Overview of HP Software Management and Monitoring Systems
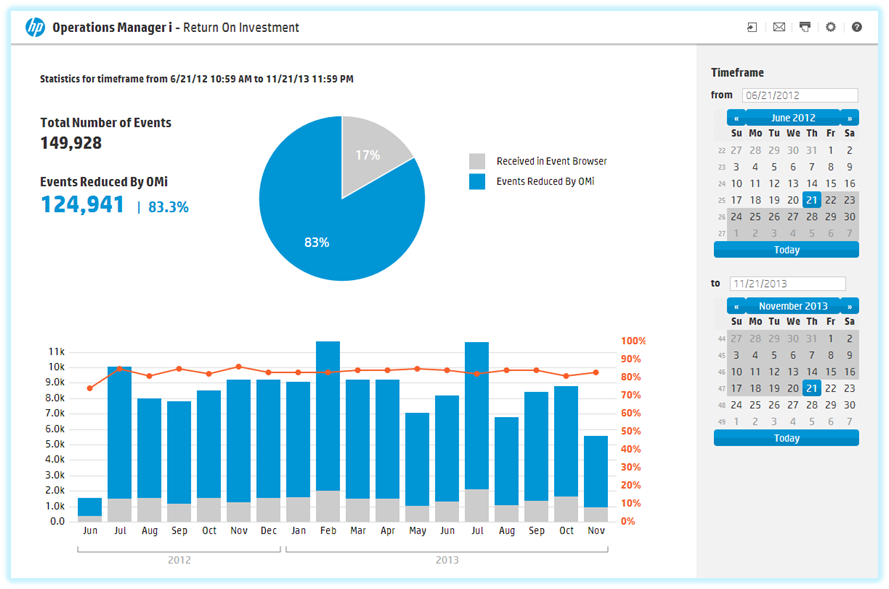
Management and monitoring of IT infrastructure is one of the main tasks of the IT department of any company. HP Software solutions will simplify the task of system administrators and organize effective control of the organization’s network.
Modern IT infrastructure is a complex heterogeneous network that includes telecommunication, server and software solutions from different manufacturers, working on the basis of various standards. Its complexity and scale determine the high level of automated monitoring and control tools that should be used to ensure reliable network operation. HP Software products will help to solve monitoring tasks at all levels, from infrastructure (network equipment, servers and storage systems) to quality control of business services and business processes.
Monitoring systems: what are they?
In modern platforms for monitoring IT, there are 3 directions for the development and taking monitoring to a new level. The first is called “Bridge” (“Umbrella System”, “Manager's Manager”). Its concept is to utilize investments in existing systems that perform the tasks of monitoring individual parts of the infrastructure, and turn the systems themselves into information agents. This approach is a logical development of routine monitoring of IT infrastructure. As a prerequisite for the implementation of a bridge system, the IT department may decide to consolidate disparate monitoring systems to switch to monitoring IT services / systems as a whole, disparate systems that are not able to show the whole picture, a case of not diagnosing a serious application failure, and a large number of warnings and alarms,
The result of the implementation will be an automated collection of all available events and metrics of IT infrastructure, a comparison of their status and impact on the "health" of the service. In the event of a failure, the operator will have access to a panel that displays the root cause of the failure with recommendations for resolving it. In the event of a typical failure, it is possible to assign a script that automates the necessary actions of the operator.
The next trend is called Anomaly Analytics. Here, as in the first case, metrics and events are collected from a number of infrastructure monitoring systems, and in addition, the collection of IT and security logs is configured. Thus, a huge amount of information is accumulated every minute, and the company wants to get the benefits of its disposal. There are a number of reasons for the implementation of Anomaly Analytics: the difficulty of collecting, storing and analyzing all the data in a timely manner, the need to reactively eliminate unknown problems, the inability to quickly identify information that is important for fixing failures, the difficulty of manually performing searches for individual logs, and the need to determine deviations and repeated failures.
The implementation of the system will allow for the automated collection of events, metrics and logs, the storage of this information for the necessary period of time, as well as the analysis of any information, including logs, performance information and system data. In addition, it will be possible to predict and resolve any type of problem and prevent known failures.
And finally, “Application Performance Management,” or identifying and resolving failures in end-user transactions. Such a solution can be a useful complement, working in close contact with the previous two. Moreover, such a system in itself can also give a quick result from implementation. In this case, the company has applications that are important for the business. At the same time, the availability and quality of the service are important, one of the key elements of which is the application (Internet banking, CRM, billing, etc.). With a decrease in the availability or quality of the provision of this service, as a rule, we are talking about proactivity and quick recovery. Such a system is usually implemented when it is necessary to increase the availability of application services and performance, as well as reduce the average recovery time. Moreover,
The implementation results may vary depending on the main task. In the general case, this allows the implementation of typical user actions by a “robot” from different regions / network segments, analysis of “mirrored” traffic, checking the availability and quality of services with identification of bottlenecks, informing the operator about the need to restore performance with an indication of the place of degradation. If necessary, it becomes possible to deeply diagnose the application to find the reasons for the systematic deterioration of services.
