Static analysis of PHP code on the example of PHPStan, Phan and Psalm

Badoo has been around for over 12 years. We have a lot of PHP code (millions of lines) and probably even lines written 12 years ago have been preserved. We have code written back in the days of PHP 4 and PHP 5. We post the code twice a day, and each layout contains about 10-20 tasks. In addition, programmers can post urgent patches — small changes. And on the day of such patches we have a couple of dozen. In general, our code is changing very actively.
We are constantly looking for opportunities to both speed development and improve the quality of the code. And once we decided to implement static code analysis. What came out of it, read under the cut.
Strict types: why we do not use it yet
Once we had a discussion in our corporate PHP chat. One of the new employees told how at the previous place of work they implemented mandatory strict_types + scalar type hints for the entire code - and this significantly reduced the number of production bugs.
Most of the old-timers chat was against this innovation. The main reason was that PHP does not have a compiler that, at the compilation stage, would check the conformity of all types in the code, and if you don’t have 100% coverage of the code with tests, there is always a risk that errors will pop up during production, which we don’t we want to allow.
Of course, strict_types will find a certain percentage of bugs caused by type mismatch and the way PHP "silently" converts types. But many experienced PHP programmers already know how type systems work in PHP, what are the rules for type conversion, and in most cases they write correct, working code.
But we liked the idea of having a certain system showing where there is a type mismatch in the code. We are thinking about alternatives to strict_types.
At first, we even wanted to patch PHP. We wanted that if the function takes some scalar type (say, int), and another scalar type comes in (for example, float), then TypeError (which is essentially an exception) would not throw, but type conversion would occur, as well as the logging of this event in error.log. This would allow us to find all the places where our assumptions about types are wrong. But such a patch seemed to us a risky business, and there could be problems with external dependencies, which were not ready for such behavior.
We abandoned the idea of patching PHP, but in time it all coincided with the first releases of the static analyzer Phan, the first commits of which were made by Rasmus Lerdorf himself. So we came up with the idea to try static code analyzers.
What is static code analysis
Static code analyzers simply read the code and try to find errors in it. They can perform both very simple and obvious checks (for example, the existence of classes, methods and functions, and more cunning ones (for example, look for type mismatch, race conditions or code vulnerabilities). The key is that analyzers do not execute code - they they analyze the text of the program and check it for typical (and not so)
errors.The most obvious example of a static PHP code analyzer are inspections in PHPStorm: when you write code, it highlights incorrect function calls, methods, mismatch of parameter types, etc. Pr and PHPStorm does not run your PHP code — it only analyzes it.
I note that in this article we are talking about analyzers that are looking for errors in the code. There is another class of analyzers - they check the style of writing code, the cyclomatic complexity, the size of the methods, the length of the lines, etc. We do not consider such analyzers here.
Although not everything that the analyzers we are looking at is exactly the mistake. By mistake, I mean the code that will create Fatal in production. Very often, what analyzers find is rather an inaccuracy. For example, in PHPDoc, an invalid parameter type may be specified. This inaccuracy does not affect the operation of the code, but subsequently the code will evolve - another programmer may make a mistake.
Existing PHP code analyzers
There are three popular PHP code analyzers:
And there is Exakat , which we have not tried.
On the user's side, all three analyzers are the same: you install them (most likely through Composer), configure them, after which you can run an analysis of the entire project or a group of files. As a rule, the analyzer is able to beautifully display the results in the console. You can also output the results in JSON format and use them in CI.
All three projects are now actively developing. Their maintainers are very actively responding to issues on GitHub. Often, on the first day after the creation of a ticket, at least they react to it (they comment or put a bug / enhancement tag). Many bugs we found were fixed in a couple of days. But I especially like the fact that the maintainers of projects actively communicate with each other, report bugs to each other, and send pull requests.
We have implemented and use all three analyzers. Everyone has their own nuances, their own bugs. But using three analyzers at the same time makes it easier to understand where the real problem is and where the false positive is.
What analyzers can do
Analyzers have many common features, so first consider what they all can do, and then we turn to the features of each of them.
Standard checks
Of course, the analyzers perform all standard code checks to ensure that:
- the code does not contain syntax errors;
- all classes, methods, functions, constants exist;
- variables exist;
- in PHPDoc, hints are true.
