Qlie visual story engine disassembly

Amateur translation of visual stories, when compared with translations of other games, has a number of features and involves working with a large amount of text. Perhaps the overwhelming majority of all visual novels were released in Japanese, only a few were translated into English (officially or by amateurs), and even less were translated into other languages.
Therefore, when working with translation, one has to deal with Japanese engines, many of which are not very friendly to localizers. Because of this, it quickly comes to the realization that the availability of translation skills, language skills, great enthusiasm and free time does not mean that the translated version of the game will soon be released.
Very roughly, the translation process of any game (not only visual stories) implies:
- Unpacking game resources (if they are not publicly available)
- Translation of the necessary parts
- Reverse packing transfer
However, in the case of Japanese visual novels, this usually looks like this:
- Unpacking game resources
- Translation of the text part of the game (game script)
- Translation of the graphic part of the game
- Reverse packing transfer
- Engine redesign to make it work with translated content
I hope our experience will be useful for someone.
Back in 2013 (and possibly earlier), I decided to translate the Bishoujo Mangekyou -Norowareshi Densetsu no Shoujo- visual novel from Japanese (美少女 япон 華 鏡 呪 呪 少女)) from Japanese. I already had experience in translating games, but before I had to translate only short stories on relatively simple and well-known engines like Kirikiri .
Here, our team of translators had to open the engine of this novel, even before getting to the actual text itself.
Let's start with the description of the .exe file, where the words QLIE and IMOSURUME are mentioned. The file itself contains the string FastMM Borland Edition 2004, 2005 Pierre le Riche, which means the engine is most likely written in Delphi.


With a quick google it is possible to find out that Qlie is the name of the visual novel engine released by Warmth Entertainment. Apparently, IMOSURUME is the internal name of the script engine, and Qlie is a commercial name. There is a site qlie.net , which lists the games released on this engine and the official site of the company Warmth Entertainment.
But nowhere in the public domain there are neither official tools for working with the engine, nor documentation for it, which is expected.
Therefore, you have to deal with the game yourself, relying on unofficial utilities. To get started is to find all the parts of the game that will need to be translated.
Game archives are in the data0.pack, data1.pack, and data7.pack files in the \ GameData subfolder. The screensavers are in the \ GameData \ Movie folder, but you can still not touch them.
The hex editor shows that there are no recognizable headers for the game .pack archives, but at the end of the file there is a piece similar to the table of contents and the FilePackVer3.0 label

Fortunately, there is already a unpacker for this format and not even one. We used the console exfp3_v3 from asmodean.
Unpacking is not as simple as it may seem. Since the engine supports several archive formats (FilePackVer1.0, FilePackVer1.0, FilePackVer3.0), and in this case, FilePackVer3.0 is used, for special unpacking you also need a special key file key.fkey, which encrypts the archive. It is located in the \ Dll subfolder.
In addition, exfp3_v3 should clarify the archive from which particular game it is unpacking.
Therefore, you also need to specify the number of the game from the list offered by the unpacker (Bishoujo Mangekyou games there at number 15), or specify the executable file of the game as the third parameter for the unpacker.

Already after unpacking the game files, a logical thought appeared: how to pack the game in the future with a ready translation? After all, the unpacker does not support reverse operation.
At our request, w8m (thanks a lot for it) added arc_conv.exe to its program to pack game archives. It is enough to pack all the modified files into a new archive (for example, data8.pack), place it in the GameData folder, and they will automatically catch up to the game.
Let's return to the unpacked resources. The game scenario files from the data0.pack archive can be found in the \ scenario \ ks_01 \ scenario subfolder.
All scenario files with the .s extension are encoded in the far from the most convenient Shift Jis encoding, and the engine does not support any Unicode encodings. Strings to translate look something like this:
【キリエ】
%1_kiri1478%
「へえ……分かっているじゃない」
私が献上したロシアンティーを見て、キリエは嬉しそうに目を細める。
^cface,,赤目微笑01
【キリエ】
%1_kiri1479%
「日本人は、ジャムを紅茶に入れて飲むのが、ロシアンティーだと勘違いしている人が多いのだけれど……」You can see that each phrase in Japanese is preceded by the name of the hero in Japanese brackets. (【】), Which this phrase is pronounced (in the game it is displayed in the upper part of the window with the text). Or, if these are the words of the author, the name is not added.

But there are still service teams.
The engine commands in the script are somewhat reminiscent of the TeX markup language, but are much more unintuitive and inconvenient compared to the Kirikiri or RenPy commands .
