Linkedin regular expression puzzle parsing
Since childhood, we all know about crosswords. Humanity invented quite a few of their varieties. And one of these varieties involves the use of regular expressions, instead of questions about erudition. The link to one of such crosswords fell into my hands, and I enthusiastically began to unravel it.

In this article, I would like to parse this crossword on points. The article may be useful to those who are already familiar and use regular expressions in business, but who have problems with non-trivial tasks. In any case, I recommend trying it yourself; it is not complicated. Well, if things like negative retrospective checks are part of your working arsenal, then you will not find anything new in the article.
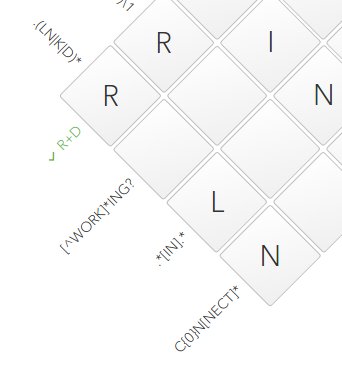
The usual crossword puzzle is rectangular in shape. The descriptions on the sides are regular expressions and should fully describe the contents of these cells. For clarity, the authors omitted the symbols
As with regular crosswords, the easiest way to start is with the simplest expression. In this case, this
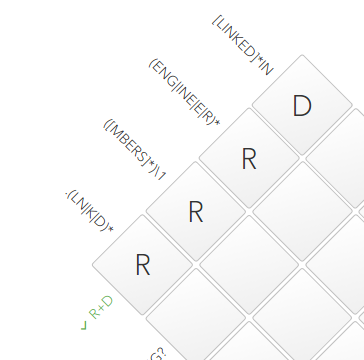
The line was marked in green, therefore, ours
These things regular expressions can be briefly described as follows: The line ends at
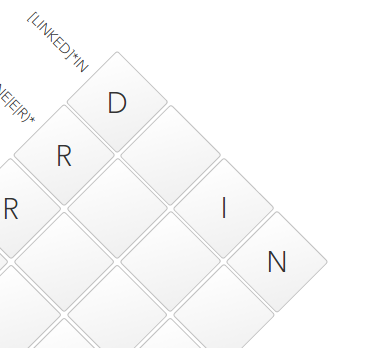
At the same time, we note the fact that
We draw attention to the fact that the line should end on
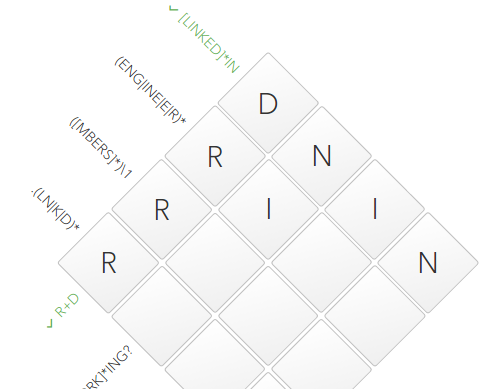
Send more complicated examples. In this case, we have a group
The symbol
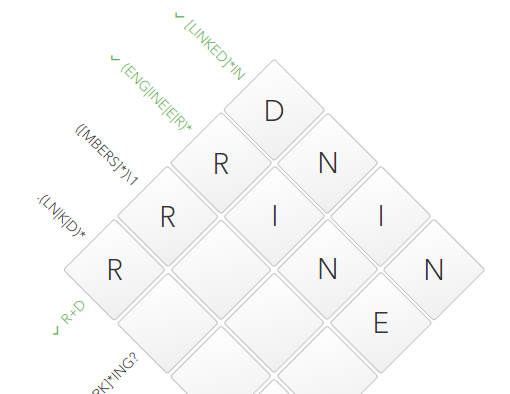
More than half of the puzzle has already been assembled.
The first trick came into play. We look at
It follows

The dot metacharacter at the beginning of the regular expression tells us that any character can be located at this position (there are nuances regarding the line break character, but they do not apply to this crossword). Already driven
Next we see a group
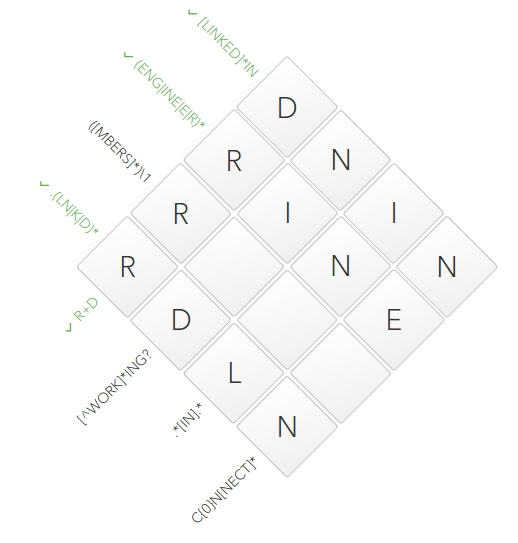
The dictionary
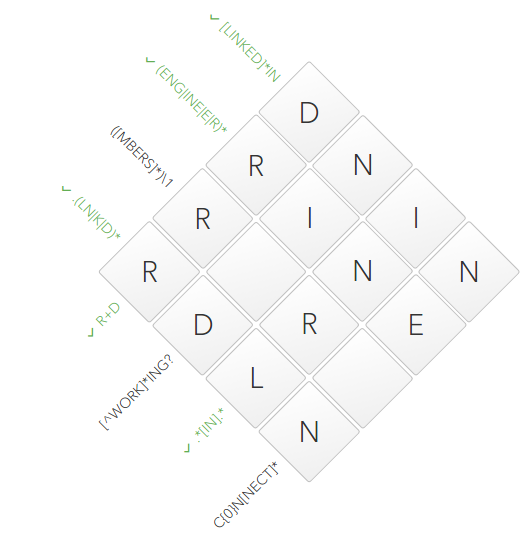
On this regular expression, I sat in a puddle. I did not have enough knowledge. Actually this is what prompted me to write this very note.