In addition, the analyzers check the code for unused arguments and variables. Many of these errors lead to real fatal code.
At first glance it may seem that good programmers do not make such mistakes, but sometimes we are in a hurry, sometimes copy-paste, sometimes we are just inconsiderate. And in such cases, these checks are very much saved.
Data Type Checks
Of course, static analyzers also perform standard checks on data types. If the code says that the function accepts, say, int, then the analyzer will check if there are any places where an object is passed to this function. With most analyzers, you can set the test strictness and imitate strict_types: check that no string or Boolean is passed to this function.
In addition to standard checks, analyzers still have a lot to do.
Union types.
All analyzers support the concept of Union types. Suppose you have a type function:
/**
* @var string|int|bool $yes_or_no
*/functionisYes($yes_or_no) :bool{
if (\is_bool($yes_or_no)) {
return $yes_or_no;
} elseif (is_numeric($yes_or_no)) {
return $yes_or_no > 0;
} else {
return strtoupper($yes_or_no) == 'YES';
}
}Its contents are not very important - the type of the input parameter is important
string|int|bool. That is, the variable $yes_or_no is either a string, or an integer, or Boolean. Using PHP, this type of function parameter cannot be described. But in PHPDoc it is possible, and many editors (for example, PHPStorm) understand it.
In static analyzers, this type is called the union type , and they are very good at checking such data types. For example, if we would write the above function like this (without checking for
Boolean):/**
* @var string|int|bool $yes_or_no
*/functionisYes($yes_or_no) :bool{
if (is_numeric($yes_or_no)) {
return $yes_or_no > 0;
} else {
return strtoupper($yes_or_no) == 'YES';
}
}the analyzers would see that either a string or a Boolean can come to the strtoupper, and return an error — you cannot pass a Boolean to the strtoupper.
This type of check helps programmers correctly handle errors or situations where a function cannot return data. We often write functions that can return some data or
null:// load() возвращает null или объект \User
$User = UserLoader::load($user_id);
$User->getName();In the case of such a code, the analyzer will tell you that the variable
$Userhere can be equal nulland this code can lead to fatal. Type false
In the PHP language itself, there are quite a few functions that can return either a value or false. If we wrote such a function, how would we document its type?
/** @return resource|bool */functionfopen(...){
…
}Formally, everything seems to be true here: fopen returns either a resource or a value
false(which has a type Boolean). But when we say that a function returns some type of data, it means that it can return any value from the set belonging to that data type. In our example for the analyzer, this means that it fopen() can return and true. And, for example, in the case of such a code:$fp = fopen(‘some.file’,’r’);
if($fp === false) {
returnfalse;
}
fwrite($fp, "some string");The analyzers would complain that it
fwritetakes the first resource parameter, and we give it bool(because the analyzer sees that the option with true is possible). For this reason, all analyzers understand such an “artificial” data type as false, and in our example we can write @return false|resource. PHPStorm also understands this type description. Array shapes
Very often, arrays in PHP are used as a type
record- a structure with a clear list of fields, where each field has its own type. Of course, many programmers are already using classes for this. But we have a lot of legacy code in Badoo, and arrays are actively used there. It also happens that programmers are too lazy to start a separate class for a one-time structure, and in such places they also often use arrays.The problem with such arrays is that there is no clear description of this structure (a list of fields and their types) in the code. Programmers can make mistakes while working with such a structure: forget the required fields or add the “left” keys, confusing the code even more.
Analyzers allow description of such structures:
/** @param array{scheme:string,host:string,path:string} $parsed_url */functionshowUrl(array $parsed_url){ … }In this example, we described an array with three string fields:
scheme, hostand path. If inside the function we turn to another field, the analyzer will show an error. If you do not describe types, then the analyzers will try to "guess" the structure of the array, but, as practice shows, with our code, this is not very good for them. :)
This approach has one drawback. Suppose you have a structure that is actively used in the code. It is impossible to declare a pseudotype in one place and then use it everywhere. You have to write PHPDoc with the array description everywhere in the code, which is very inconvenient, especially if there are many fields in the array. It will also be problematic to edit this type (add and delete fields).
