Highly Available Cluster RabbitMQ
- Tutorial
Get to know RabbitMQ
Translations on the hub:
RabbitMQ tutorial 1 - Hello World
RabbitMQ tutorial 2 - Task Queue
RabbitMQ tutorial 3 - Publish / Subscribe I
’ll add some shortcomings right away. And briefly repeat the basic terms.
How architecture works using rabbitMq
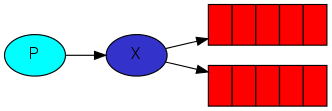
There is an application (client) generating messages, messages get to the exchange point, depending on the message parameters and settings of the exchange point, the message is copied to one or more queues (or simply deleted), after which clients can pick up messages from the queues.
The queue is associated with the exchange point using a routing key or message header.
Routing key - the value that is specified when the message is published to the exchange point serves to determine the queues to which the message will fall.
A message header is a set of key-value arguments associated with a message.
Exchange points can be 4 types:
- direct - messages that reach this exchange point will be copied only to those queues that are associated with the exchange point with a strict routing key.
- topic - the routing key can be composite, and set in the form of a pattern, for which there are two special characters: * - indicates one word, # - one or more words. Words are separated by a period. Example: routingKey = "* .database" - all messages with keys in which the second word means database will be copied to the queues bound by the pattern.
- headers - the queue is connected to the exchange point not by the routing key, but by the message header, the condition is indicated, what arguments and their values are expected, and when the exchange point receives a message with a header containing arguments from the condition, the queue receives it. An example can be found here .
- fanout - the message received at the exchange point is copied to all attached queues, without checking the routing key or message header.
Each queue has 4 flags defining its behavior:
- auto_delete - if the queue is empty and there are no active connections to it, the queue is automatically deleted
- durable - stable queue, messages are not lost upon restart of rabbitMQ (or sudden reboot), upon publication and until the end of the upload, they are stored in the database
- exclusive - the queue is designed for no more than one connection at a time
- passive - when the queue is declared passive, when the client contacts the server will consider that the queue is already created, i.e. it will not automatically create it in case of absence, this option is needed if you want to contact the server without changing its state. For example, you just need to check if the queue exists. To do this, declare the queue passive, and if you get an error, then the queue does not exist.
Now a little about the work of rabbit, when installing and starting as a service, the default settings are used, as the developers write in the official documentation , this should be enough for most scenarios, but I have not seen situations in real products when there were enough settings for by default. Operation parameters can be changed in runtime using utility utilities (located in the \ rabbitmq_server-3.2.0 \ sbin directory), however, changes made in this way will be lost when rabbitmq is restarted (respectively, and when rebooting). We move on to the next topic.
RabbitMQ configuration
The RabbitMQ server operation configuration is located in three places, these are environment variables (ports and locations and file names are set), configuration files (access settings, clusters, plug-ins), and settings specified in runtime (policies, performance settings).
When installing on Windows, the configuration file is not created, there is only an example of it located in the \ rabbitmq_server-3.2.0 \ etc \ rabbitmq.config.example directory. We create our configuration file, call it rabbitmq.config (the extension is .config, and nothing else!), And fill it with simple settings:
%% Sample
[
{rabbit,
[
{tcp_listeners, [5672]},
{log_levels, [{connection, error}]},
{default_vhost, <<"/">>},
{default_user, <<"username">>},
{default_pass, <<"password">>},
{default_permissions, [<<".*">>, <<".*">>, <<".*">>]},
{heartbeat, 60},
{frame_max, 1048576}
]}
].
Framing << >> is not a mistake, it should be so.
Comments in the settings are preceded by a double percent symbol - %%.
Now we place the file in a convenient place, for example, in the root folder with the RabbitMQ server installed, for example, let there be a path:
c: \ rabbitmq \ rabbitmq.config
In order for RabbitMq to see the configuration file, you need to create an environment variable with its location
RABBITMQ_CONFIG_FILE = c:\rabbitmq\rabbitmq
It is worth creating a variable both in the user's environment and in the system environment.
We write the path to the file name, we trim the extension. Creating a file config and setting up the environment is best done before installing the RabbitMQ server, or reinstalling it after. (For environment changes to take effect the service must be re-installed.) A simple restart does not help.
Now you can install Erlang and the RabbitMQ server .
Create and configure a cluster
Attention
Все команды выполняемые в командной строке, выполняются в каталоге инструментов установленного RabbitMQ сервера:
RabbitMQ\RabbitMQ Server\rabbitmq_server-3.2.1\sbin
The cluster, in rabbitMQ, is the connection of one or more RabbitMQ servers with each other, in which one of the nodes acts as a master server, the rest as slave servers, the wizard sets cluster settings that are duplicated to the slaves to them, in These include access settings and policies. When a master falls, one of the slaves takes on his role and becomes a master.
First of all, before creating the cluster, we need to synchronize the RabbitMQ cookies of the nodes, the cookies in RabbitMQ are the hash generated during installation, which is used as the node identifier, because the cluster acts as a single node, on each server the cookies must be identical.
On the master server we take the file
%WINDOWS%\.erlang.cookie
and copy it with replacement along the way
C:\Users\%CurrentUser%\.erlang.cookie, after which we copy with replacement for each cluster node in the specified paths.
The cluster is created by executing the following commands on each slave:
rabbitmqctl stop_app
rabbitmqctl join_cluster --ram rabbit@master
rabbitmqctl start_app
Or by specifying in the configuration file:
{cluster_nodes, {["rabbit@master", "rabbit@host01"], disc}}
This procedure needs to be performed only once, when adding a new node, in the future the node will connect to the cluster automatically (for example, after rebooting the server on which the node is raised).
The cluster is created, but it is not suitable for full use, at the current stage, the queues and messages on each node live separately, no synchronization is performed, which means that if two clients connect to the cluster to different nodes, then when one of them posts messages to the queue, the second doesn’t know anything about it. Also, when one of the nodes crashes, all messages that were on it will be lost.
Sync Policies
We go into the tools and execute the following command in runtime:
rabbitmqctl set_policy HA ".*" "{""ha-mode"": ""all""}"
Now all queues and messages in them will be synchronized. When a message is published, it becomes available to clients only after copying to all nodes of the cluster.
There was one problem, when one of the nodes crashes, the clients connected to it must determine the fact of the crash and be able to switch to available nodes, RabbitMQ developers write:
Connect to a cluster of client applications.
The client can connect to any node in the cluster. If the node falls while the rest of the cluster continues to work, then the clients connected to it must determine the fact of the fall and must be able to reconnect to the cluster, to the working nodes. As a rule, it is not recommended to add real IPs of all cluster nodes to client applications; this interferes with flexibility both in the operation of the applications themselves and in the configuration of the cluster. Instead, we recommend using a more abstract approach: it can be some kind of DNS service with a very small TTL value, or a simple TCP balancer, or some kind of mobile IP, or similar technology. In general, this aspect is beyond the scope of RabbitMQ, and we recommend using technologies developed to solve these problems.
Those. it is recommended not to write a bike, but to use a ready-made solution, in my version I use NLB as a native solution built into Windows. This step is up to you.
Usefulness
We ping the node from the command line:
rabbitmqctl eval "net_adm:ping(rabbit@hostname)."
if the node is available we get the answer pong
References
www.rabbitmq.com/clustering.html
www.rabbitmq.com/ha.html