Identification problems for ID documents on mobile devices using machine-readable zones as an example

Fig. 1 - Russian passport with MRZ zone (Image source: en.wikipedia.org/wiki/Russian_passport )
Hello, today we want to tell you about the features of the task of recognizing identity documents using a mobile phone. As an example, we consider the task of recognizing machine-readable MRZ zones on images and on frames of a video stream received from a camera of a mobile device.
1. What is MRZ?
A machine-readable zone (MRZ) is a part of an identity document made in accordance with international recommendations set forth in Doc 9303 - Machine Readable Travel Documents of the International Civil Aviation Organization .
An example of a machine-readable zone, made in accordance with these recommendations, is the MRZ of foreign passports of citizens of the Russian Federation (Fig. 1 - below).
2. MRZ recognition using scanners (including specialized)
Consider the features of using scanning equipment in the task of optical recognition of documents. When scanning, the document is located in the perpendicular optical axis of the plane at a fixed distance from the recording matrix. This ensures that the original document and its image are homothetic, and minor distortions with small deviations from this location are easily detected and corrected. During scanning, the document is stationary during exposure, therefore, defects (blurring) of the image associated with the displacement of the original document are eliminated. Lighting in the scanner is formed by special powerful backlight lamps, which guarantee stable lighting characteristics and the absence of shadows.
A special case of scanning equipment is specialized document readers and hardware-software systems in which the image is obtained on the principles of a flatbed, planetary or slot scanner. The document in such devices is either pressed against the glass or inserted into a special slot (Fig. 2), which virtually eliminates the deformation of the scanned page of the document.




Fig. 2 - Examples of document location when using readers
These types of readers allow you to receive images of documents in various lighting schemes (white, infrared, ultraviolet, white in the light). At the same time, a scheme with white and infrared illumination can be used for optical recognition, which gives a high-contrast image with a low level of interference from background filling and security elements.

Fig. 3 - Scanning a Japan passport in white and infrared (Image source: bersisteknoloji.com.tr/index_htm_files/Regula%208703_en.pdf ) The
known relative position of the lighting elements (lamps, LEDs) relative to the working surface on which the document is located allows to completely eliminate (during the design process of the device) or to significantly simplify the compensation for glare (during operation).
Depending on the model, this kind of specialized equipment allows you to receive images in a resolution of 200 DPI or higher, while most modifications have the ability to obtain images sufficient for optical recognition of text resolution (300-400 DPI).
Thus, scanning devices provide high-quality images with minimal distortion, which allows optical recognition of text with high quality and high reliability.
3. Shooting with small format digital cameras
3.1. Common problems
Compared to scanners, the optical design of the camera is more complex and in itself introduces more distortion due to aberrations, glare and reflections inside the optical system. The use of photosensors (matrices) and analog electronics by devices for registering images inevitably leads to the appearance of distortion of images called digital noise. The sources of digital noise are the process of digitizing an analog signal (signal quantization errors, thermal noise and charge transfer on the matrix) and its further amplification. Digital noise is visible on the image in the form of an imposed mask of pixels of random color and brightness. Noise is more noticeable in monochromatic areas of the image, especially in the dark. Unlike scanning, when quality lighting is guaranteed, when shooting with digital cameras, insufficient illumination often occurs, while the effect of digital noise is naturally greatly amplified. Another source of distortion is image compression algorithms, which is especially typical for frames of a video stream.


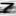

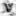
Fig. 4 - Examples of distorted images of MRZ characters of a document
Depending on the lens characteristics and the position of the document relative to the focus plane, part or all of the document image may be “blurred”. If, due to the movement of the document itself or the camera, there is a shift during exposure, then “blurring” appears (Fig. 5), which intensifies in low light conditions.



