A recurrent neural network of 10 lines of code appreciated the feedback from the audience of the new episode of Star Wars
Hello, Habr! Recently, we received an order from Izvestia to conduct a study of public opinion about the film Star Wars: The Force Awakens, which premiered on December 17. To do this, we decided to analyze the tonality of the Russian Twitter segment using several relevant hashtags. The result was expected from us in just 3 days (and this is at the very end of the year!), So we needed a very fast way. We found several similar online services on the Internet (including sentiment140 and tweet_viz ), but it turned out that they do not work with Russian and for some reason only analyze a small percentage of tweets. AlchemyAPI would help us, but the limit of 1000 requests per day did not suit us either. Then we decided to make our tonality analyzer with blackjack and everything else, creating a simple recurrent neural network with memory. The results of our study were used in the article "Izvestia", published on January 3.

In this article I’ll talk a little about this kind of networks and introduce a couple of cool tools for home experiments that will allow even schoolchildren to build neural networks of any complexity in several lines of code. Welcome to cat.
The main difference between the recurrent networks (Recurrent Neural Network, RNN) from the traditional ones is the logic of the network, in which each neuron interacts with itself. As a rule, a signal is transmitted to the input to such networks, which is a certain sequence. Each element of such a sequence is sequentially transmitted to the same neurons, which return their own prediction along with its next element until the sequence ends. Such networks, as a rule, are used when working with sequential information - mainly with texts and audio / video signals. Elements of a recurrent network are depicted as ordinary neurons with an additional cyclic arrow, which demonstrates that in addition to the input signal, the neuron also uses its additional hidden state. If you expand this image, we get a whole chain of identical neurons, each of which receives an element of the sequence as an input, gives a prediction and passes it down the chain as a kind of memory cell. You need to understand that this is an abstraction, because it is one and the same neuron that processes several times in a row.

