Cucumber in the cloud: using BDD scripts for load testing a product
Another transcript of the report with Pixonic DevGAMM Talks . Anton Kosyakin is a Technical Product Manager and is working on the ALICE Platform (such a Jira for hotels). He talked about how they integrated the existing tools in the project for testing, why load tests are needed, what tools the community offers and how to run these tools in the cloud. Below is the presentation and text of the report.
We are making a product called ALICE Platform and I’ll tell you how to solve the problem of load testing.

ALICE is Jira for hotels. We make a platform to help them deal with their insides. The concierge, the front desk operator, the cleaning staff — they also need tickets. For example: the guest calls> says that you need to get out of the room> the employee creates a ticket> the guys who are removed, know who the task is for> perform> change the status.
We have b2b, so the numbers may not be impressive - only 1,000 hotels, 5,000 DAU. This is not much for games, but for us it is very cool, because there are as many as 8 prod-servers and they hardly cope with these 5 thousand active users. Since there are a few other things under the hood - a bunch of databases, transactions, etc.

Most importantly: over the last year we have grown 2 times, now we have an engineering team in the region of 50 people and we plan to double the user base in 2019. And this is the main challenge that stands before us.
An example from life. On Friday evening, after working for the 60-hour work week, at 23:00 I finished the last phoned, quickly completed the presentation, jumped onto the train, and came here. And about five minutes ago I redid my presentation a little. So now everything works for us, because we are a startup and this is awesome. While I was driving, a part of the technical team (we call it fire at production) tried to make sure that the system did not lay down and, at the same time, users did not notice. They all turned out and we are saved.
As you can see, so far we have not slept well at night. We know for sure that our infrastructure will fall. We face it and understand it. One question: when? This is how we realized that Load testing is the key to salvation. This is what we need to attend to.

What goals do we set for ourselves. First, we must right now understand exactly the capacity and performance of our system, how well it works for current users. And this should happen before the user breaks the contract with us (and this can be a client for 150 hotels and a lot of money) due to the fact that something is not working or is very slow. In addition, the sales department has a plan: a two-fold increase over the next year. And it also happened that we bought our main competitor and migrated their users to us.
And we need to know that we will endure all this. Know beforehand, before these users come and everything will fall.
And we make releases. Every week. On Monday. Of course, not all releases extend the functionality, somewhere maintenance, somewhere error correction, but we must understand that users will not notice this and their experience will not get worse.
But we, as good developers, are lazy people and do not like to work. Therefore, they asked the community and Google what services / solutions for Load-testing are. They turned a lot. There are the simplest things, like Apache Bench, which is just a hundred streams kicking some site on urla. There is an evil and strange version of Bees with Machine Guns, where everything is the same, but it starts instances that fly and put your applications. There is a JMeter, there you can write some scripts, run in the cloud.

It seems to be all right, but, on reflection, we realized that we really have to work and first solve several problems.

First, you need to write real scenarios that will simulate the full load. In some systems, it is enough to generate random API calls with random data. In our case, these are long user scenarios: received a call, opened the screen, drove all the data (who called what he wanted), saved it. Then it appears in the mobile application of another person who will fulfill the request. Not the most trivial task.
And, remember, releases every week. The functionality is updated, the scripts must be really relevant. First you need to write them, and then also support them.
But it was not the biggest problem. Take, for example, flood.io. A cool tool, you can run Selenium in it - this is when Chrome starts up, you can control it, and it runs some scripts. You can run JMeter scripts in it. But if we want to run Selenium inside the JMeter scripts, suddenly everything falls apart, because the guys who put it together made a number of architectural decisions. Or, for example, some services can run JUnit - it is simple and straightforward, but one of these services wrote its own JUnit and it just ignores some things.

There is an acute issue of load generation, because each tool asks to generate it in its own way. And even when you managed to ensure that the scenarios were adequate, the question arises: how to run 2-4 times more? It seems to be: run and everything is fine. But no. There are all sorts of IDs in these requests - we create something, we get a new ID, change it by the old ID and a test that loads the entity by ID, changes its field to another one. And 10 tests that load the same essence 10 times are not very interesting. Because 10 times you need to load different entities and correctly scale this load.
OK, we want to solve the problem of load testing in order to understand exactly how many users the application will endure, and that our plans relate to the plans of the sales department. We analyzed the solutions that are on the market, and then we made an inventory of our pasta and sticks.
Since we make releases every week, of course, we have automated some tests - integration and something else. For this we use cucumber. This is a BDD framework where you can engage in behavior-driven development. Those. we set some scenarios that consist of steps.

Our infrastructure made it possible to run integration and functional tests in two modes: just kick backend, pull API or really run Chrome through Selenium and manage it.
We love NewRelic. He can simply monitor the server, the main indicators. Embeds into the JVM and intercepts all controller calls and the Endpoint API. Even they have a solution for the browser, and since we have most of the functionality right there, it also does something in the browser and gives some metrics.

Accordingly, you need to put it all together. We have already automated the main scripts. Our scripts (because like this BDD) imitate real users and the load is similar to real production. At the same time we can scale it. Since this is part of the release process, it is always kept up to date.

Now take any tool that is now on the market. They operate on the same primitives: http, API calls on http, JSON, JUnit, that's all. But as soon as we try to shove our tests on Cucumber, they do the same thing, operate on the same things, but nothing works. We began to think how to handle this task.
A small digression, because BDD is not a very popular term in game development, this is more for enterprise solutions.

