Pitfalls of backing up and restoring deduplicated data in a disaster recovery script

Developing the topic of backup and recovery on storage systems with a new architecture, we will consider the nuances of working with deduplicated data in the disaster recovery scenario, where storage systems with their own deduplication are protected, namely, how this effective storage technology can help or prevent data recovery.
A previous article is here: Pitfalls of backups in hybrid storage systems .
Introduction
Since deduplicated data takes up less disk space, it is logical to assume that backup and recovery should take less time. Indeed, why not back up / restore deduplicated data right away in compact deduplicated form? Indeed, in this case:
- Only unique data is placed in the backup.
- No need to re-duplicate (rehydrate) data on a productive system.
- No need to deduplicate data back to the IBS.
- Conversely, you can restore only those unique data that are necessary for reconstruction. Nothing extra.
But if you consider the situation more carefully, it turns out that not everything is so simple, the direct path is not always more effective. If only because general-purpose storage and backup storage use different deduplication.
General Purpose Deduplication
Deduplication, as a method of eliminating redundant data and increasing storage efficiency, has been and remains one of the key areas of development in the storage industry.

The principle of deduplication.
In the case of productive data, deduplication is intended not only and not so much to reduce disk space, but to increase the speed of access to data due to its denser placement on fast carriers. In addition, deduplicated data is convenient for caching.
One deduplicated block in the cache, at the top level of tiered storage, or simply located on a flash, can correspond to tens or even hundreds of identical user data blocks that used to occupy physical disk space and had completely different addresses, and therefore could not be efficiently cached.
Today, deduplication on general-purpose storage systems can be very effective and beneficial. For instance:
- On flash systems (All-Flash Array) you can put significantly more logical data than their "raw" capacity usually allows.
- With hybrid systems, deduplication helps highlight hot blocks of data because only unique data is saved. And the higher the deduplication, the more calls to the same blocks, and therefore - the higher the efficiency of tiered storage.

The effectiveness of solving the storage problem using a combination of deduplication and tiering. In each version, equal performance and capacity are achieved.
Deduplication in backup storage
Initially, deduplication is widespread in these systems. Due to the fact that the same type of data blocks are copied to the IBS dozens, or even hundreds of times, then due to the elimination of redundancy, significant space savings can be achieved. At one time, this led to an “attack” on tape systems of disk libraries for backup with deduplication. The disk is heavily crowded out because the cost of storing backups on disks has become very competitive.
The advantage of deduplicated backup to disks.
As a result, even tape lovers like Quantum began to develop deduplication disk libraries.
Which deduplication is better?
Thus, in the storage world at the moment there are two different ways of deduplication - in backup and in general-purpose systems. Different technologies are used in them - with a variable and a fixed block, respectively.

The difference between the two methods of deduplication.
Fixed-block deduplication is easier to implement. It is well suited for data that needs regular access, so it is more often used in general-purpose storage systems. Its main disadvantage is the lower ability to recognize the same data sequences in the general stream. That is, two identical flows with a slight bias will be perceived as completely different, and will not be deduplicated.
Variable block deduplication can better recognize repetitions in the data stream, but it requires more processor resources to do this. In addition, it is unsuitable for providing block or multi-threaded access to data. This is due to the structure of storing deduplicated information: in simple terms, it is also stored in variable blocks.
Both methods help to cope with their tasks perfectly, but with unusual tasks everything is much worse.
Let's look at the situation that arises at the junction of the interaction of these two technologies.
Deduplicated Data Backup Issues
The difference between both approaches in the absence of their coordinated interaction leads to the fact that if you back up with deduplication from a storage system that already stores deduplicated data, then the data is "duplicated" each time, and then deduplicated back to the backup system copying.
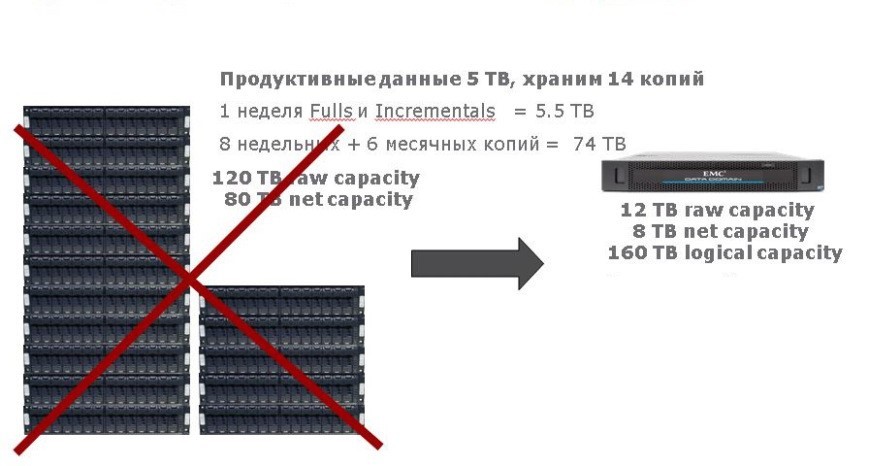
For example, 10 TB of productive deduplicated data is physically stored with a total factor of 5: 1. Then the following happens during the backup process:
- It is copied not 10, but completely 50 Tb.
- The productive system in which the source data is stored will have to do the work of rehydrating (“reducing”) the data in the opposite direction. At the same time, it must ensure the operation of productive applications and the flow of backup data. That is, three simultaneous heavy processes loading system I / O buses, cache memory and processor cores of both storage systems.
- The target backup system will have to deduplicate the data back.
From the point of view of the use of processor resources - this can be compared with the simultaneous pressing of gas and brake. The question arises - can this be somehow optimized?
The problem of restoring deduplicated data
When restoring data to volumes with deduplication enabled, you have to repeat the whole process in the opposite direction. By no means in all storage systems, this process works on the fly, and in many solutions the principle of "post process" is used. That is, the data is first written to physical disks (even if flash) as it is, then it is analyzed, data blocks are compared, duplicates are detected, and only then is it cleaned up.