Such an architecture of a neural network allows us to solve problems such as predicting the last word in a sentence, for example, the word “sun” in the phrase “the sun shines in a clear sky”.
Simulation of memory in a neural network in a similar way introduces a new dimension in the description of the process of its operation - time. Let a neural network receive a sequence of data as an input, for example, a word-by-word text or a word by letter. Then each next element of this sequence arrives at the neuron at a new conditional moment in time. At this point, the neuron already has experience accumulated from the beginning of the receipt of information. In the example with the sun, a vector characterizing the preposition "c" will appear as x 0 , the word "sky" as x 1 , and so on. As a result, as h tthere should be a vector close to the word "sun."
The main difference between different types of recurrent neurons from each other lies in how the memory cell is processed inside them. The traditional approach involves the addition of two vectors (signal and memory), followed by calculation of the activation of the sum, for example, hyperbolic tangent. It turns out a regular grid with one hidden layer. A similar scheme is drawn as follows:
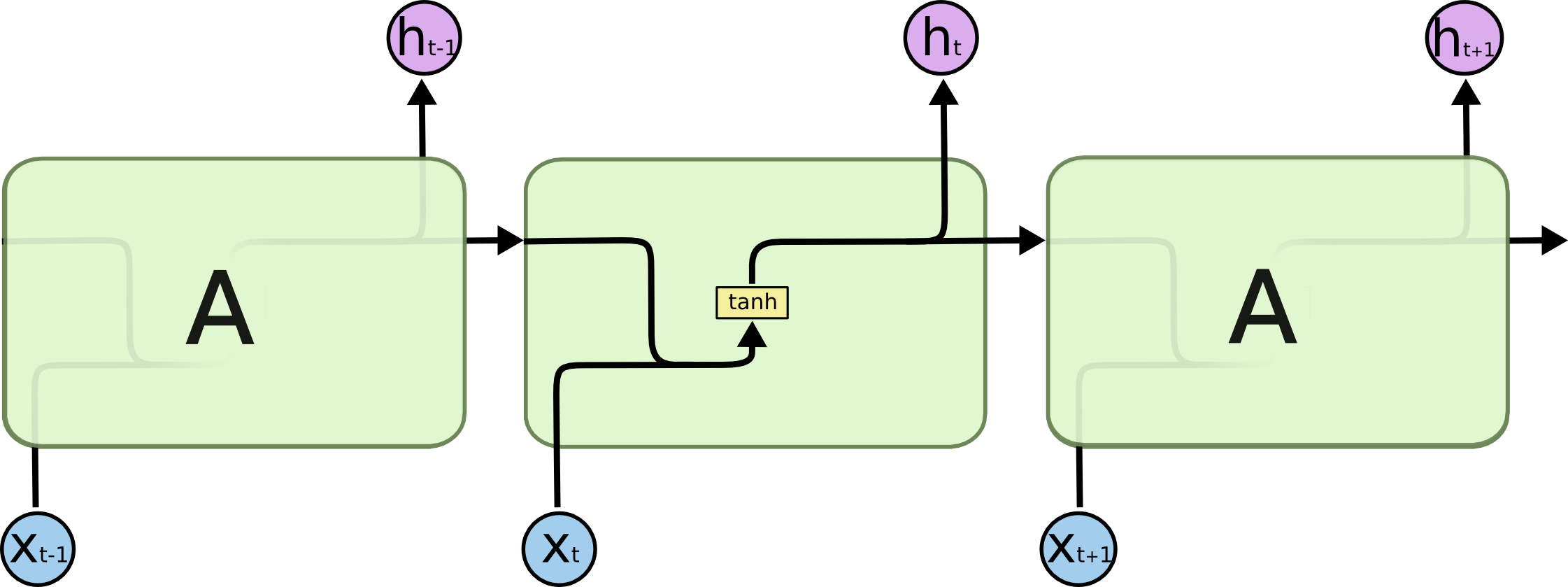
But the memory implemented in this way is very short. Since each time the information in the memory is mixed with the information in the new signal, after 5-7 iterations, the information is completely overwritten. Returning to the task of predicting the last word in a sentence, it should be noted that within a single sentence such a network will work well, but if it comes to a longer text, the patterns at its beginning will no longer make any contribution to the network’s decisions towards the end text, as well as an error on the first elements of sequences in the learning process, ceases to contribute to the overall network error. This is a very conditional description of this phenomenon, in fact, it is a fundamental problem of neural networks, which is called the problem of a vanishing gradient, and because of it, the third “winter” of deep learning began at the end of the 20th century, when neural networks lost the lead by one and a half decades to support vector machines and boosting algorithms.
