Entity Framework Code First in teamwork
From a translator: A great article on understanding the migration mechanism in Entity Framework 6 and ways to resolve migration conflicts when working in a team. Original article: Code First Migrations in Team Environments .
This article assumes that you are familiar with the Entity Framework and the basics of working with it. Otherwise, you first need to read Code First Migrations before continuing.
In teamwork, the problems are mainly related to the merging of migrations created by two developers in their local databases. While the steps to solve these problems are quite simple, they require a clear understanding of how migrations work. Please take the time to read the entire article carefully.
Before we delve into how to manage the merging of migrations created by several developers, here are some general principles.
The migration engine uses the __MigrationsHistory table to store a list of migrations that have been applied to the database. If your team has several developers generating migrations, then when trying to work with the same database (and, therefore, with the same __MigrationsHistory table ), the migration mechanism may be difficult.
Of course, if you have team members who do not create migrations, then there will be no problems with working with a central database for development.
The bottom line is that automatic migrations initially look good in team work, but in reality they just don't work. If you want to know the reason, continue to read the article, otherwise you can go to the next chapter.
Automatic migrations allow updating the database schema in accordance with the current model without the need to create files with code migration (code-based migration).
Automatic migrations will only work well in team work if you have ever used them and never created any code-based migrations. The problem is that automatic migrations are limited and cannot cope with a number of operations - renaming a property / column, transferring data from one table to another, etc. In order to process such scenarios, you will eventually create code-based migrations (and edit the generated code), which results in mixing the changes that are processed using automatic migrations. This makes it almost impossible to merge the changes between the two developers.
From a translator: 2 screencasts are posted in the original article, I recommend that you read
The key to successfully using migrations in a team is a basic understanding of how the migration mechanism tracks and uses model information to detect changes.
When you add the first migration to your project, you run something like Add-Migration First in the Package Manager Console. The steps that this command performs are shown below.
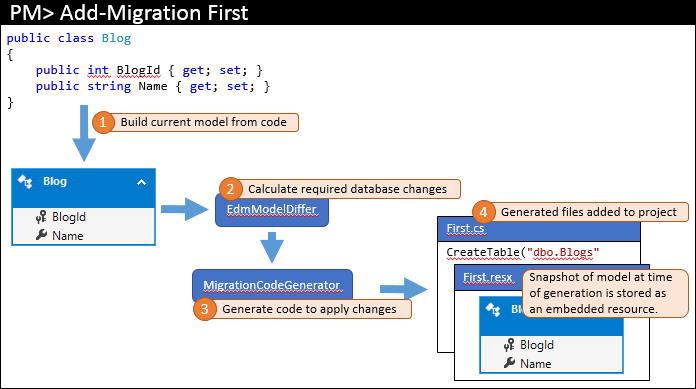
Based on the code, the current model (1) is calculated. Then, using model differ, the necessary database objects are calculated (2) - since this is the first migration, model differ uses an empty model for comparison. The necessary changes are transferred to the code generator to create the necessary migration code (3), which is then added to the Visual Studio solution (4).
In addition to the migration code, which is stored in the main file, the migration mechanism also creates additional code-behind files. These are metadata files that are used by the migration engine and you should not modify them. One of these files is a resource file (.resx), which contains a snapshot of the model at the time the migration was created. In the next section, you will see how it is used.
At this point, you can run Update-Database to apply the changes to the database, and then start implementing the rest of your application.
We’ll make some changes to the model - in our example, we will add the Url property to the Blog class . Then you need to run the Add-Migration AddUrl command to create the migration to apply the appropriate changes to the database. The steps that this command performs are shown below.