Here are some of them:
@@@- Triple dog. Often script files begin with this command. Apparently, loading definitions from third-party files. For example:
@@@Library\Avg\header.s@@- double dog. Label in the script file. You can go to it later. %1_kiri1478%- playing the voice file. These commands are inserted between the name of the hero and the text that is displayed on the screen. “1_kiri1478” - in this case, the file name from the \ voice \ folder of the data1.pack file. It is interesting that the Japanese percent (%) is used in the command, and not the usual one. ^savedate, ^saveroute, ^savescene,- three teams that are most likely used in the game's save system and must enter in the save information about the place and time of the player's save. For example:
^savedate,"現在"
^saveroute,"美少女万華鏡-1-"
^savescene,"呪われし伝説の少女 オープニング"That is, date: present moment, branch: Bishoujo Mangekyou -1-, scene: Norowareshi Densetsu no Shoujo Opening. This data should have been displayed in the save slot, but apparently the developers decided to refuse it. As a result,
^saveroutein all parts of the script is the same, it ^savedatechanges from “the present moment” to “dreams”, and in ^savescene-game days (or nights more) change. ^facewindow,- Textbox status with text displayed. (Shown - 1 or not - 0) ^sload,- playing in-game sounds from the \ sound \ folder on the corresponding channel.sload,Env1,◆セミ01アブラゼミPlaying the sound of cicadas on the channel Env1
The team has two optional parameters, the first is responsible for the looping of the sound, and the second is still a mystery, but it is rarely used in the game.
^sload,SE1,■クチュ音01,1Playing a looped sound on channel SE1.
^eeffect- display of the special effect for a certain number of seconds. Apparently, supports consistent output of several effects.^eeffect,WhiteFlashThe effect of a white flash.
^ffade- transition effect when changing the screen. It has a whole bunch of additional parameters, but only a few are really useful: the name of the transition effect, an additional picture, if it is required, and the transition time.
^ffade,Overlap,,1000Dissolving of one picture in another, in 1 second.
^iload- download the background image on the screen. You can assign an id to an image to access it in the future.^iload,BG1,0_black.pngThe output file 0_black.png as a background with id BG1
^weand ^wd- turns on and off the image in the window. ^facewindow,1and ^facewindow,0Turn on / off the image of the hero in the dialog box. ^mload- playing music on a specific channel.^mload,BGM1,nbgm13Playing the track nbgm13 on channel BGM1
Some of the most important commands:
\jmp- go to the label with the specified name. ^select- output to the selection window where the player must choose one of the options. For example:
^select, Да, Нет
\jmp,"@@route01a"+ResultBtnInt[0]
@@route01a0Here the transition will be performed after answering the question, and the answer number (0 or 1) is returned from ResultBtnInt [0]. As a result, the
\jmpstory will be moved to the @@ route01a tag + answer number. That is, @@ route01a0 or @@ route01a1 The unpleasant feature is that the usual comma in these commands serves as a separator and cannot be used in the response variants themselves. The Japanese have no such problem, they use the Japanese comma (、). In this case, we can replace the comma with ‚(U + 201A SINGLE LOW-9 QUOTATION MARK).
For example:
^select, Пожалуй‚ я соглашусь, Нет‚ спасибоThe remaining teams are not so important in the first approximation.
Of course, before translating, the script should be recoded into something more convenient, for example in UTF-8, in order to combine Cyrillic and Japanese characters.
After the change of the engine (about the next part), the game accepts both Russian and Japanese text. But for the time being, compatibility requires encoding Japanese characters in Shift Jis, and Cyrillic characters in cp1251 encoding.