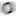

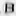

Fig. 5 - Examples of “blurred” symbol images
3.2. Projective and non-linear distortion
Unlike scanners, when shooting with a camera, the document itself is located in an arbitrary plane relative to the plane of the focused image. Deviation from the plane perpendicular to the optical axis leads to projective distortion of the document image. With insignificant deviation angles, a machine-readable zone can be recognized without additional projective correction, but in the general case, it is necessary to evaluate the parameters of the projective basis and make optical recognition for the projectively corrected image. In this case, errors in determining the parameters of the projective correction are possible, which leads to geometric distortions of symbol images. Moreover, as an object of the physical world, the original document is subject to mechanical deformation. For instance, Documents executed on paper are subject to “bending” and “curling” (most often along or across the main direction of reading), and sometimes “waves” arise when the bends in different places on the page are multidirectional. When shooting with a camera, ensuring the absence of deformations of this kind is difficult or simply impossible (Fig. 6).



Fig. 6 - Various deformation options
Mechanical deformation of a document page is combined with projective image distortion. Symbols aligned in parallel lines on the source document in the image, even after projective normalization, may not have baselines. Moreover, not only the lines themselves are distorted, but also the images of individual characters. That is, even after the correct projective normalization of the entire document, the image of the symbol from the area physically deformed on the original document will differ from the image of the same symbol from the undeformed area.
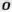
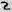
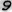
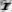
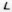
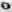
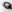
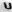

Fig. 7 - Examples of distorted images of characters due to projective and non-linear deformations
3.3. Background problems
For a machine-readable zone, ICAO 9303 states that text printing should be visually legible and black (at wavelengths B425 – B680 according to ISO 1831), and the ink should also absorb well in the near infrared range (in the range of B900 in accordance with standard ISO 1831). Thus, contrast requirements are imposed only for the infrared region of the spectral range. In practice, this leads to the fact that, subject to the standard, some countries use inks for printing the background filling of the machine-readable area, which are “transparent” in the infrared and at the same time quite “dense” in the optical (Fig. 8).

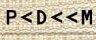


Fig. 8 - Examples of zones with "dark" and "motley" filling in the optical range
For small-format cameras of mobile devices, infrared shooting is impossible, therefore, a non-uniform background significantly complicates the process of optical zone recognition, especially in conditions of “unsuccessful” lighting.
The document lighting scheme in scanners minimizes the appearance of shadows and highlights even for “glossy” pages of documents. When shooting in natural scenes with the camera, brightness variations (shadows, reflections, reflexes, etc.) and color distortions often appear on the images, which complicate the tasks of image analysis and recognition, for example, due to the loss of existing or the appearance of false borders of objects. The pages of most documents with a machine-readable zone are either made of special plastic or coated with a protective film and have good reflective properties. Such physical properties of the subject matter lead to glare on the document (Fig. 9). Additionally, document security features often contain areas with “holographic” elements that also distort the image.


Fig. 9 - Fragments of the zone: flare from an extended light source, holographic security elements
3.4. Problems using the OCR-B font
Consider the impact of the above difficulties when using small format digital cameras on the recognition of single characters.
To print lines of text in a machine-readable zone, ICAO 9303 sets a valid subset of OCR-B font characters, with some characters having similar styles.
The most difficult to distinguish between themselves are the letter “O” and the number zero, the images of which differ only in proportions and a slight difference in “curvature”. The insignificance of differences in styles under conditions of even slight distortions or not very high resolution leads to the fact that even a person either distinguishes them with great difficulty or cannot distinguish them at all (Fig. 10).