Description of Array Key Types
In PHP, array keys can be integers and strings. Sometimes types can be important for static analysis (and for programmers). Static analyzers allow you to describe array keys in PHPDoc:
/** @var array<int, \User> $users */
$users = UserLoaders::loadUsers($user_ids);In this example, we used PHPDoc to add a hint that, in the array, the
$userskeys are integer ints, and the values are class objects \User. We could describe the type as \ User []. This would tell the analyzer that there are class objects in the array \User, but nothing would tell us about the type of keys. PHPStorm supports this array description format starting from version 2018.3.
Your PHPDoc
PHPStorm namespace (and other editors) and static analyzers can understand PHPDoc differently. For example, analyzers support this format:
/** @param array{scheme:string,host:string,path:string} $parsed_url */functionshowUrl($parsed_url){ … }And PHPStorm does not understand it. But we can write this:
/**
* @param array $parsed_url
* @phan-param array{scheme:string,host:string,path:string} $parsed_url
* @psalm-param array{scheme:string,host:string,path:string} $parsed_url
*/functionshowUrl($parsed_url){ … }In this case, both the analyzers and PHPStorm will be satisfied. PHPStorm will use
@param, and analyzers will use their PHPDoc tags.Checks related to PHP features
This type of checks is best illustrated by example.
Do we all know what the explode () function can return ? If you skim through the documentation, it seems that it returns an array. But if we look more closely, we will see that it can also return false. In fact, it may return both null and an error if you pass it the wrong types, but passing the wrong value with the wrong data type is already an error, so this option does not interest us right now.
Formally, from the point of view of the analyzer, if the function can return false or an array, then most likely, then the code should check for false. But the explode () function returns false only if the separator (the first parameter) is an empty string. Often, it is explicitly registered in the code, and analyzers can check that it is not empty, which means that in this place, the explode () function accurately returns an array and does not need to check for false.
PHP doesn’t have many of these features. Analyzers gradually add relevant checks or improve them, and we, programmers, no longer need to memorize all these features.
We proceed to the description of specific analyzers.
PHPStan
Development of a certain Ondřej Mirtes from the Czech Republic. Actively developed since the end of 2016.
To start using PHPStan, you need:
- Install it (the easiest way to do this is through Composer).
- (optional) Configure.
- In the simplest case, just run:
vendor/bin/phpstan analyse ./src(instead there
srcmay be a list of specific files that you want to check). PHPStan will read the PHP code from the transferred files. If unknown classes meet him, he will try to load them with an autoload and, through reflection, understand their interface. You can also transfer the path to the
Bootstrapfile through which you configure the autoload and include some additional files in order to simplify the PHPStan analysis. Key features:
- You can not analyze the entire code base, but only a part - PHPStan will try to load unknown classes with autoload.
- If for some reason some of your classes are not in the autoload, PHPStan will not be able to find them and will give an error.
- If you actively use magic methods through
__call / __get / __set, then you can write a plugin for PHPStan. There are already plugins for symfony, Doctrine, Laravel, Mockery, etc. - In fact, PHPStan performs autoloads not only for unknown classes, but in general for all. We have a lot of old code written before the appearance of anonymous classes, when we create a class in one file, and then we instantiate it right away, and maybe even call some methods. Autoload (
include) of such files leads to errors, because the code is not executed in a normal environment. - Configs in neon format (never heard of this format anywhere else).
- No support for your PHPDoc type tags
@phpstan-var, @phpstan-return, etc.
