How to fit in the iPhone a million stars

Such a romantic thing as the starry sky, and such a hardcore thing as optimization of memory consumption by an iOS application, may well go together: it is worth trying to stuff this starry sky into an AR application, as soon as the question arises about that very consumption.
Minimizing the use of memory will be useful in many other cases. So this text shows, on the example of a small project, optimization methods that can be useful in completely different iOS applications (and not only iOS-).
The post was prepared on the basis of the interpretation of the report by Konrad Fayler from the Mobius 2018 Piter conference. We attach its video, and then - the text version of the first person:
I am glad to welcome everyone! My name is Konrad Fayler, and under the effective name “Million Stars in One iPhone” we will discuss how you can minimize the size of memory occupied by your iOS application. Colorful and in examples.
Why optimize?
What generally encourages us to engage in optimization, what exactly would we like to achieve? We do not want this:

We do not want the user to have to wait. That is the first reason - to reduce the load time .
Another reason is to improve the quality .

Speech here can go about the quality of images, sound and even AI. "Optimized AI" means that you can achieve more - for example, calculate the game for a larger number of moves forward.
The third reason is very important: saving battery power . Optimization helps to discharge the battery less. Here is an interesting comparison, albeit from the world of Android. Here Vulkan and OpenGL ES were compared: The

second one is worse optimized for mobile platforms. Observing battery consumption, you can see that for a similar image, OpenGL ES was spending a lot more resources than Vulkan.
What kind of optimization can help here? For example, in a turn-based game, when the user thinks about his own move, you can reduce the FPS to zero. If you have a 3D engine, then it’s perfectly reasonable to just turn everything off while the user just looks at the screen.
In addition, there are times when, without an optimized approach, you will not be able to implement this or that advanced feature: it simply will not pull.
Without fanaticism
Speaking of optimization, one can not forget the thesis of Donald Knuth: “We should forget about a small efficiency, say, in 97% of cases: premature optimization is the root of all evil. Although we should not give up our opportunities in this critical 3%. ”
In 97% of cases, we should not care about efficiency, but above all about how to make our code understandable, safe, and testable. We are still developing for mobile devices, not for spacecraft. Companies where we work should not overpay for the support of the code written by us. In addition, the working time of the developer has a cost, and if you spend it on optimizing something unimportant, then you spend the company's funds. Well, the fact that a well-optimized code tends to be more difficult to understand, you can be sure of those examples that I will demonstrate to you today.
In general, meaningfully prioritize and optimize as needed.
Approaches
When working on optimization, we usually monitor either performance (read: processor load) or memory usage. Often, these two options will conflict, and you will need to find a balance between them.
In the case of a processor, we can reduce the number of processor cycles required by our operations. As you understand, fewer processor cycles give us less boot time, less battery consumption, the ability to provide better quality, etc.
For iOS developers, Xcode Instruments has a handy Time Profiler tool. It allows you to track the number of CPU cycles spent by different parts of your application. This report is not about tools, so I’m not going to dive into the details now, this was a good video from WWDC.
You can choose another goal - optimization for the sake of memory. We will try to make our application fit into the smallest possible number of RAM cells when launched. Remember that the most voluminous applications become the first candidates for a forced completion during the cleanup, which the OS has to do. Therefore, it affects how long your application will remain in the background.
It is also important that the RAM resource of different devices is also different. If you, say, decided to develop for Apple Watch, then there is little memory, and this also forces you to optimize.
Finally, sometimes a small amount of memory also makes the program very fast. I will give an example. Before you are structures of various sizes in bytes:

Element8 contains 8 bytes, Element16 - 16, and so on.

