About Duplicating Web Map Tiles
To organize the work of web maps using Slippy Map technology, it is necessary to organize a tile storage in which tiles can be pre-rendered (generated) in a predetermined map context, or a set of services can be used to generate tiles on demand, or some kind of symbiosis from the first two approaches.
The first approach has a drawback - it requires too much storage for tiles. So, according to OpenstreetMapas of March 2011, 54TB of storage space was required for tiles. According to my calculations for current data for June 2015, this figure is already about 100 TB (this is just an estimate, I did not dare to do a real experiment) for storing tiles of scales 0 ... 17. Such a “gain” in estimates is due to the fact that over the past time, the OpenStreetMap data has been substantially replenished, and areas that were empty in March 2011 were detailed. It is also impossible to write off non-optimal compression (in my case compared to OpenStreetMap) PNG format (I have an average tile size of 4.63KB against 633 bytesOpenStreetMap in March 2011), the complexity of the mapnik map drawing style and my other nuances. In any case, VERY much space is required for the tile storage, which not every server can afford. The situation is aggravated by the fact that for block file systems, small-sized tiles consume an entire block (a 103-byte tile can occupy an entire block, for example, 4KB), which leads to inefficient use of the physical space of the hard disk. For a large number of tiles (for large-scale maps) within one directory, there may still be a problem of the inability to store the required number of files or directories larger than the file system allows. But with all this, this campaign provides a comfortable time for executing the request for the return of the tile.
The second approach, although not demanding on the capacity of the tile server, but requires the organization and support of several services (PostgreSQL, Postgis, HStore, mapnik, renderd, mod_tile, apache) that would reliably generate and give the tile to the requested client service. You also need to periodically clean up the tile cache. In other words, the pay for the small capacity of the hard drive of the tile server is the complexity of the architecture and the significant time it takes to complete the request for the return of each specific tile (according to my calculations, up to 500ms for only 1 client, for a highly loaded service this time can grow to unacceptable values).
In this publication, I do not touch on the architecture of the tile server. Ultimately, it's up to you how you will build your own web-map service, starting from the hardware of your server. In the article I just want to pay attention to some features of the tile storage, knowing that you can optimally build your web map service.
By the way, I decided to build my web-map service based on a mixed approach. The fact is that the geography of user requests from my web service is quite clearly defined. Those. I know in advance the map context that users will request, which allows me to re-render tiles in this map context. In my case, the amount of required tiles was 511GB for scales of 3 ... 17. At the same time, for scales 3..13, I generated all the tiles without starting from the map context I knew before. I give statistics on the number and volume of generated tiles by map scale.
The very first thing I noticed when developing web maps (in addition to exorbitant capacities) is that the picture is often repeated. For example, in the ocean, two neighboring tiles look equally blue. But visually identical and binary identical tiles are two different things.
Testing my hypothesis, I compared the MD5 checksums of two neighboring tiles and they turned out to be the same.
Does this mean that all tiles are unique in the MD5 checksum? Of course not!
There is such a thing as collisions . Those. two visually (including binary) differing tiles can have the same checksum. There is such a risk, although it is small for files of arbitrary size. Since web cards are a resource, as a rule, that do not require absolute accuracy (unlike, for example, bank transactions or Forex quotes), we assume that the low probability of tile collisions is an acceptable risk that justifies ...
And for the sake of what, in fact, it is important for us to know that there are tiles that are identical in some hash functions? You probably already guessed. Why store several identical tiles, occupy a hard disk with them, if you can store only one file and some mapping of all duplicates to it (for example, using the banal symlink)?
So, the low probability of tile collisions is an acceptable risk, justifying a decrease in the requirements for the capacity of the tile storage. But how much will we benefit from removing all duplicates? According to my estimates, up to 70% of the tiles are duplicated. Moreover, the larger the scale, the larger this figure.
It should be noted that I was not the first to guess the elimination of duplication of tiles by hash function. So, Sputnik teamused this nuance for the optimal organization of the tile cache. Also, in the common MBtiles format, the problem of deduplication of tiles is solved.
Below in the table and in the figure I give statistics on the found duplicates (on MD5) of the tiles.
It should be borne in mind that:
Sooner or later, you will be faced with the question of choosing a file system. At first, you will use the file system that is already on your system. But when you encounter large amounts of data, encounter excessive duplication of tiles, run into problems with long file system responses during parallel requests, and the risks of failure of these disks, you will probably think about HOW to place a tile cache.
