Graph clustering and community search. Part 1: introduction, overview of tools and Hair Balls
Hello, Habr! In our work, there is often a need to highlight communities (clusters) of different objects: users, sites, product pages of online stores. The benefits of such information are very multifaceted - here are just a few areas of practical application of high-quality clusters:
 From the point of view of machine learning, getting these related groups looks like a typical clustering task. However, observational features are not always easily accessible to us, in the space of which it would be possible to search for clusters. Content or semantic features are rather laborious to obtain, as well as the integration of different data sources, where these features could be obtained from. But we have a DMP called Facetz.DCA , where on the surface are facts of user visits to pages. From them it is easy to get the number of visits to sites, both individually, and joint visits for each pair of sites. This information is already sufficient for graphing web domains or product pages. Now the clustering problem can be formulated as the task of isolating communities in the obtained graphs.
From the point of view of machine learning, getting these related groups looks like a typical clustering task. However, observational features are not always easily accessible to us, in the space of which it would be possible to search for clusters. Content or semantic features are rather laborious to obtain, as well as the integration of different data sources, where these features could be obtained from. But we have a DMP called Facetz.DCA , where on the surface are facts of user visits to pages. From them it is easy to get the number of visits to sites, both individually, and joint visits for each pair of sites. This information is already sufficient for graphing web domains or product pages. Now the clustering problem can be formulated as the task of isolating communities in the obtained graphs.
Looking ahead, I’ll say that we have already managed to use the web domain communities with great benefit in RTB advertising campaigns. A classic problem that traders face is the need to maneuver between targeting accuracy and segment volume. On the one hand, crude targeting by socio-demographic characteristics is too broad and ineffective. On the other hand, cunning thematic segments are often too narrow, and changes in the probability thresholds in the classifiers are not able to expand the segment to the required volume (say, up to several tens of millions of cookies). At the same time, people who frequently visit domains from the same cluster form good segments just for such wide-reaching campaigns.
In this series of posts I will try to focus more on the algorithmic side of the problem than on the business side, and do the following. First, describe our experiments and show the pictures that we have obtained. Secondly, to dwell on the methods in detail: what we applied / wanted to apply, but changed our minds / still want to apply in the future.
Many of you probably had to cluster the data, but probably most, like us, never clustered the graph. The main feature of graph clustering is the lack of features for observations. We do not have a distance between two arbitrary points in space, because there is no space itself, there is no norm, and it is impossible to determine the distance. Instead, we have edge metadata (ideally, for each pair of vertices). If there is a “weight” of the edge, then it can be interpreted as distance (or, on the contrary, as similarity), and then we have determined the distances for each pair of vertices.
Many of the clustering algorithms in Euclidean space are also suitable for graphs, since for these algorithms you only need to know the distance between observations, and not between arbitrary "points in space". Some require a feature space and are not suitable for graphs (for example, k-means). On the other hand, graphs have many of their unique properties that can also be used: connectivity components, local clusters of edges, places of looping information flows, etc.
To date, people have invented a huge number of graph clustering methods - each with its own advantages and jambs. In one of the following posts, we will examine in more detail some algorithms and their properties. In the meantime, we consider it useful to share links to open tools for analyzing graphs, where something has already been implemented for clustering and finding communities.
If the goal is to conduct a reproducible experiment on small data, rather than rolling out the finished product into production, then among all the above, the best options are, in our opinion, graph-tool (item 3), Gephi (item 4) or Infomap (item 9).
And now we will tell how we formed the graphs of the Runet domains and the environs, and show the pictures with the results of their clustering. In the next part of our series of articles, we will describe the algorithm by which the pictures below were obtained. These are modified k-medoids, which we wrote in the best traditions of cycling on the root python, and with the help of which we managed to surprisingly well solve some problems. Part of the information from this and the next post, as well as a description of some other algorithms, is in the presentation that I talked about on newprolab in digital october this spring:
The first task is the clustering of web domains. From DMP, we take data on users visiting different domains, and based on them we build a graph where the nodes are the domains and the edges are the affinity between the domains. Affinity (aka elevator) between the domains , and
, and  - a sample estimate of how events "Seen by the user
- a sample estimate of how events "Seen by the user  domain " and "Seen by the user domain " close to independence. If
domain " and "Seen by the user domain " close to independence. If  - the total number of users in question, and
- the total number of users in question, and  - the number of users who visited , then:
- the number of users who visited , then:

To get rid of noise, you need to filter out domains with too few visits, as well as edges with low affinity. Practice shows that a threshold of 15-20 for visits and 20-25 for affinity is enough. At a higher affinity threshold, too many isolated vertices appear as a result.
A similar way to build a graph allows you to see a fairly clear structure of the “communities” of domains in the data. One of its interesting features is that the largest domains (search engines, social networks, some large stores and news sites), as a rule, do not have very “thick” edges with no other vertex. This leads to the fact that these domains are marginalized and often remain isolated vertices without falling into any of the clusters. We consider this a plus, since a joint visit to vk.com and some highly specialized site really says little about their relationship with each other.
I must say that getting and filtering data, building a graph and calculating different matrices from it is a much more demanding task than getting the clusters themselves. Some stages (in particular, calculation of pairwise similarity) were managed to be parallelized using the pathos package ( pathos.multiprocessing ). Unlike the standard Python multiprocessing package, it does not experience serialization problems because it uses dill instead of pickle. The syntax is absolutely identical to standard multiprocessing. Here you can read about dill.