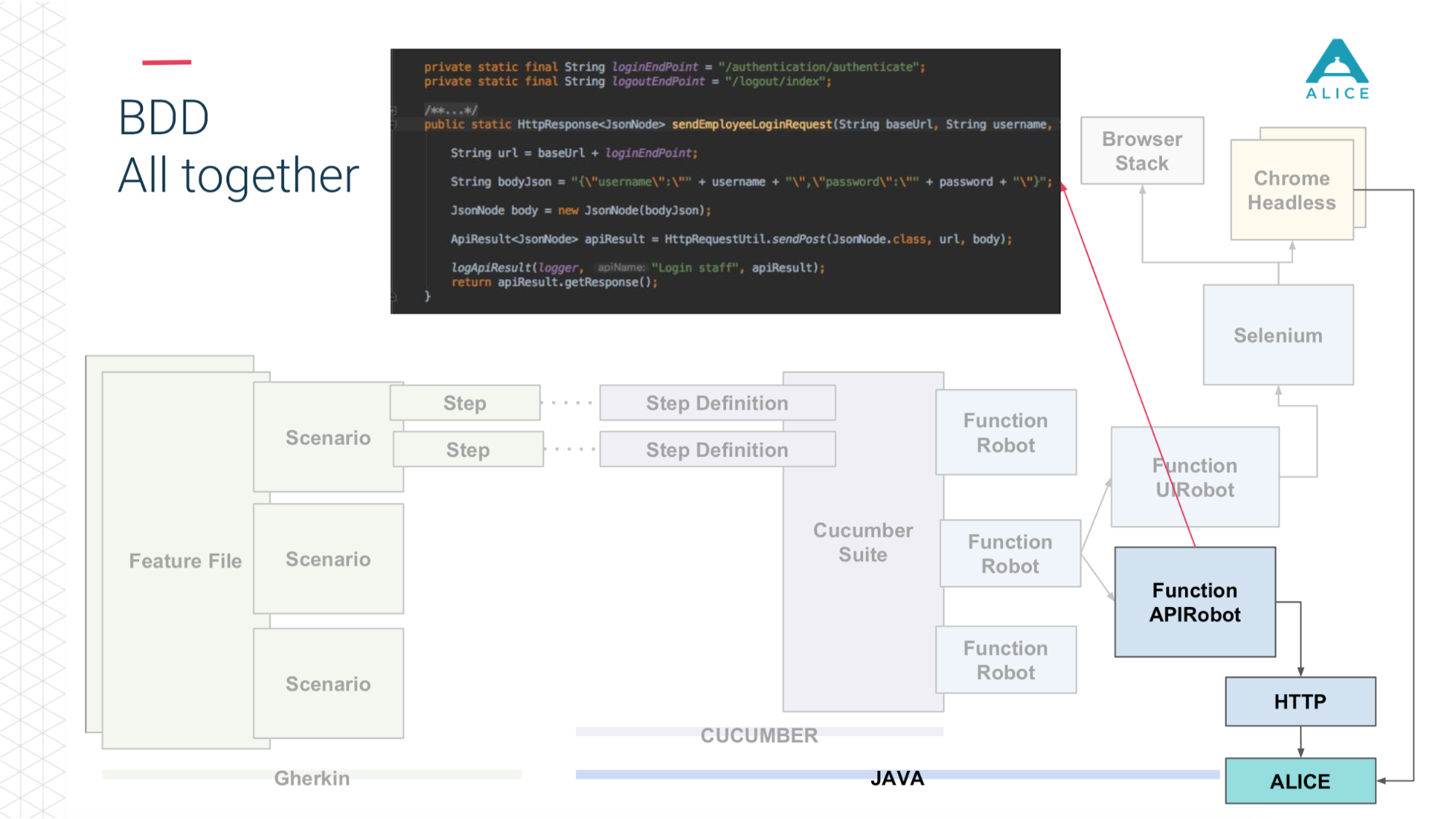
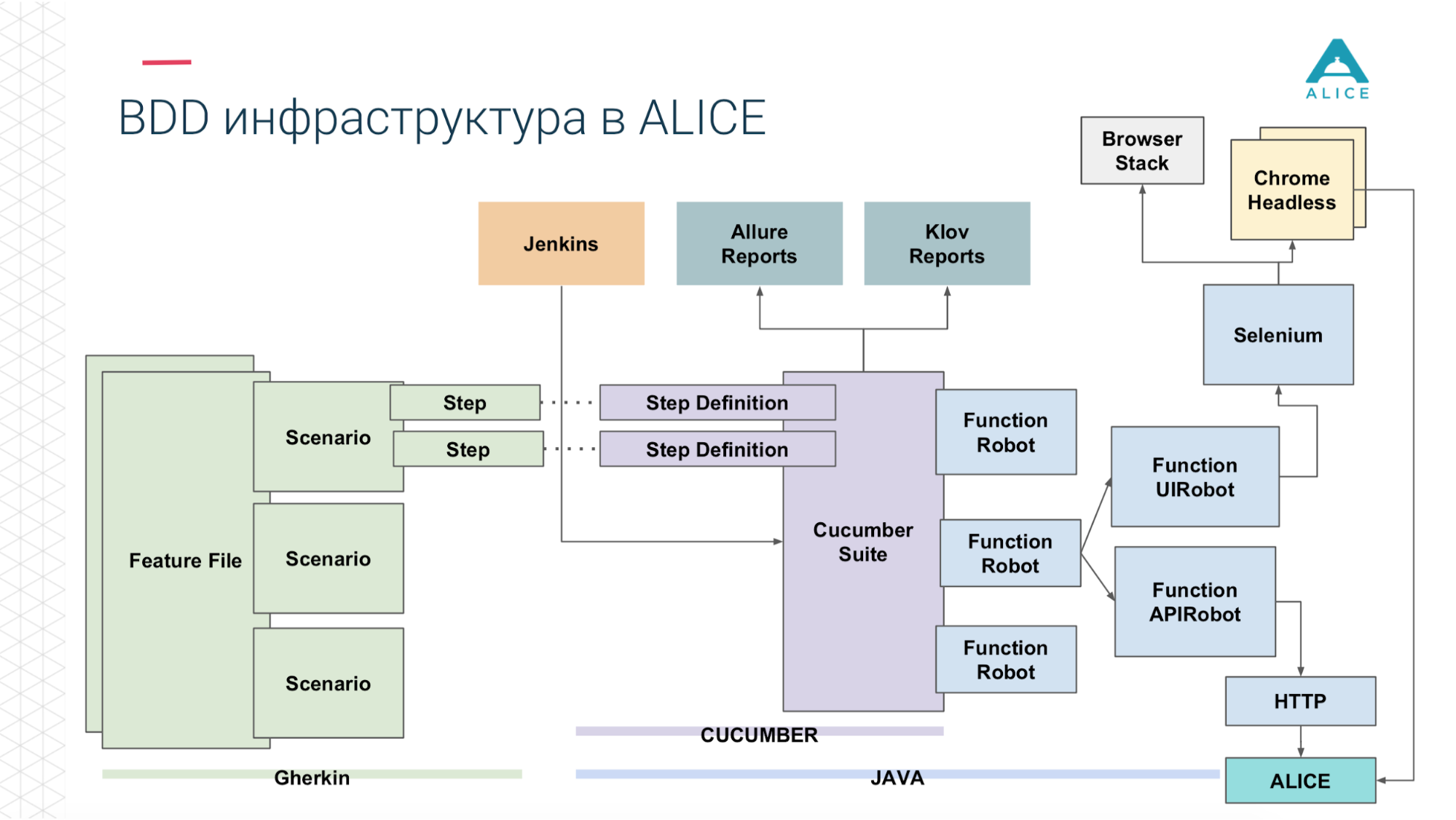
All scripts really describe some kind of behavior. The script description format is very simple: Given, When, Then - in terms of BDD is called Gherkin. Cucumber for us with annotations and attributes maps this to Java code. He is committed to seeing the script: we must give the man an apple, let's find a method in which it is implemented.
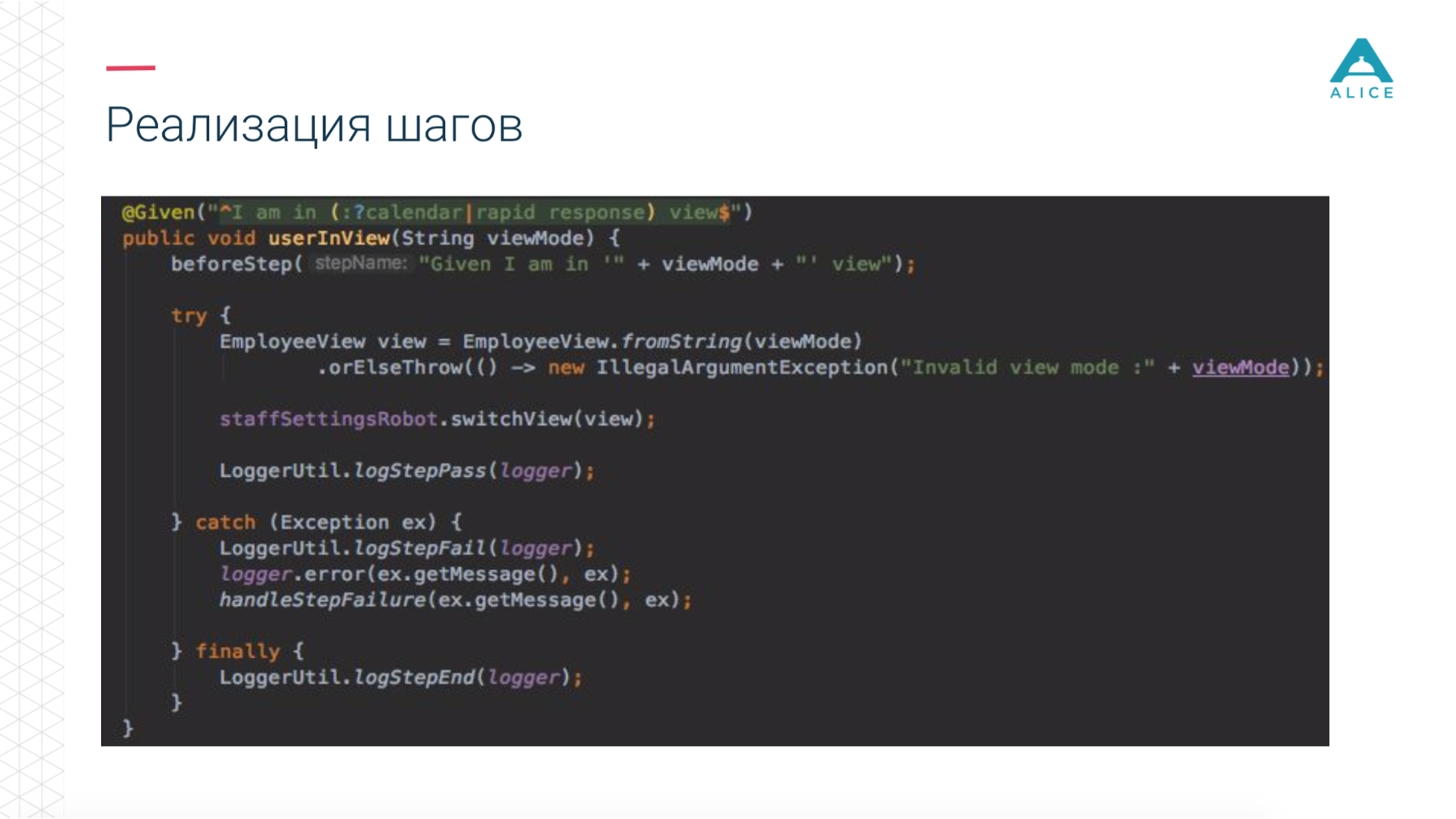
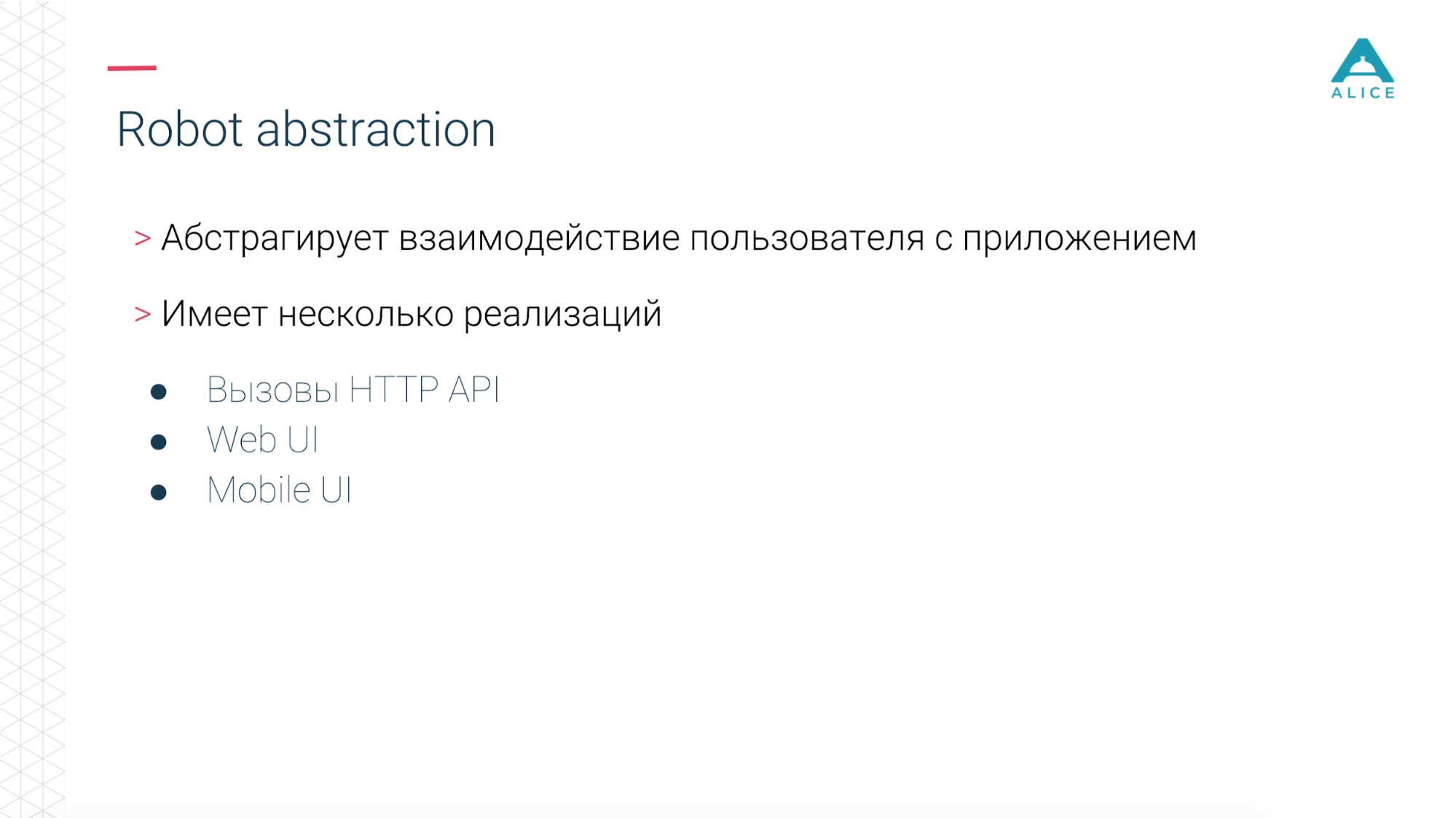