As a rule, tiles are small, which leads to inefficient use of disk space on block file systems, and a large number of tiles may very likely use up all the free number of i-nodes. If you reduce the block size to any small sizes, this will affect the maximum storage capacity, as any file system is usually limited by the maximum number of i-nodes. Even replacing duplicate tiles with symlinks, you will not be able to significantly reduce the required capacity of the tile storage. In part, the problem of non-filling of blocks can be solved with the help of metatailing mechanisms - several tiles (usually 8x8 or 16x16) are stored in a single file with a special header, which you can figure out which byte contains the required tile. But metatiles, unfortunately, reduce efforts to deduplicate tiles to nothing, because the likelihood of meeting two identical metatiles (in the aggregate N x N tiles) is significantly reduced, and the header format (the first 532 bytes with a meta file of 8 x 8 tiles) of the meta file involves writing the address of the meta file, which makes it unique and therefore eliminates the possibility of deduplication in principle. But nevertheless, today the use of meta-tyling allows you to "predict" a request for neighboring tiles, and therefore reduce the response time of a tile server.
In any case, for tile storage, a number of conditions must be met:
The file system that best meets the above requirements is ZFS. This file system does not have a fixed block size, eliminates duplication of files at the block level, implements a cache in the memory of frequently used files. At the same time, it does not have built-in support for Linux operating systems (due to incompatibility of the GPL and CDDL licenses) and creates an increased load on the processor and RAM (in comparison with traditional ExtFS, XFS, etc.), which is a consequence of its full control over physical and logical carriers.
The BtrFS file system is more Linux friendly, supports deduplication (offline), but still very raw for production systems.
There are other solutions to eliminate duplication of tiles and use disk space as efficiently as possible. Almost all of them come down to creating a virtual file system and connecting to it special services that allow you to access this virtual file system, deduplicate files on the fly, place and send them to / from the cache.
For example, UKSM, LessFS, NetApp, and many others, implement data deduplication at the service level. But on production, a heap of services is fraught with big problems, especially on high-load web services. Therefore, the choice of tile cache architecture for production should be super-fault tolerant and easy to administer.
Famous Satellite(yes, the developers mentioned above will forgive me - this project has become a kind of positive example for me on the basis of which I build my web-map service) implements its own deduplication algorithm, which also uses a certain hash function that allows deduplicating tiles, and the tiles themselves are stored in agile CouchBase.
I also tried to build something similar from the means to which I had confidence in the production. In this case, my choice fell on Redis. My experience has shown that when placing tiles in Redis's memory, it is possible to achieve a 30% reduction in the amount of occupied memory compared to placement in the file system. Do you think why use Redis? After all, he lives in RAM?
There are several reasons for this choice. First of all, reliability. Over the year at production, Redis has established itself as a very reliable and fast tool. Secondly, theoretically, a response from memory is faster than a response from a file system. Thirdly, the cost of RAM for servers has become relatively low, and the reliability of hard drives is not too much, it has improved in recent years. Those. intensive work of the server with a hard disk (as it happens when uploading tiles) greatly increases the risk of its failure. In addition, my organization has about 100 servers with 515GB of RAM each (but with small hard drives), which allows me to efficiently place tiles in my memory (if zxy is correctly proxied -> a specific server). One way or another, but my choice fell on Redis. I do not impose it on a respected reader.
This article had only one purpose - to talk about some undocumented nuances of web map services. Save your time and money at the expense of my, hopefully, not useless research work!
The first approach has a drawback - it requires too much storage for tiles. So, according to OpenstreetMapas of March 2011, 54TB of storage space was required for tiles. According to my calculations for current data for June 2015, this figure is already about 100 TB (this is just an estimate, I did not dare to do a real experiment) for storing tiles of scales 0 ... 17. Such a “gain” in estimates is due to the fact that over the past time, the OpenStreetMap data has been substantially replenished, and areas that were empty in March 2011 were detailed. It is also impossible to write off non-optimal compression (in my case compared to OpenStreetMap) PNG format (I have an average tile size of 4.63KB against 633 bytesOpenStreetMap in March 2011), the complexity of the mapnik map drawing style and my other nuances. In any case, VERY much space is required for the tile storage, which not every server can afford. The situation is aggravated by the fact that for block file systems, small-sized tiles consume an entire block (a 103-byte tile can occupy an entire block, for example, 4KB), which leads to inefficient use of the physical space of the hard disk. For a large number of tiles (for large-scale maps) within one directory, there may still be a problem of the inability to store the required number of files or directories larger than the file system allows. But with all this, this campaign provides a comfortable time for executing the request for the return of the tile.