It's time to show some pictures with graphs (how they turned out, we will tell in the next part). It is known that networkX is not intended for graph visualization, and that for this purpose it is better to refer to d3.js, gephi, or graph-tool. We found out about this too late, and contrary to common sense, we still continued to courageously draw pictures in networkX. It turned out that it wasn’t that pure honey (in particular, it was not possible to configure mutual repulsion of nodes and overlapping labels), but we tried and squeezed as much as possible out of the capabilities of networkX. In all the pictures, the diameter of the circle (domain) corresponds to its attendance, the thickness of the rib corresponds to affinity, the color of the circle indicates the domain belongs to the cluster. The color of the edge means that both vertices belong to this cluster, the gray color corresponds to the edges,
A not-so-large graph of 1285 domains:

The sparse version is drawn in the picture: most of the edges are removed using the local sparsification method (it will be described in the next part), which makes grouping into communities more distinct, and the effect of the Big Hair Ball is softened ". There are only 18 clusters. Full size image (in png).
On each vertex is written the name of the domain and the number of the cluster to which it belongs. Pay attention to isolated vertices along the outer circle - these are usually large domains without strong connections with anyone. The lower part of the graph can be described as more “feminine” (or rather, “family”). It's pretty messy, probably because several family members viewed the page from the same browser (with one cookie) at different times. The algorithm did not do very well with the allocation of communities in this part of the graph.