Then we introduced such a thing as Functional Robot. This is a certain client for the application, it has methods to log in the user, log out, create a ticket, see the list of tickets, etc. And it can work in three modes: with a mobile application, a web application, and just make API calls.
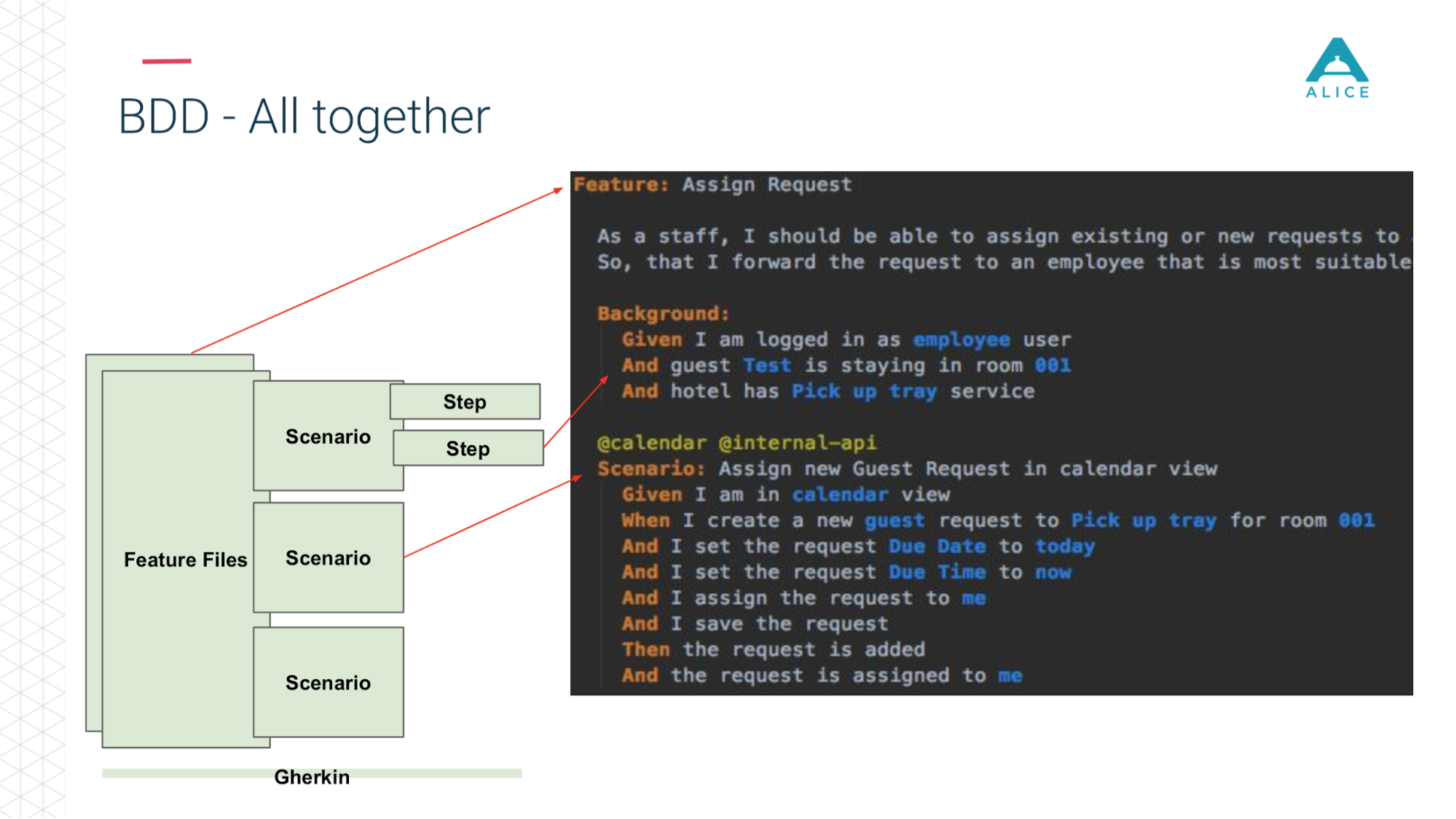
Now in a nutshell the same thing on the slides. Feature Files are divided into scripts, there are steps and all this is written in English.
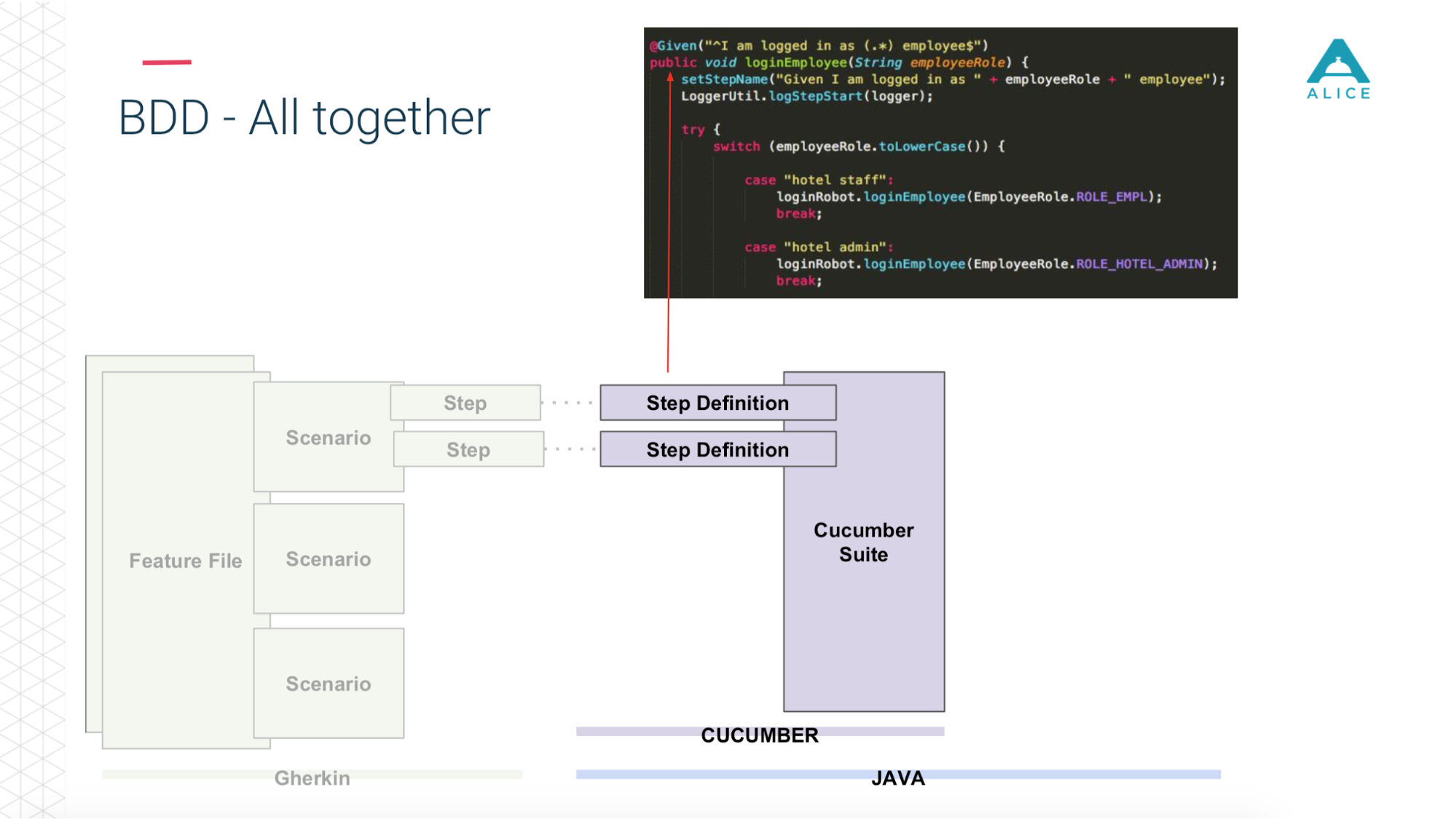
Then he enters the role of Cucumber, a Java code, he maps these scripts to code that is actually being executed.
This code uses our application.