Let's get arrays, one for each of our kinds of structures. The dimension of all arrays is the same - 10,000 elements each. Each structure contains a different number of fields (incrementally); The n field is the first field and, accordingly, is present in all structures.
And now let's try the following: for each array we will calculate the sum of all its fields n. That is, each time we will sum up the same number of elements (10,000 pieces). The only difference is that for each sum the variable n will be extracted from structures of different sizes. We are interested in whether the same time takes the summation.
The result is the following:
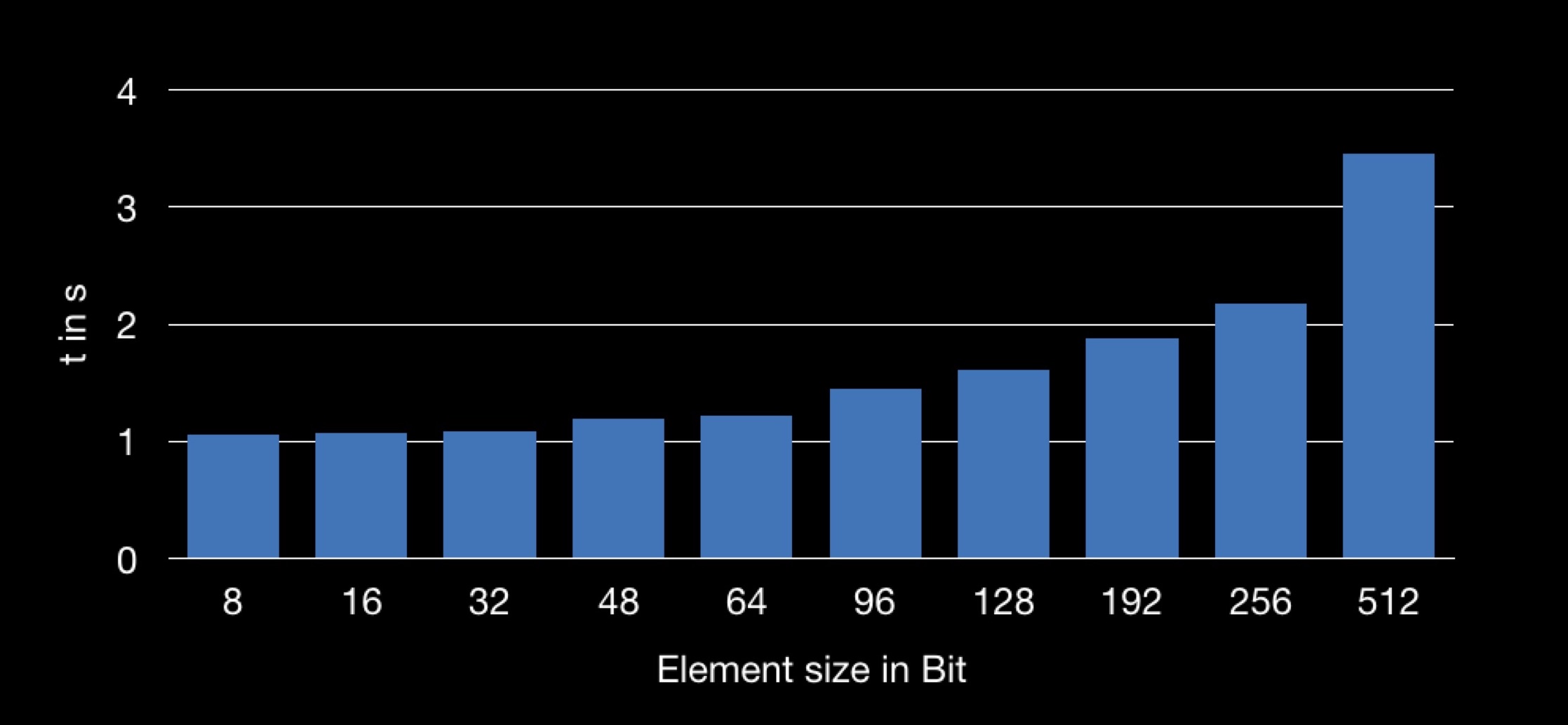
The graph shows the dependence of the summation time on the size of the structure used in the array. It turns out that it is longer to extract the field n from the larger structure, and therefore the summation operation takes longer.
Many of you have already understood why this is happening.
The processor has L1, L2 caches (sometimes also L3 and L4). The processor accesses this type of memory directly and quickly.
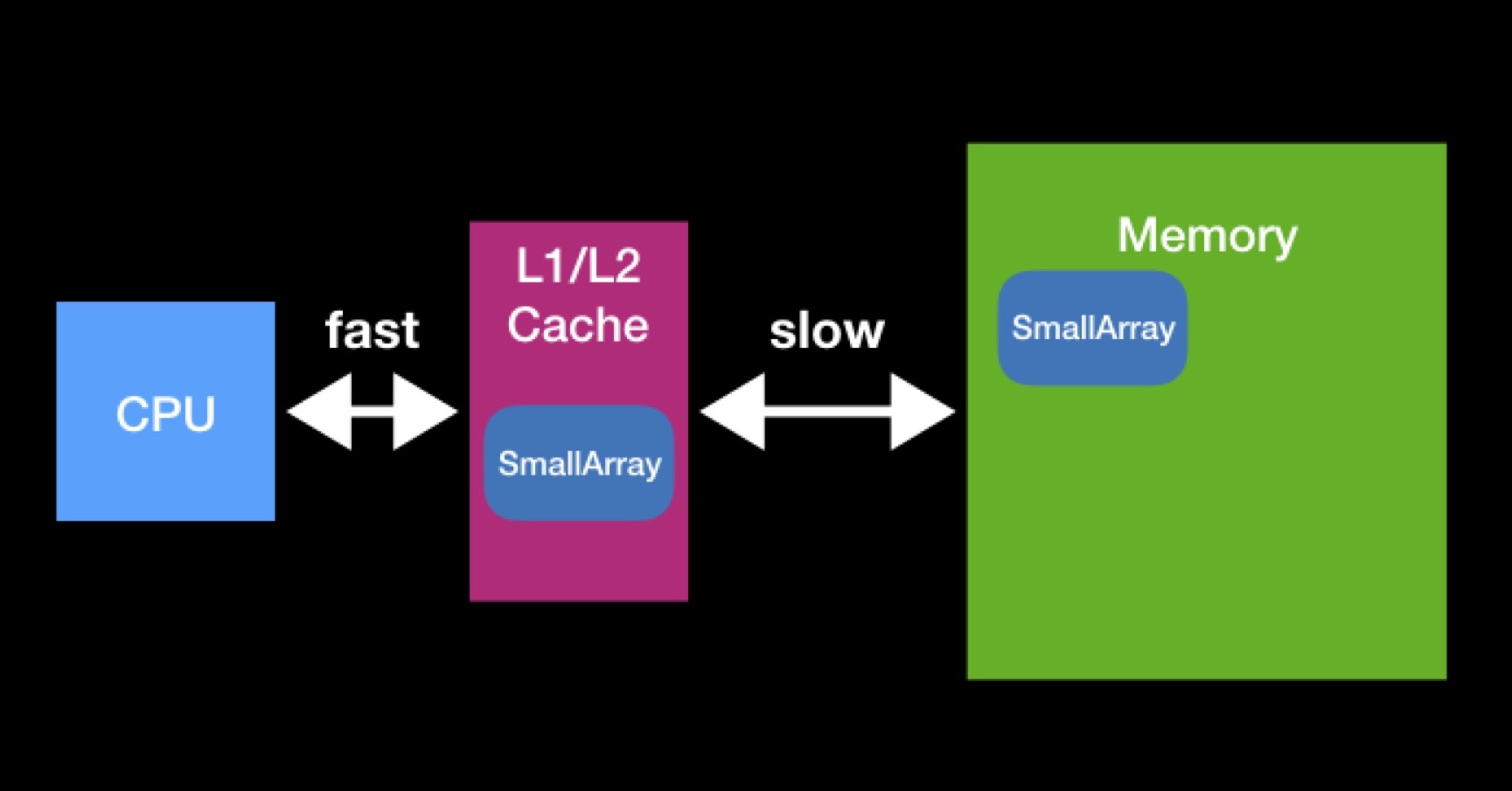
Caches exist to speed up data reuse. Suppose we work with arrays. If the array required by the processor is already present in any of the caches, then the processor already needed it. At that moment, he requested them from the main memory, put them in the cache, performed all the necessary operations with them, after which the data remained to lie down (they did not manage to wipe others).
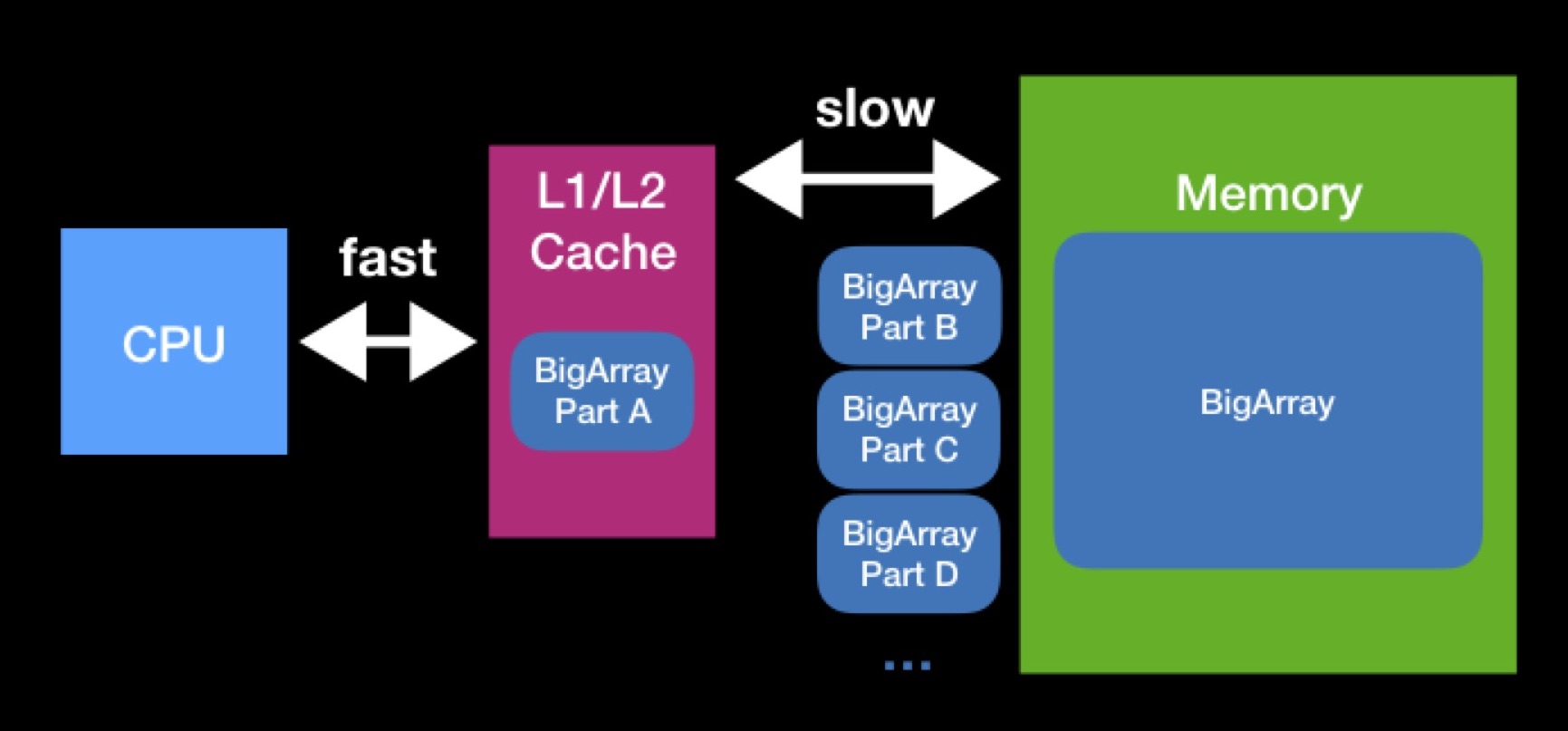
The sizes of caches L1, L2 are not so big. The array required by the processor to work may be more. In order to fully perform an operation on such an array, we will have to unload it into the cache in parts and operate with these parts in turn. Due to constant requests to the main memory, the processing of our array will take much longer.
When programming data structures, try to keep track of the caching mechanism. It is possible that by reducing the size of your data structure, you will achieve its successful cache capacity and speed up the operations that will be performed on it in the future. Interaction with the main memory has always been, is and, most likely, will remain a significant performance factor - even when you write on Swift for modern high-performance devices.
CPU vs. RAM: lazy initialization
Although in some cases when the memory used decreases, the program starts to work faster, there are also cases where these two metrics conflict, on the contrary. I will give an example with the concept of lazy initialization.
Suppose we have a method makeHeavyObject (), which returns some large object. This method will initialize the lazilyCalculated variable.