One huge cluster at number 17 (pink) got a lot of things - from pregnancy sites below and medical sites in the center, to a mishmash of weather forecasts, women's forums and magazines at the top of the cluster. To the "southwest" from it is located the culinary cluster (number 4):
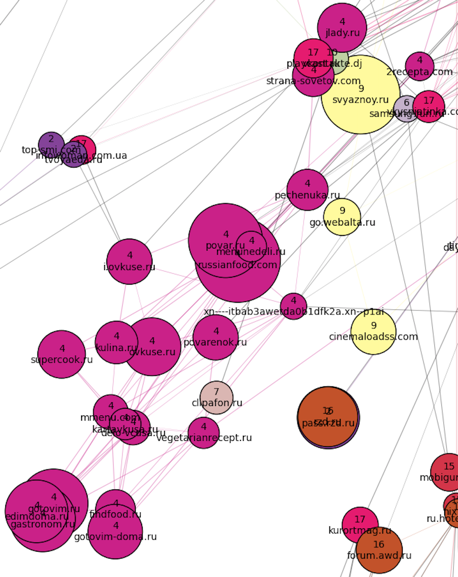
To the "southeast" of the family cluster is real estate + job search (combined into one cluster number 2):

To the "south" from cluster 17 there is a very poorly marked area. So, the algorithm failed to isolate the community of tourist domains (they are scattered across different communities), and the site about the weapon got into the culinary cluster.
The small cluster 15 (red) included mainly legal sites:

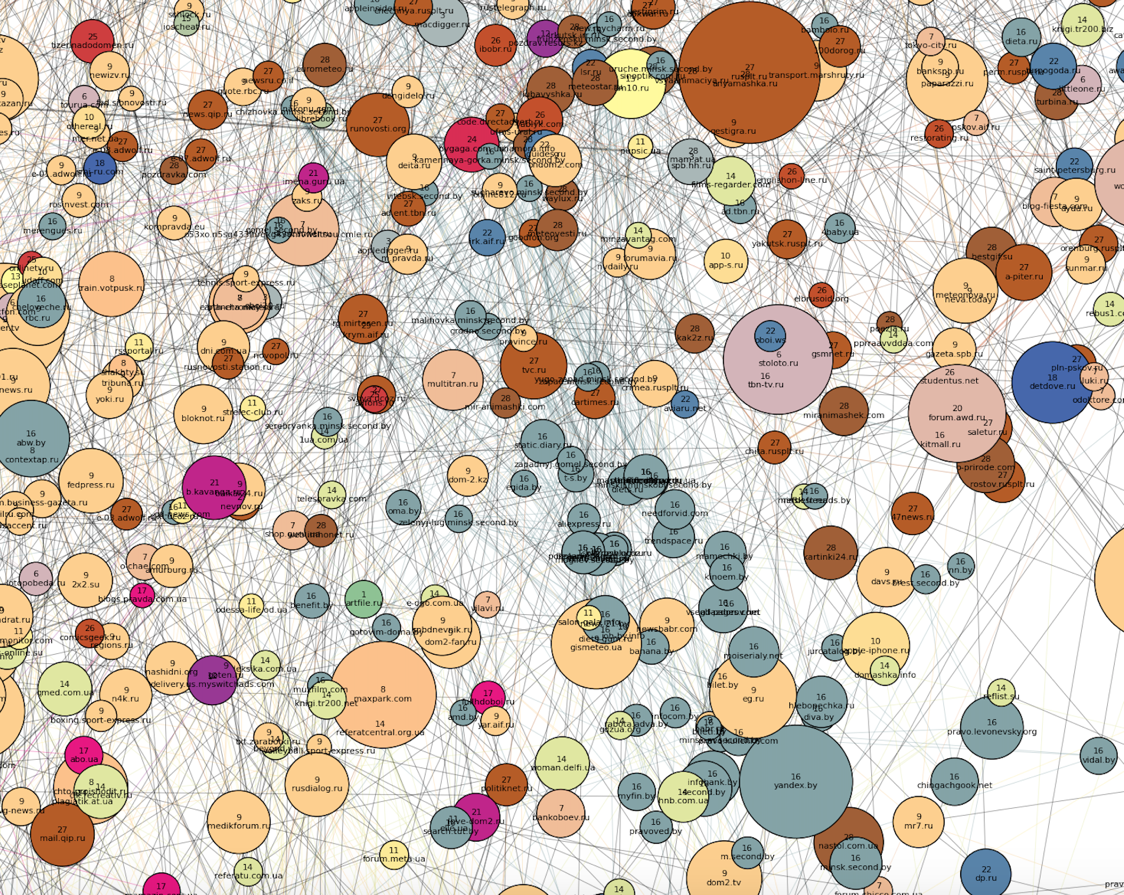
To the "northwest" of the "family" part are the most distinct clusters. Apparently, no one else uses the browsers of visitors to these sites (and this is logical, based on the topics of the clusters). Firstly, two dense clusters are striking: Russian (number 16, brick) and Ukrainian (number 12, blue) news sites, the latter being much denser, albeit smaller in size. You can also notice that the bias of sites along the Russian cluster is changing:
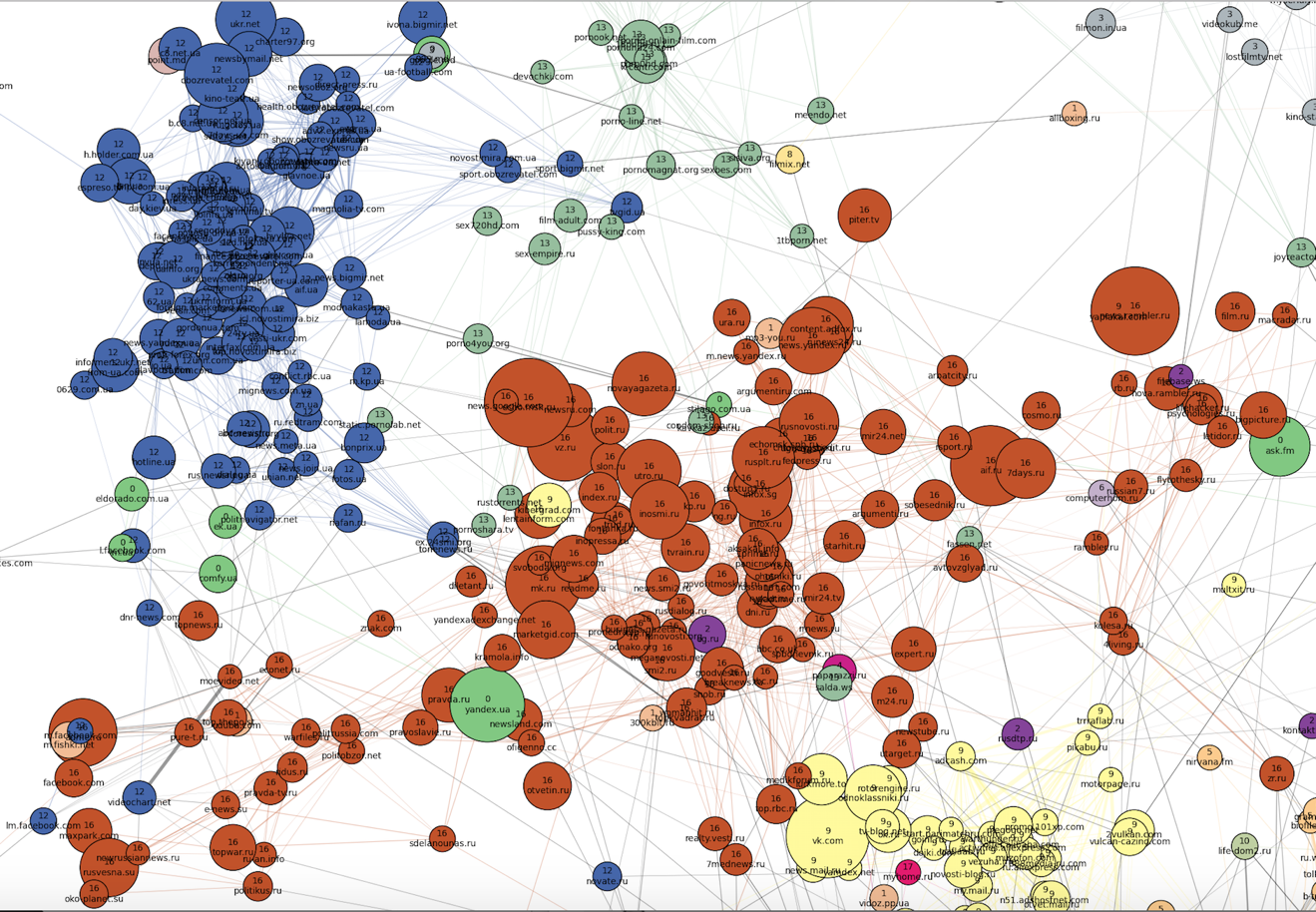
Movies, series and online cinemas (gray and yellow clusters numbered 3 and 8) are located to the "northeast" from the news sites. A cluster of pornography is located between the film clusters and the Ukrainian news cluster as a transition zone.

Closer to the east is cluster number 1 - the entire Kazakh Internet. Next to it are automobile sites (cluster 6, purple) and Russian sports sites (they joined other news in cluster 16).