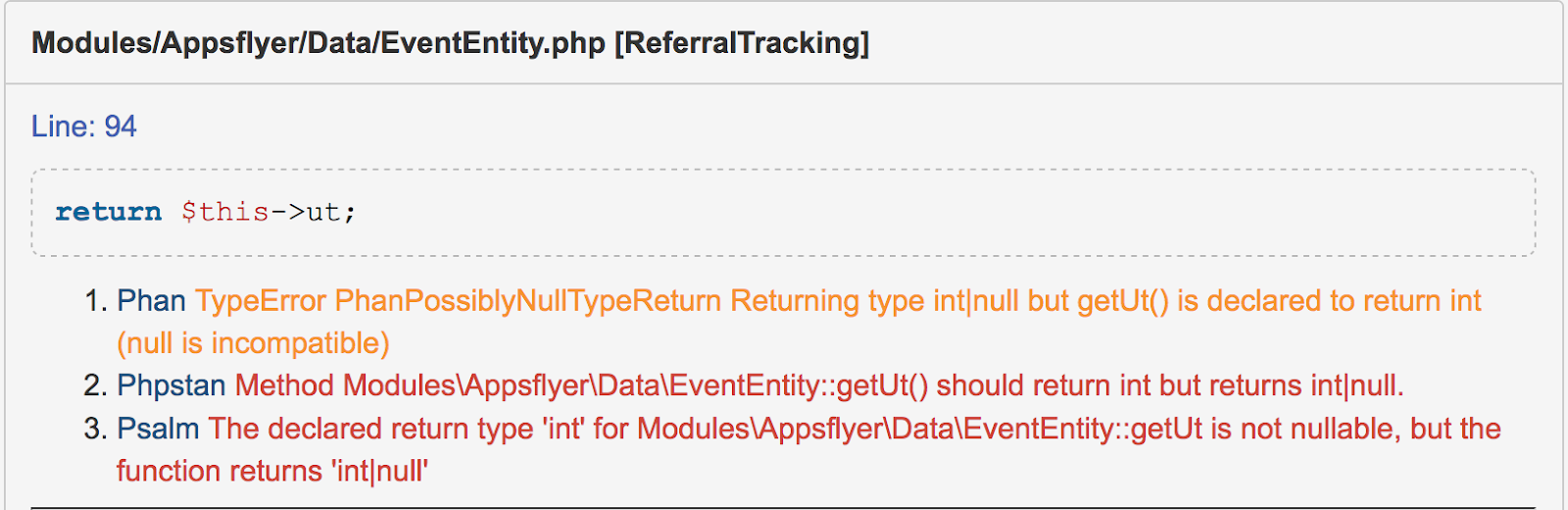
Another feature is that errors have text, but there is no type. That is, an error text is returned to you, for example:
Method \SomeClass::getAge() should return int but returns int|nullMethod \SomeOtherClass::getName() should return string but returns string|null
In this example, both errors, in general, are about the same: the method must return one type, but in reality it returns the other. But the texts of errors are different, albeit similar. Therefore, if you want to filter out any errors in PHPStan, do it only through regular expressions.
For comparison, in other analyzers errors have a type. For example, in Phan, such an error has a type
PhanPossiblyNullTypeReturn, and you can specify in the config that no check for such errors is required. Also, having the type of error, you can, for example, easily collect statistics on errors. Since we do not use Laravel, Symfony, Doctrine and similar solutions, and we rarely use magical methods in the code, the main feature of PHPStan was unclaimed. ; (Besides, due to the fact that PHPStan include-it alltested classes, sometimes its analysis simply does not work on our code base.
Nevertheless, PHPStan remains useful for us:
- If you need to check several files, PHPStan is noticeably faster than Phan and a little (20-50%) faster than Psalm.
- PHPStan reports make it easier for us to find
false-positivein other analyzers. Usually, if there is some explicit code in the codefatal, it is shown by all analyzers (or at least two of the three).
Update:
The author of PHPStan Ondřej Mirtes also read our article and suggested that PhpStan, like Psalm, has a sandbox site: https://phpstan.org/ . This is very convenient for bug reports: you reproduce the error in and give a link in GitHub.
Phan
Developed by Etsy. First commits by Rasmus Lerdorf.
Of the three considered, Phan is the only true static analyzer (in the sense that it does not execute any of your files — it parses the entire code base and then analyzes what you say). Even for analyzing several files in our code base, it takes about 6 GB of RAM, and this process takes four to five minutes. But then, a complete analysis of the entire code base takes about six to seven minutes. For comparison, Psalm analyzes it for several tens of minutes. And from PHPStan we could not achieve a complete analysis of the entire code base due to the fact that it includes classes.
The impression of Phan is twofold. On the one hand, it is the most qualitative and stable analyzer, it finds a lot and the least problems with it when it is necessary to analyze the entire code base. On the other hand, it has two unpleasant features.
