MIT course "Computer Systems Security". Lecture 12: "Network Security", part 2
- Transfer
- Tutorial
Massachusetts Institute of Technology. Lecture course # 6.858. "Security of computer systems". Nikolai Zeldovich, James Mykens. year 2014
Computer Systems Security is a course on the development and implementation of secure computer systems. Lectures cover threat models, attacks that compromise security, and security methods based on the latest scientific work. Topics include operating system (OS) security, capabilities, information flow control, language security, network protocols, hardware protection and security in web applications.
Lecture 1: “Introduction: threat models” Part 1 / Part 2 / Part 3
Lecture 2: “Controlling hacker attacks” Part 1 / Part 2 / Part 3
Lecture 3: “Buffer overflow: exploits and protection” Part 1 /Part 2 / Part 3
Lecture 4: “Privilege Separation” Part 1 / Part 2 / Part 3
Lecture 5: “Where Security System Errors Come From” Part 1 / Part 2
Lecture 6: “Capabilities” Part 1 / Part 2 / Part 3
Lecture 7: “Native Client Sandbox” Part 1 / Part 2 / Part 3
Lecture 8: “Network Security Model” Part 1 / Part 2 / Part 3
Lecture 9: “Web Application Security” Part 1 / Part 2/ Part 3
Lecture 10: “Symbolic execution” Part 1 / Part 2 / Part 3
Lecture 11: “Ur / Web programming language” Part 1 / Part 2 / Part 3
Lecture 12: “Network security” Part 1 / Part 2 / Part 3
Student: Perhaps you still have a conflict of interest problem because you could use 32 bits for the peer addresses and you have a lot of ports for each of them. Probably, you have a conflict of ordinal numbers of all these connections that you get?
Professor: it turns out that these sequence numbers are specific to the IP address and port number of the source / destination pair. So if these are different ports, then they do not interfere with each other at all. Specifically, ports have lower sequence numbers.

Student: if the sequence numbers are global, then can not an attacker get into a connection between other clients?
Professor:Yes, this is a good point. In fact, if the server increases the sequence number, for example, by 64k for each connection, you connect to the server, and then 5 more people connect to it, and here you can organize an attack. So to some extent, you are right, it is a bit troublesome. On the other hand, you could probably make it so that the packet from the last row of S-> A would be delivered immediately before this packet in the first row of C-> S. If you send your packages one after the other, there is a good chance that they will arrive at the server also one by one.
The server will receive S-> A and respond with this sequence number (SNs). It will be different than (SNs) in the second line, but with the sequence number immediately following it. And then you will know exactly which sequence number (SNs) should be invested in the third packet of your sequence.
Therefore, I think that this is not a very reliable way to connect to the server, it is based on assumptions. But if you carefully arrange your packages as needed, you can easily guess the sequence. Or maybe you try several times and you are lucky.
Student: even if the numbers are generated completely randomly, you need to guess one of the 4 billion possible numbers. It is not too much, right? I think that within a year you can probably get into this network.
Professor:Yes, you are absolutely right. You should not rely too heavily on TCP in terms of security. Because you're right, it's only 4 billion guesses. And you will probably be able to send a lot of packages during the day if you have a fairly fast connection.
So here we have a kind of interesting argument about the unreliability of TCP, because we only have 32 bits. We can not protect it. But I think that many applications that rely sufficiently on this protocol do not even think about security at all, and this is indeed becoming a problem.
But you are absolutely right. In practice, you want to use some kind of encryption on top of this in order to get more serious guarantees that no one has forged your data, since you use encryption keys longer than 32 bits. In most cases, this is still effective in preventing tampering with the TCP connection.
Let's now see why it’s bad if people can forge TCP connections from arbitrary addresses?
One of the reasons why this is bad is that it can influence the authorization based on the IP address when the server checks from which address the request came. If a server decides, based on the IP address, whether to allow or deny the connection, this could potentially be a problem for the attacker who forged the connection from an arbitrary source address.
So, one example where this was a problem, today this problem is mostly solved, it is the use of a family of r commands, such as rlogin. It used to be that you could run something like rlogin for a computer at, say, athena.dialup.mit.edu. And if your connection comes from the MIT host, then this rlogin command will succeed if you say: "Yes, I am Alice user on this computer, let me log in as Alice user on another computer." And this operation will be allowed, since all the computers on the mit.edu network are trustworthy to make such statements.