Comparison of In-line and Post-Process Dedupe.
This means that in the storage system during the first pass, there may potentially not be enough space for a complete recovery of all undeduplicated data. And then you will have to do the restoration in several passes, each of which can take a lot of time, consisting of the recovery time and the deduplication time with the release of space on general-purpose storage systems.
This possible scenario relates not so much to recovering data from a backup (Data recovery) that minimizes the risks of the Data loss class, but rather to recovering from a catastrophically large data loss (which is classified as a disaster, i.e. Disaster). However, such a Disaster Recovery is not optimal to say the least.
In addition, in a catastrophic failure, it is not at all necessary to restore all data at once. It is enough to start only with the most necessary.
As a result, the backup, which is intended to be a means of last resort, which is addressed when nothing else has worked, does not work optimally in the case of general-purpose deduplicating storage systems.
Why then do you need a backup, from which in case of a disaster you can recover only with great difficulty, and almost certainly not completely? After all, there are replication tools built into a productive storage system (mirroring, snapshots) that do not have a significant impact on performance (for example, VNX Snapshots, XtremIO Snapshots). The answer to this question will be the same. However, any normal engineer would try to optimize and improve this situation somehow.
How to combine two worlds?
The old organization of working with data during backup and recovery looks, at least, strange. Therefore, there have been many attempts to optimize backup and restore deduplicated data, and a number of problems have been solved.
Here are just a few examples:
- Windows 2012 Deduplication with Networker
- Windows Server 2012 Deduplication and Backup Exec
- Backup and Restore Considerations for Deduplicated Volumes
- Backup and Restore of Data Deduplication-Enabled Volumes
But these are just “patches” at the level of operating systems and separate isolated servers. They do not solve problems at the general hardware level in storage where it is really difficult to do.
The fact is that general purpose storage systems and backup systems use different, specially developed deduplication algorithms - with fixed and variable blocks.
On the other hand, it is far from always required to do a full backup, and much less often a full recovery. It is not necessary to deduplicate and compress all productive data. Nevertheless, you need to remember the nuances. Because no one canceled the catastrophic data loss. And to prevent them, standard industrial solutions have been developed, which should be provided for under the regulations. So if you can’t restore data from a backup in normal time, then it can cost a career to responsible people.

Let's look at how to best prepare for such a situation and avoid unpleasant surprises.
Backup
- Use incremental backup and synthetic full copies whenever possible. In Networker, for example, this feature has been available since version 8.
- Make more time for a full backup, given the need for data rehydration. Choose the time of minimal disposal of system processors. During backups, it is better to observe the utilization of processors in a productive storage system. It is better that it does not exceed 70%, at least on average for the backup period.
- Use deduplication sensibly. If the data is not deduplicated and not compressed, then why waste processor power during the backup? If the system is always deduplicating, then it must be powerful enough to cope with all the work.
- Consider the processor power allocated for deduplication in storage. This function is found even in entry-level systems that do not always cope with the simultaneous execution of all tasks.
Full data recovery, Disaster Recovery
- Prepare a sane Disaster Recovery or Business Continuity Plan that takes into account deduplication storage system behavior. Many vendors, including EMC, as well as system integrators, offer similar planning services, because each organization has its own unique combination of factors that affect the application recovery process
- If a general-purpose storage system uses the post-process deduplication mechanism, then I would recommend providing a buffer of free capacity in it, in case of recovery from backup. For example, the buffer size can be taken as 20% of the logical capacity of the deduplicated data. Try to maintain this parameter at least on average.
- Look for opportunities to archive old data so that it does not interfere with fast recovery. Even if deduplication is good and effective, do not wait for a failure, after which you have to recover from a backup and completely deduplicate volumes of many tens of Tb. All non-operational / historical data should be transferred to an online archive (for example, based on Infoarchive).
- On-the-fly data deduplication in general-purpose storage is superior to post-process in terms of speed. It can play a special role in recovering from a catastrophic loss.
These are some of my considerations regarding backing up and restoring deduplicated data. I would be glad to hear here your feedback and opinions on this matter.
And, I must say that here one interesting particular case, which requires a separate consideration, has not yet been touched. So to be continued.
Denis Serov