Under the hood, Phan uses the php-ast extension. Apparently, this is one of the reasons that the analysis of the entire code base is relatively fast. But php-ast shows the internal representation of the AST tree as it appears in PHP itself. And in PHP itself, the AST tree does not contain information about comments that are located inside the function. That is, if you wrote something like:
/**
* @param int $type
*/functiondoSomething($type){
/** @var \My\Object $obj **/
$obj = MyFactory::createObjectByType($type);
…
}then inside the AST tree there is information about the external PHPDoc for the function
doSomething(), but there is no PHPDoc hint information that is inside the function. And, accordingly, Phan also knows nothing about her. This is the most common cause false-positivein Phan. There are some recommendations on how to insert hints (via strings or asserts), but, unfortunately, they are very different from what our programmers are used to. We partially solved this problem by writing a plugin for Phan. But plugins are discussed below. The second unpleasant feature is that Phan poorly analyzes the properties of objects. Here is an example:
classA{
/**
* @var string|null
*/private $a;
publicfunction__construct(string $a = null){
$this->a = $a;
}
publicfunctiondoSomething(){
if ($this->a && strpos($this->a, 'a') === 0) {
var_dump("test1");
}
}
}In this example, Phan will tell you that in strpos you can pass null. You can learn more about this issue here: https://github.com/phan/phan/issues/204 .
Summary. Despite some difficulties, Phan is a very cool and useful development. In addition to these two types
false-positive, he almost does not make mistakes, or makes mistakes, but on some really complex code. We also liked the fact that the config is in a PHP file - this gives a certain flexibility. Phan also knows how to work as a language server, but we have not used this feature, since PHPStorm is enough for us.Plugins
Phan has a well-developed plugin API. You can add your own checks, improve type inference for your code. This API has documentation , but it’s especially cool that there are already ready-made working plugins inside that can be used as examples.
We managed to write two plugins. The first was intended for a one-time check. We wanted to evaluate how our code is ready for PHP 7.3 (in particular, to find out if there are any
case-insensitiveconstants in it ). We were almost sure that there were no such constants, but in 12 years anything could have happened - it should have been checked. And we wrote a plugin for Phan, which would curse if the define() third parameter were used.The plugin is very simple.
<?phpdeclare(strict_types=1);
usePhan\AST\ContextNode;
usePhan\CodeBase;
usePhan\Language\Context;
usePhan\Language\Element\Func;
usePhan\PluginV2;
usePhan\PluginV2\AnalyzeFunctionCallCapability;
useast\Node;
classDefineThirdParamTrueextendsPluginV2implementsAnalyzeFunctionCallCapability{
publicfunctiongetAnalyzeFunctionCallClosures(CodeBase $code_base) : array{
$define_callback = function(
CodeBase $code_base,
Context $context,
Func $function,
array $args
){
if (\count($args) < 3) {
return;
}
$this->emitIssue(
$code_base,
$context,
'PhanDefineCaseInsensitiv',
'Define with 3 arguments',
[]
);
};
return [
'define' => $define_callback,
];
}
}
returnnew DefineThirdParamTrue();In Phan, different plugins can be hung on different events. In particular, interface plug-ins
AnalyzeFunctionCallCapabilitywork when a function call is analyzed. In this plugin, we made it so that when calling a function, define() our anonymous function is called, which checks that it has at define() most two arguments. Then we just started Phan, found all the places where I define()was called up with three arguments, and made sure that we don’t case-insensitive-констант. With the help of the plugin, we also partially solved the problem
false-positivewhen Phan does not see PHPDoc hints inside the code. We often use factory methods that take a constant as input and create an object from it. Often the code looks like this:
/** @var \Objects\Controllers\My $Object */
$Object = \Objects\Factory::create(\Objects\Config::MY_CONTROLLER);Phan does not understand such PHPDoc hints, but in this code the class of the object can be obtained from the name of the constant passed to the method
create(). Phan allows you to write a plugin that is triggered when analyzing the return value of a function. And using this plugin, you can tell the analyzer what type of function the function returns in this call. An example of this plugin is more complicated. But in the Phan code there is a good example.
vendor/phan/phan/src/Phan/Plugin/Internal/DependentReturnTypeOverridePlugin.php.In general, we are very pleased with the Phan analyzer. Listed above
false-positivewe partially (in simple cases, with a simple code) learned to filter. After that, Phan became an almost standard analyzer. However, the need to immediately parse the entire code base (time and a lot of memory) still complicates the process of its implementation.Psalm
Psalm is a Vimeo development. Honestly, I didn’t even know that Vimeo uses PHP until I saw Psalm.
This analyzer is the youngest of our troika. When I read the news that Vimeo released Psalm, I was at a loss: “Why invest resources in Psalm if you already have Phan and PHPStan?” But it turned out that Psalm has its own useful features.