 - - - - -
- - - - - 

Fig. 10 - Examples of hard to distinguish characters 0 (zero, left) and O (letter, right)
Thus, when using small format digital cameras to obtain document images, it is generally not possible to guarantee a high image quality of a symbol. This leads to a significantly lower quality and reliability of the recognition results of individual characters, and the contextual processing mechanisms begin to play a much more important role (compared to scanning).
4. Problems of the language model
In modern systems of recognition and identification of structured documents, statistical correction mechanisms are used to improve recognition accuracy. These mechanisms use information about the structure of the document, about the “context” of recognition, and rely on the language model of the recognized document (or recognized field). Algorithms for such statistical correction, or post-processing, based on a group of related methods, such as Hidden Markov Models (HMM), finite state machines, N-gram and dictionary methods, as well as mechanisms using weighted finite converters (Weighted Finite-State Transducers, WFST).
4.1. Context power
Consider some text field F. From the point of view of the structure of the document, the field F has some semantic structure. From the point of view of the presentation of the document, the field F also has some syntactic structure. Based on the semantics of the document and the syntactic structure of the presentation of the document for the field, you can define some language model. For example, let F be the “date of birth of holder” field of a machine-readable zone of a foreign passport of the Russian Federation. Then, according to the semantic structure, F contains information about the holder’s year, month and birthday. Since the MRZ of the foreign passport of the Russian Federation is made in accordance with the recommendations of ICAO 9303, a separate fixed position is allocated in the MRZ data structure for field F (second line MRZ, characters 14-19, with a checksum in the 20th character) and the syntax structure is defined for it: the date is written in the format YYMMDD, where YY is the last two decimal digits of the year, MM is the decimal representation of the month number, DD is the decimal representation of the day number in the month, or in the form strings “<<<<<<” of six placeholders if the date of birth is unknown. The checksum is presented as a single decimal digit and its value is calculated according to the algorithm specified by the recommendations of ICAO 9303.
Based on the specific semantic and syntactic structures of the field, you can define a language model that will encode the set of possible field values. There are several ways to represent such a language model, for example, using BNF-grammar, or as a regular language encoded by a state machine. One of the possible ways to represent the language model is to build a checking grammar G on a variety of all kinds of strings composed of alphabet characters based on the predicate of the word P. the word S corresponds to the language model G if the predicate P takes the true value on the word S. Since ICAO 9303 provides for each field some rules that limit the set of possible field values (i.e., reinforcing the predicate P), as well as the checksum mechanism,
The task of statistical correction of the recognition result of the field F with the checking grammar G is posed quite simply: in the weighted set of possible alternative values of the field F, find the value with the maximum weight at which the predicate P is satisfied. If the number of all possible values of F is finite (for example, the maximum field length is limited), you can define “context power” as the ratio of the power of the predicate falsity region P to the power of the set of all possible values of F. The larger this ratio, the “more powerful” the field context, and, accordingly, the greater the likelihood of a successful correction of the recognition result. For example, of all possible strings of length 7, consisting of decimal digits, less than 0.4% are valid dates (considering the checksum), respectively, the context power for this field exceeds 99.6%.
4.2. MRZ document code
The “document code” field is a two-character identifier for the type of MRZ document. The document code is located at the very beginning of the first line of the MRZ zone, regardless of the type of the MRZ document, and the alphabet of its first character is strictly fixed ('P' for passports, 'V' for visas, 'A', 'C' or 'I 'for other identification documents), which allows you to build for this character a fairly reliable procedure for correcting the recognition result. However, the second character of the document code is left to the discretion of the issuing organization. Since the general checksum (see section 4.7) does not apply to the “document code” field, a language model (in addition to the general restriction on the alphabet) cannot be constructed for the second character of the document type. It is also worth noting that there are organizations that issue special documents, which in their syntactic structure resemble MRZ documents, but are not. Such documents may contain the first character of the document code that is not provided for by the ICAO 9303 standard. An example of such documents is the MRZ-like zone under the driver's license of the Republic of Moldova from 1995-2010 (Fig. 11). The structure of the MRZ-like zone on this type of document coincides with the structure of the TD-2 type documents provided for in ICAO 9303, except for the “document code” field.