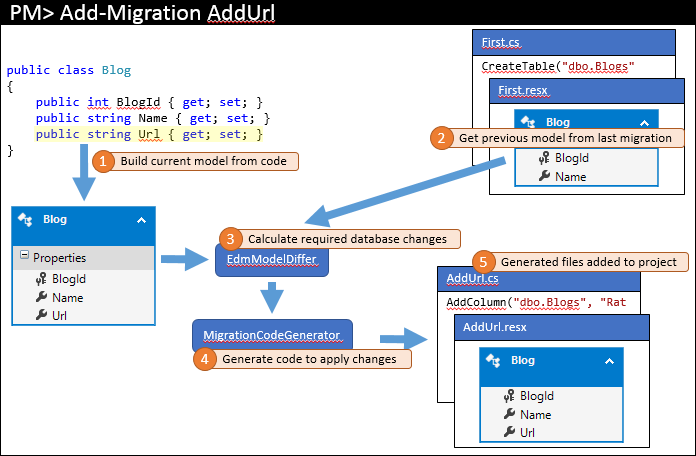
Just like last time, the current model is calculated from the code (1). However, this time there are existing migrations, and the previous model is extracted from the last migration (2). These two models are compared to find the necessary changes in the database (3), and then the process ends, as before.
The same process is used for all of the following migrations that are added to the project.
You may be wondering why EF uses model snapshots for comparison - why not just look at the database.
There are a number of reasons why EF preserves model states:
The process described in the previous section works great if you are the only developer working on the application. He also works well as a team if you are the only person who makes changes to the model. In this case, you can make changes to the model, generate migrations and send them to the version control system. Other developers may receive such changes and run Update-Database to update the schema.
Problems begin to arise when you have several developers who make changes to the EF model and submit them to the version control system. What EF lacks is a first-class way to combine local migrations with migrations of other developers sent to the version control system after the last synchronization.
First, let's look at a specific example of merging such a conflict. We will continue with the example that we examined earlier. As a starting point, let's assume that the changes from the previous section were verified by this developer. We will track two developers who make changes to the code.
We will track the EF model and migration through a series of changes. Both developers synchronize through the repository in the version control system, as shown in the following figure.
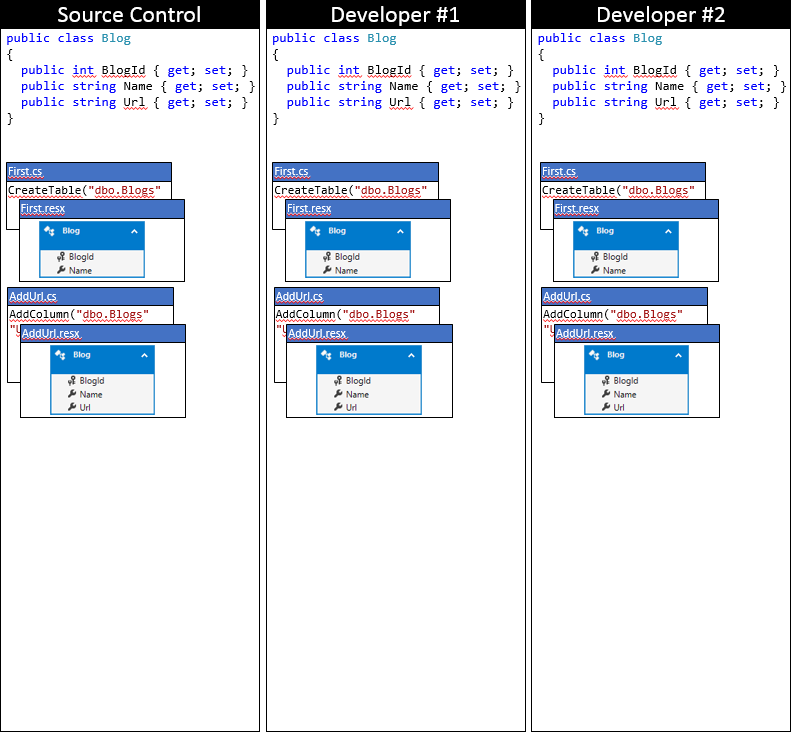
Developer # 1 and developer # 2 make some changes to the EF model in the local codebase. Developer # 1 adds Rating property to Blog class , creates AddRating migrationto apply changes to the database. Developer # 2 adds the Readers property to the Blog class , creates an AddReaders migration . Both developers run Update-Database to apply the changes to their local databases, and then continue to develop the application.