Psalm followed in the footsteps of PHPStan: it can also be given a list of files for analysis, and it will analyze them, and connect the missing classes with autoload. At the same time, it only includes non-found classes, and the files that we are asked to analyze will not include (this is in contrast to PHPStan). The config is stored in an XML file (for us, this is rather a minus, but not very critical).
Psalm has a website.with a sandbox where you can write PHP code and analyze it. This is very convenient for bug reports: you reproduce the error on the site and give a link in GitHub. And, by the way, the site describes all possible types of errors. For comparison: there are no types of errors in PHPStan, but they are in Phan, but there is no single list that could be found.
We also liked that when displaying errors, Psalm immediately shows the lines of code where they were found. This greatly simplifies the reading of reports.
But perhaps the most interesting feature of Psalm are its custom PHPDoc tags, which allow for improved analysis (especially the definition of types). We list the most interesting of them.
@ psalm-ignore-nullable-return
It sometimes happens that the method can return formally
null, but the code is already organized in such a way that it never happens. In this case, it is very convenient that you can add this PHPDoc hint to the method / function - and Psalm will assume that it is nullnot being returned. The same card there and to false:
@psalm-ignore-falsable-return.Types for closure
If you have ever been interested in functional programming, you might have noticed that there often a function can return another function or take a function as a parameter. In PHP, this style can be very confusing for your colleagues, and one of the reasons is that PHP does not have standards for documenting such functions. For example:
functionmy_filter(array $ar, \Closure $func){ … }How can a programmer understand which interface the function has in the second parameter? What parameters should it take? What should she return?
Psalm supports syntax for describing functions in PHPDoc:
/**
* @param array $ar
* @psalm-param Closure(int):bool $func
*/functionmy_filter(array $ar, \Closure $func){ … }With this description it is already clear that
my_filteryou need to pass an anonymous function, which will take an int as input and return bool. And, of course, Psalm will check that you have exactly such a function here in the code.Enums
Suppose you have a function that accepts a string parameter, and only certain strings can be passed there:
functionisYes(string $yes_or_no) : bool{
$yes_or_no = strtolower($yes_or_no)
switch($yes_or_no) {
case ‘yes’:
returntrue;
case ‘no’:
returnfalse;
default:
thrownew \InvalidArgumentException(…);
}
}
Psalm allows you to describe the parameter of this function like this:
/** @psalm-param ‘Yes’|’No’ $yes_or_no **/functionisYes(string $yes_or_no) : bool{ … }In this case, Psalm will try to understand what specific values are passed to this function, and give errors if there are values other than
Yesand No. Read more about enum ah here .
Type aliases
In the description above,
array shapesI mentioned that, although analyzers allow us to describe the structure of arrays, it is not very convenient to use this, since the description of the array has to be copied in different places. The correct solution, of course, is to use classes instead of arrays. But in the case of multi-year legacy, this is not always possible. In fact, the problem arises not only with arrays, but with any type that is not a class:
- array;
- closure;
- union type (for example, several classes or class and other types);
- enum.
Any such type, if it is used in several places, needs to be duplicated in PHPDoc and when it is changed, accordingly, it should be fixed everywhere. Therefore, Psalm has a slight improvement in this regard. You can declare alias for a type and then use this in PHPDoc
alias. Unfortunately, there is a limitation: it works within a single PHP file. But it already simplifies the description of types. True, only for Psalm.Generics aka templates
Consider this opportunity by example. Suppose you have this function:
functionidentity($x){ return $x; }How to describe the type of this function? What type does it take to enter? What does she return?
Probably the first thing that comes to mind is
mixed, that is, it can take any value as input and return any value. For a static analyzer, meeting
mixedis a disaster. This means that there is absolutely no information about the type and no assumptions can be made. But in fact, although the function identity()accepts / returns any types, it has logic: it returns the same type that it took. And for a static analyzer this is already something. This means that in the code:$i = 5; // int
$y = identity($i);the analyzer can determine the type of the input argument
(int), and therefore, can determine the type of the variable $y(too int). But how do we pass this information to the analyzer? In Psalm, there are special PHPDoc tags for this:
/**
* @template T
* @psalm-param T $x
* @psalm-return T
*/functionidentity($x){ $return $x; }That is, templates allow you to pass Psalm type information if the class / method can work with any type.