I have to say that dial-up never had this problem. This compound used "Cerberus" from the very beginning. But other systems, of course, had such problems. And this is an example of using an IP address in a connection authentication mechanism when the system checks whether the client calling the server is trustworthy. So what used to be a problem now is not. But relying on IP still seems like a bad plan.

Now rlogin is no longer used, it has recently been replaced by the secure SSH shell, which is an excellent network layer protocol. On the other hand, there are many other examples of protocols that rely on IP-based authorization. One of them is SMTP. When you send an email, you use SMTP to talk to some mail server in order to send messages. To prevent spam, many SMTP servers only accept incoming messages from a specific source IP address. For example, the Comcast mail server accepts mail only from Comcast IP addresses. The same is true for MIT mail servers - they will only accept mail from MIT IP addresses. But we had at least one server that did not work as it should, using IP authentication.
Everything is not so bad here. In the worst case, you send some spam through your mail server. So probably, therefore, they still use rlogin, while the things that allow you to log into a random account have stopped using IP-based identification.
So why is such an authentication mechanism a bad plan? As an assumption, assume that some server used rlogin. What would you do to attack? What is wrong with this can happen?
Student: an attacker can simply get into your computer, fake a user who is going to log into the network with your login, and gain access to the network.
Professor:yes, basically the attacker hijacks the computer. It synthesizes data that looks like a valid set of rlogin commands that say: "Log in as this user and execute this command in my Unix shell."
You synthesize this data data (SNc +1), mount the entire attack, and send this data as if the legitimate user was interacting with the rlogin client, and then you can proceed.

Well, this is one of the reasons why you do not want your TCP sequence numbers to be guessed. Another problem is these reset attack reset attacks. Just as we could send a SYN packet if we know someone’s sequence number, we can also send a reset packet.
We briefly mentioned a legal client that sends a bogus reset packet that the attacker has installed. An attacker can also attempt to send reset packets for an existing connection, if he somehow knows that your sequence number is on that connection. In fact, it is unclear how big the problem is.
At some level, you must assume that all your TCP connections can be broken anyway and at any time, that is, it doesn't seem like your network is secure. Therefore, perhaps you should expect connections to break.
In the case when routers “talk” with each other, this assumption is especially critical. If you have a lot of routers that communicate with each other using some routing protocols, then there are some physical connections between them. But on top of these physical connections, they communicate over a network protocol that works over TCP. In fact, in each of these physical links that routers use to exchange routing information, a TCP session is started. This uses the BGP protocol, which we'll talk about later.
This BGP protocol uses the fact that if a TCP connection is alive, then the physical connection is alive. So if a TCP connection is broken, the router considers that the connection is broken and begins to recalculate all of its routing tables.

Therefore, if an adversary wants to do some kind of a DoS denial of service attack here, he can try to guess the sequence numbers of these routers and reset these sessions. If a TCP session between two routers goes down, both routers assume that this connection is dead and they have to recalculate all routing tables, which causes the routes to change. After that, the attacker can drop another connection, and so on.
Thus, it is a somewhat disturbing attack, and not because it violates someone’s secret and so on, at least not directly, but because it does cause many access problems for other users of the system.
Student:if you are an attacker and you want to organize a targeted attack against a specific user, could you just keep sending requests to connect to the server on behalf of its IP address and force it to reset the connection to the server?
Professor: Suppose I use Gmail and you want to prevent me from receiving any information from Gmail, so you just send the packages to my machine, pretending that they come from the Gmail server. In this case, you must guess the correct source port and destination port numbers.
The destination port number is probably 443, because I use HTTPS. But the source port number will be some random 16-bit thing. In addition, the sequence numbers will vary. Therefore, if you do not guess the sequence number, which is in my TCP window and which is tens of kilobytes, you will not succeed.
So you have to guess a fair amount of things. There is no Oracle access. You can’t just request the server's sequence number from the server. That's the reason why that won't work either.
So many of these problems have been fixed, including this thing based on RST, especially for BGP routers. There were actually two funny fixes. One really shows how you can exploit existing things or use them to fix specific problems. It uses the property that these routers communicate only with each other, and not with anyone else on this network. As a result, if a packet does not arrive from a router located at the other end of the connection, then this packet is discarded.
A successful implementation of the developers of these protocols is a wonderful area in the package, which is called "lifetime", or TTL. This is an 8-bit field that is reduced by each router to ensure that packets do not fall into an infinite loop. The maximum TTL value is 255 and further decreases.