To overcome this shortcoming, the LSTM-RNN network ( Long Short-Term Memory Recurent Neural Network ) was invented , in which additional internal transformations were added, which operate with memory more carefully. Here is her diagram:
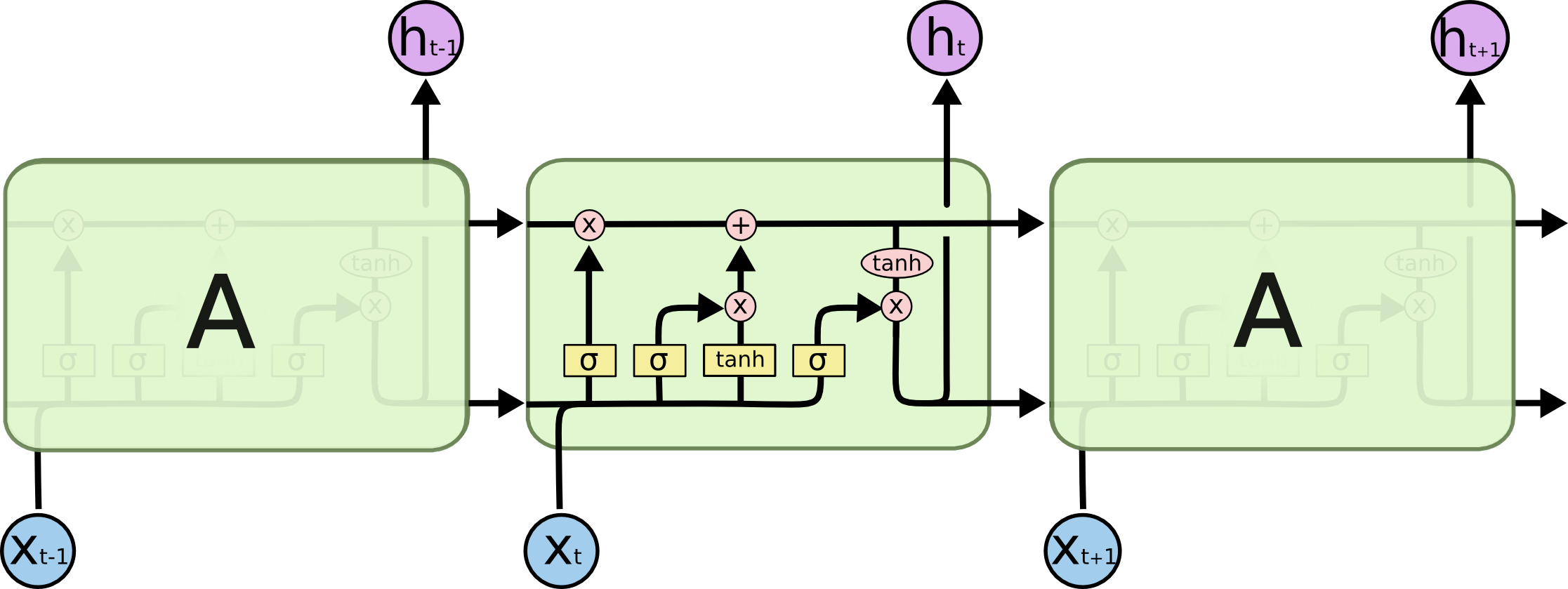
Let's take a closer look at each of the layers:
The first layer calculates how much at this step he needs to forget the previous information - in fact, the factors for the components of the memory vector.

The second layer calculates how much he is interested in the new information that came with the signal - the same factor, but for observation.
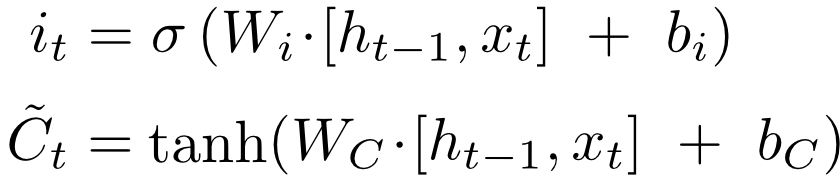
On the third layer, a linear combination of memory and observation is calculated with only the calculated weights for each of the components. Thus, a new state of memory is obtained, which is transmitted in the same form further.
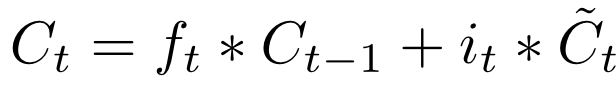
It remains to calculate output. But since part of the input signal is already in memory, it is not necessary to consider activation over the entire signal. First, the signal passes through a sigmoid, which decides which part is important for further decisions, then the hyperbolic tangent “spreads” the memory vector by a segment from -1 to 1, and at the end these two vectors are multiplied.

The h t and C t thus obtained are transmitted down the chain. Of course, there are many variations of exactly which activation functions are used by each layer, slightly modify the schemes themselves and so on, but the essence remains the same - at first they forget a part of the memory, then they remember a part of the new signal, and only then the result is calculated based on these data. I took pictures from here , there you can also see some examples of more complex LSTM schemes.
I will not talk in detail here about how such networks are trained, I can only say that the BPTT (Backpropagation Through Time) algorithm is used, which is a generalization of the standard algorithm for the case when there is time in the network. Read about this algorithm here.or here .