Further south is a cluster of cartoons and children’s games (number 10, swamp), as well as closely related school clusters of dictionaries, online resolvers and essays: a large Russian (number 5, peach) and a very small Ukrainian (number 0, green) . Cluster number 0 also included Ukrainian sites of all subjects, except news (there were very few of them). School clusters in the "south" smoothly move into the main female cluster number 17.
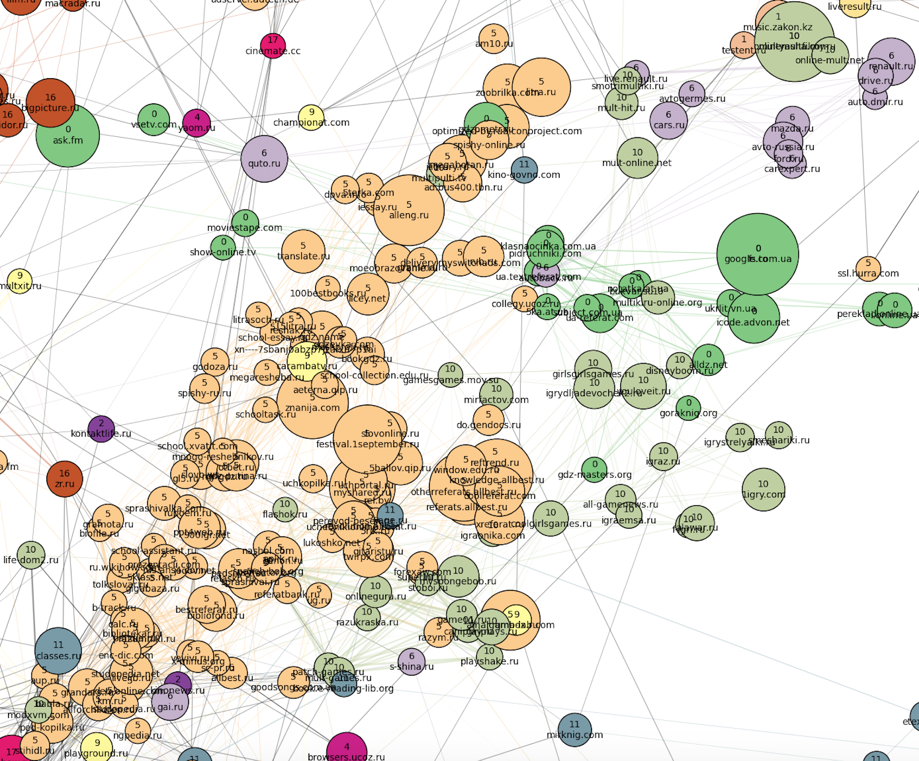
The last thing to note here is the cluster of books located on the outskirts in the "eastern" part of the picture:

Here is the same graph, only drawn without thinning:
Full size.
And here is an approximately similar graph constructed almost a year before the previous one. It has 12 clusters:
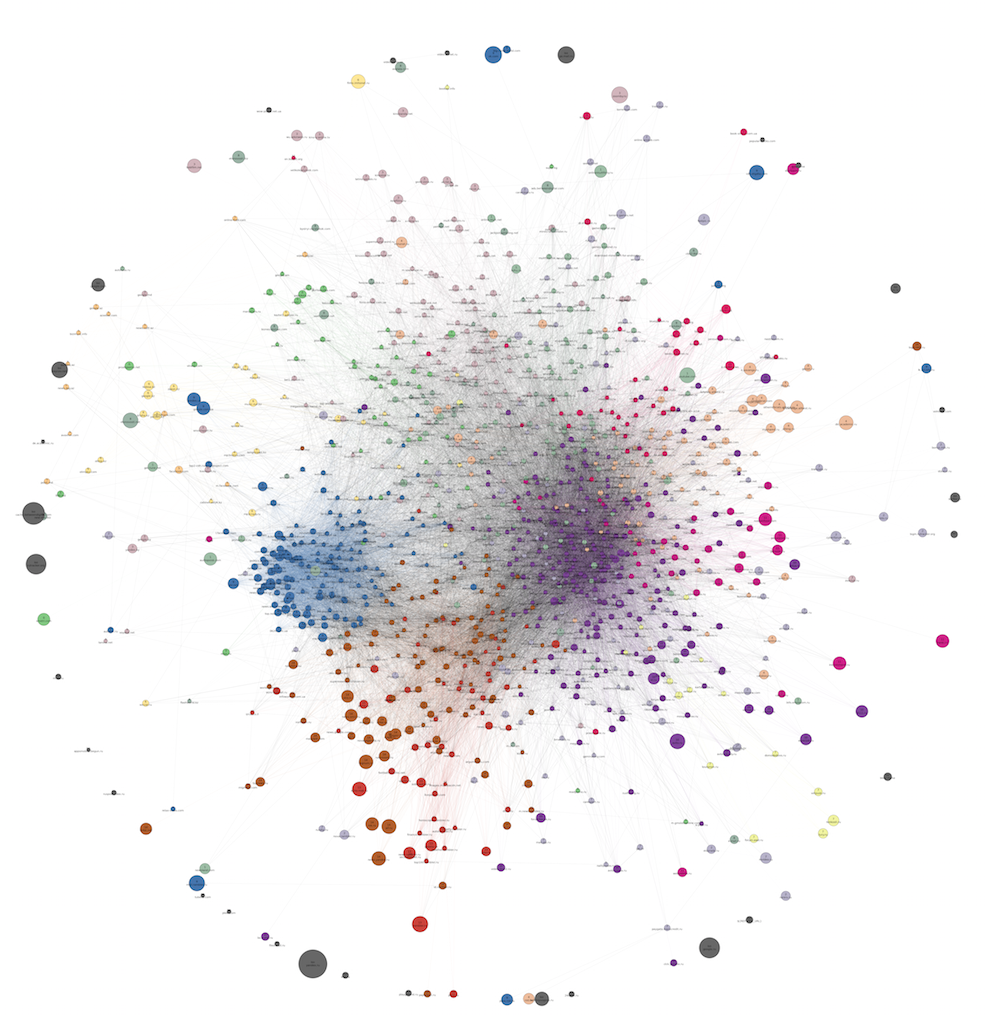
Full size.