And depending on what we have chosen: either through Selenium Chrome goes to the ALICE application.

Or the same thing via the http API.
And then (thanks to the guys from Yandex for Allure Reports) all this is beautifully shown to us - how long it took, what tests zafeleli, at what step, and even apply a screenshot if something went wrong.
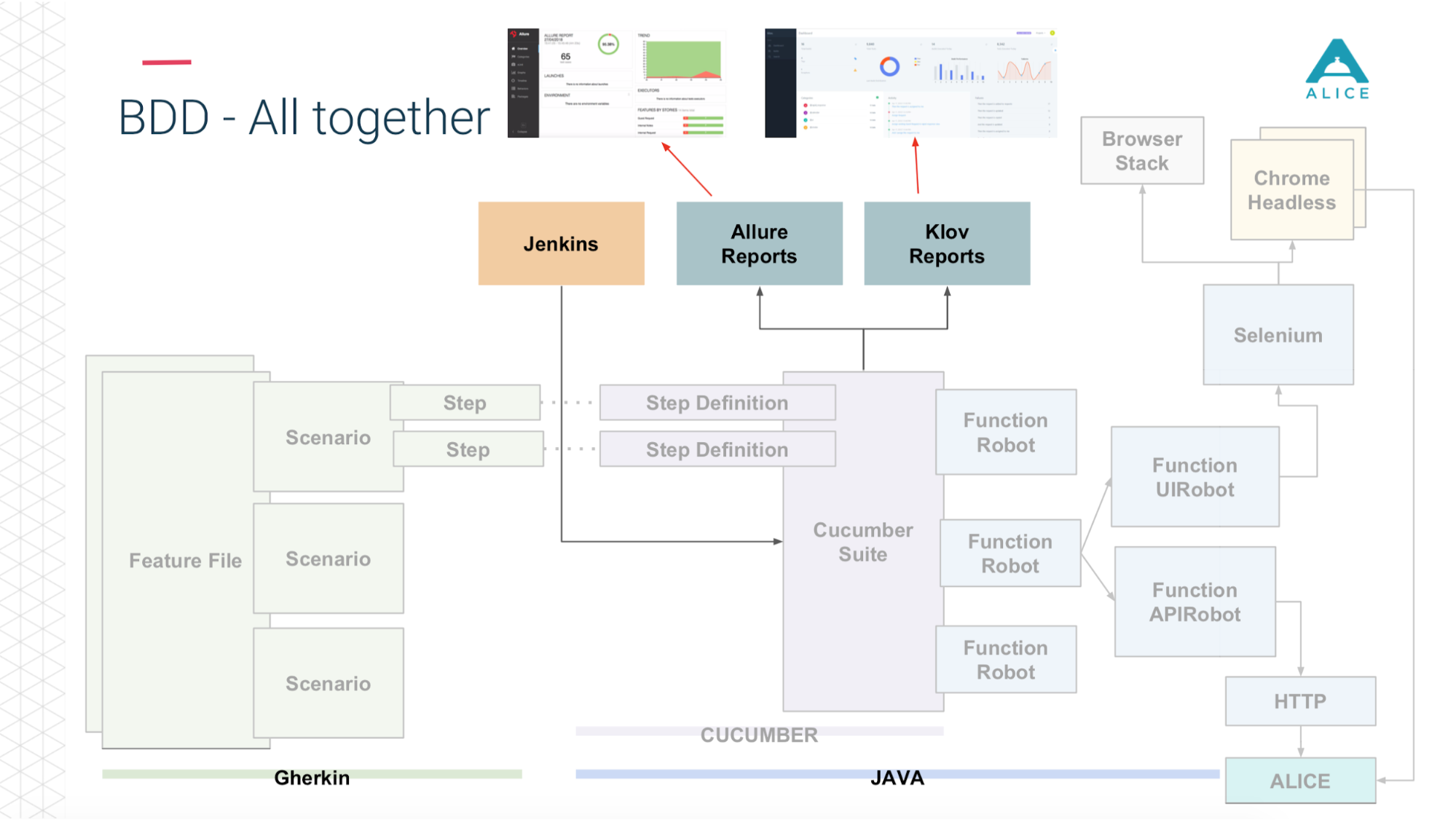
In short, what we already had.
How to build load tests from this? We had Jenkins, who ran the Cucumber Suite. These are our tests and they went to ALICE. What was the main problem? Jenkins runs tests locally, it cannot scale forever. Yes, we are hosted in Amazon, in the cloud, we can ask for an extra-large machine. Anyway, at some point we will rest, at least in the network. It is necessary to somehow load this load. Thank you Amazon, he thought for us. We can pack our Cucumber Suite in a Docker container and, using AWS service (called Fargate), say “please launch us.” The problem is solved, we can run our tests already in the cloud.

Then, since we're in the cloud, run 5-10-20 Cucumber Suite. But there is a nuance: each launch of all our functional tests generates a report. Once we launched 400 tests and generated 400 reports.
Thanks once again to the guys from Yandex for open source, we read the documentation, the source code and realized that there are ways to aggregate all 400 reports into one. Slightly corrected the data, wrote some of their extensions and everything turned out.
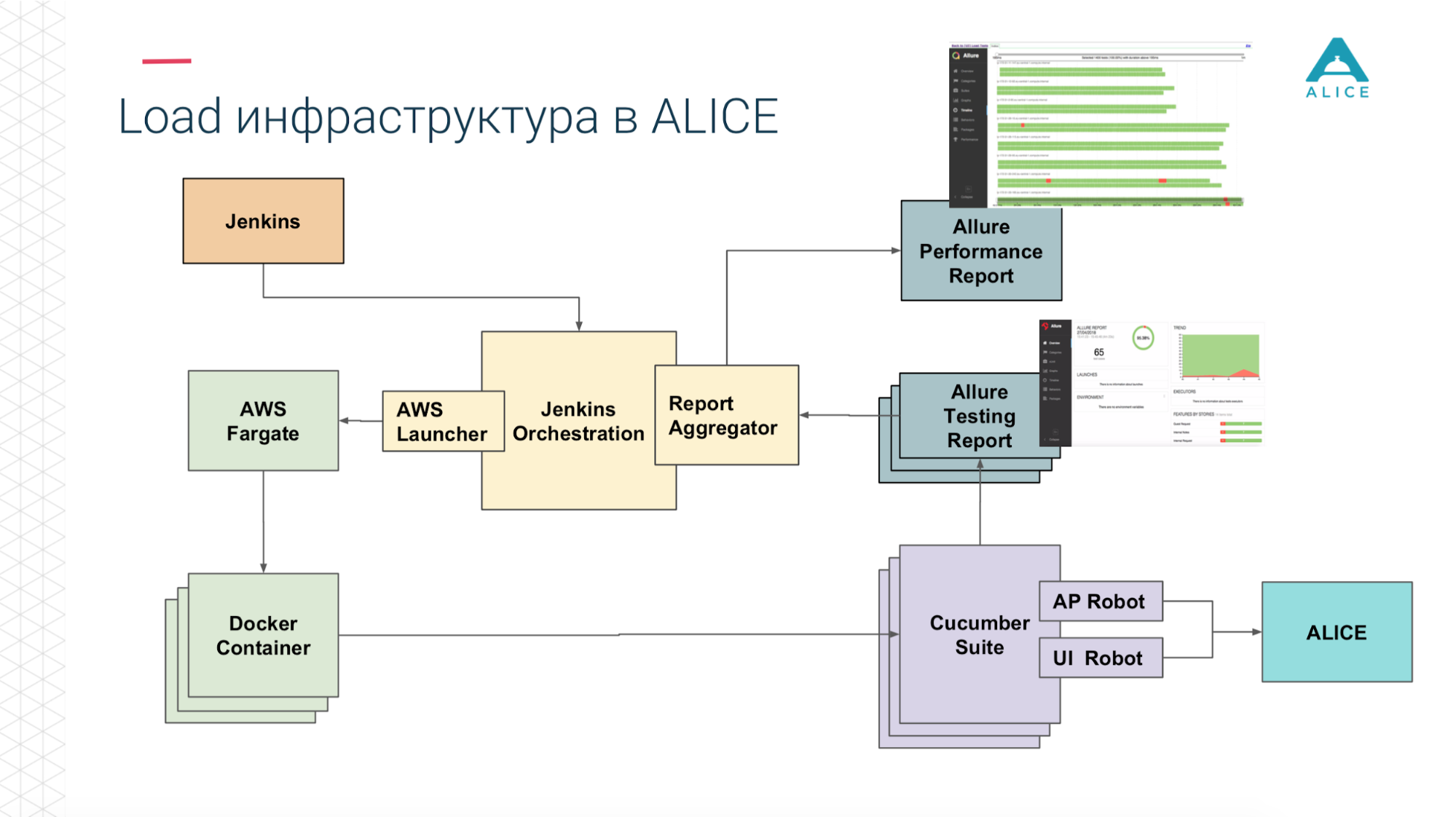
Now from Jenkins, we say, "Run 200 instances for us." Our certain orchestration script goes to Amazon, says “launch 400 containers”. Each of them contains our integration tests, they generate a report, the report is collected through the Aggregator in one piece, put in Jenkins, attached to the job, it works super.
But.
I’m sure many of you got strange things from testers, like “I played a game, jumped 10 times, fiercely clicked on the shooting and accidentally touched the shutdown button - the character started to blink, hang in the air, and then the computer turned off, figure it out. ” With a person, you can still agree and say, you know, it is impossible to reproduce. But we have soulless machines, they do everything very quickly and somewhere the data is not loaded, somewhere it is not very quickly rendered, they are trying to press a button, and there are no buttons yet or it uses some data that has not yet been downloaded from the server . Everything collapses and the test is filed. Although (I want to focus on this) we have Java code that launches Chrome, which connects to another Java and does something and still works lightning fast.
Well, the obvious problem arises from this: we have 5 thousand users, and we launched only 100 instances of our functional tests and created the same load. This is not exactly what we wanted, because we plan that next month we will have 6 thousand users. Such a load is hard to understand, to understand how many threads to run.
OK, let's humanize our system. This is what the user interface looks like:

Someone is calling, the concierge wants to press the “create a new ticket” button, a window pops up and he has to fill in all the fields.
But this does not happen instantly. A real person will reach it with a mouse, start typing, select something, click Save. So let's slow down our tests.

We called it Human mode. You just need to measure how long the step lasts and a little bit “sleep” if it was too fast. At the same time, we can measure how much this step has taken in principle - if 5 minutes, then, probably, the user experience is broken here.
Since we had quite a few tests, we did not rewrite each one for this piece. We took AspectJ, pulled on our code, added another 5 lines of code, it works great.
Short demo.


This is the start timeline. Green tests - well, somewhere - bad. Allure will show us the details, where zafeillos.
But the timeline, showing that we had a lot of instances. They performed the test, somewhere something fell.
The system really works - last week we did the first tests on production.
Now about the next steps, as we believe, this can be improved.

Most importantly, we want people to have a great user experience. The idea is that we can generate a large load on our application and it’s as if everything is simple - they simply measured the performance of each request to the server, whether it continues to respond just as quickly or if there was a drop in performance (the server became slower to process incoming requests). But no. In reality, the client / application can throw several requests to the server at once, in a heap. And wait until they are all processed. And if one of the requests, the longest, how it worked for 5 seconds, continues to work for 5 seconds, then we do not care how all the others work - just as quickly or slowed down to 4 seconds. After all, we will still wait for the longest, five seconds. Or you created a ticket, everything worked in one millisecond, but the ticket due to internal index caches appeared in the system too late. The usual approach will not solve this problem, so we want to try to measure all the scenarios and see how much worse the scenario of creating a ticket has become.
Because we have all the scenarios repelled from the use cases, we can imitate by running one person at the reception and 10 cleaners. Then 20 or 30 cleaners. But the front of people is still one. Those. we can generate a real load based on behavior patterns, very close to a realistic load.
Also multi-regional testing. Our system is used all over the world (although everything is hosted in America) and therefore we can generate load from Russia and America to see which of them will begin to slow down faster.
- You have to write a large amount of logic and when something changes a little, you have a lot of things breaking down in functional tests. It turns out that it takes almost more time to support tests than to develop?
- Yes, but no. These are BDD, these are not quite functional tests, they are closer to integration tests. And whatever we change, the script still remains the same. I press the button, see the window, enter the room number from which the request was received, the name of the person and the date on which to book the table. If the layout has changed, the fields are reversed, if something happens differently in the backend - the test is preserved, because we are at a very high level, we press the buttons in the browser. Therefore, we are protected from a large number of changes. There are times when everything can break. Therefore, in the release procedure, those guys who write a new feature - they are responsible for seeing that something has broken and corrected. But so far there have been no such problems.
- And you did not have a situation that after one change all the tests turn red.
- Did not have. Theoretically, this can happen if the script does not have a button, but some other way to open a window for entering data about the ticket. But, as I showed earlier, all scenarios in our country consist of steps. Steps are a lot of things, and if we have 100 scenarios that click on the same button, the step is still one. And if everything went down because of this particular step, we correct it, rewrite it, and all the tests immediately turn green.
Although once, when we accidentally broke something, we had this. Only 40% of green remains, although it was 99% before. It was one small change. We adjusted one step (line of code) and everything turned green again.
- Although you do not have integration tests, they are not quite functional either. Anyway, this is a kind of graphical interface, where buttons are pressed, some kind of interaction occurs specifically with the outer shell. I understand that you have tests like this, you just run many threads at the same time. And what was not arranged for the requests that are generated by the standard tools: JMeter, Gatling, which do not interact with the outer shell, but simply pour requests to the server?
- Everything is very simple. What is the architecture of our application? We have a backend, we have a frontend. Frontend is a web. There is a mobile application. And when I create a ticket, my frontend is connected, for example, to event servers. I create a ticket on the backend and all the people who are sitting in the same hotel, watch the tickets in the same hotel, they will arrive from the event servers: the guys update, the data has changed there. And in order to put everything together, we have a single point - this is the client. It connects to a large number of various components and either we program with our hands, that we created a ticket in the backend and then we connect to the event server, register on it and expect some events from it. Or they simply launched a browser in which everything is already put together, this code has already been written and we are doing everything as we need.
- But these are different approaches? Or we work specifically with the server or with the window. You can simulate requests to multiple servers at once.
- I therefore said that we have functional robots that are called from tests. There are those that raise Chrome and perform high-level pressure. There are those who do not press the button, nothing happens, but at the time of the ticket creation, it sends a request to the server, and we can start something like this or that. We chose to launch via Chrome for one simple reason - we want to imitate real users, the way they really use. While the page was loaded for him, while everything was being rendered for him, while the Java scripts and so on were working. We want to be as close to the user as possible, and this is real web.
- But a lot of things will depend on the user's Internet, which environment. But specifically the work of the application will depend on you already and on your side. The question is, what are we testing: in principle, everything or some part separately?
- A good question, so I talked about multi-regional testing. We can try to generate traffic from Mexico, where it may not be very good with the Internet. We can generate traffic from America, which is very close to the Amazon region where everything is hosted. But if a person in the background opened YouTube or started mining bitcoins, then we cannot reproduce this. There will have to wait for a call from real customers and go to them, to understand what is happening. This is not a silver bullet, yes.
- You deploy tests. Do you have some sort of Selenium Grid rises or what? You also make them multi-regional.
- Just a lot of Cucumber'ov: everything compiles in JAR, JAR is packaged in the Docker image and Fargate'u say, run this image in the container. And flood.io ran a grid from Selenium and did not have access to it, so our tests did not work.
- How wide is your testing area? You mentioned that you have Chrome, that there is an application on your phone. And if I start Internet Explorer 4 (if I dig out somewhere), then it may fall? Or under some very specific version of Android or something else.