We quickly sketched a Python program for transcoding, taking into account the Cyrillic alphabet:
UTF8 to cp1251 and ShiftJIS
# -*- coding: utf-8 -*-# UTF8 to cp1251 and ShiftJIS recoder# by Chtobi and Nazon, 2016import codecs
import argparse
from os import path
JAPANESE_CODEPAGE = 'shift_jis'
UTF_CODEPAGE = 'utf-8'
RUS_CODEPAGE = 'cp1251'defnonrus_handler(e):if e.object[e.start:e.end] == '~': # UTF-8: 0xEFBD9E -> SHIFT-JIS: 0x8160
japstr_byte = b'\x81\x60'elif e.object[e.start:e.end] == '-': # UTF-8: 0xEFBC8D -> SHIFT-JIS: 0x817C
japstr_byte = b'\x81\x7c'else:
japstr_byte = (e.object[e.start:e.end]).encode(JAPANESE_CODEPAGE)
return japstr_byte, e.end
if __name__ == '__main__':
arg_parser = argparse.ArgumentParser(prog="Recode to cp1251 and ShiftJIS",
description="Program to encode UTF8 text file to ""cp1251 for all cyrillic symbols and ShiftJIS for others. ""Output file will be inputfilename.s",
usage="recode_to_cp1251_shiftjis.py file_name")
arg_parser.add_argument('file_name', nargs=1, type=argparse.FileType(mode='r', bufsize=-1),
help="Input text file name. Only files coded in UTF8 are allowed.\n")
codecs.register_error('nonrus_handler', nonrus_handler)
input_name = arg_parser.parse_args().file_name[0].name
output_name = path.splitext(input_name)[0] + ".s"with open(input_name, 'rt', encoding=UTF_CODEPAGE) as input_file:
with open(output_name, 'wb') as output_file:
for line in input_file:
for char1 in line:
bytes_out = bytes(line, UTF_CODEPAGE)
output_file.write(char1.encode(RUS_CODEPAGE, "nonrus_handler"))
print("Done.")
However, it was not without problems. The program, when trying to transcode the symbol “tilde” U (U + FF5E FULLWIDTH TILDE), gave the error "UnicodeEncodeError: 'Shift Jis' codec can't be encoded character '\ uff5e' in position 0: illegal multibyte sequence"
First I sinned on Python, but in the end it turned out quite an unusual nuance. There is uncertainty between the Unicode and non-Unicode Japanese encoding method, depending on the specific implementation.
As a result, Windows associates the Shift Jis symbol with the code 0x8160 with Unicode ~ (U + FF5E FULLWIDTH TILDE), and other transcoders (for example, the iconv utility) correlate the same symbol with 〜 (U + 301C WAVE DASH), according to the official Unicode Ratio table - ftp://ftp.unicode.org/Public/MAPPINGS/OBSOLETE/EASTASIA/JIS/SHIFT JIS.TXT
To determine the correspondences between the symbols of Microsoft, apparently decided to use the scheme from its cp932 encoding, which is an enhanced version of Shift Jis.
The same situation with the symbol with the code 0x817C, which is converted to UTF8 as - (U + FF0D FULLWIDTH HYPHEN-MINUS) in Windows, or as - (U + 2212 MINUS SIGN) in iconv.
Since all the script files were first converted from Shift Jis to UTF8 using Notepad ++ (and it uses the matching table adopted in Windows), the reverse conversion from UTF8 to Shift Jis through our Python program appeared.
Therefore, we had to take into account the occurrence of ~ and -separate conditions.
There were other minor flaws - for example, dots ... (U + 2026 HORIZONTAL ELLIPSIS) were replaced by Cyrillic dots from cp1251, and not Japanese from Shift Jis.
After translating the text, you can proceed to work with game graphics.
Graphic files of the game are in the same pack archives, but after unpacking, they still have to work hard. For example, almost all png images are unpacked as files like sample + DPNG000 + x32y0.png In other words, png images are cut into horizontal strips, 88 pixels thick, and each strip is recorded in a separate file. The file name contains the sequence number of the bar (DPNG000 ... 009) and the x, y coordinates.

I'm still wondering why this was necessary. If it is difficult to rip resources from a game, then this is clearly not the best method.
In order to glue the cut png files, a small merge_dpng permo script from asmodeus was created, which uses ImageMagick. Unfortunately, and with him problems. First, I needed Pearl, which I did not use, and even after installing it, it turned out that the script did not work correctly.
On this occasion, we wrote a similar program on python:
Qlie engine dpng files merger
# -*- coding: utf-8 -*-# Qlie engine dpng files merger# by Chtobi and Nazon, 2016# Requires ImageMagick magick.exe on the path.import os
import glob
import re
import argparse
import subprocess
IMGMAGIC = os.path.dirname(os.path.abspath(__file__)) + '\\' + 'magick.exe'
IMGMAGIC_PARAMS1 = ['-background', 'rgba(0,0,0,0)']
IMGMAGIC_PARAMS2 = ['-mosaic']
INPUT_FILES_MASK = '*+DPNG[0-9][0-9][0-9]+*.png'
SPLIT_MASK = '+DPNG'
x_y_ajusts_re = re.compile('(.+)\+DPNG[0-9][0-9][0-9]\+x(\d+)y(\d+)\.')