Note: Migrations start with a timestamp, so our figure shows that AddReaders migration from developer # 2 comes after AddRating migration from developer # 1. From the point of view of working in a team, it does not matter to us in what order these changes were created, we will consider the process of their integration in the next section.
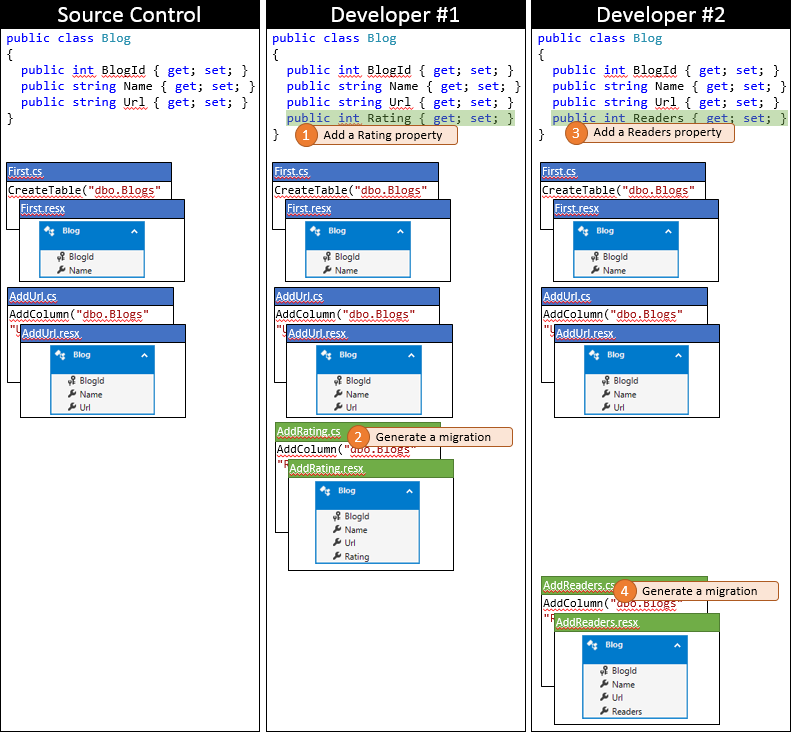
Today, developer # 1 was lucky as he was the first to post his changes to the version control system. Since no one else has submitted changes to the repository, he can simply post his changes without performing any merge.
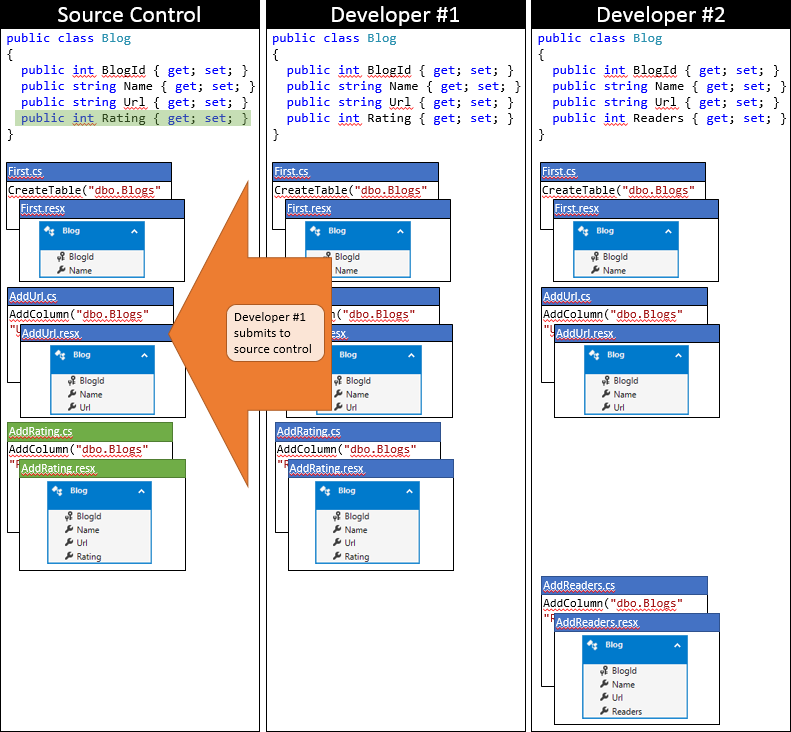
Now it's time for developer # 2 to submit the changes. He's not so lucky. Because someone posted the changes after the last synchronization, the developer must pick them up and merge. The version control system is likely to be able to automatically merge changes at the code level, as they are very simple. The status of the local developer code base # 2 after synchronization is depicted in the following figure.