As you can see, during this time, the structure as a whole remained the same (news sites, a large female cluster, a large sparse area of entertainment sites of different directions). Of the differences, the final disappearance of the cluster with music during this time can be noted. Probably, during this time, people almost stopped using specialized sites to find music, often turning to social networks and gaining momentum services like Spotify. The separability of the entire graph into communities as a whole has increased, and the number of meaningful clusters has been brought up from 12 to 18. The reasons for this, most likely, lie not in changing user behavior, but simply in changing our data sources and data collection mechanism.
If we increase the sample of users and keep the filters at the minimum number of visits to a domain and a pair of domains, as well as the minimum affinity for forming an edge, we will get a larger graph. Below is a graph of 10121 peaks and 30 clusters. As you can see, the power drawing algorithm from networkx no longer really copes and produces a rather confusing picture. Nevertheless, some patterns can be traced in this form. The number of edges has been reduced from one and a half million to 40,000 using the same local sparsification method. The PNG file occupies 80 MB, so please view the full size here.
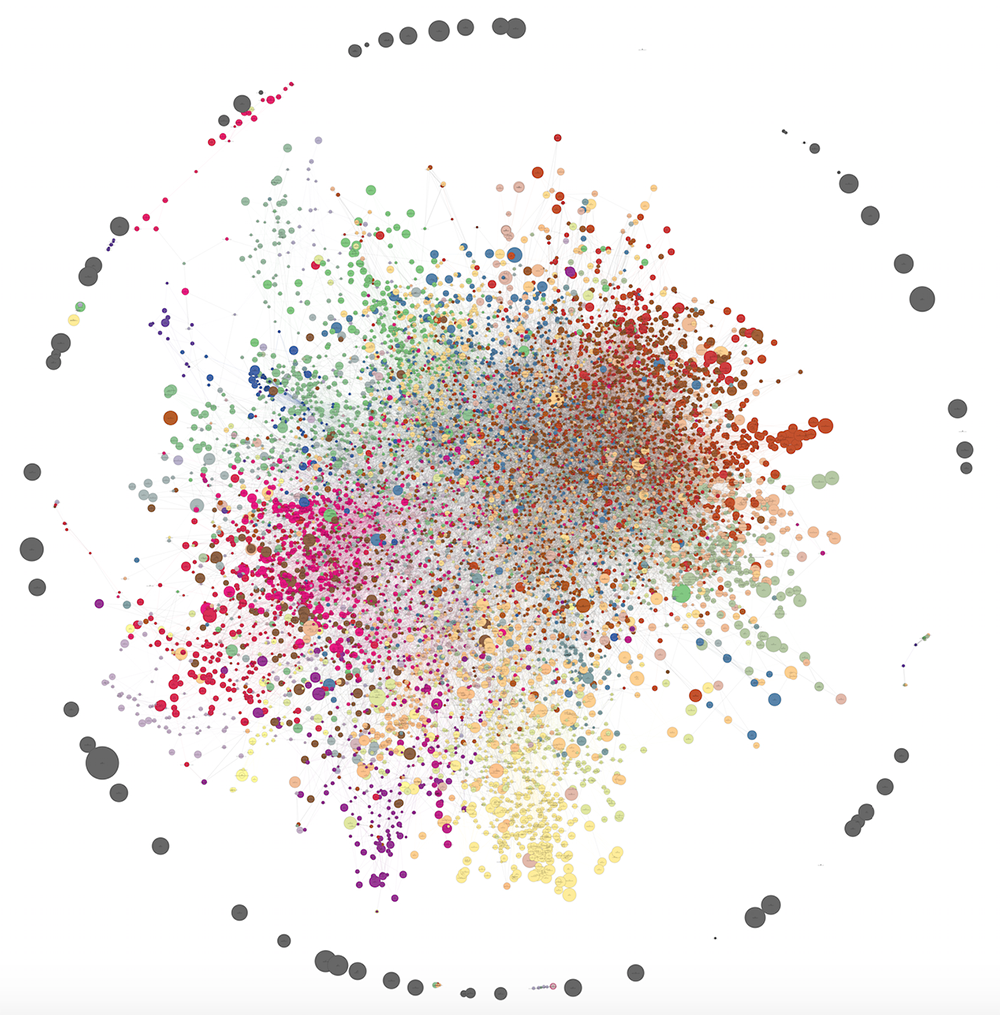
On visualization, it was not possible to properly distinguish the structure of communities (a hash in the center), but in reality the clusters turned out to be no less meaningful than in the case of 1285 domains.
With an increase in the amount of data, interesting patterns are observed. On the one hand, small peripheral clusters begin to stand out, which were indistinguishable on small data. On the other hand, what is poorly clustered on small data is poorly clustered on large data (for example, real estate and job search sites mix, esotericism and astrology often adjoin them).
