Download and convert video on Rutube: from crutches to meta-programming
Like a theater with a hanger, video hosting starts with downloading and converting video. Therefore, in our second article, we decided to focus on these platform components. It is good that in ancient times there were no problems with the final format (no alternative flash in the browser), and the variety of sources was not the same as it is now - otherwise the first years of Rutube would have been even more fun.
But the remaining elements of the download and conversion system fully compensated for the temporary calm.

The problems began with the “physical” loading of the source through the uploader.
In 2009, nginx c nginx-upload-module served as the host, which supported the current version of the web server and could correctly give the file upload progress, but ... only within the framework of one machine. And since there were more than one machine (in fact, two), progress worked exactly every other time.
After downloading, the files were transferred to the NFS ball, and the corresponding clips in the database were marked with the status “ready for conversion”. The converter downloaded the file from NFS to a local folder, made something like 700k @ 360p in flv format from it, “rolled up” the iflv index from above and uploaded via SSH to the fileCluster server (more about what FileCluster can be found here )
With the increase in the number of videos, the converter scheduler began to have problems: organizing conversion queues on the statuses of the main site table (track) began to create transaction deadlocks and timeouts in large quantities.
Just at that moment, the Beanstalkd queue server appeared in the field of vision, and the idea arose of using it in the conversion system. In the new version of the uploader, upon completion of the download, the task was set in beanstalkd. The task was taken by one of the free workers, and, in close collaboration with the site’s database, he drove the video through video processing algorithms.
Meanwhile, life did not stand still and brought both new formats and viewing devices, and new types of source files. In 2011, the question arose of switching from RTMP to HDS, and, accordingly, from the original iflv format to mp4. A “deindexer” was added to the system, making iflv a normal “machine-readable” flv, which was then repacked to mp4.
The result of the change in the surrounding reality was a strong growth of the code base, engaged in circumventing theseschools of features.
The entire volume of crutches and logical branches soon ceased to fit into the head of the developer in the form of code, and was rewritten using meta-programming on graphs. Tumbler
Tells :
With the advent of multi-bitrate support, the conversion management system faced even greater difficulties: there was a need to process one clip on several servers at once, tricky conditions for choosing a list of qualities depending on the characteristics of the source file, logical problems with synchronization of parallel tasks in the absence of coordinating became noticeable center.
But these are still “flowers” in comparison with the calls received by the download and conversion system from the Licensing Department: support for various DRMs; custom settings for conversion parameters and priorities; re-conversion of existing videos, recording VOD from LIVE streams; loading files in professional formats such as mxf (accompanied by a file with a marking of logical pauses that must be deleted during conversion); sending conversion results not only to Rutube storage, but also to external archive servers; Add logos to the video stream. And the creative competition began season 8, and exquisite experiments in source formats continued.
It became clear that meta-programming couldn’t be saved anymore - more refactoring was needed!
At the moment, any administrative logic is cut out from the converter and it is directly involved in conversion. And the administration of the conversion processes is carried out by the DUCK service - Download, Upload, Convert King .

DUCK, at the request of different subsystems, creates sessions, sets tasks in celery, monitors the performance and load of servers, and most importantly, processes all events from tasks - mainly to track errors that occur. It turned out to be a separate service in general , which you can say: "Hey dude, take the file" here. " Make it "this" out of it and put it "here." How do you do, pull this “link.”
After receiving the task, the converter runs DUCK workers on the processing servers and "replaces" the empty bodies of the celery tasks with the processing code.
For example, the task code “duck.download” downloads via FTP / HTTP, monitors errors and timeouts. The code “duck.encode.images” creates screenshots from the source files.
All these tasks are wrapped in “chain” and “chord” from the “celery.canvas” module, and the base class “celery.Task” has acquired additional functionality: under certain conditions, the long chain can be skipped to the final part - “duck.cleanup "; this allows you to do without going through all the tasks of the chain, if, for example, at the stage of creating the video, it turned out that the file is broken.
On the other hand, all unknown errors automatically fall into the WTF queue. It is scooped up by the developers (usually there are not many such cases - but they are interesting): it either turns into bugs in the bug tracker, or the tasks are performed anew from the beginning of the chain (convenient, for example, if the server on which the file was processed “died”).
DUCK monitors the progress of tasks using celery "cameras": the conversion session changes the status in the database depending on the events that came to the "camera"; errors and progress of task processing are automatically processed. In this case, the most important events, such as registration of the fact that the processed file was successfully saved in FileHeap, are done through RPC: this way the files will not be lost for sure.