The second approach, although not demanding on the capacity of the tile server, but requires the organization and support of several services (PostgreSQL, Postgis, HStore, mapnik, renderd, mod_tile, apache) that would reliably generate and give the tile to the requested client service. You also need to periodically clean up the tile cache. In other words, the pay for the small capacity of the hard drive of the tile server is the complexity of the architecture and the significant time it takes to complete the request for the return of each specific tile (according to my calculations, up to 500ms for only 1 client, for a highly loaded service this time can grow to unacceptable values).
In this publication, I do not touch on the architecture of the tile server. Ultimately, it's up to you how you will build your own web-map service, starting from the hardware of your server. In the article I just want to pay attention to some features of the tile storage, knowing that you can optimally build your web map service.
By the way, I decided to build my web-map service based on a mixed approach. The fact is that the geography of user requests from my web service is quite clearly defined. Those. I know in advance the map context that users will request, which allows me to re-render tiles in this map context. In my case, the amount of required tiles was 511GB for scales of 3 ... 17. At the same time, for scales 3..13, I generated all the tiles without starting from the map context I knew before. I give statistics on the number and volume of generated tiles by map scale.
| Scale | Total Tiles Generated | Total tiles for scale (4 ^ zoom) | Share in% of the total number of tiles | Volume of generated tiles | Total tiles for scale | Share in% of total tiles |
|---|---|---|---|---|---|---|
| 3 | 64 | 64 | 100 | 1.3M | 1.3M | 100 |
| 4 | 256 | 256 | 100 | 4.3M | 4.3M | 100 |
| 5 | 1,024 | 1,024 | 100 | 15M | 15M | 100 |
| 6 | 4,096 | 4,096 | 100 | 50M | 50M | 100 |
| 7 | 16 384 | 16 384 | 100 | 176M | 176M | 100 |
| 8 | 65,536 | 65,536 | 100 | 651M | 651M | 100 |
| 9 | 262 144 | 262 144 | 100 | 1.7G | 1.7G | 100 |
| 10 | 1,048,576 | 1,048,576 | 100 | 6.1G | 6.1G | 100 |
| eleven | 4 194 304 | 4 194 304 | 100 | 18G | 18G | 100 |
| 12 | 16 777 216 | 16 777 216 | 100 | 69g | 69g | 100 |
| thirteen | 67 108 864 | 67 108 864 | 100 | 272g | 272g | 100 |
| 14 | 279 938 | 268 435 456 | 0.10 | 3.2G | 1.1T | 0.29 |
| fifteen | 1 897 562 | 1,073,741,824 | 0.18 | 15G | 4.35T | 0.34 |
| 16 | 5 574 938 | 4,294,967,296 | 0.13 | 34G | 17.4T | 0.19 |
| 17 | 18 605 785 | 17 179 869 184 | 0.11 | 94g | 69.6T | 0.13 |
| Total | 115 842 662 | 366 503 875 925 | 0.51 | 511G | 92.8T | 0.51 |
Excessive duplication of tiles
The very first thing I noticed when developing web maps (in addition to exorbitant capacities) is that the picture is often repeated. For example, in the ocean, two neighboring tiles look equally blue. But visually identical and binary identical tiles are two different things.
Testing my hypothesis, I compared the MD5 checksums of two neighboring tiles and they turned out to be the same.
root@map:~# md5sum 10/0/0.png
a99c2d4593978bea709f6161a8e95c03 10/0/0.png
root@map:~# md5sum 10/0/1.png
a99c2d4593978bea709f6161a8e95c03 10/0/1.png
Does this mean that all tiles are unique in the MD5 checksum? Of course not!
There is such a thing as collisions . Those. two visually (including binary) differing tiles can have the same checksum. There is such a risk, although it is small for files of arbitrary size. Since web cards are a resource, as a rule, that do not require absolute accuracy (unlike, for example, bank transactions or Forex quotes), we assume that the low probability of tile collisions is an acceptable risk that justifies ...
And for the sake of what, in fact, it is important for us to know that there are tiles that are identical in some hash functions? You probably already guessed. Why store several identical tiles, occupy a hard disk with them, if you can store only one file and some mapping of all duplicates to it (for example, using the banal symlink)?
So, the low probability of tile collisions is an acceptable risk, justifying a decrease in the requirements for the capacity of the tile storage. But how much will we benefit from removing all duplicates? According to my estimates, up to 70% of the tiles are duplicated. Moreover, the larger the scale, the larger this figure.