So, what are these smart protocols doing? They drop any packet with a TTL value that is not equal to 255. Because if the packet has a value of 255, then it can only come from the router on the other side of the connection. And if an adversary tries to inject any other packet into an existing BGP connection, it will have a TTL value less than 255, because this value will be reduced by other routers along the routing path, including this router. Therefore, this package will simply be rejected by the recipient.
So this is one example of the smart combination of backward-compatible techniques that solve this very specific problem.

Student: Doesn't the bottom right router send something with a TTL of 255?
Professor:this is a physical router. And he knows that these are separate links, so he looks at both TTL and where the package came from. So if a packet came from the top left router, it will not accept it for a TCP connection between it and the top right router.
For the most part, these routers trust their immediate neighbors, and this process can be controlled using the AutoPath multi-path routing mechanism.
Other fixes for BGP are to implement some form of authentication header, including the MD5 authentication header. But in reality, the developers focused on this particular application, for which a reset attack is particularly critical.
This problem persists today. If there is any long-existing connection and I want to interrupt it, I just have to send a large number of RST packets, approximately hundreds of thousands, but probably not 4 billion. Because the servers are actually somewhat vulnerable to what sequence number they take to reset.
This can be any package in a specific window. In this case, the attacker could break this connection, without making special efforts. This is still a problem for which there is no really good solution.
And the last bad thing that can happen because of the predictability of sequence numbers is the injection of data into existing connections. Suppose we have a hypothetical protocol, similar to rlogin, which does not actually perform IP-based authentication, so you must enter your password to log in.
The problem is that once you have entered your password, it is possible that your TCP connection is simply established and can accept arbitrary data. So the attacker just needs to wait until one of you guys log in to your computer by entering your password.
The attacker does not know what the password is, but as soon as you have established a TCP connection, he will immediately try to guess your sequence number and enter some data into your existing connection. So if I can correctly guess your sequence number, it will allow me to pretend that it was not me, but you entered some command after you were correctly authenticated with a password.

All this suggests why you really do not want to rely on these 32-bit sequence numbers in terms of security. But let's see what modern TCP stacks actually do to mitigate this problem. One approach to the problem, which we will consider in the next 2 lectures, is to implement some degree of security at the application level. At this level, we will use cryptography to authenticate, encrypt, sign, and validate messages without special TCP involvement.
Some of the existing applications also help solve security problems or at least make it more difficult for an attacker to use these problems. People put this into practice today, for example, in Linux and Windows, supporting different initial sequence numbers for each source / destination pair.
Thus, most TCP SYN implementations still compute this initial ISN sequence number just as we did before. So this is an old style isn, let's say. And in order to actually generate a sequence number for any particular connection, we add to this old-fashioned ISN a random 32-bit offset. That is, we add a function to it - something like a hash function or SHA-1, or something better.
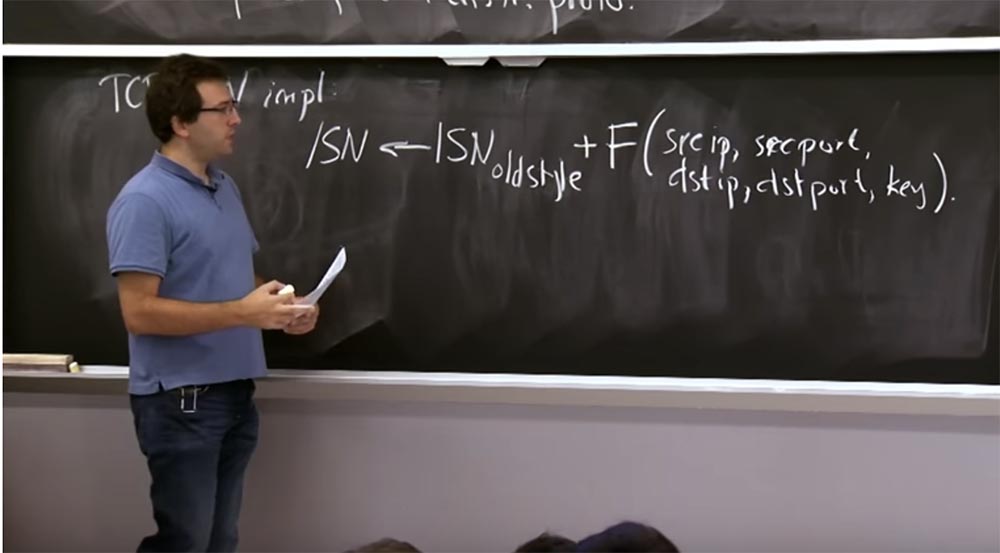
This feature includes the source IP address, source port number, destination IP address, destination port number, and some secret key that only the server knows. Thus, we create a good opportunity for any particular connection to determine the IP address and port for a source / destination pair, while retaining all the good features of this old style sequence number assignment algorithm.