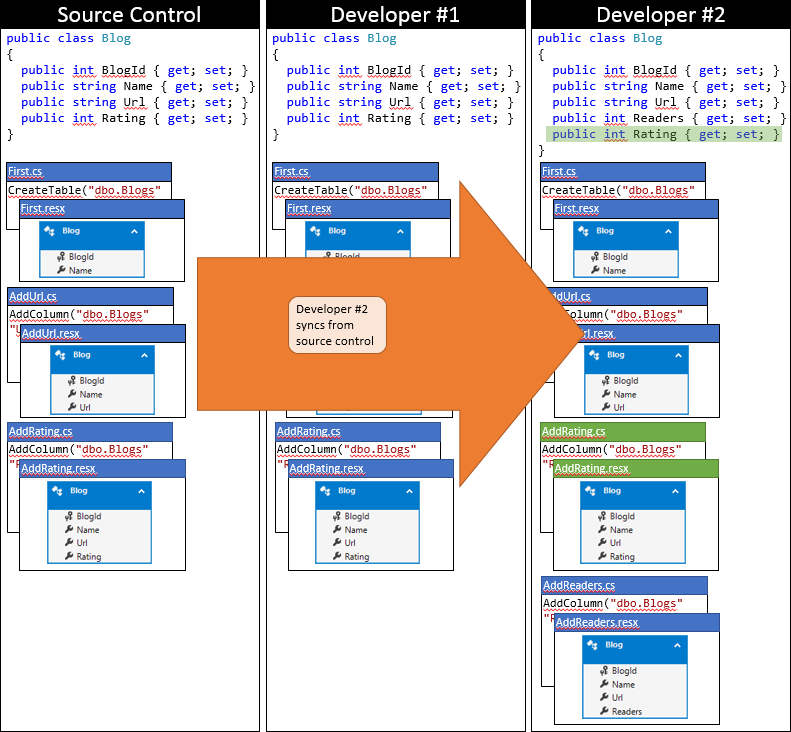
At this point, developer # 2 can run Update-Database , which lets you discover the new AddRatingmigration (which has not been applied to developer database # 2), and apply it. Now the Rating column is added to the Blogs table and the database is synchronized with the model.
There are several problems, for example:
The good news is that it’s not very difficult to merge migrations manually, if you understand how migration works. So if you missed the beginning of this article ... sorry, you need to go back and read the first part of the article first!
There are two options, the easiest is to create an empty migration that has the correct snapshot of the model. The second option is to update the snapshot in the last migration to have the correct model snapshot. This is a bit more complicated and this option cannot be used in every case. Its advantage is that it does not involve the addition of additional migration.
In this option, we generate an empty migration solely so that the last migration has the correct snapshot of the model stored in it.
This feature can be used regardless of who created the last migration. In the example, we watched developer # 2, who generated the last migration. But these same steps can be used if developer # 1 generated the last migration. The steps also apply if there are multiple migrations.
The following algorithm can be used from the moment when changes appear that should be synchronized with the version control system.