DUCK also stores conversion settings for different users. It can be like priority settings (for example, highlights from live sports broadcasts need to be made available for viewing immediately, and filling in the archive of past years can take place in the background for several weeks); as well as restrictions on the number of videos being processed and converted. In the settings, custom parameters for converting each of the qualities can be indicated (need 4K? - Welcome!); the need to trim the "black bars" (a common problem with the "television" source), normalize the sound and add a logo to the video stream, automatically "cut" unnecessary fragments.
Of course, we would like to wrap the possibilities of user editing with a frontend and make it accessible to everyone (we are doing this a bit within the framework of the Dashboard project), but so far the immediate goal is to significantly speed up the conversion. According to preliminary estimates - almost 10 times. We will tell you about the results!
But the remaining elements of the download and conversion system fully compensated for the temporary calm.
Childhood diseases
The problems began with the “physical” loading of the source through the uploader.
In 2009, nginx c nginx-upload-module served as the host, which supported the current version of the web server and could correctly give the file upload progress, but ... only within the framework of one machine. And since there were more than one machine (in fact, two), progress worked exactly every other time.
After downloading, the files were transferred to the NFS ball, and the corresponding clips in the database were marked with the status “ready for conversion”. The converter downloaded the file from NFS to a local folder, made something like 700k @ 360p in flv format from it, “rolled up” the iflv index from above and uploaded via SSH to the fileCluster server (more about what FileCluster can be found here )
Marginal notes: The first mistake was to rely on the nginx-upload-module progress in the memory of one process.
Even rewriting the uploader to Twisted, we did not get the desired stability - we had to spend a lot of time setting up hardware balancing so that progress would not fall off due to requests to another server. It would seem that sticky sessions solve the problem, but no - they tried it too - the question of load imbalance arises. Now the download progress is periodically thrown off in Redis and is available from any machine.
The clouds are gathering
With the increase in the number of videos, the converter scheduler began to have problems: organizing conversion queues on the statuses of the main site table (track) began to create transaction deadlocks and timeouts in large quantities.
Just at that moment, the Beanstalkd queue server appeared in the field of vision, and the idea arose of using it in the conversion system. In the new version of the uploader, upon completion of the download, the task was set in beanstalkd. The task was taken by one of the free workers, and, in close collaboration with the site’s database, he drove the video through video processing algorithms.
Marginal notes: Now we know that Beanstalkd is not the best choice for ensuring reliable processing of tasks. In addition to the binlog, it does not have backup and duplication tools, and the binlog itself is "with surprises."
For example, the simplest DOS in the case of a busy server can be organized by putting one (!) Task in a queue that no one will listen to. The binlog will begin to grow in this case until it takes up all available space, or until “That Task” is removed from the queue. Our record is 170GB. But they just managed to put the task in the Buried status into the “working” line — postponed forever. If the beanstalk “died”, it would hardly have risen with such a binlog.
Meanwhile, life did not stand still and brought both new formats and viewing devices, and new types of source files. In 2011, the question arose of switching from RTMP to HDS, and, accordingly, from the original iflv format to mp4. A “deindexer” was added to the system, making iflv a normal “machine-readable” flv, which was then repacked to mp4.
Marginal notes: UGC content is generally a ready-made set of tests: video without audio, audio with tumbnails and just “beaten” files.
If earlier originality was limited only to flash-clips a la "Masyanya" and PowerPoint presentations, now everything is much more fun. There are files in the metadata of which the offset of the audio relative to the video and the video relative to the audio were simultaneously indicated - and different!
There was a fashion to record, it’s okay, just a vertical video, and also change orientation many times during the shooting process, and then (pre) edit the unfortunate video file in incomplete shareware editors.
Tip: if this extreme is not enough for you, then become the organizer of a creative video contest.
The result of the change in the surrounding reality was a strong growth of the code base, engaged in circumventing these
Rescue Meta Programming
The entire volume of crutches and logical branches soon ceased to fit into the head of the developer in the form of code, and was rewritten using meta-programming on graphs. Tumbler
Tells :
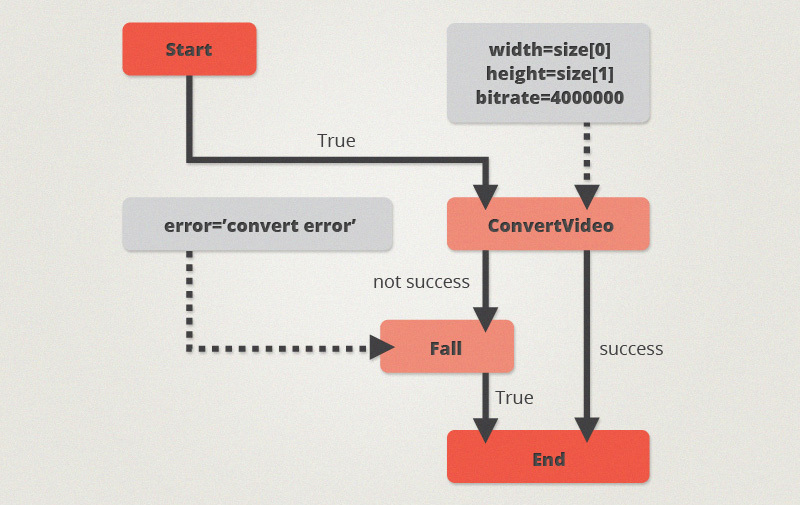
- In general, this was not even the case. At first, the entire file processing algorithm was manually drawn in the yed editor: just to understand and to simplify. The result is a large XML file, which is essentially a description of a directed graph with text data bound to vertices and edges.