The lazy modifier sets lazilyCalculated lazy initialization. This means that the value will be assigned to it only when the first access to it occurs during execution. It is then that the makeHeavyObject () method will work and the resulting object will be assigned to the variable lazilyCalculated.
What is the plus here? From the moment of initialization (let it be later, but it will be executed) we have an object located in the memory. Its value is counted, it is ready to use - just make a request. Another thing is that our object is large and from the moment of initialization it will occupy its lion’s share of cells in memory.
You can go the other way - do not store the value of the field at all:

With each link to the field lazilyCalculated, the makeHeavyObject () method will be re-executed. The value will be returned to the query point, but it will not be stored in memory. As you can see, storing a variable is optional.
What is more expensive - to keep a large object in memory, but not to spend processor time, or to call the method every time we need our field, while saving memory? Do you have a ready value at hand or calculate it on the fly? This kind of dilemma arises quite often, no matter where you perform your calculations — on a remote server or on your local machine, no matter what cache you have to work with. You will have to make a decision based on the system constraints in this particular case.
Optimization cycle

Whatever you optimize, your work, as a rule, will be based on the same algorithm. First, you examine the code, profile / measure it (in Xcode using appropriate tools), trying to identify its bottlenecks. Essentially, you order the methods by how much time they are executed. And then look at the top lines to determine what to optimize.
By selecting an object, you set yourself a task (or, scientifically speaking, put forward a hypothesis): by applying certain optimization methods, you can make the selected piece of code run faster.
Next you try to optimize. After each modification, you look at the performance indicators, assessing how effective the modification turned out to be, how much you have managed to progress.
Just like in scientific work: assumption, experiment, analysis of results. You go through this cycle of action time after time. Practice shows that the work constructed in this way really allows you to eliminate the bottlenecks one by one.
Unit tests

Briefly about unit tests: we have some function that we test, some input data input and output data output; receiving input, our function should always return output, and none of our optimizations should violate this property.
Unit tests help us track down a breakdown. If, in response to input, our function stopped returning output, then, directly or indirectly, we changed the old workflow of our function.
Don't even try to start optimizing if you haven't written a generous portion of unit tests to your code. You must have regression testing. If you look at GitHub my commits in my example application, to which I will go further, you can see that some of my optimizations have brought bugs with them.
And now the most interesting - go to the stars.
Million stars
There is a large (huge) database describing a million stars. Over it I have created several applications. One of them uses augmented reality, in real time, drawing the stars over the image from the camera of the phone. Now I will demonstrate it in action:
In the absence of city lights, a person can discern up to 8,000 stars in the sky. I would need about 1.8 MB to store 8000 records. In principle, acceptable. But I wanted to add those stars that a person can see through a telescope - it turned out about 120,000 stars (according to the so-called Hipparcos catalog, now obsolete). This required 27 MB already. And among the modern directories in the public domain you can find one that will total about 2,500,000 stars. Such a database would have occupied about 560 MB. As you can see, it requires a lot of memory. And after all, we want not just a database, but an application based on it, with ARKit, SceneKit and other things that also require memory.
What to do?
We will optimize the stars.
MemoryLayout tool
You can estimate the size of the program as a whole. But for such jewelry work as optimization, you will need tools to estimate the size of each individual data structure.
Swift allows you to do this quite simply - using MemoryLayout <> objects. You declare a MemoryLayout <>, specifying the data structure that interests you as a generic type. Now, referring to the properties of the resulting object, you can get a variety of useful information about its structure.