It should be noted that I was not the first to guess the elimination of duplication of tiles by hash function. So, Sputnik teamused this nuance for the optimal organization of the tile cache. Also, in the common MBtiles format, the problem of deduplication of tiles is solved.
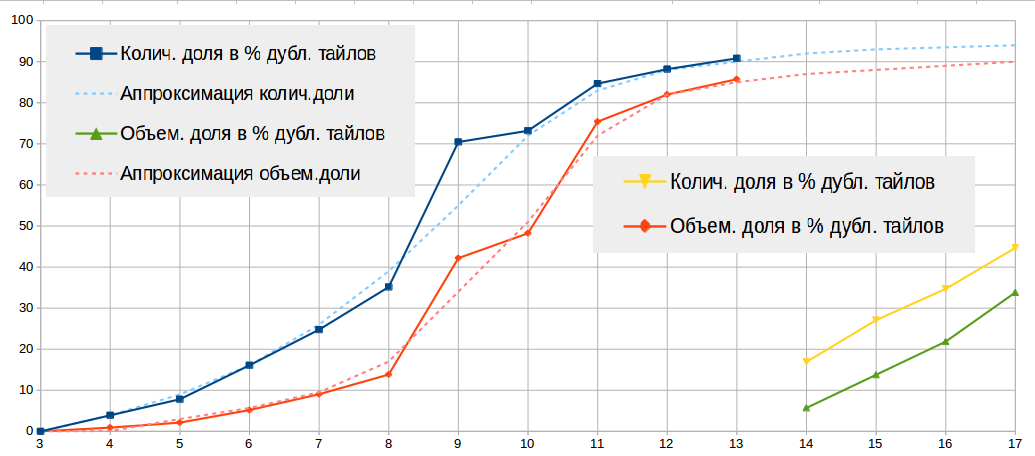
Below in the table and in the figure I give statistics on the found duplicates (on MD5) of the tiles.
| Scale | Total Gene. tiles | Total take. tiles | Kolich. share in% double. tiles | The volume of the gene. tiles | The amount of tiles after creating symlinks | Volume. share in% double. tiles |
|---|---|---|---|---|---|---|
| 3 | 64 | 0 | 0 | 1.3M | 1.3M | 0 |
| 4 | 256 | 10 | 3.91 | 4.3M | 4.2M | 0.92 |
| 5 | 1,024 | 80 | 7.81 | 14.6M | 14.3M | 2.13 |
| 6 | 4,096 | 659 | 09/16 | 49.7M | 47.1M | 5.18 |
| 7 | 16 384 | 4 058 | 24.77 | 175.4M | 159.6M | 9.04 |
| 8 | 65,536 | 23 031 | 35.14 | 650.3M | 560.3M | 13.83 |
| 9 | 262 144 | 184 668 | 70.45 | 1710M | 989M | 42.18 |
| 10 | 1,048,576 | 767 431 | 73.19 | 6.1G | 3.1G | 48.22 |
| eleven | 4 194 304 | 3,553,100 | 84.67 | 18G | 4.4G | 75.41 |
| 12 | 16 777 216 | 14 797 680 | 88.18 | 69g | 12.4G | 82.01 |
| thirteen | 67 108 864 | 60 945 750 | 90.82 | 271.1G | 38.7g | 85.74 |
| 14 | 279 938 | 47 307 | 16.9 | 3.2G | 185M | 5.71 |
| fifteen | 1 897 537 | 514 005 | 09/27 | 14.2G | 12.3G | 13.78 |
| 16 | 5 574 938 | 1 934 553 | 34.70 | 33.8g | 26.4G | 21.86 |
| 17 | 18 605 785 | 8 312 466 | 44.68 | 93.8G | 62G | 33.82 |
| Total edit | 115 842 662 | 91 084 800 | 78.63 | 511G | 164G | 07/32 |
It should be borne in mind that:
- I generated tiles in the context of large cities, which in itself worsens the duplication rate of tiles, because in large cities there are less chances to meet two identical tiles than in the sea. Therefore, data of scales 3 ... 13 show the degree of duplication of tiles over the entire globe, and data of scales 14 ... 17 show duplication only in the context of large cities.
- tiles of scales 3 ... 10 I generated with one mapnik style file, and tiles 11 ... 17 with another style file. Moreover, different rules for drawing styles work at different scales, which leads to heterogeneity in drawing tiles at different scales. This fact makes some noise in the statistics.