Fig. 11 - MRZ-like zone on the driver's license of Moldova from 1995-2010 (Image source: www.skyscrapercity.com/showthread.php?t=1540248 )
4.3. Issuing Authority Code and Citizenship
The fields “issuing state / authority” and “nationality” determine, respectively, the unique code of the organization issuing the document containing the MRZ zone and the citizenship of the document holder. These codes are based on three-letter state codes according to ISO 3166-1 with some extensions (codes corresponding to special non-governmental organizations authorized to issue identification documents and codes for persons without a specific citizenship have been added). The language model of both fields can be a dictionary - i.e. just a finite set of all kinds of three-letter codes. The share of valid codes from various three-letter words is ~ 1.4%, therefore, the power of the context of such a language model is quite high - ~ 98.6%.
4.4. Name of document holder
The “name” field is one of the most complex fields in terms of standardization, taking into account the variety of name structures in different countries and in different languages. ICAO document 9303 describes some requirements for the design of the name, on the basis of which the primary verification rules can be drawn up: the “name” field can consist of one or two sections separated by two placeholder characters (“<”), each section can consist of one or multiple words separated by one placeholder. Each word should consist only of letters of the Latin alphabet. No additional verification mechanisms are provided by ICAO 9303 (the total checksum of the MRZ document does not apply to the name field). For the “name” field, you can use well-known methods for post-processing such fields,
4.5. Document number and personal number
The fields “document number” and “personal number” (personal number / optional data) are fields with a weakly fixed syntactic structure, and therefore it is difficult to construct a sufficiently powerful mechanism of statistical correction. The alphabet for these fields is not limited (i.e., limited only by the characters possible in the MRZ document). If there is a recommendation for the “document number” field, according to which the number should not contain placeholders at the beginning and middle of the number (that is, the field can be supplemented with placeholders to the desired length, but only at the end), then the syntax structure of the “ personal number ”is entirely left to the discretion of the issuing organization. Both fields have a checksum, but even with it, the effectiveness of the post-processing mechanism is not high enough: since the alphabet contains both letters and numbers, the efficiency of post-processing decreases due to the features of calculating the checksum according to the algorithm described in ICAO 9303 (see clause 4.7). The context power for both fields can be increased using the result of other fields, such as the “issuing authority code”. Some organizations issuing identification documents define their own syntactic structure of the fields “document number” and “personal number”. Accordingly, after the result of recognition of the field “code of the issuing authority” is received (and corrected, see clause 4.3), the syntactic structure of the fields “document number” and / or “personal number” can be clarified if the limitations of the issuing organization are known in advance. post-processing efficiency decreases due to the features of calculating the checksum using the algorithm described in ICAO 9303 (see clause 4.7). The context power for both fields can be increased using the result of other fields, such as the “issuing authority code”. Some organizations issuing identification documents define their own syntactic structure of the fields “document number” and “personal number”. Accordingly, after the result of recognition of the field “code of the issuing authority” is received (and corrected, see clause 4.3), the syntactic structure of the fields “document number” and / or “personal number” can be clarified if the limitations of the issuing organization are known in advance. post-processing efficiency decreases due to the features of calculating the checksum using the algorithm described in ICAO 9303 (see clause 4.7). The context power for both fields can be increased using the result of other fields, such as the “issuing authority code”. Some organizations issuing identification documents define their own syntactic structure of the fields “document number” and “personal number”. Accordingly, after the result of recognition of the field “code of the issuing authority” is received (and corrected, see clause 4.3), the syntactic structure of the fields “document number” and / or “personal number” can be clarified if the limitations of the issuing organization are known in advance. Some organizations issuing identification documents define their own syntactic structure of the fields “document number” and “personal number”. Accordingly, after the result of recognition of the field “code of the issuing authority” is received (and corrected, see clause 4.3), the syntactic structure of the fields “document number” and / or “personal number” can be clarified if the limitations of the issuing organization are known in advance. Some organizations issuing identification documents define their own syntactic structure of the fields “document number” and “personal number”. Accordingly, after the result of recognition of the field “code of the issuing authority” is received (and corrected, see clause 4.3), the syntactic structure of the fields “document number” and / or “personal number” can be clarified if the limitations of the issuing organization are known in advance.