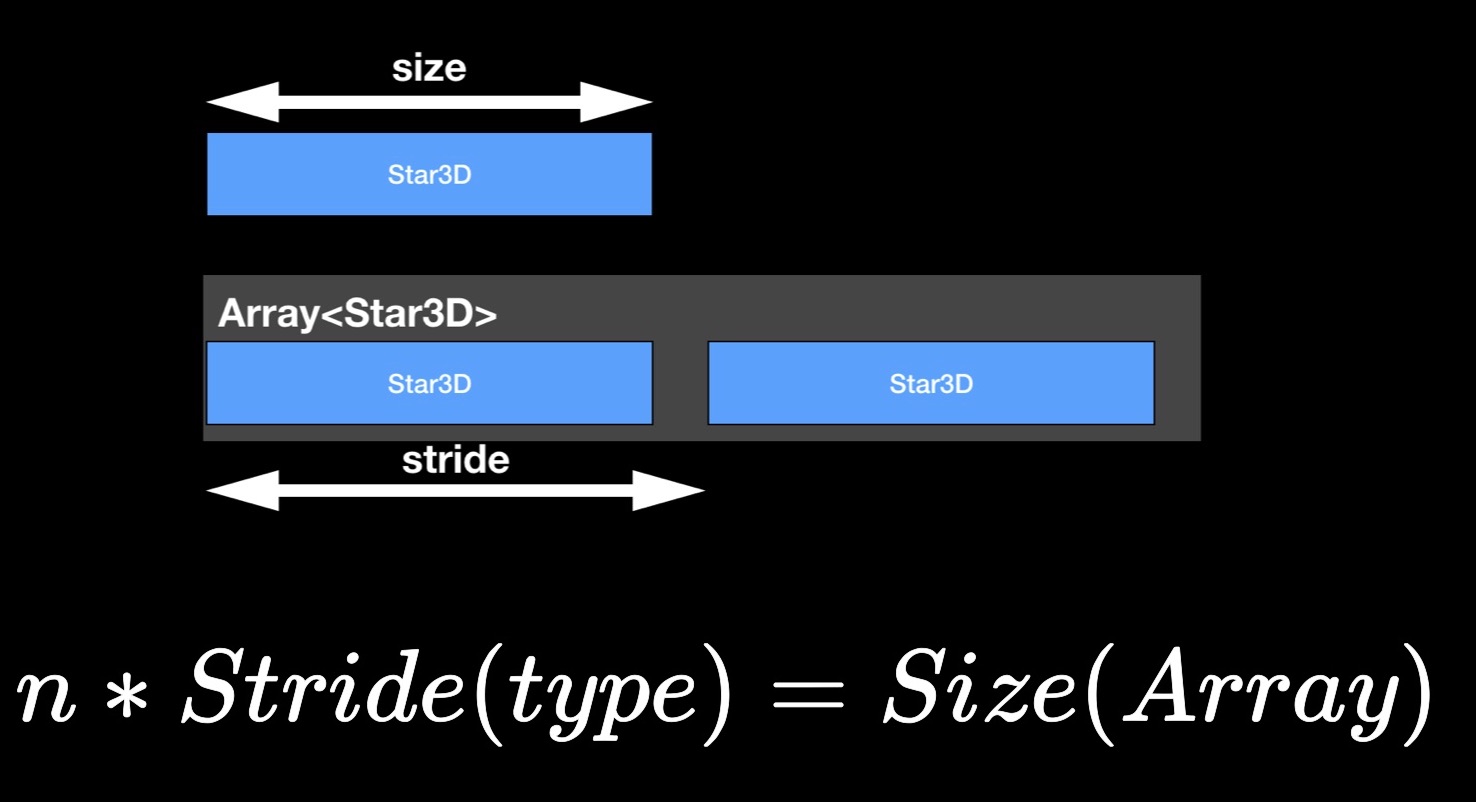
The size property gives us the number of bytes occupied by a single instance of the structure.
Now about the stride property. You may have noticed that the size of the array, as a rule, is not equal to the sum of the sizes of its constituent elements, but exceeds it. Obviously, some “air” is left in the memory between the elements. To estimate the distance between successive elements in an adjacent array, we use the stride property. If you multiply it by the number of elements in the array, you get its size.
StarData, our experimental structure, in its original non-optimized state:
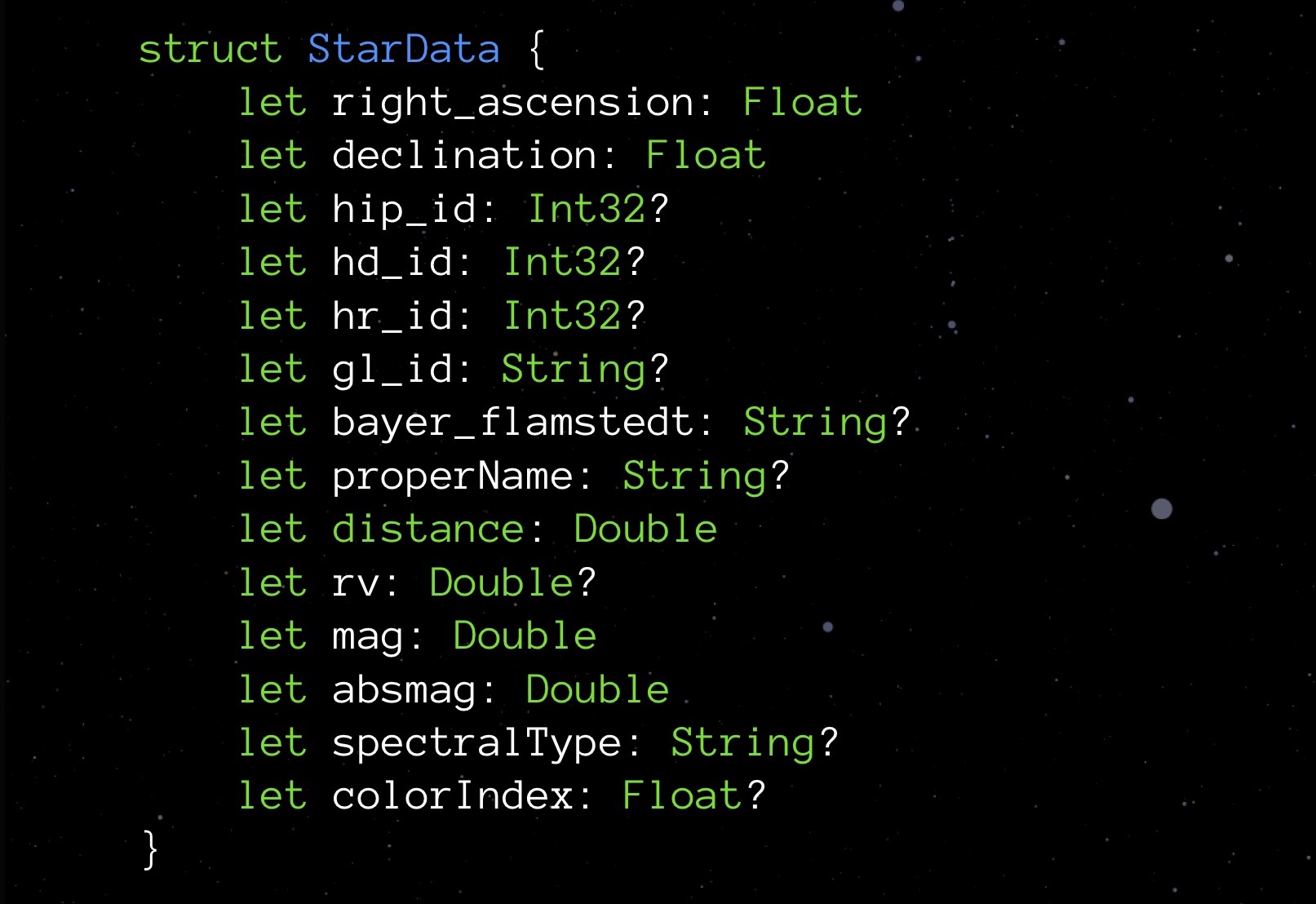
This is a data structure for storing data about a single star. You do not have to go into what each of these elements mean. It is more important now to pay attention to the types: Float variables that store the coordinates of the star (in fact, latitude and longitude), several Int32 for different IDs, String for storing names and names of various classifications; There is a distance, color and some other values needed to properly display a star.
Request the stride property:

At the moment our structure weighs 208 bytes. A million of these structures will require 250 MB - this, as you understand, is too much. Therefore, it is necessary to optimize.
Correct int
The fact that there are different types of Int, tell more on the first programming lessons. The most familiar Int to us in the Swift language is called Int8. It takes 8 bits (1 byte) and can store values from -128 to 127 inclusive. There are also other ints:
- Int16 size is 2 bytes, the range of values is from -32,768 to 32,767;
- Int32 size is 4 bytes, the range of values is from -2,147,483,648 to 2,147,483,647;
- Int64 (or simply Int) with a size of 8 bytes, the range of values is from -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807.
Probably those of you who have been doing web development and have dealt with SQL are already thinking about it. But yes, the first thing is to choose the optimal Int. I am in this project even before approaching the optimization of the mind, I started doing a bit of premature optimization (which, as I just said, you don’t need to do).
Let's look, for example, on fields with ID. We know that we will have about a million stars - not a few tens of thousands, but not a billion. It means that for such fields it is optimal to choose Int32. Then I realized that for Float, 4 bytes is enough. Double will take on 8, String on 24, we will add this all - 152 bytes turn out. If you remember, earlier MemoryLayout told us that 208. Why? We must dig deeper.
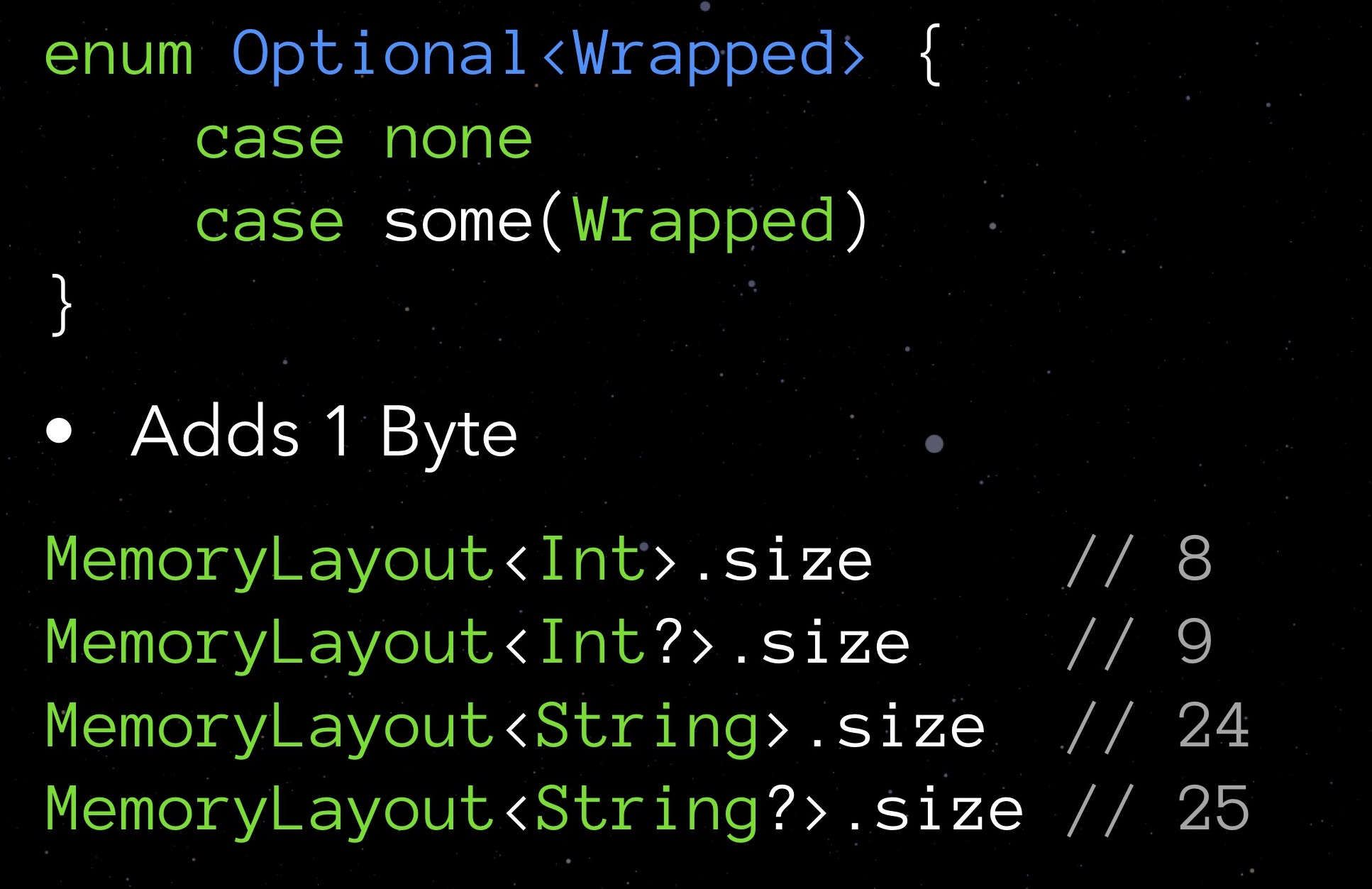
First, let's take a look at Optional. Optional types are distinguished by the fact that in the absence of an assigned value they store nil. This achieves security in conjunction with objects. But as you understand, such a measure does not cost for free: by requesting the size property of any optional type, you will see that such a type always takes one byte more. We pay for the opportunity to register for the nil field.
We would not want to spend an extra byte on a variable. At the same time, the idea embedded in optional, we really like. What to think up? Let's try to realize our structure.
Choose a value that is reasonably considered “invalid” for a given field, whichever is appropriate for the type claimed. For getHipId (Int32) this may be, for example, the value “-1”. It will mean that our field is not initialized. Here is such a bicycle optional, which can do without an extra byte on nil.
It is clear that with such a trick we have a potential vulnerability. To protect yourself from an error, we create a getter for the field that will independently manage our new logic and check the value of the field for validity.