Inside Psalm there are good examples of working with templates:
- vendor / vimeo / psalm / src / Psalm / Stubs / CoreGenericFunctions.php ;
- vendor / vimeo / psalm / src / psalm / Stubs / CoreGenericClasses.php .
Similar functionality exists in Phan, but it only works with classes: https://github.com/phan/phan/wiki/Generic-Types .
Overall, we really liked Psalm. It seems that the author is trying to “side” screw the smarter type system and smarter and practically useful tips for the analyzer. We also liked that Psalm immediately shows the lines of code in which errors were found, and we even implemented this for Phan and PHPStan. But more about that below.
Code Inspection in PHPStorm
The analyzers have a common minor flaw: you receive information about the error not at the time of writing the code, but much later. Usually you write code, then open the console and run the analyzers, and then get a report.
It would be more convenient for a programmer to get information about errors in the code editing process. Phan is moving in this direction, which is developing its language server. But we in PHPStorm, alas, are not comfortable using it.
But, fortunately, PHPStorm has its own excellent analyzer (code inspection), which is comparable in quality with the solutions described above. And in addition to it there is a cool plugin - Php Inspections (EA Extended). The main difference from analyzers is the convenience for the programmer, which consists in the fact that errors are visible in the editor while writing code. In addition, these inspections can be very finely tuned. For example, you can select different scopes files in a project and set up inspections differently for different scopes.
I would also point out such a useful plugin as deep-assoc-completion . He understands the structure of arrays and simplifies autocomplete keys.
Using analyzers in Badoo
How does this work with us?
Today, static code analysis is used by several teams, but we plan to implement this practice in all.
We analyze only the changed files, down to the lines. That is, when the developer completes his task, we take it
git diff and run the analyzers only for modified / added files, and from the resulting list of errors we remove those that belong to the old (unchanged) lines. Thus we hide from the developer the mistakes that were made earlier. Of course, this approach is not entirely correct: a programmer can break something outside of his code with his code.
git diff. Here we compromise. Even in this form, the use of static analysis yields its fruits in the form of errors found in the new code. And we do not want to force the programmer to correct old errors. But, of course, in the future, when our code becomes cleaner from the point of view of analyzers, we will reconsider this decision. Having received reports from three analyzers, we merge them into one, where errors are grouped by files and lines:
In the process of generating this report, we also try to remove some
false-positive. For example, we remember that Phan has problems with determining the type for the properties of objects, and approximately know what type these errors have. Therefore, if only Phan complained about some line and the type of error is similar to the one in which he often makes mistakes, we hide this error from the programmer.Place of analyzers in our QA
We do our best to reduce the number of bugs in production:
- we use several types of autotests;
- we have code review ;
- we have manual testing .
Static analyzers are, in fact, another tool on this list, and it complements it well. Static analyzers have several advantages:
- they can cover 100% of the code (as opposed to tests, which should be written separately for each section of code);
- they often catch such errors that are difficult to notice in the code review process;
- they are able to analyze even the code that is difficult or impossible to run with manual testing.
The task of implementing static analysis has grown out of the idea to implement
strict types. But as a result, static analyzers gave us a lot more checks than strict types, and they are more flexible:- analyzers work for the whole code, and to see the errors
strict types, you need to execute the code - The analyzer error can be corrected later if it is not critical (this may not be the best practice, but in some cases it may be useful);
- the type system in static analyzers is even more flexible than in PHP itself (for example, they support
union types, which are not in PHP); - Static analyzers bring us closer to implementation
strict types, since they are able to emulate the same rigorous checks.
Analyzers reports: the opinion of programmers
This is not to say that all programmers are delighted with static analyzers. There are several reasons for this.
First, many people have distrust of the analyzers, believing that the latter are able to find only some primitive errors that we do not allow.
Secondly, as mentioned above, a lot of analyzer reports are simply inaccuracies, for example, incorrectly specified types in PHPDoc. Some programmers dismiss such errors - the code works.
Third, some programmers have high expectations. They thought that the analyzers would find some tricky bugs, and instead they force them to add type checks and fix PHPDoc. :)
However, the benefits brought by analyzers override all these minor grievances. And whatever one may say, this is a good investment in the future code.