The above approaches can be implemented using HP Software products, which will be discussed later.
HP Bridge
HP Operations Bridge introduces the latest generation of "umbrella monitoring systems." The solution combines monitoring data from its own agents, various HP Software monitoring modules and monitoring tools from other developers. The flow of events from all sources of information is superimposed on the resource-service model, correlation mechanisms are applied to it to determine which events are the causes, symptoms and consequences.
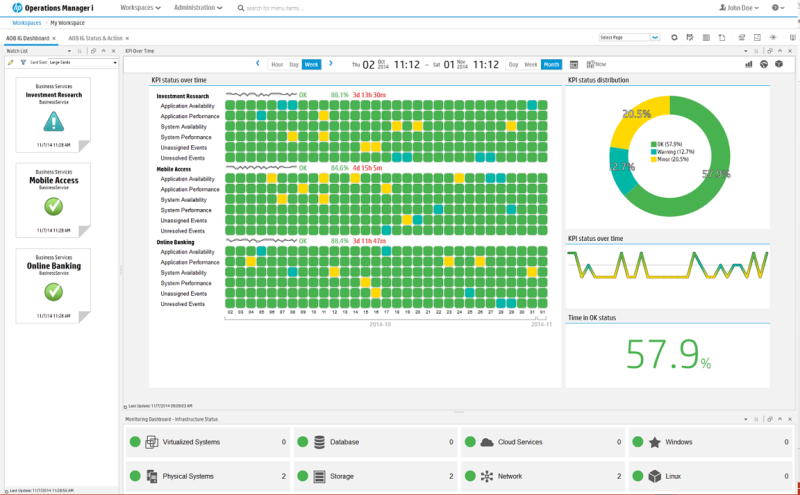
Separately, it is necessary to dwell on the resource-service model, and more precisely on the models, since such models can have an unlimited number for analyzing information from different angles. The possibility of a decision to correlate the flow of events depends on its completeness and relevance. To maintain the relevance of the models, intelligence tools based on agents and agentless technologies are used, which allow obtaining detailed information about the components of the service, the relationships between them and the mutual influence on each other. It is also possible to import data on the service topology from external sources - monitoring systems.
Another important aspect is ease of use. In complex and dynamically changing environments, it is important to adjust the monitoring system when changing the structure of systems and adding new services. Operations Bridge includes the Monitoring Automation component, which allows you to automatically configure the systems entered into the monitoring perimeter, which uses data on service-resource models. At the same time, the configuration and modification of previously performed monitoring settings is supported.
If earlier administrators could perform the same settings of the same infrastructure components (for example, metrics on Windows, Linux, or UNIX servers), which required considerable time and effort, now it is possible to dynamically and centrally configure threshold values for a metric in the context of a service or a service.
Application analytics
Using the traditional monitoring approach implies that it is initially known which parameters to monitor and which events to monitor. The growing complexity and dynamics of the development of IT infrastructures makes us look for other approaches, as it becomes increasingly difficult to control all aspects of the system.
HP Operations Analytics allows you to collect and save all the data about the application: log files, telemetry, business metrics and performance metrics, system events, etc., and use analytical mechanisms to identify trends and forecast. The solution brings the collected data to a single format and then, making a contextual selection, on the basis of the data of the log files displays on the timeline what, at what moment and on which system it happened. The product provides several forms of data visualization (for example, an interactive “heat map” and the topology of log file relationships) and uses the helper function in order to find the entire set of data collected for a specific period in the context of an event or by a query entered in the search bar. This helps the operator understand what caused the failure (or, when using HP SHA data together with HP OA data, make an appropriate forecast), and also identify both the culprit and the root cause of the failure. HP Operations Analytics provides an opportunity to reproduce the picture of the service and the environment at the time of a failure and isolate it in context and time.