if __name__ == '__main__':
arg_parser = argparse.ArgumentParser(prog="DPNG Merger\n""Program to merge sliced png files from QLIE engine. ""All files with mask *+DPNG[0-9][0-9][0-9]+*.png""into the input directory will be merged and copied to the""output directory.\n",
usage="connect_png.py input_dir [output_dir]\n")
arg_parser.add_argument("input_dir_param", nargs=1, help="Full path to the input directory.\n")
arg_parser.add_argument("output_dir_param", nargs='?', default=os.path.dirname(os.path.abspath(__file__)),
help="Full path to the output directory. ""It would be a script parent directory if not specified.\n")
input_dir = arg_parser.parse_args().input_dir_param[0]
output_dir = arg_parser.parse_args().output_dir_param[0]
os.chdir(input_dir)
all_append_files = glob.glob(INPUT_FILES_MASK) # Select only files with DPNG
prep_bunches = []
for file_in_dir in all_append_files:
# Check all files and put all splices that should be connected in separate listfor num, bunch in enumerate(prep_bunches):
name_first_part = bunch[0].partition(SPLIT_MASK)[0] # Part of the filename before +DPNG should be uniqueif name_first_part == file_in_dir.partition(SPLIT_MASK)[0]:
prep_bunches[num].append(file_in_dir)
breakelse:
prep_bunches.append([file_in_dir])
os.chdir(os.path.dirname(os.path.abspath(__file__))) # Go to the script parent dirfor prepared_bunch in prep_bunches:
sorted_bunch = sorted(prepared_bunch)
# Prepare -page params for imgmagic
png_pages_params = [["(", "-page", "+{0}+{1}".format(*[(x_y_ajusts_re.match(part_file).group(2)),
x_y_ajusts_re.match(part_file).group(3)]), input_dir+part_file, ")"]
for part_file in sorted_bunch]
connect_png_list = \
[imgmagick_page for imgmagick_pages in png_pages_params for imgmagick_page in imgmagick_pages]
output_file = output_dir + sorted_bunch[0].partition(SPLIT_MASK)[0] + ".png"
subprocess.check_output([IMGMAGIC] + IMGMAGIC_PARAMS1 + connect_png_list + IMGMAGIC_PARAMS2 + [output_file])It would seem that now we got the whole set of pictures that appears in the game? Not at all - if you view all the connected pictures from all the archives, it still turns out that some are missing, although they are in the game. The fact is that in the engine there is another type of files - with the extension .b. This is something like an animation with images and sounds recorded inside.
The resources stored inside are quite easy to get, but, alas, none of the ready unpackers of .b files in our case worked as it should. Either some files remained unpacked, or there were errors due to Japanese names, and I did not want to boot from the Japanese locale.
Here one more our script came in handy. Since then we were not familiar with something like Kaitai Struct , we had to act almost from scratch.
The .b file format was simple and, moreover, our unpacker was required to unpack resources only from this game. In other games on the Qlie engine, additional types of resources appeared inside the .b files, but we will not dwell on them in detail.
So, open any .b file in a hex editor and look at the beginning. Before evaluation, it should be noted that the byte order of all numeric values will be Little-endian.
- Header file abmp12
- Ten bytes 0x00
- The header of the first section abdata12 with service information.
- Eight bytes 0x00
- The size of the abdata12 section, a four-byte integer. You can safely skip it.
- Header section abimage10
- Seven bytes 0x00
- The number of files in the section, single-byte integer. In this case, in the section one file.
- Header section abgimgdat13
- Six bytes 0x00
- The length of the file name within the section, a two-byte integer. In this case, the length is 4 bytes.
- Shift Jis file name
- The length of the file checksum entry, a two-byte integer.
- The checksum file itself.
- Unknown byte, apparently, is always 0x03 or 0x02
- Twelve unknown bytes possibly related to animation.
- The size of the png file inside the section, four-byte integer.
And finally, the png file itself.