Recursive neural networks built on similar principles are very popular, here are some examples of such projects:
There are also successful examples of using LSTM grids as one of the layers in hybrid systems. Here is an example of a hybrid network that answers questions from a picture in the series “How many books are depicted?”:

Here, the LSTM network works in conjunction with the image recognition module in the pictures. Here it is available comparing various hybrid architectures to solve this problem.
There are many very powerful libraries for creating neural networks for the Python language. Not aiming to give at least some complete overview of these libraries, I want to introduce you to Theano library . Generally speaking, out of the box this is a very effective toolkit for working with multidimensional tensors and graphs. Implementations of most algebraic operations on them are available, including the search for extrema of tensor functions, the calculation of derivatives, and so on. And all this can be effectively parallelized and run calculations using CUDA technologies on video cards.
It sounds great, if not for the fact that Theano itself generates and compiles C ++ code. Maybe this is my prejudice, but I am very distrustful of such systems, because, as a rule, they are filled with an incredible number of bugs that are very difficult to find, maybe because of this I did not pay enough attention to this library for a long time. But Theano was developed at the Canadian MILA Institute under the guidance of Yoshua Bengio, one of the most famous specialists in the field of deep learning of our time, and for my so far short experience with it, I, of course, did not find any errors.
Nevertheless, Theano is only a library for efficient calculations, you need to independently implement backpropagation, neurons and everything else on it. For example, here is the codeusing only Theano of the same LSTM network, which I talked about above, and it has about 650 lines, which does not correspond at all to the title of this article. But maybe I would never try to work with Theano, if not for the amazing keras library . Being essentially only sugar for the Theano interface, it just solves the problem stated in the title.
Any code using keras is based on a model object that describes what order and which layers your neural network contains. For example, the model we used to evaluate the tonality of the Star Wars tweets took a sequence of words as input, so its type was
After declaring the model type, layers are added to it sequentially, for example, you can add an LSTM layer with this command:
After all layers are added, the model must be compiled, if desired, indicating the type of loss function, optimization algorithm and a few more settings:
Compilation takes a couple of minutes, after which the model has accessible methods for everyone fit (), predict (), predict_proba () and evaluate (). It’s so simple, in my opinion this is an ideal option to start diving into the depths of deep learning. When the keras features are not enough and you want to, for example, use your own loss functions, you can go down one level and write part of the code on Theano. By the way, if someone is also scared of the programs that other programs themselves generate, you can also connect the fresh TensorFlow from Google as a backend to keras , but it still works much slower.
Let's get back to our initial task - to determine whether the Russian audience liked Star Wars or not. I used the simple TwitterSearch library as a convenient tool for iterating over Twitter search results. Like all open APIs of large systems, Twitter has certain limitations . The library allows you to call callback after each request, so it is very convenient to pause. Thus, about 50,000 tweets in Russian were pumped out according to the following hashtags:
While they were pumped out, I began to search for a training sample. In English, several marked-up tweet bodies are freely available, the largest of them is the Stanford training sample of sentiment140 mentioned at the very beginning, there is also a list of small datasets. But they are all in English, and the task was posed specifically for Russian. In this regard, I want to express my special thanks to the graduate student (probably already a former?) Of the Institute of Informatics Systems named after A.P. Ershova SB RAS Yulia Rubtsova, who posted an open access corps of almost 230,000 tweeted (with an accuracy of more than 82%). There would be more people in our country who support the community at no cost. In general, we worked with this dataset, you can read about it and download it bylink .
I cleared all the tweets from unnecessary, leaving only continuous sequences of Cyrillic characters and numbers that I drove through PyStemmer . Then he replaced the same words with the same numerical codes, eventually getting a dictionary of about 100,000 words, and the tweets appeared as sequences of numbers, they are ready for classification. I did not begin to clean from low-frequency garbage, because the grid is smart and it will itself be guessed that there is excess.
Here is our keras neural network code:
Except for imports and variable declarations, exactly 10 lines were issued, and it would be possible to write in one. Let's go over the code. There are 6 layers in the network:
In order for training to take place on the GPU when this code is executed, you need to set the appropriate flag, for example like this:
On the GPU, this same model learned from us almost 20 times faster than on the CPU - about 500 seconds on a dataset of 160,000 tweets (a third of the tweets went for validation).