Here are some examples of new communities. At the very outskirts, the Spanish cluster stood out, as we see something from there:

Not far from it, closer to the main cluster of points, is the Azerbaijani cluster (number 2) and the Georgian (number 4): an
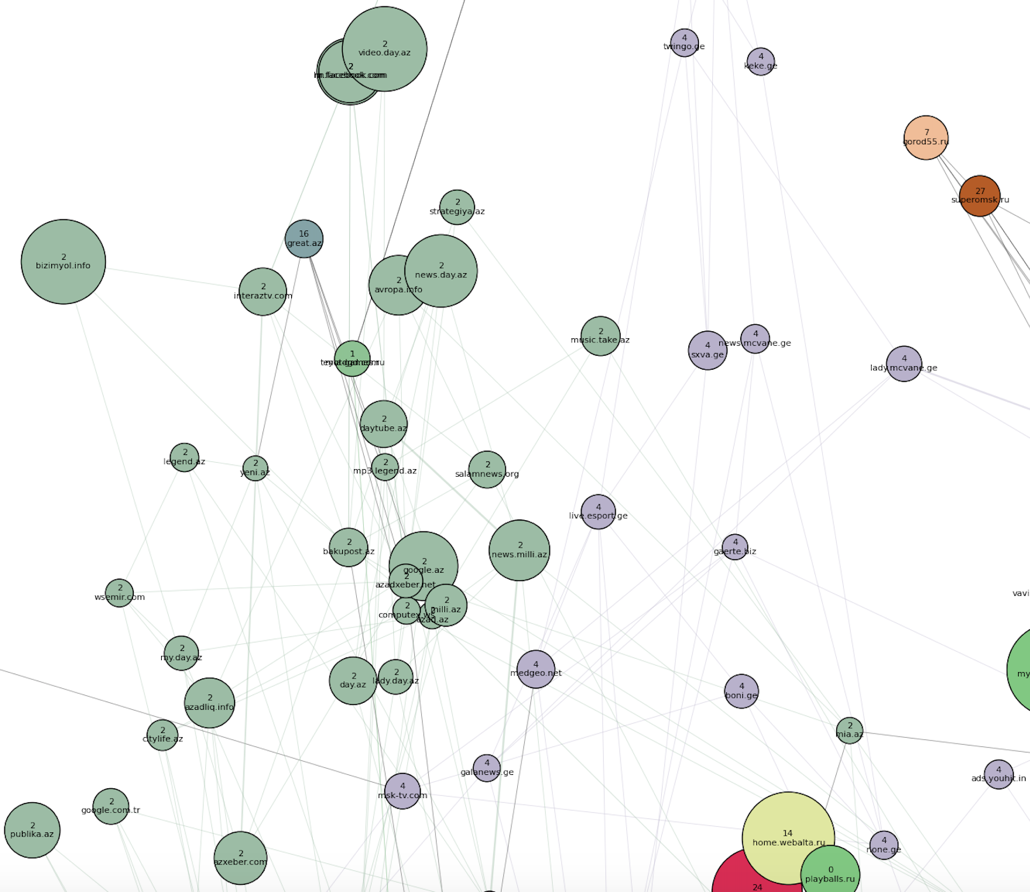
Uzbek-Tajik cluster has appeared, as well as a Belarusian (number 16) - inside the bulk of the domains, next to the “Russian news” and “Ukrainian non-news” communities:
In the next post there will be a description of the algorithm:
- how the clusters themselves were obtained so that the graph could be colored so;
- how to remove excess ribs.
Ready to answer your questions in the comments. Stay tuned!
- Allocation of user segments for targeted advertising campaigns.
- Using clusters as predictors (“features”) in personal recommendations (in content-based methods or as additional information in collaborative filtering).
- Dimension reduction in any machine learning task where the pages or domains visited by the user act as features.
- Comparison of product URLs between different online stores in order to identify among them groups corresponding to the same product.
- Compact visualization - it will be easier for a person to perceive the data structure.
From the point of view of machine learning, getting these related groups looks like a typical clustering task. However, observational features are not always easily accessible to us, in the space of which it would be possible to search for clusters. Content or semantic features are rather laborious to obtain, as well as the integration of different data sources, where these features could be obtained from. But we have a DMP called Facetz.DCA , where on the surface are facts of user visits to pages. From them it is easy to get the number of visits to sites, both individually, and joint visits for each pair of sites. This information is already sufficient for graphing web domains or product pages. Now the clustering problem can be formulated as the task of isolating communities in the obtained graphs.Looking ahead, I’ll say that we have already managed to use the web domain communities with great benefit in RTB advertising campaigns. A classic problem that traders face is the need to maneuver between targeting accuracy and segment volume. On the one hand, crude targeting by socio-demographic characteristics is too broad and ineffective. On the other hand, cunning thematic segments are often too narrow, and changes in the probability thresholds in the classifiers are not able to expand the segment to the required volume (say, up to several tens of millions of cookies). At the same time, people who frequently visit domains from the same cluster form good segments just for such wide-reaching campaigns.
In this series of posts I will try to focus more on the algorithmic side of the problem than on the business side, and do the following. First, describe our experiments and show the pictures that we have obtained. Secondly, to dwell on the methods in detail: what we applied / wanted to apply, but changed our minds / still want to apply in the future.