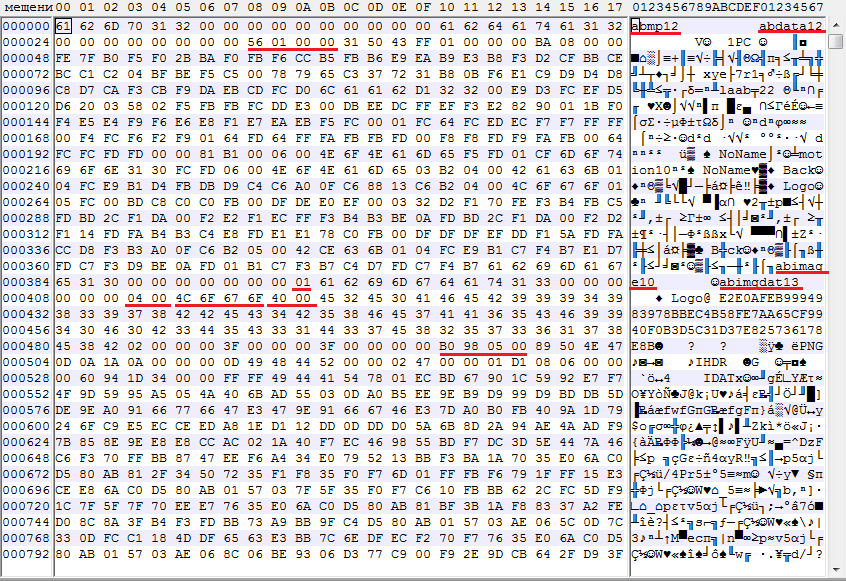
The absound section is similar in structure to abimage.
AnimatedBMP extractor
# -*- coding: utf-8 -*-# Extract b# AnimatedBMP extractor for Bishoujo Mangekyou game files# by Chtobi and Nazon, 2016import glob
import os
import struct
import argparse
from collections import namedtuple
b_hdr = b'abmp12'+bytes(10)
signa_len = 16
b_abdata = (b'abdata10'+bytes(8), b'abdata11'+bytes(8), b'abdata12'+bytes(8), b'abdata13'+bytes(8))
b_imgdat = (b'abimgdat10'+bytes(6), b'abimgdat11'+bytes(6), b'abimgdat14'+bytes(6))
b_img = (b'abimage10'+bytes(7), b'abimage11'+bytes(7), b'abimage12'+bytes(7), b'abimage13'+bytes(7),
b'abimage14'+bytes(7))
b_sound = (b'absound10'+bytes(7), b'absound11'+bytes(7), b'absound12'+bytes(7))
# not sure about structure of sound11 and sound12
b_snd = (b'absnddat11'+bytes(7), b'absnddat10'+bytes(7), b'absnddat12'+bytes(7))
Abimgdat13_pattern = namedtuple('Abimgdat13', ['signa', 'name_size_len', 'hash_size_len', 'unknown1_len',
'unknown2_len', 'data_size_len'])
Abimgdat13 = Abimgdat13_pattern(signa=b'abimgdat13'+bytes(6), name_size_len=2, hash_size_len=2, unknown1_len=1,
unknown2_len=12, data_size_len=4)
Abimgdat14_pattern = namedtuple('Abimgdat14', ['signa', 'name_size_len', 'hash_size_len', 'unknown1_len',
'data_size_len'])
Abimgdat14 = Abimgdat14_pattern(signa=b'abimgdat14'+bytes(6), name_size_len=2, hash_size_len=2, unknown1_len=77,
data_size_len=4)
Abimgdat_pattern = namedtuple('Abimgdat', ['name_size_len', 'hash_size_len', 'unknown1_len', 'data_size_len'])
# probably, abimgdat10,abimgdat11 and others
Other_imgdat = Abimgdat_pattern(name_size_len=2, hash_size_len=2, unknown1_len=1, data_size_len=4)
Absnddat11_pattern = namedtuple('Absnddat11', ['signa', 'name_size_len', 'hash_size_len', 'unknown1_len',
'data_size_len'])
Absnddat11 = Absnddat11_pattern(signa=b'absnddat11'+bytes(7), name_size_len=2, hash_size_len=2, unknown1_len=1,
data_size_len=4)
defcreate_parser():
arg_parser = argparse.ArgumentParser(prog='AnimatedBMP extractor\n',
usage='extract_b input_file_name output_dir\n',
description='AnimatedBMP extractor for QLIE engine *.b files.\n')
arg_parser.add_argument('input_file_name', nargs='+', help="Input file with full path(wildcards are supported).\n")
arg_parser.add_argument('output_dir', nargs=1,
help="Output directory.\n")
return arg_parser
defcheck_type(file_buf):if file_buf.startswith(b'\x89' + b'PNG'):
return'.png'elif file_buf.startswith(b'BM'):
return'.bmp'elif file_buf.startswith(b'JFIF', 6):
return'.jpg'elif file_buf.startswith(b'IMOAVI'):
return'.imoavi'elif file_buf.startswith(b'OggS'):
return'.ogg'elif file_buf.startswith(b'RIFF'):
return'.wav'else:
return''defbytes_shiftjis_to_utf8(shiftjis_bytes):
shiftjis_str = shiftjis_bytes.decode('shift_jis', 'strict')
utf_str = shiftjis_str.encode('utf-8', 'strict').decode('utf-8', 'strict')
return utf_str
defcheck_signa(f_buffer):if f_buffer.endswith(b_abdata):
return'abdata'elif f_buffer.endswith(b_img):
return'abimgdat'elif f_buffer.endswith(b_sound):
return'absound'defprepare_filename(out_file_name, out_dir, postfix=''):
ready_name = out_dir + os.path.basename(out_file_name) + postfix
return ready_name
defcreate_file(file_name_hndl, out_buffer):if len(out_buffer) != 0:
with open(file_name_hndl, 'wb') as ext_file:
ext_file.write(out_buffer)
else:
print("Zero file. Skipped.")