For such tasks, there are no clear rules for the formation of the network topology. We honestly spent half a day experimenting with various configurations, and this one showed the best accuracy - 75%. We compared the result of the grid prediction with an ordinary logistic regression, which showed 71% accuracy on the same dataset when vectorizing text using the tf-idf method and about the same 75%, but when using tf-idf for bigrams. The reason that the neural network almost did not overtake the logistic regression is most likely because the training sample was still small (to be honest, such a network needs at least 1 million tweets of the training sample) and is noisy. The training took place in just 1 era, since then we recorded a strong retraining.
The model predicted the likelihood that the tweet is positive; We considered the feedback with this probability from 0.65 positive, negative to 0.45, and the gap between them neutral. By day, the dynamics are as follows:
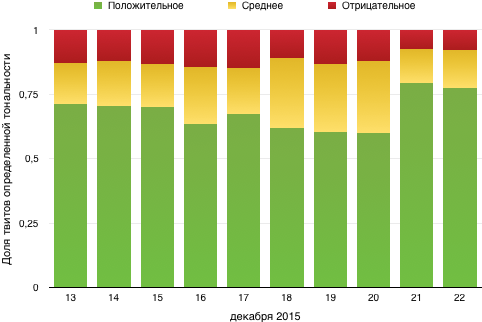
In general, it is clear that people rather liked the film. Although I personally do not really :)
I chose 5 examples of tweets from each group (the indicated number is the probability that the review is positive):
0.9945:
0.9171:
0.8428:
0.8013:
0.7515:
0.6476:
0.6473:
0.6420:
0.6389:
0.5947:
0.3408:
0.1187:
0.1056:
0.0939:
0.0410:
PS Already after the study was conducted, we came across an article in which praise convolutional networks for solving this problem. We’ll try them next time, they are also supported in keras . If one of the readers decides to check it himself, write in the comments about the results, very interesting. May the Power of Big Data be with you!
In this article I’ll talk a little about this kind of networks and introduce a couple of cool tools for home experiments that will allow even schoolchildren to build neural networks of any complexity in several lines of code. Welcome to cat.
What is an RNN?
The main difference between the recurrent networks (Recurrent Neural Network, RNN) from the traditional ones is the logic of the network, in which each neuron interacts with itself. As a rule, a signal is transmitted to the input to such networks, which is a certain sequence. Each element of such a sequence is sequentially transmitted to the same neurons, which return their own prediction along with its next element until the sequence ends. Such networks, as a rule, are used when working with sequential information - mainly with texts and audio / video signals. Elements of a recurrent network are depicted as ordinary neurons with an additional cyclic arrow, which demonstrates that in addition to the input signal, the neuron also uses its additional hidden state. If you expand this image, we get a whole chain of identical neurons, each of which receives an element of the sequence as an input, gives a prediction and passes it down the chain as a kind of memory cell. You need to understand that this is an abstraction, because it is one and the same neuron that processes several times in a row.
Such an architecture of a neural network allows us to solve problems such as predicting the last word in a sentence, for example, the word “sun” in the phrase “the sun shines in a clear sky”.
Simulation of memory in a neural network in a similar way introduces a new dimension in the description of the process of its operation - time. Let a neural network receive a sequence of data as an input, for example, a word-by-word text or a word by letter. Then each next element of this sequence arrives at the neuron at a new conditional moment in time. At this point, the neuron already has experience accumulated from the beginning of the receipt of information. In the example with the sun, a vector characterizing the preposition "c" will appear as x 0 , the word "sky" as x 1 , and so on. As a result, as h tthere should be a vector close to the word "sun."