4.6. Dates of birth and expiration of the document
The syntactic structure of the fields “birth date” and “expiry date” are described above in paragraph (4.1). These fields are the most successful from the point of view of the language model - the alphabet of their characters is rigidly fixed (only numbers, with the exception of the separately considered case of an unknown date) and based on the semantic structure of the date field, you can build a language model with a fairly powerful context. When constructing an algorithm for combined post-processing of several fields, one can also take into account the fact that the expiration date of a document cannot be earlier than the holder’s birth date, so the power of the context for joint consideration of these fields can be further increased.
4.7. Checksums
According to ICAO document 9303, a checksum is provided for the fields “document number”, “date of birth”, “expiration date” and “personal number”. A so-called “composite check digit” is also provided, with the help of which the four fields are re-validated. However, the general checksum is not provided in all types of documents (it is absent in the so-called MRV-A and MRV-B - in machine-readable visas). The checksum takes one character of the MRZ zone for each field, and is calculated as follows:
- Each field character is assigned its weight. The first character is assigned a weight of 7, the second - 3, the third - 1. The fourth - 7, the fifth - 3, etc. repeating weights 7, 3 and 1 cyclically.
- The code of each character is multiplied by its weight. The placeholder character code ('<') is zero, the code of each decimal digit is the value of this digit, the code of each letter of the Latin alphabet is 9 + <the number of the letter in the alphabet> (The code of the letter 'A' is 10, the code of 'B' is 11 and so on. The letter code 'Z' is 35).
- The resulting works are summarized. The value of the check digit is the remainder of the received amount modulo 10.
Since the final sum of weighted character codes is taken modulo 10, a significant number of collisions occur. Particular difficulties are caused by collisions on pairs of characters that are difficult to distinguish by single-character recognition mechanisms in the conditions of recognition of mobile devices from the camera (see paragraphs 3.1, 3.2). So, the same codes (taken modulo 10) have the characters' F 'and' P ',' H 'and' R ',' G 'and' 6, 'S' and '8'. In such fields as “document number” and “personal number”, both numbers and letters of the Latin alphabet can be found, and the main method of validation is the checksum. However, if at the stage of recognition of single characters one of the characters from the above pairs was mistakenly recognized as the other member of this pair, then the checksum will not change, and the probability
The weights by which the character codes of the field being tested are multiplied also raise questions. For example, weights 7 and 3 applied to adjacent symbols give a total of 10. This means that the same symbols (or different symbols, but with the same codes modulo 10) next to each other with weights 7 and 3 together give a zero contribution to checksum, regardless of what these characters are. This in turn means that if there is a local distortion in the photo or on the frame of the video stream on which the MRZ document is recognized, due to which two adjacent characters were recognized with an error (for example, a pair of digits' 00 'was recognized as a pair of letters' OO '), and these two characters are in the positions of the field with weights 7 and 3, then using the checksum they cannot be fixed.
To increase the reliability of the sensitive data validation mechanism, ICAO 9303 provides a common checksum for some types of MRZ documents. However, the total checksum does not apply to the entire MRZ document, but only to those fields that are already protected by its own checksum.
As a result, from the point of view of language modeling with the aim of constructing mechanisms for correcting the results of recognition of an MRZ document, some fields provided by ICAO 9303 allow constructing quite powerful contexts. However, for individual fields (such as “document number”, “personal number”), the definition of a more rigorous syntactic structure would increase the quality of recognition, both in systems working with cameras of mobile devices and in traditional systems based on scanners. The quality and reliability of recognition of MRZ documents would also be enhanced by the introduction of checksums for all significant fields, or common checksums that apply to the entire document.
5. Conclusion
We described to you the main problems that we had to face while developing our Smart 3D OCR MRZ software product - Software Developer Kit for offline recognition of MRZ documents on mobile devices. In the future, we plan to present you with a review article on architecture and a number of articles on algorithms that we use in our developments related to the recognition of documents in a video stream.