Many of you probably had to cluster the data, but probably most, like us, never clustered the graph. The main feature of graph clustering is the lack of features for observations. We do not have a distance between two arbitrary points in space, because there is no space itself, there is no norm, and it is impossible to determine the distance. Instead, we have edge metadata (ideally, for each pair of vertices). If there is a “weight” of the edge, then it can be interpreted as distance (or, on the contrary, as similarity), and then we have determined the distances for each pair of vertices.
Many of the clustering algorithms in Euclidean space are also suitable for graphs, since for these algorithms you only need to know the distance between observations, and not between arbitrary "points in space". Some require a feature space and are not suitable for graphs (for example, k-means). On the other hand, graphs have many of their unique properties that can also be used: connectivity components, local clusters of edges, places of looping information flows, etc.
Tools Overview
To date, people have invented a huge number of graph clustering methods - each with its own advantages and jambs. In one of the following posts, we will examine in more detail some algorithms and their properties. In the meantime, we consider it useful to share links to open tools for analyzing graphs, where something has already been implemented for clustering and finding communities.
- Very fashionable and developing now GraphX . It had to be written as the first element in the list, but as such there are no ready-made clustering algorithms there (version 1.4.1). There is a count of triangles and connected components, which, together with standard operations on Spark RDD, can be used to write your own algorithms. So far, GraphX has api only for scala, which can also complicate its use.
- A library for Apache Giraph called Okapi uses several algorithms, including a fairly new proprietary algorithm called Spinner , based on label propagation. Giraph is an add-on for Hadoop designed to handle graphs. It has almost no machine learning, and Okapi was created at Telefonica to compensate for this. Probably, now Giraph does not look so promising against the background of GraphX, but the Spinner algorithm itself fits well with the Spark paradigm. You can read about Spinner here .
- The graph-tool library for python contains some of the latest clustering algorithms and is very fast. We used it to compare URLs corresponding to the same product. All that is possible is parallelized over the processor cores, and for local computing (graphs up to a couple of hundred thousand nodes) this is the fastest option.
- Gephi is a well-known tool that we ignored, perhaps undeservedly. For a long time, Gephi practically did not develop, but it appeared to have good plugins, including for highlighting communities . Recently, the project has come back to life and version 0.9 is expected
- GraphLab Create . This is a python wrapper over C ++ that allows you to run machine learning both locally and distributed (in Yarn). Clustering graphs is still not there, only finding k-kernels .
- The vaunted networkX, despite the abundance of algorithms , does not know how to cluster graphs, but only analyze connected components and clicks. In addition, it is much slower than the graph-tool, and in terms of visualization it is inferior to the same graph-tool and gephi.
- Implementation of the Markov clustering algorithm (MCL) from its inventor. The author reduced the complexity of the usual MCL in the worst case from
to
, where
is the number of nodes, and
is the maximum degree of the node, and is offended when the MCL algorithm is called unscalable. He also added chips to adjust the number of clusters. However, the MCL had several other serious problems, and it is unclear whether they have been resolved. For example, the problem of cluster size instability (our small experiment produced one giant connected component and many small clusters of 2-3 nodes each, but perhaps we did not find the right handle). The latest news on the site dates back to 2012, which is not very good.
- Different implementations of one of the most popular Louvain algorithms: for C , for Python , and even for Python . A classic article about this algorithm: link .
- The site dedicated to the Infomap algorithm and its modifications, from the authors of the method. As elsewhere, there is open source. In addition to good support and documentation, there are amazing demos illustrating the operation of the algorithm: here it is . You can find out how the algorithm works here .
- A package for R called igraph . It implements quite a lot of clustering algorithms, but we cannot say anything specific about them, since we have not studied the package.
If the goal is to conduct a reproducible experiment on small data, rather than rolling out the finished product into production, then among all the above, the best options are, in our opinion, graph-tool (item 3), Gephi (item 4) or Infomap (item 9).
Our experiments
And now we will tell how we formed the graphs of the Runet domains and the environs, and show the pictures with the results of their clustering. In the next part of our series of articles, we will describe the algorithm by which the pictures below were obtained. These are modified k-medoids, which we wrote in the best traditions of cycling on the root python, and with the help of which we managed to surprisingly well solve some problems. Part of the information from this and the next post, as well as a description of some other algorithms, is in the presentation that I talked about on newprolab in digital october this spring:
Data
The first task is the clustering of web domains. From DMP, we take data on users visiting different domains, and based on them we build a graph where the nodes are the domains and the edges are the affinity between the domains. Affinity (aka elevator) between the domains
To get rid of noise, you need to filter out domains with too few visits, as well as edges with low affinity. Practice shows that a threshold of 15-20 for visits and 20-25 for affinity is enough. At a higher affinity threshold, too many isolated vertices appear as a result.
A similar way to build a graph allows you to see a fairly clear structure of the “communities” of domains in the data. One of its interesting features is that the largest domains (search engines, social networks, some large stores and news sites), as a rule, do not have very “thick” edges with no other vertex. This leads to the fact that these domains are marginalized and often remain isolated vertices without falling into any of the clusters. We consider this a plus, since a joint visit to vk.com and some highly specialized site really says little about their relationship with each other.
I must say that getting and filtering data, building a graph and calculating different matrices from it is a much more demanding task than getting the clusters themselves. Some stages (in particular, calculation of pairwise similarity) were managed to be parallelized using the pathos package ( pathos.multiprocessing ). Unlike the standard Python multiprocessing package, it does not experience serialization problems because it uses dill instead of pickle. The syntax is absolutely identical to standard multiprocessing. Here you can read about dill.