The main difference between different types of recurrent neurons from each other lies in how the memory cell is processed inside them. The traditional approach involves the addition of two vectors (signal and memory), followed by calculation of the activation of the sum, for example, hyperbolic tangent. It turns out a regular grid with one hidden layer. A similar scheme is drawn as follows:
But the memory implemented in this way is very short. Since each time the information in the memory is mixed with the information in the new signal, after 5-7 iterations, the information is completely overwritten. Returning to the task of predicting the last word in a sentence, it should be noted that within a single sentence such a network will work well, but if it comes to a longer text, the patterns at its beginning will no longer make any contribution to the network’s decisions towards the end text, as well as an error on the first elements of sequences in the learning process, ceases to contribute to the overall network error. This is a very conditional description of this phenomenon, in fact, it is a fundamental problem of neural networks, which is called the problem of a vanishing gradient, and because of it, the third “winter” of deep learning began at the end of the 20th century, when neural networks lost the lead by one and a half decades to support vector machines and boosting algorithms.
To overcome this shortcoming, the LSTM-RNN network ( Long Short-Term Memory Recurent Neural Network ) was invented , in which additional internal transformations were added, which operate with memory more carefully. Here is her diagram:
Let's take a closer look at each of the layers:
The first layer calculates how much at this step he needs to forget the previous information - in fact, the factors for the components of the memory vector.
The second layer calculates how much he is interested in the new information that came with the signal - the same factor, but for observation.
On the third layer, a linear combination of memory and observation is calculated with only the calculated weights for each of the components. Thus, a new state of memory is obtained, which is transmitted in the same form further.
It remains to calculate output. But since part of the input signal is already in memory, it is not necessary to consider activation over the entire signal. First, the signal passes through a sigmoid, which decides which part is important for further decisions, then the hyperbolic tangent “spreads” the memory vector by a segment from -1 to 1, and at the end these two vectors are multiplied.
The h t and C t thus obtained are transmitted down the chain. Of course, there are many variations of exactly which activation functions are used by each layer, slightly modify the schemes themselves and so on, but the essence remains the same - at first they forget a part of the memory, then they remember a part of the new signal, and only then the result is calculated based on these data. I took pictures from here , there you can also see some examples of more complex LSTM schemes.
I will not talk in detail here about how such networks are trained, I can only say that the BPTT (Backpropagation Through Time) algorithm is used, which is a generalization of the standard algorithm for the case when there is time in the network. Read about this algorithm here.or here .
Using LSTM-RNN
Recursive neural networks built on similar principles are very popular, here are some examples of such projects:
There are also successful examples of using LSTM grids as one of the layers in hybrid systems. Here is an example of a hybrid network that answers questions from a picture in the series “How many books are depicted?”:
Here, the LSTM network works in conjunction with the image recognition module in the pictures. Here it is available comparing various hybrid architectures to solve this problem.
Theano and keras
There are many very powerful libraries for creating neural networks for the Python language. Not aiming to give at least some complete overview of these libraries, I want to introduce you to Theano library . Generally speaking, out of the box this is a very effective toolkit for working with multidimensional tensors and graphs. Implementations of most algebraic operations on them are available, including the search for extrema of tensor functions, the calculation of derivatives, and so on. And all this can be effectively parallelized and run calculations using CUDA technologies on video cards.
It sounds great, if not for the fact that Theano itself generates and compiles C ++ code. Maybe this is my prejudice, but I am very distrustful of such systems, because, as a rule, they are filled with an incredible number of bugs that are very difficult to find, maybe because of this I did not pay enough attention to this library for a long time. But Theano was developed at the Canadian MILA Institute under the guidance of Yoshua Bengio, one of the most famous specialists in the field of deep learning of our time, and for my so far short experience with it, I, of course, did not find any errors.
Nevertheless, Theano is only a library for efficient calculations, you need to independently implement backpropagation, neurons and everything else on it. For example, here is the codeusing only Theano of the same LSTM network, which I talked about above, and it has about 650 lines, which does not correspond at all to the title of this article. But maybe I would never try to work with Theano, if not for the amazing keras library . Being essentially only sugar for the Theano interface, it just solves the problem stated in the title.