But if you have connections from different source / destination sets, then there is nothing that allows you to find out the exact value of the sequence number of another connection set. In fact, you have to guess this key in order to calculate this value.
I hope that the OS kernel of the server stores this key somewhere in its memory and does not give it to anyone. This is how most TCP stacks solve today this particular problem in the area of common 32-bit sequence numbers. This is not too cool, but it works.
Student: could you repeat that again? What about the uniqueness of the key ...
Professor:when my machine boots, or when any machine boots, it generates a random key. Every time you reboot it, it generates a new key. This means that each time the sequence numbers of a particular source / destination pair change with the same frequency offset. Thus, for a given source / destination pair, the function parameters are fixed. So you follow the sequence when the numbers evolve according to your initial sequence numbers for new compounds, varying according to a certain algorithm. In this way, protection is provided against the injection of old packages from previous compounds into new compounds, as well as protection against the reassignment of packages.
The only thing for which we need this serial number of the old sample is the choice of an algorithm to prevent problems with these duplicate packages. Earlier, we considered that if you get a sequence number for a single connection A: A -> S: SYN (...), then you can conclude about the sequence number for an ACK connection (SNs).
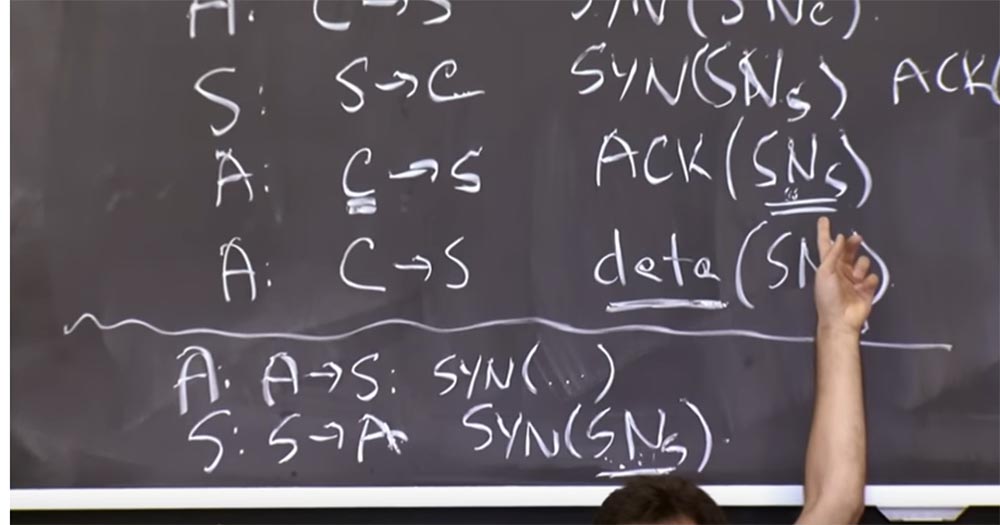
Now this is no more, since each connection has a different offset in this 32-bit space as it is implemented by function F. Thus, this completely eliminates the connection between different initial sequence numbers, as is seen in each connection.
Student: what's the point of including a key in this function?
Professor:if you do not turn on the key, then I can contact you. I will calculate the same function F, calculate the value of the sequence number, then calculate the function F for the connection I want to fake, and I will guess what the original sequence number will be for this.
Student: since the machines rarely reboot now, is it possible to try to fake authentication with the help of reverse ...
Professor:I think that usually this F function is something like a cryptographically secure hash function, and it is difficult to invert it cryptographically. Even if you have been given the literal input and output of this hash function, with the exception of the key, deciphering it will be very difficult even in an isolated set. So, hopefully, it will at least be as difficult to accomplish in a comprehensive data set. Later we will talk a little more about what these F functions are and how to use them correctly.
So, it was a kind of example of attacks using TCP sequence numbers, which are not particularly relevant today. Each operating system in our time uses this protection plan, so it is difficult to conclude what will be someone's serial number.