- Fortunately, this is an enterprise. And the enterprise has one very interesting thing, namely requirements. Plus, we naturally counted - our mobile phone is a hybrid application, it also goes to the backend, just web view. Therefore, if Android can launch the web view and it has normal functionality, there are no particular problems with this.
- I listened where you are testing, where do you load load? Right on the production?
- Open the slide.
There Environment and dropdown list. And we excluded production from there. There was an interesting story when it was not yet Load, but just was automation. There you entered a custom 4-letter url, on which to go, he pasted on aliceapp.com. Then we did load tests and removed it from there because we accidentally put preproduction. Not that he just went to 504, and generally did not get back, because MySQL replication collapsed and synchronization with ElasticSearch collapsed.
- If you do not produce (which is good), how do you later understand that production will also be exactly the same? You obviously do not lift exactly the same volume of instans.
- Our Load-environment is configured identically to production and we have a procedure, every day a dump from the production base is uploaded to the environment. Those. we imitate a copy.
- And you keep it all the time, do not raise at the time of the tests?
- No, we do not hold. We are a startup, on Friday everything turns off except production, on Monday it turns back on request.
- Did I understand correctly that your tests imitate user behavior and fill in the fields, i.e. directly in html click buttons or make requests by the API method?
- The browser opens and Selenium allows you to get direct access to the DOM-model of this browser: pull any events, you can say in the input field, this is where the key down event has passed, but click on it. And we operate with these terms.
- Who writes the tests? Developers, testers?
- At the moment there is a special team. At first there was nothing, we suffered. Then QC appeared, we began to suffer less, QC suffered. They made a list of Smoke tests and a check list. Then we came to them and said “give your check-list, we will automate it”. The next step is to force developers to write these tests when developing a new functionality, because the infrastructure is there, all the frameworks are there, they just need to implement pushing buttons and other such things.
We are making a product called ALICE Platform and I’ll tell you how to solve the problem of load testing.
ALICE is Jira for hotels. We make a platform to help them deal with their insides. The concierge, the front desk operator, the cleaning staff — they also need tickets. For example: the guest calls> says that you need to get out of the room> the employee creates a ticket> the guys who are removed, know who the task is for> perform> change the status.
We have b2b, so the numbers may not be impressive - only 1,000 hotels, 5,000 DAU. This is not much for games, but for us it is very cool, because there are as many as 8 prod-servers and they hardly cope with these 5 thousand active users. Since there are a few other things under the hood - a bunch of databases, transactions, etc.
Most importantly: over the last year we have grown 2 times, now we have an engineering team in the region of 50 people and we plan to double the user base in 2019. And this is the main challenge that stands before us.
An example from life. On Friday evening, after working for the 60-hour work week, at 23:00 I finished the last phoned, quickly completed the presentation, jumped onto the train, and came here. And about five minutes ago I redid my presentation a little. So now everything works for us, because we are a startup and this is awesome. While I was driving, a part of the technical team (we call it fire at production) tried to make sure that the system did not lay down and, at the same time, users did not notice. They all turned out and we are saved.
As you can see, so far we have not slept well at night. We know for sure that our infrastructure will fall. We face it and understand it. One question: when? This is how we realized that Load testing is the key to salvation. This is what we need to attend to.
What goals do we set for ourselves. First, we must right now understand exactly the capacity and performance of our system, how well it works for current users. And this should happen before the user breaks the contract with us (and this can be a client for 150 hotels and a lot of money) due to the fact that something is not working or is very slow. In addition, the sales department has a plan: a two-fold increase over the next year. And it also happened that we bought our main competitor and migrated their users to us.
And we need to know that we will endure all this. Know beforehand, before these users come and everything will fall.
And we make releases. Every week. On Monday. Of course, not all releases extend the functionality, somewhere maintenance, somewhere error correction, but we must understand that users will not notice this and their experience will not get worse.
But we, as good developers, are lazy people and do not like to work. Therefore, they asked the community and Google what services / solutions for Load-testing are. They turned a lot. There are the simplest things, like Apache Bench, which is just a hundred streams kicking some site on urla. There is an evil and strange version of Bees with Machine Guns, where everything is the same, but it starts instances that fly and put your applications. There is a JMeter, there you can write some scripts, run in the cloud.
It seems to be all right, but, on reflection, we realized that we really have to work and first solve several problems.
First, you need to write real scenarios that will simulate the full load. In some systems, it is enough to generate random API calls with random data. In our case, these are long user scenarios: received a call, opened the screen, drove all the data (who called what he wanted), saved it. Then it appears in the mobile application of another person who will fulfill the request. Not the most trivial task.
And, remember, releases every week. The functionality is updated, the scripts must be really relevant. First you need to write them, and then also support them.
But it was not the biggest problem. Take, for example, flood.io. A cool tool, you can run Selenium in it - this is when Chrome starts up, you can control it, and it runs some scripts. You can run JMeter scripts in it. But if we want to run Selenium inside the JMeter scripts, suddenly everything falls apart, because the guys who put it together made a number of architectural decisions. Or, for example, some services can run JUnit - it is simple and straightforward, but one of these services wrote its own JUnit and it just ignores some things.
There is an acute issue of load generation, because each tool asks to generate it in its own way. And even when you managed to ensure that the scenarios were adequate, the question arises: how to run 2-4 times more? It seems to be: run and everything is fine. But no. There are all sorts of IDs in these requests - we create something, we get a new ID, change it by the old ID and a test that loads the entity by ID, changes its field to another one. And 10 tests that load the same essence 10 times are not very interesting. Because 10 times you need to load different entities and correctly scale this load.
OK, we want to solve the problem of load testing in order to understand exactly how many users the application will endure, and that our plans relate to the plans of the sales department. We analyzed the solutions that are on the market, and then we made an inventory of our pasta and sticks.
Since we make releases every week, of course, we have automated some tests - integration and something else. For this we use cucumber. This is a BDD framework where you can engage in behavior-driven development. Those. we set some scenarios that consist of steps.
Our infrastructure made it possible to run integration and functional tests in two modes: just kick backend, pull API or really run Chrome through Selenium and manage it.
