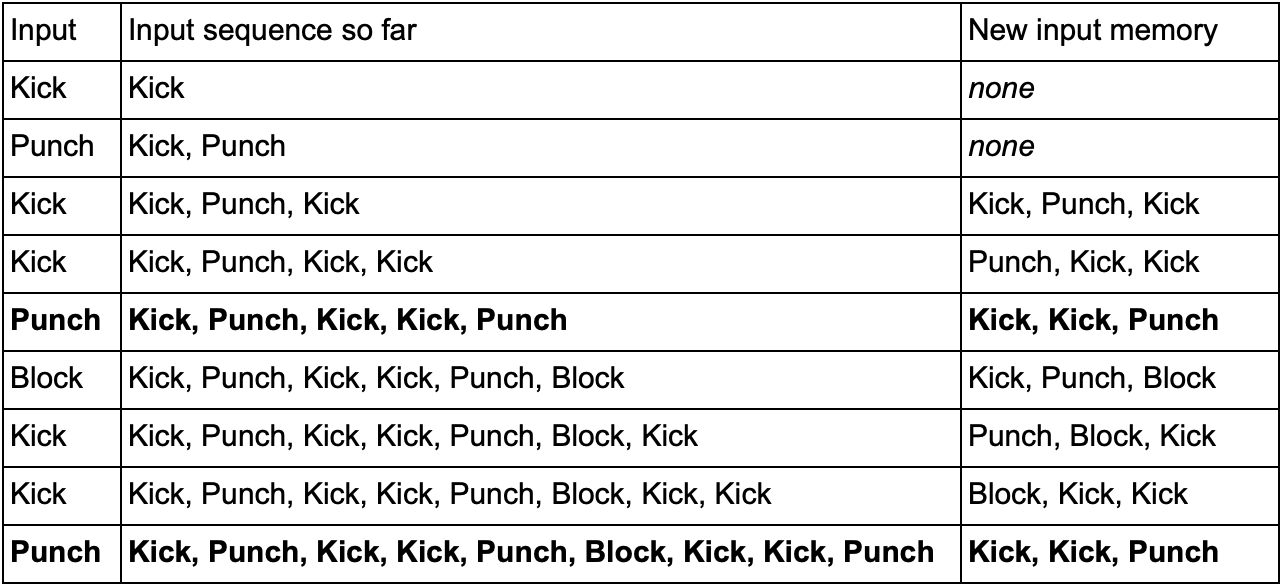
(Bold lines are highlighted when the player launches the SuperDeathFist attack.)
The AI will see all the options when the player chooses a Kick, followed by another Kick, and then notice that the next entry is always Punch. This will allow the agent to predict the SuperDeathFist combo method and block it, if possible.
These sequences of events are called N-grams (N-grams), where N is the number of stored items. In the previous example, it was a 3-gram (trigram), which means: the first two records are used to predict the third. Accordingly, in the 5-gram first four records predict the fifth and so on.
The developer needs to carefully choose the size of N-grams. A smaller number N requires less memory, but also stores a smaller history. For example, a 2-gram (bigram) will record Kick, Kick or Kick, Punch, but will not be able to store Kick, Kick, Punch, so the AI will not respond to the SuperDeathFist combo.
On the other hand, larger numbers require more memory and AI will be harder to learn, as there will be many more options. If you had three possible Kick, Punch or Block inputs, and we used a 10-gram, you will get about 60 thousand different options.
A bigram model is a simple Markov chain — each pair of “past state / current state” is a bigram, and you can predict a second state based on the first. 3-grams and larger N-grams can also be considered as Markov chains, where all the elements (except the last in the N-gram) together form the first state, and the last element is the second. The example with the fighting game shows the chance of transition from the state of Kick and Kick to the state of Kick and Punch. Considering several entries in the input history as one unit, we essentially convert the input sequence into a part of the whole state. This gives us a Markov property that allows us to use Markov chains to predict the next input and guess which combo move will be next.
Conclusion
We talked about the most common tools and approaches in the development of artificial intelligence. They also examined situations in which they need to be applied and where they are especially useful.
This should be enough to understand the basic things in game AI. But, of course, this is not all methods. The less popular, but no less effective are:
- optimization algorithms, including hill climbing, gradient descent and genetic algorithms
- competitive search / scheduling algorithms (minimax and alpha-beta pruning)
- classification methods (perceptrons, neural networks and support vector machines)
- systems for processing perception and agent memory
- architectural approaches to AI (hybrid systems, a subset of architectures and other ways of imposing AI systems)
- animation tools (motion planning and coordination)
- performance factors (level of detail, algorithms anytime, and timeslicing)
Online resources on the topic:
1. On GameDev.net there is a section with articles and tutorials on AI , as well as a forum .
2. AiGameDev.com contains many presentations and articles on a wide range of related to the development of game AI.
3. The GDC Vault includes topics from the GDC AI Summit, many of which are available for free.
4. Useful materials can also be found on the site AI Game Programmers Guild .
5. Tommy Thompson, an AI researcher and game developer, makes videos on the AI and Games YouTube channel with an explanation and study of AI in commercial games.
Related books:
1. The Game AI Pro book series is a collection of short articles explaining how to implement specific functions or how to solve specific problems.
The AI Pro the Game: Collected Wisdom of the Game the AI Professionals Help
the Game the AI Pro 2: Collected Wisdom of the Game the AI Professionals Help
the Game Pro the AI 3: Collected Wisdom of the Game the AI Professionals Help
2. Series AI Game Programming Wisdom - the predecessor series Game AI Pro. It has older methods, but almost all are relevant even today.
AI Game Programming Wisdom 1
AI Game Programming Wisdom 2
AI Game Programming Wisdom 3
AI Game Programming Wisdom 4
3. Artificial Intelligence: A Modern Approach- This is one of the basic texts for all who want to understand the general field of artificial intelligence. This book is not about game development - it teaches the basics of AI.