Then the idea came up not to manually encode from the graph, but to generate a state machine in python, the result of which would be a set of side effects - video files and pictures. The vertices of the graph turned into the names of the called functions, the edges into conditional transitions.
Arguments of functions also fit neatly on the graph (at the vertices of a different kind).
Marginal notes: Unlike the code, the whole graph fit perfectly on two A4 sheets and was quite convenient for changing and analyzing. The only drawback that we have not yet overcome is the impossibility of conducting a review of changes to this graph using existing tools.
With the advent of multi-bitrate support, the conversion management system faced even greater difficulties: there was a need to process one clip on several servers at once, tricky conditions for choosing a list of qualities depending on the characteristics of the source file, logical problems with synchronization of parallel tasks in the absence of coordinating became noticeable center.
But these are still “flowers” in comparison with the calls received by the download and conversion system from the Licensing Department: support for various DRMs; custom settings for conversion parameters and priorities; re-conversion of existing videos, recording VOD from LIVE streams; loading files in professional formats such as mxf (accompanied by a file with a marking of logical pauses that must be deleted during conversion); sending conversion results not only to Rutube storage, but also to external archive servers; Add logos to the video stream. And the creative competition began season 8, and exquisite experiments in source formats continued.
It became clear that meta-programming couldn’t be saved anymore - more refactoring was needed!
Current architecture
At the moment, any administrative logic is cut out from the converter and it is directly involved in conversion. And the administration of the conversion processes is carried out by the DUCK service - Download, Upload, Convert King .
DUCK, at the request of different subsystems, creates sessions, sets tasks in celery, monitors the performance and load of servers, and most importantly, processes all events from tasks - mainly to track errors that occur. It turned out to be a separate service in general , which you can say: "Hey dude, take the file" here. " Make it "this" out of it and put it "here." How do you do, pull this “link.”
After receiving the task, the converter runs DUCK workers on the processing servers and "replaces" the empty bodies of the celery tasks with the processing code.
For example, the task code “duck.download” downloads via FTP / HTTP, monitors errors and timeouts. The code “duck.encode.images” creates screenshots from the source files.
All these tasks are wrapped in “chain” and “chord” from the “celery.canvas” module, and the base class “celery.Task” has acquired additional functionality: under certain conditions, the long chain can be skipped to the final part - “duck.cleanup "; this allows you to do without going through all the tasks of the chain, if, for example, at the stage of creating the video, it turned out that the file is broken.
On the other hand, all unknown errors automatically fall into the WTF queue. It is scooped up by the developers (usually there are not many such cases - but they are interesting): it either turns into bugs in the bug tracker, or the tasks are performed anew from the beginning of the chain (convenient, for example, if the server on which the file was processed “died”).
DUCK monitors the progress of tasks using celery "cameras": the conversion session changes the status in the database depending on the events that came to the "camera"; errors and progress of task processing are automatically processed. In this case, the most important events, such as registration of the fact that the processed file was successfully saved in FileHeap, are done through RPC: this way the files will not be lost for sure.
DUCK also stores conversion settings for different users. It can be like priority settings (for example, highlights from live sports broadcasts need to be made available for viewing immediately, and filling in the archive of past years can take place in the background for several weeks); as well as restrictions on the number of videos being processed and converted. In the settings, custom parameters for converting each of the qualities can be indicated (need 4K? - Welcome!); the need to trim the "black bars" (a common problem with the "television" source), normalize the sound and add a logo to the video stream, automatically "cut" unnecessary fragments.
Of course, we would like to wrap the possibilities of user editing with a frontend and make it accessible to everyone (we are doing this a bit within the framework of the Dashboard project), but so far the immediate goal is to significantly speed up the conversion. According to preliminary estimates - almost 10 times. We will tell you about the results!