defcheck_file_header(file_handle, bytes_num):
file_handle.seek(0)
readed_bytes = file_handle.read(bytes_num)
if readed_bytes == b_hdr:
print("File is valid abmp")
returnTrueelse:
print("Can't read header. Probably, wrong file...")
returnFalseif __name__ == '__main__':
parser = create_parser()
arguments = parser.parse_args()
all_b_files = glob.glob(arguments.input_file_name[0])
output_dir = arguments.output_dir[0]
for b_file in all_b_files:
file_buffer = bytearray(b'')
with open(b_file, 'rb') as bfile_h:
check_file_header(bfile_h, len(b_hdr))
read_byte = bfile_h.read(1)
file_buffer.extend(read_byte)
while read_byte:
read_byte = bfile_h.read(1)
file_buffer.extend(read_byte)
# Finding content sections signature
check_result = check_signa(file_buffer)
if check_result:
if check_result == 'abdata':
file_buffer = bytearray(b'')
read_length = bfile_h.read(4)
size = struct.unpack('<L', read_length)[0]
file_buffer.extend(bfile_h.read(size))
# Adding _abdata to separate from other parts
outfile_name = prepare_filename(b_file, output_dir, '_abdata')
create_file(outfile_name, file_buffer)
elif check_result == 'abimgdat':
images_number = struct.unpack('B', bfile_h.read(1))[0] # Number of pictures in sectionfor i1 in range(images_number):
file_buffer = bytearray(b'')
file_name = ''
imgsec_hdr = bfile_h.read(signa_len)
if imgsec_hdr == Abimgdat13.signa:
file_name_size = struct.unpack('<H', bfile_h.read(Abimgdat13.name_size_len))[0]
# Decode filename to utf8
file_name = bytes_shiftjis_to_utf8(bfile_h.read(file_name_size))
# CRC size
hash_size = struct.unpack('<H', bfile_h.read(Abimgdat13.hash_size_len))[0]
# Picture CRC (don't need it)
pic_hash = bfile_h.read(hash_size)
unknown1 = bfile_h.read(Abimgdat13.unknown1_len)
unknown2 = bfile_h.read(Abimgdat13.unknown2_len)
pic_size = struct.unpack('<L', bfile_h.read(Abimgdat13.data_size_len))[0]
print("pic_size:", pic_size)
file_buffer.extend(bfile_h.read(pic_size))
elif imgsec_hdr == Abimgdat14.signa:
file_name_size = struct.unpack('<H', bfile_h.read(Abimgdat14.name_size_len))[0]
file_name = bytes_shiftjis_to_utf8(bfile_h.read(file_name_size))
hash_size = struct.unpack('<H', bfile_h.read(Abimgdat14.hash_size_len))[0]
pic_hash = bfile_h.read(hash_size)
bfile_h.seek(Abimgdat14.unknown1_len, os.SEEK_CUR)
pic_size = struct.unpack('<L', bfile_h.read(Abimgdat14.data_size_len))[0]
file_buffer.extend(bfile_h.read(pic_size))
else: # probably abimgdat10, abimgdat11...