What we have? We have a group containing a dictionary
The symbol
From which it follows that since we know the first character, the third one has become known: The
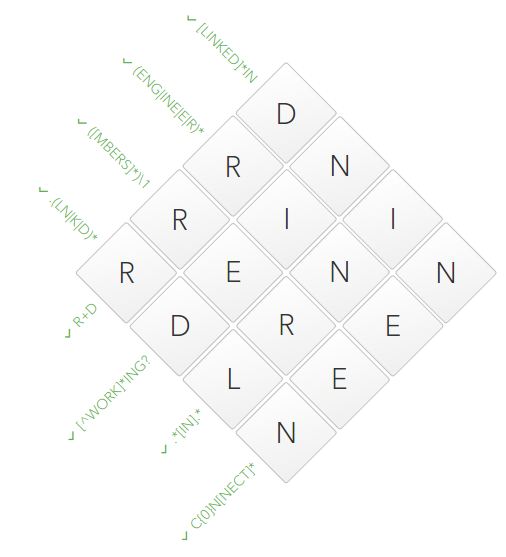
last touch remains. Of
Linkedin congratulates our:
In this article, I would like to parse this crossword on points. The article may be useful to those who are already familiar and use regular expressions in business, but who have problems with non-trivial tasks. In any case, I recommend trying it yourself; it is not complicated. Well, if things like negative retrospective checks are part of your working arsenal, then you will not find anything new in the article.
What is this?
The usual crossword puzzle is rectangular in shape. The descriptions on the sides are regular expressions and should fully describe the contents of these cells. For clarity, the authors omitted the symbols
^and $. Those. R+Dyou need to understand how ^R+D$. The symbol ^denotes the beginning of a row, and $its end, thus, the expression describes the contents of all 4 cells (row or column) as a whole.Where do we start?
As with regular crosswords, the easiest way to start is with the simplest expression. In this case, this
R+D. Obviously. that the fourth cell will be occupied by a symbol D, and the first three will be nothing but three Rin a row. +after Rcan be described as follows: Rshould meet 1 or more times. The line was marked in green, therefore, ours
RRRDsatisfied the regular expression ^R+D$. Move on.[LINKED] * IN
These things regular expressions can be briefly described as follows: The line ends at
IN, and before that it contains an arbitrary jumble of the following dictionary: L, I, N, K, E, D. We drive in the obvious IN: At the same time, we note the fact that
Dfrom R+Dfits perfectly into this dictionary. One cell was left empty, we will return to it later.[^ WORK] * ING?
We draw attention to the fact that the line should end on
INGor IN. Those. in fact, we have two options. ?before Gtells us about what Gmay or may not be. We look into the dictionary from [LINKED]*IN, and do not find a symbol in it G. All that remains is the option with IN:(ENG | INE | E | R) *
Send more complicated examples. In this case, we have a group
(ENG|INE|E|R)that can meet as many times as you like (see symbol *). Group offers us a number of options: ENG, INE, Eand R. Those. the final line might be EEEE, ERER, ENGE, RINE, etc. The symbol
Rfrom R+Dus is already entered, in the group it is also present. In the second cell, we already have a symbol entered I, and it is present at the beginning INE. Therefore, the line will take the form R+ INE= RINE: More than half of the puzzle has already been assembled.
C {0} N [NECT] *
The first trick came into play. We look at
{0}where instead there 0could be “1”, “1.3”, “5” and other options that govern the possible number of repetitions. But we have 0. That is Cthere is simply no symbol . Ignore him. It follows
N, therefore, we enter it:. (LN | K | D) *
The dot metacharacter at the beginning of the regular expression tells us that any character can be located at this position (there are nuances regarding the line break character, but they do not apply to this crossword). Already driven
Ris quite suitable. Next we see a group
(LN|K|D)that can be repeated as many times as necessary. The remarkable thing in it is that only LNfrom it comes to our 4th cell. And this in turn allows us to safely enter L:[^ WORK] * ING?
The dictionary
[^WORK]begins with a symbol ^, i.e. it contains a list of characters that should NOT occur in this position. (LN|K|D)contains two single-letter variants, this Kand D. KWe exclude the symbol since he is in our dictionary of denial. It remains only D:The finish line ([MBERS] *) \ 1
On this regular expression, I sat in a puddle. I did not have enough knowledge. Actually this is what prompted me to write this very note.
What we have? We have a group containing a dictionary
[MBERS]that can be repeated as many times as you like. In the first cell, we already have a symbol Rthat is in the dictionary. The symbol
\1tells us that the first group in regular expression should be duplicated at this position without changes. There is \1nothing between the group , it turns out that our 4 cells must contain all the same two-letter group twice in a row. For example: RRRR, SRSRor RSRS. From which it follows that since we know the first character, the third one has become known: The
last touch remains. Of
C{0}N[NECT]*we know that the 4th cell should fit into the dictionaries [NECT]and [MBERS]. The only intersection is the symbol E. 4th cell found. Therefore, the second one, i.e. crossword puzzle solved: Linkedin congratulates our:
Congratulations! Only 12% of people who attempt this puzzle solve it. I believe that 12% are taken from the ceiling.