Any code using keras is based on a model object that describes what order and which layers your neural network contains. For example, the model we used to evaluate the tonality of the Star Wars tweets took a sequence of words as input, so its type was
model = Sequential()
After declaring the model type, layers are added to it sequentially, for example, you can add an LSTM layer with this command:
model.add(LSTM(64))
After all layers are added, the model must be compiled, if desired, indicating the type of loss function, optimization algorithm and a few more settings:
model.compile(loss='binary_crossentropy', optimizer='adam', class_mode="binary")
Compilation takes a couple of minutes, after which the model has accessible methods for everyone fit (), predict (), predict_proba () and evaluate (). It’s so simple, in my opinion this is an ideal option to start diving into the depths of deep learning. When the keras features are not enough and you want to, for example, use your own loss functions, you can go down one level and write part of the code on Theano. By the way, if someone is also scared of the programs that other programs themselves generate, you can also connect the fresh TensorFlow from Google as a backend to keras , but it still works much slower.
Tweet sentiment analysis
Let's get back to our initial task - to determine whether the Russian audience liked Star Wars or not. I used the simple TwitterSearch library as a convenient tool for iterating over Twitter search results. Like all open APIs of large systems, Twitter has certain limitations . The library allows you to call callback after each request, so it is very convenient to pause. Thus, about 50,000 tweets in Russian were pumped out according to the following hashtags:
- #starwars
- #star Wars
- #star #wars
- #star Wars
- #AwakeningForces
- #TheForceAwakens
- #awakening #power
While they were pumped out, I began to search for a training sample. In English, several marked-up tweet bodies are freely available, the largest of them is the Stanford training sample of sentiment140 mentioned at the very beginning, there is also a list of small datasets. But they are all in English, and the task was posed specifically for Russian. In this regard, I want to express my special thanks to the graduate student (probably already a former?) Of the Institute of Informatics Systems named after A.P. Ershova SB RAS Yulia Rubtsova, who posted an open access corps of almost 230,000 tweeted (with an accuracy of more than 82%). There would be more people in our country who support the community at no cost. In general, we worked with this dataset, you can read about it and download it bylink .
I cleared all the tweets from unnecessary, leaving only continuous sequences of Cyrillic characters and numbers that I drove through PyStemmer . Then he replaced the same words with the same numerical codes, eventually getting a dictionary of about 100,000 words, and the tweets appeared as sequences of numbers, they are ready for classification. I did not begin to clean from low-frequency garbage, because the grid is smart and it will itself be guessed that there is excess.
Here is our keras neural network code:
from keras.preprocessing import sequence
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.layers.embeddings import Embedding
from keras.layers.recurrent import LSTM
max_features = 100000
maxlen = 100
batch_size = 32
model = Sequential()
model.add(Embedding(max_features, 128, input_length=maxlen))
model.add(LSTM(64, return_sequences=True))
model.add(LSTM(64))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='adam',
class_mode="binary")
model.fit(
X_train, y_train,
batch_size=batch_size,
nb_epoch=1,
show_accuracy=True
)
result = model.predict_proba(X)
Except for imports and variable declarations, exactly 10 lines were issued, and it would be possible to write in one. Let's go over the code. There are 6 layers in the network:
- The Embedding layer, which is preparing features, the settings indicate that there are 100,000 different features in the dictionary, and the grid should wait for a sequence of no more than 100 words.
- Next, two LSTM layers, each of which gives out the tensor dimension batch_size / length of a sequence / units in LSTM, and the second gives the batch_size / units in LSTM matrix. In order for the second to understand the first, the flag return_sequences = True is set
- The Dropout layer is responsible for retraining. It zeroes out a random half of the features and interferes with the co-adaptation of weights in the layers (we believe the word Canadians ).
- The Dense layer is a regular linear unit that weightedly sums the components of the input vector.
- The last activation layer pushes this value in the range from 0 to 1, so that it becomes a probability. In essence, Dense and Activation in this order is a logistic regression.