We love NewRelic. He can simply monitor the server, the main indicators. Embeds into the JVM and intercepts all controller calls and the Endpoint API. Even they have a solution for the browser, and since we have most of the functionality right there, it also does something in the browser and gives some metrics.
Accordingly, you need to put it all together. We have already automated the main scripts. Our scripts (because like this BDD) imitate real users and the load is similar to real production. At the same time we can scale it. Since this is part of the release process, it is always kept up to date.
Now take any tool that is now on the market. They operate on the same primitives: http, API calls on http, JSON, JUnit, that's all. But as soon as we try to shove our tests on Cucumber, they do the same thing, operate on the same things, but nothing works. We began to think how to handle this task.
A small digression, because BDD is not a very popular term in game development, this is more for enterprise solutions.
All scripts really describe some kind of behavior. The script description format is very simple: Given, When, Then - in terms of BDD is called Gherkin. Cucumber for us with annotations and attributes maps this to Java code. He is committed to seeing the script: we must give the man an apple, let's find a method in which it is implemented.
Then we introduced such a thing as Functional Robot. This is a certain client for the application, it has methods to log in the user, log out, create a ticket, see the list of tickets, etc. And it can work in three modes: with a mobile application, a web application, and just make API calls.
Now in a nutshell the same thing on the slides. Feature Files are divided into scripts, there are steps and all this is written in English.
Then he enters the role of Cucumber, a Java code, he maps these scripts to code that is actually being executed.
This code uses our application.
And depending on what we have chosen: either through Selenium Chrome goes to the ALICE application.
Or the same thing via the http API.
And then (thanks to the guys from Yandex for Allure Reports) all this is beautifully shown to us - how long it took, what tests zafeleli, at what step, and even apply a screenshot if something went wrong.
In short, what we already had.
How to build load tests from this? We had Jenkins, who ran the Cucumber Suite. These are our tests and they went to ALICE. What was the main problem? Jenkins runs tests locally, it cannot scale forever. Yes, we are hosted in Amazon, in the cloud, we can ask for an extra-large machine. Anyway, at some point we will rest, at least in the network. It is necessary to somehow load this load. Thank you Amazon, he thought for us. We can pack our Cucumber Suite in a Docker container and, using AWS service (called Fargate), say “please launch us.” The problem is solved, we can run our tests already in the cloud.
Then, since we're in the cloud, run 5-10-20 Cucumber Suite. But there is a nuance: each launch of all our functional tests generates a report. Once we launched 400 tests and generated 400 reports.
Thanks once again to the guys from Yandex for open source, we read the documentation, the source code and realized that there are ways to aggregate all 400 reports into one. Slightly corrected the data, wrote some of their extensions and everything turned out.
Now from Jenkins, we say, "Run 200 instances for us." Our certain orchestration script goes to Amazon, says “launch 400 containers”. Each of them contains our integration tests, they generate a report, the report is collected through the Aggregator in one piece, put in Jenkins, attached to the job, it works super.
But.
I’m sure many of you got strange things from testers, like “I played a game, jumped 10 times, fiercely clicked on the shooting and accidentally touched the shutdown button - the character started to blink, hang in the air, and then the computer turned off, figure it out. ” With a person, you can still agree and say, you know, it is impossible to reproduce. But we have soulless machines, they do everything very quickly and somewhere the data is not loaded, somewhere it is not very quickly rendered, they are trying to press a button, and there are no buttons yet or it uses some data that has not yet been downloaded from the server . Everything collapses and the test is filed. Although (I want to focus on this) we have Java code that launches Chrome, which connects to another Java and does something and still works lightning fast.
Well, the obvious problem arises from this: we have 5 thousand users, and we launched only 100 instances of our functional tests and created the same load. This is not exactly what we wanted, because we plan that next month we will have 6 thousand users. Such a load is hard to understand, to understand how many threads to run.
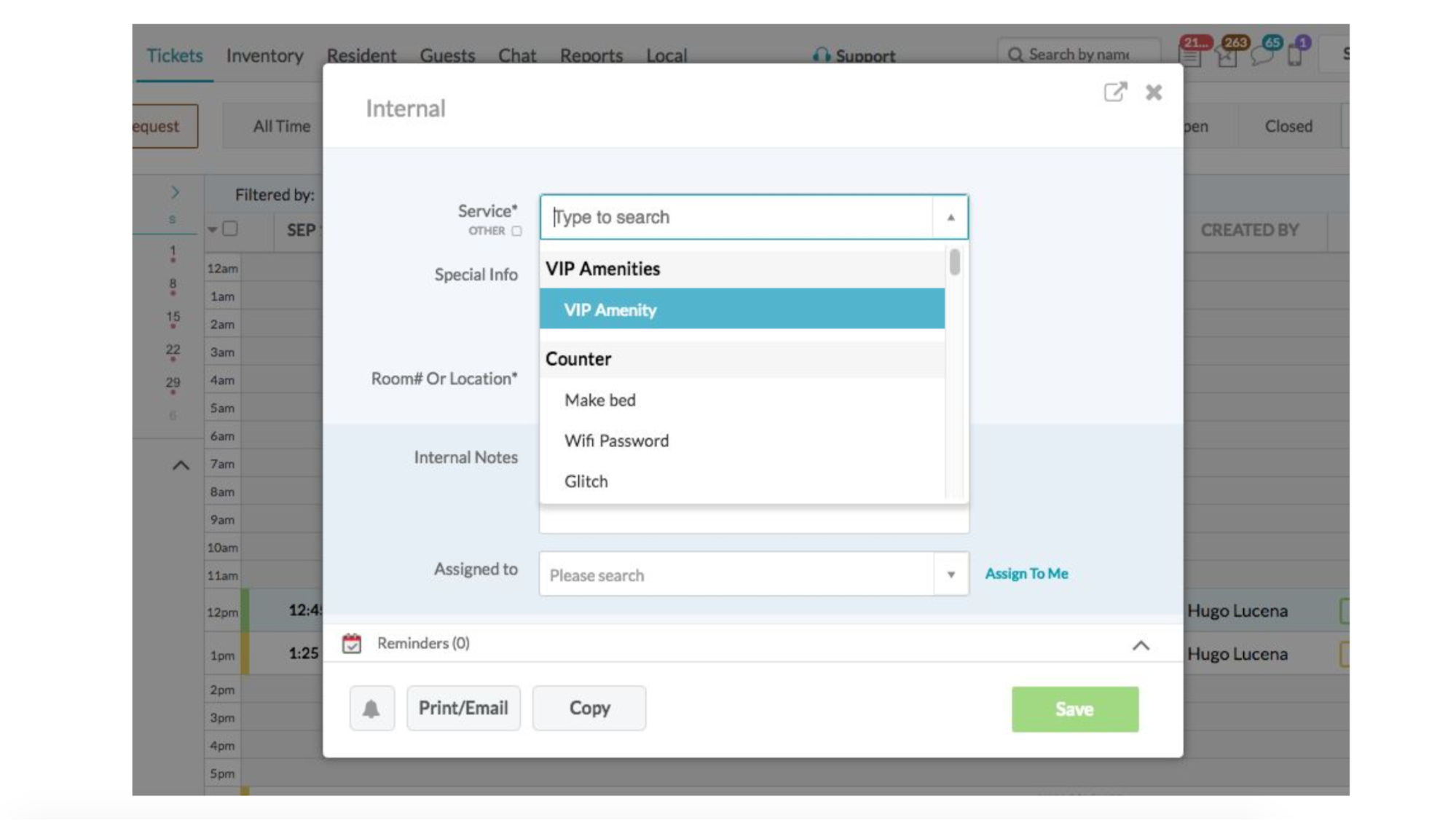
OK, let's humanize our system. This is what the user interface looks like:
Someone is calling, the concierge wants to press the “create a new ticket” button, a window pops up and he has to fill in all the fields.
But this does not happen instantly. A real person will reach it with a mouse, start typing, select something, click Save. So let's slow down our tests.
We called it Human mode. You just need to measure how long the step lasts and a little bit “sleep” if it was too fast. At the same time, we can measure how much this step has taken in principle - if 5 minutes, then, probably, the user experience is broken here.
Since we had quite a few tests, we did not rewrite each one for this piece. We took AspectJ, pulled on our code, added another 5 lines of code, it works great.
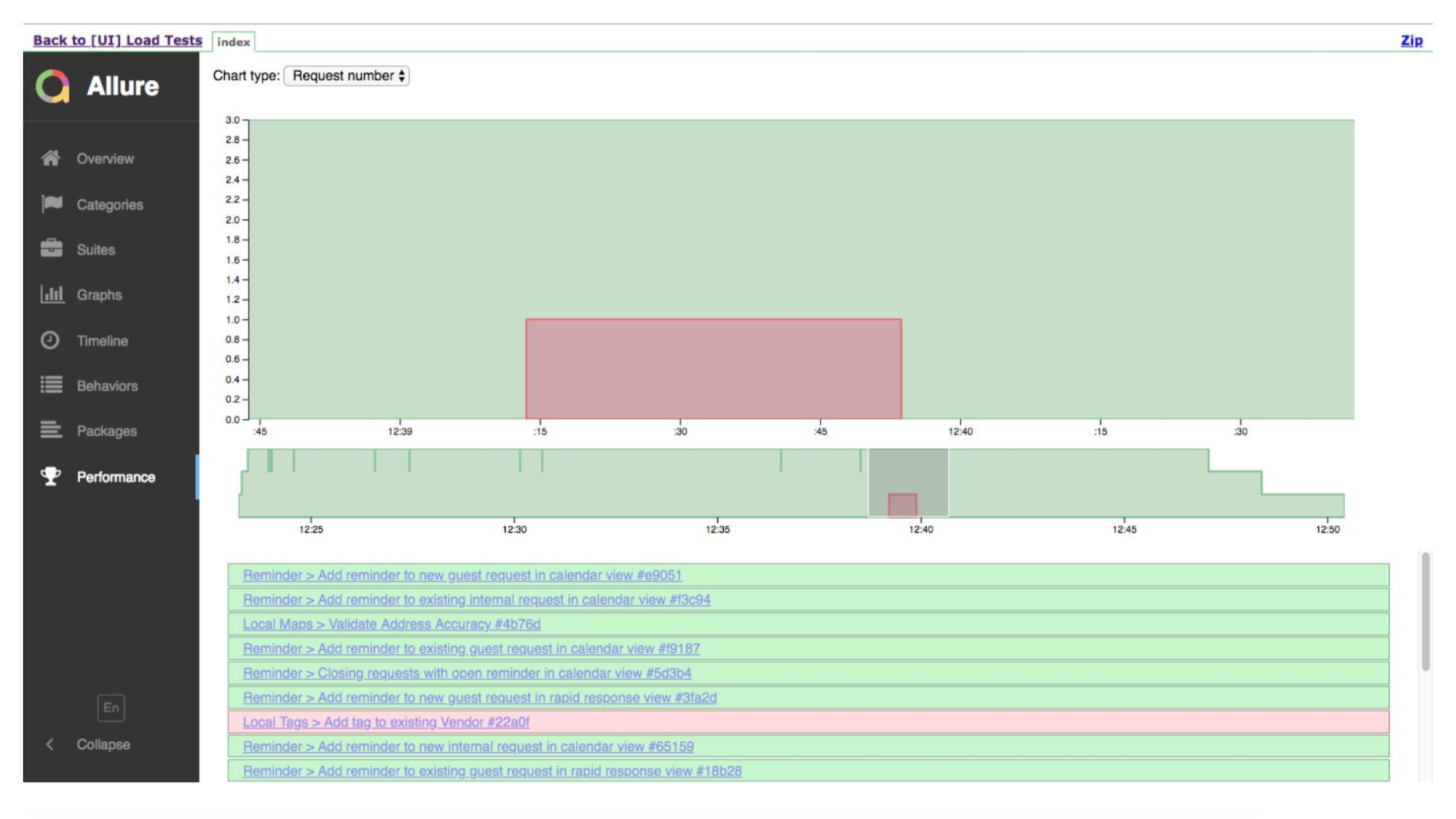
Short demo.
This is the start timeline. Green tests - well, somewhere - bad. Allure will show us the details, where zafeillos.
But the timeline, showing that we had a lot of instances. They performed the test, somewhere something fell.
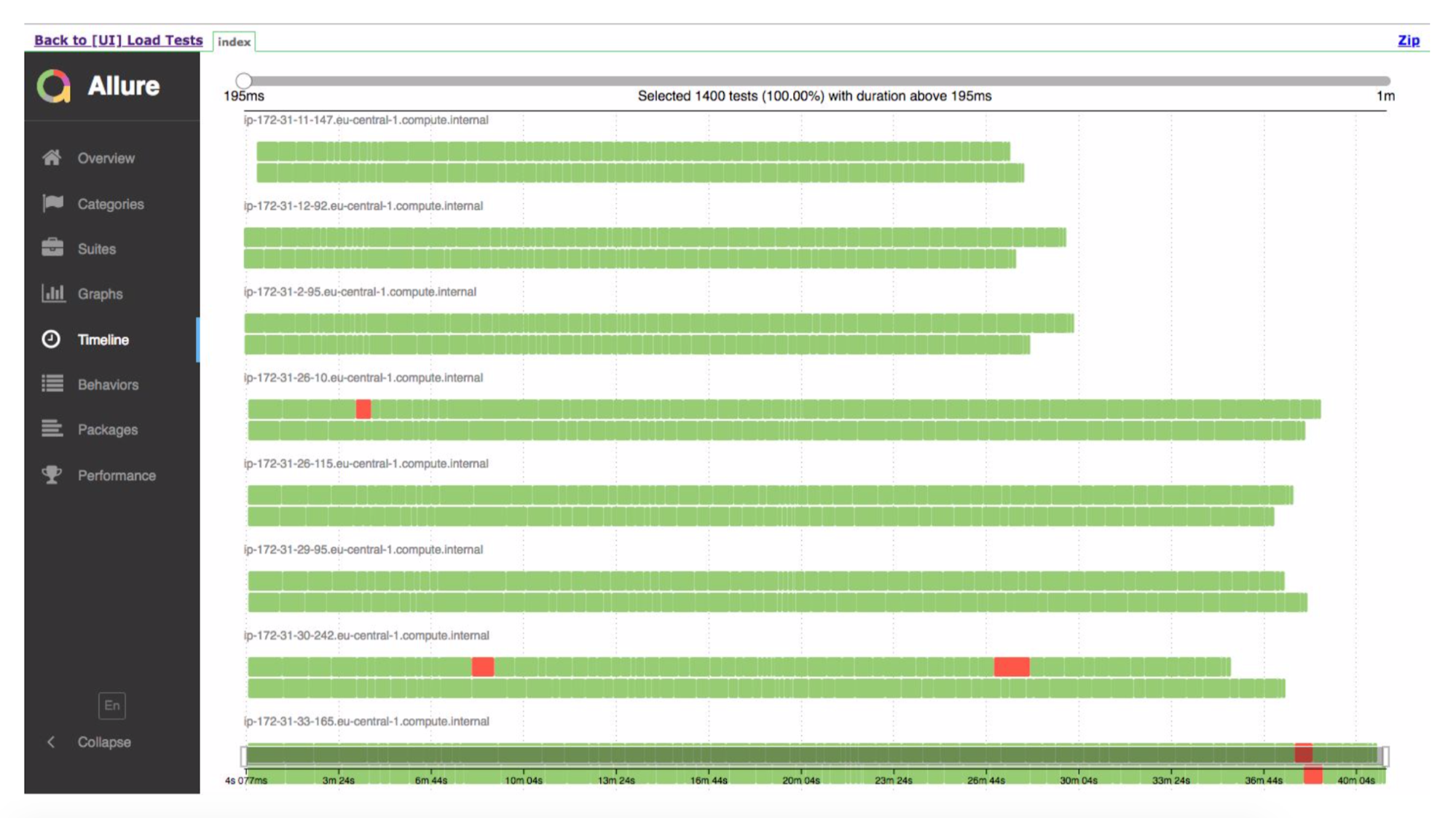
The system really works - last week we did the first tests on production.
Now about the next steps, as we believe, this can be improved.
Most importantly, we want people to have a great user experience. The idea is that we can generate a large load on our application and it’s as if everything is simple - they simply measured the performance of each request to the server, whether it continues to respond just as quickly or if there was a drop in performance (the server became slower to process incoming requests). But no. In reality, the client / application can throw several requests to the server at once, in a heap. And wait until they are all processed. And if one of the requests, the longest, how it worked for 5 seconds, continues to work for 5 seconds, then we do not care how all the others work - just as quickly or slowed down to 4 seconds. After all, we will still wait for the longest, five seconds. Or you created a ticket, everything worked in one millisecond, but the ticket due to internal index caches appeared in the system too late. The usual approach will not solve this problem, so we want to try to measure all the scenarios and see how much worse the scenario of creating a ticket has become.
Because we have all the scenarios repelled from the use cases, we can imitate by running one person at the reception and 10 cleaners. Then 20 or 30 cleaners. But the front of people is still one. Those. we can generate a real load based on behavior patterns, very close to a realistic load.
Also multi-regional testing. Our system is used all over the world (although everything is hosted in America) and therefore we can generate load from Russia and America to see which of them will begin to slow down faster.
Questions from the audience
- You have to write a large amount of logic and when something changes a little, you have a lot of things breaking down in functional tests. It turns out that it takes almost more time to support tests than to develop?