file_name_size = struct.unpack('<H', bfile_h.read(Other_imgdat.name_size_len))[0]
file_name = bytes_shiftjis_to_utf8(bfile_h.read(file_name_size))
hash_size = struct.unpack('<H', bfile_h.read(Other_imgdat.hash_size_len))[0]
pic_hash = bfile_h.read(hash_size)
bfile_h.seek(Other_imgdat.unknown1_len, os.SEEK_CUR)
pic_size = struct.unpack('<L', bfile_h.read(Other_imgdat.data_size_len))[0]
file_buffer.extend(bfile_h.read(pic_size))
for i, letter in enumerate(file_name): # Replace any unusable symbols from filename with _if letter == '<'or letter == '>'or letter == '*'or letter == '/':
file_name = file_name.replace(letter, "_")
# Checking file signature and adding proper extension
outfile_name = prepare_filename(b_file, output_dir, '_' + file_name +
check_type(file_buffer))
create_file(outfile_name, file_buffer)
file_buffer = bytearray(b'')
elif check_result == 'absound':
sound_files_number = struct.unpack('B', bfile_h.read(1))[0]
for i2 in range(sound_files_number):
file_buffer = bytearray(b'')
file_name = ''
sndsec_hdr = bfile_h.read(signa_len)
if sndsec_hdr == Absnddat11.signa:
file_name_size = struct.unpack('<H', bfile_h.read(Absnddat11.name_size_len))[0]
file_name = bytes_shiftjis_to_utf8(bfile_h.read(file_name_size))
hash_size = struct.unpack('<H', bfile_h.read(Absnddat11.hash_size_len))[0]
snd_hash = bfile_h.read(hash_size)
unknown1 = bfile_h.read(Absnddat11.unknown1_len)
snd_size = struct.unpack('<L', bfile_h.read(Absnddat11.data_size_len))[0]
file_buffer.extend(bfile_h.read(snd_size))
else:
file_name_size = struct.unpack('<H', bfile_h.read(Absnddat11.name_size_len))[0]
file_name = bytes_shiftjis_to_utf8(bfile_h.read(file_name_size))
hash_size = struct.unpack('<H', bfile_h.read(Absnddat11.hash_size_len))[0]
snd_hash = bfile_h.read(hash_size)
unknown1 = bfile_h.read(Absnddat11.unknown1_len)
snd_size = struct.unpack('<L', bfile_h.read(Absnddat11.data_size_len))[0]
file_buffer.extend(bfile_h.read(snd_size))
for i, letter in enumerate(file_name):
if letter == '<'or letter == '>'or letter == '*'or letter == '/':
file_name[i] = '_'
outfile_name = prepare_filename(b_file, output_dir, '_' + file_name +
check_type(file_buffer))
print("create absound")
create_file(outfile_name, file_buffer)
file_buffer = bytearray(b'')
The script should automatically unpack found png, jpg, bmp, ogg and wav files. But beyond that, the unknown imoavi files also come across.
The point is that in the game all the animations are made either as a full-fledged video in ogv format, or as images animated by the engine, which are recorded in .b files, or as animated jpg files in imoavi format.
In this case, we were interested in jpg images, so we had to deal with them as well.
There are two sections in imoavi: SOUND and MOVIE. In the MOVIE section, 47 bytes after the header, there are four bytes of the jpg file size. The files are recorded one after another in the original form, separated by a sequence of 19 bytes, where the size of the next file is recorded.
The imoavi voiced in the game did not come across, therefore the SOUND section is always empty.
Well, since we started to engage in pulling out all the resources of the game, a small script was also written at the same time to pull out jpg from imoavi.
Imoavi extractor
# -*- coding: utf-8 -*-# Extract imoavi# Imoavi extractor for Bishoujo Mangekyou game files# by Chtobi and Nazon, 2016import glob
import os
import struct
import argparse
imoavi_hdr = b'IMOAVI'
hdr_len = len(imoavi_hdr)
defcreate_file(file_name, out_buffer, wr_mode='wb'):if len(out_buffer) != 0:
with open(file_name, wr_mode) as ext_file:
ext_file.write(out_buffer)
else:
print("Zero file. Skipped.")