In order for training to take place on the GPU when this code is executed, you need to set the appropriate flag, for example like this:
THEANO_FLAGS=mode=FAST_RUN,device=gpu,floatX=float32 python myscript.py
On the GPU, this same model learned from us almost 20 times faster than on the CPU - about 500 seconds on a dataset of 160,000 tweets (a third of the tweets went for validation).
For such tasks, there are no clear rules for the formation of the network topology. We honestly spent half a day experimenting with various configurations, and this one showed the best accuracy - 75%. We compared the result of the grid prediction with an ordinary logistic regression, which showed 71% accuracy on the same dataset when vectorizing text using the tf-idf method and about the same 75%, but when using tf-idf for bigrams. The reason that the neural network almost did not overtake the logistic regression is most likely because the training sample was still small (to be honest, such a network needs at least 1 million tweets of the training sample) and is noisy. The training took place in just 1 era, since then we recorded a strong retraining.
The model predicted the likelihood that the tweet is positive; We considered the feedback with this probability from 0.65 positive, negative to 0.45, and the gap between them neutral. By day, the dynamics are as follows:
In general, it is clear that people rather liked the film. Although I personally do not really :)
Network Examples
I chose 5 examples of tweets from each group (the indicated number is the probability that the review is positive):
Positive tonality
0.9945:
You can breathe out calmly, the new Star Wars are old-school excellent. Abrams is cool, as always. The script, music, actors and filming are perfect.— snowdenny (@maximlupashko) December 17, 2015
0.9171:
I advise everyone to go to the Star Wars super movie— Nicholas (@ shans9494) December 22, 2015
0.8428:
POWER WAKE UP! YES ARRIVING WITH YOU TODAY ON THE PREMIERE OF THE MIRACLE WHICH YOU WAITED FOR 10 YEARS! #TheForceAwakens #StarWars - Vladislav Ivanov (@Mrrrrrr_J) December 16, 2015
0.8013:
Although I’m not a fan of #StarWars , but this performance is wonderful! #StarWarsForceAwakens https://t.co/1hHKdy0WhB - Oksana Storozhuk (@atn_Oksanasova) December 16, 2015
0.7515:
Who watched star wars today? me me :)) - Anastasiya Ananich (@NastyaAnanich) December 19, 2015
Mixed tone
0.6476:
New Star Wars is better than the first episode, but worse than everyone else— Igor Larionov (@ Larionovll1013) December 19, 2015
0.6473:
plot spoiler
Han Solo will die. Happy viewing. # Star Wars - Nick Silicone (@nicksilicone) December 16, 2015
0.6420:
Everyone has Star Wars around. Am I the only one in the subject? : / - Olga (@dlfkjskdhn) December 19, 2015
0.6389:
To go or not to go to Star Wars, that’s the question - annet_p (@anitamaksova) December 17, 2015
0.5947:
Star Wars left a double impression. And good and not very. In some places, it was not felt that they were the same ... something else was slipping— Evgeny Kolot (@ KOLOT1991) December 21, 2015
Negative tonality
0.3408:
There is so much talk around, am I really not a fan of Star Wars? #StarWars #StarWarsTheForceAwakens - modern mind (@ modernmind3) December 17, 2015
0.1187:
they tore my poor heart out of the chest and broke it into millions and millions of fragments #StarWars - Remi Evans (@Remi_Evans) December 22, 2015
0.1056:
I hate dokklov, star wars spoiled me— Niall's pajamas (@harryteaxxx) December 17, 2015
0.0939:
I woke up and realized that the new Star Wars was disappointing.— Tim Frost (@Tim_Fowl) December 20, 2015
0.0410:
I am disappointed # probuzhdeniesily - Eugenjkee; Star Wars (@eugenjkeee) December 20, 2015
PS Already after the study was conducted, we came across an article in which praise convolutional networks for solving this problem. We’ll try them next time, they are also supported in keras . If one of the readers decides to check it himself, write in the comments about the results, very interesting. May the Power of Big Data be with you!