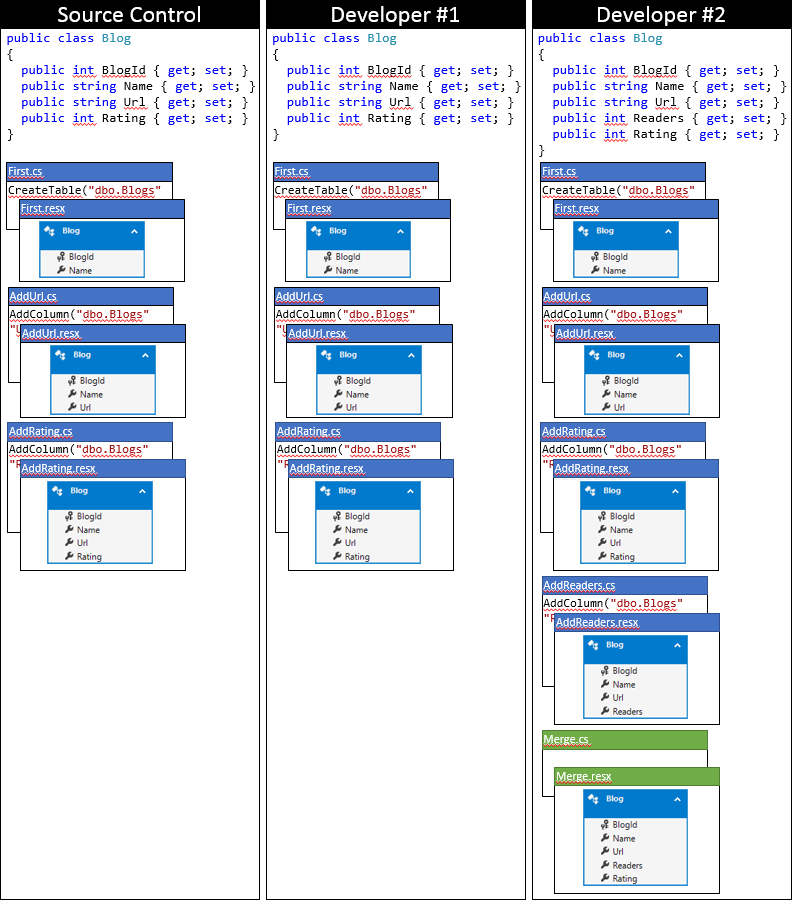
This is the state of developer model # 2 after applying this approach.
This option is very similar to option 1, but removes unnecessary empty migration.
This approach is possible if the last migration exists only locally and has not yet been sent to the version control system (i.e. the last migration was created by the user performing the merge). Editing migration metadata that is used by other developers, or even worse, applied to the combat database, can lead to unexpected side effects. In the process, we will roll back the last migration to our local database and reapply with the updated metadata.
As long as the last migration is locally, there are no restrictions on the number or order of migrations.
The same steps apply for multiple migrations from several different developers.
The following algorithm can be used when changes appear that should be synchronized with the version control system.
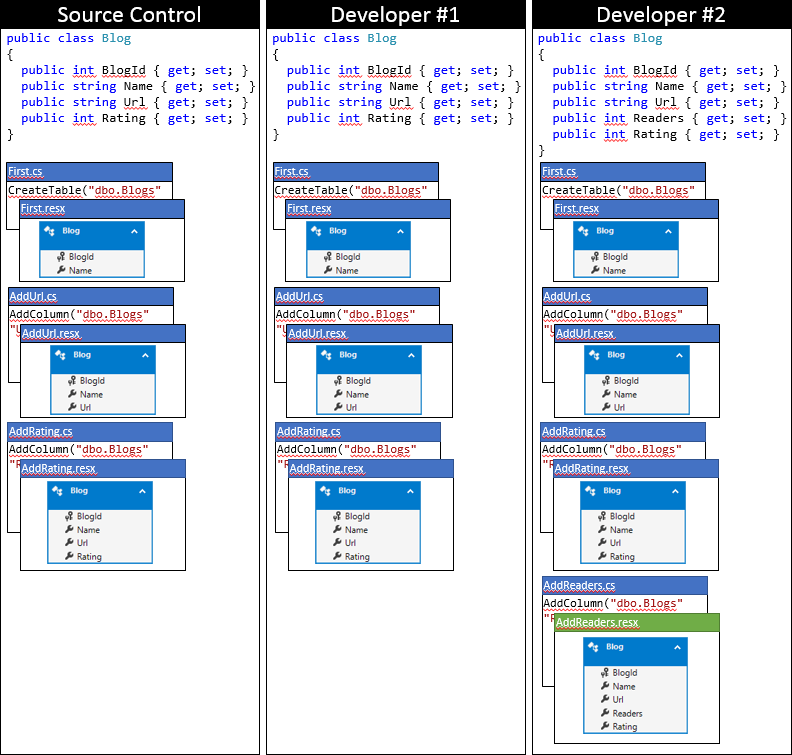
This is the state of the local codebase of developer # 2 after applying this approach.