- Yes, but no. These are BDD, these are not quite functional tests, they are closer to integration tests. And whatever we change, the script still remains the same. I press the button, see the window, enter the room number from which the request was received, the name of the person and the date on which to book the table. If the layout has changed, the fields are reversed, if something happens differently in the backend - the test is preserved, because we are at a very high level, we press the buttons in the browser. Therefore, we are protected from a large number of changes. There are times when everything can break. Therefore, in the release procedure, those guys who write a new feature - they are responsible for seeing that something has broken and corrected. But so far there have been no such problems.
- And you did not have a situation that after one change all the tests turn red.
- Did not have. Theoretically, this can happen if the script does not have a button, but some other way to open a window for entering data about the ticket. But, as I showed earlier, all scenarios in our country consist of steps. Steps are a lot of things, and if we have 100 scenarios that click on the same button, the step is still one. And if everything went down because of this particular step, we correct it, rewrite it, and all the tests immediately turn green.
Although once, when we accidentally broke something, we had this. Only 40% of green remains, although it was 99% before. It was one small change. We adjusted one step (line of code) and everything turned green again.
- Although you do not have integration tests, they are not quite functional either. Anyway, this is a kind of graphical interface, where buttons are pressed, some kind of interaction occurs specifically with the outer shell. I understand that you have tests like this, you just run many threads at the same time. And what was not arranged for the requests that are generated by the standard tools: JMeter, Gatling, which do not interact with the outer shell, but simply pour requests to the server?
- Everything is very simple. What is the architecture of our application? We have a backend, we have a frontend. Frontend is a web. There is a mobile application. And when I create a ticket, my frontend is connected, for example, to event servers. I create a ticket on the backend and all the people who are sitting in the same hotel, watch the tickets in the same hotel, they will arrive from the event servers: the guys update, the data has changed there. And in order to put everything together, we have a single point - this is the client. It connects to a large number of various components and either we program with our hands, that we created a ticket in the backend and then we connect to the event server, register on it and expect some events from it. Or they simply launched a browser in which everything is already put together, this code has already been written and we are doing everything as we need.
- But these are different approaches? Or we work specifically with the server or with the window. You can simulate requests to multiple servers at once.
- I therefore said that we have functional robots that are called from tests. There are those that raise Chrome and perform high-level pressure. There are those who do not press the button, nothing happens, but at the time of the ticket creation, it sends a request to the server, and we can start something like this or that. We chose to launch via Chrome for one simple reason - we want to imitate real users, the way they really use. While the page was loaded for him, while everything was being rendered for him, while the Java scripts and so on were working. We want to be as close to the user as possible, and this is real web.
- But a lot of things will depend on the user's Internet, which environment. But specifically the work of the application will depend on you already and on your side. The question is, what are we testing: in principle, everything or some part separately?
- A good question, so I talked about multi-regional testing. We can try to generate traffic from Mexico, where it may not be very good with the Internet. We can generate traffic from America, which is very close to the Amazon region where everything is hosted. But if a person in the background opened YouTube or started mining bitcoins, then we cannot reproduce this. There will have to wait for a call from real customers and go to them, to understand what is happening. This is not a silver bullet, yes.
- You deploy tests. Do you have some sort of Selenium Grid rises or what? You also make them multi-regional.
- Just a lot of Cucumber'ov: everything compiles in JAR, JAR is packaged in the Docker image and Fargate'u say, run this image in the container. And flood.io ran a grid from Selenium and did not have access to it, so our tests did not work.
- How wide is your testing area? You mentioned that you have Chrome, that there is an application on your phone. And if I start Internet Explorer 4 (if I dig out somewhere), then it may fall? Or under some very specific version of Android or something else.
- Fortunately, this is an enterprise. And the enterprise has one very interesting thing, namely requirements. Plus, we naturally counted - our mobile phone is a hybrid application, it also goes to the backend, just web view. Therefore, if Android can launch the web view and it has normal functionality, there are no particular problems with this.
- I listened where you are testing, where do you load load? Right on the production?
- Open the slide.
There Environment and dropdown list. And we excluded production from there. There was an interesting story when it was not yet Load, but just was automation. There you entered a custom 4-letter url, on which to go, he pasted on aliceapp.com. Then we did load tests and removed it from there because we accidentally put preproduction. Not that he just went to 504, and generally did not get back, because MySQL replication collapsed and synchronization with ElasticSearch collapsed.
- If you do not produce (which is good), how do you later understand that production will also be exactly the same? You obviously do not lift exactly the same volume of instans.
- Our Load-environment is configured identically to production and we have a procedure, every day a dump from the production base is uploaded to the environment. Those. we imitate a copy.
- And you keep it all the time, do not raise at the time of the tests?
- No, we do not hold. We are a startup, on Friday everything turns off except production, on Monday it turns back on request.
- Did I understand correctly that your tests imitate user behavior and fill in the fields, i.e. directly in html click buttons or make requests by the API method?
- The browser opens and Selenium allows you to get direct access to the DOM-model of this browser: pull any events, you can say in the input field, this is where the key down event has passed, but click on it. And we operate with these terms.
- Who writes the tests? Developers, testers?
- At the moment there is a special team. At first there was nothing, we suffered. Then QC appeared, we began to suffer less, QC suffered. They made a list of Smoke tests and a check list. Then we came to them and said “give your check-list, we will automate it”. The next step is to force developers to write these tests when developing a new functionality, because the infrastructure is there, all the frameworks are there, they just need to implement pushing buttons and other such things.
More reports from Pixonic DevGAMM Talks
- Using Consul to scale stateful services (Ivan Bubnov, DevOps at BIT.GAMES);
- CICD: Seamless Deploy on Distributed Cluster Systems without Downtime (Egor Panov, Pixonic System Administrator);
- Practice using the model of actors in the back-end platform of the Quake Champions game (Roman Rogozin, backend developer of Saber Interactive);
- The architecture of the meta-server mobile online shooter Tacticool (Pavel Platto, Lead Software Engineer in PanzerDog);
- How ECS, C # Job System and SRP change the approach to architecture (Valentin Simonov, Field Engineer in Unity);
- KISS principle in development (Konstantin Gladyshev, Lead Game Programmer at 1C Game Studios);
- General game logic on the client and server (Anton Grigoriev, Deputy Technical Officer in Pixonic).