On the other hand, people continue to make the same mistakes. Even after the bias mechanism was implemented for TCP, another protocol was developed called DNS, which remained extremely vulnerable to attacks of this kind. The reason was that the DNS was run through the UDP protocol for user datagrams. UDP is a stateless protocol when you do not actually establish a connection in which you exchange serial numbers. In UDP, you simply send a request from your source to the server. The server finds out what the response should be and sends it back regardless of the source address in the packet. This is a route along the same path, in which there is no time and opportunity to exchange sequence numbers and establish the fact that you really communicate with the right source. As a result, it was very easy to fake DNS server responses. What does a typical DNS query look like?

Suppose a client sends a C: C53 -> S53 request to the DNS server to access the mit.edu resource, usually it is received and sent via port 53.
Next, the server responds to the client with an S: S53 -> C53 packet with the name of the requested resource and its IP- address, and that's it, the connection is established.
The problem is that some hackers can easily send a similar response packet, pretending that this packet was sent by the server, and there are not so many accidents here. If I know that you are trying to connect to mit.edu, I will simply send a lot of such packages to your computer.
I know exactly which DNS server you are going to request. I know your IP address for sure, I know port numbers and I know what you are asking about. Therefore, I can simply indicate here my IP address instead of the resource IP address mit.edu. And if my package goes there after you send your request, but before you receive the real server response, your client machine will use my package. So this is another example where the lack of randomness in the protocol makes it very easy to inject the answers or the packets in the connection.
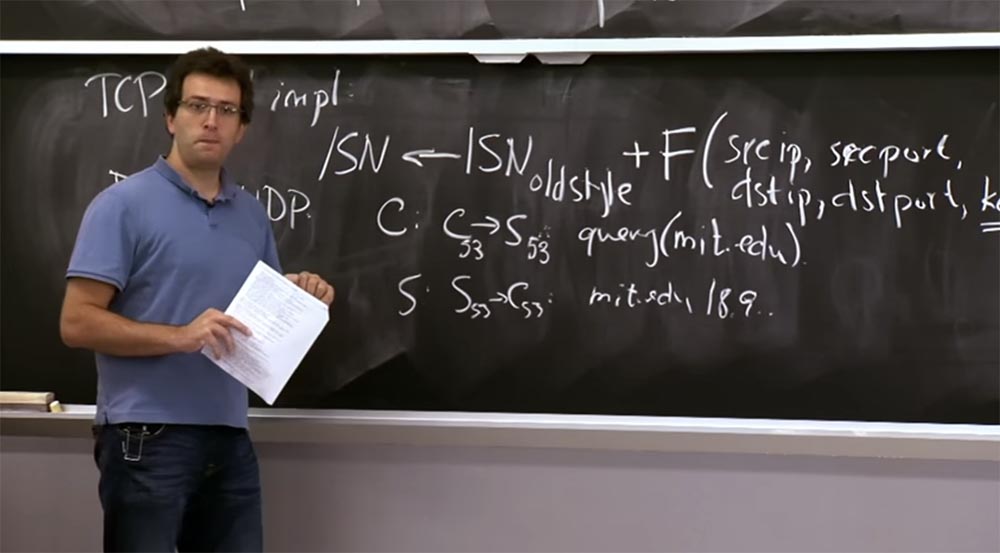
In fact, in a sense, it is even worse than the previous attack. Because here you can convince a client to connect to a different IP address. This result is probably cached because the DNS server uses caching. Because of this, you can be inside for a very long time, while your client will use the fake IP address mit.edu before rebooting.
Student: Is it possible to fix this by including some random value in the client request, which allows the server to know that this is a real client?
Professor:this is exactly what they have done. The problem, as we mentioned, is backward compatibility. It is very difficult to change the software of each DNS server, so it is very difficult to figure out exactly where randomness can be entered. The developers found only 2 such places. The first is the source port number, which uses 16 bits of randomness. So if you can randomly select the source port number, you will get 16 bits. Inside the packet there is a request identifier ID, which is also equal to 16 bits, and the server does not return the request identifier.
Thus, by combining these two things together, most modern discriminators obtain 32 bits of randomness from this protocol. This, again, makes it noticeably harder to fake such an answer and so that it is accepted by the client, but still not perfect in the sense of cryptography.