There are some problems when using Code First migrations in a team. However, a general understanding of how migrations work, and some simple approaches to resolving merge conflicts make these problems easy to overcome.
A fundamental problem is erroneous metadata that is stored in the last migration. This allows Code First to incorrectly determine that the current model and database schema do not match and generate the wrong code for the next migration. This situation can be corrected by generating an empty migration with the correct model, or updating metadata in the latest migration.
This article assumes that you are familiar with the Entity Framework and the basics of working with it. Otherwise, you first need to read Code First Migrations before continuing.
Pour a cup of coffee, you need to read the whole article
In teamwork, the problems are mainly related to the merging of migrations created by two developers in their local databases. While the steps to solve these problems are quite simple, they require a clear understanding of how migrations work. Please take the time to read the entire article carefully.
Some general principles
Before we delve into how to manage the merging of migrations created by several developers, here are some general principles.
Each team member must have a local development database.
The migration engine uses the __MigrationsHistory table to store a list of migrations that have been applied to the database. If your team has several developers generating migrations, then when trying to work with the same database (and, therefore, with the same __MigrationsHistory table ), the migration mechanism may be difficult.
Of course, if you have team members who do not create migrations, then there will be no problems with working with a central database for development.
Avoid Auto Migrations
The bottom line is that automatic migrations initially look good in team work, but in reality they just don't work. If you want to know the reason, continue to read the article, otherwise you can go to the next chapter.
Automatic migrations allow updating the database schema in accordance with the current model without the need to create files with code migration (code-based migration).
Automatic migrations will only work well in team work if you have ever used them and never created any code-based migrations. The problem is that automatic migrations are limited and cannot cope with a number of operations - renaming a property / column, transferring data from one table to another, etc. In order to process such scenarios, you will eventually create code-based migrations (and edit the generated code), which results in mixing the changes that are processed using automatic migrations. This makes it almost impossible to merge the changes between the two developers.
From a translator: 2 screencasts are posted in the original article, I recommend that you read
Principles of the mechanism of migration
The key to successfully using migrations in a team is a basic understanding of how the migration mechanism tracks and uses model information to detect changes.
First migration
When you add the first migration to your project, you run something like Add-Migration First in the Package Manager Console. The steps that this command performs are shown below.
Based on the code, the current model (1) is calculated. Then, using model differ, the necessary database objects are calculated (2) - since this is the first migration, model differ uses an empty model for comparison. The necessary changes are transferred to the code generator to create the necessary migration code (3), which is then added to the Visual Studio solution (4).
In addition to the migration code, which is stored in the main file, the migration mechanism also creates additional code-behind files. These are metadata files that are used by the migration engine and you should not modify them. One of these files is a resource file (.resx), which contains a snapshot of the model at the time the migration was created. In the next section, you will see how it is used.
At this point, you can run Update-Database to apply the changes to the database, and then start implementing the rest of your application.
Subsequent migrations
We’ll make some changes to the model - in our example, we will add the Url property to the Blog class . Then you need to run the Add-Migration AddUrl command to create the migration to apply the appropriate changes to the database. The steps that this command performs are shown below.
Just like last time, the current model is calculated from the code (1). However, this time there are existing migrations, and the previous model is extracted from the last migration (2). These two models are compared to find the necessary changes in the database (3), and then the process ends, as before.
The same process is used for all of the following migrations that are added to the project.
Why steam with model shots?
You may be wondering why EF uses model snapshots for comparison - why not just look at the database.
There are a number of reasons why EF preserves model states:
- This allows your database to be different from the EF model. These changes can be made directly in the database, or you can change the scaffolded code in your migrations to make changes. Here are some examples of this in practice:
- You want to add Inserted and Updated columns to one or more tables, but you do not want to include them in the EF model. If the migration engine looked at the database, it would constantly try to delete these columns every time you generate the migration code. Using the model snapshot, EF will only detect the desired changes in the model.