- As a rule, the so-called Empty Tiles are duplicated, having a size of only 103 bytes. Therefore, a significant reduction in the size of the tile storage should not be expected, which is shown by the data of scales 9..12. On average, with a duplication rate of tiles of 70%, it is possible to reduce the size of the scale directory to just 50%.
- in view of the randomness of choosing the original tile, the statistics on the scale are noisy, i.e. if the same tile occurs on the 10th and 12th scales, then taking the original tile of scale 10 as a duplicate will be considered a tile of scale 12, and vice versa. Depending on how the tile was classified, this will introduce noise into statistics of an appropriate scale. In this regard, there is some element of randomness in the table along the lines of scales. Absolute trust deserves only the line “Total”.
A few words about block file system issues
Sooner or later, you will be faced with the question of choosing a file system. At first, you will use the file system that is already on your system. But when you encounter large amounts of data, encounter excessive duplication of tiles, run into problems with long file system responses during parallel requests, and the risks of failure of these disks, you will probably think about HOW to place a tile cache.
As a rule, tiles are small, which leads to inefficient use of disk space on block file systems, and a large number of tiles may very likely use up all the free number of i-nodes. If you reduce the block size to any small sizes, this will affect the maximum storage capacity, as any file system is usually limited by the maximum number of i-nodes. Even replacing duplicate tiles with symlinks, you will not be able to significantly reduce the required capacity of the tile storage. In part, the problem of non-filling of blocks can be solved with the help of metatailing mechanisms - several tiles (usually 8x8 or 16x16) are stored in a single file with a special header, which you can figure out which byte contains the required tile. But metatiles, unfortunately, reduce efforts to deduplicate tiles to nothing, because the likelihood of meeting two identical metatiles (in the aggregate N x N tiles) is significantly reduced, and the header format (the first 532 bytes with a meta file of 8 x 8 tiles) of the meta file involves writing the address of the meta file, which makes it unique and therefore eliminates the possibility of deduplication in principle. But nevertheless, today the use of meta-tyling allows you to "predict" a request for neighboring tiles, and therefore reduce the response time of a tile server.
In any case, for tile storage, a number of conditions must be met:
- ensure efficient use of disk space, which can be achieved by reducing the block size of the block file system,
- provide support for a large number of files and directories
- provide the fastest possible return of tiles on request
- exclude duplication of tiles
The file system that best meets the above requirements is ZFS. This file system does not have a fixed block size, eliminates duplication of files at the block level, implements a cache in the memory of frequently used files. At the same time, it does not have built-in support for Linux operating systems (due to incompatibility of the GPL and CDDL licenses) and creates an increased load on the processor and RAM (in comparison with traditional ExtFS, XFS, etc.), which is a consequence of its full control over physical and logical carriers.
The BtrFS file system is more Linux friendly, supports deduplication (offline), but still very raw for production systems.
There are other solutions to eliminate duplication of tiles and use disk space as efficiently as possible. Almost all of them come down to creating a virtual file system and connecting to it special services that allow you to access this virtual file system, deduplicate files on the fly, place and send them to / from the cache.
For example, UKSM, LessFS, NetApp, and many others, implement data deduplication at the service level. But on production, a heap of services is fraught with big problems, especially on high-load web services. Therefore, the choice of tile cache architecture for production should be super-fault tolerant and easy to administer.
Famous Satellite(yes, the developers mentioned above will forgive me - this project has become a kind of positive example for me on the basis of which I build my web-map service) implements its own deduplication algorithm, which also uses a certain hash function that allows deduplicating tiles, and the tiles themselves are stored in agile CouchBase.
I also tried to build something similar from the means to which I had confidence in the production. In this case, my choice fell on Redis. My experience has shown that when placing tiles in Redis's memory, it is possible to achieve a 30% reduction in the amount of occupied memory compared to placement in the file system. Do you think why use Redis? After all, he lives in RAM?
There are several reasons for this choice. First of all, reliability. Over the year at production, Redis has established itself as a very reliable and fast tool. Secondly, theoretically, a response from memory is faster than a response from a file system. Thirdly, the cost of RAM for servers has become relatively low, and the reliability of hard drives is not too much, it has improved in recent years. Those. intensive work of the server with a hard disk (as it happens when uploading tiles) greatly increases the risk of its failure. In addition, my organization has about 100 servers with 515GB of RAM each (but with small hard drives), which allows me to efficiently place tiles in my memory (if zxy is correctly proxied -> a specific server). One way or another, but my choice fell on Redis. I do not impose it on a respected reader.
This article had only one purpose - to talk about some undocumented nuances of web map services. Save your time and money at the expense of my, hopefully, not useless research work!