Such a getter completely abstracts the complexity of the invented solution.
Turn to our StarData. Replace all optional types with ordinary ones and see what stride shows:
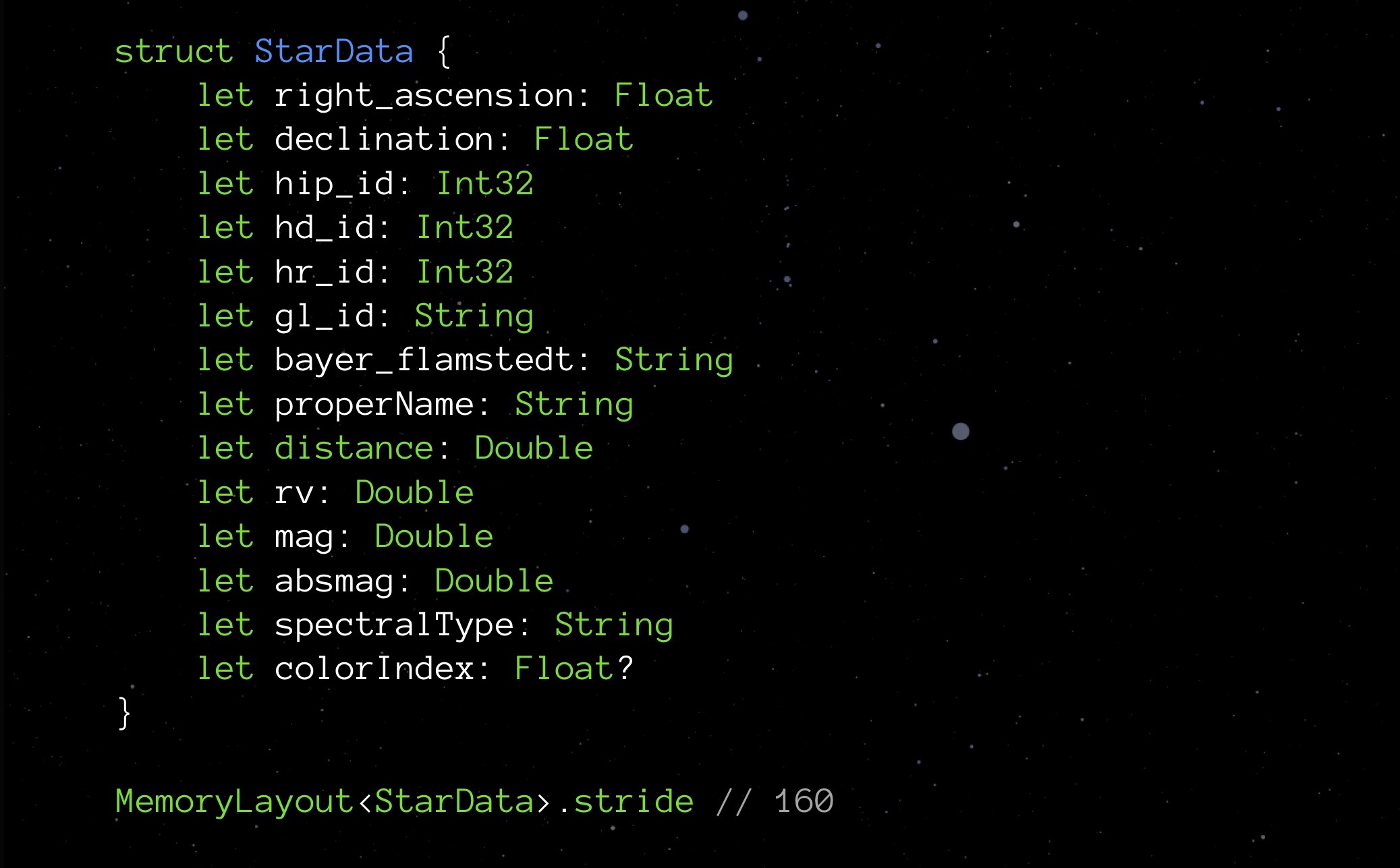
It turns out that by eliminating options, we did not save 9 bytes (one byte for each of the nine optionsals), but 48 as many. A pleasant surprise, but I would like to know why this happened. And this happened because of the alignment of data in memory.
Data alignment
Recall that before Swift we wrote on Objective-C, and it was repelled by C - and this situation also has its roots in C.
Putting any structures into memory, modern processors place their elements not in a continuous flow (not “shoulder to shoulder ”), and a grid that is inhomogeneously thinned by voids. This is the alignment of the data. It allows you to simplify and speed up access to the desired data elements in memory.
Data alignment rules are applied to each variable depending on its type:
- a char variable can begin on the 1st, 2nd, 3rd, 4th, etc. byte, since it alone takes only one byte;
- the short variable is 2 bytes, so it can start from the 2nd, 4th, 6th, 8th, etc. bytes (that is, from each even byte);
- a float variable takes 4 bytes, which means it can start from every 4th, 8th, 12th, 16th, etc. bytes (that is, from every fourth byte);
- Double and String variables occupy 8 bytes each, so they can start from 8th, 16th, 24th, 32nd, etc. byte;
- etc.
MemoryLayout <> objects have an alignment property that returns the corresponding alignment rule for the specified type.
Can we apply knowledge of alignment rules to optimize the code? Let's look at an example. There is a User structure: for firstName and lastName we use a regular String, for middleName - an optional String (the user may not have such a name). In memory, an instance of such a structure will be located as follows:

As you can see, since the middleName option takes up 25 bytes (instead of multiple 8 24 bytes), the alignment rules oblige to skip the 7 bytes that follow it and spend 80 bytes on the whole structure . Here, no matter how you rearrange blocks with lines, it is impossible to count on a smaller number of bytes.
And now an example of unsuccessful alignment:

The BadAligned structure first declares isHidden of type Bool (1 byte), then size of type Double (8 bytes), isInteractable of type bool (1 byte) and finally age of type Int (also 8 bytes). Declared in this order, our variables will be placed in memory in such a way that the total structure will take 32 bytes.
Let's try to change the order of the declaration of the fields - arrange them in ascending order of the occupied volume and see how the picture changes in memory.
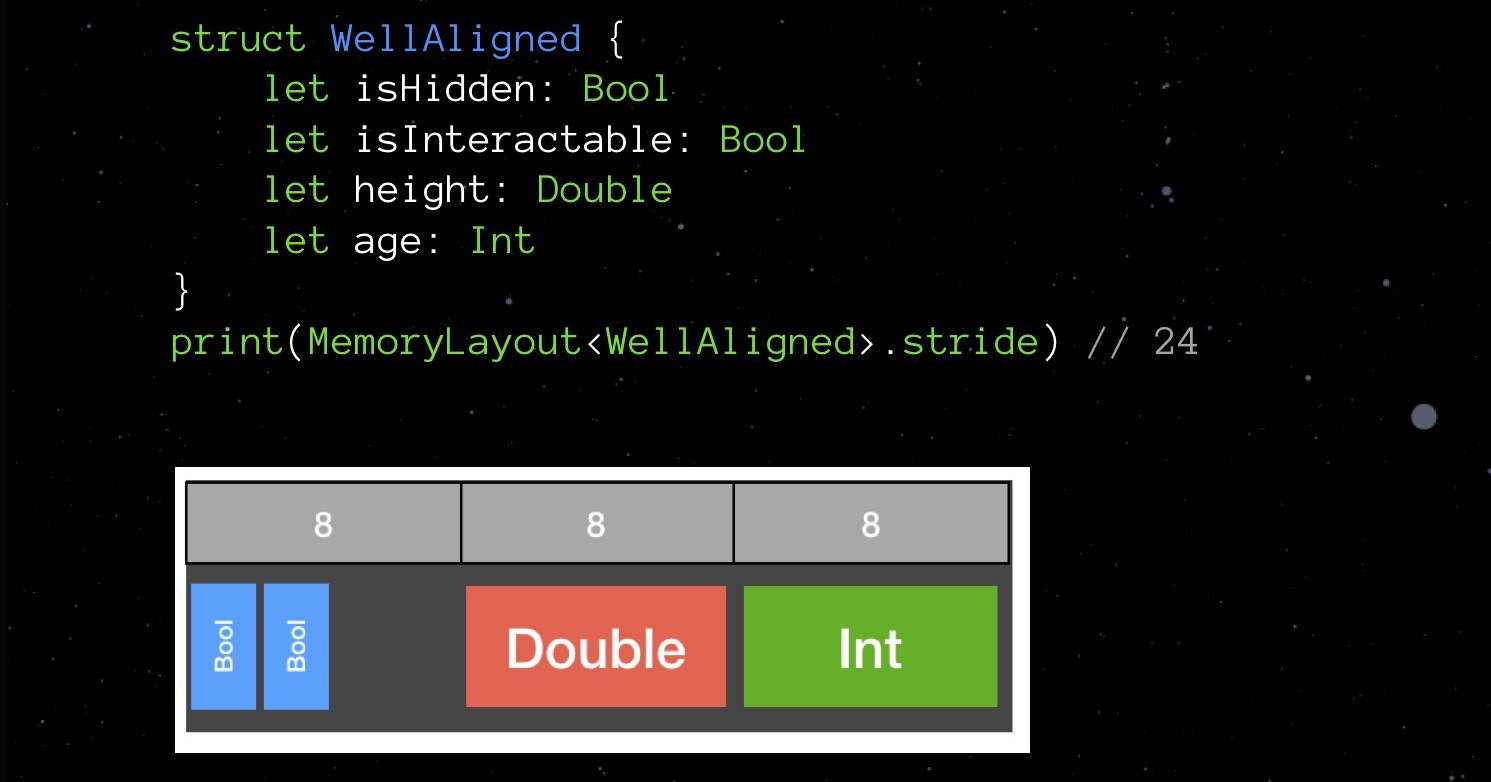
Our structure does not occupy 32 bytes, but 24. Savings by 25%.
Looks like a Tetris game, isn't it? Swift owes such low-level things to the C language - its ancestor. By declaring the fields in a large data structure out of focus, you are more likely to use more memory than you would, given the alignment rules. Therefore, try to remember them and take into account when writing code - this is not so difficult.
Turn again to our StarData. Let's try to arrange its fields in ascending order of occupied volume.
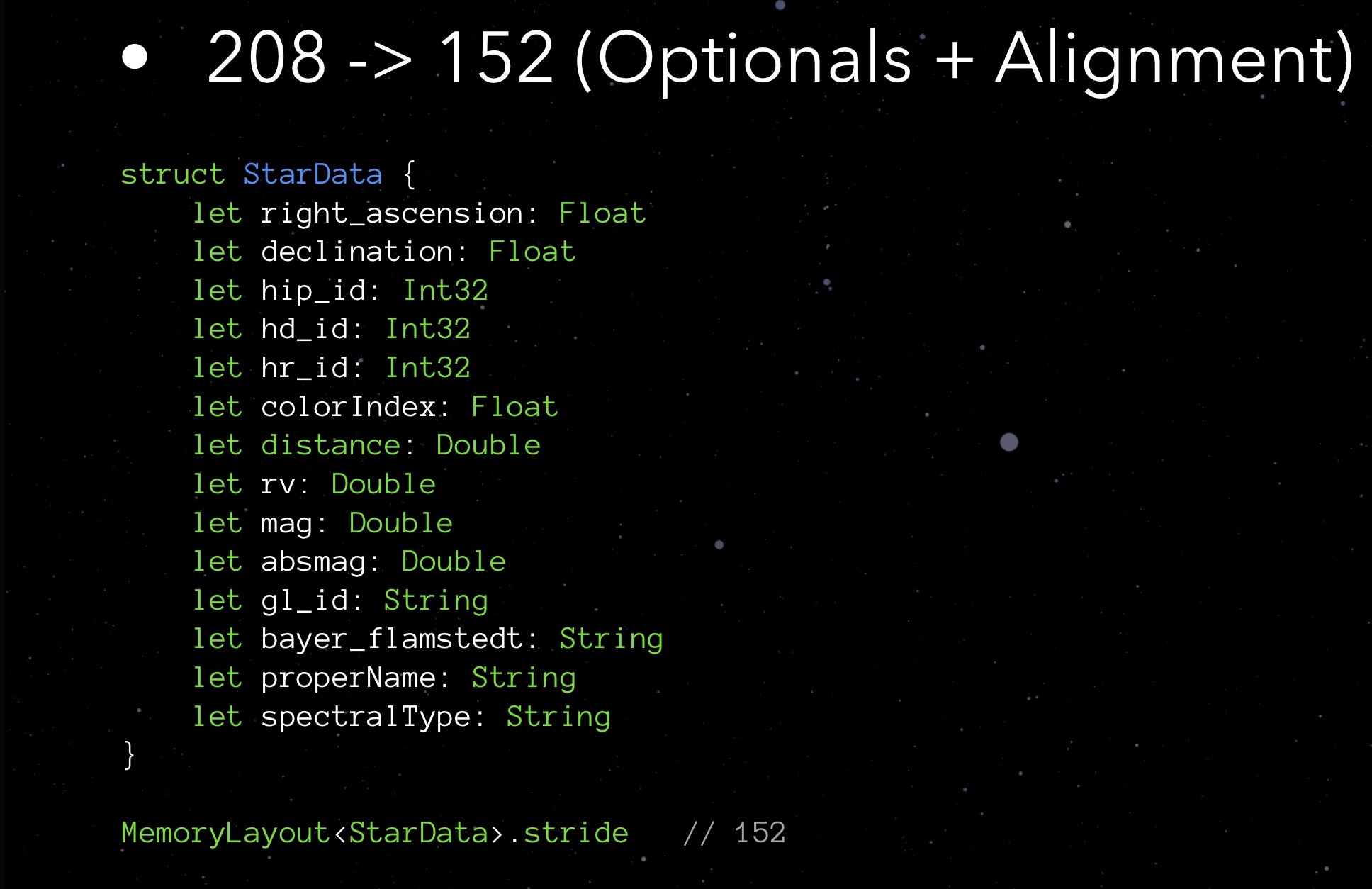
First Float and Int32, then Double and String. Not such an elaborate Tetris!
The stride we received is 152 bytes. That is, by optimizing the implementation of optionals and having worked with alignment, we managed to reduce the size of the structure from 208 to 152 bytes.
Are we approaching the limit of our optimization capabilities? Probably yes. However, there is something else that we have not tried - something more complicated by an order of magnitude, but sometimes capable of striking our results.
Domain Logic
Try to focus on what specificity is inherent in your service. Remember my example with chess: the idea of varying the FPS index, when nothing changes on the screen, is just optimization by taking into account the domain logic of the application.
Take another look at StarData. Our obvious bottleneck is String type fields, they really take up a lot of space. And here the specifics are as follows: during runtime, most of these lines remain empty! Only 146 stars have a “real” name, which is indicated in the properName field. And gl_id is the star ID in accordance with the Gliese catalog, which has 3801 stars, is also far from a million. bayer_flamstedt — the Flemsteed designations — will be assigned to 3064th stars. SpectralType spectral type - 4307-mi. It turns out that for the majority of stars, the entered string variables will be empty, while occupying 24 bytes each.
I came up with the next solution. Let's create as an additional structure an associative array. The key is a unique numeric identifier of the Int16 type, as a value, depending on the presence of a characteristic string, either its value or -1.
In our StarData, opposite the properName, gl_id, bayer_flamstedt and spectralType, we will prescribe the index corresponding to the key in the array. If it is necessary to get one or another characteristic string, we will request a value from the array using an index. There is no need to do this manually - we better implement a convenient, secure getter: The