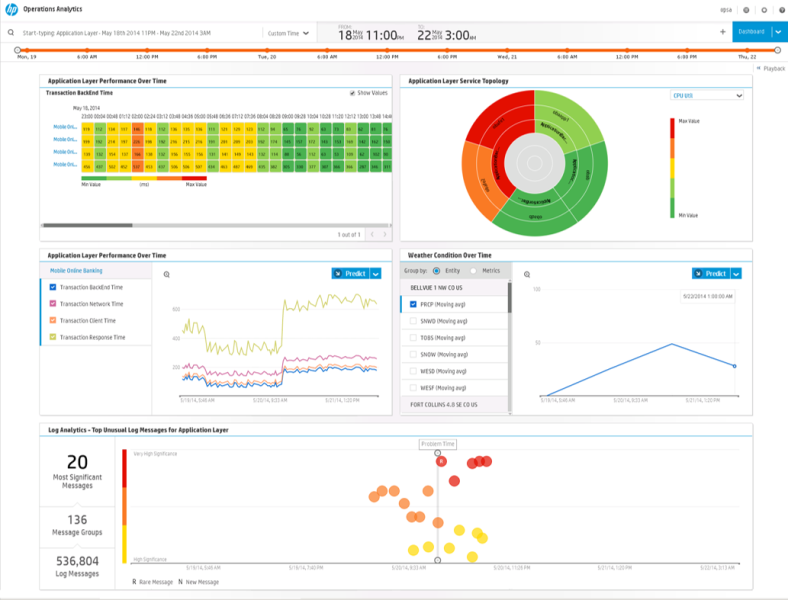
Another analytical tool is the HP Service Health Analyzer. HP SHA identifies abnormal behavior of controlled infrastructure elements in order to prevent a possible denial of services or violation of the specified parameters for their provision. The product uses special algorithms for statistical data analysis based on the topological service-resource model HP BSM. With their help, it is possible to build a profile of normal values of performance parameters collected both from software and hardware platforms and from other BSM modules (for example, HP RUM, HP BPM) characterizing the status of services. Typical parameter values are entered into such profiles taking into account the days of the week and time of day. SHA performs historical and statistical analysis of accumulated data (to understand the essence of the identified data),
Application Performance Monitoring
When it comes to application performance monitoring, the following components of the HP solution should be highlighted:
- HP Real User Monitoring (HP RUM) - control of the passage of transactions of real users;
- HP Business Process Monitoring (HP BPM) - control of application availability by emulating user actions;
- HP Diagnostics - control the flow of requests within the application.
HP RUM and HP BPM allow you to evaluate the availability of an application from an end-user perspective.
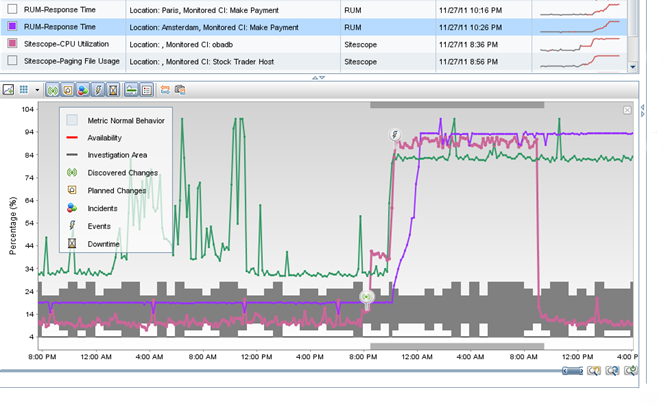
HP RUM parses network traffic, revealing in it the transactions of real users. At the same time, you can control the exchange of data between application components: the client part, the application server and the database. This makes it possible to track user activity, the processing time of various transactions, as well as determine the relationship between user actions and business metrics. Using HP RUM, monitoring service operators will be able to instantly receive prompt notifications of service availability issues and error information that users have encountered.
HP BPM is an active monitoring tool that performs synthetic user transactions that are indistinguishable from real systems for controlled systems. It is convenient to use HP BPM monitoring data for calculating a real SLA, since the "robot" performs identical checks at equal intervals of time, providing constant quality control of processing typical (or most critical) requests. By setting up samples to perform synthetic transactions from several points (for example, from different company offices), you can also evaluate the availability of the service for various users, taking into account their location and communication channels. To simulate activity, HP BPM uses the Virtual User Generator (VuGen) tool, which is also used in the popular HP LoadRunner stress testing product.
If the cause of the service crashes or slows down is within technologies such as Java, .NET, etc., HP Diagnostics will help.
The solution provides deep control of Java, .NET, Python on Windows, Linux and Unix platforms. The product supports a variety of application servers (Tomcat, Jboss, WebLogic, Oracle, etc.), MiddleWare and databases. HP Diagnostics specialized agents install on application servers and collect technology-specific data. For example, for a Java application, you can see what requests are being executed, what methods are being used, and how much time is being spent on them. The application structure is automatically drawn, it becomes clear how its components are involved. HP Diagnostics allows you to track the progress of business transactions within complex applications, identify bottlenecks and provide experts with the necessary information for decision-making.
Distribution of HP solutions in Ukraine , Georgia , Tajikistan , CIS countries .
Training courses on HP technologies in Kiev (UT MUK)
MUK-Service - all types of IT repair: warranty, non-warranty repair, sale of spare parts, contract service