defprepare_filename(file_name, out_dir, postfix=''):
ready_name = out_dir + os.path.basename(file_name) + postfix
return ready_name
defcreate_parser():
arg_parser = argparse.ArgumentParser(prog='Imoavi extractor\n',
usage='extract_imoavi input_file_name output_dir\n',
description='Imoavi extractor for QLIE engine *.imoavi files.\n')
arg_parser.add_argument('input_file_name', nargs='+', help="Input file with full path(wildcards are supported).\n")
arg_parser.add_argument('output_dir', nargs='+', help="Output directory.\n")
return arg_parser
if __name__ == '__main__':
parser = create_parser()
arguments = parser.parse_args()
all_imoavi = glob.glob(arguments.input_file_name[0])
output_dir = arguments.output_dir[0]
for imoavi_f in all_imoavi:
file_buffer = bytearray(b'')
with open(imoavi_f, 'rb') as imoavi_h:
# Read imoavi file header
imoavi_h.read(hdr_len)
imoavi_h.seek(2, os.SEEK_CUR) # 0x00
imoavi_h.seek(1, os.SEEK_CUR) # 0x64
imoavi_h.seek(3, os.SEEK_CUR) # 0x00
imoavi_h.seek(5, os.SEEK_CUR) # SOUND
imoavi_h.seek(3, os.SEEK_CUR) # 0x00
imoavi_h.seek(1, os.SEEK_CUR) # 0x64
imoavi_h.seek(11, os.SEEK_CUR)
imoavi_h.seek(5, os.SEEK_CUR) # Movie
imoavi_h.seek(3, os.SEEK_CUR) # 00 ??
imoavi_h.seek(1, os.SEEK_CUR) # 0x64
imoavi_h.seek(3, os.SEEK_CUR) # 0x00 ??
imoavi_h.seek(4, os.SEEK_CUR) # ??
imoavi_h.seek(1, os.SEEK_CUR) # Number of jpg files in section
imoavi_h.seek(4, os.SEEK_CUR) # 0x00
imoavi_h.seek(1, os.SEEK_CUR) # 0x05 ???
imoavi_h.seek(2, os.SEEK_CUR) # 0x00 ??
imoavi_h.seek(4, os.SEEK_CUR) # 720 ??
imoavi_h.seek(4, os.SEEK_CUR) # Full size without header?
to_next_size = struct.unpack('<L', imoavi_h.read(4))[0] # Bytes till next header
imoavi_h.seek(16, os.SEEK_CUR) # 0x00
jpg_size = struct.unpack('<L', imoavi_h.read(4))[0]
imoavi_h.seek(4, os.SEEK_CUR) # 0x00
file_num = 0
file_buffer.extend(imoavi_h.read(jpg_size))
outfile_name = prepare_filename(imoavi_f, output_dir, '_' + (str(file_num)).zfill(3) + '.jpg')
create_file(outfile_name, file_buffer)
while to_next_size != 0:
file_buffer = bytearray(b'')
to_next_size = struct.unpack('<L', imoavi_h.read(4))[0]
if to_next_size == 24: # 0x1C header for index part
file_buffer.extend(imoavi_h.read(to_next_size))
outfile_name = prepare_filename(imoavi_f, output_dir, '_' + '.index')
create_file(outfile_name, file_buffer, 'ab') # concatenate with index fileelse:
imoavi_h.seek(2, os.SEEK_CUR) # unknown
imoavi_h.seek(2, os.SEEK_CUR) # Unknown, almost always FF FF or FF FE
file_num = struct.unpack('B', imoavi_h.read(1))[0] # File number
imoavi_h.seek(11, os.SEEK_CUR) # 0x00
jpg_size = struct.unpack('<L', imoavi_h.read(4))[0]
imoavi_h.seek(4, os.SEEK_CUR) # 0x00
file_buffer.extend(imoavi_h.read(jpg_size))
outfile_name = prepare_filename(imoavi_f, output_dir, '_' + (str(file_num)).zfill(3) + '.jpg')
create_file(outfile_name, file_buffer)
After unpacking, you can make sure that the animation from the screen saver in the menu is stored just in the 1_ イ ト ル 画面 ム ム ー ビ ー .b file in imoavi format.
On this game with all the resources.
Unfortunately, during the translation process, several more unpleasant nuances emerged that could not be overcome. The game, as I already wrote, does not support Unicode encodings. Therefore, all translated text is displayed at the wrong letter spacing. There were a few more problems with back-packing files and running the game without changing the system encoding to Japanese.
At some point, we (or rather, the one who was responsible for the technical part of the translation in our team) thought: maybe we shouldn't hang around with the old engine, but port the novelty to the Renpy engine, at the same time getting a cross-platform format?
Perhaps we hurried, but at some point, it was a pity to quit, and there was nothing left but to finish the translation.
What did we have to face during porting?
About this in the second part.
Links:
Our scripts on bitbucket
About the Qlie engine in Japanese
Shift Jis encoding table
Learn more about the problem of transcoding from Shift Jis to UTF-8
The exfp3_v3 utility from asmodean