getter is very important here - it hides the complexity of its own implementation from us. The array can be registered as private, now it is not necessary to know about its existence.
Of course, such a solution has a minus. Saving memory can not affect the CPU load. With this scheme, we are forced to constantly make calls to our associative array; in most cases, for nothing, since most of the lines will remain empty and queries will return “-1”.
Therefore, I had to slightly change the concept of the application. It was decided to provide the user with information about the star only when they click on this star - only then a query to the associative array will be executed and the data will be displayed on the screen.
Despite the abstraction by the getter, we must admit that the introduction of an associative array, we still significantly complicate the code. This is usually the case with optimization. Therefore, it is important to conduct high-quality unit-testing - to make sure that our associative array will not let us down at an unexpected moment.
Total: stride now gives us 64 bytes!
That's all? No, now we need to recall the alignment rules again: we rearrange Int16-type fields higher.

Now that's it. As you can see, with the help of a small number of simple methods, we managed to reduce the size of the StarData structure from 208 to 56 bytes. A million stars now occupy not 500 MB, but 130. Four times less!
Do not forget about the dangers of premature optimization. If your User data structure will be used for some 20 users, you won’t win there so much that there’s any point in doing this. It’s much more important that the next developer after you is comfortable supporting the code. Please do not say then "this dude at the conference said that the order should be exactly like that"! Do not do this just for fun. Well, for me such things are a good entertainment, I don’t know how for you.
Swift compiler optimization
Most programmers are well aware of the pain of a long (unbearably long) reassembly project. You just made a small change to the code, and here you are again sitting and waiting for the build to finish.
But the build process can tell you something about your code. This is an excellent indicator of bottlenecks, you only need to adapt it to work.
Personally, I researched compilation in Xcode. As a tool, I used the following command:

This command controls xCode to keep track of the compile time of each function and write it to the culprits.txt file. The file contents are in passing sorted.

Using my simple tool, I could observe interesting things. Some methods could be compiled for as long as 2 seconds, containing only three lines of code. What can cause?
For example, such a thing as output by the type compiler. If you do not specify the types explicitly, Swift is forced to detect them yourself. For this (I must say, non-trivial) operation requires CPU time, therefore, from the point of view of the compiler, it is always better to specify the type. Only by explicitly typing types, I once was able to reduce the build time of an application from 5 to 2 (!) Minutes.
But there is one “but”: code without types is still more readable. And we have already talked about priorities. Do not optimize ahead of time: at first, readability of the code will cost more.
Server option
So far, I have only mentioned my application with augmented reality. But based on a million stars, I also created a server application for Swift. You can see both it itself and its GitHub code . This is an API service that allows you to get information about any stars from my huge database. I was able to optimize it using the same methods that I used for the ARkit application. The result in this case was literally material for me: having reduced the volume to the 500 MB mark, I was able to place it on the free Bluemix server. As a result, my service costs me completely free of charge.
Summarizing
In conclusion, a brief summary of the main thoughts that I wanted to address to you today:
- Be careful about the choice of goals to fight. Optimization will always cost you the effort. You can work hard to ensure that your variables are evaluated only once during runtime, but is it worth it if each of these variables is requested only a couple of times in the code?
- Do not allow yourself to optimize if you do not have unit tests. Remember that each optimization step you must generously cover with existing unit tests. You must be sure that you have not made a mess and did not accidentally break the existing logic. Unit tests are needed not for a tick, but for your peace of mind.
- Pack structures compactly. If you still decide to optimize, then start with a harmless game with Tetris. The rule here is one, and it is simple: small variables - forward large ones.
- Work with the domain logic of your application. The most powerful optimization tool is skillful work with domain logic. Know the features of the work, the specifics of your application - try to take them into account, look for your "personal" solutions.
- RAM vs. CPU. Try your best to balance the use of memory and processor resources. This is always a great difficulty, but it is still possible to find some optimum in each specific case.
If you liked this report from the Mobius conference, please note that Mobius 2018 Moscow will take place on December 8-9 , where there will also be a lot of interesting things. From November 1, ticket prices increase, so it makes sense to make a decision now!