Visualization
It's time to show some pictures with graphs (how they turned out, we will tell in the next part). It is known that networkX is not intended for graph visualization, and that for this purpose it is better to refer to d3.js, gephi, or graph-tool. We found out about this too late, and contrary to common sense, we still continued to courageously draw pictures in networkX. It turned out that it wasn’t that pure honey (in particular, it was not possible to configure mutual repulsion of nodes and overlapping labels), but we tried and squeezed as much as possible out of the capabilities of networkX. In all the pictures, the diameter of the circle (domain) corresponds to its attendance, the thickness of the rib corresponds to affinity, the color of the circle indicates the domain belongs to the cluster. The color of the edge means that both vertices belong to this cluster, the gray color corresponds to the edges,
Comments on clusters as an example of one of the graphs
A not-so-large graph of 1285 domains:
The sparse version is drawn in the picture: most of the edges are removed using the local sparsification method (it will be described in the next part), which makes grouping into communities more distinct, and the effect of the Big Hair Ball is softened ". There are only 18 clusters. Full size image (in png).
On each vertex is written the name of the domain and the number of the cluster to which it belongs. Pay attention to isolated vertices along the outer circle - these are usually large domains without strong connections with anyone. The lower part of the graph can be described as more “feminine” (or rather, “family”). It's pretty messy, probably because several family members viewed the page from the same browser (with one cookie) at different times. The algorithm did not do very well with the allocation of communities in this part of the graph.
One huge cluster at number 17 (pink) got a lot of things - from pregnancy sites below and medical sites in the center, to a mishmash of weather forecasts, women's forums and magazines at the top of the cluster. To the "southwest" from it is located the culinary cluster (number 4):
To the "southeast" of the family cluster is real estate + job search (combined into one cluster number 2):
To the "south" from cluster 17 there is a very poorly marked area. So, the algorithm failed to isolate the community of tourist domains (they are scattered across different communities), and the site about the weapon got into the culinary cluster.
The small cluster 15 (red) included mainly legal sites:
To the "northwest" of the "family" part are the most distinct clusters. Apparently, no one else uses the browsers of visitors to these sites (and this is logical, based on the topics of the clusters). Firstly, two dense clusters are striking: Russian (number 16, brick) and Ukrainian (number 12, blue) news sites, the latter being much denser, albeit smaller in size. You can also notice that the bias of sites along the Russian cluster is changing:
Movies, series and online cinemas (gray and yellow clusters numbered 3 and 8) are located to the "northeast" from the news sites. A cluster of pornography is located between the film clusters and the Ukrainian news cluster as a transition zone.
Closer to the east is cluster number 1 - the entire Kazakh Internet. Next to it are automobile sites (cluster 6, purple) and Russian sports sites (they joined other news in cluster 16).
Further south is a cluster of cartoons and children’s games (number 10, swamp), as well as closely related school clusters of dictionaries, online resolvers and essays: a large Russian (number 5, peach) and a very small Ukrainian (number 0, green) . Cluster number 0 also included Ukrainian sites of all subjects, except news (there were very few of them). School clusters in the "south" smoothly move into the main female cluster number 17.
The last thing to note here is the cluster of books located on the outskirts in the "eastern" part of the picture:
Yearly changes
Here is the same graph, only drawn without thinning:
Full size.
And here is an approximately similar graph constructed almost a year before the previous one. It has 12 clusters:
Full size.
As you can see, during this time, the structure as a whole remained the same (news sites, a large female cluster, a large sparse area of entertainment sites of different directions). Of the differences, the final disappearance of the cluster with music during this time can be noted. Probably, during this time, people almost stopped using specialized sites to find music, often turning to social networks and gaining momentum services like Spotify. The separability of the entire graph into communities as a whole has increased, and the number of meaningful clusters has been brought up from 12 to 18. The reasons for this, most likely, lie not in changing user behavior, but simply in changing our data sources and data collection mechanism.
If we increase the sample of users and keep the filters at the minimum number of visits to a domain and a pair of domains, as well as the minimum affinity for forming an edge, we will get a larger graph. Below is a graph of 10121 peaks and 30 clusters. As you can see, the power drawing algorithm from networkx no longer really copes and produces a rather confusing picture. Nevertheless, some patterns can be traced in this form. The number of edges has been reduced from one and a half million to 40,000 using the same local sparsification method. The PNG file occupies 80 MB, so please view the full size here.
{kind=link}
On visualization, it was not possible to properly distinguish the structure of communities (a hash in the center), but in reality the clusters turned out to be no less meaningful than in the case of 1285 domains.
With an increase in the amount of data, interesting patterns are observed. On the one hand, small peripheral clusters begin to stand out, which were indistinguishable on small data. On the other hand, what is poorly clustered on small data is poorly clustered on large data (for example, real estate and job search sites mix, esotericism and astrology often adjoin them).
Here are some examples of new communities. At the very outskirts, the Spanish cluster stood out, as we see something from there:
Not far from it, closer to the main cluster of points, is the Azerbaijani cluster (number 2) and the Georgian (number 4): an
Uzbek-Tajik cluster has appeared, as well as a Belarusian (number 16) - inside the bulk of the domains, next to the “Russian news” and “Ukrainian non-news” communities:
In the next post there will be a description of the algorithm:
- how the clusters themselves were obtained so that the graph could be colored so;
- how to remove excess ribs.
Ready to answer your questions in the comments. Stay tuned!