- You want to change the body of the stored procedure used to update certain debugging information. If the migration mechanism looked at the stored procedure in the database, he would constantly try to reset it back to the definition. When using a model snapshot, EF will generate code to modify the stored procedure when you change the procedure in the EF model
- The same principles apply when adding additional indexes, including additional tables in the database, mapping EF to DB View, etc.
- You want to add Inserted and Updated columns to one or more tables, but you do not want to include them in the EF model. If the migration engine looked at the database, it would constantly try to delete these columns every time you generate the migration code. Using the model snapshot, EF will only detect the desired changes in the model.
- The EF model contains more than just a database image. Having a model, the migration mechanism allows you to view information about the properties and classes of your model and how they are mapped to columns and tables. This information allows the migration engine to be smarter with automatic code generation. For example, if you rename a column, migration mapping will detect the renaming, seeing that this is the same property. It would be impossible to do if we looked only at the database
What causes teamwork issues
The process described in the previous section works great if you are the only developer working on the application. He also works well as a team if you are the only person who makes changes to the model. In this case, you can make changes to the model, generate migrations and send them to the version control system. Other developers may receive such changes and run Update-Database to update the schema.
Problems begin to arise when you have several developers who make changes to the EF model and submit them to the version control system. What EF lacks is a first-class way to combine local migrations with migrations of other developers sent to the version control system after the last synchronization.
Conflict Merge Example
First, let's look at a specific example of merging such a conflict. We will continue with the example that we examined earlier. As a starting point, let's assume that the changes from the previous section were verified by this developer. We will track two developers who make changes to the code.
We will track the EF model and migration through a series of changes. Both developers synchronize through the repository in the version control system, as shown in the following figure.
Developer # 1 and developer # 2 make some changes to the EF model in the local codebase. Developer # 1 adds Rating property to Blog class , creates AddRating migrationto apply changes to the database. Developer # 2 adds the Readers property to the Blog class , creates an AddReaders migration . Both developers run Update-Database to apply the changes to their local databases, and then continue to develop the application.
Note: Migrations start with a timestamp, so our figure shows that AddReaders migration from developer # 2 comes after AddRating migration from developer # 1. From the point of view of working in a team, it does not matter to us in what order these changes were created, we will consider the process of their integration in the next section.
Today, developer # 1 was lucky as he was the first to post his changes to the version control system. Since no one else has submitted changes to the repository, he can simply post his changes without performing any merge.
Now it's time for developer # 2 to submit the changes. He's not so lucky. Because someone posted the changes after the last synchronization, the developer must pick them up and merge. The version control system is likely to be able to automatically merge changes at the code level, as they are very simple. The status of the local developer code base # 2 after synchronization is depicted in the following figure.
At this point, developer # 2 can run Update-Database , which lets you discover the new AddRatingmigration (which has not been applied to developer database # 2), and apply it. Now the Rating column is added to the Blogs table and the database is synchronized with the model.
There are several problems, for example:
- Although the Update-Database operation will apply AddRating migrations , it will also display a warning:
Unable to update database to match the current model because there are pending changes and automatic migration is disabled ...
The problem is that the model snapshot is stored in the last migration (AddReader) , which overlooks the Rating property in the Blog class (since it was not part of the model when the migration was created).
Code First detects that the model in the previous migration does not match the current model and displays a warning. - Running the application will result in an InvalidOperationException "The model backing the 'BloggingContext' context has changed since the database was created. Consider using Code First Migrations to update the database ... ”
Again, the problem is that the model snapshot is stored in the last migration that does not match the current model - Finally, one would expect the launch of Add-Migration will now generate an empty migration (since there are no changes that need to be applied to the database). But since the migrations compare the current model in one of the last migrations (which does not have the Rating property ), this will generate another AddColumn call to add the Rating column .
Of course, this migration will fail with the Update-Database because the Rating column already exists.