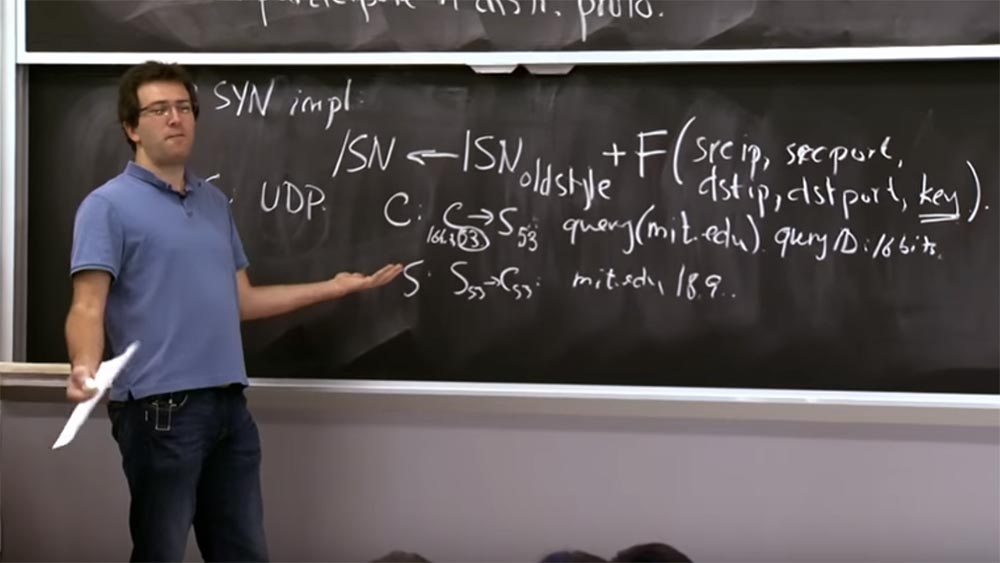
Unfortunately, such problems constantly arise, although this protection option was developed several years ago.
I think a bit aside there is another solution to this DNS problem and ensuring DNS security at the application level. Instead of relying on the randomness properties of a small number of bits in a packet, you can try encryption in DNS protocols. For example, the DNS SEC protocol, which is briefly described in the article by Stephen. Instead of relying on any security properties at the network level, they require that all DNS names have signatures attached to them. This seems like a reasonable plan, but it turns out that working out the details is actually quite time consuming.
One example of a problem found is the name and origin of origin. In DNS, you want to get the answer that this resource name has this IP address, or the answer: “sorry, but there is no such name”. That way, you also want to sign an answer denying the existence of a name, because otherwise, the attacker can send you an answer that the given name does not exist, even if it exists. So how can you sign an answer that the given name does not exist even before the request for the given name was sent?
I think one of the possibilities is to provide your DNS server with a key that will sign all your records. However, this seems like a bad plan. Because then someone who compromises your DNS server can take possession of this key. Instead, the model by which the DNS SEC works is that you sign all your names in the domain in advance, and then provide the DNS server with this list of signatures. Now the DNS server can respond to any requests, and even if it is compromised, the attacker can do little - because all these things are signed, and the key is not on the server.
The DNS SEC protocol has a smart mechanism for signing non-existent names, called NSEC. He does this by signing spaces in the namespace. For example, the NSEC can say that once there is the name foo.mit.edu, the next name in alphabetical order is goo.mit.edu, and between these two names there can be nothing else arranged in alphabetical order.

Therefore, if you request a name that is between these two names, sorted alphabetically, the server can send you a message stating that there is nothing between these two names, that is, you are quite safe to get the real answer “sorry, but that name does not exist".
However, this allows the attacker to fully list your domain names. That is, he can request a domain name, find this entry foo.mit.edu -> goo.mit.edu -> .... and say, "fine, these two names exist, and now let me ask for the name gooa.mit.edu." This will give him the answer, saying what the next name is in your domain, etc.
So it's actually a little difficult to come up with the right a protocol that preserves all the good properties of the DNS and at the same time prevents the transfer of names and other problems.Now a good thing called NSEC3 is used there that tries to solve this problem partially - something seems to work, something is not quite.
52: 00 min
course MIT «Security of computer systems." Lecture 12: "Network security", part 3
Full version of the course is available here .
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to friends, 30% discount for Habr users on a unique analogue of the entry-level servers that we invented for you: The whole truth about VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps from $ 20 or how to share the server? (Options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps until December for free if you pay for a period of six months, you can order here .
Dell R730xd 2 times cheaper? Only here2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV from $ 249 in the Netherlands and the USA! Read about How to build an infrastructure building. class c using servers Dell R730xd E5-2650 v4 worth 9000 euros for a penny?