Merge Conflict Resolution
The good news is that it’s not very difficult to merge migrations manually, if you understand how migration works. So if you missed the beginning of this article ... sorry, you need to go back and read the first part of the article first!
There are two options, the easiest is to create an empty migration that has the correct snapshot of the model. The second option is to update the snapshot in the last migration to have the correct model snapshot. This is a bit more complicated and this option cannot be used in every case. Its advantage is that it does not involve the addition of additional migration.
Option 1: Adding an Empty “Merge” Migration
In this option, we generate an empty migration solely so that the last migration has the correct snapshot of the model stored in it.
This feature can be used regardless of who created the last migration. In the example, we watched developer # 2, who generated the last migration. But these same steps can be used if developer # 1 generated the last migration. The steps also apply if there are multiple migrations.
The following algorithm can be used from the moment when changes appear that should be synchronized with the version control system.
- Make sure that all model changes in your local codebase have been saved in the migration. This step ensures that you don’t miss any important changes when it comes time to create a clean migration.
- Sync code with version control system
- Run the Update-Database to apply any new migrations made by other developers.
Note: if you do not receive any warnings during the execution of Update-Database, then there were no new migrations from other developers and there is no need to perform additional merges. - Perform Add-Migration
-ignorechanges (e.g. add-migration merge -ignorechanges ). This command creates a migration with all metadata (including a snapshot of the current model), but will ignore any changes that it detects when comparing the current model with the snapshot of the last migration (that is, you will get empty Up and Down methods). - Continue development, or submit changes to the version control system (after starting the unit tests of course).
This is the state of developer model # 2 after applying this approach.
Option 2: Update a snapshot of the latest migration model
This option is very similar to option 1, but removes unnecessary empty migration.
This approach is possible if the last migration exists only locally and has not yet been sent to the version control system (i.e. the last migration was created by the user performing the merge). Editing migration metadata that is used by other developers, or even worse, applied to the combat database, can lead to unexpected side effects. In the process, we will roll back the last migration to our local database and reapply with the updated metadata.
As long as the last migration is locally, there are no restrictions on the number or order of migrations.
The same steps apply for multiple migrations from several different developers.
The following algorithm can be used when changes appear that should be synchronized with the version control system.
- Make sure that all model changes in your local codebase have been saved in the migration.
This step ensures that you don’t miss any important changes when it comes time to create a clean migration. - Sync your code with a version control system.
- Run the Update-Database to apply any new migrations made by other developers.
Note: if you do not receive any warnings during the execution of Update-Database , then there were no new migrations from other developers and there is no need to perform additional merges. - Run Update-Database -TargetMigration
(in the example, this would be Update-Database -TargetMigration AddRating ).
This action rolls the database back to the state of the penultimate migration - in fact,
where the last migration to the database was not applied.
Note: This step is necessary to make it safe to edit migration metadata, since metadata is also stored in the __MigrationsHistory table in the database. That is why you should use this function only if the last migration is only locally. If you need to apply the last migration on other databases, you also need to roll it back and reapply the last migration to update the metadata. - Perform Add-Migration
(in the example, this would be something like Add-Migration 201311062215252_AddReaders migration add -ons ).
Note: You must specify a label so that the migration engine understands that you want to modify an existing migration, rather than create a new one. This will update the metadata for the latest migration to fit the current model. You will receive the following warning when the command completes, but this is exactly what you want. “Only the Designer Code for migration '201311062215252_AddReaders' was re-scaffolded. To re-scaffold the entire migration, use the -Force parameter. ” - Run Update-Database to reapply the latest migration with updated metadata.
- Continue development, or submit changes to the version control system (after starting the unit tests of course).
This is the state of the local codebase of developer # 2 after applying this approach.
Total
There are some problems when using Code First migrations in a team. However, a general understanding of how migrations work, and some simple approaches to resolving merge conflicts make these problems easy to overcome.
A fundamental problem is erroneous metadata that is stored in the last migration. This allows Code First to incorrectly determine that the current model and database schema do not match and generate the wrong code for the next migration. This situation can be corrected by generating an empty migration with the correct model, or updating metadata in the latest migration.